浏览器缓存库设计总结(localStorage/indexedDB)
Posted 趣谈前端
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了浏览器缓存库设计总结(localStorage/indexedDB)相关的知识,希望对你有一定的参考价值。
每个Web应用体验都必须快速,对于渐进式 Web 应用更是如此。快速是指在屏幕上获取有意义内容所需的时间,要在不到 5 秒的时间内提供交互式体验。并且,它必须真的很快。很难形容可靠的高性能有多重要。可以这样想: 本机应用的首次加载令人沮丧。已安装的渐进式 Web 应用必须能让用户获得可靠的性能。
本文会介绍一些笔者曾经做过的Web性能优化方案以及浏览器缓存的基本流程,并会着重介绍如 // html内容 这样虽然可以实现功能,但是每一个业务都要写类似的代码, 往往很难受, 所以作为一个有追求的程序员,我们可以在请求上下功夫.我们都有过axios或者fetch库的使用经验,我们也接触过请求/响应拦截器的使用, 那么我们能不能考虑对请求本身也做一层拦截呢?我想实现的效果是我们在业务里还是正常的像之前一样使用请求,比如: 然而内部已经帮我们做好请求缓存了,我们的req实际上不是axios或者fetch的实例,而是一层代理. 通过这种方式我们对原来的请求方式可以不做任何改变, 完全采用代理机制在请求拦截器中和响应拦截器中布局我们的代理即可,关键点就是存到数据库中的内容要和服务器响应的内容结构一致. 以上方式我们可以对所有的get请求做缓存,如果我们只想对部分请求做缓存,其实利用以上机制实现也很简单,我们只需要设置缓存白名单, 在请求拦截器中判断如果在白名单内才走缓存逻辑即可. 这样,我们再次进行某项数据的搜索时,可以不走任何http请求,直接从indexedDB中获取,这样可以为公司节省大量的流量. 关于indexedDB的库的封装,我也发布到npm和github上了,大家可以直接使用或者进行二次开发. github地址: xdb-采用promise封装的indexedDB存储库
dao @alex_xu/dao
interface Window xdb: any;
xdb = (() =>
instance:any = dbName = DB = cfg =
name: args.name || version: args.version || onSuccess(e:Event)
args.onSuccess && args.onSuccess(e)
,
onUpdate(e:Event)
args.onUpdate && args.onUpdate(e)
,
onError(e:Event)
args.onError && args.onError(e)
(!
_this =
(event:Event)
cfg.onError(event)
(event:Event)
_this.db = _this.request.result
cfg.onSuccess(event)
(event:any)
_this.db = event.target.result
cfg.onUpdate(event)
objectStore:any
(! opts =
keyPath: opts.keyPath,
indexs:
objectStore = opts.indexs.forEach((item:any) =>
objectStore.createIndex(item.indexName, item.key, unique: item.unique )
)
objectStore
_this = transaction = objectStore = transaction.objectStore(tableName)
request = objectStore.get(keyPathVal)
request.onerror = reject(status:
request.onsuccess = (request.result)
resolve(status: _this.del(tableName, keyPathVal)
resolve(status:
resolve(status:
)
objectStore = result:any = []
objectStore.openCursor().onsuccess = (event:any)
cursor = event.target.result
(cursor)
result.push(cursor.value)
cursor.continue()
reslove(status:
objectStore.openCursor().onerror = (event:Event)
reject(status:
)
request = .objectStore(tableName)
.add( request.onsuccess = (event:Event)
reslove(status:
request.onerror = (event:Event)
reject(status:
)
request = .objectStore(tableName)
.put(row)
request.onsuccess = (event:Event)
reslove(status:
request.onerror = (event:Event)
reject(status:
)
request = .objectStore(tableName)
.delete(keyPathVal)
request.onsuccess = (event:Event)
resolve(status:
request.onerror = (event:Event)
reject(status:
)
request = .objectStore(tableName)
.clear()
request.onsuccess = (event:Event)
resolve(status:
request.onerror = (event:Event)
reject(status:
)
loadDB(args:any)
|| dbName !== args.name)
instance = (DB any)(args)
instance
)()
xdb
http.get( res && store.set(* * * )
复制代码
复制代码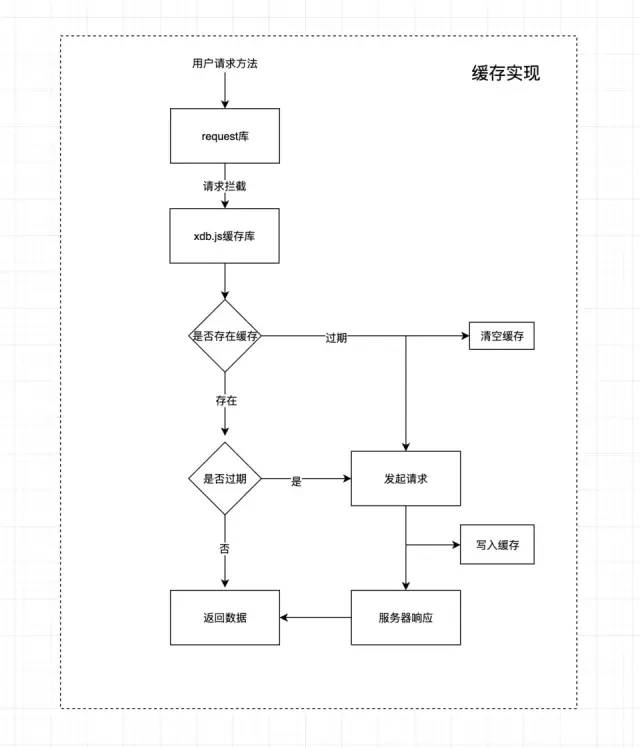
200 行 TypeScript 代码实现一个高效缓存库
这两天用到 cacheables 缓存库,觉得挺不错的,和大家分享一下我看完源码的总结。
一、介绍
「cacheables」正如它名字一样,是用来做内存缓存使用,其代码仅仅 200 行左右(不含注释),官方的介绍如下:
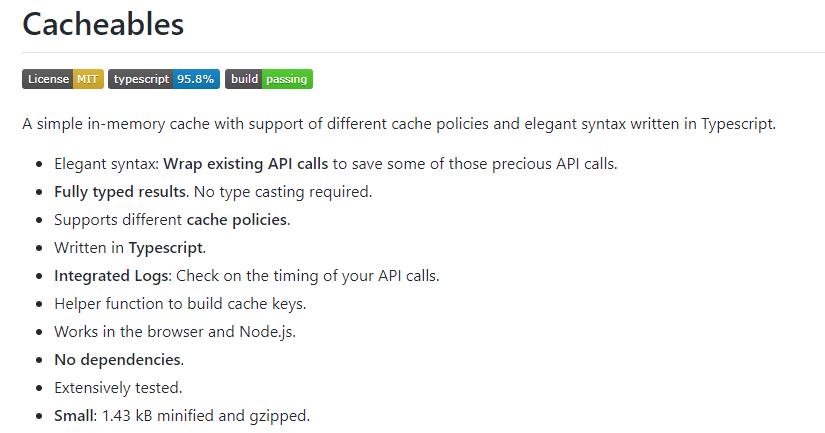
一个简单的内存缓存,支持不同的缓存策略,使用 TypeScript 编写优雅的语法。
