kafka生产者怎么样能够保障数据不丢,不重复且分区内数据有序!
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了kafka生产者怎么样能够保障数据不丢,不重复且分区内数据有序!相关的知识,希望对你有一定的参考价值。
参考技术A acks=0,生产者发送过来数据就不管了,可靠性差,效率高;acks=1,生产者发送过来数据Leader应答,可靠性中等,效率中等;
acks=-1,生产者发送过来数据Leader和ISR队列里面所有Follwer应答,可靠性高,效率低;
在生产环境中,acks=0很少使用;acks=1,一般用于传输普通日志,允许丢个别数据;acks=-1,一般用于传输和钱相关的数据,
对可靠性要求比较高的场景。
至少一次(At Least Once)= ACK级别设置为-1 + 分区副本大于等于2 + ISR里应答的最小副本数量大于等于2
最多一次(At Most Once)= ACK级别设置为0
总结:
At Least Once可以保证数据不丢失,但是不能保证数据不重复;
At Most Once可以保证数据不重复,但是不能保证数据不丢失。
精确一次(Exactly Once):对于一些非常重要的信息,比如和钱相关的数据,要求数据既不能重复也不丢失。
Kafka 0.11版本以后,引入了一项重大特性:幂等性和事务。
幂等性就是指Producer不论向Broker发送多少次重复数据,Broker端都只会持久化一条,保证了不重复。
经上所述,如果保障数据不丢,不重复需要保证一下条件:
精确一次(Exactly Once) = 幂等性 + 至少一次( ack=-1 + 分区副本数>=2 + ISR最小副本数量>=2)
开启参数 enable.idempotence 默认为 true,false 关闭。
如何保障kafka内数据有序呢?
kafka在1.x及以后版本保证数据单分区有序,条件如下:
(2)开启幂等性
max.in.flight.requests.per.connection需要设置小于等于5。
(1)未开启幂等性
max.in.flight.requests.per.connection需要设置为1。
原因说明:因为在kafka1.x以后,启用幂等后,kafka服务端会缓存producer发来的最近5个request的元数据,
故无论如何,都可以保证最近5个request的数据都是有序的
大数据之kafka生产者数据可靠性保障
🌸在上一篇的博客中,我们学习了kafka的生产者传输数据的原理,今天我们来学习生产者通过哪些机制确保将数据正确无误地发送给kafka集群的,对往期内容感兴趣的小伙伴可以参考如下内容👇:
