文献总结| 基于机器学习方法的地面PM2.5定量反演研究
Posted Sai sama
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了文献总结| 基于机器学习方法的地面PM2.5定量反演研究相关的知识,希望对你有一定的参考价值。
前言
目前来看,地面 定量反演研究具有较为成熟的技术方法。大多数的研究者基于气溶胶光学厚度(Aerosol Optical Depth, AOD) 地面 之间的高度相关性,利用一些统计学方法(如, 机器学习方法)或物理模式,实现地面 的定量反演研究。本文便是对利用机器学习方法实现这一研究目的的文献总结。
由于我在看论文的时候,喜欢先了解一番问题的研究背景,再深入学习文献中具体的技术方法和结果讨论,故本文将从以下几点展开讨论:
-
为什么要进行地面 的定量反演研究 -
地面 定量反演研究存在的主要问题 -
地面 定量反演研究的常用方法 -
基于机器学习方法的地面 定量反演研究
前四点作为研究背景进行简要概述,最后一点将着重讨论研究者如何通过机器学习方法实现地面 定量反演研究。
1 研究背景
1.1 为何要进行地面 定量反演研究
「 空间分布 --> 对人体健康的影响」我国 污染已经十分严重,在多数城市 成为其首要污染物。为此,了解我国 的全域分布成为研究 污染问题的一个重点课题,这为 流行病研究和风险分析的暴露评估提供重要支撑。目前我国也加大 地面监测力度,建立起 地面监测网络。然而,一个主要的问题在于,这些地面监测站点是离散的,并且在地理位置上呈现明显的分布不均匀,这对刻画 的空间分布存在一定的局限性。
「AOD与地面PM2.5的高度相关性」 目前,很多学者都开始利用卫星遥感数据(主要是基于卫星数据反演的AOD产品)实现地面 的定量反演。原因如下:
-
地面PM2.5监测站点分布稀疏、分布不均匀、监测年限少 -
AOD数据全球覆盖、相对高的分辨率、长期监测记录 -
AOD与地面PM2.5呈现明显的正相关性
1.2 地面 定量反演研究存在的主要问题
「卫星数据--> AOD反演产品--> 地面 反演结果」卫星反演 浓度方法一般分为两个步骤,首先从遥感影像中反演AOD分布,然后再以AOD为基础建立 浓度估算模型。好在大多数的卫星数据都提供了其反演的AOD数据,因此,我们可以直接利用AOD进行 反演。不过,有时候官网提供的AOD数据不能满足研究要求,这时我们便需要自己构建卫星到AOD之间的反演算法。本文的重心在于AOD至 的反演过程,当然对前一步也会进行简单的介绍。以下内容节选自基于遥感与地面监测数据的 定量反演研究_黄文喜。
