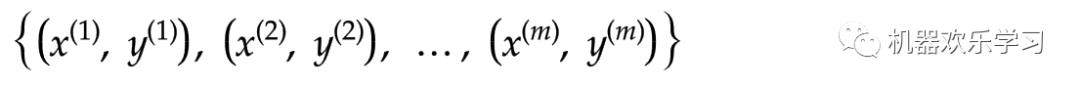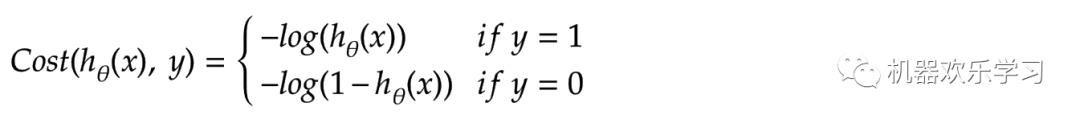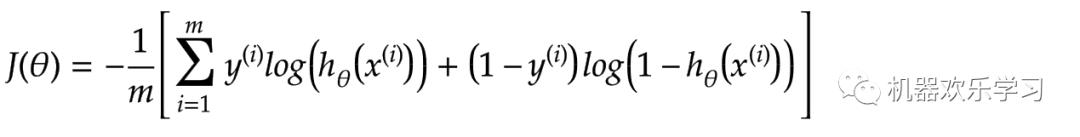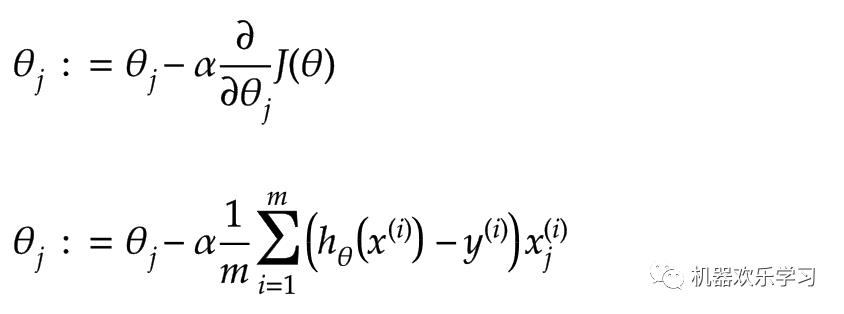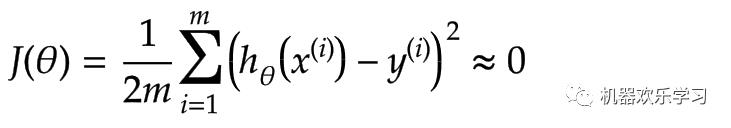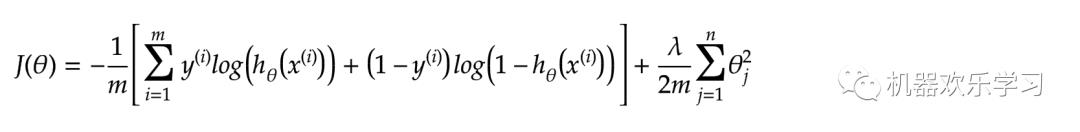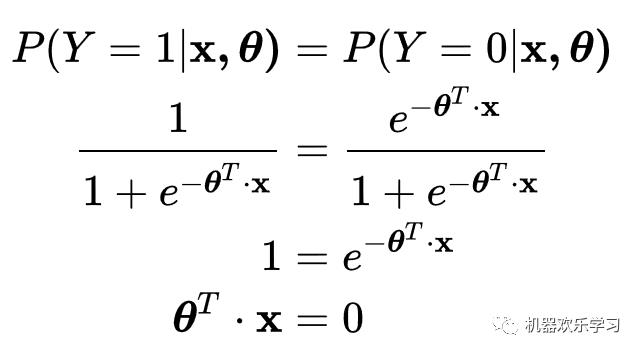最常用的机器学习模型竟然是它?!
Posted 机器欢乐学习
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了最常用的机器学习模型竟然是它?!相关的知识,希望对你有一定的参考价值。
二丫是一个海王,她同时和20个男生搞暧昧,终于有一天,她发现自己精力有限必须选择通讯录中的“优质男生”继续撩骚,放弃“不优质男生”。她决定用
身高,颜值,财富,学识,才华,这5点分别评分,通过线性加权求和的方式做决策,那她是怎么做的呢?
