万字长文助你上手软件领域驱动设计 DDD
Posted 腾讯技术工程
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了万字长文助你上手软件领域驱动设计 DDD相关的知识,希望对你有一定的参考价值。

作者:faryrong,腾讯 CSIG 后台开发工程师
在聚合边界内保护业务规则不变性。最近看了一本书《解构-领域驱动设计》,书中提出了领域驱动设计统一过程(DDDRUP),它指明了实践 DDD 的具体步骤,并很好地串联了各种概念、模式和思想。因此,我对书本内容做了梳理、简化,融入自己的理解,并结合之前阅读的书籍以及实践经验,最终形成这篇文章。希望可以帮助大伙理顺 DDD 的各种概念、模式和思想,降低上手 DDD 的门槛。
法则 1 包含了两个关键点:a) 参与维护业务规则不变性的领域概念应该置于同一个聚合内;b) 在任何情况下都要保护业务规则不变性。比如,在 sms 系统中分数和绩点具有转换关系,这是业务规则的不变性,因此这两个概念被放在了同一个聚合边界内;当出现老师修改分数的场景时,需要保证绩点的换算同时被执行。由于这里绩点对象是值对象,不需要关心其生命周期管理的问题。当业务规则涉及到多个实体时,就需要通过本地事务来保证规则不变性(即实体间基于业务规则的数据一致性)。
法则 3 通过身份标识符关联其他聚合。
注意这里强调了关联关系,关联关系会涉及聚合 A 对聚合 B 的生命周期管理的问题,对于这种聚合间的关联关系,我们通过身份标识建立关联。而当聚合 A 引用聚合 B,但不需要对聚合 B 进行生命周期管理时,我们认为这是一种依赖关系(比如方法中的入参,而非类中的属性),对于聚合间的依赖关系,我们可以通过对象引用(聚合根实体的引用)的方式建立依赖。(PS:假设设计之初难以判断聚合之间到底是关联关系,还是依赖关系,我们就统一使用身份标识符作为关系引用即可)
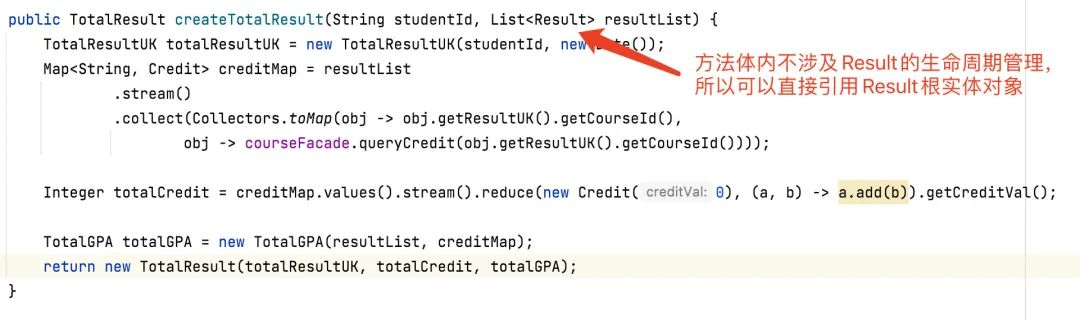
聚合间的依赖关系通常分为两种方式
7.3.2.2 设计步骤
1. 理顺对象图
分析对象是实体还是值对象。
2. 分解关系薄弱处
聚合本质是一个高内聚的边界,因此我们可以根据领域对象之间关系的强弱来定义出聚合的边界。对象间的关系由强到弱可以分为:泛化关系,关联关系和依赖关系。其中关联关系和依赖关系在 7.3.2.1 小节已讲述,而泛化关系可以理解为是继承关系(即父子关系)。
泛化关系
虽然泛化关系是强耦合关系,但是根据对业务理解的视角不同,会产生不同的设计:
关联关系
上述提到过,聚合间的关联关系会涉及聚合 A 对聚合 B 的生命周期管理,这其实是一个比较宽松的约束。那聚合内实体的关联关系应该是怎么样的呢?生命周期一致的、共存亡的,当主实体被销毁时,从实体也随之会被销毁。比如商品实体和商品明细实体。而在示例-SMS 中,成绩和总成绩会被定义为两个聚合,原因是总成绩在成绩锁定后被统计,随后将不再发生改变,可见两者不存在上述的共存亡的关联关系。
PS: 实际上根据关联关系来区分边界的方法同样适用于限界上下文的边界划分。比如示例-SMS 中的课程和成绩生命周期不同,先有课程,后有成绩;而且成绩锁定后,课程被撤销也不会对成绩有影响,因此就可以定义出课程上下文和成绩上下问。
依赖关系
依赖关系主要体现的是实体间的职责委派和创建行为,可以分到不同的聚合边界。
3. 调整聚合边界
根据业务规则调整聚合边界。为了维护业务规则的不变性,相关的实体应该至于同一个聚合边界内。
└── TotalResultTask.java
├── ResultApplicationService.java
├── event // 应用事件,用于发布
└── adapter // 防腐层适配器接口
├── ... 这段有点长,其代码结构与成绩聚合一致,因此省略 ...
