农业生产中的机器学习技术 Posted 2021-04-03 深度学习与计算机视觉
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了农业生产中的机器学习技术相关的知识,希望对你有一定的参考价值。
农业对你今天的生活有什么影响?如果你住在城市里,你可能会觉得你与生产食物的农场和田地没有多大联系,但是农业却是我们生活的一个核心部分,而我们却常常不认为是这样的。
今天的农民面临着一个巨大的挑战,即用更少的土地来养活日益增长的全球人口。预计到2050年,世界人口将增长到近100亿,这使得全球粮食需求增加50%。
随着粮食需求的增长,土地、水和其他资源将面临更大的压力。农业中固有的可变性,如气候条件的变化,以及杂草和害虫等威胁,也会对农民生产粮食的能力产生影响。在使用更少资源的同时生产出更多粮食的唯一方法是通过智能机器,该机器可以帮助工作困难的农民,提供更高的一致性,准确性和效率。
农业机器人
在蓝河科技,我们正在制造下一代智能机器。农民使用我们的工具来控制杂草和降低成本,以促进农业的可持续发展。
我们的除草机器人集成了摄像头、计算机视觉、机器学习和机器人技术,还具备了一款智能喷雾器,可以在田间行驶(使用AutoTrac将驾驶员的负载降至最低),并快速锁定目标并喷洒杂草,而使作物完好无损。
AutoTrac:
https://www.deere.com/en/technology-products/precision-ag-technology/guidance/auto-trac/
这台机器需要实时决定什么是庄稼,什么是杂草。当机器在野外行驶时,高分辨率相机以高帧速率采集图像。
我们开发了一个卷积神经网络(CNN模型),使用Pytorch分析每一帧,并生成一张像素精确的农作物和杂草所在的地图。一旦所有的植物都被识别出来,则每个杂草和作物都被映射到田间位置,机器人只喷洒杂草。
整个过程在几毫秒内完成,因为效率很高,农民就可以覆盖尽可能多的土地。
以下这是一个很棒的See&Spray视频,详细介绍了该过程。
https://youtu.be/XH-EFtTa6IU
为了支持机器学习(ML)和机器人技术,我们基于NVIDIA Jetson AGX Xavier Edge AI平台构建了一个令人印象深刻的计算单元。
由于我们所有的推断都是实时进行的,上传到云端需要的时间太长,所以我们将服务器带到了作业现场。
专门用于视觉推理和喷雾的机器人总计算能力与IBM的超级计算机Blue Gene(2007)相当,这使它成为全球移动机械中具有最高计算能力的机器!
杂草检测模型的建立
我的研究人员和工程师团队负责训练识别作物和杂草的神经网络模型,这是一个具有挑战性的问题,因为许多杂草看起来就像庄稼。专业的农学家和杂草科学家进行我们的标签工作,让我们的工作人员可以正确地标记图像——你能发现下面哪些是杂草吗?
机器学习栈
在机器学习方面,我们有一个复杂的堆栈。我们用Pytorch训练我们所有的模型。我们在Pytorch上建立了一组内部库,允许我们进行可重复的机器学习实验。我的团队职责分为三类:
与机器学习、A/B测试、流程改进、软件工程相关的数据分析/数据科学
我们选择Pytorch是因为它非常灵活且易于调试,新的团队成员可以很快跟上进度,而且文档非常详尽。
在使用PyTorch之前,我们的团队广泛使用Caffe和Tensorflow。2019年,我们决定改用Pytorch,过渡很顺利,这个改变同时也为工作流的研究提供了支持。
例如,我们使用Torchvision库进行图像变换和张量变换,它包含了一些基本的功能,并且与像imgauge这样复杂的增强包进行了很好的集成。torchvision 中的变换对象与imgauge的集成都是小菜一碟。
下面是一个使用Fashion MNIST数据集(
https://github.com/zalandoresearch/fashion-mnist
) 的代码示例。
名为CustomAugmentor的类将初始化构造函数中的iaa.Sequential对象,然后在__call__方法中调用invoke_image(),然后在ToTensor()之前将CustomAugmentor()添加到对transforms.Compose()的调用中。