太长不看版本:“线性回归模型后加上一个sigmoid函数使回归问题变成了分类问题”,硬核知识在最后。
今天讲解一个既经典,又简单,用途又广泛的模型,逻辑回归。
在讲解模型中间,我们依旧穿插这将各种机器学习的思想和本质。水友们带着以下四个问题,开冲~
-
-
-
-
深入思考逻辑回归。
逻辑回归的本质是什么,为什么非要用sigmoid,为什么非要用交叉熵损失函数?
基本上把机器学习分成了五个模块,
监督学习,无监督学习,强化学习,集成学习,深度学习。每个模块又有很多分支,这里我们就不细讲了。大伙看了这个,直接溜了溜了,太多了模型,有点畏惧。这里我想跟大家说,大家可以先把精力放在
常用模型上。
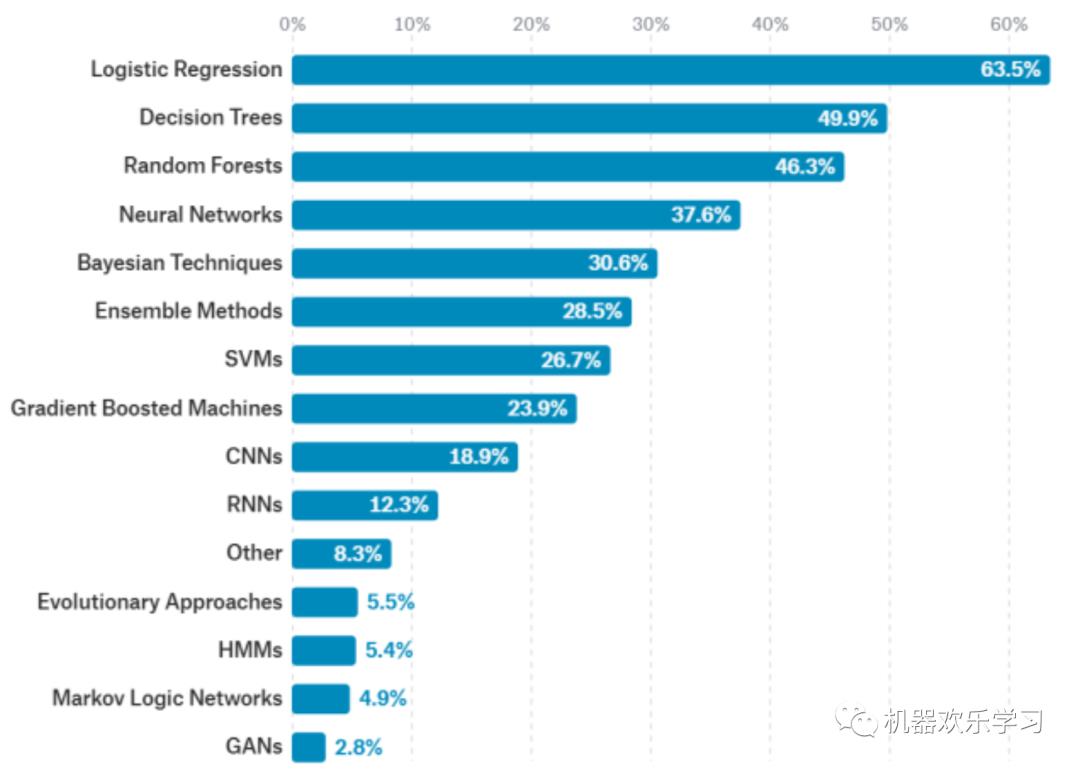
那什么是常用模型了?我们用数据说话,机器学习比赛Kaggle上显示:
我们发现,
数据科学中更常见的还是使用经典的机器学习算法,包括思想比较简单的逻辑回归,决策树,朴素贝叶斯,SVM都使用得非常非常多
。
真正使用频率超过10%的模型只有10个,这都是我们应该重点学习的。
而逻辑回归是最常用的机器学习方法,远远超过了神经网络,有点意外嗷。但是其实这也正常,因为逻辑回归完美的数学推导和深刻的生物,数学,信息学意义,使其很容易嵌入到各种模型中。
此外,如果我们单独拿分类这一个任务来看,随机神经,SVM,boosting和神经网络也都各在10%的数据集上得到第一。这说明,虽然神经网络非常火爆,但是传统的机器学习算法依旧具有非常强的竞争力。当然了仅看计算机视觉,CNNs无疑是屠杀一切;而自然语言处理领域则是RNNs独领风骚。
