深入浅出前端监控
Posted 全栈修仙之路
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深入浅出前端监控相关的知识,希望对你有一定的参考价值。
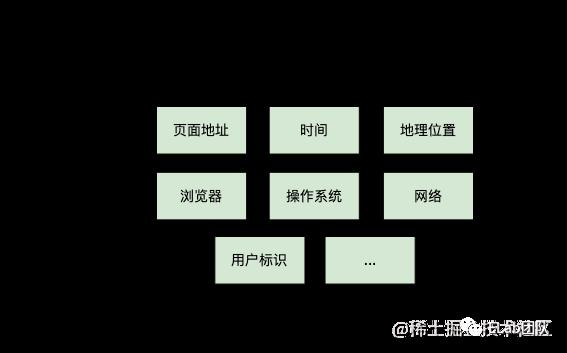
采集的监控数据一般都会设置一些通用的环境信息,这些环境信息可以提供更多的维度以帮助用户发现问题和解决问题。下图列举了一些常见的环境信息:
JSON.parse 解析出错或浏览器兼容性问题导致,属于运行时错误并非编译时错误。
对于异常监控我们主要关注 JS 运行时错误,多数场景下的处理手段如下:
| 错误场景 | 如何上报 |
|---|---|
| 场景一:自行感知的同步运行时异常 | try-catch 后进行错误上报 |
| 场景二:没有手动 catch 的运行时异常(包括异步但不包括 promise 异常) | 通过 window.onerror进行监听 |
| 场景三:自行感知的 promise 异常 | promise catch 进行捕获后进行错误上报 |
| 场景四:没有手动 catch 的 promise 异常 | 监听 window 对象的 unhandledrejection 事件 |
整体来看,监控 SDK 会在全局帮助用户去捕获他们没有自行感知的异常并上报,对于自行捕获的异常一般会提供手动上报接口进行上报。
方法中处理。