├── adapter
│ ├── CourseAdapterImpl.java
│ ├── facade
│ └── translator
└── repository
└── TotalResultRepositoryImpl.java
9.杂谈9.1 DDD 与微服务
微服务拆解指的是把一个单体服务拆分为粒度“足够小”的多个服务,而这里的“足够小”是一个主观的,没有任何标准的定义。尽管如此,我们对“微”这个词还是有一些基本要求的:足够内聚,足够独立,足够完备,这才使得拆分出来的微服务收益大于投入,试想如果一个微服务提供的业务功能会牵扯到与其他众多微服务的协作,那岂不是芭比 Q 了。
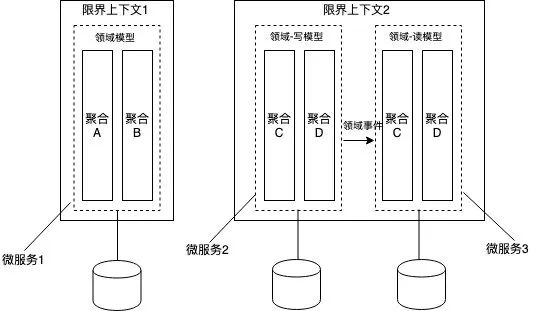
而上述我们对微服务的基本要求,实际上与限界上下文的特征(最小完备,自我履行,稳定空间,独立进化)不谋而合,因此,我们可以把限界上下文映射为微服务。我在日常实践中,都是将限界上下文和微服务的关系进行一一对应的,但这不是绝对的!限界上下文是站在领域角度给出的逻辑边界,而微服务的设计往往还要考虑物理边界,以及实际的质量需求(性能,可用性,安全性等),比如当我们采用的是 CQRS 架构,领域模型会被分为命令模型和查询模型,虽然它们同属一个限界上下文,但是它们往往是物理隔离的。因此,限界上下文只能作为微服务拆分的指导,而拆分过程中需要考虑质量需求,架构设计等技术因素。
9.2 事务
9.2.1 本地事务
上文在提及限界上下文识别和聚合设计的时候其实都提到需要考虑事务属性,即需要通过本地事务来保证业务规则的不变性/一致性。这里我们会疑惑的是:谁来承担管理事务的职责?事务管理的边界是什么?
应用层承担管理事务的职责
事务本质是一种技术手段,而领域模型本身与技术无关,因此事务应该由应用层负责管理。
事务管理的边界是聚合,有时限界上下文也可以
资源库操作的基本单元是聚合,因此事务管理的边界是聚合便是自然而然得出的结论。这里需要考虑的是当需要保证事务属性的不仅仅只有资源库操作,还包括发布领域事件时(即保证聚合落库和事件发布的原子性),我们可能需要采用可靠事件模式,即通过把领域事件落库事件表来表示事件的发布。此时应用层在管理事务时就没什么心智负担了。当然,采用可靠事件模式实际是限制了领域模型的实现,也算是技术对领域模型的一种入侵吧,但相比于解放应用层而言,应该是利大于弊。
我们也知道,应用层的核心职责是负责编排和协调不同聚合的领域服务,而应用层又负责事务管理,自然我们能推到出事务管理的边界是多个聚合(即限界上下文)。但这里有两个关注点:
a)一般是出于质量需求(性能会好一些,时效性更高一些);
b)同一个限界上下文内的多个聚合共享一个 DB。
9.2.2 Saga 事务
为了避免耦合,DDD 主张通过柔性事务来保证跨聚合、跨限界上下文的最终一致性。而目前业界比较主流的应用是 Saga 模式:通过使用异步消息来协调一系列本地事务,从而维度多个服务之间的数据一致性。而另一个非常著名的柔性事务方案 TCC 为啥没有 Saga 契合呢?
TCC 共分为三个阶段:
Try 阶段:准备阶段,对资源进行锁定或预留; Confirm 阶段:提交阶段,执行实际的操作; Cancel 阶段:补偿阶段,任意执行的操作出错了,就需要执行补偿,即释放 Try 阶段预留的资源。
可以看到 TCC 实际对领域模型的侵入是比较大的:
a)TCC 要求领域模型设计时,定义相关的属性以支持资源锁定/预留的问题;
b)TCC 对服务接口定义做出了要求,领域模型需要提供 Try,Confirm 和 Cancel 相应的领域服务。
Saga 模式并不要求其对资源进行锁定/预留,而其补偿操作也是通过执行操作的逆操作来完成(比如支付的逆操作是退款)。而大部分情况下,完整的领域模型都会对外提供操作及其逆操作。
10. 参考《解耦-领域驱动设计》 《领域驱动设计:软件核心复杂性应对之道》 《实现领域驱动设计》 《微服务架构设计模式》 极客时间《DDD 实战课》 极客时间《如何落地业务建模》 《领域驱动设计精粹》
最近其他好文:
深入揭秘 epoll 是如何实现 IO 多路复用的
低代码是什么?有什么优势
Go 高性能编程技法

├── event // 应用事件,用于发布
└── adapter // 防腐层适配器接口
├── ... 这段有点长,其代码结构与成绩聚合一致,因此省略 ...
