文本挖掘|真正“读懂”数据,让数据分析得心应手
Posted 海量大数据分析平台官方号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了文本挖掘|真正“读懂”数据,让数据分析得心应手相关的知识,希望对你有一定的参考价值。
文本挖掘指的是从文本数据中获取有价值的信息和知识,它是数据挖掘的一种方法,也是自然语言处理的一个分支。
自然语言处理(英语:natural language processing,缩写作 NLP)是人工智能和语言学领域的分支学科。自然语言认知则是指让电脑“懂”人类的语言。自然语言生成系统把计算机数据转化为自然语言。自然语言理解系统把自然语言转化为计算机程序更易于处理的形式。
文本挖掘技术层次结构
文本挖掘与分词密不可分,中文分词技术是自然语言处理技术的基础,是将连续的字序列按照一定的规范重新组合成词序列的过程。分词是文本挖掘过程中的处理环节。
海量的中文分词

命名实体识别

篇章特征
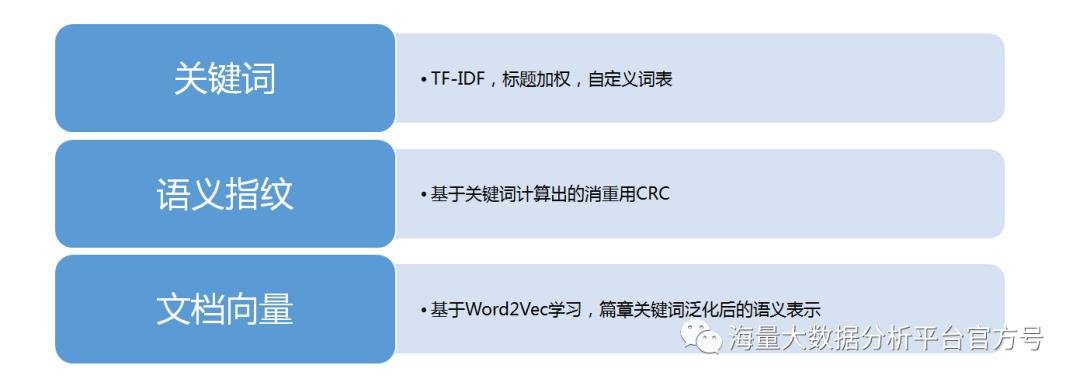
篇章分析

分词使用是为了使结果数据产生数据标签

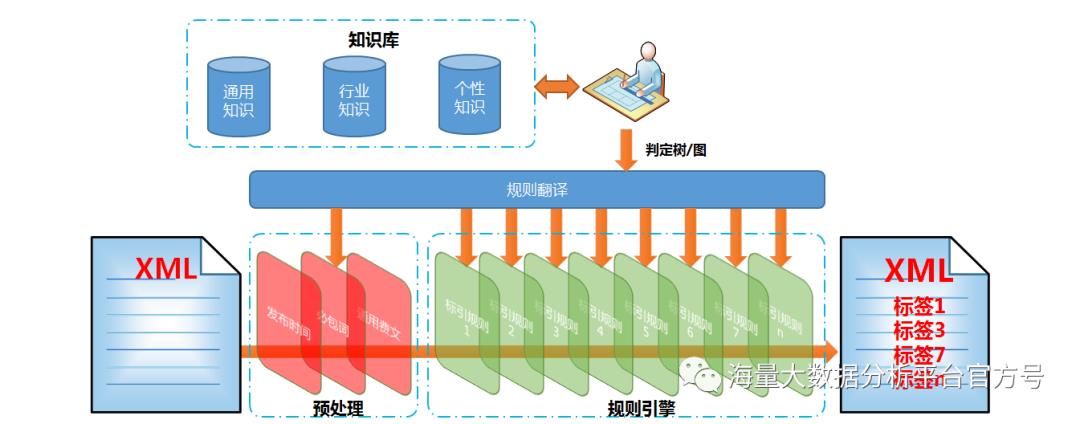
文本挖掘的基本原理
通过文本挖掘,实现文本数据结构化,使得文本数据可被计算分析。
通过文本挖掘,从纷杂的文本中过滤掉无用信息,筛选出有用的数据。
文本挖掘会让数据分析价值更直观,更具说服力和可视性!