「AOD反演问题」
-
气溶胶定量遥感精度低
一方面因为气溶胶多变的时空特性,同时受限于现有的探测技术精度和关键信息(如单次散射反照率)缺乏,气溶胶定量遥感反演理论与技术并不完善。
-
缺乏大气综合信息
大气垂直信息不易获得,利用探空飞艇、无人机等测量工具作为采集平 台,实施方案较为繁琐,站点有限且费用高昂,不仅为研究带来较大困难,也无法满足大空间尺度遥感探测的要求。
-
云检测处理算法尚不完善
当前大多数的大气颗粒物卫星遥感监测方案都是在晴朗或无云条件下实现 的,部分研究中虽然提前针对薄云进行云检测,并对云覆盖区域反演结果插值计 算,当云层较厚时,插值结果仍无法满足研究需要。对厚云干扰的处理,仍然需 要探索更高效的算法。
「AOD- 时空关系模型构建存在的问题」
-
数据问题
就数据源而言,我国长期缺乏大气遥感、颗粒物监测专用的有效卫星 载荷,使得当前研究中卫星数据使用多样化,不同来源的卫星数据和气溶胶产品 间缺乏有效连接,并造成一定程度的资源浪费。并且PM2.5监测数据离散、不均匀、监测时限短。
-
AOD与地面 的关系
就AOD与PM2.5相关关系而言,二者间的定量关系受大气排污、环境因素、地貌生态等多方因子综合作用,且因素之间存在耦合效应,使得遥感定量 反演存在较大困难,精度难以提升。
1.3 地面 定量反演研究的常用方法
「气溶胶反演常用方法」
暗目标算法(Dark Target,DT) 和 深蓝算法(Deep Blue,DB) 为其中最广泛使用的两种方法。这两种算法在反演过程中均需要借助可见光与中红外波段反射率之间的关系,采用辐射传输方程、人为地设置气溶胶类型和大气模式。下图是一些常用的气溶胶反演算法,图片来源于上文提到的黄文喜博士的学位论文,具体参考文献可看原文。
「AOD反演地面 的方法」
-
基于 与AOD相关性的简单线性回归法
-
考虑到气溶胶粒子随RH及卫星高度方向上分布规律对二者相关关系的影响,基于混合层高度(Mixing Height,MH) 和湿度因子等信息对AOD进行修正,再与 进行相关性分析或者构建有关模型(混合高度+湿度修正+相关性)
-