资源加载异常触发的 error事件不会冒泡,因此使window.addEventListener(\'error\', cb,true)在事件捕获阶段进行捕获。
第一种方式侵入性太强,不够优雅,目前主流方案均采用第二种方式进行监控:
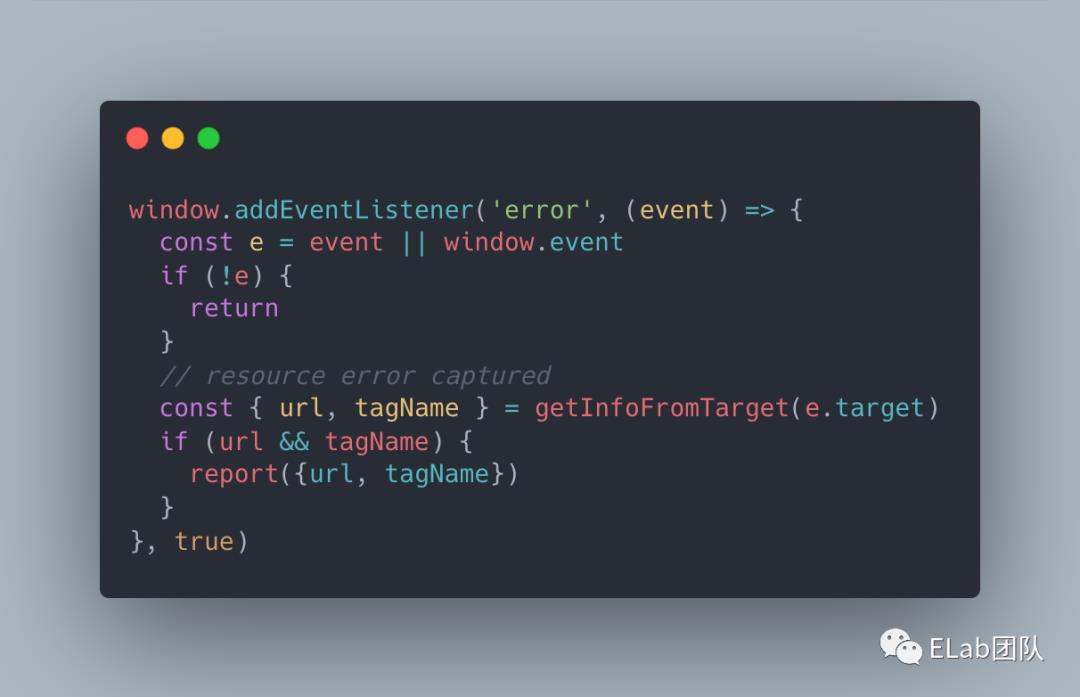
捕获静态资源加载异常
对象和APM 平台一般会有所有静态资源加载的明细,其原理是通过 PerformanceResourceTiming API 来采集静态资源加载的基本情况,这里不做展开。
fetch 方法进行重写,从而在代理对象中实现状态码的监听和错误上报: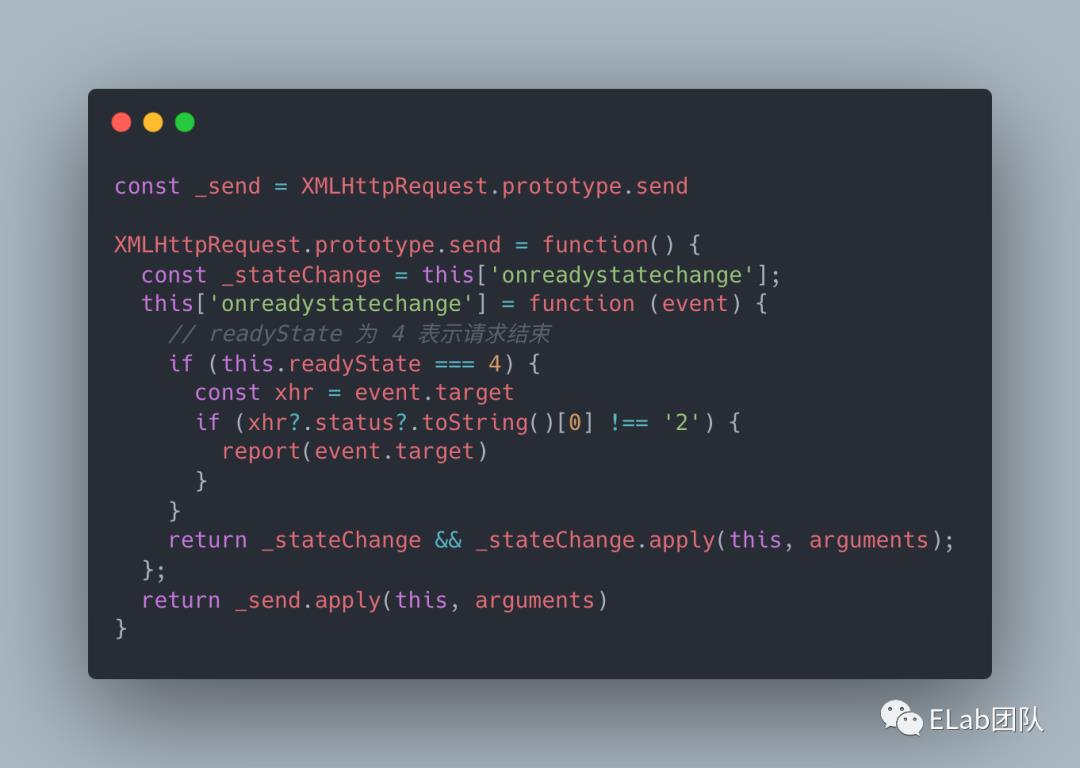
重写 XMLHttpRequest 对象
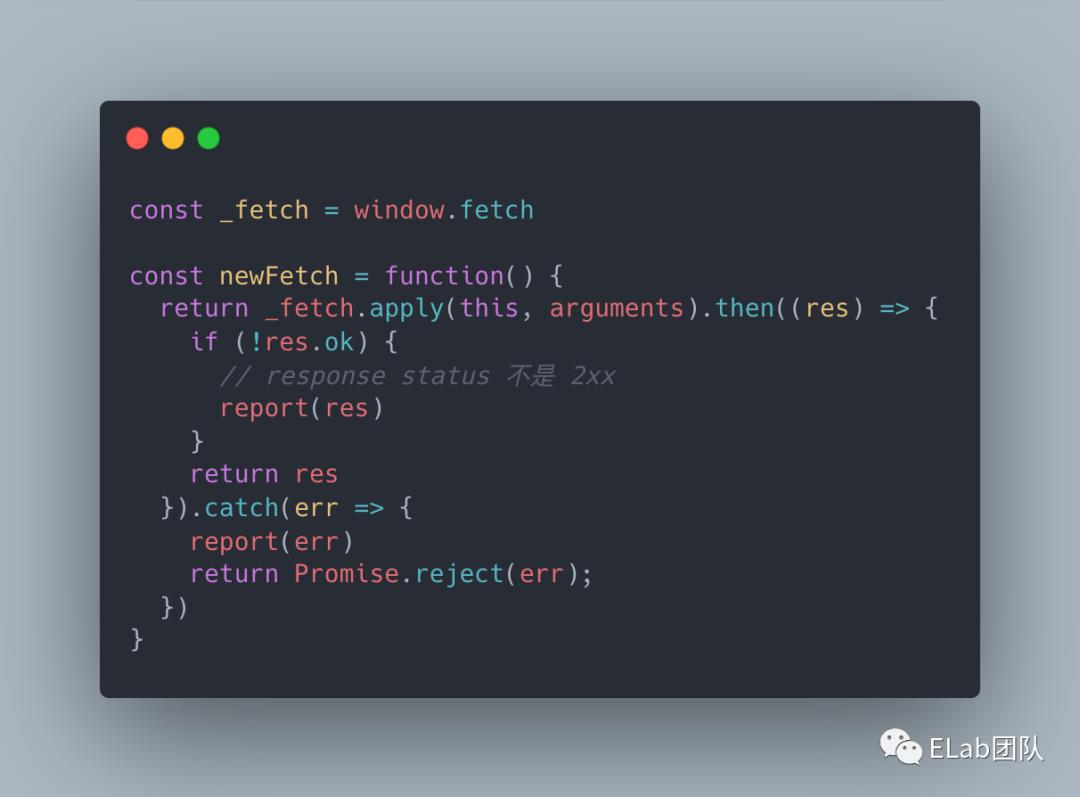
重写 fetch 方法
当然了,重写上述方法后除了异常请求可以被监控到之外,正常响应的请求状态自然也能被采集到,比如 Slardar 会将对所有上报请求的持续时间进行分析从而得出慢请求的占比:
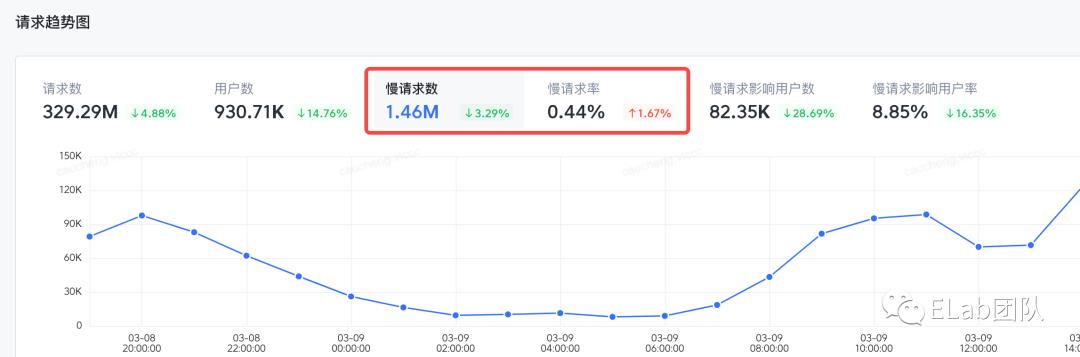
方法模拟实现,浏览器会在下一次重绘之前执行PS:如果通过 XHR 或 fetch 来上报监控数据的话,上报请求也会被被拦截,可以有选择地做一层过滤处理。