0
1
多维度数据来源

可外接全类型线下数据
百亿级历史积累,随时获取历史信息
全网10万+网站、主流社交媒体 、主流行业、家电商网站数据秒级更新
可外接全类型线下数据
百亿级历史积累,随时获取历史信息
全网10万+网站、主流社交媒体 、主流行业、家电商网站数据秒级更新
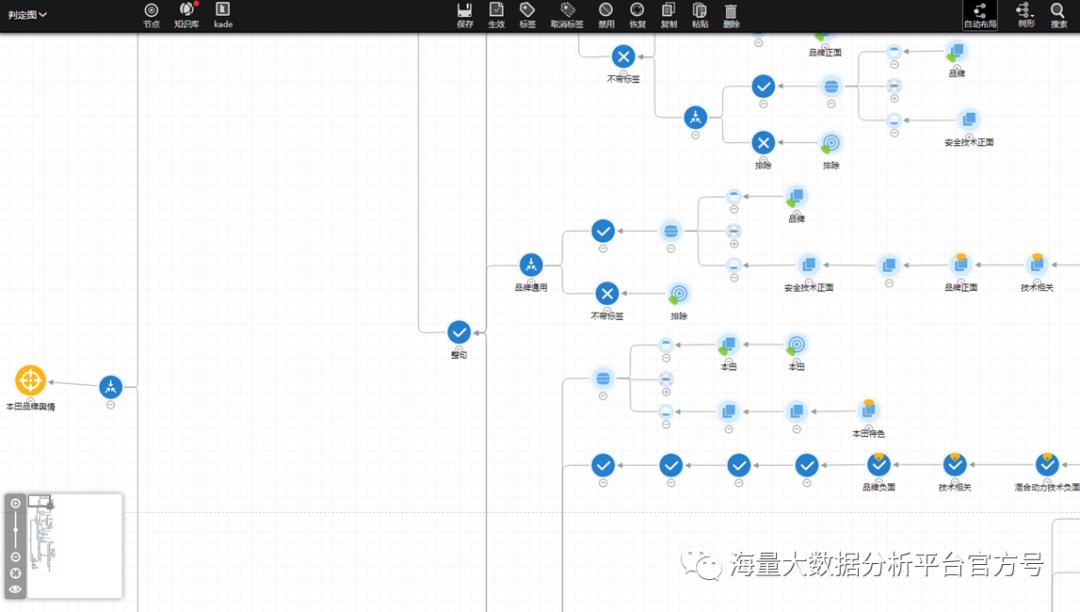
自由定制个性化判定逻辑及数据标签
单个任务的标签嵌套层级无限制、支持标签数量至少1万+
如:品牌/产品/高管的声量、正负面舆情、消费者评价分析、用户画像快速构建、评论内容情绪分析、情感分析等
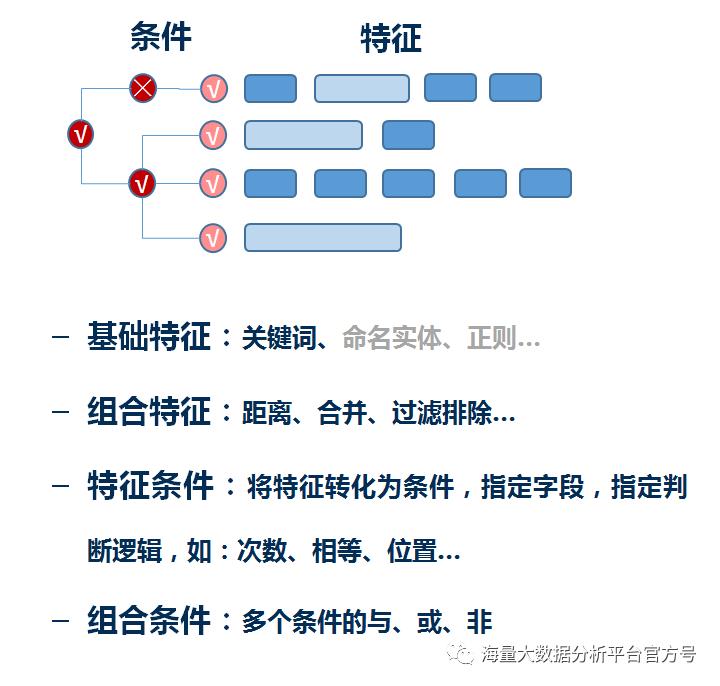
内容判定:与或非、并集、交集、次序、频次、分词排歧、修饰排除(否定、疑问、前后紧邻)、正则匹配等
实体识别:人名、地名、机构、联系方式、时间、数量等
数字/时间运算:大于、小于、等于、区间等
通用知识库:情绪态度、企业知识、政府舆情、人物、废文、事件、违法、广告、敏感等
行业知识库:共涉及汽车、快消、家电3c、母婴、个人护理、食品、乳制品等100多个行业知识库
