蓝昶:谷歌分布式机器学习优化实践
Posted DataFunTalk
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了蓝昶:谷歌分布式机器学习优化实践相关的知识,希望对你有一定的参考价值。


编辑整理:何文婷 字节跳动
出品平台:DataFunTalk
导读:随着机器学习模型和数据规模的增长,大规模分布式机器学习训练的性能越来越成为公有云用户关注的问题。本文将介绍谷歌云 Vertex AI 平台在分布式机器学习训练性能优化方面做的一系列工作。
具体将围绕以下几点展开:
训练优化的背景
Fast Socket: NCCL的高性能网络栈
用Reduction Server加速梯度聚合
1. Google Vertex AI平台简介
Vertex AI是Google的一站式托管云服务,是一个集成了AutoML和AI Platform的AI机器学习以及服务平台。Vertex AI覆盖了从数据到特征工程、模型训练,超参调整和模型预测以及可预测性支持在内的一系列的需求。接下来的分享主要是聚焦在模型加速的技术部分。
2. 训练优化的背景
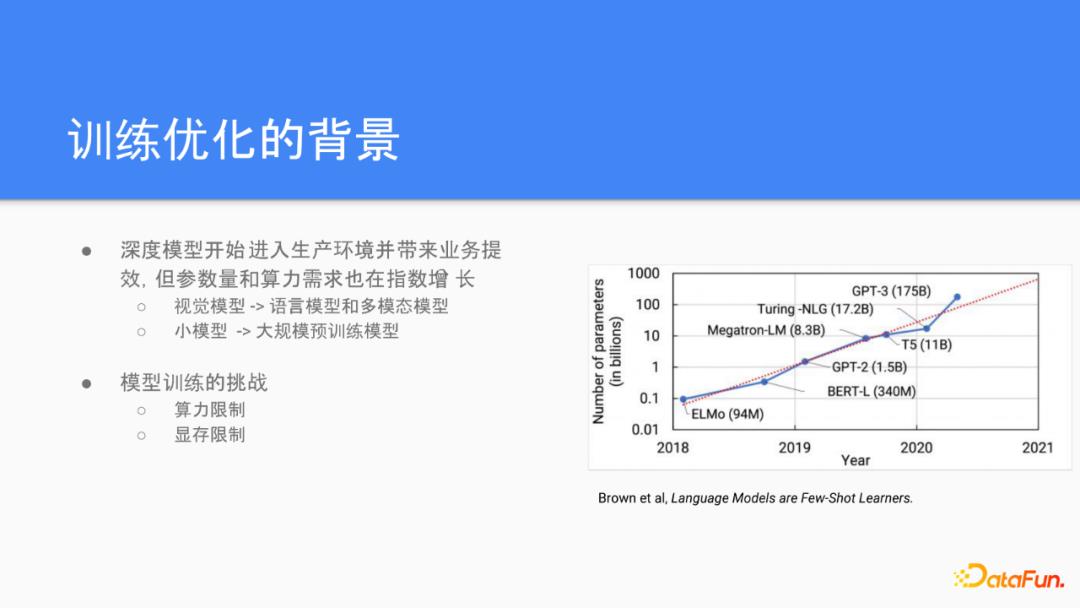
我们先回顾一下我们为什么需要做分布式的训练,以及我们作为一个平台为什么需要关注这个问题。最近几年我们可以看到深度模型最开始是在学术界的各个任务上取得了一些SOTA的突破,我们最近几年也看到这些应用开始渗入到企业级的用户,并且带来实实在在的业的提效。
云平台上的负载也从最初的视觉模型开始,现在变得非常多样,语言模型跟多模态模型也逐渐增多。随着大规模训练模型,语言模型在各个任务上的效果也实现了突破的话。我们看到用户的模型负载规模也是在指数的增长。支持这些海量的大规模型的训练,也给我们带来一些新的挑战。简单来说,单卡训练不再是主流,训练大模型所需要的算力在指数增长,所以单卡不足以在足够的时间里面输出足够的算力。此外,由于GPU显存的限制,除非通过一些跟主存进行数据交换的一些trick,简单的单卡训练也不再可行。在这种情况下,分布式训练作为一种水平扩展的解决方式,是目前主流的选择。从目前扩展的方式来看,我们最早遇到的是算力的限制,所以我们最早是在主流的框架里面看到很多数据并行的一些API支持。现在随着模型规模的继续增大,模型并行以及混合并行也开始进入主流的AI框架的开发路线。
3. 水平扩展的挑战:内存墙
图2水平扩展面临的一个根本的挑战是内存墙的问题。这个问题有两个方面,首先我们可以看到,内存带宽是在长期来看是慢于显著慢于算力的增长,在过去的20年里面计算的算力提升了九万倍,但内存的带宽只提高了30倍,这是一个根本的差距,并且差距会越来越大。其次,广义的内存带宽既包括片上的内存带宽,也包括片间的互联带宽,还有网络带宽。这几类带宽的长期趋势也都面临内存墙的问题。我们从这个图里面可以看到,内存带宽,高速互联带宽跟网络带宽之间也是一直存在着数量级上的差距,所以随着训练规模的不断增大,训练的性能瓶颈最终会落到网络带宽上。由于有这两个方面的影响,如果只是依靠硬件本身的发展,模型规模很快就会撞到内存墙,这也就是为什么我们需要在框架跟算法方面做更多工作的大背景。那么从一个云平台的角度来看,我们做性能优化工作的首要目标当然是提升性能,为用户降低TCO,其次,我们希望做到非侵入式的优化,做到框架无关,让用户保持选择框架的自由度。
在实际的场景里面,我们可以看到内存墙对于训练性能的影响。上图显示了一个例子,在单机跟多机的场景下,对于同一个模型的单步训练时间的比较,由于在多机跟单机之间计算跟参数更新的时间大体是恒定的,真正拖慢训练时间的是梯度聚合这一步,占用了大概2/3的时间,所以all-reduce往往是分布式训练的性能瓶颈。
4. 训练优化的技术路径

关于深度的分布式训练,主要工作主从技术栈上呈现从浅层到深层的一个过程。前三类的优化基本上是处于框架层,需要平台为用户提供基础的框架支持。比如说在计算图的并行化策略方面,我们通过GSPMD和GPipe提供了包括数据并行、模型并行和流水线并行的通用化的并行化策略的抽象层。此外,我们通过DeepSpeed来做支持,用ZeRO (Zero Redundancy Optimizer)来优化Optimizer的显存使用,以及我们可以用低精度的压缩来加速参数的同步。在本次的分享里面,我会重点分享最后一类的优化,也就是在集合通信层的一些优化。在AI框架的设计里面,这是讨论的比较少,但是对于一个平台来说是非常重要的一类优化。
首先对于基础设施的优化往往是需要有一个全局的提效,其次这类优化对于用户跟上层的框架完全透明,不需要改动上层的代码就能够真正落地。我们接下来通过一些具体的例子来看如何以集合通信层为入手点来做这一类的优化。
5. NCCL简介
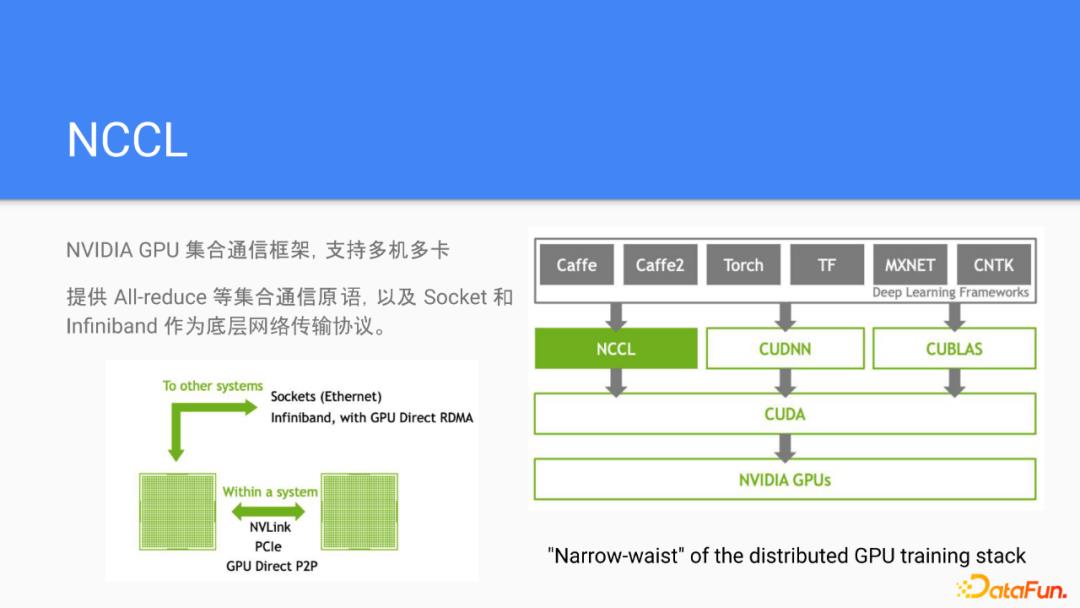
在GPU的训练场景里面,集合通信往往跟NCCL是同义词。NCCL是NVIDIA实现的一个集合通信库,它提供了像allreduce, allgather, broadcast等集合通信原语以及高性能的实现,用来支持多机多卡的训练。对于节点内通信,支持NVLink,PCIE和device P2P等方式;对于节点间通信支持像Socket和Infiniband等网络协议,并且网络协议可以支持通过用插件的形式来扩展。从软件栈的角度来看,NCCL对主要的训练框架都提供了支持,并且是主流框架默认使用的GPU的通信库。拿网络的协议站做一个类比的话,NCCL基本上跟IP协议一样,是整个协议栈的narrow waist的位置。
我们认为NCCL特别适合用来作为框架无关的性能提升的着力点。具体到几个通信的优化,我们可以分为两类,一类是对于底层通信网络栈的优化,而另一类是对于几个通信算法的优化。那么接下来我们将会用两个例子来分享我们在这两个方面做的工作。
首先我们要介绍的工作是我们对NCCL实现了一个高性能的底层网络栈。为什么需要做这方面的工作呢?我们前面提到NCCL用了非常多巧妙的设计和底层的优化来实现高性能的集合通信,但是它具体的实践还有很多需要提高的地方,对此我们对大消息和小消息做分别的讨论。
1. 提高大消息的吞吐率

