机器学习系列-ROC曲线以及AUC计算
Posted 人工智能与数据分析
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习系列-ROC曲线以及AUC计算相关的知识,希望对你有一定的参考价值。
对于分类器,或者是机器学习中的分类算法,评价指标主要有precision,recall,F1-score以及接下来我们要讨论的ROC以及AUC。本文主要是对以上评价指标做一些简单的原理介绍,然后通过python和SPSS两种软件来实现二分类和多分类的ROC曲线。
本菜鸟之前在面试猪场数据分析岗的时候,面试官出了一道这样的题“AUC的计算公式是什么?”,我当场就蒙了,就把计算ROC的公式给罗列的一番,面试完,百度发现答非所问,那么到底什么是AUC呢?又该如何计算呢?
这里只罗列一些关于AUC概念以及两种计算方法。
1、原理篇
到底什么是AUC,百度百科:随机挑选一个正样本以及一个负样本,当前的分类算法根据得到的Score值将这个正样本排在负样本前面的概率就是AUC值。这里的Score值就是预测为正的概率的值,排在前面表示的是正样本的预测为正的概率值大于负样本的预测为正的概率值。
计算方法有两种:
1:绘制ROC曲线,ROC下面的曲线面试就是AUC的值
2:假设总共有(m+n)个样本,其中正样本m个,负样本n个,总共有m*n个样本对,计数,正样本预测为正样本的概率值大于负样本预测为正样本的概率值记为1,累加计数,然后除以(m*n)就是AUC的值
那么ROC又是什么呢?对于二分类问题(0,1),经常会用到ROC 曲线值来衡量我们模型分类的效果,但是对于ROC曲线的理解还存在一些模糊的地方,这次就详细的记录一下。
1.1 混淆矩阵
详细介绍ROC曲线之前,这里先需要理解一个叫做混淆矩阵的概念
针对预测值和真实值之间的关系,我们可以将样本分为四个部分:
真正例(TP):预测值和真实值都是1
假正例(FP):预测值为1,真实值为0
真负值(TN):预测值和真实值都是0
假负值(FN):预测值为0,真实值为1
注:其中TP表示正确的肯定数目;FN表示漏报;FP表示误报;TN表示正确拒绝的非匹配数目
以下是上述内容的列表,其中1代表正类,0代表负类:
该矩阵就被成为混淆矩阵
根据混淆矩阵的概念可得一下公式:
Fp rate = FP/N2 原本是错的预测为对的比例(数值越小越好)
Tp rate= TP/N1 原来是对的预测为对的比例(数值越大越好)
Precision= TP/N3 预测为对的当中,原本为对的比例(数值越大越好)
Recall= TP/N1 原本为对的当中,预测为对的比例(数值越大越好)
Accuracy= (TP+TN)/N 预测为对的占整个的比例
F-measure= 2*precison*recall/(precison+recall) F度量是对准确率和召回率做一个权衡(数值越大越好)
理解了以上公式以后,那么恭喜你,接下来介绍的ROC曲线也就非常好理解了。
下图为一个标准的ROC曲线图,其中横坐标为Fp rate(假阳率,FPR),纵坐标为Tp rate(真阳率,TPR)
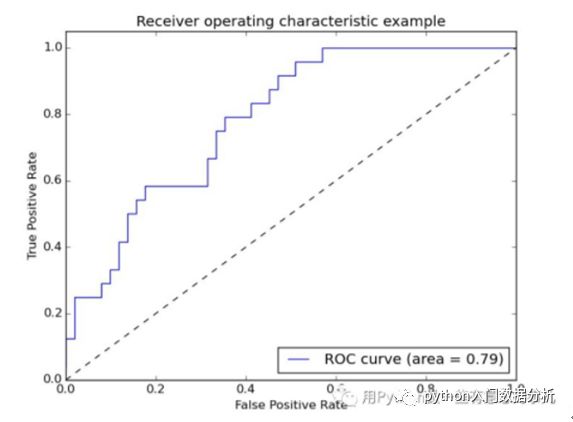
其中TPR决定了一个分类器的所有正类样本中能正确分辨出正类的性能,而FPR是决定了所有负类样本中有多少个假正类的判断。每一个预测结果在ROC曲线中以一个点代表。
2、ROC曲线的特殊点和线
(1)ROC曲线图中的四个点
