如何提速机器学习模型训练
Posted 老齐教室
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何提速机器学习模型训练相关的知识,希望对你有一定的参考价值。
Scikit-Learn是一个非常简单的机器学习库,然而,有时候模型训练的时间会过长。对此,有没有改进的策略?下面列举几种,供参考。
选择合适的Solver
更好的算法能够将硬件的性能发挥到极致,从而得到更好的模型。在Scikit-Learn提供的模型中,可以通过参数slover实现不同的算法,即不同的Solver(求解器)。例如,scikit-learn中的Logistic回归,可以为solver设置的值为newton-cg、lbfgs、liblinear、sag和saga。
要想了解不同求解器的工作方式,推荐观看scikit-learn核心贡献者GaëlVaroquaux的演讲。他在演讲中提到,梯度下降算法虽然收敛速度快,但是计算成本比较高,因为每次都需要针对所有数据进行计算。如果使用重采样方法,就可以降低每次迭代的计算成本,但收敛速度会变慢。注意,在实践中,并非总强调快速收敛[1]。以前面提到的Logistic回归为例,其中不同的Solver的计算速度有所不同。
import time
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
# 创建数据集
X, y = make_classification(n_samples=100000, n_features=100, n_classes=2)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=1000)
# Slovers
solvers = ['liblinear', 'saga']
for sol in solvers:
start = time.time()
logreg = LogisticRegression(solver=sol)
logreg.fit(X_train, y_train)
end = time.time()
print(sol + " Fit time: " , end-start)
# 输出
liblinear Fit time: 1.4556050300598145
saga Fit time: 2.8493809700012207
在具体问题中,要使用哪一个Solver,还需要根据具体情况而定,特别是要熟悉每个Solver的特点,请阅读官方文档。
超参数调优
在机器学习中,超参数是在训练开始之前设置的,不能通过训练进行更改。而其他普通参数,则不需要提前设定,是通过数据集,在模型训练过程中得到的,或者说,模型训练的过程就是得到普通参数的过程。
下面的表格中列举了常见机器学习模型中超参数和普通参数[2]。
| 模型 | 普通参数举例 | 超参数举例 |
|---|---|---|
| 决策树 | 在每个节点上选择的输入变量;每个节点上选择的阈值 | 每个叶节点所应包括的最少数据量;训练后的剪枝(pruning)策略 |
| 随机森林 | 同上 | 决策树的数量;输入变量的数量 |
| 支持向量机 | 支持向量(support vector)的选择;每个支持向量的拉格朗日乘数 | 核(kernel)的选择;正则化常量C和核函数的超参数 |
| K近邻 | 近邻K的选择;距离函数的选择;初始化选择等 | |
| 朴素贝叶斯 | 每一类的先验概率 | 数值属性用核数密度估计量或正态分布;核密度估计量的窗口宽度 |
| 神经网络 | 每层的权重 | 隐藏层的数量;每层的神经元数量;训练的epoch;学习率等 |
由于超参数不能训练,选择合适的超参数,就是成为机器学习中的研究重点,它影响着模型的性能。在Scikit-Learn中提供了一些常见的超参数优化方法,比如:
-
网格搜索(grid search),又称参数扫描,它能穷尽所有的参数组合,通过 sklearn.model_selection.GridSearchCV类实现。 -
随机搜索(randomized search),从具有一定分布的参数空间抽样给定数量的参数,通过 sklearn.model_selection.RandomizedSearchCV类实现。 -
对以上两个两个的改进:HalvingGridSearchCV 和 HalvingRandomSearch)。
此外,还有其他一些工具能够实现超参数的优化,比如Tune-sklearn,提供了更多超参数优化技术,如贝叶斯优化(bayesian optimization)、早停法(early stopping)、分布执行(distributed execution)等,在某种程度上,能够替代网格搜索和随机搜索方法,优化了模型的速度。
下面列出Tune-sklearn的几个特点,供参阅:
-
兼容 Scikit-learn:从Scikit-learn转向Tune-sklearn,只需要修改几行代码,例如:
"""
An example training a RandomForestClassifier, performing
randomized search using TuneSearchCV.