对于大消息的传输,重点是需要提高吞吐,但我们实测发现,在高带宽非RDMA的环境里面,NCCL的网络吞吐性能往往不尽如人意,所以在100G的以太网环境里面,实际用到的带宽远远达不到line rate,因此有巨大的提升空间。NCCL的默认实现其实也考虑了如何使用高带宽网络的问题。首先它的默认实现是在多个节点之间的每个环,NCCL都会建立多个TCP的链接来并行传输消息,此外它本身也会使用多个Ring来处理集合通信的请求(Ring是NCCL里面自己定义的一个概念,可以理解为是一个独立的通道,每个通信通道也需要独立的占用CPU跟GPU的kernel资源)。但是这种简单的使用大量连接的方式对于大消息的吞吐率效果并不理想,原因有两个:
使用大量连接和Ring会占用CPU跟GPU的资源,反而会影响到计算本身的速度,并且会增加性能的抖动。
在实际的网络环境里面,不同的TCP流,它的带宽占用并不一致,所以会导致straggler effect,所以其他已经完成的流会等需要等待最后最慢完成的流,成为性能的瓶颈。

我们可以仔细看一看NCCL的传输层的实现,简单把它抽象成右边这个图里面显示的这么一个结构。当NCCL获得最上层的传输请求之后,他会用Proxy的线程将准备传输的消息切片,然后用Round Robin的方式把切片后的数据交给Helper线程,通过不同的Socket发送到对面的节点。理想的情况下,Socket之间的带宽相会是相等的,所以这种方式看起来应该是没有什么问题。但实际的数据中心网络里面影响带宽的方式很多,像如果是有multi-path的话,不同的connection会被路由到不同的path上,路由器的buffer占用也不一样,所以就会导致不同的连接的带宽并不均等,所以大消息的吞吐率往往会被这样的straggler连接给拖慢。
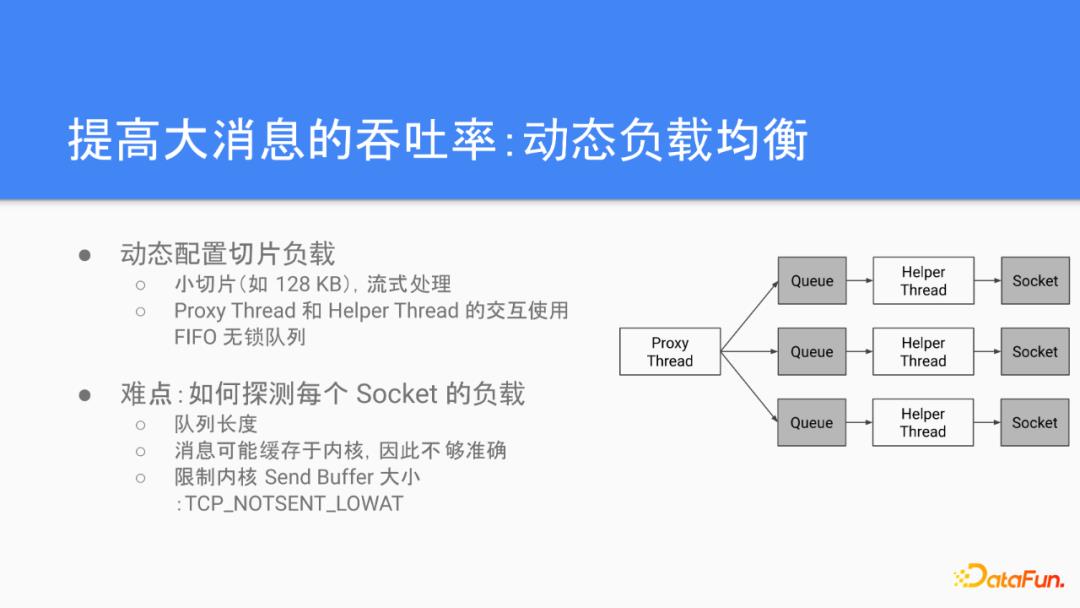
为了解决这个问题,我们采用了动态负载均衡的办法。首先我们在NCCL原有架构的基础上,继续做细粒度的数据切分,流式地处理数据切片,其次,我们改变了原来Proxy线程通过Round Robin分配负载的做法,通过感知每个Socket当前的负载量和进度,把负载分配到最快的Socket之上,这里的难点就应该如何感知每个Socket的负载。这里一个小背景是Socket线程和Helper线程之间使用的是个一个无锁队列进行数据交互,一个很自然的想法就是说我们希望看看每个线程对应的队列长度,缓冲区的长度越长,说明对面对应的Socket越慢,反之就越快。这也是我们最初的版本采用的一个做法,但是实际上我们发现效果提高有限。原因在于除了用户态的无锁队列之外,数据还可以在内核的Socket的缓冲区被缓冲,所以你如果只看队列的长度,并不能准确地反映出Socket的当前的负载。修复这个问题也很简单,我们通过调整内核Socket的参数可以关闭发送的缓冲区,这样就可以让信号的反馈更加准确。此外,我们通过压缩缓冲区的大小也可以控制在大量使用Socket的情况下。对于内核内存的占用,总体上对于性能也是有帮助的。

除了动态负载均衡,我们还改进了NCCL对于请求的处理方式。NCCL本来的实现是不能并行处理传输的消息的,它只能在完成当前的请求之后才能处理下一个请求。我们改进了这个方式,通过实现对请求队列的look ahead处理,可以流式地处理这个变行请求。另外,我们开启了发送端的zero copy来降低用户态到内核态的拷贝开销,对于大于十KB的消息,我们实测会有有明显的提升效果。
2. 降低小消息的延迟

对于小消息,我们重点关注的是降低延迟。前面提到消息的发送是需要通过Proxy线程到helper线程的数据交换,每一次的发送都会引起多次的线程唤醒,跟上下文切换,造成比较大的开销。我们解决这个问题的方法是通过Proxy线程直接控制Socket的发送,避免线程切换的开销。
为了实现这个优化,我们也重新设计了NCCL控制消息的结构以及传输控制消息的方法。在数据消息足够小的时候,我们可以相当于是把消息内inline在控制消息里面,通过proxy直接发送。
最后我们也引入了内核的Busy polling用于控制socket,让内核来动态的来poll socket可以明显地降低小消息的延迟跟抖动。
3. End to end 测试