它的特点:
- 优雅的语法,包装现有 API 调用,节省 API 调用;
- 完全输入的结果。不需要类型转换。
- 支持不同的缓存策略。
- 集成日志:检查 API 调用的时间。
- 使用辅助函数来构建缓存 key。
- 适用于浏览器和 Node.js。
- 没有依赖。
- 进行大范围测试。
- 体积小,gzip 之后 1.43kb。
当我们业务中需要对请求等异步任务做缓存,避免重复请求时,完全可以使用上「cacheables」。
二、上手体验
上手 cacheables很简单,看看下面使用对比:
// 没有使用缓存
fetch("https://some-url.com/api");
// 有使用缓存
cache.cacheable(() => fetch("https://some-url.com/api"), "key");
接下来看下官网提供的缓存请求的使用示例:
1. 安装依赖
npm install cacheables
// 或者
pnpm add cacheables
2. 使用示例
import { Cacheables } from "cacheables";
const apiUrl = "http://localhost:3000/";
// 创建一个新的缓存实例 ①
const cache = new Cacheables({
logTiming: true,
log: true,
});
// 模拟异步任务
const wait = (ms: number) => new Promise((resolve) => setTimeout(resolve, ms));
// 包装一个现有 API 调用 fetch(apiUrl),并分配一个 key 为 weather
// 下面例子使用 'max-age' 缓存策略,它会在一段时间后缓存失效
// 该方法返回一个完整 Promise,就像' fetch(apiUrl) '一样,可以缓存结果。
const getWeatherData = () =>
// ②
cache.cacheable(() => fetch(apiUrl), "weather", {
cachePolicy: "max-age",
maxAge: 5000,
});
const start = async () => {
// 获取新数据,并添加到缓存中
const weatherData = await getWeatherData();
// 3秒之后再执行
await wait(3000);
// 缓存新数据,maxAge设置5秒,此时还未过期
const cachedWeatherData = await getWeatherData();
// 3秒之后再执行
await wait(3000);
// 缓存超过5秒,此时已过期,此时请求的数据将会再缓存起来
const freshWeatherData = await getWeatherData();
};
start();
上面示例代码我们就实现一个请求缓存的业务,在 maxAge为 5 秒内的重复请求,不会重新发送请求,而是从缓存读取其结果进行返回。
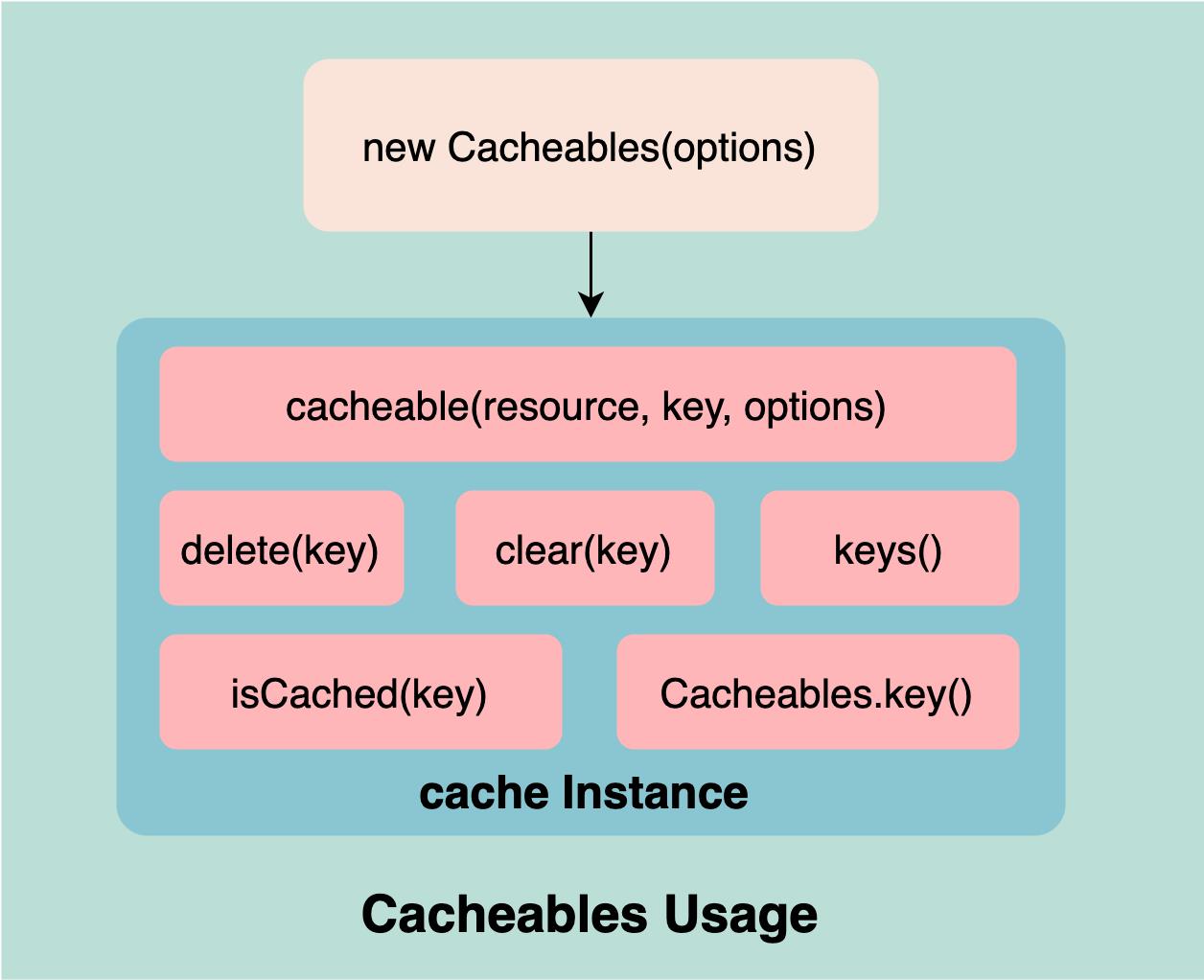
3. API 介绍
官方文档中介绍了很多 API,具体可以从文档中获取,比较常用的如 cache.cacheable(),用来包装一个方法进行缓存。
所有 API 如下:
new Cacheables(options?): Cacheablescache.cacheable(resource, key, options?): Promise<T>cache.delete(key: string): voidcache.clear(): voidcache.keys(): string[]cache.isCached(key: string): booleanCacheables.key(...args: (string | number)[]): string
可以通过下图加深理解:
三、源码分析
克隆 cacheables 项目下来后,可以看到主要逻辑都在 index.ts中,去掉换行和注释,代码量 200 行左右,阅读起来比较简单。
接下来我们按照官方提供的示例,作为主线来阅读源码。
1. 创建缓存实例
示例中第 ① 步中,先通过 new Cacheables()创建一个缓存实例,在源码中Cacheables类的定义如下,这边先删掉多余代码,看下类提供的方法和作用:
export class Cacheables {
constructor(options?: CacheOptions) {
this.enabled = options?.enabled ?? true;
this.log = options?.log ?? false;
this.logTiming = options?.logTiming ?? false;
}
// 使用提供的参数创建一个 key
static key(): string {}
// 删除一笔缓存
delete(): void {}
// 清除所有缓存
clear(): void {}
// 返回指定 key 的缓存对象是否存在,并且有效(即是否超时)
isCached(key: string): boolean {}
// 返回所有的缓存 key
keys(): string[] {}
// 用来包装方法调用,做缓存
async cacheable<T>(): Promise<T> {}
}
这样就很直观清楚 cacheables 实例的作用和支持的方法,其 UML 类图如下:
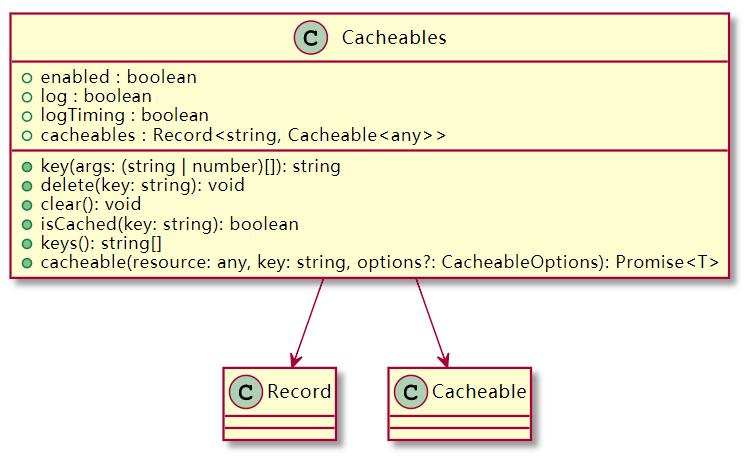
在第 ① 步实例化时,Cacheables 内部构造函数会将入参保存起来,接口定义如下:
const cache = new Cacheables({
logTiming: true,
log: true,
});
export type CacheOptions = {
// 缓存开关
enabled?: boolean;
// 启用/禁用缓存命中日志
log?: boolean;
// 启用/禁用计时
logTiming?: boolean;
};
根据参数可以看出,此时我们 Cacheables 实例支持缓存日志和计时功能。
2. 包装缓存方法
第 ② 步中,我们将请求方法包装在 cache.cacheable方法中,实现使用 max-age作为缓存策略,并且有效期 5000 毫秒的缓存:
const getWeatherData = () =>
cache.cacheable(() => fetch(apiUrl), "weather", {
cachePolicy: "max-age",
maxAge: 5000,
});
其中,cacheable 方法是 Cacheables类上的成员方法,定义如下(移除日志相关代码):
// 执行缓存设置