rAF 的回调,因此可以通过计算每秒内 rAF 的执行次数来计算当前页面的 FPS。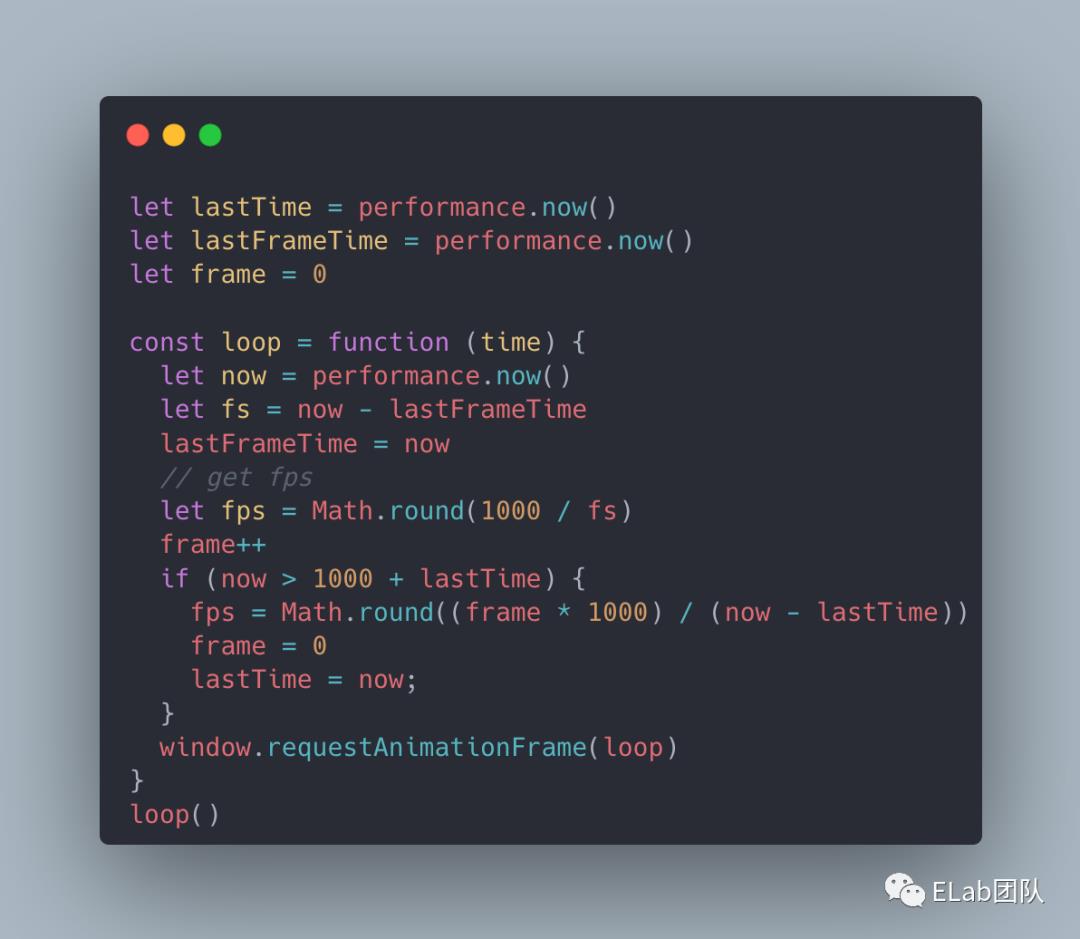
通过 rAF 计算 FPS
FPS 持续低于预期:当前页面连续 3s FPS 低于 20。用户操作带来的卡顿:当用户进行交互行为后,渲染新的一帧的时间超过 16ms + 100ms。
性能监控并不只是简单的监控“页面速度有多快”,需要从用户体验的角度全面衡量性能指标。(就是所谓的 RUM 指标)目前业界主流标准是 Google 最新定义的 Core Web Vitals:
加载(loading) :LCP 交互(interactivity) :FID 视觉稳定(visual stability) :CLS 可以看到最新标准中,以往熟知的 FP、FCP、FMP、TTI 等指标都被移除了,个人认为这些指标还是具备一定的参考价值,因此下文还是会将这些指标进行相关介绍。(谷歌的话不听不听
Sentry 前端监控系列
之前在做前端监控的时候,研究了一下sentry的源码,颇有启发。这次又准备做前端监控,所以借此机会想深入了解一番。但是此之前,我想谈谈自己对前端监控的一些思考。
前端监控到底要监控什么
基于数据驱动原则,我们需要统计线上项目中,用户的行为和使用情况,从而更加贴近用户,为我们的决策提供相应的数据支持,更好地迭代升级我们的产品,创造用户价值。
既然如此,研发同学以及业务方对前端监控的诉求应该有:
- 主动监控,并提供告警功能
- 性能数据的采集,并提供慢会话的日志分析
