4万字全面掌握数据库, 数据仓库, 数据集市,数据湖,数据中台
Posted 数据社
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了4万字全面掌握数据库, 数据仓库, 数据集市,数据湖,数据中台相关的知识,希望对你有一定的参考价值。
如今,随着诸如互联网以及物联网等技术的不断发展,越来越多的数据被生产出来-据统计,每天大约有超过2.5亿亿字节的各种各样数据产生。这些数据需要被存储起来并且能够被方便的分析和利用。
随着大数据技术的不断更新和迭代,数据管理工具得到了飞速的发展,相关概念如雨后春笋一般应运而生,如从最初决策支持系统(DSS)到商业智能(BI)、数据仓库、数据湖、数据中台等,这些概念特别容易混淆,本文对这些名词术语及内涵进行系统的解析,便于读者对数据平台相关的概念有全面的认识。
数据仓库就是为了解决数据库不能解决的问题而提出的。那么数据库无法解决什么样的问题呢?这个我们得先说说什么是OLAP和OLTP。
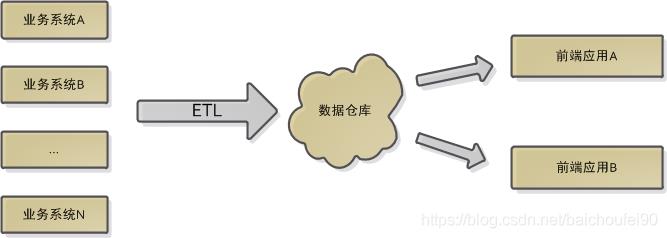
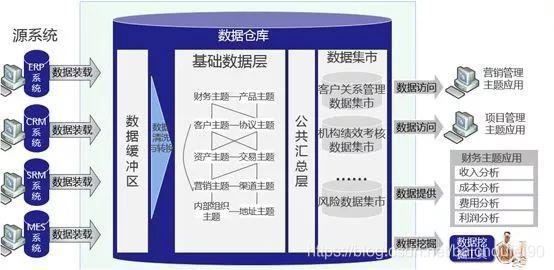
数据仓库的核心组件有四个:业务系统各源数据库,ETL,数据仓库,前端应用。如下图所示:
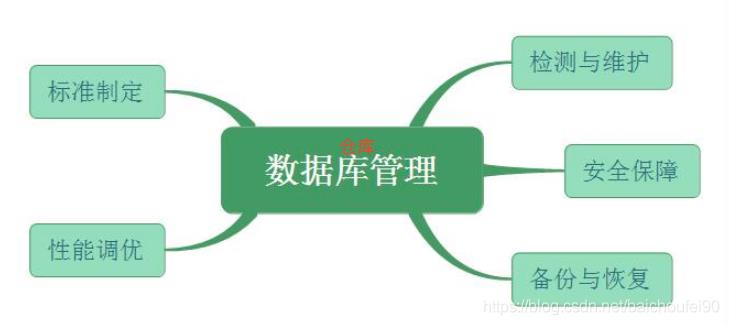
数据仓库系统发行后,控制权便从数据仓库设计、实现、部署的团队移交给了数据仓库管理员,并由他们来对系统进行管理,涵盖了确保一个已经部署的数据仓库系统正确运行的各种行为。为了实现这一目标,具体包含以下范畴:
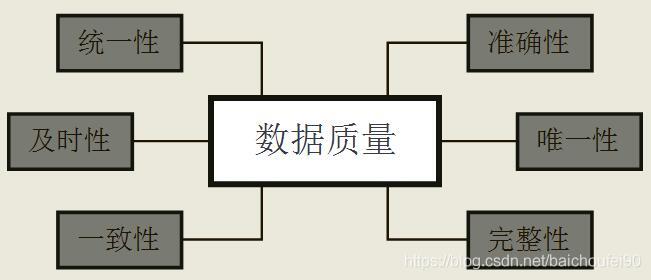
数据仓库系统需要重视数据质量问题。用一句话概括,数据质量就是衡量数据能否真实、及时反映客观世界的指标。具体来说,数据质量包含以下几大指标:
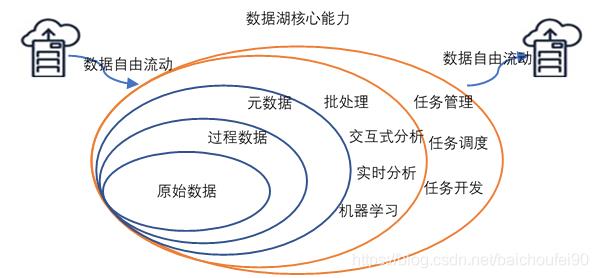
Pentaho首席技术官James Dixon创造了“数据湖”一词。它把数据集市描述成一瓶水(清洗过的,包装过的和结构化易于使用的)。
而数据湖更像是在自然状态下的水,数据流从源系统流向这个湖。用户可以在数据湖里校验,取样或完全的使用数据。
这个也是一个不精确的定义。数据湖还有以下特点:
从源系统导入所有的数据,没有数据流失。
数据存储时没有经过转换或只是简单的处理。
