基于画像推荐系统设计(离线+实时)
Posted 数据仓库与Python大数据
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于画像推荐系统设计(离线+实时)相关的知识,希望对你有一定的参考价值。
不点蓝字,我们哪来故事?
目录
一、架构设计
二、内容画像
离线文章画像构建
TFIDF计算
TEXTRANK计算
文章画像结果计算
离线增量文章画像计算
Word2Vec与文章相似度
三、用户画像
3.1 为什么要进行用户画像构建
3.2 用户画像标签建立
用户行为处理
用户画像标签权重计算
用户画像标签权重计算算法
3.3 用户画像增量更新
四、召回和排序
4.1 离线召回
召回表设计和召回方式
召回表设计
模型召回
内容召回
4.2 离线排序模型训练
离线排序模型-CTR预估
点击率预测
特征服务中心
五、实时计算
实时计算业务的作用
实时日志分析处理
实时召回集实现
热门和新文章召回
六、推荐业务流的实现和ABTest
导读
利用数仓用户埋点的点击行为、浏览行为、收藏行为等建立用户画像和文章画像,结合机器学习等相关算法,找出用户画像和文章画像的关系,达到千人千面的推荐效果。
一、系统框架
使用lambda大数据数仓实时和离线计算架构,利用用户的点击行为、浏览行为、收藏行为等建立用户画像和文章画像的关系,通过机器学习推荐算法进行推荐。
架构流程:
基础数据层
- 业务数据(用户基础信息、文章基本信息)和用户行为日志数据(用户行为日志埋点信息)
- 业务批量存储在HDFS上用以做离线分析数据处理层
- 基础计算(基于离线和实时数据,对各类基础数据计算成用户画像、文章画像)
- 召回和排序
- 召回(使用算法筛选出用户感兴趣的文章候选集合)
- 排序(点击率预估模型、特征处理、模型评价)推荐业务层(对外提供rpc接口实现推荐业务接入,用户可不断下拉刷新)
二、文章画像
文章的画像主要就是文章的标签化,根据内容定性的制定一系列的标签,主要是提取出文章的相关分类词、关键词和主题词。
用户画像主要是用户的喜好程度,用户喜欢看的内容就可以当做用户喜好的标签,就是在用户画像过程中加上文章喜好这一类。
离线画像构建存到hbase,业务数据使用sqoop从业务表导到hive中。
发现频道是app的内容频道,其下文章主要分布在知识库中,知识库目前分为故事儿歌、宝宝学堂、家长大学、动漫卡通、手工制作等分类。这些分类下又有小分类,在给用户打标签的过程中可以把这些分类的主题词打进去。
另外根据用户行为的浏览(时长/频率)、点击、分享、收藏、关注、购买等其他关键信息均可以不同程度的代表用户对这个内容的喜好程度。
2.1 离线文章画像构建
文章画像:给每篇文章定义一些主题词和关键词(主题词经过了规范化处理)。
关键词:通过TEXTRANK算法计算出的结果TOPK个词以及权重
主题词:通过TEXTRANK算法计算出的TOPK词与TFIDF计算的TOPK个词的交集
步骤:
合并文章信息(文章标题 + 文章频道名称 + 文章内容)作为一个字段存到表中,避免一些词漏掉。
所有历史文章的Tfidf计算
所有历史文章的TextRank计算
2.2 TFIDF计算
