更底层的算法部署工程师:机器学习系统与SysML&DL
Posted oldpan博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了更底层的算法部署工程师:机器学习系统与SysML&DL相关的知识,希望对你有一定的参考价值。
老潘想说:
知其然还要知其所以然,对于深度学习框架基本的一些底层原理,在平常的使用中可能体会不到。但如果想要更进一步地了解其数据流动方式和运行逻辑,强烈建议看一下这篇文章,让你对框架的理解比别人更深一步。文章较为费脑,建议先收藏~

前言
在使用过TVM、TensorRT等优秀的机器学习编译优化系统以及Pytorch、Keras等深度学习框架后,总觉得有必要从理论上对这些系统进行一些分析,虽然说在实践中学习是最快最直接的,但恶补一些关于系统设计的一些知识还是非常有用了,权当是巩固一些基础了。
因此,有必要学习了解一下机器学习系统的设计和思想。如果不是很了解机器学习系统的设计,可以看下知乎上关于这个问题的回答:相比AI算法研究,计算机系统研究没落了吗?[1]
以下是本系列文章的笔记来源:
-
CSE 599W: Systems for ML [2] -
AI-Sys Spring 2019 [3]
注意,这一系列文章并不是传统的深度学习或者机器学习讲解,关于这部分的讲解可以看CS231n或者吴恩达的入门课,该系列文章适合在深度学习方面有经验有了解的童鞋。
附一张CSE 599W一开始的讲解说明:

这门课主要的重点不在深度学习理论算法,而是讲解与深度学习有关、机器学习系统方面的讲解。
什么是深度学习
简单说下深度学习这个概念。

由上图可知,深度学习所包含的基本内容,也就是以下四大部分:
-
模型的设计(最核心的地方,不同的任务设计的模型不同,使用的具体算法也不同) -
目标函数,训练策略(用于训练模型权重参数的目标函数,也就是损失函数,以及一些训练的方法) -
正则化和初始化(与训练过程中的模型权重信息有关系,加快训练的收敛速度,属于训练部分) -
足够多的数据(机器学习亦或深度学习都是由数据驱动着了,没有数据的话就什么都不是)
我们在学习深度学习的过程中,难免会有一些实践,于是我们就利用以下这些优秀的深度学习库去实现我们自己设计的模型,并且设计好损失函数,一些正则化策略,最终利用这些库去读入我们需要新联的数据,然后运行等待即可。

这些优秀的深度学习库(caffe、Mxnet、TF、Pytorch)我们应该都耳熟能详了,那么这些深度学习库的大概结构都是什么呢?
大部分的深度学习库都是由以下三个部分组成
-
用户API -
系统组件 -
底层架构
大多数的我们其实并不需要接触除了用户API以外的其他两个部分,而用户API也是深度学习库最顶层的部分。

Logistic Regression
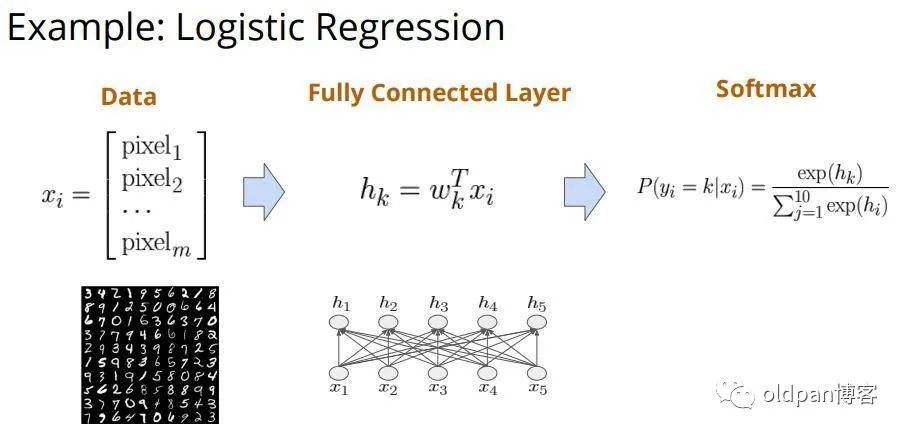
拿个例子简单说一下用户的API,首先我们有一个逻辑回归的任务,就拿最熟悉的MNIST数据集来进行演示,我们通过输入每个数字的向量化数据,然后通过全连接层去计算这些向量并且利用softmax函数进行预测。整个网络模型很简单已有一层全连接层。
接下来我们看一下使用numpy和tinyflow[4](这是一个迷你的深度学习系统库,麻雀虽小五脏俱全,值得我们去学习)去训练一个简单的神经网络识别MNIST手写数据库的例子:
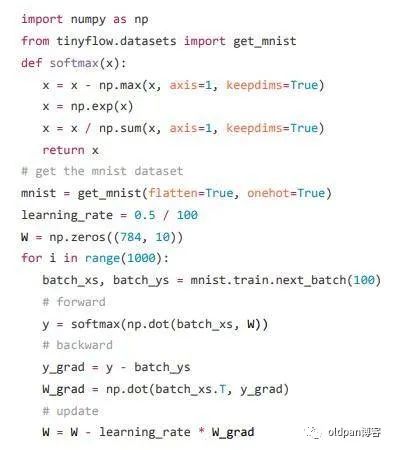