├── adapter
│ ├── CourseAdapterImpl.java
│ ├── facade
│ └── translator
└── repository
└── TotalResultRepositoryImpl.java
9.杂谈9.1 DDD 与微服务
微服务拆解指的是把一个单体服务拆分为粒度“足够小”的多个服务,而这里的“足够小”是一个主观的,没有任何标准的定义。尽管如此,我们对“微”这个词还是有一些基本要求的:足够内聚,足够独立,足够完备,这才使得拆分出来的微服务收益大于投入,试想如果一个微服务提供的业务功能会牵扯到与其他众多微服务的协作,那岂不是芭比 Q 了。
而上述我们对微服务的基本要求,实际上与限界上下文的特征(最小完备,自我履行,稳定空间,独立进化)不谋而合,因此,我们可以把限界上下文映射为微服务。我在日常实践中,都是将限界上下文和微服务的关系进行一一对应的,但这不是绝对的!限界上下文是站在领域角度给出的逻辑边界,而微服务的设计往往还要考虑物理边界,以及实际的质量需求(性能,可用性,安全性等),比如当我们采用的是 CQRS 架构,领域模型会被分为命令模型和查询模型,虽然它们同属一个限界上下文,但是它们往往是物理隔离的。因此,限界上下文只能作为微服务拆分的指导,而拆分过程中需要考虑质量需求,架构设计等技术因素。
9.2 事务
9.2.1 本地事务
上文在提及限界上下文识别和聚合设计的时候其实都提到需要考虑事务属性,即需要通过本地事务来保证业务规则的不变性/一致性。这里我们会疑惑的是:谁来承担管理事务的职责?事务管理的边界是什么?
应用层承担管理事务的职责
事务本质是一种技术手段,而领域模型本身与技术无关,因此事务应该由应用层负责管理。
事务管理的边界是聚合,有时限界上下文也可以
资源库操作的基本单元是聚合,因此事务管理的边界是聚合便是自然而然得出的结论。这里需要考虑的是当需要保证事务属性的不仅仅只有资源库操作,还包括发布领域事件时(即保证聚合落库和事件发布的原子性),我们可能需要采用可靠事件模式,即通过把领域事件落库事件表来表示事件的发布。此时应用层在管理事务时就没什么心智负担了。当然,采用可靠事件模式实际是限制了领域模型的实现,也算是技术对领域模型的一种入侵吧,但相比于解放应用层而言,应该是利大于弊。
我们也知道,应用层的核心职责是负责编排和协调不同聚合的领域服务,而应用层又负责事务管理,自然我们能推到出事务管理的边界是多个聚合(即限界上下文)。但这里有两个关注点:
a)一般是出于质量需求(性能会好一些,时效性更高一些);
b)同一个限界上下文内的多个聚合共享一个 DB。
9.2.2 Saga 事务
为了避免耦合,DDD 主张通过柔性事务来保证跨聚合、跨限界上下文的最终一致性。而目前业界比较主流的应用是 Saga 模式:通过使用异步消息来协调一系列本地事务,从而维度多个服务之间的数据一致性。而另一个非常著名的柔性事务方案 TCC 为啥没有 Saga 契合呢?