需要依靠现有文章先训练模型(一个是每篇文章的词频cv模型,另一种是逆文档频率idf模型)。
对文章进行分词。
通过cv模型得到每篇文章的词频结果
将词频结果导入到idf模型
在jieba分词过程中加载自己的分词词典和停用词。
对于每篇文章的词的tfidf的权重排序获取topk个词。
2.3 TEXTRANK计算
14年提出,通过词之间的相邻结构关系构建网络,使用PageRank迭代计算每个词的rank值,根据rank值排序即可得到关键词,提取一篇文章的关键词和权重。
TextRank提取关键词步骤:
对文本进行分词和词性(jieba.posseg模块可以获取词性,根据词性可以方便处理停用词)的标注处理,根据自己的分词词典和停用词得到分词结果
建立一个为k(根据情况设定)的窗口,相当于每个单词要将票投给它身前身后距离5以内的单词
对次进行迭代投票
可以使用jieba.analyse.textrank模块可以获取权重结果。
2.4 文章画像结果计算
目前有两张表,一个是dfidf结果表,一个是textrank表。
通过这两张表将关键词和主题词存到 文章画像表。
加载idf,保留关键词及权重计算(TextRank * IDF)
合并关键词及权重到一个字典保存到表中
计算tfidf和textrank的共同词作为主题词
关键词与主题词合并,得到文章最终画像
2.5 离线增量文章画像计算
增量文章可以设定时间1小时同步一次数据,在增量过程中如果有新文章则计算新文章的tfidf值和textrank值并重复之前离线的操作,如果没有新文章入库,就不需要做上述操作
2.6 Word2Vec与文章相似度
每个频道推荐的时候会通过颖计算好的两两文章相似度,快速达到在线推荐的效果。
来了新用户,通过用户发生的行为,可以快速推荐文章。
方式:
计算两两文章tfidf之间的相似度
计算两两文章的Word2Vec或者doc2vec的向量相似度(效果更好)
通过Word2Vec得到文章向量思路
通过大量历史文章数据,从之前合并的文章表中取出合并文章,然后分词,训练得到文章的词向量
得到文章画像关键词的词向量
通过关键词的词向量计算得到文章的平均词向量(文章向量),保存到数据库
文章向量: 通过文章的topk的关键词向量,平均词向量=文章向量
文章向量的计算
离线通过文章向量计算文章相似度
在每个频道内去文章的相似度
在推荐相似文章的时候,只会取topk个相似文章被推荐出去
两两计算文章量很大解决方案:
频道内首先聚类,在每个类别下在进行文章相似度计算
局部敏感哈希LSH
局部敏感哈希基本思想:
如果两个文本在原有的数据空间是相似的,那么进过哈希函数转换后也具有很高的相似度(欧式距离)
计算得到的结果存储到HBASE中,因为计算出来的相似度要在实时推荐的时候使用,而Hbase的速度非常快,和redis不相上下,存在Hive只适合在离线分析时候使用
LSH详细过程
mini hashing
通过签名向量的方式,如果两篇文章相似,到同一个桶的概率非常大
对所有文档、对应不同的词进行文档标记
对默认所有的词的顺序做一个随机打乱,然后文章进行重新标记
重复第二步骤:
Random Projection
Random Projection是一种随即算法随即投影的算法很多,如PCA、高斯随即投影
