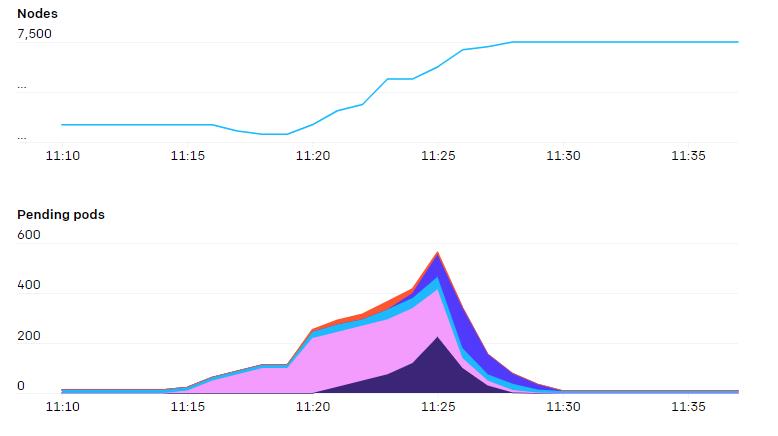
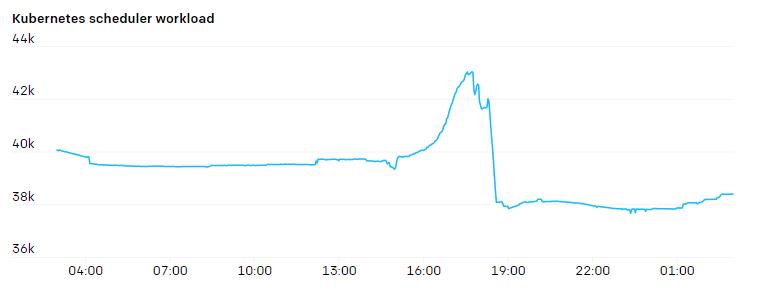
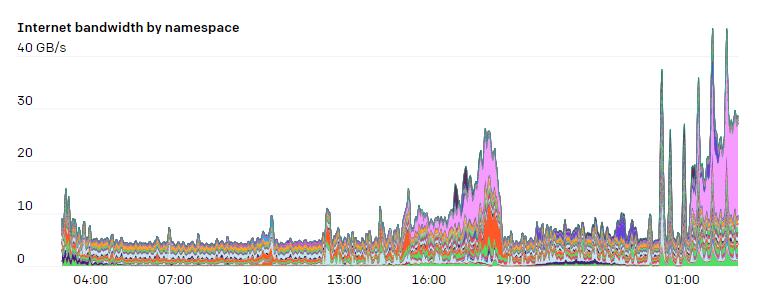
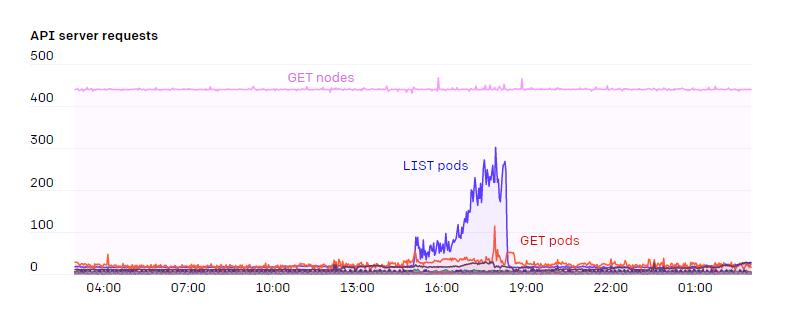
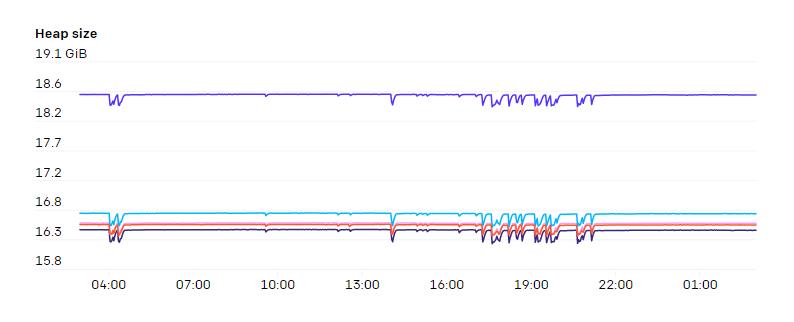
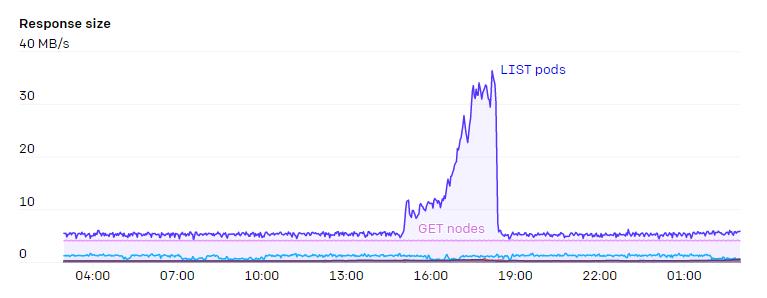
由于集群内的节点数和 Pod 数不断增长,我们发现 Flannel 难以扩展到所需的吞吐量。于是,我们转而使用原生 Pod 网络技术,管理 Azure VMSSes 的 IP配置和相关的 CNI 插件。这样我们的 Pod 就能够获得宿主级别的网络吞吐量。我们改用基于别名的 IP 寻址的另一个原因是,我们最大的集群上大约有20万个IP地址正在使用中。在测试基于路由的 Pod 网络时,我们发现我们可以有效利用的路由数量受到了严重限制。不采用封装增加了对底层 SDN 或路由引擎的需求,但能让网络结构更简单。添加VPN或隧道也不需要添加任何额外的适配器。我们也不需要担心由于某部分网络的MTU较低而导致数据分片的问题。网络策略和流量都很容易监控,每个数据包的源地址和目的地址都没有任何歧义。我们在宿主上使用iptables来跟踪每个命名空间和Pod上网络资源的使用情况。这样研究人员就可以可视化网络的使用情况。具体来说,因为许多实验的互联网和Pod间通信都有独特的模式,所以能够调查何处可能出现瓶颈是非常必要的。iptables 的 mangle 规则可以给任何符合特定规则的数据包做标记。我们采用了以下规则来检测流量属于内部还是发向外网。FORWARD 规则负责 Pod 间的流量,而 INPUT 和 OUTPUT 负责来自宿主的流量:
一些健康检查是被动的,永远在节点上运行。这些健康检查会监视基本的系统资源,如网络不通畅、磁盘失败或磁盘满、GPU错误等。GPU会呈现多种错误,但最常见的就是“Uncorrectable ECC error”(无法修复的ECC错误)。Nvidia的Data Center GPU Manager (DCGM)工具可以帮助查询该错误,以及许多其他的“Xid”错误。跟踪错误的方法之一就是使用 dcgm-exporter工具将度量导出到Prometheus监视系统中。这样就可以创建DCGM_FI_DEV_XID_ERRORS度量,其内容为最近发生过的错误代码。此外,NVMLDevice Query API 还可以提供有关 GPU 的健康情况和操作的更详细信息。检测到错误之后,通常重启就能修复 GPU 或系统,尽管有些情况下需要更换显卡。