如何为文本数据打上丰富的业务分类标签,是文本大数据分析的重要基础工作,分析师可以在多维数据标签的基础上进行高复杂性的分类与统计,从结果中洞察业务趋势及可能存在的问题。
按照客户的定制逻辑,结合多维度高复杂的运算方式和海量知识库,对数据内容进行多层级的标签标注,为大数据分析提供基础数据,便于敏锐洞悉背后的深层含义。
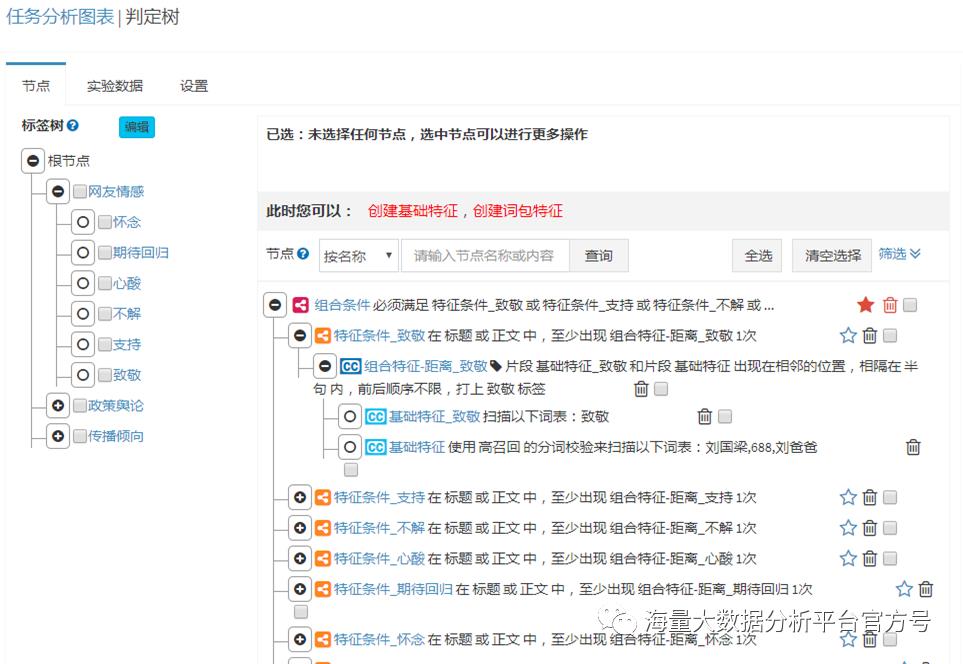
自然语言非结构化的问题对数据的分类、加工及分析带来了非常大困难,而文本信息抽取可以从自然语言文本中抽取出特定的数据信息,帮助数据应用者将海量内容自动分类、提取和重构。
从自然语言文本中,抽取出特定的事件或信息,将非结构化的文本内容变成结构化的数据,将信息内容自动分类、提取和重构,应用于信息检索、智能问答、智能对话等各类人工智能产品。
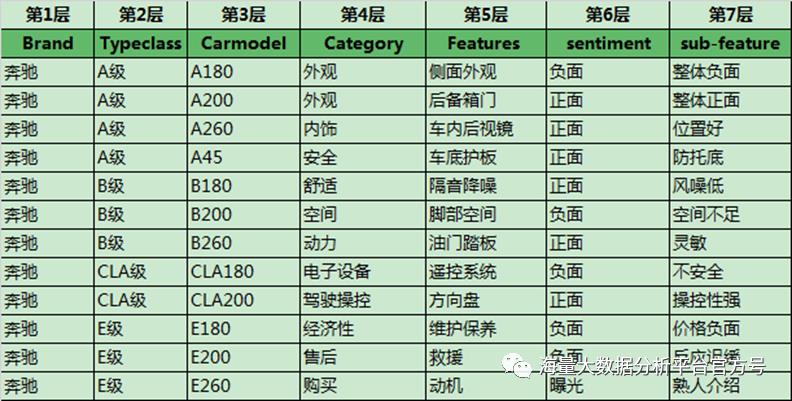
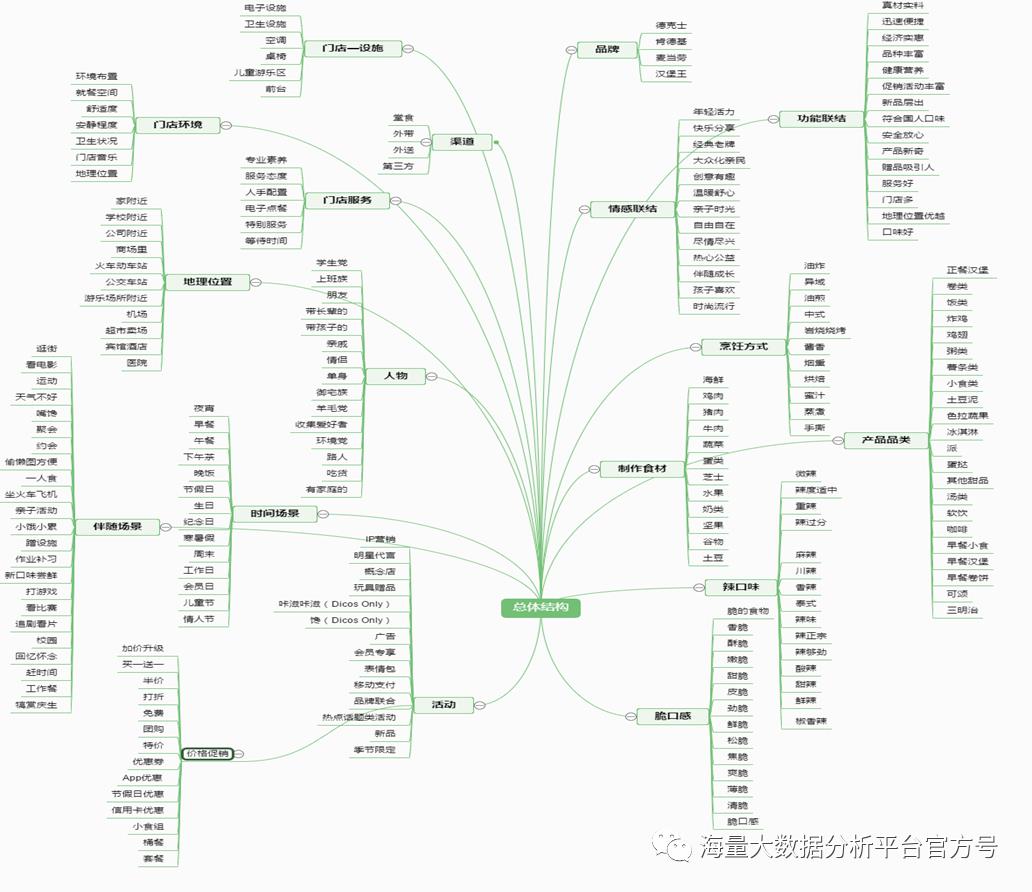