"""
from tune_sklearn import TuneSearchCV
from sklearn.ensemble import RandomForestClassifier
from sklearn import datasets
from sklearn.model_selection import train_test_split
from scipy.stats import randint
import numpy as np
digits = datasets.load_digits()
x = digits.data
y = digits.target
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=.2)
clf = RandomForestClassifier()
param_distributions = {
"n_estimators": randint(20, 80),
"max_depth": randint(2, 10)
}
tune_search = TuneSearchCV(clf, param_distributions, n_trials=3)
tune_search.fit(x_train, y_train)
pred = tune_search.predict(x_test)
accuracy = np.count_nonzero(np.array(pred) == np.array(y_test)) / len(pred)
print(accuracy) -
具有多种现代超参数优化方法:贝叶斯优化,早停法和分布式执行等,都能很容易地在代码中实现。
-
支持多种框架:除了Scikit-learn,还支持Pytorch、Keras、XGBoost等(点击超链接,可以查看相应的代码示例)。
-
可扩展性强:Tune-sklearn基于Ray Tune——一种用于分布式超参数优化的库——来高效透明地实现在多核上,甚至在多台机器上进行并行计算,交叉验证。
下图来自《GridSearchCV 2.0 — New and Improved》,比较了Tune-sklearn和Scikit-learn的训练时间。
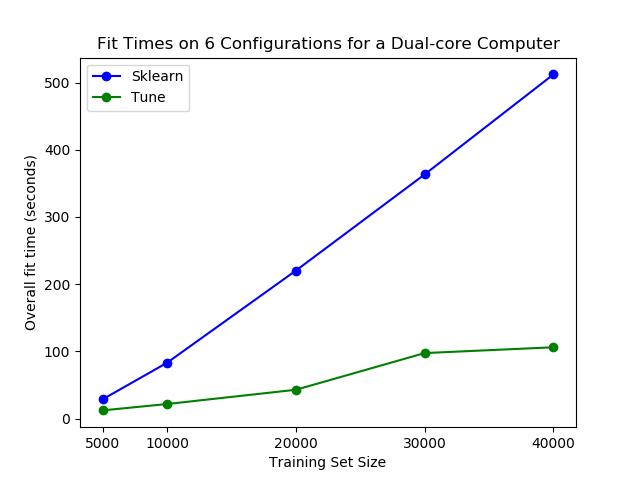
并行计算
另外一种提升模型训练速度的方法是使用 joblib 和 Ray 实现并行计算,并将训练进行分发。默认情况下,Scikit-learn只用单核完成模型训练,但是,现在很多计算机都已经是多核了,比如我现在用的MacBook Pro具有4核。因此,在个人计算机上,就具备了提升模型训练速度的可能性。特别是当你的模型可以进行高度的并行计算时,比如随机森林模型(如下图所示)。
应用joblib,能让Scikit-Learn实现单个节点上并行训练,默认情况下joblib使用loky并行模式[4],还可以选择其他模式,如:multiprocessing,dask和ray等。loky模式只能优化单个节点,不能实现分布式计算[5]。如果执行分布式计算,可能需要考虑更多东西,如:
-
多台机器之间的任务调度 -
数据的高效传输 -
故障恢复
幸运的是,如果设置为joblib.parallel_backend('ray'),即ray并行计算模式,能够自动将上面的各项要求都兼顾,让你操作起来更简单。下图分别比较了ray、multiprocessing、dask和loky四种并行计算模式对训练模型速度的影响[6]。
如果你对这种做法有兴趣,不妨查看参考文献[6]的内容。
结论
本文介绍了三种提升使用Scikit-learn库训练模型速度的方法,既可以使用scikit-learn中提供的一些方法,也可以用其他库,如Tune-sklearn和Ray。
参考文献
[1]. https://leon.bottou.org/publications/pdf/nips-2007.pdf
[2]. https://www.jiqizhixin.com/graph/technologies/5619ca3f-5d4e-48c1-824d-d2a0aea0c7d1
[3]. https://medium.com/distributed-computing-with-ray/how-to-speed-up-scikit-learn-model-training-aaf17e2d1e1
[4]. https://joblib.readthedocs.io/en/latest/parallel.html
[5]. https://scikit-learn.org/stable/modules/generated/sklearn.utils.parallel_backend.html
[6]. https://medium.com/distributed-computing-with-ray/easy-distributed-scikit-learn-training-with-ray-54ff8b643b33
以上是关于如何提速机器学习模型训练的主要内容,如果未能解决你的问题,请参考以下文章