TCC 共分为三个阶段:
Try 阶段:准备阶段,对资源进行锁定或预留; Confirm 阶段:提交阶段,执行实际的操作; Cancel 阶段:补偿阶段,任意执行的操作出错了,就需要执行补偿,即释放 Try 阶段预留的资源。
可以看到 TCC 实际对领域模型的侵入是比较大的:
a)TCC 要求领域模型设计时,定义相关的属性以支持资源锁定/预留的问题;
b)TCC 对服务接口定义做出了要求,领域模型需要提供 Try,Confirm 和 Cancel 相应的领域服务。
Saga 模式并不要求其对资源进行锁定/预留,而其补偿操作也是通过执行操作的逆操作来完成(比如支付的逆操作是退款)。而大部分情况下,完整的领域模型都会对外提供操作及其逆操作。
10. 参考《解耦-领域驱动设计》 《领域驱动设计:软件核心复杂性应对之道》 《实现领域驱动设计》 《微服务架构设计模式》 极客时间《DDD 实战课》 极客时间《如何落地业务建模》 《领域驱动设计精粹》
最近其他好文:
深入揭秘 epoll 是如何实现 IO 多路复用的
低代码是什么?有什么优势
Go 高性能编程技法
│ ├── CourseAdapterImpl.java
│ ├── facade
│ └── translator
└── repository
└── TotalResultRepositoryImpl.java
9.杂谈
9.1 DDD 与微服务
微服务拆解指的是把一个单体服务拆分为粒度“足够小”的多个服务,而这里的“足够小”是一个主观的,没有任何标准的定义。尽管如此,我们对“微”这个词还是有一些基本要求的:足够内聚,足够独立,足够完备,这才使得拆分出来的微服务收益大于投入,试想如果一个微服务提供的业务功能会牵扯到与其他众多微服务的协作,那岂不是芭比 Q 了。
而上述我们对微服务的基本要求,实际上与限界上下文的特征(最小完备,自我履行,稳定空间,独立进化)不谋而合,因此,我们可以把限界上下文映射为微服务。我在日常实践中,都是将限界上下文和微服务的关系进行一一对应的,但这不是绝对的!限界上下文是站在领域角度给出的逻辑边界,而微服务的设计往往还要考虑物理边界,以及实际的质量需求(性能,可用性,安全性等),比如当我们采用的是 CQRS 架构,领域模型会被分为命令模型和查询模型,虽然它们同属一个限界上下文,但是它们往往是物理隔离的。因此,限界上下文只能作为微服务拆分的指导,而拆分过程中需要考虑质量需求,架构设计等技术因素。
9.2 事务
9.2.1 本地事务
上文在提及限界上下文识别和聚合设计的时候其实都提到需要考虑事务属性,即需要通过本地事务来保证业务规则的不变性/一致性。这里我们会疑惑的是:谁来承担管理事务的职责?事务管理的边界是什么?
应用层承担管理事务的职责
事务本质是一种技术手段,而领域模型本身与技术无关,因此事务应该由应用层负责管理。
事务管理的边界是聚合,有时限界上下文也可以
资源库操作的基本单元是聚合,因此事务管理的边界是聚合便是自然而然得出的结论。这里需要考虑的是当需要保证事务属性的不仅仅只有资源库操作,还包括发布领域事件时(即保证聚合落库和事件发布的原子性),我们可能需要采用可靠事件模式,即通过把领域事件落库事件表来表示事件的发布。此时应用层在管理事务时就没什么心智负担了。当然,采用可靠事件模式实际是限制了领域模型的实现,也算是技术对领域模型的一种入侵吧,但相比于解放应用层而言,应该是利大于弊。
我们也知道,应用层的核心职责是负责编排和协调不同聚合的领域服务,而应用层又负责事务管理,自然我们能推到出事务管理的边界是多个聚合(即限界上下文)。但这里有两个关注点:
a)一般是出于质量需求(性能会好一些,时效性更高一些);
b)同一个限界上下文内的多个聚合共享一个 DB。
9.2.2 Saga 事务