在AOD的基础上添加多项气象因子(包括RH、气压、近地面风速等)、地表因子(如观测站点坐标、地类划分等)等辅助因素对 扩散特性的影响,建立统计学模型,进行反演。(机器学习的统计模型)
-
为获取更精准的气溶胶空间分布特征,部分学者利用气候状况数值模拟首先推算气溶胶垂直廓线,接下来由AOD遥感数据获取 浓度的变化因子,据此因子进一步实现 浓度信息预测。(数值模式+统计模型)
基于机器学习方法的地面 定量反演研究
这部分内容是对当下一些使用较为广泛的反演算法的文献总结,使用到的反演算法有GWR(Geographically Weighted Regression)[1],Two-Stage Model(LME+GWR)[2], Geoi-DBN(Deep Belief Networks)[3], STRF(Space-Time Random Forest)[4], MI+Two-stage(Multiply Imputation + LME+GAM)[5]。
2.1 PM2.5反演算法流程
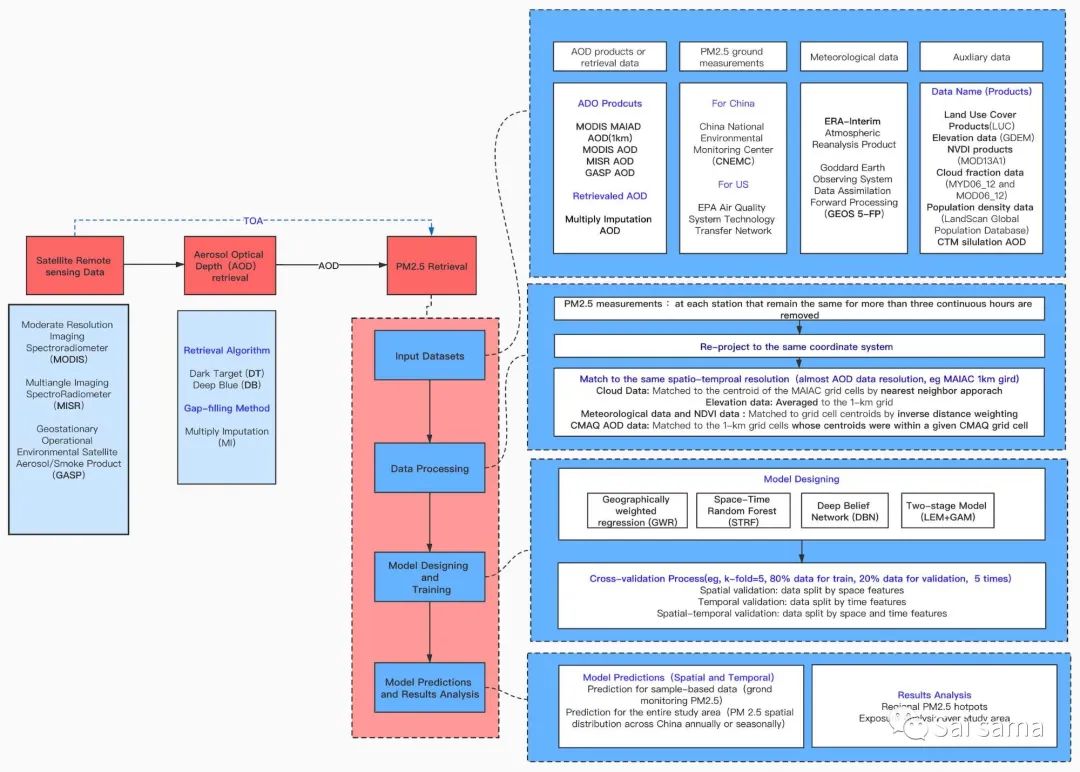
下图是利用卫星遥感数据定量反演地面PM2.5的算法流程。这里主要关注AOD-PM2.5的反演过程,与传统的机器学习算法流程类似,包括以下几个步骤:
-
「输入数据」
PM2.5反演算法的输入数据来源有AOD数据(官网提供的AOD数据或者自己设计算法反演的AOD结果), 地面监测PM2.5数据,气象数据(包括风速,温度,湿度,风向等),还有一些其他的辅助数据(地形数据、地面高度数据、NVDI数据、人口密度数据等)。
-
「数据预处理」
数据预处理主要包括两个步骤,将重投影到同一坐标系,所有数据转换到同一时空分辨率(通常是AOD数据的空间分辨率),这里具体来说一下如何操作。对于PM2.5数据,剔除其中连续三小时以上连续的异常数据。转换到同一时空分辨的方法,通常有最邻近方法、平均值、双线性插值法等。
-
「算法设计及训练」
将预处理好的数据输入设计好的反演算法中,这里列举出几个反演算法:GWR(Geographically Weight Regression)、STRF(Space-time Random Forest) 、Two-stage(LME+GWR) 、DBN(Deep Belief Networks),具体的算法内容将在下一节介绍。