文章相似度增量更新
当后端审核通过一篇文章后发生点击行为,因为相似度计算是离线计算的,所以对新增的文章我们也要做和历史数据做相似度计算,这样我们就可以根据新文章给用户推荐相似的历史文章。
三、用户画像
3.1 为什么要进行用户画像构建
为了更清楚的了解用户,构建用户画像是一劳多得的事情,不仅可以满精准推送、精准推荐、精准营销,还可以作为网站的用户属性分析,用户行为分析、商业转化分析等,共用一套用户画像,可以对用户有统一的认知。
用户画像主要包括用户信息、用户行为信息等其他数据。用户信息包括个人信息。生活习惯、社会关系。用户行为信息包括浏览、点击、分享、收藏、点赞等行为。
3.2 用户画像标签建立
根据用户发生行为的文章,进行频道和标签提取建立用户画像标签建立
基础画像信息
用户画像流程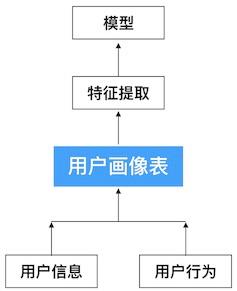
根据我们之间给文章建立好的标签,利用这些文章标签给用户贴上相应的标签,如: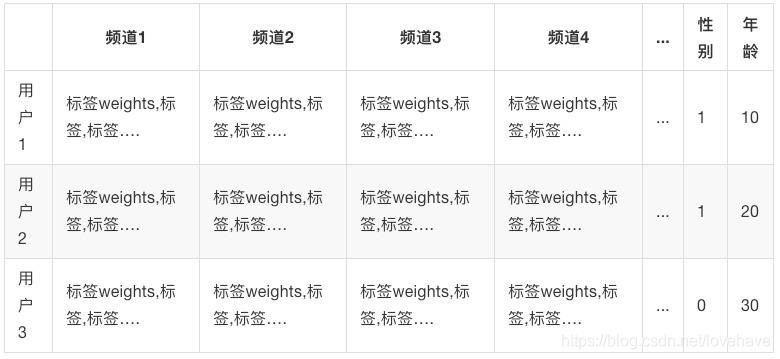
1)用户行为处理
创建Hive基本数据表
读取固定时间内的用户行为日志
进行用户日志数据处理
存储到用户行为表中

更新用户行为表
点击、分享、收藏需要更新,新的行为数据和历史行为数据按照用户id和文章id进行合并变成一行数据 ,如: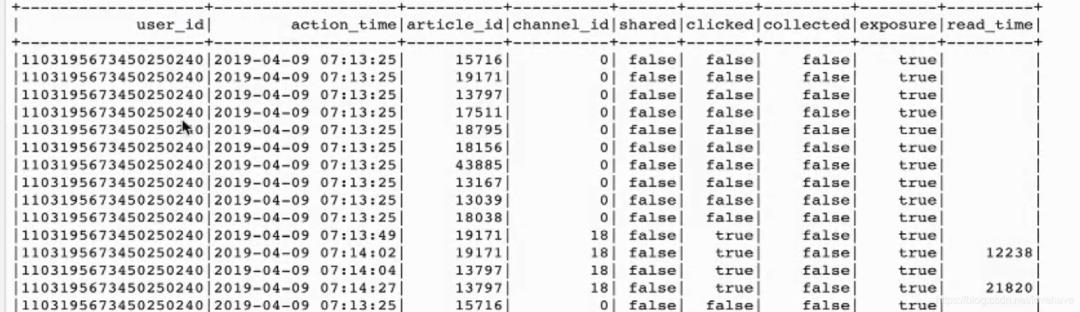
2)用户画像标签权重计算
画像存储:
用户画像作为特征提供需要快速读取使用,所以选择存储在HBASE中,如果离线分析也需要使用,可以建立Hive到Hbase的外部表(实时分析可以用,离线也可以用)
获取用户各频道的关键词,进行用户权重计算并落地存储
3)用户画像标签权重计算算法
用户标签权重=(行为类型权重之和)* 时间衰减
时间衰减:1/(log(t)+1) ,t(一般按天)为时间发生时间距离当前时间的大小。
行为类型权重: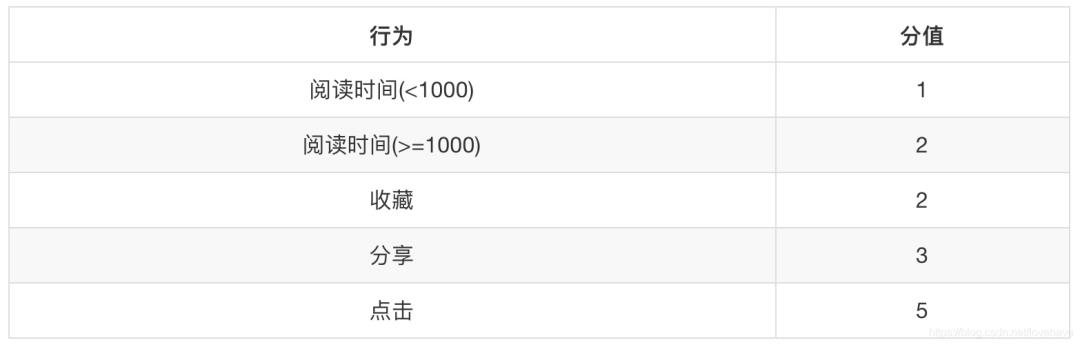
3.3 用户画像增量更新
用户基础信息画像定时更新
用户行为画像增量定时更新
四、召回和排序
4.1 离线召回
召回:从文章库中获取相似度高的文章作为候选文章
排序:从召回集中根据特征做排序进行推荐
召回和排序流程: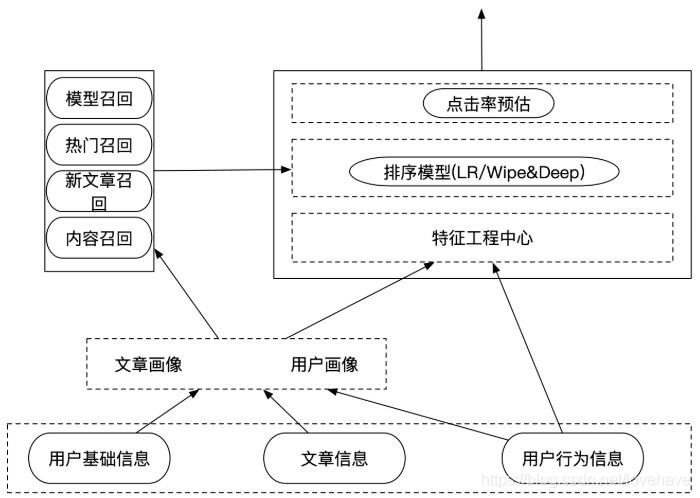
召回一共分为四类召回方式:模型召回、热门召回、新文章召回、内容召回
主要针对以下两种情况:
用户冷启动:
基于内容的协同过滤在线召回:基于用户实时兴趣画像相似的召回
非个性化推荐:
- 热门召回:自定义热门规则,根据当前时间段热点定期更新文章库
- 新文章召回:为了提高新文章的曝光率,对新文章进行推荐个性化推荐:
离线部分的召回:
基于模型协同过滤推荐离线召回:ALS(spark有模块可以实现,暂不考虑)
基于内容的离线召回:就是基于用户画像的召回
召回表设计和召回方式
1)召回表设计
因为HBASE可以有多个版本数据存在同一张表的功能(调整参数VERSIONS的大小),我们把基于模型和基于内容的召回结果存入同一张表,避免多张表进行处理。另外增加一个历史召回表,把历史召回表的数据和后来的召回数据进行比对,防止重复推荐。