async cacheable<T>(
resource: () => Promise<T>, // 一个返回Promise的函数
key: string, // 缓存的 key
options?: CacheableOptions, // 缓存策略
): Promise<T> {
const shouldCache = this.enabled
// 没有启用缓存,则直接调用传入的函数,并返回调用结果
if (!shouldCache) {
return resource()
}
// ... 省略日志代码
const result = await this.#cacheable(resource, key, options) // 核心
// ... 省略日志代码
return result
}
其中cacheable 方法接收三个参数:
resource:需要包装的函数,是一个返回 Promise 的函数,如() => fetch();key:用来做缓存的key;options:缓存策略的配置选项;
返回 this.#cacheable私有方法执行的结果,this.#cacheable私有方法实现如下:
// 处理缓存,如保存缓存对象等
async #cacheable<T>(
resource: () => Promise<T>,
key: string,
options?: CacheableOptions,
): Promise<T> {
// 先通过 key 获取缓存对象
let cacheable = this.#cacheables[key] as Cacheable<T> | undefined
// 如果不存在该 key 下的缓存对象,则通过 Cacheable 实例化一个新的缓存对象
// 并保存在该 key 下
if (!cacheable) {
cacheable = new Cacheable()
this.#cacheables[key] = cacheable
}
// 调用对应缓存策略
return await cacheable.touch(resource, options)
}
this.#cacheable私有方法接收的参数与 cacheable方法一样,返回的是 cacheable.touch方法调用的结果。
如果 key 的缓存对象不存在,则通过 Cacheable类创建一个,其 UML 类图如下:
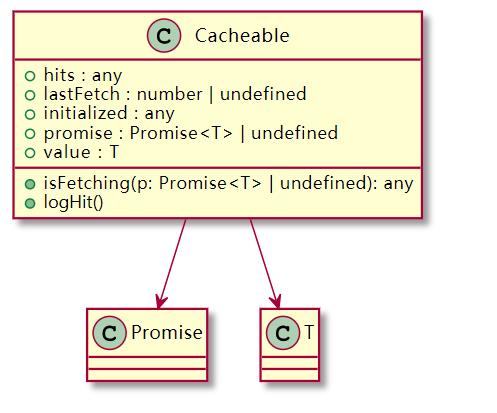
3. 处理缓存策略
上一步中,会通过调用 cacheable.touch方法,来执行对应缓存策略,该方法定义如下:
// 执行缓存策略的方法
async touch(
resource: () => Promise<T>,
options?: CacheableOptions,
): Promise<T> {
if (!this.#initialized) {
return this.#handlePreInit(resource, options)
}
if (!options) {
return this.#handleCacheOnly()
}
// 通过实例化 Cacheables 时候配置的 options 的 cachePolicy 选择对应策略进行处理
switch (options.cachePolicy) {
case 'cache-only':
return this.#handleCacheOnly()
case 'network-only':