现在,当加载批次数据进行训练和验证时,train和val数据加载器将应用CustomAugmentor()中定义的增强操作。
from imgaug import augmenters as iaaimport numpy as npimport osimport torchfrom torch.utils.data import DataLoader, random_splitfrom torchvision.datasets import FashionMNISTfrom torchvision import datasets, transforms'./fashionMNIST/' class CustomAugmentor :def __init__ (self) :0.5 ),0.0 , 0.1 )),0.9 , 1.1 )),0 , 0.05 )),0 , 0.05 *255 ))def __call__ (self, img) :# 在此处返回一个副本以解决错误:至少一个步幅 #在给定的numpy数组中为负,张量为负跨度 #当前不支持。 return self.aug.augment_image(img).copy()# 转换图像 True , download=True , transform=transform)False , download=True , transform=transforms.ToTensor())55000 , 5000 ])64 )64 )64 )
此外,PyTorch已成为计算机视觉生态系统中最入门的工具(请参阅
https://paperswithcode.com/
,PyTorch是常见的提交),这样一来,我们就可以轻松地尝试诸如Debiased Contrastive Learning之类的新技术来进行半监督式训练。
在模型训练方面,我们有两个正常的工作流程:生产和研究。
对于研究应用程序,我们的团队在内部本地计算群集上运行PyTorch。在本地群集上执行的作业由Slurm管理,Slurm是基于HPC批处理作业的调度程序,它是免费且易于设置和维护的,提供了我们小组运行数千个机器学习作业所需的所有功能。
对于基于生产的工作流程,我们在AWS托管的Kubernetes(K8s)集群之上利用Argo工作流程,我们的PyTorch训练代码是使用Docker部署到云中的。
在农业机器人上部署模型
对于生产部署,我们的首要任务之一是在边缘计算设备上进行高速推理。如果机器人需要开得慢一点来等待推断,那么它在田间的效率就不可能那么高了。
为此,我们使用TensorRT将网络转换为NVIDIA Jetson AGX Xavier优化模型。TensorRT不接受JIT模型作为输入,因此我们使用ONNX从JIT转换为ONNX格式,然后使用TensorRT转换为直接部署到设备上的TensorRT引擎文件。
随着工具栈的发展,我们期望这个过程也会得到改进。我们的模型使用Jenkins构建过程部署到Artifactory,并通过从Artifactory中提取来将它们部署到现场的远程机器上。
为了监控和评估我们的机器学习运行,我们发现
http://wandb.com/
平台是最好的解决方案,他们的API使得将W&B日志集成到现有的代码库中变得更快。我们使用W&B监控正在进行的训练,包括训练的实时曲线和验证损失。
SGD vs Adam Project
作为使用Pytorch和W&B的一个例子,我将运行一个实验,来比较在Pytorch中使用不同求解器的结果。Pytorch中有许多不同的求解器,那我们应该选择哪一种?
Adam 是一个很受欢迎的解决方案,它通常在不需要设置任何参数的情况下给出良好的结果,该求解器位于
https://pytorch.org/docs/stable/optim.html
下
对于机器学习研究人员来说,另一个流行的求解器选择是随机梯度下降(SGD),此求解器在Pytorch中可用
https://pytorch.org/docs/stable/optim.html#torch.optim.SGD
来获得
如果你不知道两者之间的差异,我建议你把这两个的区别写下来。动量是机器学习中的一个重要概念,它可以避免陷入优化空间中的局部最小值,从而找到更好的解决方案。使用SGD和动量的问题是:我能找到击败Adam的SGD的动量设置吗?