为了避免耦合,DDD 主张通过柔性事务来保证跨聚合、跨限界上下文的最终一致性。而目前业界比较主流的应用是 Saga 模式:通过使用异步消息来协调一系列本地事务,从而维度多个服务之间的数据一致性。而另一个非常著名的柔性事务方案 TCC 为啥没有 Saga 契合呢?
TCC 共分为三个阶段:
Try 阶段:准备阶段,对资源进行锁定或预留; Confirm 阶段:提交阶段,执行实际的操作; Cancel 阶段:补偿阶段,任意执行的操作出错了,就需要执行补偿,即释放 Try 阶段预留的资源。
可以看到 TCC 实际对领域模型的侵入是比较大的:
a)TCC 要求领域模型设计时,定义相关的属性以支持资源锁定/预留的问题;
b)TCC 对服务接口定义做出了要求,领域模型需要提供 Try,Confirm 和 Cancel 相应的领域服务。
Saga 模式并不要求其对资源进行锁定/预留,而其补偿操作也是通过执行操作的逆操作来完成(比如支付的逆操作是退款)。而大部分情况下,完整的领域模型都会对外提供操作及其逆操作。
10. 参考《解耦-领域驱动设计》 《领域驱动设计:软件核心复杂性应对之道》 《实现领域驱动设计》 《微服务架构设计模式》 极客时间《DDD 实战课》 极客时间《如何落地业务建模》 《领域驱动设计精粹》
浅析 DDD 领域驱动设计
一、前言
二、什么是DDD
DDD 是 Eric Evans 在2003年出版的书名,同时也是这个架构设计方法名的起源。Eric Evans “领域驱动设计之父”,世界杰出软件建模专家。他创建的 “Domain Language” 公司,就是致力帮助公司机构创建与业务紧密相关的软件。
DDD 不是一套架构,而是一种架构思想,所以导致在代码层面缺乏了足够的约束,因此 DDD 在实际应用中上手门槛比较高,而且在绝大部分公司中实际应用中是没有应用到的,或者说只是应用到了 DDD 部分思想 比如: 建模的思想,对整个架构体系的思想是无法落地的,而且一些依然火热的ORM工具(Hibernate)助长了贫血模型的扩散,同样因为传统的基于数据库技术以及MVC的四成架构应用(UI、Business、Data Access、Database)依然能够为我们解决绝大部分的应用开发。
之前的服务架构 局限于单机 +LB 用MVC提供的Rest接口提供外部服务调用,或者用WebService 做RPC调用,到了2014年,SOA开始火热起来了,微服务开始如雨后春笋一样的开始冒头,怎么把一个应用或者项目合理化的进行拆分多个微服务,成为了各个技术负责人的思考的重点,而在DDD里面的 Bounded Context(限界上下文)中就为我们提供了一整套合理的架构思想。
但是 DDD 可以让我们思考 在我们的项目中哪些是可以被服务化拆分,哪些业务逻辑需要被聚合在一起,实现最小的开发和维护成本。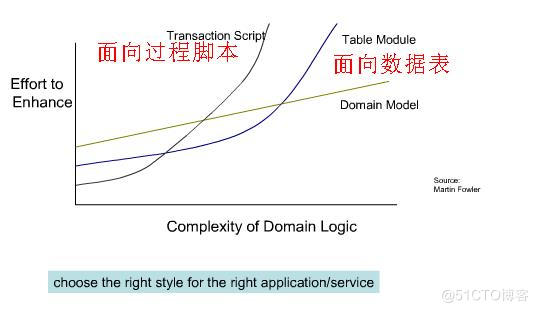
三、领域驱动设计-基本概念
DDD 的全称为 Domain Driven Design,即领域驱动设计,DDD不是架构,而是一种方法论(Methodology),微服务架构从一出来就没有很好的理论支撑如何合理的划分服务边界。
在我们早期常见的软件开发就是拿到产品需求后,先考虑数据库设计,根据数据库设计,建立对应的实体层、服务层等等,但是这种方式会将 分析、设计和业务需求脱节,而更多的是直接考虑应该如何实现,这就有点本末倒置了,而DDD 是从问题本身出发进行的设计方法。
概念: 系统设计应该是一种以领域为核心的设计和开发,设计应该通过维护一个深度反应领域概念的模型,以及提供可行的经过实践校验的大量模式来应对领域的复杂性。
DDD 更像小颗粒的迭代设计,最小单元是 领域模型(Domain Model)