之前介绍了我们具体做的一些优化的措施,我们也测试了NCCL在64M到1G的消息大小上,对于all-reduce的网络吞吐率,可以看到经过Fast Socket的优化之后,NCCL在各个大小的带宽测试里面都取得了60%以上的加速比。在实际的100G以太网络里面,实际带宽也能跑到将近line rate的数字。
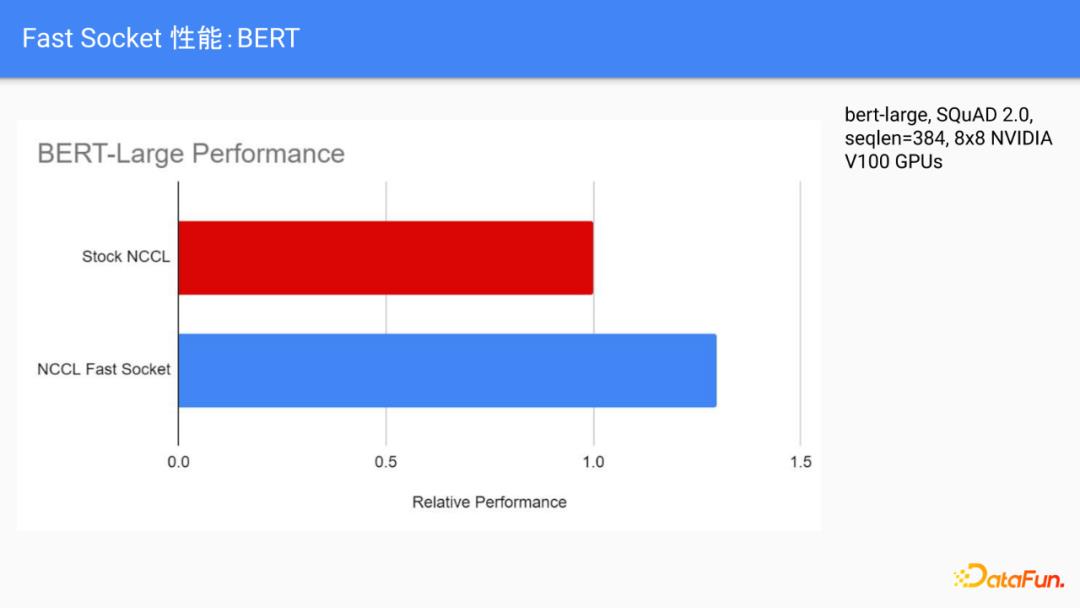
对于end to end的性能测试,Fast Socket也能取得一个比较明显的提速。图中显示的是在Fine-tune BERT-Large这种模型的时候,Fast Socket可在每秒训练的步数上会有大概30%以上的提速。这种提速是面向全平台的,所以我们不需要用户侧做任何的改动,就能让用户实际的落地加速的效果。
4. 小结

我们在此对Fast Socket做一个简单的小结。Fast Socket是我们为NCCL在高带宽的网络环境里面实现的一个优化的网络栈,因为这些优化都位于NCCL的通信层,所以支持所有的主流分布式的框架,并且能够做到全平台的加速。目前Fast Socket以插件的方式类似于Google Cloud的Deep Learning VM和Vertex AI等机器学习环境里,具体的实现代码,也以开源的形式开放给社区,欢迎试用和交流。
我们前面的提到的Fast Socket主要是用工程的方式对集合通讯层做了非常多细致的底层优化。在这个工作里面,我们换一个视角引出下一个工作,看看我们如何从改进集合通信算法的角度来加速梯度的聚合。
1. All-reduce简介

我们先给一个all-reduce的具体的例子来回顾all-reduce的语义,这里面每个worker的节点有一个等长的数组,在训练里面通常是对应于某个参数的梯度,因为在数据并行的训练里面,每个worker的训练输入的数据的批次不一样,梯度的数值也不同,因此我们需要对不同的批次的梯度求和,也就是对应于all-reduce的操作。操作完成之后,每个worker都会得到相同的结果。

所以总结来说,all-reduce的语义是:
规约所有节点上的数组,并且把这个结果返回到所有节点。
All-reduce有很多具体的实现,通常是可以由两步组合而成,通常分别是由reduce-scatter和all-gather的两步组合而成。Reduce-scatter完成之后,每个节点各自拥有N分之一完整规约过后的数据。
在右图这个例子里面,每个节点需要至少要发送(n-1)/n的数据,这一点非常容易证明。比如说在图中的例子,节点1,2,3分别要来自需要来自节点0的1/4的数据,所以这个节点0至少需要送发送3/4的数据,同样属于节点0规约的1/4的数据块需要来自节点1,2,3相同位置的数据块,所以它也至少需要接受3/4的数据。
下一步的all-gather则是将各个节点上1/4的规约结果发送到所有的节点。效果上等价于四次的broadcast。我们也很容易证明all-gather的每个节点也需要收发(n-1)/n的数据,因此all-reduce里面每个节点需要传输大概两倍于原始输入的数据。这个是个非常关键的结论,我们待会会回到结论来看看如何优化这一点。
2. All-reduce性能分析

我们可以通过这么一个简单的模型来分析all-reduce的性能。我们可以定义算法带宽为输入数据的大小除以all-reduce执行的时间。比如说每个节点的输入数据是1G,然后all-reduce用了一秒,算法带宽就是1G/秒。
我们可以把算法带宽拆分为两项,第一项是输入数据的大小除以实际在网络里面传输的数据,那么我们称为算法效率,这一项对于一个特定的算法是一个常数,对,比如说对于ring all-reduce来讲,这一项就是n/(2(n-1)),当节点数N非常大的时候,这个数相当于1/2,第二项就是实际传输的数据除以执行时间,也就是实际的网络或者说总线的吞吐率,我们称之为总线带宽。这一项也受到实际的硬件和协议栈的限制。
为了提高整个算法带宽,有两种思路:
用更新更好的硬件提高总线开关,然后再加上更优化的网络栈实现,比如说像我们刚才提到的fast socket,或者说用Infiniband RDMA等等。但是从我们刚才提到的内存墙的趋势,我们可以看到硬件带宽的增长始终是有限度的。
通过提高算法的效率,在这个场景下,也就是降低数据的传输量。一个可以证明的结论是all-reduce的算法效率理论上界是ring all-reduce目前的水平,也就是当N非常大,当工作节点的数量非常大的时候,大概就是1/2。我们的reduction server工作调整了all-reduce的一个设定,通过一个稍微不同的思路,算法效率提到了提高到目前的两倍。
3. Reduction Server

Reduction Server启发于parameter server的通信方式。在parameter server的架构里面,worker的节点在每个iteration只传输一次的参数数据。受到启发。就是说实际上我们可以想在all-reduce的框架里面,我们是不是也可以通过这种方式来做集合运算。我们的方式是引入了reduction server节点,它的通信拓扑跟parameter server是一致的,但是节点的实现更加简单,比如说节点,它不需要保存参数,也不需要计算梯度,它只要在每个action里面规约来自worker节点的梯度数据,并且返回给worker节点,通过这种方式,worker也只需要发送跟接收一次完整的完整的梯度数据,并且我们可以通过实现流式的规约,隐藏worker收发之间的延迟,充分的利用双向的带宽。
另外一个非常重要的点是,我们虽然增加了额外的节点数量,但是这些节点都是轻量级的CPU节点,总开销,如果用公有云的价格来看的话,总开销的节点开销是GPU节点的10%以内,并且还有一个优势是我们可以把这些轻量级的CPU节点跟他其他网络利用率低的节点混合部署,所以实际上增加的成本可以忽略不计。这个表里总结了跟传统的all-reduce算法相比,reduction server能做到的优势,首先它能把数据的传输量减半,也就是说算法带宽相当于是原来的两倍,另外一个优势是它能把延迟的量级从ring all-reduce的O(N)降到O(1),这一点是对于小消息的性能也是非常重要的。
我们来看看我们实现的方式,那么在worker的节点端,我们基于NCCL以下的通信层实现了一个到reduction server的通信层,所以我们可以在不改动框架的情况下实现从all-reduce到reduction server的无缝切换跟加速。在reduction server的节点端,我们基于Fiber实现了高性能的网络通信层。在这之上是一个轻量级的规约引擎。规则引擎的主要工作是通过高性能SIMD优化过后的算子对输入的数据进行规约。我们在规约引擎也实现了完整的数据类型支持,并且能够支持混合精度的压缩、规约。
4. 训练性能&TCO

最后我们看看reduction server对于训练性能的提升,我们可以看到它对于各个大小的消息的all-reduce操作都会有明显的性能提升。
在end to end的测试里面,相对于传统的ring all-reduce, reduction server可以把训练速度提升75%左右。除了纯粹性能方面的优化,下面这个表的例子里面我们可以看到,因为相当于说我们的速度变快了,我们花费的时间也少,所以就是说它实际上总成本也能降低。即使考虑了额外的CPU节点的开销在内,用户仍然可以大幅降低训练的TCO。

目前reduction server已经集成到Vertex AI的平台,用户无需改动代码就可以很方便地为目前自己已有的分布式训练任务开启reduction server的支持。我们在Vertex AI的平台的网站上也发发布了相应的博客文档以及Notebook的样例,有兴趣可以继续参考。

总结一下今天分享的内容,内存墙问题是目前大规模模型训练很难避开的一个问题,并且很有可能是一个长期的问题,只靠硬件的自然演进应该是不够的,所以这也是我们在框架的基础上,技术栈的各个层面做性能工作的一个大背景。未来随着业务模型的变化,我们也看到将会围绕着更多其他并情化策略的优化工作。今天我主要是从云平台的角度看,我们需要怎么样的性能优化工作,侧重分享的是跟框框架无关的底层的一些优化。但是我们也可以看到很多跟框架或者甚至模型强强耦合的一些性能工作,比如说Deep Speed或者Horovod。这实际上代表的是两种范式,也可以引出很多讨论,比如说我们在做一些上性能方面的设计的时候,是应该尽量做到平台无关,还是对于某个优化应该推出一个新的框架,或者更进一步,更好的性能是不是一个AI框架的核心竞争力,我想这些都是一些非常有意思的问题。今天我的分享就到这里,如果有问题的话也欢迎提出,谢谢大家。
今天的分享就到这里,谢谢大家。
在文末分享、点赞、在看,给个3连击呗~
分享嘉宾:

关于我们:
Angel:深度学习在腾讯广告推荐系统中的实践

分享嘉宾:郭跃超 腾讯 应用研究员
编辑整理:康德芬
出品平台:DataFunTalk
Angel机器学习平台
广告推荐系统与模型
模型训练和优化
优化效果
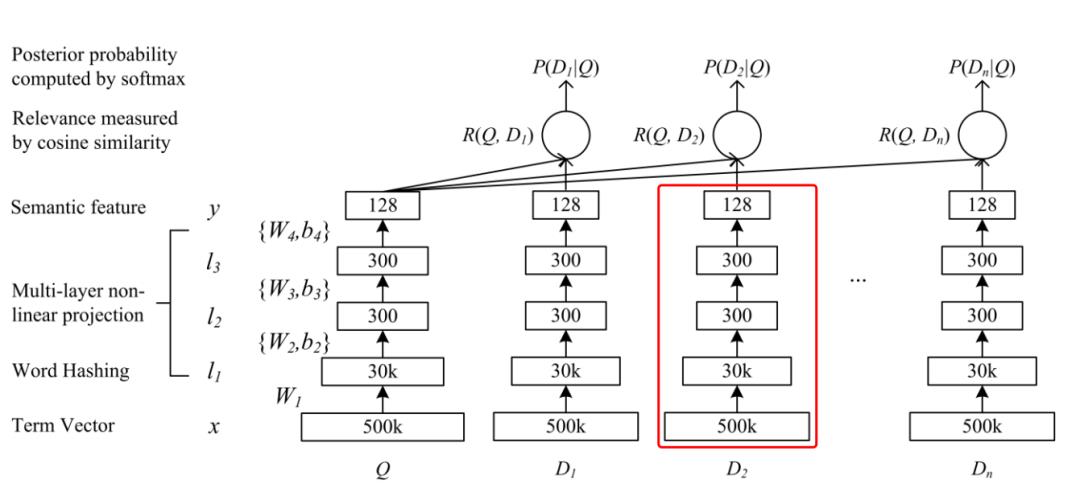
1. Angel机器学习平台架构
Angel机器学习平台是腾讯自研的基于传统Parameter Server架构的高性能分布式的机器学习平台如图1所示,详细架构图如图2所示。它是一个全栈机器学习平台,支持特征工程、模型训练、模型服务、参数调优等,同时支持机器学习、深度学习、图计算和联邦学习等场景。已经应用在众多业务如腾讯内部广告、金融和社交等场景,吸引了包括华为、新浪、小米等100多家外部公司的用户和开发者。
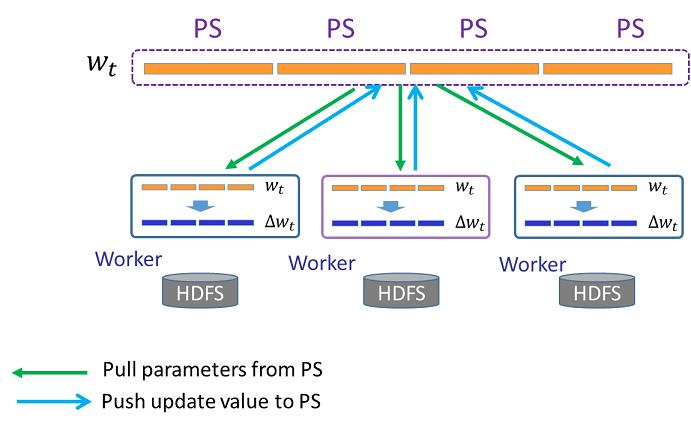
Angel机器学习平台设计时就考虑到了很多问题,首先是易用性,Angel机器学习平台编程接口简单,可快速上手使用,支持训练数据和模型的自动化切分,减少用户的干预,简单易用。然后是可扩展性方面,Angel提供了PsFun接口,继承特定的类可实现自定义参数更新逻辑和自定义数据格式和模型切分方式等。之后是灵活性,Angel实现了ANGEL_PS_WORKER和ANGEL_PS_SERVICE两种模式,ANGEL_PS_WORKER模式下模型的训练和推理服务由Angel平台自身的PS和Worker完成,这种模式主打速度。而ANGEL_PS_SERVICE模式下,Angel只启动Master和PS,具体的计算交给其他计算平台(如Spark,TensorFlow)负责,Angel只负责提供Parameter Server的功能,主打生态来扩展Angel机器学习平台的生态位。Angel通信模式支持BSP、SSP、ASP等通信协议,满足各种复杂的实际通信环境的要求。最后是稳定性,Angel的PS容错采用CheckPoint模式,Angel每隔一段时间会将PS承载的参数写入到分布式存储系统中,如果某个PS实例挂掉,PS会读取最后一个CheckPoint重新进行服务。Angel的Worker容错方面,如果Work挂掉,Master会重新启动一个Work实例,该实例会从Master上获取挂掉时参数迭代信息。Angel的Master任务信息也会定期存储到分布式存储系统中,如果Mater挂掉,会借助Yarn Master重启机制重新拉起一个Master并加载信息从之前的断点开始任务。Angel还有有慢work检测机制,如果某个Work运行过慢其任务会被调度到其他的Work上进行。
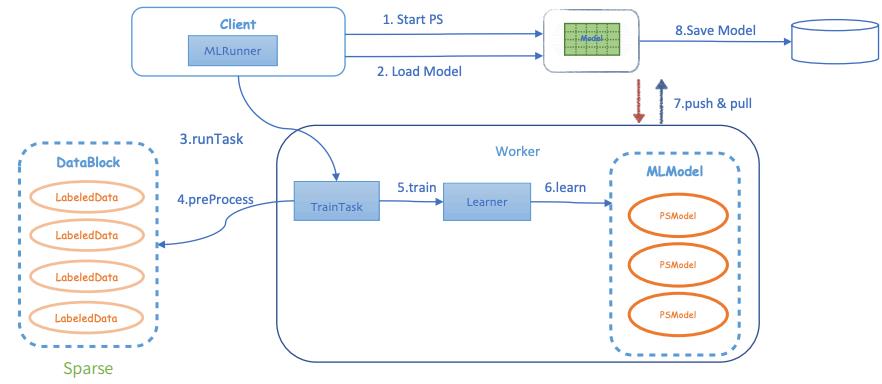