数据转换和定义schema 用于满足分析需求。
数据湖为什么叫数据湖而不叫数据河或者数据海?一个有意思的回答是:
“河”强调的是流动性,“海纳百川”,河终究是要流入大海的,而企业级数据是需要长期沉淀的,因此叫“湖”比叫“河”要贴切;
同时,湖水天然是分层的,满足不同的生态系统要求,这与企业建设统一数据中心,存放管理数据的需求是一致的,“热”数据在上层,方便应用随时使用;温数据、冷数据位于数据中心不同的存储介质中,达到数据存储容量与成本的平衡。
不叫“海”的原因在于,海是无边无界的,而“湖”是有边界的,这个边界就是企业/组织的业务边界;因此数据湖需要更多的数据管理和权限管理能力。
叫“湖”的另一个重要原因是数据湖是需要精细治理的,一个缺乏管控、缺乏治理的数据湖最终会退化为“数据沼泽”,从而使应用无法有效访问数据,使存于其中的数据失去价值。
数据湖能给企业带来多种能力,例如,能实现数据的集中式管理,在此之上,企业能挖掘出很多之前所不具备的能力。
另外,数据湖结合先进的数据科学与机器学习技术,能帮助企业构建更多优化后的运营模型,也能为企业提供其他能力,如预测分析、推荐模型等,这些模型能刺激企业能力的后续增长。数据湖能从以下方面帮助到企业:
实现数据治理(data governance);
通过应用机器学习与人工智能技术实现商业智能;
预测分析,如领域特定的推荐引擎;
信息追踪与一致性保障;
根据对历史的分析生成新的数据维度;
有一个集中式的能存储所有企业数据的数据中心,有利于实现一个针对数据传输优化的数据服务;
帮助组织或企业做出更多灵活的关于企业增长的决策。


误解一:数据仓库和数据湖二者在架构上只能二选一 很多人认为数据仓库和数据湖在架构上只能二选一,其实这种理解是错误的。数据湖和数据仓库并不是对立关系,相反它们的并存可以互补给企业架构带来更多的好处:
数据仓库存储结构化的数据,适用于快速的BI和决策支撑,
而数据湖可以存储任何格式的数据,往往通过挖掘能够发挥出数据的更大作为。
所以在一些场景上二者的并存是可以给企业带来更多效益的。
误解二:相对于数据湖,数据仓库更有名更受欢迎 人工智能(AI)和机器学习项目的成功往往需要数据湖来做支撑。因为数据湖可让您存储几乎任何类型的数据而无需先准备或清理,所以可以保留尽可能多的潜在价值。而数据仓库存储的数据都是经过清洗,往往会丢失一些有价值的信息。