上述代码中最重要的也就是三个部分(在上图右侧已经列了出来):
-
前向计算:因为只有一个全连接层,所以我们的计算也很简单 ,其中 为输入的数据, 为权重, 为权重向量和数据向量点乘的结果。计算出来结果后我们使用softmax函数对其进行分类计算得到对应十个数字的概率向量(最后输出的向量包含10个元素,分别为每个数字的可能性) -
反向求导:我们求出权重W关于极大似然损失的导数,这里我们人工写了出来,在右图第二部分 -
梯度更新:我们简单对权重W进行更新,更新值为学习率乘以W的梯度,即 ,也就是我们经常用的SGD
整个深度学习库中最重要的也就是上述三个部分,大部分的深度学习库已经帮我们实现了上述的代码,我们不需要重复造轮子,直接使用即可。
尝试使用TensorFlow like API
接下来,我们使用类似于TensorFlow的API来对上述描述的代码进行重构,使用TensorFlow的API格式来实现上述代码实现的训练过程。
那么,为什么要使用TensorFlow类型的API进行演示而不是采用Pytorch呢?其实TensorFlow与Pytorch构建的图类型很不一样,虽然在最近一段时间TensorFlow已经出现了eager mode,但经典的TensorFlow是采用静态图来构建整个训练过程的。
也就是说,在TF中构建的是静态图,而在Pytorch中构建的是动态图:

其实关于静态图和动态图对于这个话题已经经过了很多的讨论,动态图灵活多变,而静态图虽然没有动态图灵活,但是因为提前都确定好了输入参数,计算方式等等过程,系统可以针对这些特点来对计算进行规划,所以在计算过程中的性能比动态图是要高一些的。
首先我们确定要进行的前向数据以及操作算子:
-
输入x为float32类型的向量,[None,784]中None表示当前输入的batch-size未知 -
W为权重信息,维度为[784,10] -
y为前向计算函数,利用算子函数嵌套定义了整个计算过程。

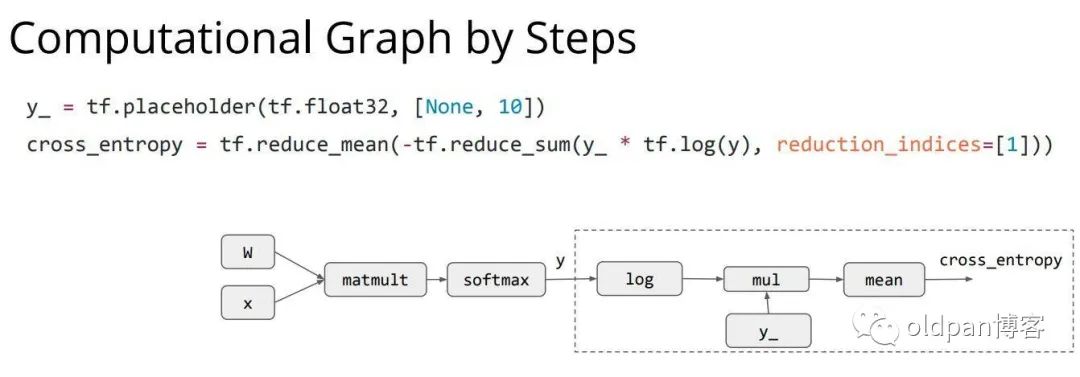
接下来设定了损失函数,可以看到
cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_*tf.log(y), reduction_indices=[1]))
这句中声明了一个损失函数,使用的是分类任务中最常用的交叉熵损失,注意y_代表存放了一个数据的分类label,每一个数据的分类标签是一个元素数量为10的向量,用于与预测出来的值进行比对。具体的公式在下图右侧。

