spark(yarn模式)工作流程
Posted 迪答
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了spark(yarn模式)工作流程相关的知识,希望对你有一定的参考价值。
spark是继hadoop框架之后第二个主力框架,spark的出现解决了hadoop框架中MapReduce计算速度慢的问题。对于数据的存储还是依靠hadoop中的HDFS。spark通过基于内存和支持迭代计算极大的提高了数据的处理运算速度。
spark有三种部署模式
1.local模式:是运行在一台计算机上的,通常是用来做测试;
2.standalone模式:这个模式是spark自带资源调度引擎,构建成master+wordker的spark集群,这是由于该框架开发时,hadoop还有发布2.x版本,并没有yarn(资源调度),所以自己开发带有了资源调度的功能,但是由于该模式对集群的性能要求太高,在生产中使用相对较少;
3.使用yarn(模式),该模式下是使用hadoop带有资源调度yarn来运行spark程序;
Spark设计为可以高效地在一个计算节点到数千个计算节点之间伸缩计算。为了实现这样的要求,同时获得最大灵活性,Spark支持在各种集群管理器(Cluster Manager)上运行,包括Hadoop YARN、Apache Mesos,以及Spark自带的一个简易调度器,叫作独立调度器。

yarn模式的工作流程
yarn模式中有两种运行提交任务的方式,yarnclient运行模式和yarncluster运行模式,两者最主要的区别在于driver的运行节点的不同。
yarn-client:driver程序运行在客户端,适用于交互,调试,希望立即看到程序的运行的结果;
yarn-cluster:driver程序运行在ResourceManager启动的APPMaster,在生产环境中使用;
client模式:提交程序
--class org.apache.spark.examples.SparkPi--master yarn--deploy-mode client./examples/jars/spark-examples_2.12-3.0.0.jar10
工作流程:
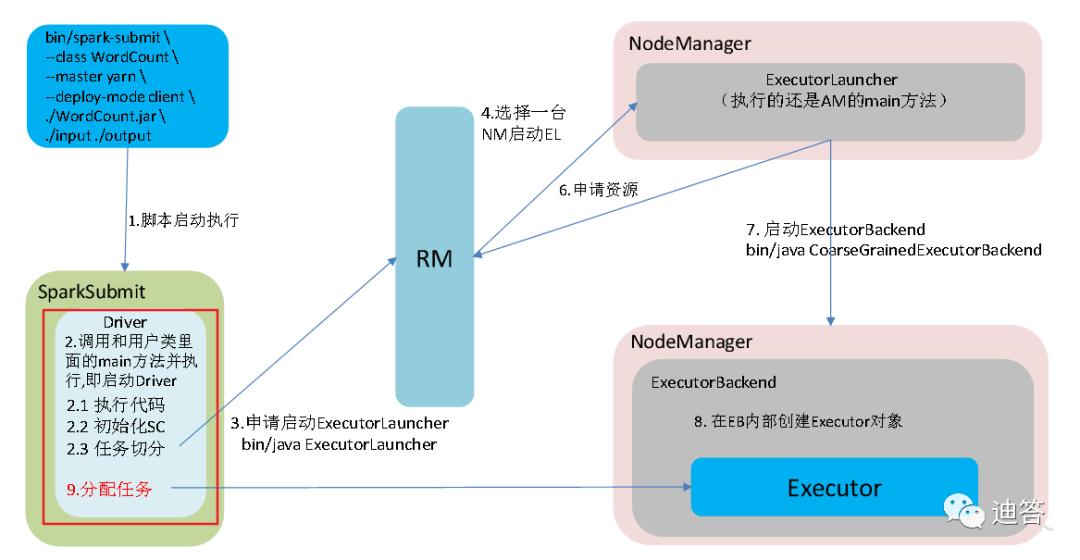
在client模式下程序执行完后会直接在客户端显示执行的结果,可以直接看到。
cluster模式:提交程序
--class org.apache.spark.examples.SparkPi--master yarn--deploy-mode cluster./examples/jars/spark-examples_2.12-3.0.0.jar10
工作流程:
这种模式下需要登录yarn的web界面中查看执行情况;
两种模式下的图中RM(ResourceManager)和NodeManager分别是yarn中的两个角色,作用是管理调度资源(cpu和内存)及执行任务;
spark框架模块
Spark Core:实现了Spark的基本功能,包含任务调度、内存管理、错误恢复、与存储系统交互等模块。Spark Core中还包含了对弹性分布式数据集(Resilient Distributed DataSet,简称RDD)的API定义。
Spark SQL:是Spark用来操作结构化数据的程序包。通过Spark SQL,我们可以使用 SQL或者Apache Hive版本的HQL来查询数据。Spark SQL支持多种数据源,比如Hive表、Parquet以及JSON等。
Spark Streaming:是Spark提供的对实时数据进行流式计算的组件。提供了用来操作数据流的API,并且与Spark Core中的 RDD API高度对应。
Spark MLlib:提供常见的机器学习功能的程序库。包括分类、回归、聚类、协同过滤等,还提供了模型评估、数据 导入等额外的支持功能。
Spark GraphX:主要用于图形并行计算和图挖掘系统的组件
附录
spark官网:http://spark.apache.org/
以上是关于spark(yarn模式)工作流程的主要内容,如果未能解决你的问题,请参考以下文章