数据仓库虽然是这两种中比较知名的,但是随着数据挖掘需求的发展,数据湖的受欢迎程度可能会继续上升。数据仓库对于某些类型的工作负载和用例工作良好,而数据湖则是为其他类型的工作负载提供服务的另一种选择。
误解三:数据仓库易于使用,而数据湖却很复杂 确实,数据湖需要数据工程师和数据科学家的特定技能,才能对存储在其中的数据进行分类和利用。数据的非结构化性质使那些不完全了解数据湖如何工作的人更难以访问它。
但是,一旦数据科学家和数据工程师建立了数据模型或管道,业务用户就可以利用建立的数据模型以及流行的业务工具(定制或预先构建)的来访问和分析数据,而不在乎该数据存储在数据仓库中还是数据湖中。
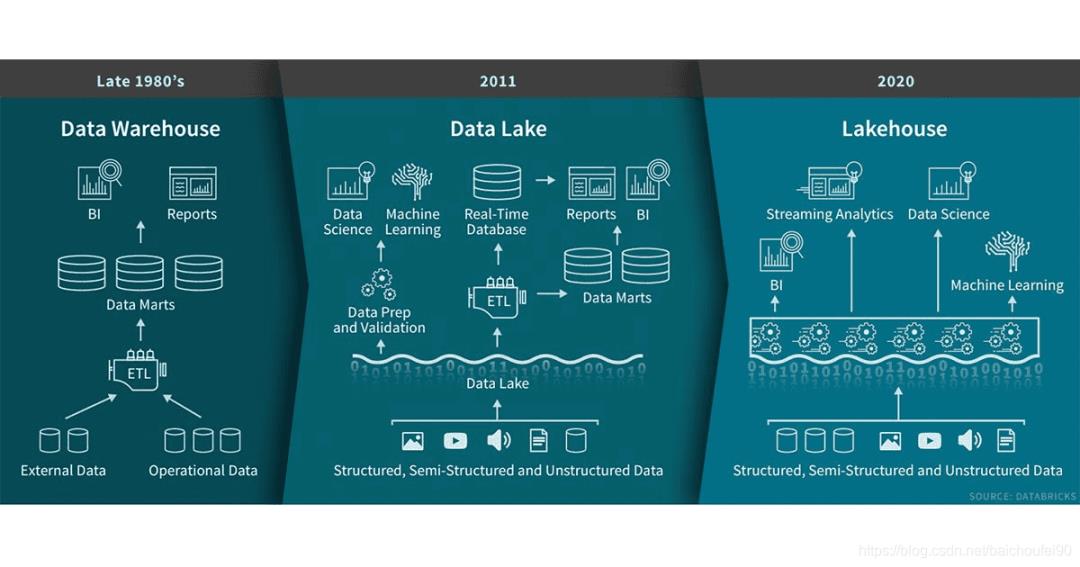
个人认为数据湖是比传统大数据平台更为完善的大数据处理基础支撑设施,完善在数据湖是更贴近客户业务的技术存在。所有数据湖所包括的、且超出大数据平台存在的特性,例如元数据、数据资产目录、权限管理、数据生命周期管理、数据集成和数据开发、数据治理和质量管理等,无一不是为了更好的贴近业务,更好的方便客户使用。数据湖所强调的一些基本的技术特性,例如弹性、存储计算独立扩展、统一的存储引擎、多模式计算引擎等等,也是为了满足业务需求,并且给业务方提供最具性价比的TCO。
数据湖的建设过程应该与业务紧密结合;但是数据湖的建设过程与传统的数据仓库,甚至是大热的数据中台应该是有所区别的。区别在于,数据湖应该以一种更敏捷的方式去构建,“边建边用,边用边治理”。为了更好的理解数据湖建设的敏捷性,我们先来看一下传统数仓的构建过程。业界对于传统数仓的构建提出了“自下而上”和“自顶而下”两种模式,分别由Inmon和KimBall两位大牛提出。具体的过程就不详述了,不然可以再写出几百页,这里只简单阐述基本思想。
1)Inmon提出自下而上(EDW-DM)的数据仓库建设模式,即操作型或事务型系统的数据源,通过ETL抽取转换和加载到数据仓库的ODS层;ODS层中的数据,根据预先设计好的EDW(企业级数据仓库)范式进行加工处理,然后进入到EDW。EDW一般是企业/组织的通用数据模型,不方便上层应用直接做数据分析;因此,各个业务部门会再次根据自己的需要,从EDW中处理出数据集市层(DM)。
优势:易于维护,高度集成;劣势:结构一旦确定,灵活性不足,且为了适应业务,部署周期较长。此类方式构造的数仓,适合于比较成熟稳定的业务,例如金融。