逻辑回归是一种广义线性回归,它与线性回归的模型形式基本上相同,都具有wx+b,其中w和b是待求参数,其区别是线性回归直接将wx+b作为输出变量,即y=wx+b,而logistic回归则通过函数L将wx+b对应一个隐状态p,p =L(wx+b),然后根据p 大小决定输出的值。
如果L是logistic函数,就是logistic回归,用于二分类;
如果L是softmax函数就是多项式回归,用于多分类。
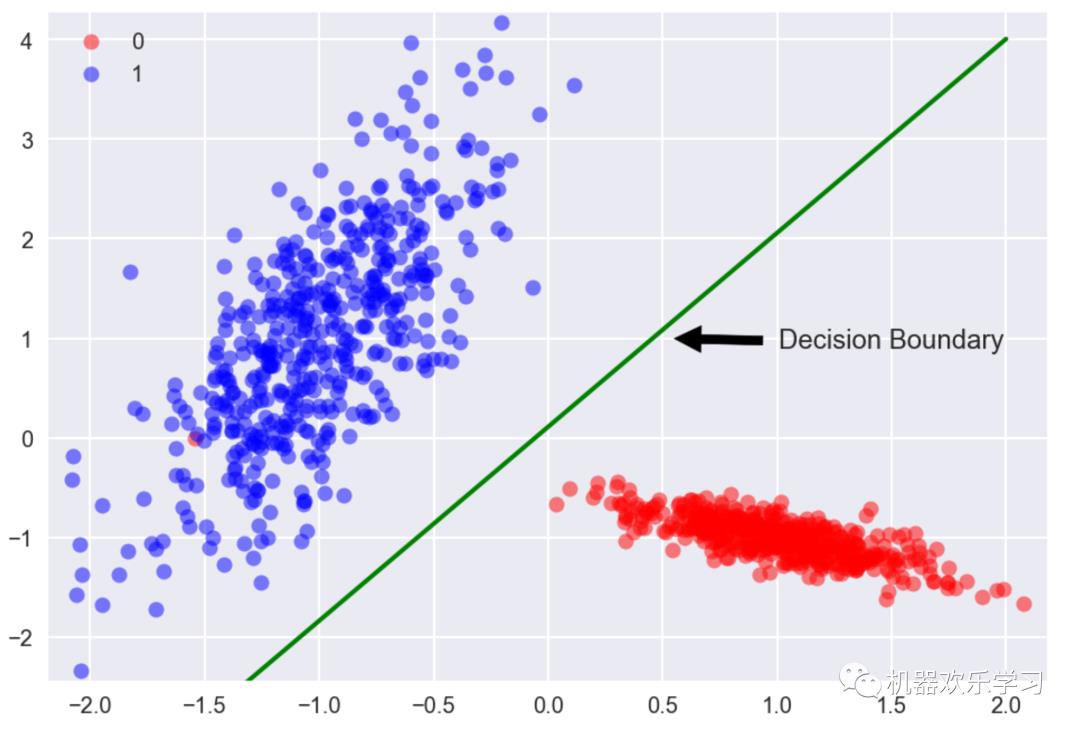
对应逻辑回归的
数据,就是上图中所有的点,
和相对应的颜色,我们假设有m个数据:
y我们认为只取1或者0,对应上图中的蓝色或者红色。相当于是分类问题,分成类1或者类0。
模型就是最佳的绿色的线。
在传统的机器学习分类问题上,我们把学习到的模型叫做超平面
。机器学习中,可以将
模型分解成抽象模型和模型学习到的参数。逻辑回归的抽象模型就是:
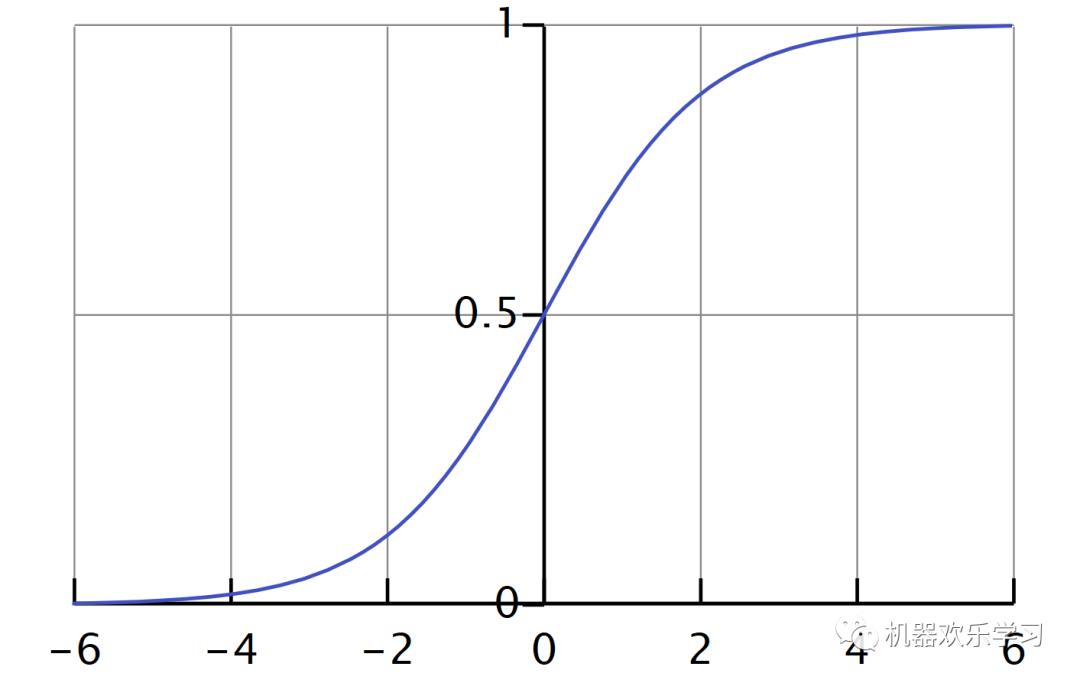
特征就是 我们输入一个新的x,通过学习到的θ,通过加权求和再放入sigmiod函数后,就能得到提取的特征h。我们设置阈值为0.5,如果h<0.5我们就认为y=0,如果h>=0.5,我们就认为y=1。相当于说,
sigmoid函数将一个回归的问题变成了分类的问题。
这里我们可以看到:数据,模型,特征,三者本身都是高维向量,特别是,