- 错误,异常数据的采集
- 能重现用户行为
而目前,对于我们来说,需要做的前端监控包括: 异常监控,指标监控,埋点监控
异常监控
由于前端代码的执行环境非常复杂,很难保证在不同的环境下不出现问题,而且有些问题往往是因为浏览器或者操作的原因,难以复现,所以我们需要收集异常数据,方便快速定位问题。
指标监控
什么是指标呢,我理解的应该是衡量我们项目工程化能力的数据。比如记录FCP作为我们的白屏时间,LCP作为首屏时间等等。通过这些数据我们得知我们是否需要对项目进行优化。
埋点监控
这个主要是与业务相关,比如我们会需要记录我们投放的营销页面的转化率,用户进入我们的页面之后,点击了什么按钮,将页面滚动到了什么位置,等等。用于还原用户行为的信息记录,为业务方提供业务调整的方向和依据。
接下来
因为内容会比较多,所以准备分好几篇文档来阐述。目前要写的有:
- sentry 的前端异常监控方案
- sentry的数据上报机制
// 其他的还没想好,待定中
以上是关于深入浅出前端监控的主要内容,如果未能解决你的问题,请参考以下文章
可以看到最新标准中,以往熟知的 FP、FCP、FMP、TTI 等指标都被移除了,个人认为这些指标还是具备一定的参考价值,因此下文还是会将这些指标进行相关介绍。(谷歌的话不听不听
Sentry 前端监控系列
之前在做前端监控的时候,研究了一下sentry的源码,颇有启发。这次又准备做前端监控,所以借此机会想深入了解一番。但是此之前,我想谈谈自己对前端监控的一些思考。