训练过程采用交叉验证(cross validation, CV) 的方法,如五折交叉验证,将整个数据集分成五份,每次取其中的80%作为训练集,剩下的20%作为验证集,以上步骤重复五次,验证集的部分不重复,5次后正好取满整个数据集。为了分别验证算法在时间和空间的拟合效果,在做交叉验证的时候做了以下三种处理:时间交叉验证(数据集按照时间特征划分为训练集和验证集)、空间交叉验证(数据集按照空间特征划分为训练集和验证集)、时空交叉验证(数据集按照时间和空间特征划分为训练集和验证集)。
-
「模型预测与结果分析」
模型预测:在经过多次训练和调参,得到拟合性能较好的算法模型后,需要检测模型的泛化能力,即模型对未见过的数据的预测效果。这里同样考察模型在时间、空间和时空三方面的预测性能。时间预测:如训练-验证数据集取2015年数据,预测过程可验证对2016年数据的拟合效果。空间预测:分为站点数据预测和整个研究区域的空间分布预测。时空预测:同时考虑到时间空间信息的预测,如预测2016年整个研究区域的PM2.5空间分布。
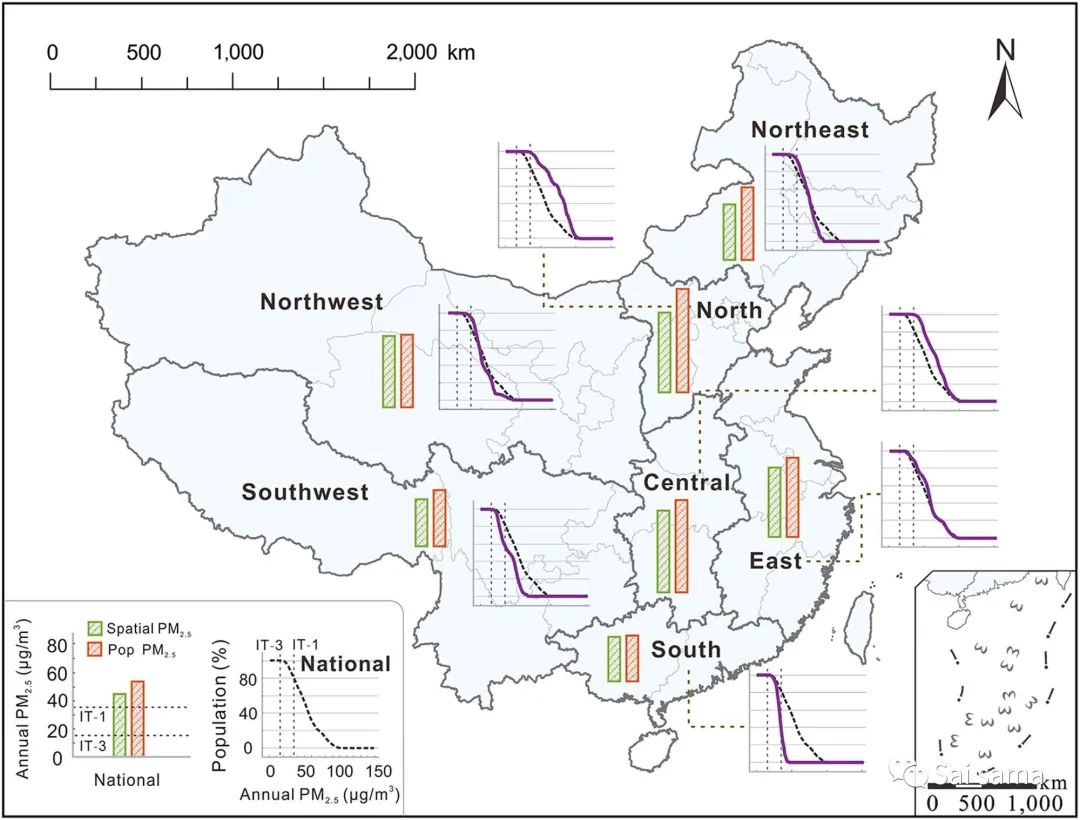
结果分析:在这几篇论文中,结果分析大多停留在模型预测结果的分析阶段,如研究区域内年均PM2.5空间分布、季节性PM2.5空间分布。这里给出两点引申,以研究区域为整个中国为例,可以进行PM2.5热点研究区域的分析,也可以做PM2.5暴露分析(各省人均PM2.5值)。
2.2 PM2.5反演算法
-
「GWR」
GWR中文名一般翻译成地理加权回归。GWR是一种局部回归模型,这是相当于全局回归模型而言的,什么意思呢?看下面两个公式:
全局回归就是对于每一个样本点,其权重 一致,而局部回归则不同,对于不同的样本点,其权重 也不同。这里举一个简单的例子,比如计算全国人均收入水平,我们知道不同省份、不同城市的人均收入是不同的,如果我们统一的用一个权重来拟合北京和18线小城市的人均收入,得到的结果往往与实际结果相去甚远,对于这种与空间位置相关的问题,我们一般都会考虑采用局部回归的方式来拟合。
式(2.2)就是GWR的拟合方程,看起来要比(2.1)式复杂,实际上是同一表达方式,只不过这里的权重 随样本点选取不同而改变,所以GWR的关键就在于怎样求得变动的权重值。
这里的
即样本,
为空间权重矩阵,我们可以通过一系列的核函数求解
,进而求解