模型本身就是抽象的模型+模型参数,数据和模型参数按照抽象的模型进行数学运算得到特征。与此同时,逻辑回归和线性回归的唯一区别就是,
逻辑回归将线性回归得到的y放入sigmoid函数中,将得到的特征用于分类。
学习就是一个降低模型对数据的误差的过程。我们用模型得到的特征和真实特征的误差做一个对比,来描述模型的糟糕程度。
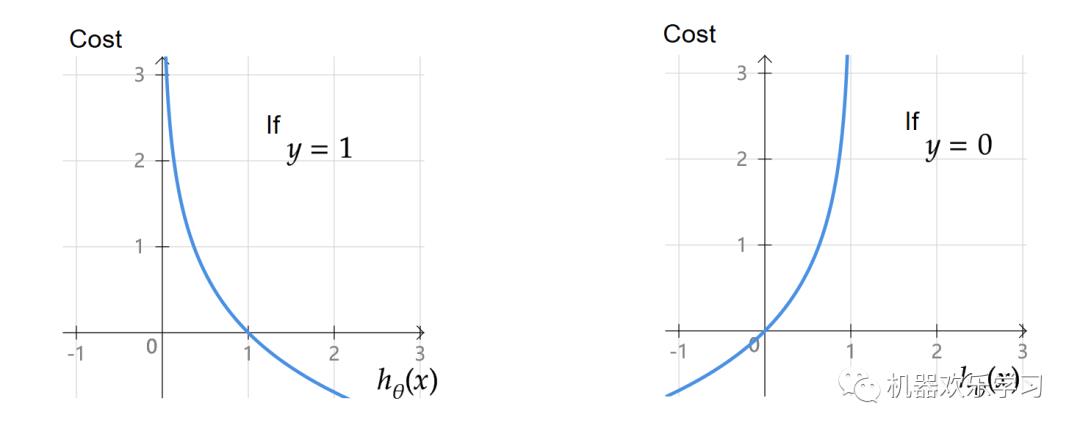
其中x表示第i个训练数据的输入,y表示第i个训练数据的真实输出(分类结果)。通过这两个函数图像我们可以看出,当数据的真实输出为1时(y=1),如果模型预测得越靠近0,误差越大,
如果模型预测得越靠近1,
误差越小。反之亦反。
将两个公式合在一起,我们就可以得到大鼎鼎的交叉熵损失函数:
这里我们继续强调一下:
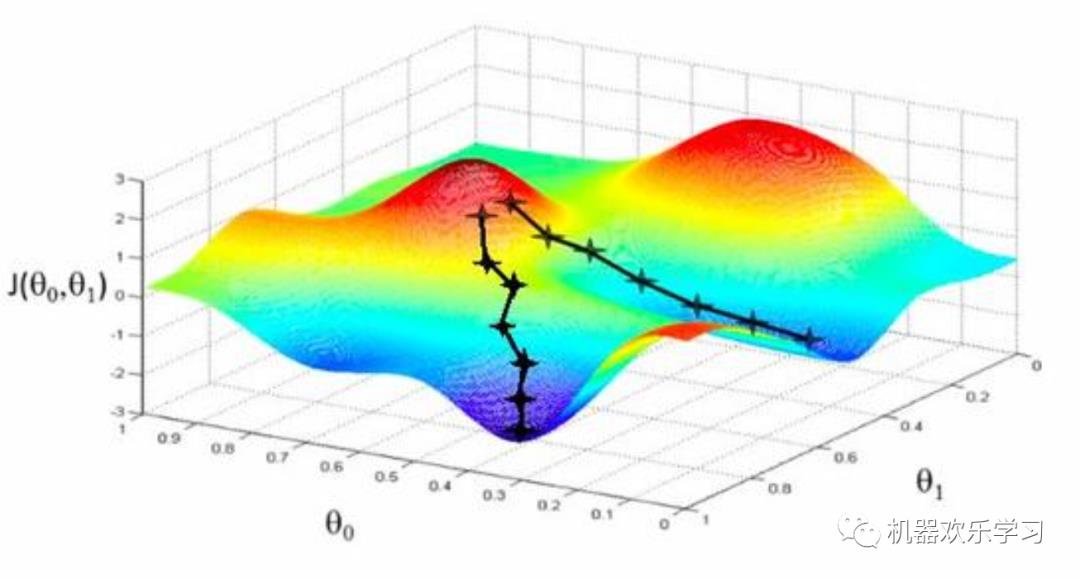
机器究竟如何学习?有了损失函数,我们就可以用梯度下降算法,优化该模型了。梯度下降法是一种迭代优化算法,用于寻找损失函数的最小值。为了用梯度下降法求函数的极小值,我们把与函数在当前点
梯度的负值作为搜索方向。当得到模型的最小值得时候,我们就认为模型最不糟糕。
其中α是学习率,表示每次要学习多少参数的导数。公式二表示,当每次梯度下降都使用批量(batch)的训练数据时,学习的公式。
也就是说,本质上机器怎么学习:
就是用数据与算法让模型的参数更新,使模型的参数对观测数据的误差更小,这样我们就认为,模型对数据的拟合能力更强,从而能泛化未来未知的数据。