实验装置如下,我对每次运行使用相同的训练数据,并在同一个测试集中评估结果。我要比较一下F1 score在不同的运行中的得分。我用SGD作为求解器设置了许多次运行,并从0–0.99扫描动量值(当使用动量时,大于1.0的任何值都会导致求解器发散)。
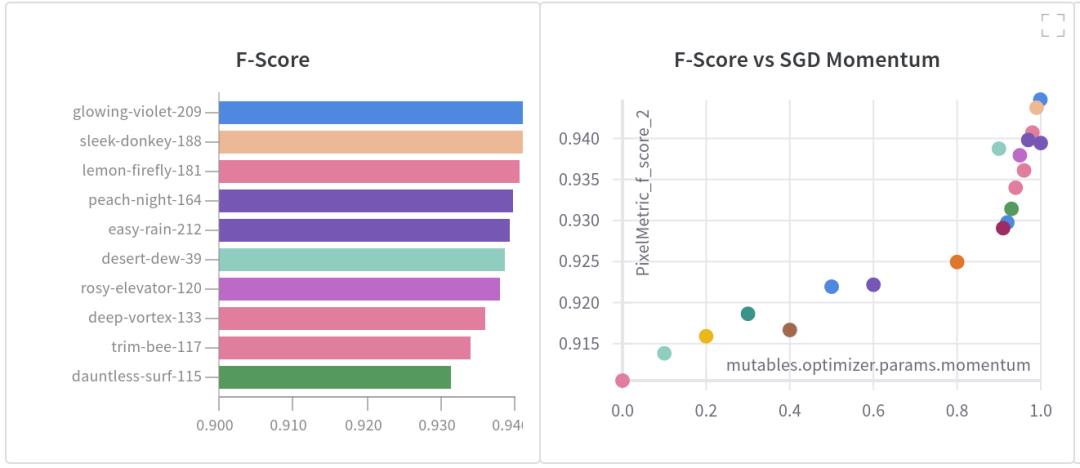
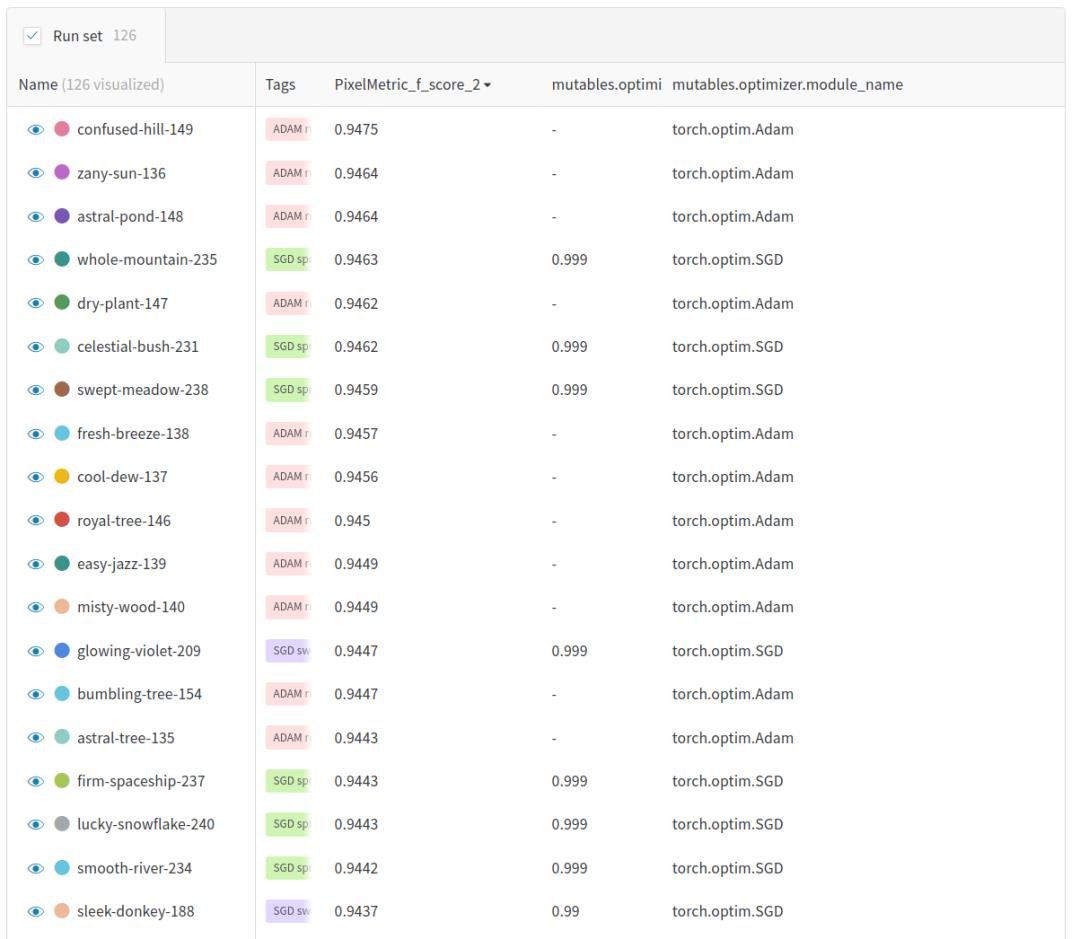
我运行了10次,动量值从0到0.9,增量为0.1,接下来,我又运行了10次,这次动量值在0.90到0.99之间,增量为0.01。在看了这些结果之后,我还进行了一组动量值为0.999和0.9999的实验。每次运行都使用不同的随机种子,并在W&B中被赋予“SGD扫描”标签。结果如图1所示。
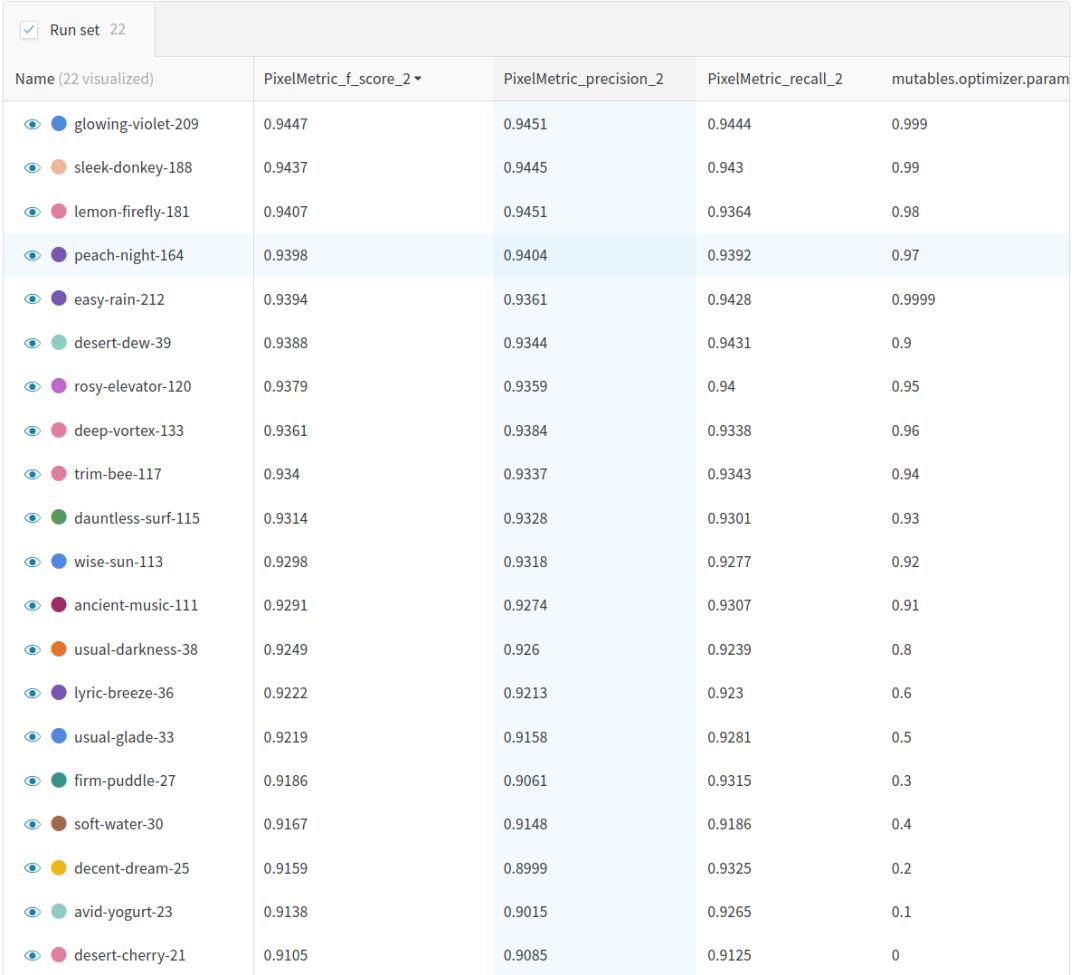
从图1非常清楚,动量值越大,f1分数越高,最佳值0.9447在动量值0.999时出现,在动量值0.9999时下降到0.9394。数值如下表所示。
表1:每次运行在上表中显示为一行,最后一栏是运行的动量设置,显示了第2类(庄稼)的F1得分,准确性和召回率。
这些结果与Adam相比如何?为了测试这一点,我仅用默认参数来使用 torch.optim.Adam 。我用W&B中的“Adam runs”标签来标识这些运行记录,同时还标记了每一组SGD运行以进行比较。
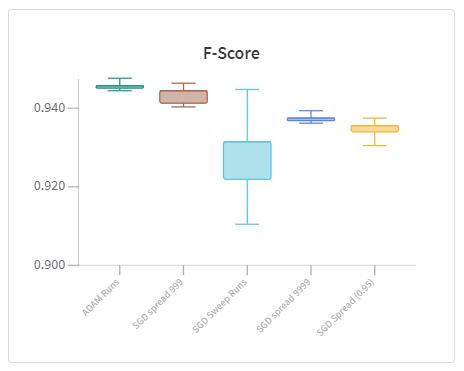
由于每次运行使用不同的随机种子,求解器每次初始化都会不同,并在最后一个epoch使用不同的权重,这会在每次运行的测试集中得到稍微不同的结果。为了比较它们,我需要测量Adam和SGD运行值的分布,使用W&B中按标签分组的箱形图可以轻松做到这一点。
结果在图2中以图表形式进行显示,在表2中以表格形式进行显示。完整的报告也可以在线获得。