- 链接: kafka入门基础.
- 链接: 大数据之kafka生产者原理.
🍃在生产者和kafka集群之间进行消息传输时,会涉及到ACK(消息确认,PositiveAcknowlegement),那么kafka的ACK是如何运作的,又分为哪几种级别呢?
本文目录
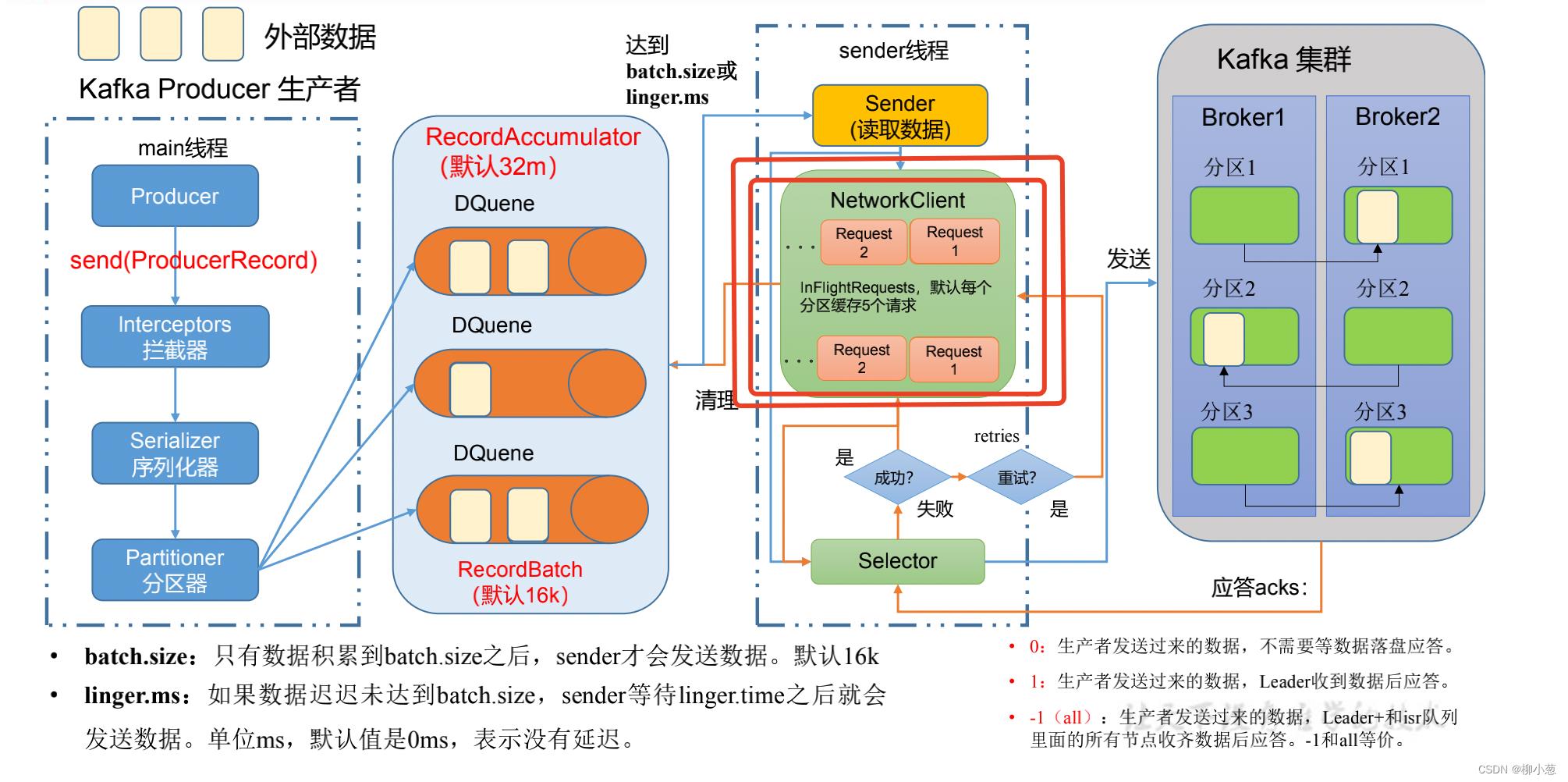
1. 生产者的消息发送流程
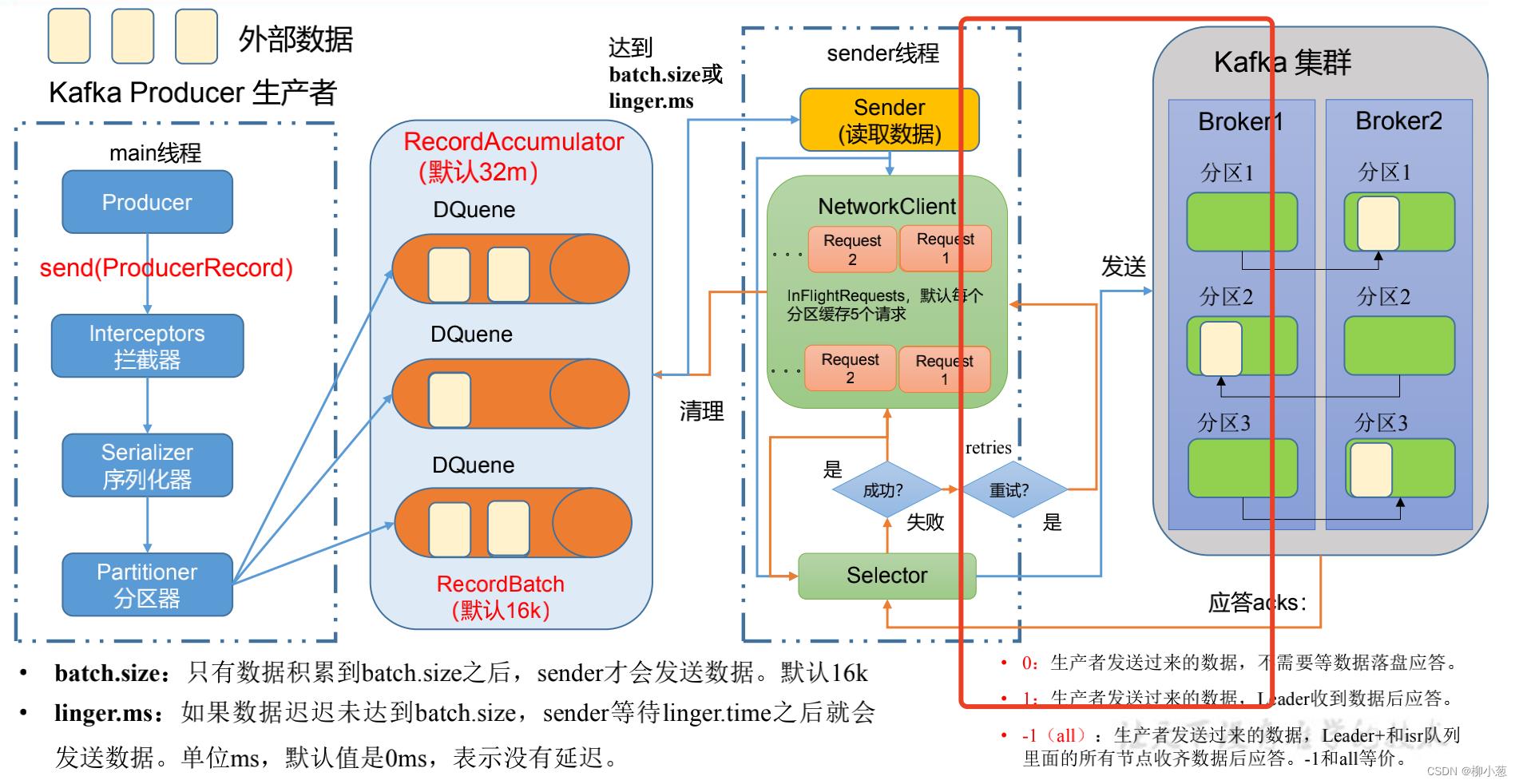
这里展示的生产者消息传输的过程,其中ACK的应答机制在上图红色框框的部分,也就是kafka集群收到消息后返回给生产者确认收到的信息。
2. kafka的ACK应答级别
kafka的应答级别主要有三种:0、1、-1
2.1 ACK=0
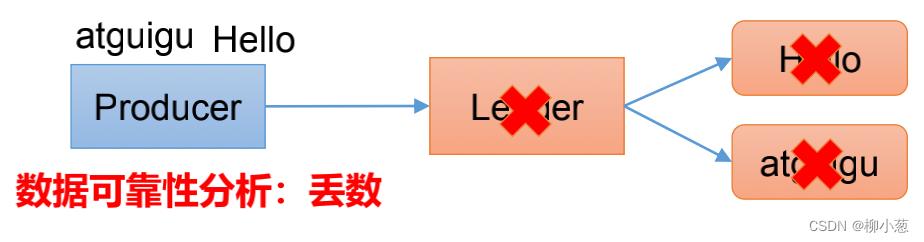
ACK=0等于0代表着发送过来的数据,不需要应答(leader数据没有落盘,也没有和follower同步),直接回复收到,这样带来的结果就是leader挂掉之后数据直接就丢失了。(几乎没人使用)
2.2 ACK=1
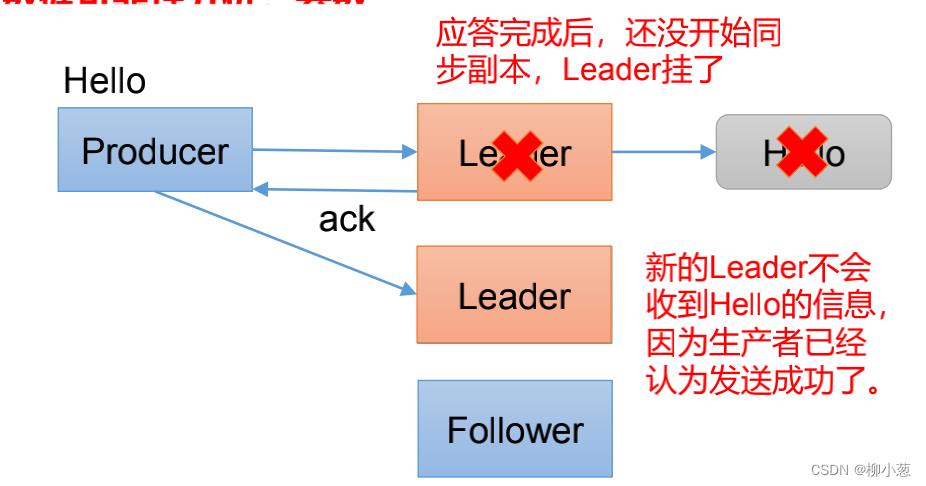