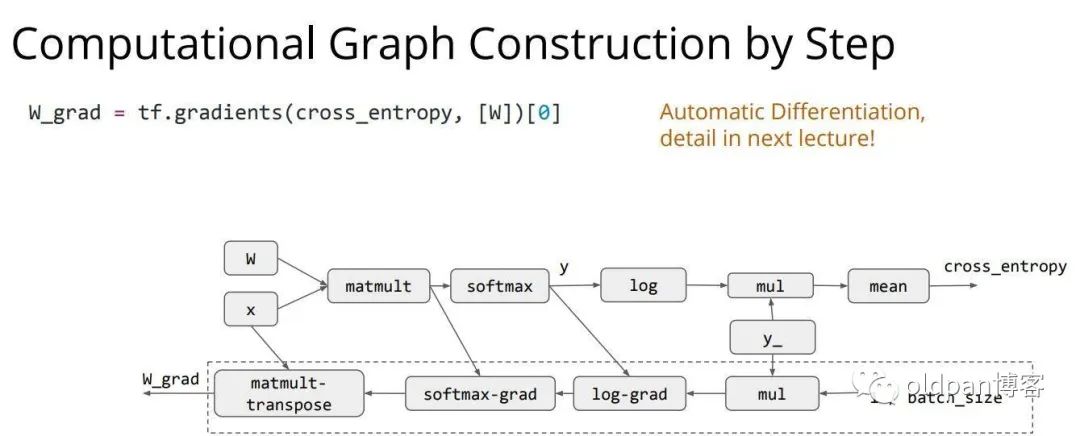
接下来设定了自动求导的过程,这一步中我们要求的是权重向量对损失值(也就是交叉熵损失后计算出来的值)的梯度,这里我们只是声明了一个函数,但是其中的计算过程是比较复杂的(也就是我们常说的自动求导的过程),这个之后会进行讲解,自动求导是我们必须要掌握的,直接手撸是必须的。

设定好了损失函数,接下来我们就要拿计算出来的梯度值来更新网络的权重信息了,在这个例子中使用SGD随机梯度下降的方式进行权重更新,我们只需要设定学习率这个超参数就可以。

因为在TF中,所有的声明式都仅仅是对要计算的流程进行声明,实际上并没有计算(这里可以称为一个懒计算的方法),也就是所谓的静态图方式定义好了整个网络以及训练的步骤,只是没有开始运作而已。
在运行完sess.run一句后,整个网络才开始正式执行起来。

这几张ppt的内容讲述了一个典型的神经网络库的运行流程(TF类型的,如果是Pytorch的话略有不同),通过这个我们可以知道一个深度学习框架的基本作用。接下来要说的就是上述过程中最为重要的自动求导过程。
计算图(Computation Graph)
计算图是实现自动求导的基础,也是每个深度学习框架必须实现的部分,接下来我们简单说说计算图是什么?
要说起计算图首先简单提一下声明式编程,正如下图中所展示的,计算图本质上是一种声明式语言,怎么说比较合适,这种语言不同于我们平时所说的python和C++,它是一种DSL(领域语言)或者一种迷你语言,这种语言深入嵌入到Python和C++中,也就是我们使用Python去操作,使用C++去具体实现。
声明式编程不是简单地一条接一条地执行我们的指令,而是根据我们给出的所有指令创建一个计算图(computing graph)。这个图被内部优化和编译成可执行的 C++ 代码。这样我们就能同时利用上两个世界的最优之处:Python 带来的开发速度和 C++ 带来的执行速度。
最终形态就是我们提前设定好了计算逻辑,其他的交给系统就行了,具体怎么优化就不用我们去操心。
下图中就是一个简单的例子,我们定义计算的逻辑a*b+3这个逻辑,其中node表示计算内容,箭头表示依赖关系。