什么是领域(Domain)?
什么是领域?比如我们经常使用的某宝、某东、属于网上电商领域,那么这些领域就会有对应的商品浏览、购物车、下单、扣减库存、供应商、付款等等核心环境。再比如我们想做一个聊天系统,那这个系统的核心业务就要确定,比如有 联系人、分组、朋友圈、视频、聊天记录等功能。
所以,我们可以得知,一个领域的本质上可以理解为一个问题域,只要是同一个领域的,那么他们 一定会有相同的问题域,因此只要我们确定了系统所属的领域,那这个系统的核心业务,也就是我们要解决的关键问题,问题的范围边界也就基本确定了。
什么是设计(Design)?
DDD 中的设计主要是指领域模型的设计,为什么说是领域模型的设计而不是架构设计或者其他的设计?因为DDD是一种基于模型驱动开发的软件开发思想,强调领域模型是这个系统的核心,领域模型也是整个系统的核心价值所在,每一个领域,都有对应的领域模型,因为领域模型能够很好的帮助我们解决复杂的业务问题。
领域模型绑定了领域和代码的是吸纳,确保了最终的代码实现就一定是解决了领域中的核心问题,
四、四色原型建模
简单描述: 某个人(Party)的角色(PartyRole)在某个地点(Place)的角色(PlaceRole)用某个东西(Thing)的角色(ThingRole)做了某件事情(MomentInterval)
PartPlaceThing:简称PPT,用淡绿色表示,常见的PPT有:部门、岗位、人员、地点、物品等。
Description:简称Des,用淡蓝色表示,主要用来对PPT进行描述,常见的Des有:部门类型、岗位层级、人员类型、地点区域、物品分类等。
Role:用淡黄色表示,主要表示PPT在某个场景下扮演的角色,常见的角色有:财务类部门、管理类岗位、请假者、销售点、产品等。
MomentInterval:简称MI,用淡红色表示,主要表示在一刻或一段时间内发生的一件事情,常见的MI有:部门移动、岗位移动、员工离职、产品销售等。
MomentInteval:简称MIDetail,用淡红色表示,主要表示MI的明细。
五、分层架构
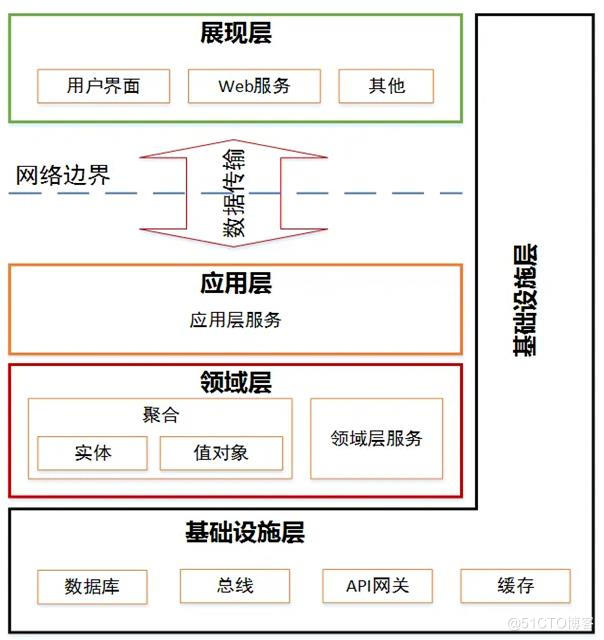
分层架构是将软件模块按照水平切分的方式分成多个层
最基本的是分层架构是三层:即表现层,领域层和数据持久层
DDD中 四层架构:表现层,应用层、领域层和基础层
四层中的应用层是对三层架构中领域层进行进一步拆分。但是无论怎么分层,业务逻辑永远在领域层。
三层架构:
- 表现层: 负责向用户展示信息和接收用户的指令。需要负责处理展示逻辑,比如用户通过我们的系
统进行信用卡还款,系统会返回三个状态未申请,处理中,处理完成。表面层需要根据这个状态给
用户返回不同的页面,根据这三个不同的状态,向用户展示不同的中文说明。 - 领域层: 负责表达业务逻辑,是整个系统的核心层。比如信用卡还款服务。
- 持久层: 提供数据查询和存储服务,包括按照状态查询信用卡。
四层架构:
- 表现层: 同三层架构表现层。
- 应用层: 定义软件要完成的任务,不包含业务逻辑,而是协调,比如受理用户请求的任务。负责非
业务逻辑(批量删除、修改等) - 领域层: 同三层架构领域层。
- 基础层: 为各层提供通用的技术能力。为领域层提供数据和文件存储。
-
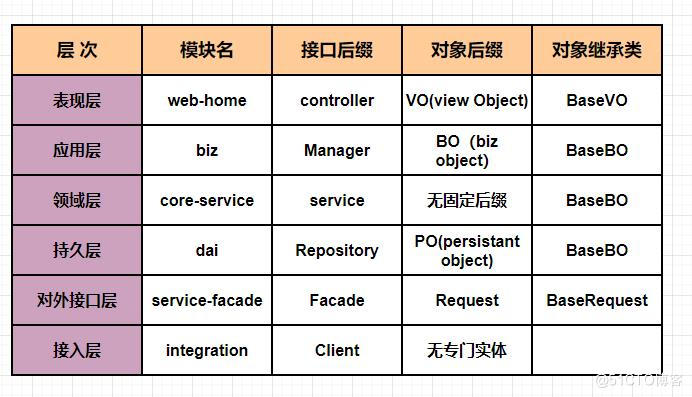
分层架构最重要的是每一层关注自己的职责,持久层只负责提供查询、更新和存储数据的服务,和业务逻辑无关的,所以持久层提供按照还款状态查询信用卡的服务,这样做的好处增加复用性,后续领域层提供展示已还款的信用卡服务时能复用持久层的查询服务。
分层架构的好处
分层架构的目的是通过关注点分离来降低系统的复杂度,同时满足单一职责、高内聚、低耦合、提高可复用性和降低维护成本。