当我们基本了解了逻辑回归模型后。这里我们在更深入的了解一下逻辑回归模型。
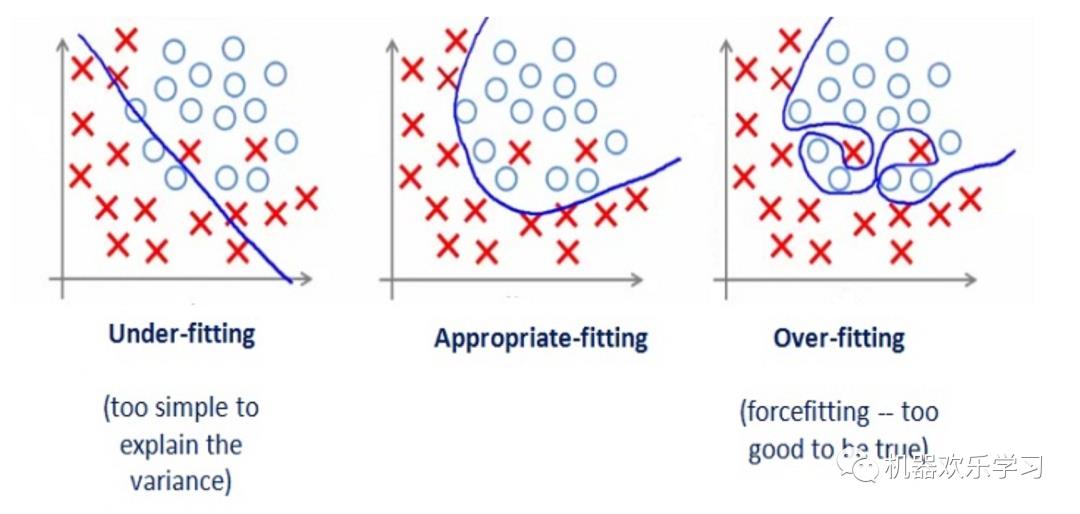
如果我们有太多的特征,学习的参数模型可能很适合训练集:
但它
很
可
能无法预测到
新的例子,比如下图分别表示和欠拟合,恰拟合和过拟合
。
正则化中我们将保留所有的特征变量,但是会减小特征变量的数量级(参数数值的大小θ(j))。这个方法非常有效,当我们有很多特征变量时,其中每一个变量都能对预测产生一点影响。
下面才是今天真正的硬核知识。大家有什么想过,逻辑回归的本质是什么,为什么非要用sigmoid,为什么非要用交叉熵损失函数?
这是一个面试的常考题,之所以常考,是因为这个问题是天坑,直接回答是线性还是非线性都是不准确的。逻辑回归从定义上讲是
广义线性模型。
逻辑回归引入了sigmoid函数映射,是非线性模型,但本质上又是一个线性回归模型,因为除去sigmoid映射函数关系,其他的步骤,算法都是线性回归的。
可以说,逻辑回归,都是以线性回归为理论支持的。而作为一个机器学习模型,逻辑回归是线性模型,即x的任何一维都只被单一学习参数所约束,导致它的决策边界是线性的。所以究竟是线性还是非线性呢?它是广义线性模型。下面公式推到了逻辑回归的决策平面。
为什么逻辑回归非要用sigmoid函数?这其实是一个比较难解释的问题。
