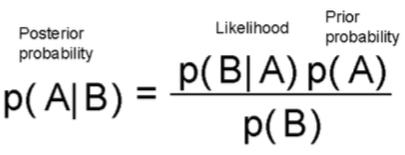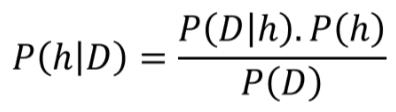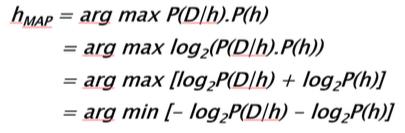来源 : 新智元 【导读】当贝叶斯、奥卡姆和香农一起给机器学习下定义,将统计学、信息理论和自然哲学的一些核心概念结合起来,我们便会会发现,可以对监督机器学习的基本限制和目标进行深刻而简洁的描述。令人有点惊讶的是,在所有机器学习的流行词汇中,我们很少听到一个将统计学、信息理论和自然哲学的一些核心概念融合起来的短语。 而且,它不是一个只有机器学习博士和专家懂得的晦涩术语,对于任何有兴趣探索的人来说,它都具有精确且易于理解的含义,对于ML和数据科学的从业者来说,它具有实用的价值。 这个术语就是最小描述长度(Minimum Description Length)。 让我们剥茧抽丝,看看这个术语多么有用…… 贝叶斯和他的理论 我们从托马斯·贝叶斯(Thomas Bayes)说起,顺便一提,他从未发表过关于如何做统计推理的想法,但后来却因“贝叶斯定理”而不朽。 Thomas Bayes 那是在18世纪下半叶,当时还没有一个数学科学的分支叫做“概率论”。人们知道概率论,是因为亚伯拉罕 · 棣莫弗(Abraham de Moievre)写的《机遇论》(Doctrine of Chances)一书。 1763年,贝叶斯的著作《机会问题的解法》(An Essay toward solving a Problem in the Doctrine of opportunities)被寄给英国皇家学会,但经过了他的朋友理查德·普莱斯(Richard Price)的编辑和修改,发表在伦敦皇家学会哲学汇刊。在那篇文章中,贝叶斯以一种相当繁复的方法描述了关于联合概率的简单定理,该定理引起了逆概率的计算,即贝叶斯定理。 自那以后,统计科学的两个派别——贝叶斯学派和频率学派(Frequentists)之间发生了许多争论。但为了回归本文的目的,让我们暂时忽略历史,集中于对贝叶斯推理的机制的简单解释。请看下面这个公式: 这个公式实际上告诉你,在看到数据/证据(可能性)之后更新你的信念(先验概率),并将更新后的信念程度赋予后验概率。你可以从一个信念开始,但每个数据点要么加强要么削弱这个信念,你会一直更新你的假设。 听起来十分简单而且直观是吧?很好。 不过,我在这段话的最后一句话里耍了个小花招。你注意了吗?我提到了一个词“假设”。 在统计推理的世界里,假设就是信念。这是一种关于过程本质(我们永远无法观察到)的信念,在一个随机变量的产生背后(我们可以观察或测量到随机变量,尽管可能有噪声)。在统计学中,它通常被称为概率分布。但在机器学习的背景下,它可以被认为是任何一套规则(或逻辑/过程),我们认为这些规则可以产生示例或训练数据,我们可以学习这个神秘过程的隐藏本质。 因此,让我们尝试用不同的符号重新定义贝叶斯定理——用与数据科学相关的符号。我们用D表示数据,用h表示假设,这意味着我们使用贝叶斯定理的公式来尝试确定数据来自什么假设,给定数据。我们把定理重新写成: 现在,一般来说,我们有一个很大的(通常是无限的)假设空间,也就是说,有许多假设可供选择。贝叶斯推理的本质是,我们想要检验数据以最大化一个假设的概率,这个假设最有可能产生观察数据(observed data)。我们一般想要确定P(h|D)的argmax,也就是想知道哪个h的情况下,观察到的D是最有可能的。为了达到这个目的,我们可以把这个项放到分母P(D)中,因为它不依赖于假设。这个方案就是最大后验概率估计(maximum a posteriori,MAP)。 现在,我们应用以下数学技巧: