论文原文:Generalization and width. Neyshabur et al. [2018b] found that wider networks generalize better. Can we now explain this? Intuitively, wider networks have more sub-networks at any given level, and so the sub-network with maximum coherence in a wider network may be more coherent than its counterpart in a thinner network, and hence generalize better. In other words, since—as discussed in Section 10—gradient descent is a feature selector that prioritizes well-generalizing (coherent) features, wider networks are likely to have better features simply because they have more features. In this connection, see also the Lottery Ticket Hypothesis [Frankle and Carbin, 2018]
Based on our theory, finite learning rate, and mini-batch stochasticity
are not necessary for generalization
我们认为较低的学习率可能无法降低泛化误差,因为较低的学习率意味着更多的迭代次数(与早停相反)。
Assuming a small enough learning rate, as training progresses, the generalization gap cannot decrease. This follows from the iterative stability analysis of training: with 40 more steps, stability can only degrade. If this is violated in a practical setting, it would point to an interesting limitation of the theory
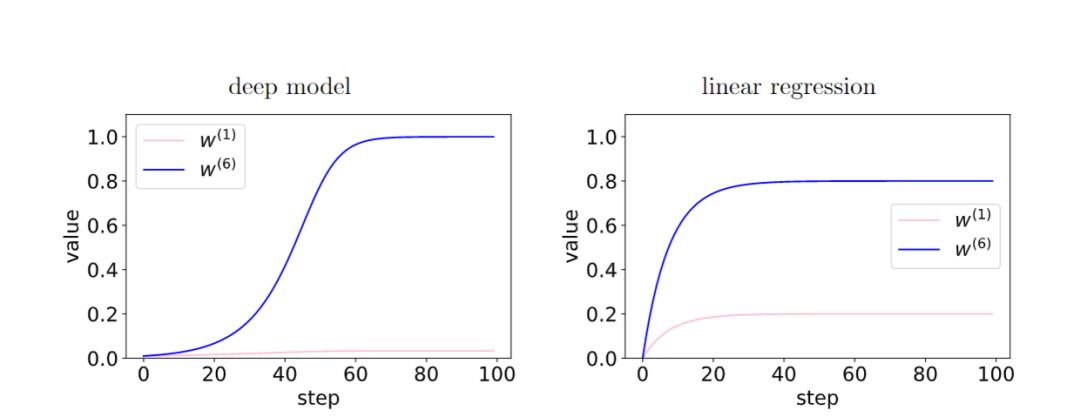
在深度模型中,由于层之间的反馈加强了有相干性的梯度,存在相干性梯度的特征(W6)和非相干梯度的特征(W1)之间的相对差异在训练过程中呈指数放大。从而使得更深的网络更偏好相干梯度,从而更好泛化能力。
(注:简单的样本,是那些在数据集里面有很多梯度共同点的样本,正由于这个原因,大多数梯度对它有益,收敛也比较快。)
我们可以把“L2正则化(权重衰减)”看作是一种“背景力”,可将每个参数推近于数据无关的零值 ( L1容易得到稀疏解,L2容易得到趋近0的平滑解) ,来消除在弱梯度方向上影响。只有在相干梯度方向的情况下,参数才比较能脱离“背景力”,基于数据完成梯度更新。