社会化媒体分析-汽车行业
互联网信息多样且夹杂着违法、违规、广告、灌水等垃圾信息,会给网站的运营带来风险,也会给大数据分析的精准度带来影响。可见,垃圾信息的清洗对网站的运营及数据分析至关重要。
一是提供网站内容净化服务,对网站互动栏目中的违法广告、违规广告、色情广告、灌水广告等进行自动识别,降低网站运营风险;
二是对大数据中的垃圾信息进行过滤,避免对分析结果的精准性产生影响。
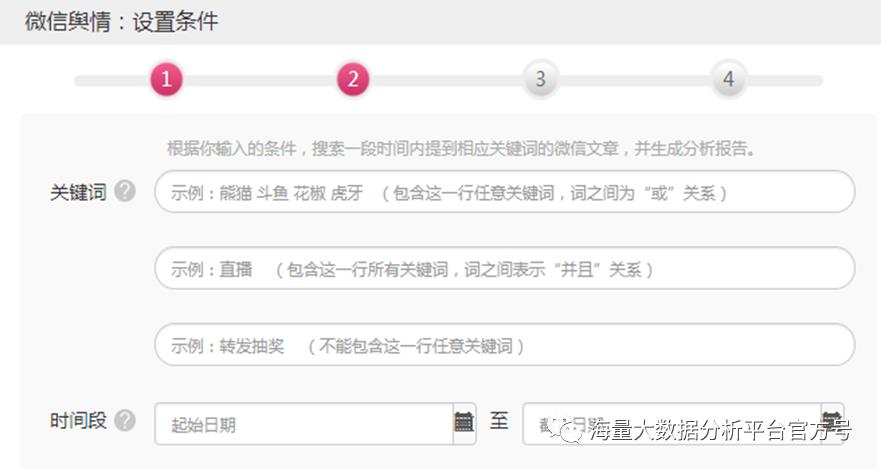
常见舆情产品监测条件设置
文本挖掘已经是一项相当成熟的技术。对企业而言,每天都在产生大量不同形式的数据,通过用文本挖掘技术进行归类、整理和分析,不但可以节省大量人力成本,还能帮助企业提升运营效率。
另外,还可以利用文本挖掘的结果做更深入的利用,如智能数据监控系统等。也可以打造出具有针对性的行业文本数据产品,专门服务于不同领域。
END
点击下方”阅读原文“开启1对1预约咨询。
精彩案例
产品&技术
以上是关于文本挖掘|真正“读懂”数据,让数据分析得心应手的主要内容,如果未能解决你的问题,请参考以下文章