2)KimBall提出自顶而下(DM-DW)的数据架构,通过将操作型或事务型系统的数据源,抽取或加载到ODS层;然后通过ODS的数据,利用维度建模方法建设多维主题数据集市(DM)。各个DM,通过一致性的维度联系在一起,最终形成企业/组织通用的数据仓库。
优势:构建迅速,最快的看到投资回报率,敏捷灵活;劣势:作为企业资源不太好维护,结构复杂,数据集市集成困难。常应用于中小企业或互联网行业。
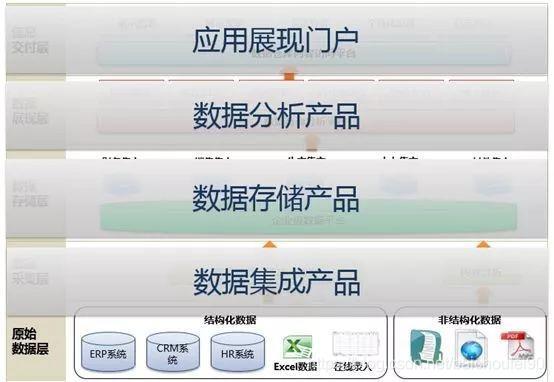
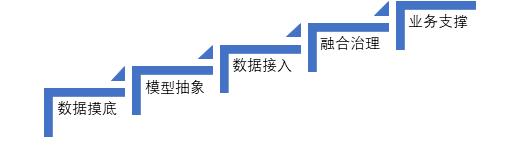
其实上述只是一个理论上的过程,其实无论是先构造EDW,还是先构造DM,都离不开对于数据的摸底,以及在数仓构建之前的数据模型的设计,包括当前大热的“数据中台”,都逃不出下图所示的基本建设过程。
数据中台是指通过企业内外部多源异构的数据采集、治理、建模、分析,应用,使数据对内优化管理提高业务,对外可以数据合作价值释放,成为企业数据资产管理中枢。数据中台建立后,会形成数据API,为企业和客户提供高效各种数据服务。
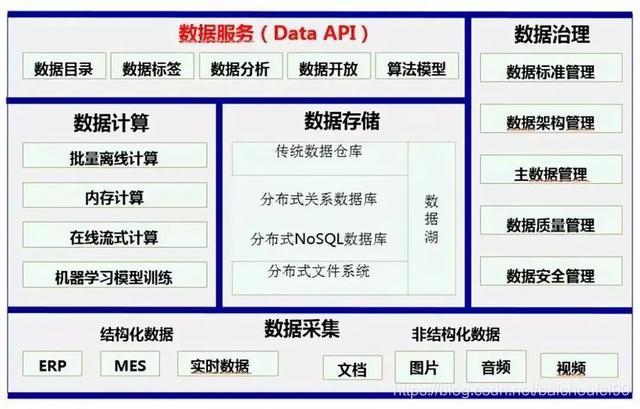
数据中台整体技术架构上采用云计算架构模式,将数据资源、计算资源、存储资源充分云化,并通过多租户技术进行资源打包整合,并进行开放,为用户提供“一站式”数据服务。
利用大数据技术,对海量数据进行统一采集、计算、存储,并使用统一的数据规范进行管理,将企业内部所有数据统一处理形成标准化数据,挖掘出对企业最有价值的数据,构建企业数据资产库,提供一致的、高可用大 数据服务。
数据中台不是一套软件,也不是一个信息系统,而是一系列数据组件的集合,企业基于自身的信息化建设基础、数据基础以及业务特点对数据中台的能力进行定义,基于能力定义利用数据组件搭建自己的数据中台。
数据中台对一个企业的数字化转型和可持续发展起着至关重要的作用。数据中台为解耦而生,企业建设数据中台的最大意义就是应用与数据解藕。这样企业就可以不受限制地按需构建满足业务需求的数据应用。
构建了开放、灵活、可扩展的企业级统一数据管理和分析平台, 将企业内、外部数据随需关联,打破了数据的系统界限。
利用大数据智能分析、数据可视化等技术,实现了数据共享、日常报表自动生成、快速和智能分析,满足集团总部和各分子公司各级数据分析应用需求。
深度挖掘数据价值,助力企业数字化转型落地。实现了数据的目录、模型、标准、认责、安全、可视化、共享等管理,实现数据集中存储、处理、分类与管理,建立大数据分析工具库、算法服务库,实现报表生成自动化、数据分析敏捷化、数据挖掘可视化,实现数据质量评估、落地管理流程。