ACK=1代表leader收到数据后,数据落盘了,但是没有和follower进行同步,就可以应答。这情况容易出现的问题是leader的数据已经落盘了,但是没有进行副本的存储,一旦这个时候leader挂掉了,kafka会推荐出新的follower成为新的leader,但是上面挂掉的leader的数据已经丢失了。
2.3 ACK=-1
ACK=-1代表leader收到数据,且所有的follower都拉取到了leader的数据之后,才进行应答,这样保证了leader挂掉之后,数据也存在了follower之中,可以进行恢复,不会丢失数据。(企业中使用较多)
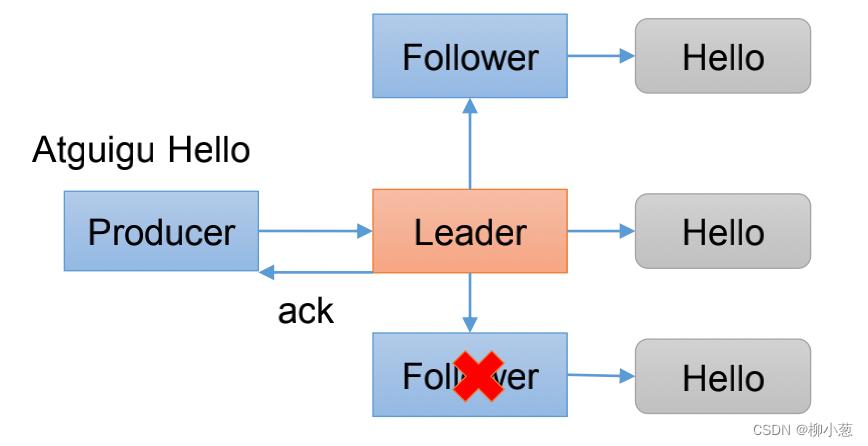
在企业中ACK=-1是最可靠的,也是用的最多的,但是这种情况会面临一个问题,既然需要等到follower应答之后才能确认成功,但是如果这个过程中follower出现故障,那么生产者就会一直得不到应答,消息就不会继续发送。
3. Leader中的ISR队列
3.1 ISR的介绍
ACK=-1的情况中,会出现follower挂掉而导致leader一直不能应答的情况,便出现了ISR队列。
leader维护了一个动态的in-sync replica set (ISR)队列,主要是存储正常工作的leader+follower的信息集合,如 (leader: 0, isr.0,1,2),表示当前leader为broker 0,follower为 broker 1,2。