单一职责:每一层只负责一个职责,职责边界清晰,如持久层只负责数据查询和存储,领域层只负
责处理业务逻辑。
高内聚: 分层是把相同的职责放在同一个层中,所有业务逻辑内聚在领域层。这样做有什么好处呢?试想一下假如业务逻辑分散在每一层,修改功能需要去各层修改,测试业务逻辑需要测试所有层的代码,这样增加了整个软件的复杂度和测试难度。
低耦合: 依赖关系非常简单,上层只能依赖于下层,没有循环依赖。
可复用: 某项能力可以复用给多个业务流程。比如持久层提供按照还款状态查询信用卡的服务,既可以给申请信用卡做判断使用,也可以给展示未还款信用卡使用。
易维护: 面对变更容易修改。把所有对外接口都放在对外接口层,一旦外部依赖的接口被修改,只需要改这个层的代码即可。
以上这些既是分层的好处也是分层的原则,大家在分层时需要遵循以上原则,不恰当的分层会违背了分层架构的初衷。
分层架构的缺点
分层架构也有几个缺点
开发成本高: 因为多层分别承担各自的职责,增加功能需要在多个层增加代码,这样难免会增加开发成本。但是合理的能力抽象可以提高了复用性,又能降低开发成本。
性能略低: 业务流需要经过多层代码的处理,性能会有所消耗。
可扩展性低: 因为上下层之间存在耦合度,所有有些功能变化可能涉及到多层的修改。
六、领域模型(domain model)
领域模型是对领域内的概念类或现实世界中对象的可视化表示。又称概念模型、业务对象模型、领域对象模型、分析对象模型。
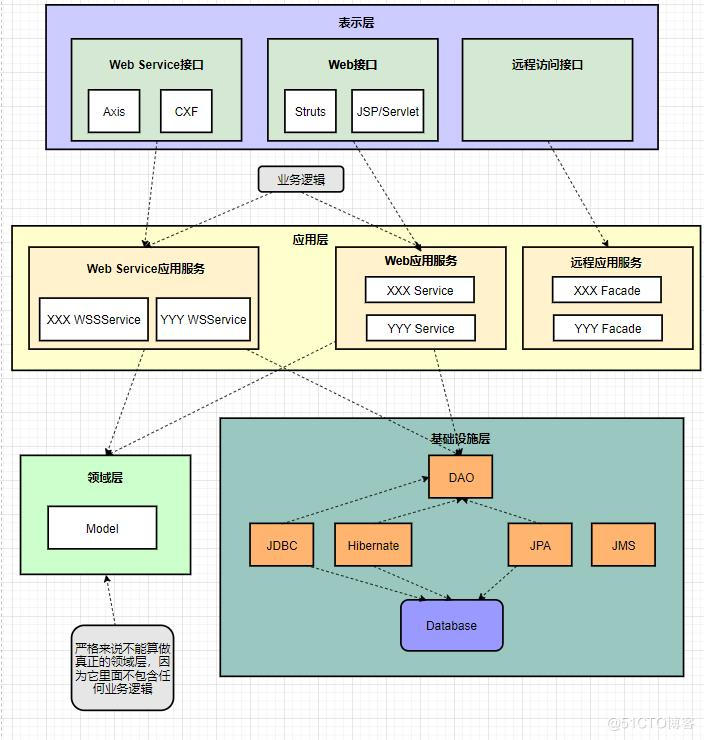
它专注于分析问题领域本身,发掘重要的业务领域概念,并建立业务领域概念之间的关系。
优点是系统层次结构清楚,各层之间单向依赖, Client -> (Business Facade) -> Business Logic -> Data Access Object 可见,领域对象几乎只做传输介质的用处,不会影响到层次的划分。
领域对象只是作为保存状态或者传递状态使用,它是没有生命的,只是数据没有行为的对象不是真正的对象。
七、贫血模型
贫血模型是指领域对象里只有 get 和 set 方法(一般是指POJO),所有的业务逻辑是不包含在这里面的而是放在 Business Logic层。
在使用Spring的时候,通常就暗示着我们使用的是贫血模型,我们把Domain类用来单纯地储存数据,Spring管不着这些类的注入和管理,Spring关心的逻辑层(比如单例的被池化了的Business Logic层) 可以被设计成Singleton的Bean。
假设我们这里改变一下,就在Domain类中提供业务逻辑方法,那么我们在使用Spring构造这样的数据Bean的时候会遇到很多麻烦,比如 Bean之间的引用,可能引起大范围的Bean之间的潜逃构造器的调用。
八、充血模型
大多业务逻辑和持久化放在Domain Object 里面,Business Logic只是简单封装部分业务逻辑以及控制事务、权限等,这样层次结构就变成 Client -> (Business Facade) -> Business Logic -> Domain Object -> Data Access Object。
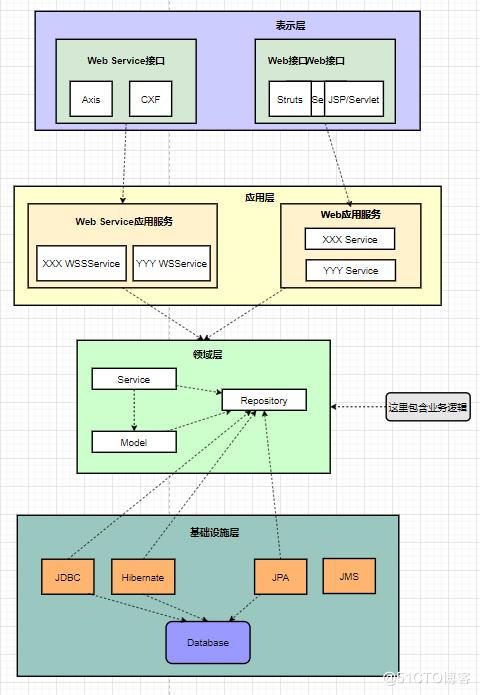
优点:
是面向对象,Business Logic 符合单一职责,不像在贫血模型里面那样包含所有的业务逻辑太过沉重。
缺点
如何划分业务逻辑,什么样的逻辑应该放在 Domain Object中,什么样的业务逻辑应该放在Business Logic中,其实是比较模糊的。
即使划分好了业务逻辑,由于分散在Business Logic和Domain Object层中,不能更好的划分模块开发。