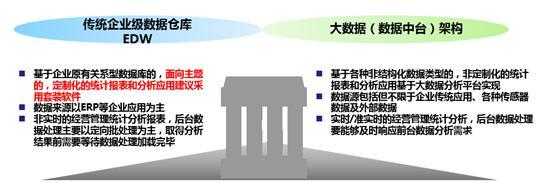
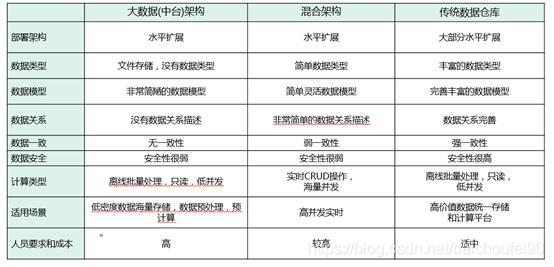
作为工业企业,一般采用混搭架构:

数据集市和数据仓库经常会被混淆,但两者的用途明显不同。
数据集市通常是数据仓库的子集;它等数据通常来自数据仓库 – 尽管还可以来自其他来源。数据集市的数据专门针对特定的用户社区(例如销售团队),以便他们能够快速找到所需的数据。通常,数据保存在那里用于特定用途,例如财务分析。
数据集市也比数据仓库小得多 – 它们可以容纳数十千兆字节,相比之下,数据仓库可以存储数百千兆字节到PB级数据,并可用于数据处理。
数据集市可从现有数据仓库或其他数据源系统构建,你只需设计和构建数据库表,使用相关数据填充数据库表并决定谁可以访问数据集即可。
操作数据存储(ODS)是一种数据库,用作所有原始数据的临时存储区域,这些数据即将进入数据仓库进行数据处理。我们可以将其想象成仓库装卸码头,货物在此处交付、检查和验证。在ODS中,数据在进入仓库前可以被清理、检查(因为冗余目的),也可检查是否符合业务规则。
在ODS中,我们可以对数据进行查询,但是数据是临时的,因此它仅提供简单信息查询,例如正在进行的客户订单状态。
ODS通常运行在关系数据库管理系统(RDBMS)或Hadoop平台。
数据仓库、数据湖与关系数据库系统之间的主要区别在于:
关系数据库用于存储和整理来自单个来源(例如事务系统)的结构化数据,
而数据仓库则用于存储来自多个来源的结构化数据。
数据湖的不同之处在于它可存储非结构化、半结构化和结构化数据。
关系数据库创建起来相对简单,可用于存储和整理实时数据,例如交易数据等。关系数据库的缺点是它们不支持非结构化数据库数据或现在不断生成的大量数据。这使得我们只能在数据仓库与数据湖间做出选择。尽管如此,很多企业仍然继续依赖关系数据库来完成运营数据分析或趋势分析等任务。
内部或云端可用的关系数据库包括Microsoft SQL Server、Oracle数据库、mysql和IBM Db2、以及Amazon Relational Database Service、Google Cloud Spanner等。
可参考
解读阿里巴巴集团的“大中台、小前台”组织战略
互联网中台重要性
What is a Lakehouse?