2)模型召回
模型训练基于特征(抽取用户特征和文章特种并合并),使用ALS模型进行处理
为了方便实时排序处理,用户特征和文章特征会先离线抽取好落地到表中
3)内容召回
内容召回是基于用户的协同过滤推荐,首先过滤用户点击的文章,根据用户每次操作的文章进行相似度推荐,相似结果只取前10或20
4.2 离线排序模型训练
1)离线排序模型-CTR预估
CTR(Click-Through Rate)预估: 给定一个item,预测该item被点击的概率。
进行CTR预估有两种方式,一种是通过离线的模型训练,另一种根据用户和文章的特征进行处理。
模型训练
模型训练通过逻辑回归LR模型进行CTR预估,首先读取用户点击行为表、用户画像、文章画像,构造训练样本,使用LR模型进行训练、预测、结果评估。
特征处理原则
如果是离散数据,进行one-hot编码。
如果是连续数据,进行归一化处理。
如果是图片或文本,根据文章标签和关键词提取。
合并特征向量
(频道id channel_id1个+用户特征权重10个+文章向量100个+文章关键词权重) = 121个特征
2)点击率预测
使用训练好的模型加载文章得到对这个文章点击和不点击的概率。
3)特征服务中心
特征服务中心可以作为离线计算存储用户和文章特征的中转中心,可以为程序快速提供特征结果,其原则是对可用到的用户及文章特征进行存储,便于实时推荐进行读取。特征中心的数据存储到HBASE中。特征服务中心在HBASE中存储两张表,一个是用户特征表,一个是文章特征表。
文章的特征:
关键词的权重
文章的频道
文章向量结果
文章特征存取步骤:
读取文章画像
进行文章相关特征处理和提取
合并文章所有的特征作为模型训练或者预测的初始特征
文章特征存到HBASE
五、实时计算
5.1 实时计算业务的作用
实时在线计算主要目的是解决用户冷启动问题,新用户没有日志记录,所以只能走实时推荐。
根据用户的实时点击反馈,快速获取用户的特征喜好
5.2 实时日志分析处理
正常情况下日志数据会收集到hadoop,但是在实时分析的时候需要将每个时刻的用户行为日志收集到kafka中,等到实时程序(flink或者spark streaming)去消费。
5.3 实时召回集实现
实时召回基于画像相似的文章推荐。对用户日志进行处理,实时获取到相似文章放入用户召回集中。
实时召回实现步骤:
配置实时程序信息(flink或者spark streaming)
读取用户行为日志数据,获取相似文章集合
过滤历史文章集合
存入召回结果和历史记录结果
5.4 热门和新文章召回
通过对日志数据的处理,可以获取到热门文章集合,对热门文章实时召回来增加对当前热点文章的点击。
对新文章进行曝光推荐来增加新文章的点击量,对于权重比较高的新文章,通过SparkStreaming计算可以推给另外的客户,这样新用户就能看到大家比较喜欢看的文章。
热门和新文章召回步骤:
在kafka中添加热门文章和新文章的配置信息
编写热门文章和新文章手机程序
将获取到的文章id存到redis缓存中
六、推荐业务流和ABTest
这部分后面会专门文章展开整理分享,敬请期待..
以上是关于基于画像推荐系统设计(离线+实时)的主要内容,如果未能解决你的问题,请参考以下文章