https://app.wandb.ai/blueriver/blog-post/reports/AI-For-AG-Production-ML-for-Agriculture--VmlldzoxNTA1MDg?accessToken=icdp45djyu5zxey5h0sa41bdvoncfqp1buga0h2fnj6cgf6cs8xsg23hiar8qr14
你可以看到,仅通过SGD调整动量值是无法击败Adam的。动量设置为0.999可以得到非常相似的结果,但Adam运行的方差更小,平均值也更高,因此,Adam似乎是解决我们的植物分割问题的一个好选择!
Pytorch可视化
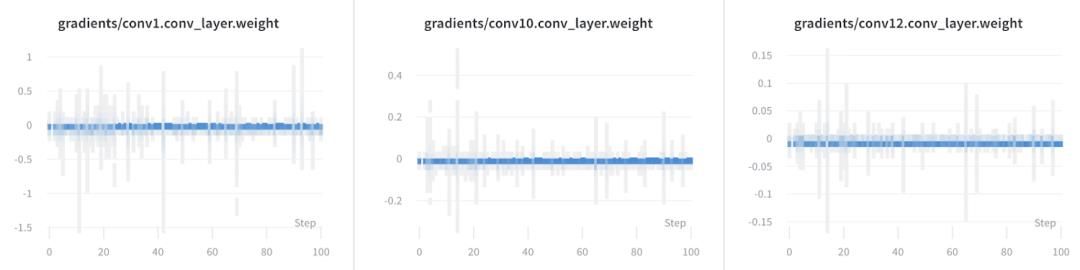
通过集成Pytorch,W&B可以在每一层中获取梯度,让我们在训练期间检查网络。
W&B实验跟踪还可以使Pytorch模型在训练期间更容易可视化,因此你可以在中央仪表板上实时查看损失曲线。我们在团队会议中使用这些可视化效果来讨论最新结果并共享更新。
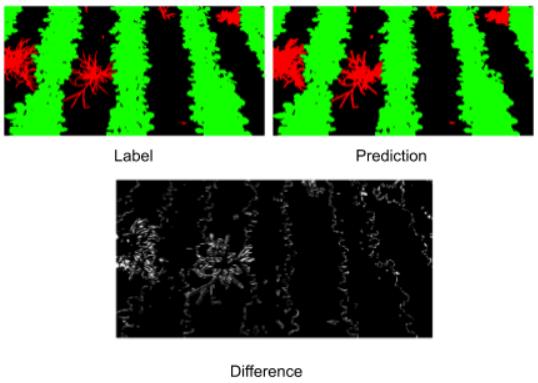
当图像通过Pytorch模型时,我们将预测记录到 Weights & Biases 中,以可视化模型训练的结果。在这里我们可以看到预测、正确标注和标签,这样可以轻松地确定模型性能未达到我们期望的情况。
在这里,我们可以快速浏览正确标注,预测以及两者之间的差异。我们将农作物标记为绿色,将杂草标记为红色,如你所见,该模型在识别图像中的农作物和杂草方面做得相当合理。
# Per-sample dataframe with images. # Loop through the mini-batches. Each batch is a dictionary. in batches:255.0 'image' ] = wandb.Image(image)# colorize_segmentation is a method which alpha-blends the class colors into an image. 