I
S
R
=
(
l
e
a
d
e
r
:
0
;
i
s
r
:
0
,
1
,
2
)
ISR=(leader:0;isr:0,1,2)
ISR=(leader:0;isr:0,1,2)
如果follower长时间未向leader发送通信请求或同步数据,则该follower将被踢出ISR。该时间國值由replica.lag.time.max.ms参数设定,默认30s。例如2超时,直接去除broker2, ISR为(leader:0, isr:0,1)。这样就不用等长期联系不上或者己经故障的节点。
注:如果分区副本数设置为1,或者ISR里面的最小副本数设置为1,则效果等同于ACK=1。所以kafka数据可靠性保障为:
数
据
可
靠
=
(
A
C
K
=
−
1
)
+
(
分
区
副
本
数
>
1
)
+
(
I
S
R
里
面
的
最
小
副
本
数
>
1
)
数据可靠=(ACK=-1)+(分区副本数>1)+(ISR里面的最小副本数>1)
数据可靠=(ACK=−1)+(分区副本数>1)+(ISR里面的最小副本数>1)
3.2 ISR的新问题
有了ISR能够保障数据不丢,但是面临着新的问题:如果数据在leader同步完,follower也同步完,但是在发送ack消息的时候,leader挂掉,系统选取新的follower作为leader,这就出现了一个问题,我们的‘hello’数据其实已经在这个follower中同步完了,但是producer没收到ack应答,且这个follower成为了新的leader,于是又发送了‘hello’数据,这就导致了数据重复的问题。
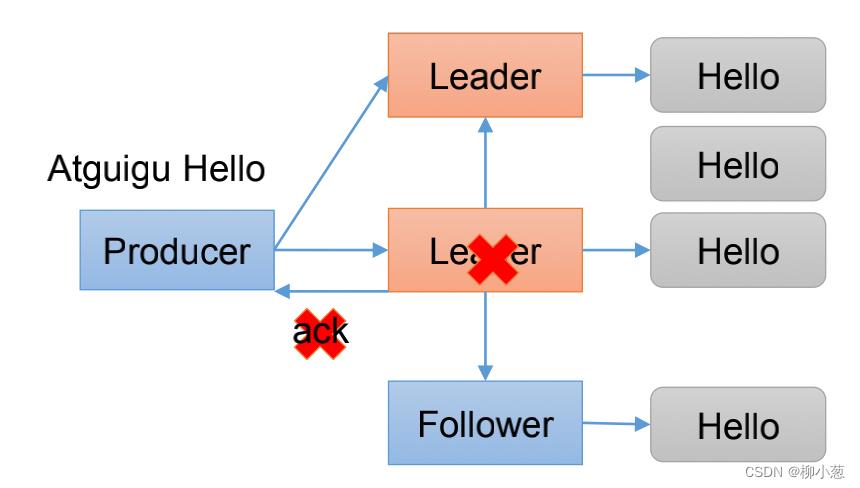
4. 生产者的数据重复
数据一致性保障有三种类型:
- 至少一次(at least once):数据可以重复不能丢失
- 最多一次(at most once):数据可以丢失但不能重复
- 精确一次(exactly once):数据即不丢失也不重复
4.1 幂等性
幂等性很像幂写入,是指producer无论向broker发送多少条重复的数据,broker端只会持久化一条,保证了不重复:
精
确
一
次
=
幂
等
性
+
上
面
的
数
据
可
靠
精确一次=幂等性+上面的数据可靠
精确一次=幂等性+上面的数据可靠
kafka发送消息是以<PID,Partition,SeqNumber>三个主键的来判断消息是否重复,其中:
- PID代表的生产者id,每次重启都会产生一个PID
- Partition代表消息的分区号
- SeqNumber序列化号,单调递增的
幂等性处理的消息的过程如下:
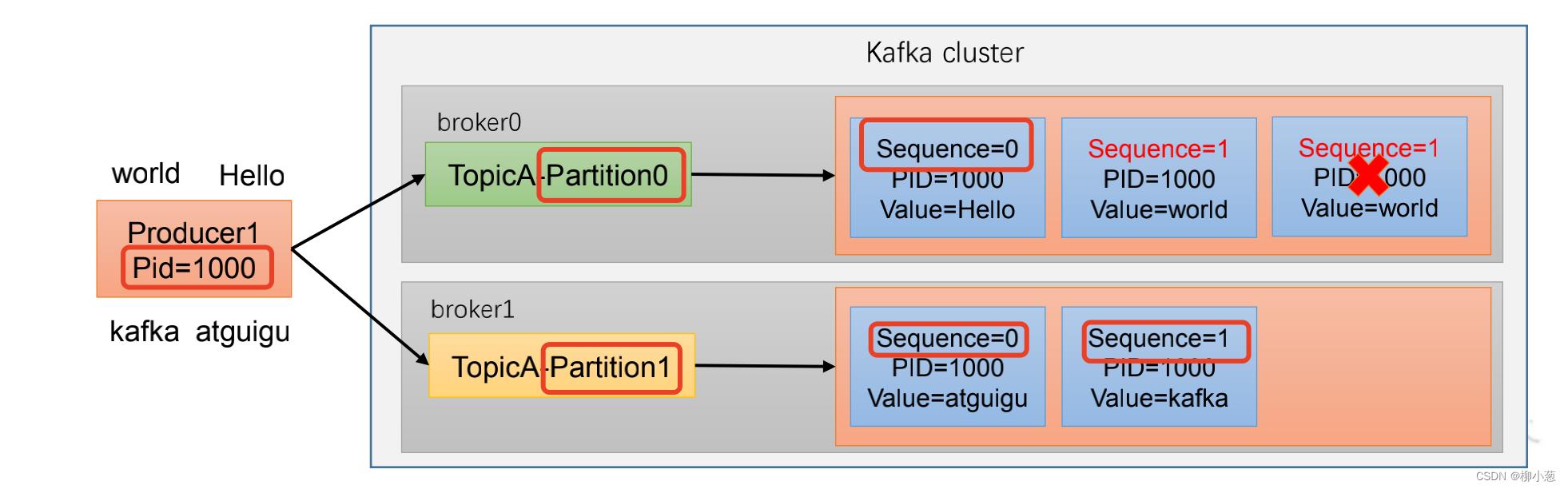
幂等性能够保障消息在单分区,单会话内消息不重复。配置方式为设置enable.Idempotence为true。
4.2 事务
事物有以下几点需要注意:
- 开启事物必须先开启幂等性
- Transaction Coordinator:用来处理事物
- :存储在硬盘中
- tansactional.id 严格唯一
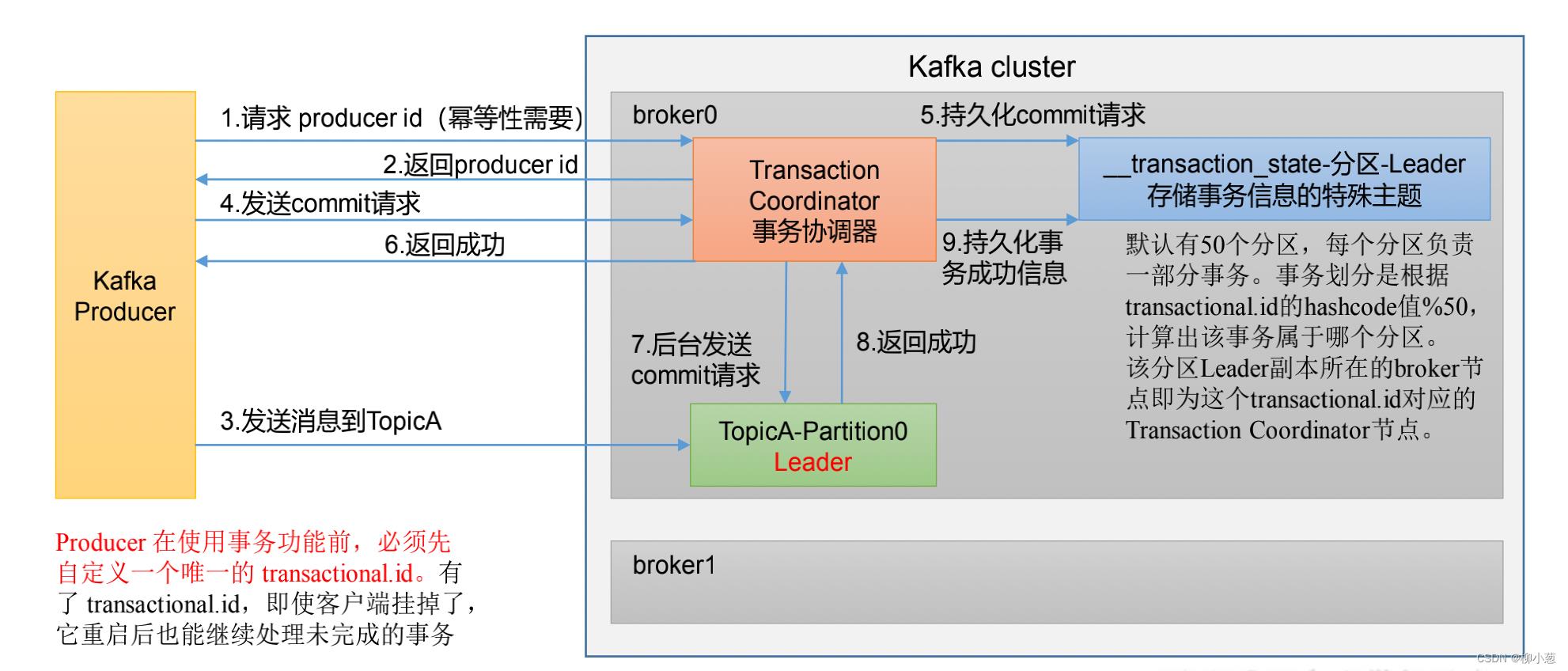
过程如下:(了解即可)
- 生产者请求PID
- 事物协调器返回PID
- 生产者向broker提交发送消息的请求
- 事物协调器将发送持久化到请求发送到特殊主题
- 将持久化到消息返回生产者
- 事务协调器是发送请求给leader确认数据是否持续化完毕
- 确认成功后返回,事务完毕。
5. 数据有序
因为有了分区的概念,生产者产生的数据和消费者消费的数据可能顺序不一致:
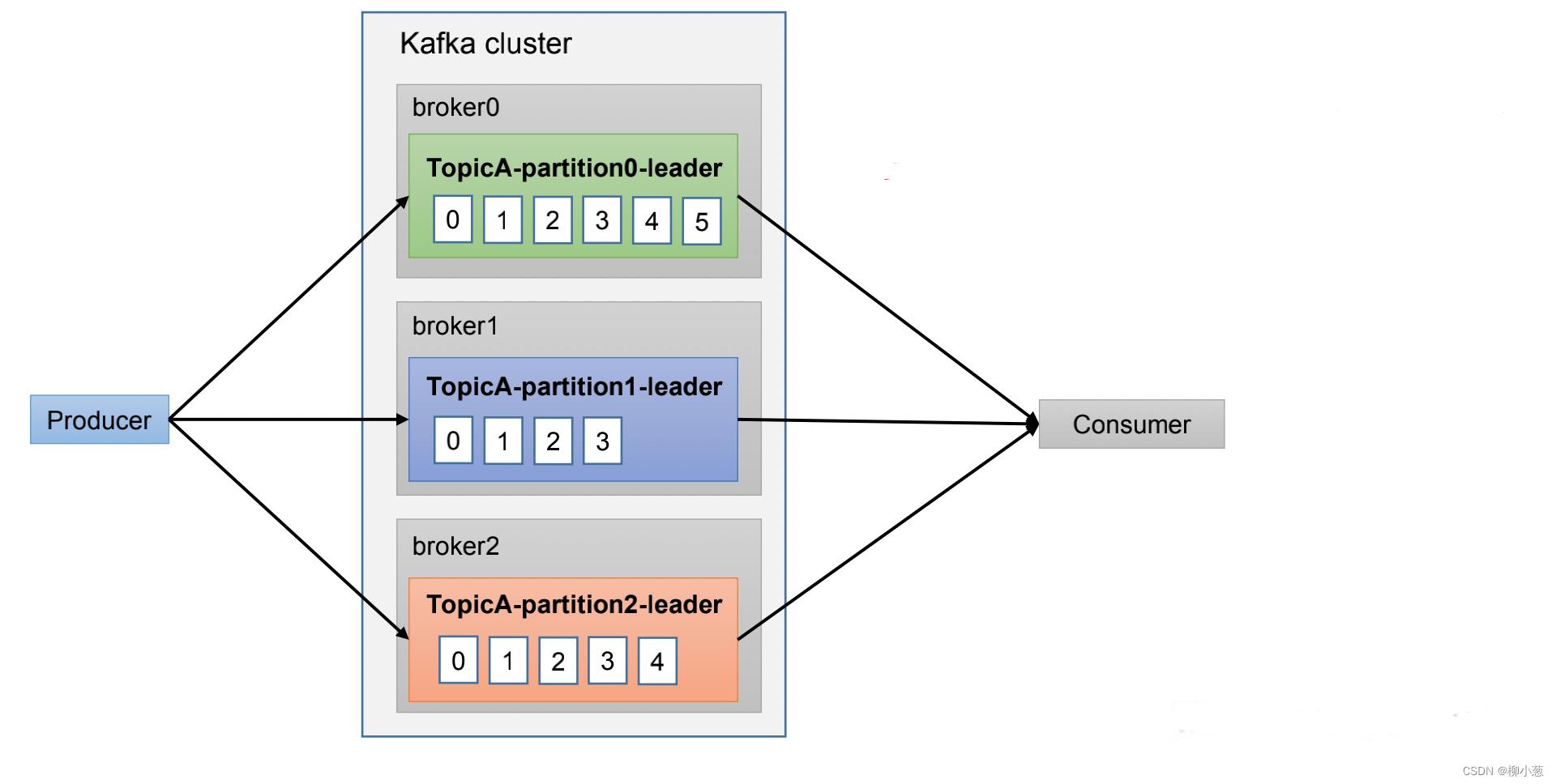
kafka能够保证单分区内数据有序,多分区间无序。如果想实现所有分区数据有序,我们可以将各个分区的数据聚合起立再排序一次,但是这样效率很低,一般情况都是传输到flink或者spark streaming中采用窗口和水位线机制来保证数据有序。