熵是信息理论中的概念,用在概率分布上可以表示这个分布中所包含的不确定度,熵越大不确定度越大。而我们现在关心的是,给定某些假设之后,熵最大的分布。也就是说这个分布应该在满足我假设的前提下越混乱越均匀越好。
回过来看logistic regression,这里假设了什么呢?首先,我们在建模预测Y|X,并认为 Y|X 服从伯努利分布,所以我们只需要知道 P(Y|X);其次我们需要一个线性模型,所以 P(Y|X) = f(wx)。而通过最大熵原则推出的这个f,就是sigmoid。其实伯努利的指数族形式,也即sigmoid。
生物学与电学:生物受到刺激后,电信号感知会如同单位跃迁函数一样传递。而sigmoid函数是处处可导的最像单位跃迁的函数。
数学:基于Stone-Weierstrass定理和KST。有兴趣的大佬可以看一下参考文献[2]。
交叉熵损失函数本质上预测二分类时的相对熵[3]。与此同时,逻辑回归的对数似然函数最大化也等价交叉熵损失函数。
五.小结
今天是机器学习的第二讲,我们讲述了非常简单又非常常用的逻辑回归模型和一些的机器学习知识和思想。大家如果还想做一下关于逻辑回归的相关实验的话,可以在公众号后台回复“逻辑回归实验”鸭~~
-
https://vas3k.ru/blog/machine_learning/
-
Kolmogorov's Theorem and Multilayer Neural Networks
-
https://zhuanlan.zhihu.com/p/70804197
以上是关于最常用的机器学习模型竟然是它?!的主要内容,如果未能解决你的问题,请参考以下文章