第一个点,(0,1),即FPR=0, TPR=1,这意味着FN(false negative)=0,并且FP(false positive)=0。这是一个完美的分类器,它将所有的样本都正确分类。第二个点,(1,0),即FPR=1,TPR=0,类似地分析可以发现这是一个最糟糕的分类器,因为它成功避开了所有的正确答案。第三个点,(0,0),即FPR=TPR=0,即FP(false positive)=TP(true positive)=0,可以发现该分类器预测所有的样本都为负样本(negative)。类似的,第四个点(1,1),分类器实际上预测所有的样本都为正样本。经过以上的分析,,ROC曲线越接近左上角,该分类器的性能越好。
(2)ROC曲线图中的一条特殊线
考虑ROC曲线图中的虚线y=x上的点。这条对角线上的点其实表示的是一个采用随机猜测策略的分类器的结果,例如(0.5,0.5),表示该分类器随机对于一半的样本猜测其为正样本,另外一半的样本为负样本
3、No BB,show me thecode
看了这么多的原理讲解,大家肯定对如何画出炫酷(并没有卵用)的ROC曲线图产生了浓厚的兴趣,本着No BB,Show me the code,以下是本菜鸟对ROC实现的代码部分,文章主要是为了记录,如果哪里有不对的地方,也不要告诉我了:
这里我主要是引用了一个强大的包,Scikit-plot,该包中可以实现多种机器学习视图,不在本文做过多介绍。想要详细理解以及安装的小伙伴可以在这里找到答案:
https://github.com/reiinakano/scikit-plot/tree/26007fbf9f05e915bd0f6acb86850b01b00944cf这里直接画二分类的ROC曲线,至于二分类的请读者自行实现
本例中用到的数据是sklearn中的手写字体数据,以下是代码部分:
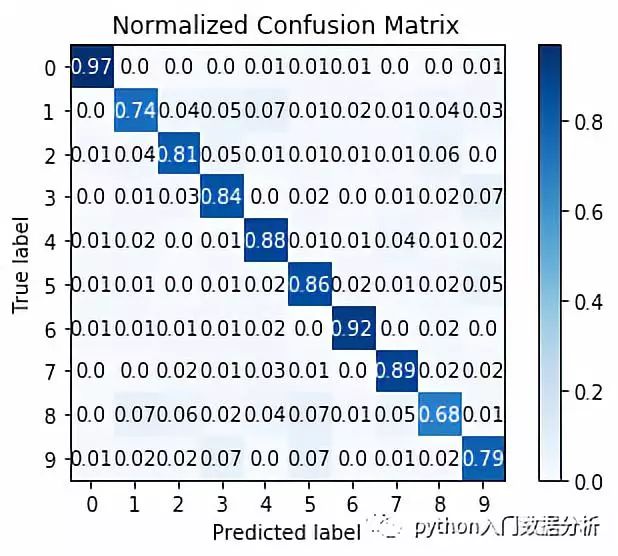
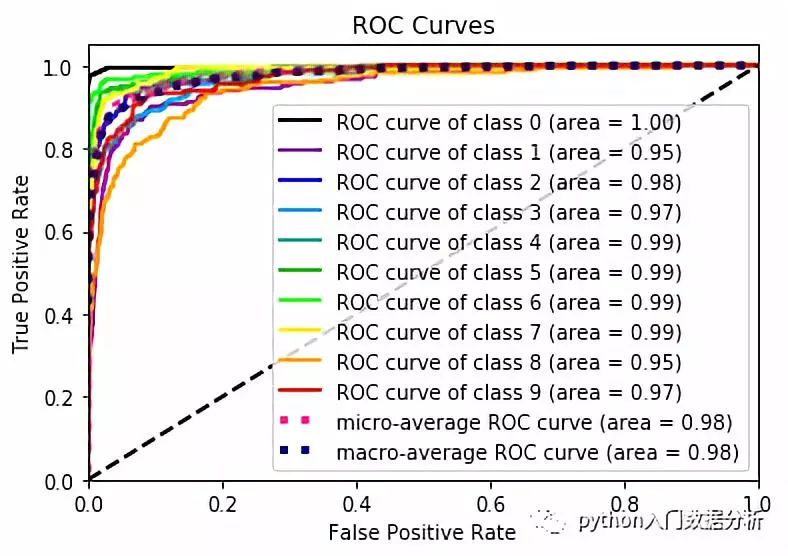
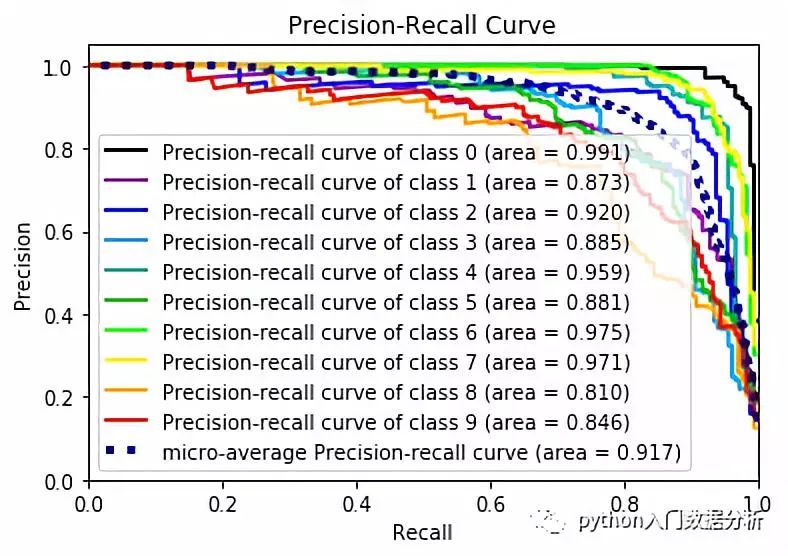
# -*- coding: utf-8 -*-"""Created on Wed Jan 30 21:07:56 2019@author: Johnson"""from sklearn.datasets import load_digitsimport matplotlib.pyplot as pltfrom scikitplot import classifier_factoryX,y = load_digits(return_X_y=True)from sklearn.ensemble import RandomForestClassifierclf = RandomForestClassifier(n_estimators=5,max_depth=5,random_state=1)import scikitplot.plotters as skplt#skplt.plot_learning_curve(clf,X,y) #学习率曲线clf.fit(X,y)classifier_factory(clf)clf.plot_confusion_matrix(X,y,normalize = True) # 混淆矩阵clf.plot_roc_curve(X,y) #roc曲线clf.plot_precision_recall_curve(X,y) #recall 曲线#skplt.plot_feature_importances(clf)plt.show()
混淆矩阵图如下:
ROC曲线如下
召回率曲线如下:
附加功能
在试玩scikitplot这个包的时候发现,感觉比较有意思,这里贴出来以供后来查看
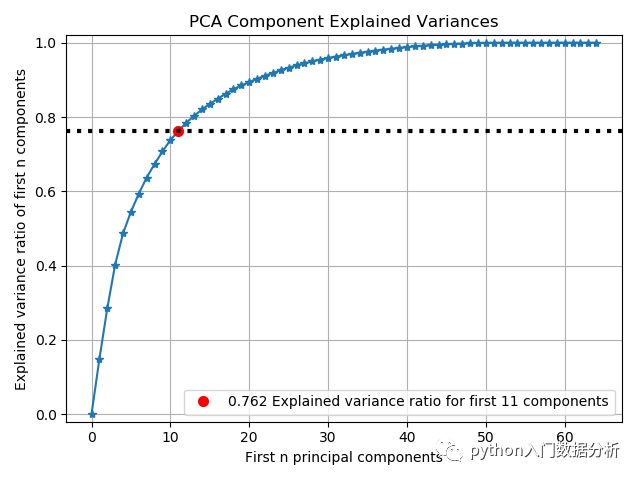
PCA
from sklearn.decomposition import PCA
from sklearn.datasets import load_digits as load_data
import scikitplot as skplt
import matplotlib.pyplot as plt
X, y = load_data(return_X_y=True)
pca = PCA(random_state=1)
pca.fit(X)
skplt.decomposition.plot_pca_component_variance(pca)
plt.show()
结果输出
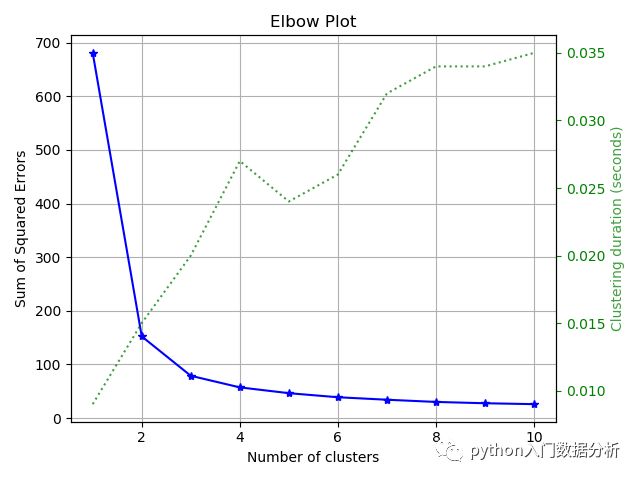
肘部法则
import matplotlib.pyplot as plt
import scikitplot as skplt
from sklearn.cluster import KMeans
from sklearn.datasets import load_iris as load_data
X, y = load_data(return_X_y=True)
kmeans = KMeans(random_state=1)
skplt.cluster.plot_elbow_curve(kmeans, X, cluster_ranges=range(1, 11))
plt.show()
结果输出
特征重要性
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_iris as load_data
import matplotlib.pyplot as plt
import scikitplot as skplt
X, y = load_data(return_X_y=True)
rf = RandomForestClassifier()
rf.fit(X, y)
skplt.estimators.plot_feature_importances(rf,
feature_names=['petal length',
'petal width',
'sepal length',
'sepal width'])
plt.show()
结果输出
ks统计图
import matplotlib.pyplot as plt
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import load_breast_cancer as load_data
import scikitplot as skplt
X, y = load_data(return_X_y=True)
lr = LogisticRegression()
lr.fit(X, y)
probas = lr.predict_proba(X)
skplt.metrics.plot_ks_statistic(y_true=y, y_probas=probas)
plt.show()
结果输出
以上是关于机器学习系列-ROC曲线以及AUC计算的主要内容,如果未能解决你的问题,请参考以下文章