另一种健康检查会跟踪来自上游云服务提供商的维护事件。每个主流云服务提供商都会提供一种方法,获知当前使用的VM是否即将维护,从而导致服务中断。VM 可能需要重启,因为需要给监视程序打补丁,或者给物理服务器更换硬件。这些被动的健康检查在所有节点的后台时刻运行。如果健康检查失败,节点就会自动禁止访问,这样新的Pod就会被调度到其他节点。对于更严重的健康检查失败,我们还会驱逐 Pod,要求所有当前正在运行的 Pod 立即退出。是否退出依然取决于 Pod 本身,这一点可以通过 Pod 中断预算进行配置,决定是否允许驱逐发生。最终,在所有 Pod 终止或者经过7天之后(我们的 SLA 中的规定),我们会强制终止 VM。
主动 GPU 测试
不幸的是,并非所有的 GPU 问题都能从 DCGM 中看到错误码。我们自己构建了GPU测试库,能够捕获额外的错误,确保硬件和驱动程序按照预期运行。这些测试无法在后台运行,因为运行测试需要独占 GPU 几秒钟或几分钟。首先,我们会在节点启动时运行测试,称为“预运行”。所有加入集群的节点都会加上 “preflight” 污染并打标签。该污染可以防止普通 Pod 被调度到节点上。然后配置一个 DaemonSet,在所有带有该标签的 Pod 上运行预运行测试。测试成功后,测试程序会移除污染,节点就可以正常使用了。我们还会在节点的生命周期内定期执行测试。测试通过 CronJob 运行,因此可以在集群中的任何可用节点上执行。虽然这样无法控制测试在哪个节点上运行,但我们发现,只要时间足够长,它就能提供足够的测试覆盖,同时不会对服务造成太多干扰。
除了使用 cluster-autoscaler 来动态伸缩集群之外,我们还会删除并重新添加集群内的不健康节点。实现方法是将集群的最小尺寸设置为零,最大尺寸设置为可用的容量。但是,如果 cluster-autoscaler 看到空闲节点,就会尝试将集群收缩至必要限度大小。从许多角度来看(VM 的启动延迟、预分配的成本、对API服务器的影响)来看,这种空闲状态的伸缩并不理想。所以,我们同时为仅支持 CPU 的宿主和支持 GPU 的宿主引入了气球部署。该部署包含一个 ReplicaSet,其中设置了低优先级 Pod 的最大数量。这些 Pod 会占用一个节点内的资源,所以自动缩放器就不会认为该节点闲置。但是由于这些 Pod 优先级很低,因此调度器可以随时将其驱逐,给真正的作业腾出空间。(我们选择了使用部署而不是 DaemonSet,避免 DaemonSet 在节点上被认为是闲置负载。)需要注意的一点是,我们使用了 Pod 反亲和性来保证 Pod 最终会均匀地分布到节点上。Kubernetes 早期版本的调度器在处理 Pod 反亲和性时的性能为O(N^2),不过这一点在1.8版本后就修正了。