前端监控到底要监控什么
基于数据驱动原则,我们需要统计线上项目中,用户的行为和使用情况,从而更加贴近用户,为我们的决策提供相应的数据支持,更好地迭代升级我们的产品,创造用户价值。
既然如此,研发同学以及业务方对前端监控的诉求应该有:
- 主动监控,并提供告警功能
- 性能数据的采集,并提供慢会话的日志分析
- 错误,异常数据的采集
- 能重现用户行为
而目前,对于我们来说,需要做的前端监控包括: 异常监控,指标监控,埋点监控
异常监控
由于前端代码的执行环境非常复杂,很难保证在不同的环境下不出现问题,而且有些问题往往是因为浏览器或者操作的原因,难以复现,所以我们需要收集异常数据,方便快速定位问题。
指标监控
什么是指标呢,我理解的应该是衡量我们项目工程化能力的数据。比如记录FCP作为我们的白屏时间,LCP作为首屏时间等等。通过这些数据我们得知我们是否需要对项目进行优化。
埋点监控
这个主要是与业务相关,比如我们会需要记录我们投放的营销页面的转化率,用户进入我们的页面之后,点击了什么按钮,将页面滚动到了什么位置,等等。用于还原用户行为的信息记录,为业务方提供业务调整的方向和依据。
接下来
因为内容会比较多,所以准备分好几篇文档来阐述。目前要写的有:
- sentry 的前端异常监控方案
- sentry的数据上报机制
// 其他的还没想好,待定中
以上是关于深入浅出前端监控的主要内容,如果未能解决你的问题,请参考以下文章