by Ben Lorica, Michael Armbrust, Ali Ghodsi, Reynold Xin and Matei Zaharia Posted in COMPANY BLOGJanuary 30, 2020
带你读《企业数据湖》之一:数据导论
带你读《企业数据湖》之二:数据湖概念概览
带你读《企业数据湖》之三:Lambda架构:一种数据湖实现模式
阿里云-什么是数据湖分析
历史好文推荐 从0到1搭建大数据平台之计算存储系统
从0到1搭建大数据平台之调度系统
从0到1搭建大数据平台之数据采集系统
如何从0到1搭建大数据平台

sql 新集市蜂巢脚本参数
以上是关于4万字全面掌握数据库, 数据仓库, 数据集市,数据湖,数据中台的主要内容,如果未能解决你的问题,请参考以下文章
数据仓库系统发行后,控制权便从数据仓库设计、实现、部署的团队移交给了数据仓库管理员,并由他们来对系统进行管理,涵盖了确保一个已经部署的数据仓库系统正确运行的各种行为。为了实现这一目标,具体包含以下范畴:
数据仓库系统需要重视数据质量问题。用一句话概括,数据质量就是衡量数据能否真实、及时反映客观世界的指标。具体来说,数据质量包含以下几大指标:
Pentaho首席技术官James Dixon创造了“数据湖”一词。它把数据集市描述成一瓶水(清洗过的,包装过的和结构化易于使用的)。
而数据湖更像是在自然状态下的水,数据流从源系统流向这个湖。用户可以在数据湖里校验,取样或完全的使用数据。
这个也是一个不精确的定义。数据湖还有以下特点:
从源系统导入所有的数据,没有数据流失。
数据存储时没有经过转换或只是简单的处理。
数据转换和定义schema 用于满足分析需求。
数据湖为什么叫数据湖而不叫数据河或者数据海?一个有意思的回答是:
“河”强调的是流动性,“海纳百川”,河终究是要流入大海的,而企业级数据是需要长期沉淀的,因此叫“湖”比叫“河”要贴切;
同时,湖水天然是分层的,满足不同的生态系统要求,这与企业建设统一数据中心,存放管理数据的需求是一致的,“热”数据在上层,方便应用随时使用;温数据、冷数据位于数据中心不同的存储介质中,达到数据存储容量与成本的平衡。
不叫“海”的原因在于,海是无边无界的,而“湖”是有边界的,这个边界就是企业/组织的业务边界;因此数据湖需要更多的数据管理和权限管理能力。
叫“湖”的另一个重要原因是数据湖是需要精细治理的,一个缺乏管控、缺乏治理的数据湖最终会退化为“数据沼泽”,从而使应用无法有效访问数据,使存于其中的数据失去价值。
数据湖能给企业带来多种能力,例如,能实现数据的集中式管理,在此之上,企业能挖掘出很多之前所不具备的能力。
另外,数据湖结合先进的数据科学与机器学习技术,能帮助企业构建更多优化后的运营模型,也能为企业提供其他能力,如预测分析、推荐模型等,这些模型能刺激企业能力的后续增长。数据湖能从以下方面帮助到企业:
实现数据治理(data governance);
通过应用机器学习与人工智能技术实现商业智能;
预测分析,如领域特定的推荐引擎;
信息追踪与一致性保障;
根据对历史的分析生成新的数据维度;
有一个集中式的能存储所有企业数据的数据中心,有利于实现一个针对数据传输优化的数据服务;
帮助组织或企业做出更多灵活的关于企业增长的决策。
很多人认为数据仓库和数据湖在架构上只能二选一,其实这种理解是错误的。数据湖和数据仓库并不是对立关系,相反它们的并存可以互补给企业架构带来更多的好处:
数据仓库存储结构化的数据,适用于快速的BI和决策支撑,
而数据湖可以存储任何格式的数据,往往通过挖掘能够发挥出数据的更大作为。
所以在一些场景上二者的并存是可以给企业带来更多效益的。
人工智能(AI)和机器学习项目的成功往往需要数据湖来做支撑。因为数据湖可让您存储几乎任何类型的数据而无需先准备或清理,所以可以保留尽可能多的潜在价值。而数据仓库存储的数据都是经过清洗,往往会丢失一些有价值的信息。