,下图列举了一些常用的核函数,可以看到,这些核函数中有一个关键的参数b(bandwidth),即带宽。这说明我们在拟合y时,并不是取所有的样本点,而是取落在b区间内的样本点。而这个b的取值,对于GWR拟合的效果至关重要。
在简单介绍完GWR的原理后,我们来看一下怎么将其应用到PM2.5的反演中
这里的 即权重参数, 可以看作是截距。 为误差项。GWR算法可以通过R语言的GWmodel或者Arcgis软件来实现。模型的评估指标可以选用R2和莫兰指数。
-
「Two-stage model」
故名思意,Two-stage model包含两个步骤,这里的Two-stage特指LME(Linear Mixed Effect Model)和GWR。第一层用于提取与时间相关的信息,第二层用于提取与空间相关的信息。
LME包含固定效应项(fixed-effects terms)和随机效应项(random-effects terms),固定效应影响总体均值,而随机效应与抽样程序有关,并有助于协方差结构数据。具体的关系如下式:
这里 表示第t天站点s的地面监测站点PM2.5浓度值, (day-spcific)分别是固定效应的和随机效应的截距; (day-spcific)分别是AOD固定效应的和随机效应的斜率;后面依此类推。 是多元正态分布; 是非结构化的随机效应的方差-协方差矩阵。
固定项AOD和风速代表整个研究期间对PM2.5浓度的平均影响,而随机项影响则说明了依赖和独立之间关系的每日变化变量。将该方程应用于整个拟合数据集,以针对所有天数和随机效应生成固定效应截距和斜率每一天的截距和斜率。第一阶段LME可以通过每天生成所有站点的每日AOD斜率来说明PM2.5-AOD关系中的每日变化。
GWR与上节中的方法类似,不过这里拟合的是第一阶段后的PM2.5残差值(第一阶段预测值与PM2.5真实值的差值),表现形式如下
其中 表示第t天第s点的第一阶段模型的残差, 是第t天第s点的AOD值(无单位), 和 分别表示位置特定的截距和斜率。
通过以上两步,即可在反演过程中考虑时间和空间信息。不过我认为,这种方法的时空信息提取是剥离的,没有考虑到时空信息之间的耦合作用,是单独提出时间和空间信息的过程。
-
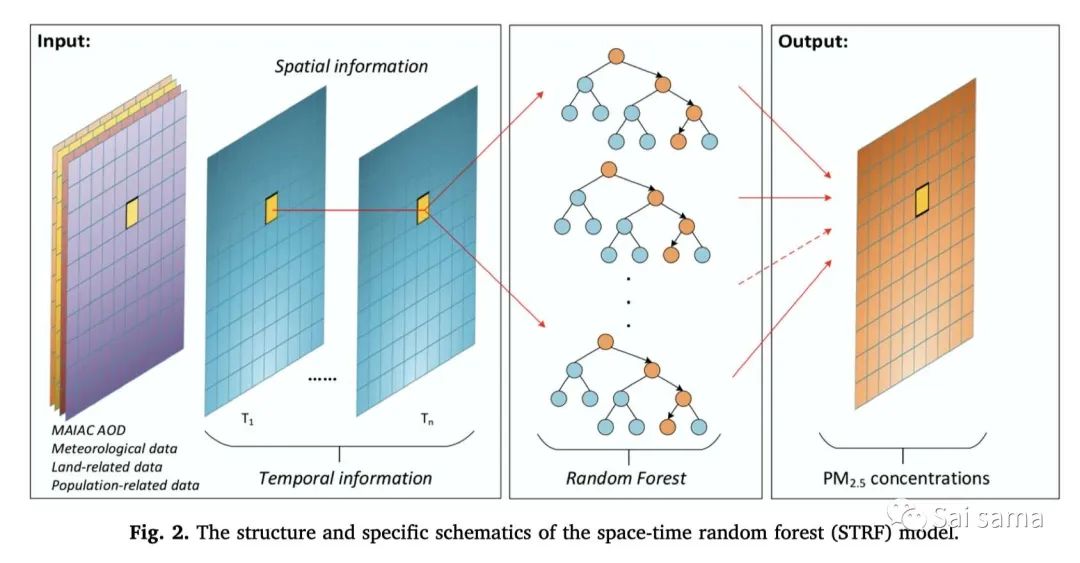
「STRF」
STRF即时空随机森林,这里所说时空,就是在原本随机森林算法的基础上加上能够提取时空信息的权重因子。随机森林是一种非常有效且常用的决策数模型,是一种集成算法,对于其具体的内容这里不再赘述,网上有详尽的资料可供参考。这里主要解释怎样提取时空特征,具体过程见下式