下图中我们就利用TF-like API去实现一个简单的 的过程,这个过程需要的数据(x、W)和算子(matmult、softmax)都已经提前定义好了。

接下来是设置损失函数的计算部分:
然后设定与自动求导相关的梯度下降部分:
接下来是设定梯度更新的方式:
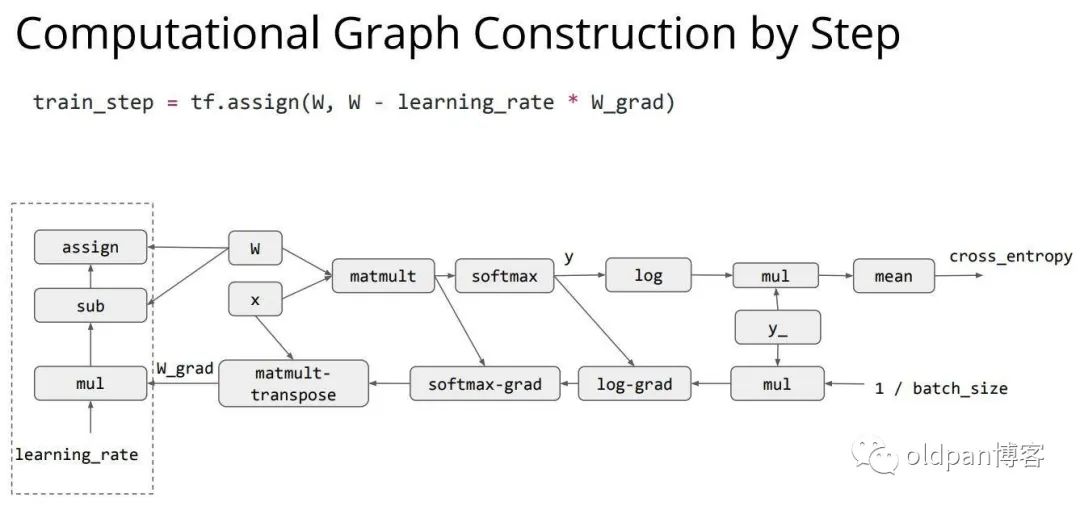
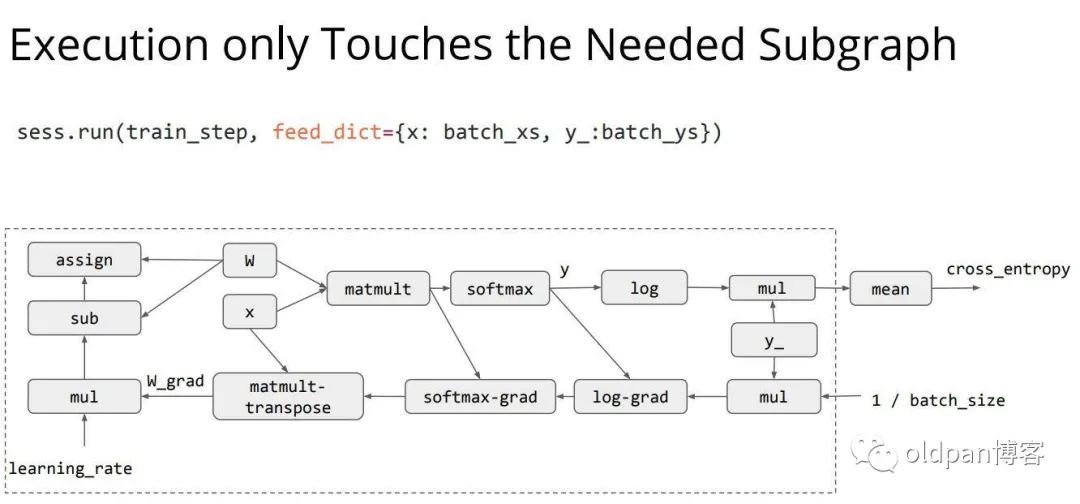
在设定完所有的计算逻辑后,这里正式开始计算的过程,只有执行完sess.run这句后,整个计算图才开始真正的进行计算了。
上面关于自动求导的具体过程并没有展示,这个过程将在下一节中进行讲解,不过关于自动求导的具体流程也可以在CS231n这门课中见到,具体在Backpropagation and Neutal Networks这一节中。
numpy 与 TF-program 的比较
之前我们使用了numpy与TF-like API的方式模拟了一个简单的Logistic Regression的过程,也就是实现利用一个简单的全连接网络去识别手写数字集MNIST的过程,这个过程中我们使用了两种不同的方式去构建,用计算图来说就是动态图(numpy)与静态图(TF),而用语言类型来说就是命令式编程(numpy)和声明式编程(TF)。
其实上述的numpy的例子也可以使用Pytorch做演示,因为Pytorch是一个类numpy的深度学习库,其操作的算子逻辑和numpy几乎一致,可以说是一个利用动态图结构的领域语言。
也就是说关于numpy与 TF-program 的比较,可以等同于关于动态图和静态图的比较,两者各有优缺点,但是如果追求性能和开发效率的话,静态图更胜一筹,但是如果追求灵活性和可拓展性,那么动态图的优势就展现出来了。