'pred' ] = wandb.Image(colorize_segmentation(zeros, pred, alpha=1.0 ))'label' ] = wandb.Image(colorize_segmentation(zeros, label, alpha=1.0 ))'diff' ] = wandb.Image(diff)# Convert the list of datapoints to a pandas dataframe and log it to W&B. 'my_awesome_dataframe’' ] = log_df
可复制模型
再现性和可追溯性是任何ML系统的关键特性,而且该过程很难得到正确的结果。当比较不同的网络体系结构和超参数时,输入数据必须相同才能使运行具有可比性。
通常ML团队中的个体实践者都会保存YAML或JSON配置文件,即要找到团队成员的运行记录并仔细查看他们的配置文件以找出使用了什么训练集和超参数,这是一件非常痛苦的事情。
W&B刚刚发布的一个新特性解决了这个问题。工件(Artifact)允许我们跟踪训练和评估运行的输入和输出,这对我们的可重复性和可追溯性有很大帮助,我可以知道使用了哪些数据集来训练模型,生成了哪些模型(来自多次运行)以及模型评估的结果。
典型的用例如下。数据暂存过程将下载最新和最大的数据,并将其暂存到磁盘上进行训练和测试(每个数据集都是单独的),这些数据集被指定为工件(Artifact)。
训练运行将训练集工件(Artifact)作为输入,并将经过训练的模型输出为输出工件(Artifact)。评估过程将测试集工件(Artifact)与训练的模型工件(Artifact)一起作为输入,并输出可能包含一组度量或图像的评估。
有向无环图(DAG)是在W&B中形成和可视化的,这是很有帮助的,因为跟踪将机器学习模型发布到生产中所涉及的工件(Artifact)非常重要,这样的DAG很容易形成:
Artifacts特性的一大优点是可以选择上传下载所有工件(Artifact)(数据集、模型、评估),也可以选择只上传下载对工件(Artifact)的引用,这是一个很好的特性,因为移动大量数据既耗时又慢。对于数据集工件(Artifact),我们只需在W&B中存储对这些工件(Artifact)的引用,这就允许我们保持对数据的控制(并避免长时间的传输),并且在机器学习中仍然可以获得可追溯性和再现性。
# 初始化 wandb. "train" , reinit=True , project=”blog-post”, False ) # 指定用于训练运行的工件(Artifact)。在这里我们指定一个训练数据集和测试数据集。 # 遍历列表,并告诉wandb使用工件(Artifact)。 for elem in artifact_list:
领导ML团队
回顾我领导机器学习工程师团队的这些年,我看到了一些常见的挑战:
效率:当我们开发新模型时,我们需要快速试验并分享结果。Pytorch使我们很容易快速添加新特性,W&B为我们提供了调试和改进模型所需的可见性。
灵活性:与我们的客户合作,每天都会带来新的挑战。我们的团队需要能够满足我们不断变化需求的工具,这就是为什么我们选择Pytorch作为其蓬勃发展的生态系统,选择W&B作为轻量级的模块化集成。
性能:归根结底,我们需要为我们的农业机器人建立最精确和最快的模型。Pytorch使我们能够快速迭代,然后将模型产品化并部署到现场。我们在W&B的开发过程中具有完全的可视性和透明度,使我们很容易确定性能最好的模型。
参考链接:https://medium.com/pytorch/ai-for-ag-production-learning-for-agriculture-e8cfdb9849a1
如果看到这里,说明你喜欢这篇文章,请
转发、点赞
。微信搜索「uncle_pn」,欢迎添加小编微信「 mthler」,每日朋友圈更新一篇
高质量博文
。
以上是关于农业生产中的机器学习技术的主要内容,如果未能解决你的问题,请参考以下文章