数据仓库虽然是这两种中比较知名的,但是随着数据挖掘需求的发展,数据湖的受欢迎程度可能会继续上升。数据仓库对于某些类型的工作负载和用例工作良好,而数据湖则是为其他类型的工作负载提供服务的另一种选择。
确实,数据湖需要数据工程师和数据科学家的特定技能,才能对存储在其中的数据进行分类和利用。数据的非结构化性质使那些不完全了解数据湖如何工作的人更难以访问它。
但是,一旦数据科学家和数据工程师建立了数据模型或管道,业务用户就可以利用建立的数据模型以及流行的业务工具(定制或预先构建)的来访问和分析数据,而不在乎该数据存储在数据仓库中还是数据湖中。
个人认为数据湖是比传统大数据平台更为完善的大数据处理基础支撑设施,完善在数据湖是更贴近客户业务的技术存在。所有数据湖所包括的、且超出大数据平台存在的特性,例如元数据、数据资产目录、权限管理、数据生命周期管理、数据集成和数据开发、数据治理和质量管理等,无一不是为了更好的贴近业务,更好的方便客户使用。数据湖所强调的一些基本的技术特性,例如弹性、存储计算独立扩展、统一的存储引擎、多模式计算引擎等等,也是为了满足业务需求,并且给业务方提供最具性价比的TCO。
数据湖的建设过程应该与业务紧密结合;但是数据湖的建设过程与传统的数据仓库,甚至是大热的数据中台应该是有所区别的。区别在于,数据湖应该以一种更敏捷的方式去构建,“边建边用,边用边治理”。为了更好的理解数据湖建设的敏捷性,我们先来看一下传统数仓的构建过程。业界对于传统数仓的构建提出了“自下而上”和“自顶而下”两种模式,分别由Inmon和KimBall两位大牛提出。具体的过程就不详述了,不然可以再写出几百页,这里只简单阐述基本思想。
1)Inmon提出自下而上(EDW-DM)的数据仓库建设模式,即操作型或事务型系统的数据源,通过ETL抽取转换和加载到数据仓库的ODS层;ODS层中的数据,根据预先设计好的EDW(企业级数据仓库)范式进行加工处理,然后进入到EDW。EDW一般是企业/组织的通用数据模型,不方便上层应用直接做数据分析;因此,各个业务部门会再次根据自己的需要,从EDW中处理出数据集市层(DM)。
优势:易于维护,高度集成;劣势:结构一旦确定,灵活性不足,且为了适应业务,部署周期较长。此类方式构造的数仓,适合于比较成熟稳定的业务,例如金融。
2)KimBall提出自顶而下(DM-DW)的数据架构,通过将操作型或事务型系统的数据源,抽取或加载到ODS层;然后通过ODS的数据,利用维度建模方法建设多维主题数据集市(DM)。各个DM,通过一致性的维度联系在一起,最终形成企业/组织通用的数据仓库。
优势:构建迅速,最快的看到投资回报率,敏捷灵活;劣势:作为企业资源不太好维护,结构复杂,数据集市集成困难。常应用于中小企业或互联网行业。
其实上述只是一个理论上的过程,其实无论是先构造EDW,还是先构造DM,都离不开对于数据的摸底,以及在数仓构建之前的数据模型的设计,包括当前大热的“数据中台”,都逃不出下图所示的基本建设过程。
数据中台是指通过企业内外部多源异构的数据采集、治理、建模、分析,应用,使数据对内优化管理提高业务,对外可以数据合作价值释放,成为企业数据资产管理中枢。数据中台建立后,会形成数据API,为企业和客户提供高效各种数据服务。
数据中台整体技术架构上采用云计算架构模式,将数据资源、计算资源、存储资源充分云化,并通过多租户技术进行资源打包整合,并进行开放,为用户提供“一站式”数据服务。
利用大数据技术,对海量数据进行统一采集、计算、存储,并使用统一的数据规范进行管理,将企业内部所有数据统一处理形成标准化数据,挖掘出对企业最有价值的数据,构建企业数据资产库,提供一致的、高可用大 数据服务。