未完待续
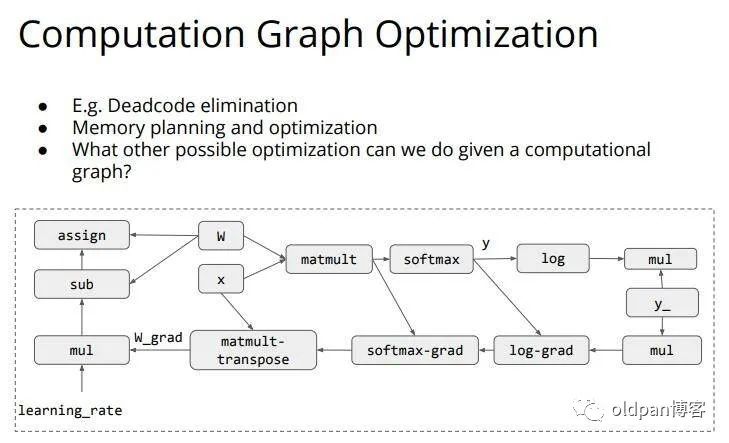
这节课的末尾提出了一些后续要讲的内容,首当其冲的就是计算图的优化。
计算图优化在TVM中这个深度学习编译器中占了很大的篇幅,正如下面所说,我们建立了计算图,因为这个计算图是静态的,所以我们可以在底层对其进行尽可能地优化,从而加快神经网络运行的速度,那么如何去优化呢?这可就是一个大学问,总之就是我们可优化的空间很大,而关于优化的具体细节放在之后进行描述。
另外一点,数据并行也是重点解决的问题之一,毕竟现在的数据越来越多,显卡计算能力虽然每年提升,但是内存(具体点就是显存)的提升有限。那么如何更高效更快地训练大量的数据,直接的途径就是并行分布式训练,如何处理并行期间出现的问题也是一个重点的方向。
相关参考
http://dlsys.cs.washington.edu/schedule https://ucbrise.github.io/cs294-ai-sys-sp19/ https://blog.csdn.net/tealex/article/details/75333222
脚注参考链接
相比AI算法研究,计算机系统研究没落了吗?: https://www.zhihu.com/question/322296599/answer/673561614
[2]CSE 599W: Systems for ML: http://dlsys.cs.washington.edu/schedule
[3]AI-Sys Spring 2019: https://ucbrise.github.io/cs294-ai-sys-sp19/
[4]tinyflow: https://github.com/tqchen/tinyflow
往期回顾
以上是关于更底层的算法部署工程师:机器学习系统与SysML&DL的主要内容,如果未能解决你的问题,请参考以下文章