6. 数据乱序
6.1 乱序原因
数据乱序的原因是因为生产者向broker发送传输数据请求的时候,由于某些原因导致某些request失败,后面的request成功先发送数据的情况。如下图红色框框的部分。
6.2 乱序解决方式
kafka1.X版本之前,request只允许存放一个请求,意思是只有request1成功后,才能进行request2。所以不会产生乱序。
而在kafka1.X版本之后,request可以存放5个请求,这就依靠的是幂等性来保证数据不乱序,我们前面提到幂等性消息是以<PID,Partition,SeqNumber>三个主键的来判断消息是否重复,而SeqNumber是单调递增的,kafka服务端会缓存5个request,当request1,request2,request4,request5,request3乱序到达,但kafka服务端会排序完再将数据写入,保证数据不乱。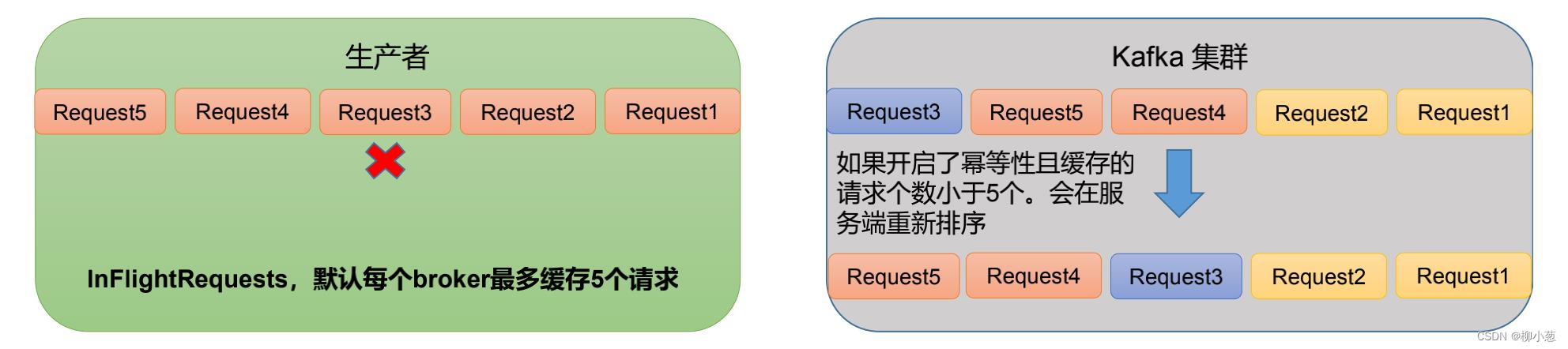
7. 参考资料
-《尚硅谷大数据技术之 Kafka》
-《kafka权威指南》
-《 知乎》: kafka生产数据时的应答机制(ACK)
以上是关于kafka生产者怎么样能够保障数据不丢,不重复且分区内数据有序!的主要内容,如果未能解决你的问题,请参考以下文章