数据中台不是一套软件,也不是一个信息系统,而是一系列数据组件的集合,企业基于自身的信息化建设基础、数据基础以及业务特点对数据中台的能力进行定义,基于能力定义利用数据组件搭建自己的数据中台。
数据中台对一个企业的数字化转型和可持续发展起着至关重要的作用。数据中台为解耦而生,企业建设数据中台的最大意义就是应用与数据解藕。这样企业就可以不受限制地按需构建满足业务需求的数据应用。
构建了开放、灵活、可扩展的企业级统一数据管理和分析平台, 将企业内、外部数据随需关联,打破了数据的系统界限。
利用大数据智能分析、数据可视化等技术,实现了数据共享、日常报表自动生成、快速和智能分析,满足集团总部和各分子公司各级数据分析应用需求。
深度挖掘数据价值,助力企业数字化转型落地。实现了数据的目录、模型、标准、认责、安全、可视化、共享等管理,实现数据集中存储、处理、分类与管理,建立大数据分析工具库、算法服务库,实现报表生成自动化、数据分析敏捷化、数据挖掘可视化,实现数据质量评估、落地管理流程。
作为工业企业,一般采用混搭架构:
数据集市和数据仓库经常会被混淆,但两者的用途明显不同。
数据集市通常是数据仓库的子集;它等数据通常来自数据仓库 – 尽管还可以来自其他来源。数据集市的数据专门针对特定的用户社区(例如销售团队),以便他们能够快速找到所需的数据。通常,数据保存在那里用于特定用途,例如财务分析。
数据集市也比数据仓库小得多 – 它们可以容纳数十千兆字节,相比之下,数据仓库可以存储数百千兆字节到PB级数据,并可用于数据处理。
数据集市可从现有数据仓库或其他数据源系统构建,你只需设计和构建数据库表,使用相关数据填充数据库表并决定谁可以访问数据集即可。
操作数据存储(ODS)是一种数据库,用作所有原始数据的临时存储区域,这些数据即将进入数据仓库进行数据处理。我们可以将其想象成仓库装卸码头,货物在此处交付、检查和验证。在ODS中,数据在进入仓库前可以被清理、检查(因为冗余目的),也可检查是否符合业务规则。
在ODS中,我们可以对数据进行查询,但是数据是临时的,因此它仅提供简单信息查询,例如正在进行的客户订单状态。
ODS通常运行在关系数据库管理系统(RDBMS)或Hadoop平台。
数据仓库、数据湖与关系数据库系统之间的主要区别在于:
关系数据库用于存储和整理来自单个来源(例如事务系统)的结构化数据,
而数据仓库则用于存储来自多个来源的结构化数据。
数据湖的不同之处在于它可存储非结构化、半结构化和结构化数据。
关系数据库创建起来相对简单,可用于存储和整理实时数据,例如交易数据等。关系数据库的缺点是它们不支持非结构化数据库数据或现在不断生成的大量数据。这使得我们只能在数据仓库与数据湖间做出选择。尽管如此,很多企业仍然继续依赖关系数据库来完成运营数据分析或趋势分析等任务。
内部或云端可用的关系数据库包括Microsoft SQL Server、Oracle数据库、mysql和IBM Db2、以及Amazon Relational Database Service、Google Cloud Spanner等。
可参考
解读阿里巴巴集团的“大中台、小前台”组织战略
互联网中台重要性
What is a Lakehouse? by Ben Lorica, Michael Armbrust, Ali Ghodsi, Reynold Xin and Matei Zaharia Posted in COMPANY BLOGJanuary 30, 2020
带你读《企业数据湖》之一:数据导论
带你读《企业数据湖》之二:数据湖概念概览
带你读《企业数据湖》之三:Lambda架构:一种数据湖实现模式
阿里云-什么是数据湖分析
从0到1搭建大数据平台之计算存储系统
从0到1搭建大数据平台之调度系统
从0到1搭建大数据平台之数据采集系统
如何从0到1搭建大数据平台