根据地理学第一定律,我们知道距离越近产生的影响越大,距离越远产生的效果越小,这里通过计算反距离实现实现以上过程,在时间信息的提取上采取了同样的方法。现在来看上式,ds和dt分别代表空间和时间距离,W和L代表站点附近的w像素,同一像素的前l天。加入时间和空间特征后,反演算法可由下式表示
具体的算法流程见下图
-
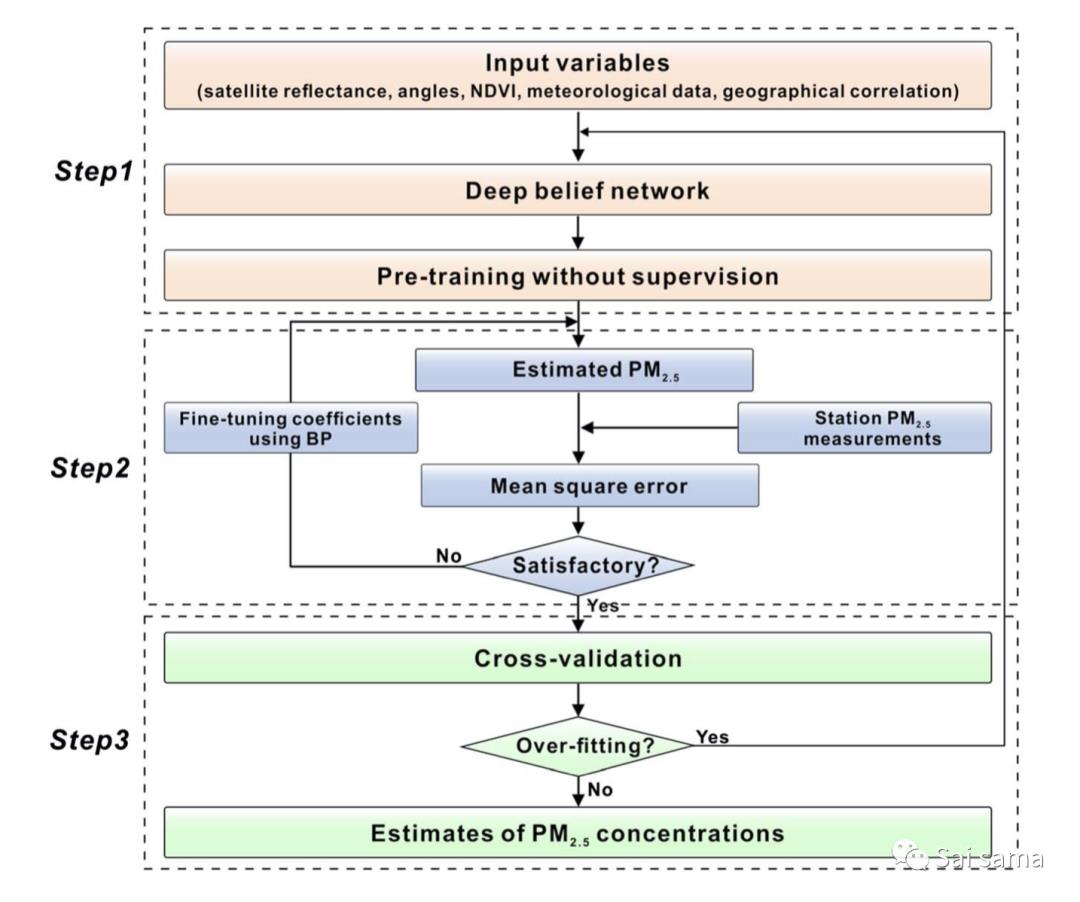
「Geoi-DBN」
深度信念网络(DBN)模型是最典型的深度学习模型之一,于2006年由Hinton推出。DBN由多个受限的Boltzmann机器(RBM)层 和后向传播(BP)层组成,可用于分类或预测问题。DBN之后在深入学习,这里将文章中内容简单翻译以下。
RBM由可见层和隐藏层组成,其中先前RBM的隐藏层是下一个RBM的可见层。以第一个RBM为例,从可见层(v)到隐藏层(h1),
其中i表示第i个神经元的数量, 表示神经元i的偏差。 表示传递函数 。从隐藏层计算可见层的方法相同。对比散度算法通常用于训练RBM。权重在第n次迭代中更新为
其中ε是学习率,v1表示从隐藏层 的重建,而 和 分别基于等式(2.5)从x和v1生成。RBM在没有监督的情况下被一对一地训练,并且训练后的权重用于初始化多层神经网络。然后,DBN模型可以用作前馈神经网络,而使用BP算法的误差减少在此称为“细调”。在这里,Geoi-DBN在DBN的基础上,添加了提取空间信息特征的步骤,其方法与上节STRF完全一致。下图是Geoi-DBN的算法结构
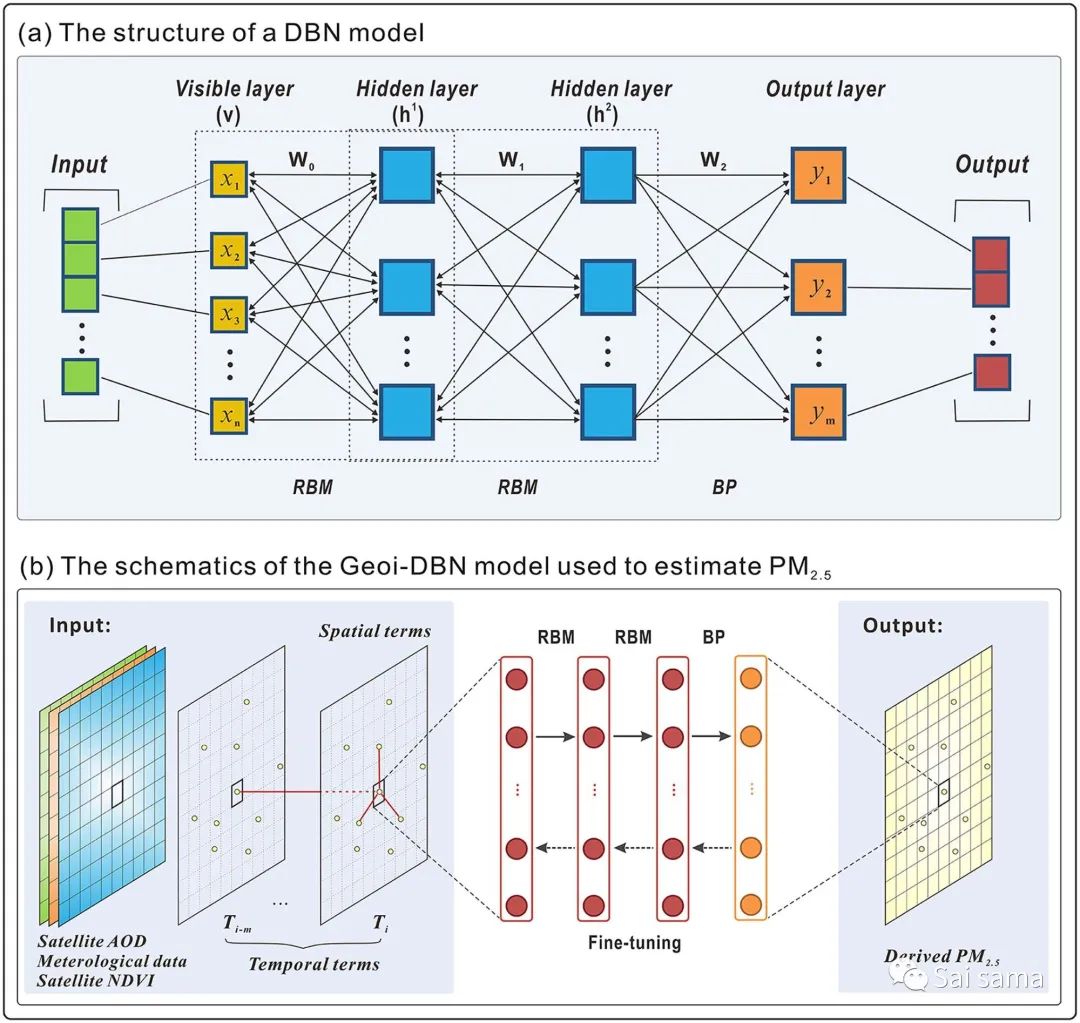
Geoi-DBN训练过程主要包括以下三个步骤,可参见下图:
-
预训练(Pretrain)。使用收集到的数据记录,可以在没有监督的情况下对RBM进行逐层训练。这种无监督的训练可以提取与PM2.5相关的基本特征,并将它们从先前的RBM转移到下一个RBM层。因此,较高的层可以提取与PM2.5相关的更深层特征。
-
微调(Fine tuning)。通过预先的预训练步骤,生成了Geoi-DBN的初始权重,我们可以获得计算出的PM2.5。与PM2.5测量相比,可以获得估计误差,然后将其发送回Geoi-DBN模型,以使用BP算法对权重系数进行微调。