Angel机器学习平台任务提交执行简单,具体步骤如图3所示,进入Cient后,启动一个PS实例,该PS会从Client端加载模型,之后Client会启动多个Work,Work会加载训练数据开始训练和学习,push和pull会进行参数的拉取和更新,训练完成后将模型存入指定的路径。
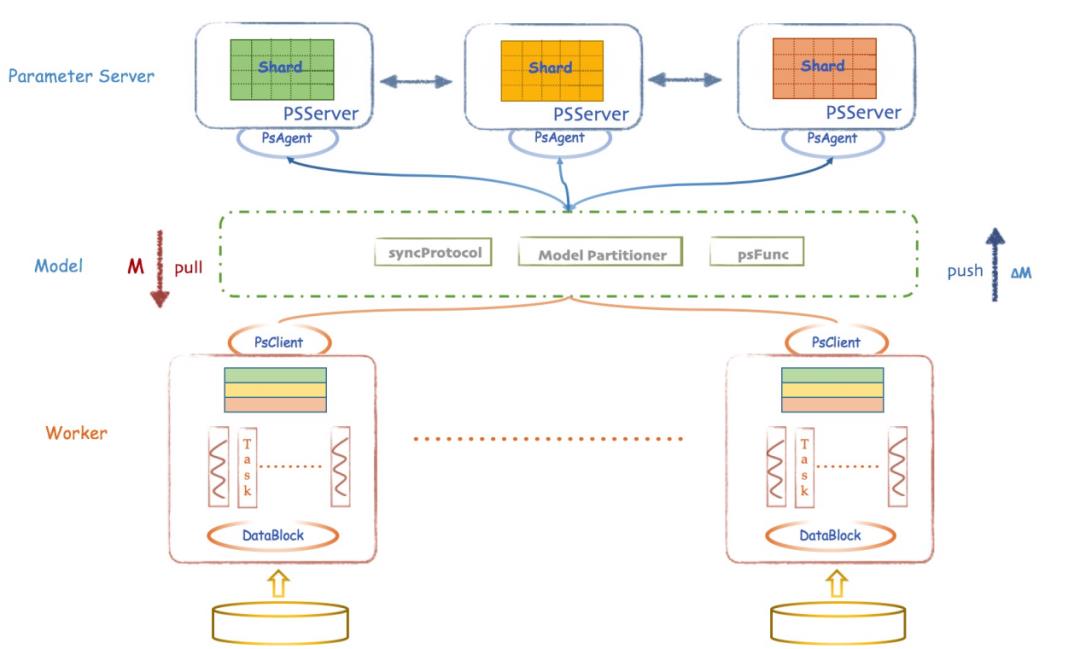
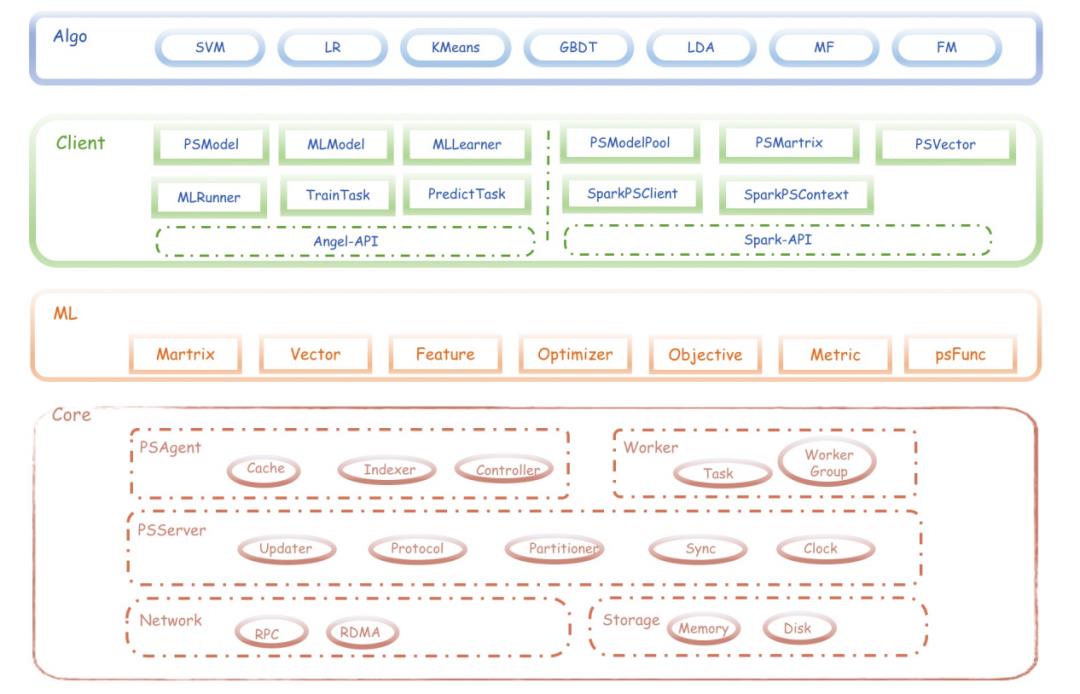
Angel机器学习平台在代码结构设计上做了很多的抽象,这样的设计方式可扩展性强,整个结构主要分为四层如图4所示。核心层(Angel-Core)是基础层,主要包括PSAgent、PSServer、Work、Network和Storage等。机器学习层(Angel-ML)提供基础数据类型和方法,同时用户可根据PsFunc定义自己的方法把私有模型接入。接口层(Angel-Client)可插拔式扩展,支持多种用途比如接入TensorFlow和pyTorch等。算法层(Angel-MLLib)提供了封装好的算法如GBDT、SVM等。
2. Angel机器学习平台在深度学习方向上的拓展和应用
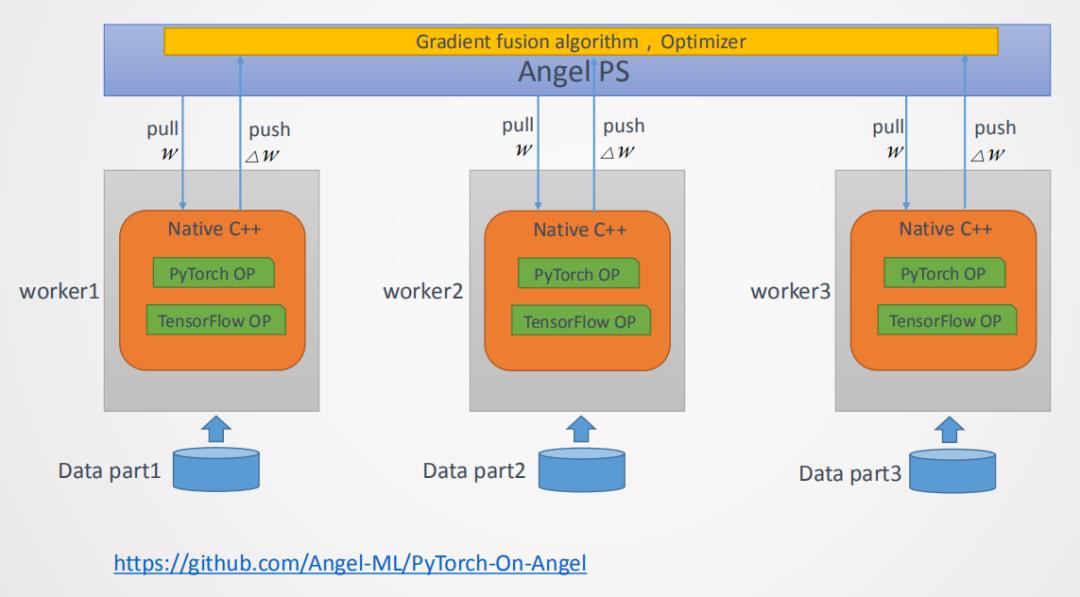
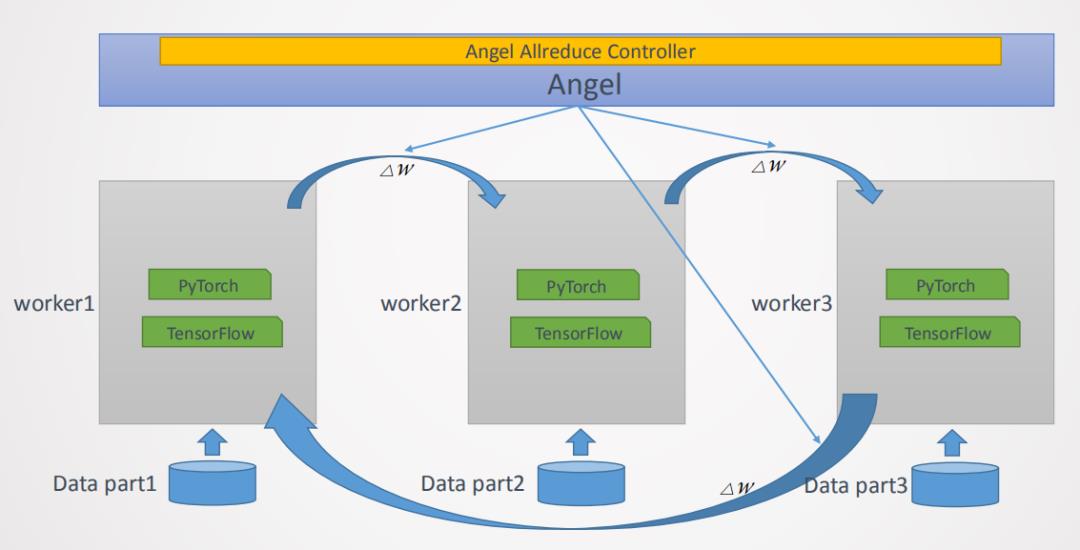
深度学习常用的分布式计算范式有两种,分别是MPI ( 基于消息模型的通信模式 ) 和Parameter Server,如图5所示。这两种范式均在Angel平台上有实现,对于Parameter Server范式的实现如图6所示,Angel Work可通过Native C++的API接口接入常用的深度学习的OP如PyTorch或者Tensorflow等,在训练的起始端Angel PS会把模型Push到每个Worker上,Worker会加载到对应的OP上进行训练,每次训练完成后会将梯度信息回传到PS上进行融合,以及应用优化器得到更新的参数,完成后又会分发到每个Worker上,重复上述过程直到训练结束,最终将模型保存到指定路径。这种方案Angel PS提供了一个梯度PS的控制器,来接入多个分布式的Worker,每个Worker上可以运行一些通用的深度学习框架例,这种方案PyTorch版本的工作我们已经完成,并已经开源了(PyTorch on Angel)。另外一种是MPI AllReduce范式如图7所示,这种范式梯度信息是通过AllReduce方法进行融合的,在这种范式的实现上,Angel PS是一个进程控制器,会在每个Work上拉起一个进程,这个进程可以是PyTorch或者是Tensorflow等进程,这种范式对用户侵入少,用户开发的算法不需要太多的修改即可接入到Angel平台进行训练。
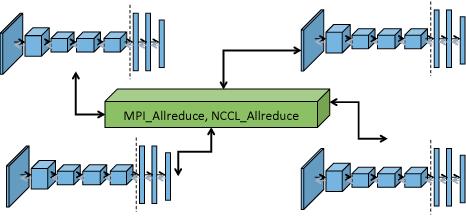
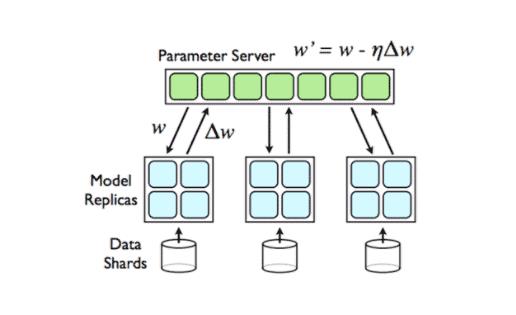
Parmeter Server范式
1. 腾讯的广告推荐系统