return this.#handleNetworkOnly(resource)
case 'stale-while-revalidate':
return this.#handleSwr(resource)
case 'max-age': // 本案例使用的类型
return this.#handleMaxAge(resource, options.maxAge)
case 'network-only-non-concurrent':
return this.#handleNetworkOnlyNonConcurrent(resource)
}
}
touch方法接收两个参数,来自 #cacheable私有方法参数的 resource和 options。
本案例使用的是 max-age缓存策略,所以我们看看对应的 #handleMaxAge私有方法定义(其他的类似):
// maxAge 缓存策略的处理方法
#handleMaxAge(resource: () => Promise<T>, maxAge: number) {
// #lastFetch 最后发送时间,在 fetch 时会记录当前时间
// 如果当前时间大于 #lastFetch + maxAge 时,会非并发调用传入的方法
if (!this.#lastFetch || Date.now() > this.#lastFetch + maxAge) {
return this.#fetchNonConcurrent(resource)
}
return this.#value // 如果是缓存期间,则直接返回前面缓存的结果
}
当我们第二次执行 getWeatherData() 已经是 6 秒后,已经超过 maxAge设置的 5 秒,所有之后就会缓存失效,重新发请求。
再看下 #fetchNonConcurrent私有方法定义,该方法用来发送非并发的请求:
// 发送非并发请求
async #fetchNonConcurrent(resource: () => Promise<T>): Promise<T> {
// 非并发情况,如果当前请求还在发送中,则直接执行当前执行中的方法,并返回结果
if (this.#isFetching(this.#promise)) {
await this.#promise
return this.#value
}
// 否则直接执行传入的方法
return this.#fetch(resource)
}
#fetchNonConcurrent私有方法只接收参数 resource,即需要包装的函数。
这边先判断当前是否是【发送中】状态,如果则直接调用 this.#promise,并返回缓存的值,结束调用。否则将 resource 传入 #fetch执行。
#fetch私有方法定义如下:
// 执行请求发送
async #fetch(resource: () => Promise<T>): Promise<T> {
this.#lastFetch = Date.now()
this.#promise = resource() // 定义守卫变量,表示当前有任务在执行
this.#value = await this.#promise
if (!this.#initialized) this.#initialized = true
this.#promise = undefined // 执行完成,清空守卫变量
return this.#value
}