-
预测(Prediction)。此步骤评估在输入数据记录上建立的Geoi-DBN模型的性能,并预测那些没有地面站的位置的PM2.5值。因此,可以重建空间连续的PM2.5数据。
2.3 其他问题
-
卫星-PM2.5
事实上,这里讨论的算法都是基于ADO-PM2.5的反演过程,那么能不能直接从satellite-PM2.5呢?已经有学者作出这样的创新,也就是Geoi-DBN的作者在提出这个模型后,进一步改变数据源,直接利用卫星数据(*Top-Of-Atmosphere(TOA)反射*)反演PM2.5[6],也取得了很好的反演效果。
-
AOD缺失值填补
在前面的内容提到,AOD-PM2.5反演效果的制约因素之一就是AOD数据缺失值较多(受到云层的影响),因此有学者提出AOD缺失值填补算法,将卫星数据经过一定处理后,得到较为完整的AOD,然后在通过PM2.5反演算法进行反演。
MI,即多重填补算法。MI算法的思想是将缺失的数据替换为根据其他观察到的参数估计的值,假设这些参数可以完全解释缺失数据的可变性。由于随机误差,插补导致额外的可变性,为了解决这种额外的可变性,我们进行了多次插补,以合理的值多次插补缺失的数据。多重插补方法可以适当地解决插补模型的不确定性和绘制插补值时的随机误差。
一般而言,多重插补采用蒙特卡洛的方法实现缺失值填补。多重插补可通过R语言的mice包来完成,分为以下三个步骤:
-
mice()函数实现缺失值多重填补,得到多个完整数据集 -
with()函数可依次对每个完整数据集应用统计模型(如线性模型或广义线性模型) -
pool()函数将这些单独的分析结果整合为一组结果。最终模型的标准误和p值都将准确地反映出由于缺失值和多重插补而产生的不确定性。
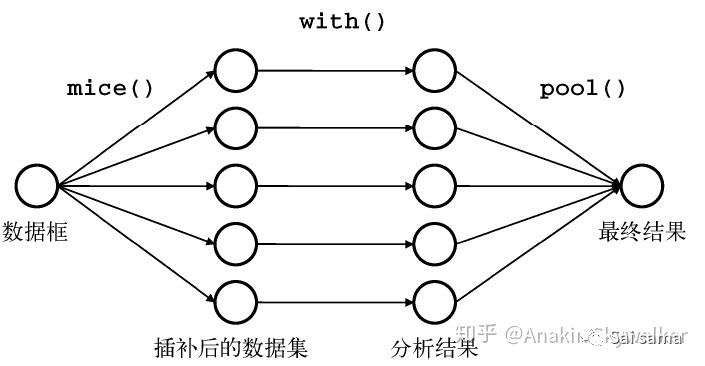
参考文献5提供了一种思路:MI(Multiply Imputation)+Two-stagemodel(LME+GAM),通过MI算法生成过个完整的AOD数据集(对应mice步),将每一个完整AOD数据集利用Two-stage model实现PM2.5反演(对应with),最后取平均值作为最终的反演结果(对应pool)。
我们使用有放回抽样方法,通过对原始数据集进行重复采样并进行替换来拟合该插补模型,以考虑插补过程中的不确定性。
MI缺失值填补算法设计如下:
其中 代表是第t天第j单元的平均每日MAIAC AOD; 是网格单元j的质心的坐标(km); 为第t天网格单元j的日平均云分数; 是第t天网格单元j的日平均CMAQ AOD;是第t天网格单元j边界层下的每日平均气温(K),平均相对湿度和平均比湿度(kg / kg)。海拔高度 j是网格单元j处的海拔高度(m); 是五个虚拟变量,代表期间的日期索引,而s函数表示空间位置的平滑函数。这里对原始数据填补10次,得到10个不同的完整数据集。
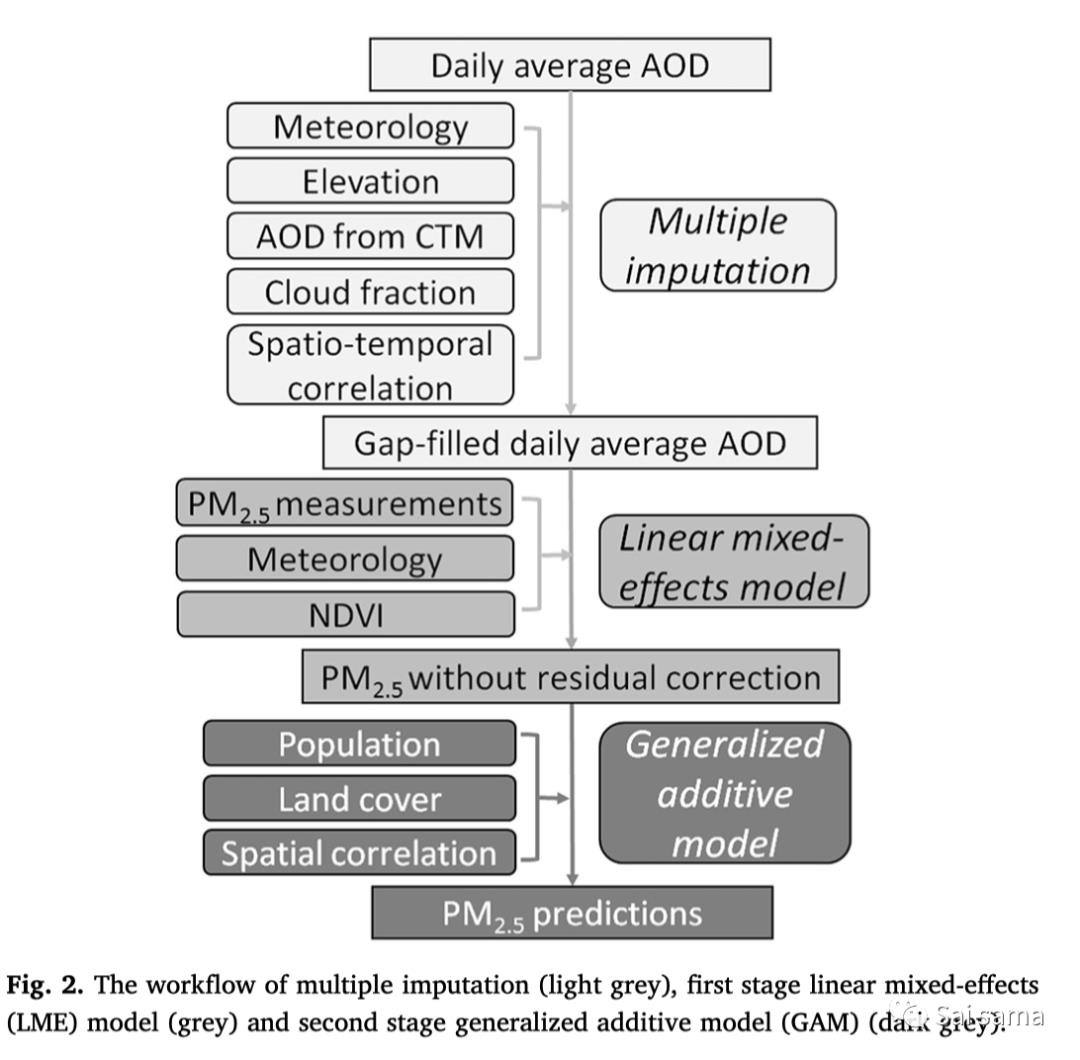
将得到的数据用于PM2.5的反演,反演过程采用Two-stage model。这里每一份数据集用于单独反演,最后取所有预测结果的平均值作为最后的反演结果。第一阶段为LME,与上文使用方法类似,这里不再赘述;第二阶段采用GAM(Generalized addictive model),形式如下
其中 是单元格j的质心的X和Y坐标的平滑函数, 是单元格j的绿地面积的平滑函数, 是单元格j的道路长度的平滑函数, 是单元格j的人口密度的平滑函数, 是单元格j中的加油站数量,范围为0到4, 分别代表均值与随机误差。
2.4 模型预测与结果分析
这部分内容一般集中在反演后的PM2.5空间分布,PM2.5的年均值、季节性均值空间分布。下面是一些模拟结果:(a)基于STRF算法的PM2.5空间分布 (b)基于STRF算法的PM2.5空间分布 (c)GWR预测结果 (d)MI+Two-stage model预测结果(年均值,左边未填补,右边填补)
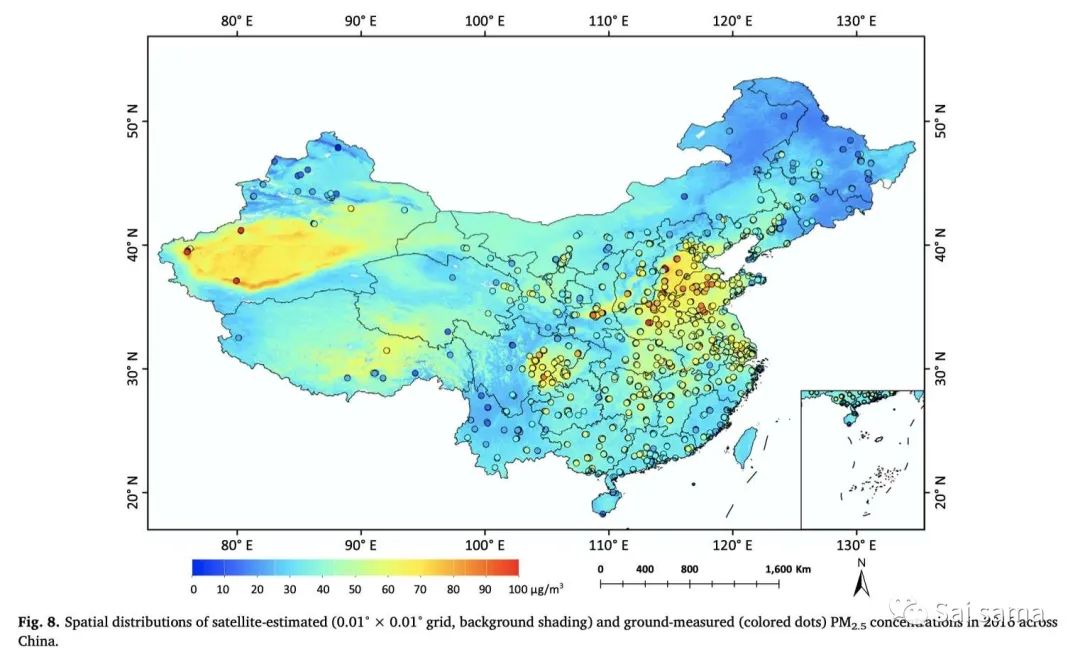
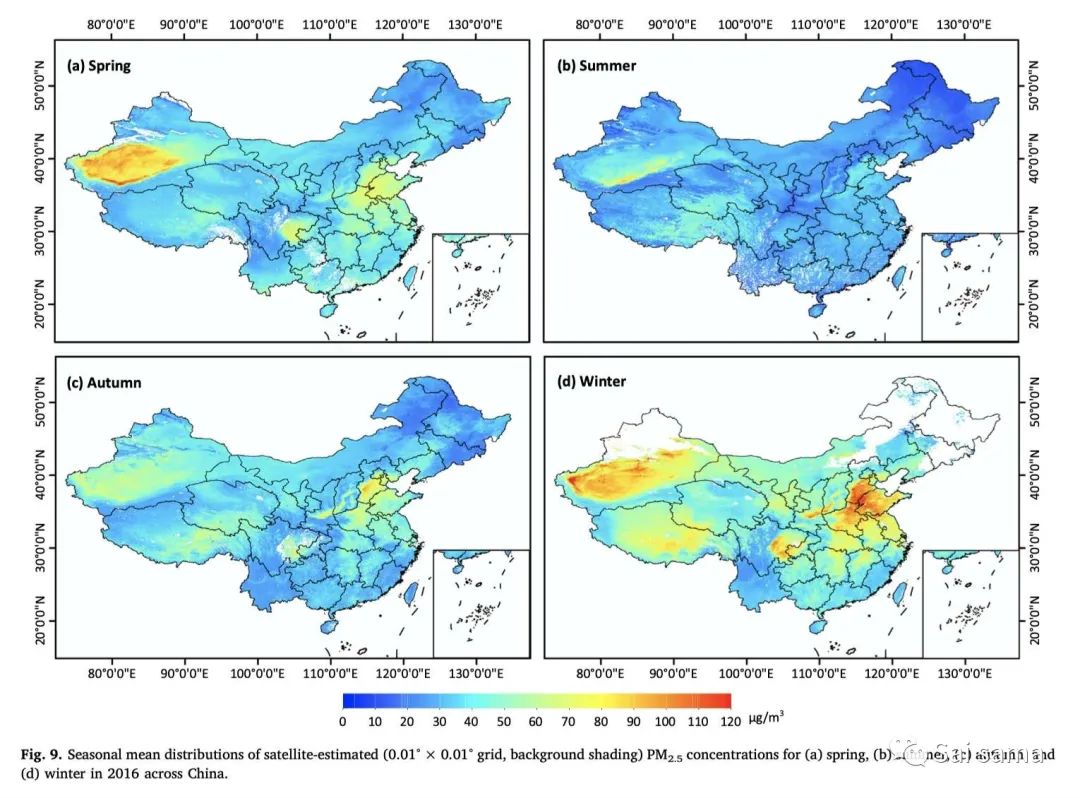
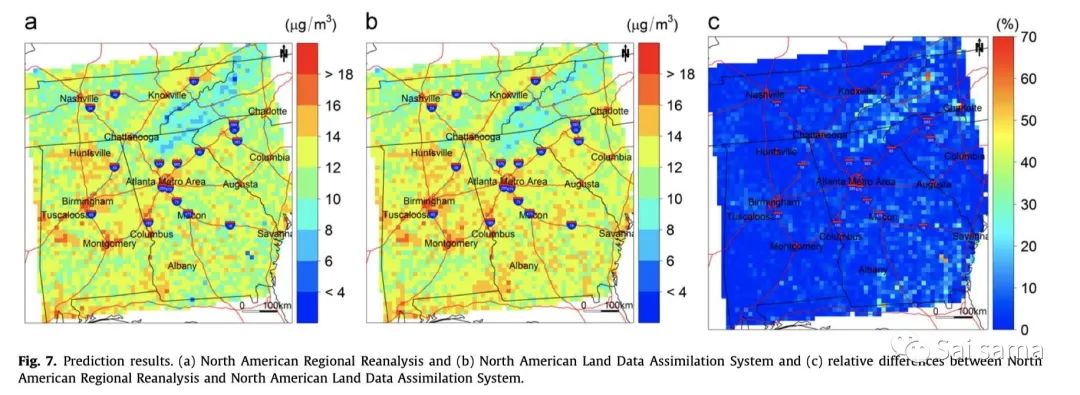
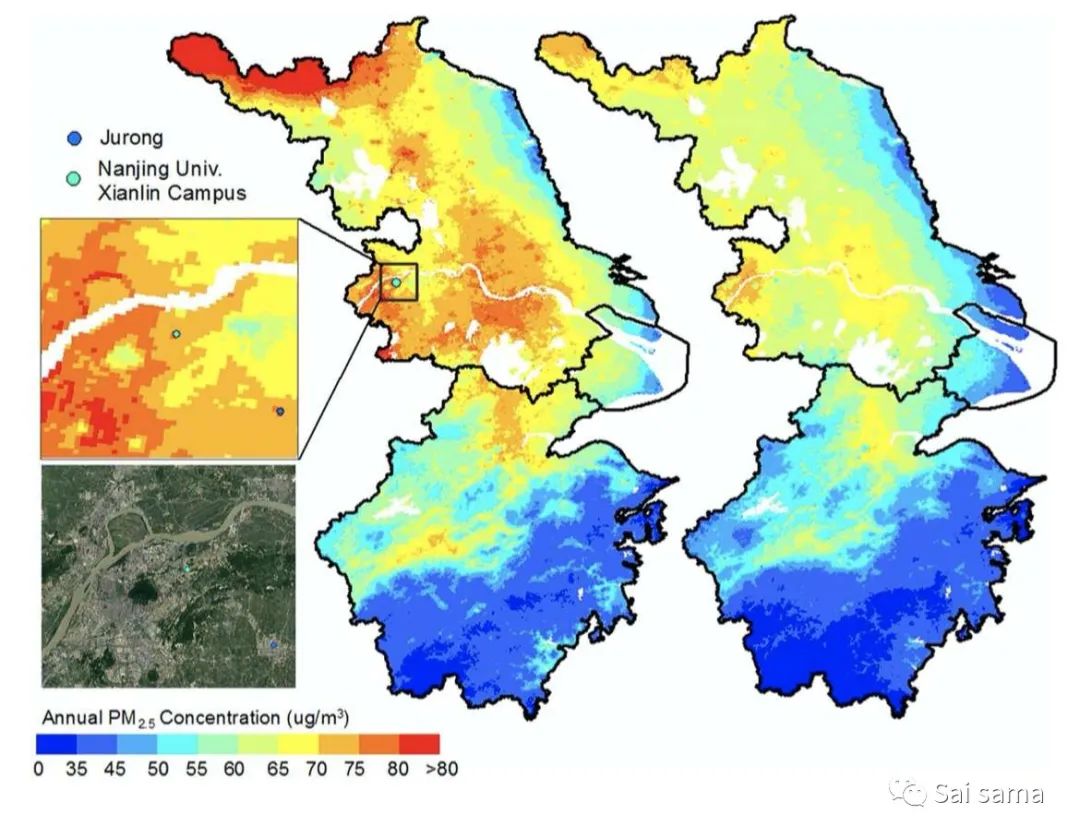
<<< 左右滑动见更多 >>>
还有一些额外的结果分析,添加这一部分内容是希望拓宽结果分析角度,加上文章深度。
-
PM2.5热点区域
STRF一文中,结构分析中讨论了PM2.5热点区域。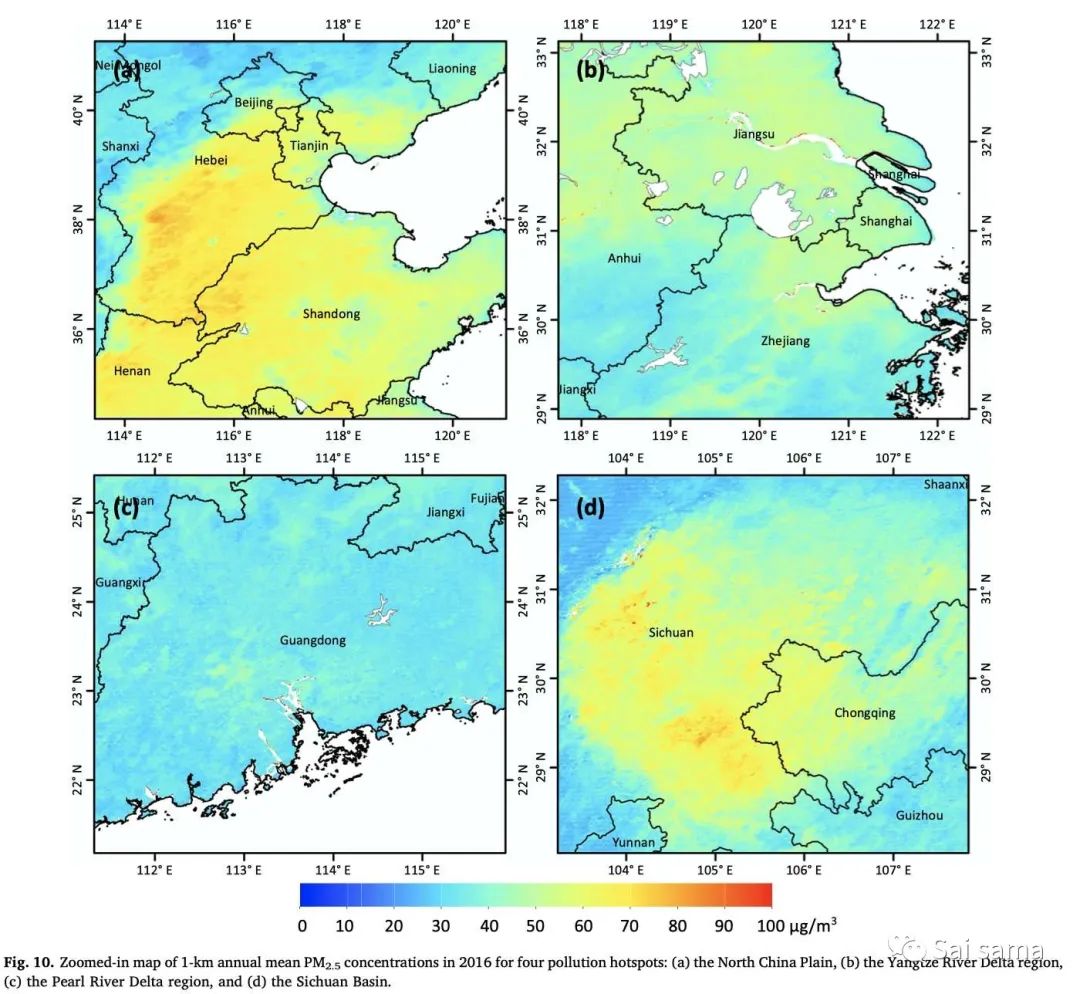
-
PM2.5人均暴露水平
Geoi-DBN一文中,分析了区域性PM2.5人均暴露水平