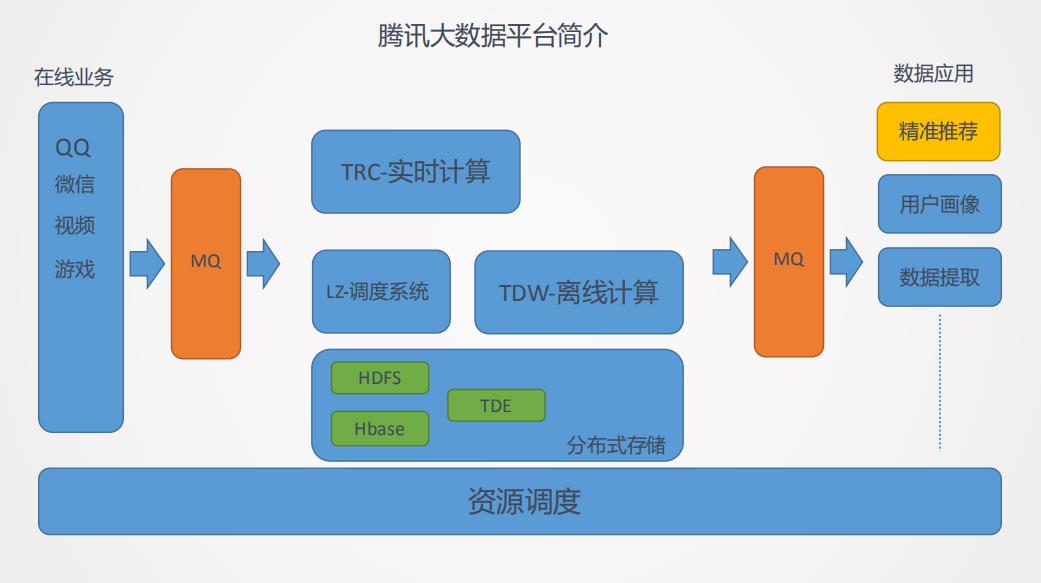
腾讯大数据示意图,如图8所示,在线业务的数据如微信游戏等会通过消息中间件实时地传递到中台系统,中台系统包括实时计算、离线计算、调度系统和分布式存储,这些数据有的会进行实时计算有的会进行离线计算,数据的应用也是从消息中间件中获取其需要的数据。
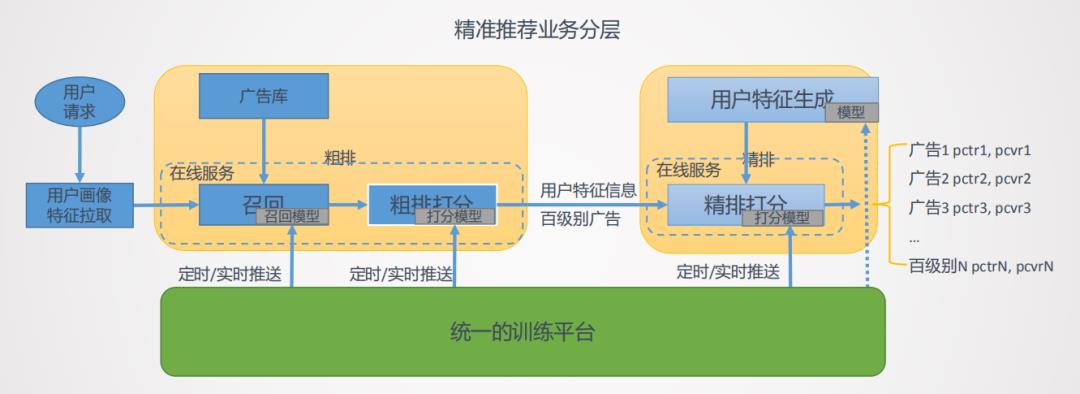
腾讯的推荐广告推荐系统业务分层如图9所示,用户发送一个请求后会去拉取用户地画像特征,之后会对广告库的广告进行一个初步地排序和打分,打分之后会提取用户地特征信息,同时将广告库的ID数量降为百级别,在这个百级范围内会有一个精细的排序,完成后将广告推送给用户。整个推荐系统面临着下面的几大挑战,首先是数据来源多样化,数据既有线上数据也有历史落盘数据。其次是数据的格式多元化,包括用户信息、Item信息、点击率和图像等数据的多元格式。然后是增量数据多,用户请求频繁,广告库也在不断更新中。最后是训练任务多元化,整个推荐系统涉及到粗排、精排、图像检测和OCR等任务。为了解决上述问题,我们在精准排序任务上开发了一整套的软件框架"智凌"(基于TensorFlow)来满足训练需求。
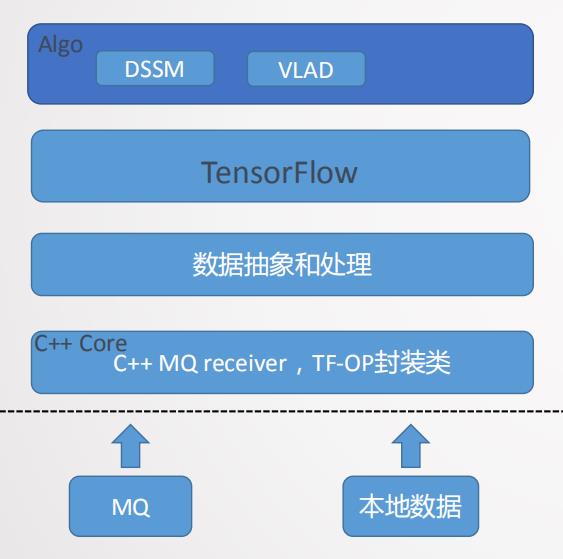
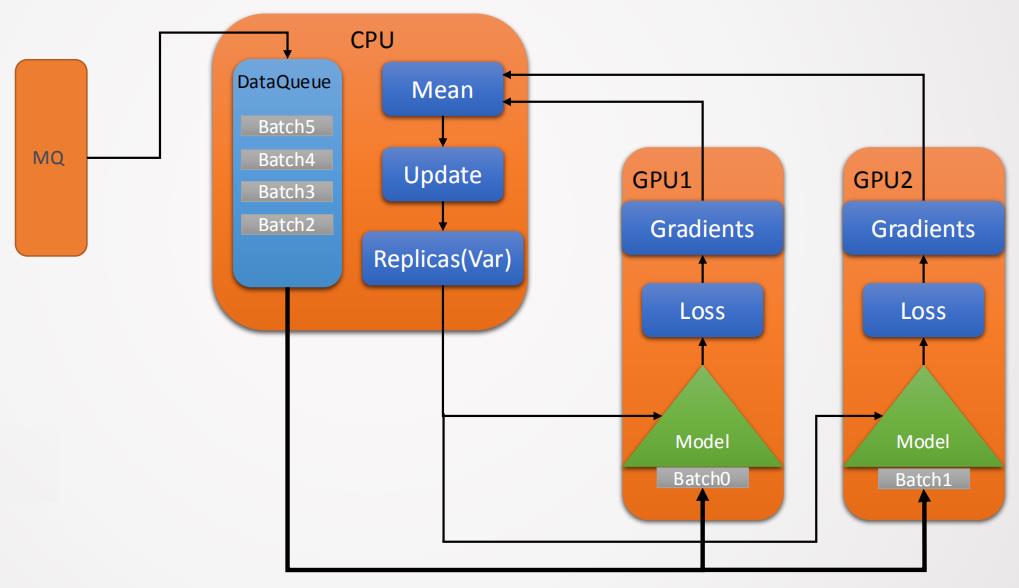
"智凌"框架结构如图10所示,该框架最底层C++ core封装了MQ receiver和深度学习框架的一些OP类,最典型的是TensorFlow的dataset类,通过封装tensorflow的dataset类来提供从MQ获取数据的能力。数据抽象和处理在C++和Python上完成。然后是深度学习的framework(tensorflow)层提供各种深度学习的库。最后是具体的应用模型如DSSM、VLAD和一些图像算法的模型等。"智凌"软件框架具有算法封装完整、开发新模型较快、数据和算法隔离解耦较好、预处理逻辑方便修改和更新及兼容性好等优点,但同时对于Tensorflow框架侵入性修改多、单机多卡性能差、多机分布式不支持、算法和OP层面优化不够完全等缺点。图11是"智凌"在基础数据上的训练流程图,从图中看到从消息中间件中读取数据到本地的DataQueue中,DataQueue给每个在GPU节点上的模型分发Batch数据然后进行训练,训练完成后读取到CPU进行梯度融合和备份然后分发给各个GPU进行再训练,这种设计是面向单机结构的设计,CPU去实现梯度的融合和优化器的功能,CPU资源消耗大,这种设计很不合理,针对这种情况我们做了很多的优化后面会向大家介绍。
2. 腾讯的广告推荐系统中的模型
DSSM增强语义模型如图12,在这里我们用该模型来计算用户和推荐ID之间的相关性并在此基础上计算用户对给定推荐ID的点击率,相关性和点击率计算公式分别是:

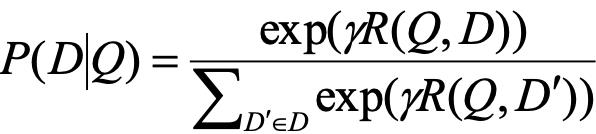
DSSM模型较为简单,分为Quey Id和Item Id并表达为低维语义向量,然后通过余弦距离来计算两个语义向量之间的距离。通过模型计算Query和Item之间的相关性,打分最高点就是我们要推荐的Item, 广告推荐系统中的DSSM模型要支持以下一些新的需求点:
ID类特征维度亿级别;
变化快,每周有25%是新条目,支持增量训练。
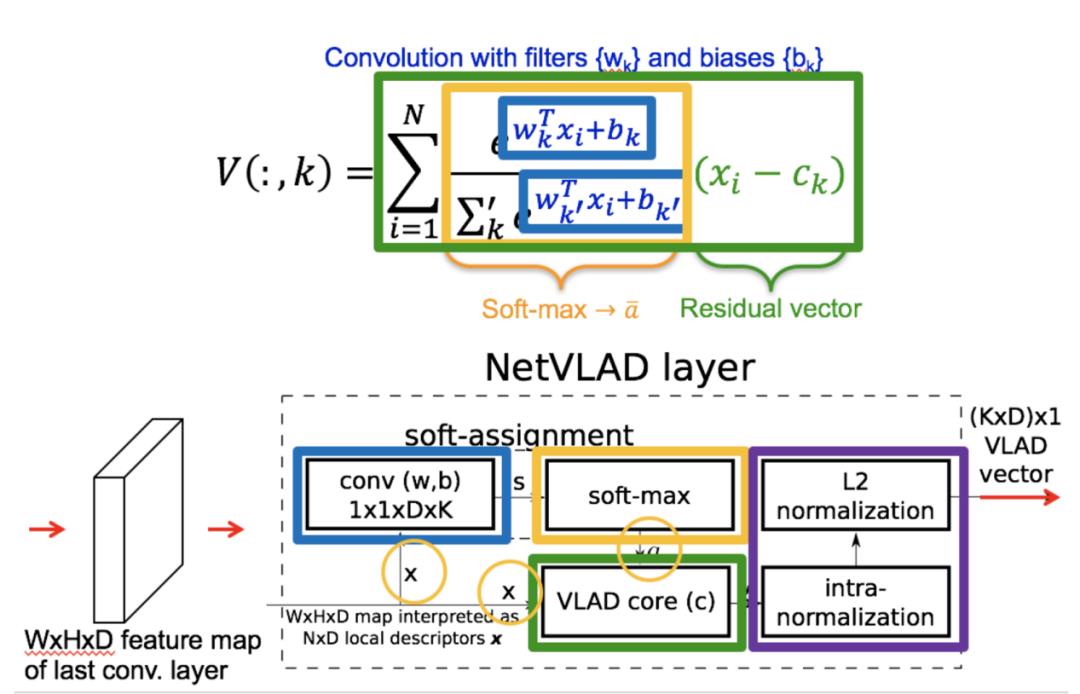
VLAD/NetVLAD/NeXtVLAD等模型我们主要用来判断两个广告之间的距离关系,传统的VLAD可以理解为一个聚类合并的模型,其向量计算公式为:
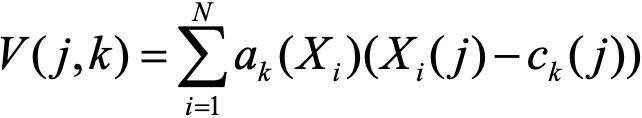
NeXtVLAD如图13则通过将ak符号函数变成一个可导函数来得到一个更好距离效果,NeXtVLAD的向量计算公式为:
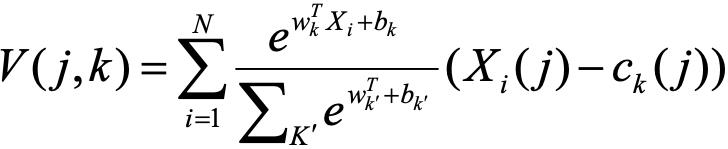
其中,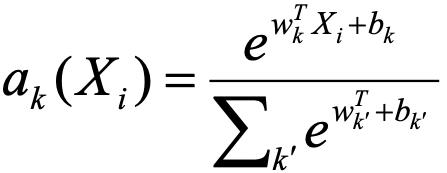 。
。
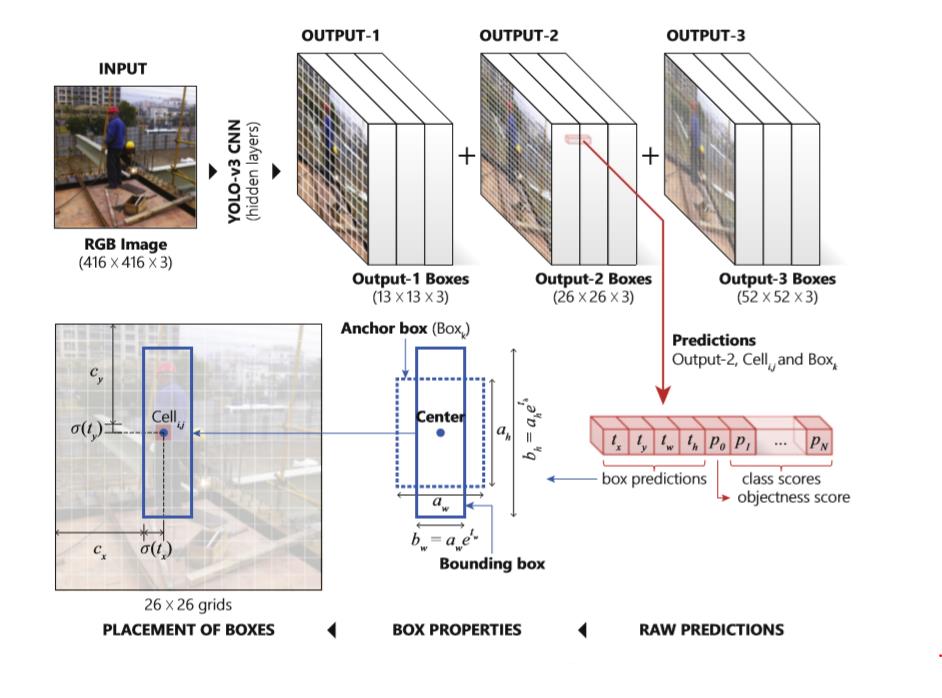
YOLO V3如图14是图像处理模型,在这里我们将其应用在OCR业务最前端做初检,它的特点是图片输入尺寸大(608*608,1024*1024),也因此YOLO模型的Loss部分占据比较大的计算。
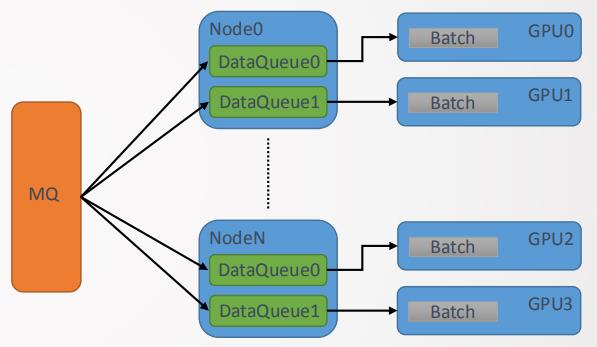
1. 数据流优化
前面的介绍中我们知道"智凌"软件框架是单管道数据流,现在我们将其优化为多管道如图15所示,即通过多机多数据流来解决单机IO瓶颈问题。原来的单管道数据中会有DataQueue,如果数据流很大会对IO造成很大的压力,优化为多对管道后为每一个训练进程GPU定义了一个DataQueue,通过这种分布式方法来有效解决IO瓶颈问题。这种情况下的管理工作是通过Angel PS(AllReduce版本)进程控制器来进行管理的。
2. Embedding计算优化
Embedding Lookup过程常会碰到如果在hash之前进行SparseFillEmptyRows操做会对空行填充默认值,增加过多的字符串操做,优化后我们先做hash操做然后再做SparseFillEmptyRows操做,去除耗时过多的字符串操作 ( 百万级别 ),节省CPU算力来提升QPS,此优化单卡性能约有6%的提升。