熟悉业务逻辑的开发人员需要渗透到Domain Logic中去,而在Domain Logic又包含了持久化,对于开发者者这是十分混乱的。
如果Business Logic要控制事务并且为上层提供一个统一的服务调用入口点,它就必须把在Domain logic里实现的业务逻辑全部重新包装一遍,完全属于重复劳动。
使用RoR开发时,每一个领域模型对象都可以具备自己的基础业务方法,通常满足充血模型的开发,充血模型更适合复杂业务逻辑的设计开发。
充血模型的层次和模块的划分是一门学问,对开发人员要求也比较高,可以考虑定义这样的一些规则:
(1) 事务控制不要放在领取模型的对象中实现,可以放在facade中完成。
(2) 领域模型对象中只保留该模型驱动的一般方法,对于业务特征明显的特异场景方法调用放在facade中完成。
九、传统的数据驱动开发模式
View、Service、Dao 这种三层模式,开发者会很自然的写出过程式代码,这种开发方式中的对象只是数据载体,而没有行为,是一种贫血对象模型,以数据为中心,以数据库ER图为设计驱动,分层架构在这种开发模式下可以认为是数据处理和实现的过程。
十、限界上下文(Bounded Context)
限界上下文:定义了每个模型的应用范围
一个业务领域可以划分成多个BC,它们之间通过Context Map进行集成。BC是一个显式的边界,领域模型Bianc便存在于这个边界之内。领域模型是关于某个特定业务员领域的软件模型,通常,领域模型通过对象模型来实现,这些对象同时包含了数据和行为,并且表达了准确的业务含义。
关于限界上下文,有一个很形象的类别,细胞和细胞膜的类比:
细胞之所以能存在,是因为细胞膜定义了什么在细胞内,什么在细胞外,而且确认了什么物质可以通过细胞膜
BC可以类比为细胞膜,大型系统由于其复杂性,对于一个对象如果采取统一建模方式,可能会产生不可预测的效果。例如书中提到的客户发票中的收费对象故障,其实类似问题也在很多地方可以看到。
十一、什么是 CQRS?
CQRS —— Command Query Responsibility Segreation(命令查询职责分离),故名思义是将 command 与 query 分离的一种模式。这种命令与查询的分离方式,可以更好地控制请求者的操作。查询操作不会造成数据的修改,因而它属于一种幂等操作,可以反复地发起,而不用担心会对系统造成影响。基于这种特性,我们还可以为其提供缓存,从而改进查询的性能。
query很好理解,就是我们经常使用到的查询。
那么 command 又是什么呢,我们可以看 CRUD,其实可以分为读(R)和写(CUD),大部分情况就是一个方法要么是执行一个Command完成一个动作,要么就是查询返回数据,比如我们回答问题的人不应该去修改问题。
只要充分理解了运用CQRS模式的意图,理解CQRS模式就变得容易了许多。下图是CQRS框架AxonFramework官方文档给出的CQRS架构图。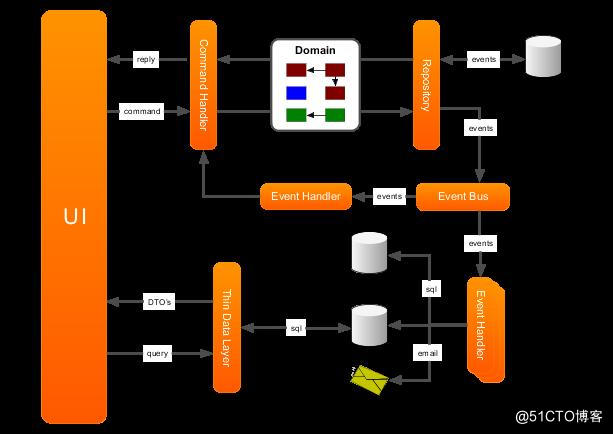
十二、统一语言(Ubiquitous Language)
业务人员和我们使用一样的语言,我们的程序比如让业务尽量集中在领域里,比如在传统的数据驱动里,如果说 张三喜欢李四,我们一般会这么写
但是我们业务人员很奇怪谁Love谁? 为什么要UserService?, 如果我们写成下面这样
如果我们用
这样我们就更容易让业务人员参与进来,而且代码可以更易于表示真实的业务场景。

以上是根据课堂笔记来记录的,如果有错误或者不懂的地方,欢迎大家在下面留言。
我是牧小农,怕什么真理无穷,进一步有进一步的欢喜!
以上是关于万字长文助你上手软件领域驱动设计 DDD的主要内容,如果未能解决你的问题,请参考以下文章