#fetch 私有方法接收前面的需要包装的函数,并通过对守卫变量赋值,控制任务的执行,在刚开始执行时进行赋值,任务执行完成以后,清空守卫变量。
这也是我们实际业务开发经常用到的方法,比如发请求前,通过一个变量赋值,表示当前有任务执行,不能在发其他请求,在请求结束后,将该变量清空,继续执行其他任务。
完成任务。「cacheables」执行过程大致是这样,接下来我们总结一个通用的缓存方案,便于理解和拓展。
四、通用缓存库设计方案
在 Cacheables 中支持五种缓存策略,上面只介绍其中的 max-age:
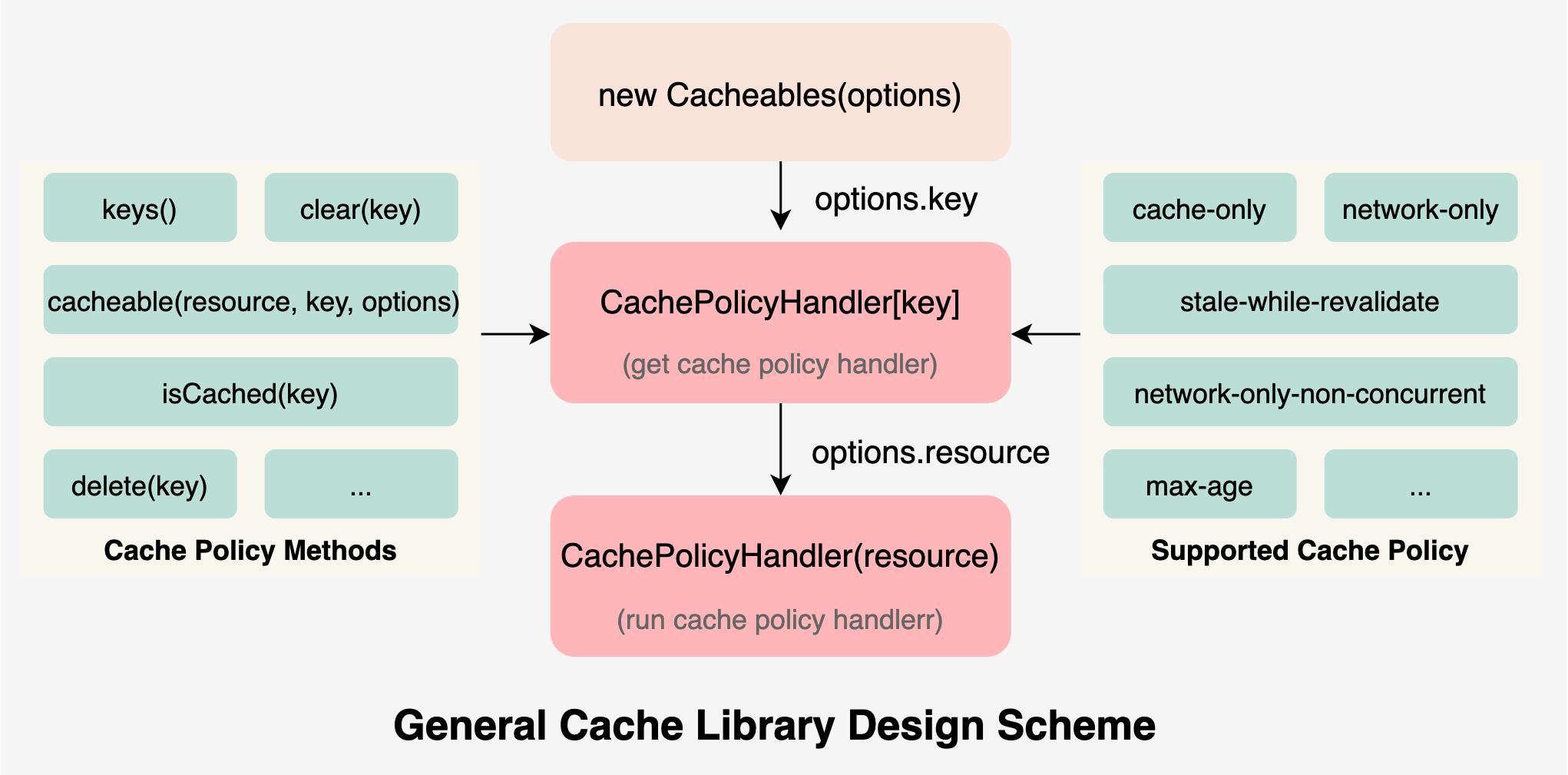
这里总结一套通用缓存库设计方案,大致如下图:

该缓存库支持实例化是传入 options参数,将用户传入的 options.key作为 key,调用CachePolicyHandler对象中获取用户指定的缓存策略(Cache Policy)。
然后将用户传入的 options.resource作为实际要执行的方法,通过 CachePlicyHandler()方法传入并执行。
上图中,我们需要定义各种缓存库操作方法(如读取、设置缓存的方法)和各种缓存策略的处理方法。
当然也可以集成如 Logger等辅助工具,方便用户使用和开发。本文就不在赘述,核心还是介绍这个方案。
五、总结
本文与大家分享 cacheables 缓存库源码核心逻辑,其源码逻辑并不复杂,主要便是支持各种缓存策略和对应的处理逻辑。文章最后和大家归纳一种通用缓存库设计方案,大家有兴趣可以自己实战试试,好记性不如烂笔头。
思路最重要,这种思路可以运用在很多场景,大家可以在实际业务中多多练习和总结。
六、还有几点思考
1. 思考读源码的方法
大家都在读源码,讨论源码,那如何读源码?
个人建议:
- 先确定自己要学源码的部分(如 Vue2 响应式原理、Vue3 Ref 等);
- 根据要学的部分,写个简单 demo;
- 通过 demo 断点进行大致了解;
- 翻阅源码,详细阅读,因为源码中往往会有注释和示例等。
如果你只是单纯想开始学某个库,可以先阅读 README.md,重点开介绍、特点、使用方法、示例等。抓住其特点、示例进行针对性的源码阅读。
相信这样阅读起来,思路会更清晰。
2. 思考面向接口编程
这个库使用了 TypeScript,通过每个接口定义,我们能很清晰的知道每个类、方法、属性作用。这也是我们需要学习的。
在我们接到需求任务时,可以这样做,你的效率往往会提高很多:
- 功能分析:对整个需求进行分析,了解需要实现的功能和细节,通过 xmind 等工具进行梳理,避免做着做着,经常返工,并且代码结构混乱。
- 功能设计:梳理完需求后,可以对每个部分进行设计,如抽取通用方法等,
- 功能实现:前两步都做好,相信功能实现已经不是什么难度了~
3. 思考这个库的优化点
这个库代码主要集中在 index.ts中,阅读起来还好,当代码量增多后,恐怕阅读体验比较不好。
所以我的建议是:
- 对代码进行拆分,将一些独立的逻辑拆到单独文件维护,比如每个缓存策略的逻辑,可以单独一个文件,通过统一开发方式开发(如 Plugin),再统一入口文件导入和导出。
- 可以将
Logger这类内部工具方法改造成支持用户自定义,比如可以使用其他日志工具方法,不一定使用内置 Logger,更加解耦。可以参考插件化架构设计,这样这个库会更加灵活可拓展。
以上是关于浏览器缓存库设计总结(localStorage/indexedDB)的主要内容,如果未能解决你的问题,请参考以下文章