3. 模型算法层面优化
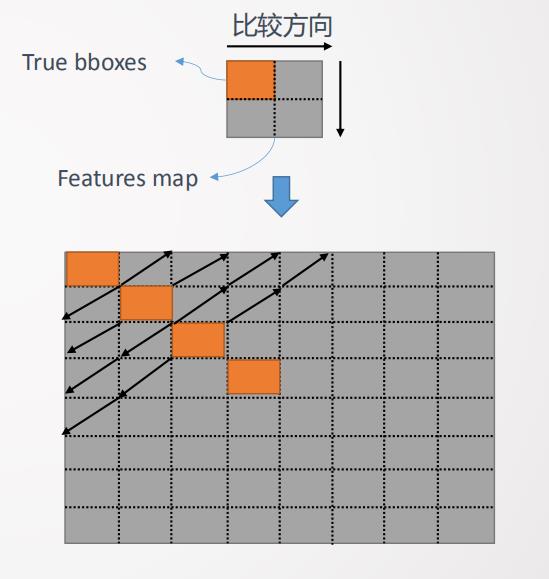
YOLO的Loss计算量较大,我们对其进行了特殊的优化。YOLO模型有三个Feature map层,传统寻找正负样本的时候,真正的Bounding box会在Feature map上会做一个遍历比较,先横向遍历然后再纵向遍历,遍历的过程中寻找Feature map点和Bounding box IOU最大的值作为正样本。因为图像的size很大,所以Feature map也很大,这使计算Loss耗时过长。计算Loss优化方法如下,由于x轴方向上的块和y轴方向上的块关于对角线对称,所以我们计算Feature map和Bounding box 的IOU的时候按照中轴线对角点方向进行遍历如图16所示。先计算对角线方向上的的块,然后再计算每个feature map块两边的块。这种优化方法可减少大量的计算量。另外,在某个点上向两边遍历所有的Feature map块的时候有一些计算技巧特点,比如往右上开始遍历的时候,x轴与y轴是关于对角线对称变化的,我们可以预估这种变化,从而有意识地去寻找最大的Anchor位置,然后丢弃其他信息,通过这样的优化方法也可以大量的减少计算量。我么通过上述方法优化了Loss计算之后单卡性能有约10%的提升。
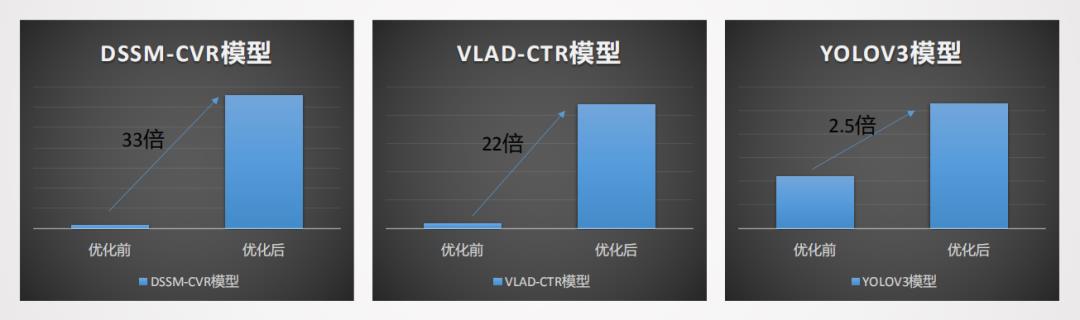
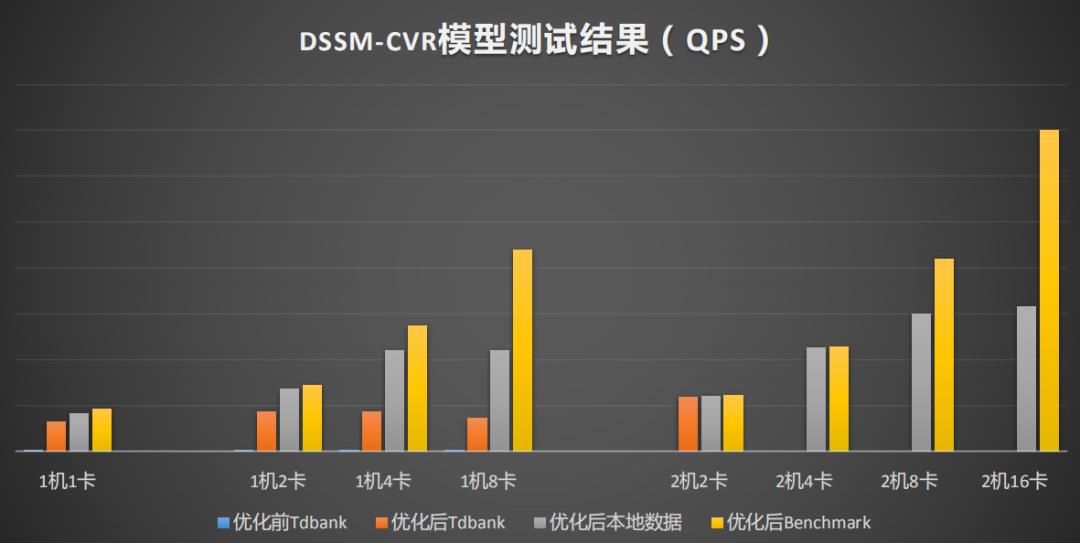
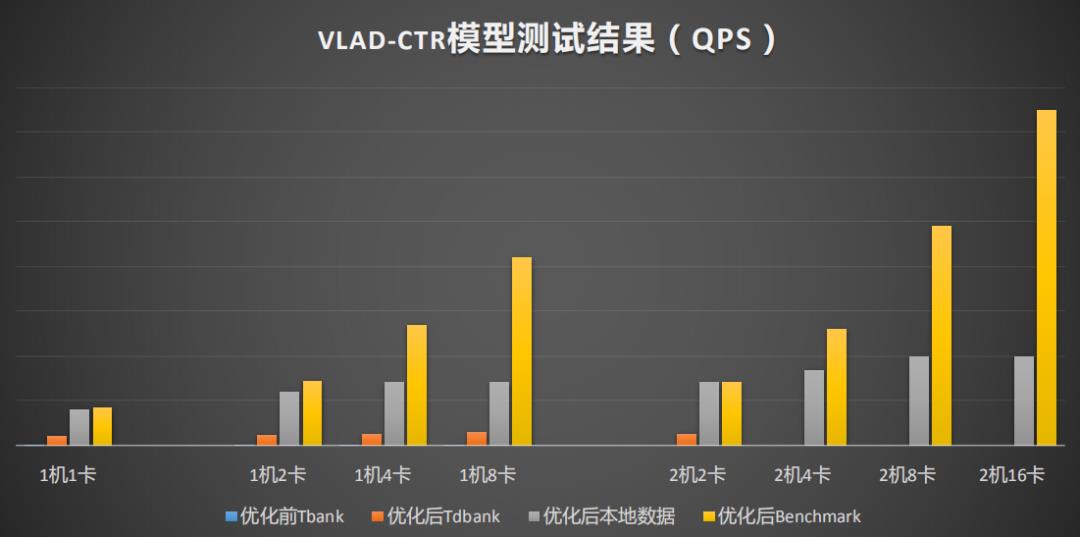
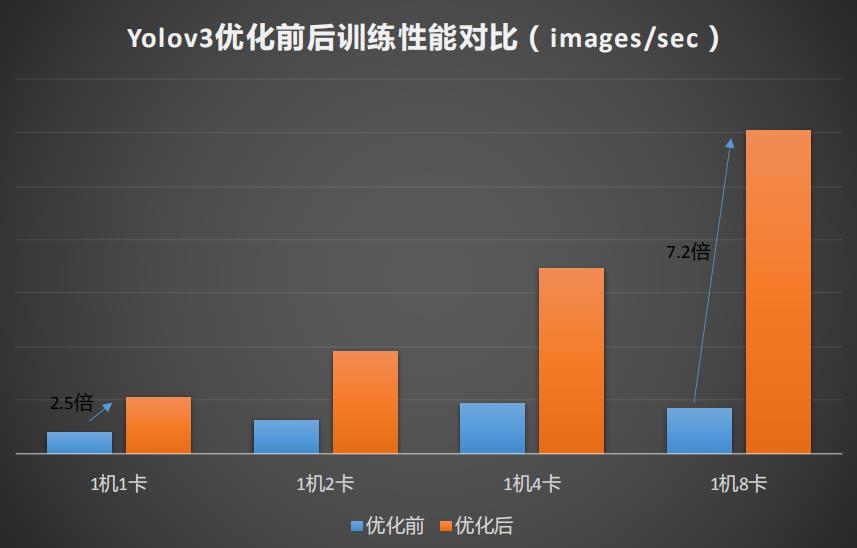
通过在模型层面和数据层面的优化,以及Angel平台应用到整个控制流程中,DSSM的单卡性能有33倍的提升,VLAD有22倍的提升,YOLO有2.5倍的提升如图17所示。图18、19、20是详细测评结果,它们有三种类型的测试模式,分别是训练数据通过TDbank(腾讯自研的MQ系统)线上拉取(时延包括网络传输、数据packing等);本地数据读取,训练数据预先存放本地磁盘(时延包括磁盘IO,数据映射预处理);Benchmark模式训练数据放内存(时延仅包括数据映射预处理)。从图18中看到Benchmark不考虑数据读取前的延时基本能把整个系统计的算能力跑满这是一个准线性地提升。考虑到实际的数据是从MQ中读取,在1卡中提升不大TPS为3000多,2卡QPS为4000多,两机两卡TPS达到6000多,所以随着多机越多,训练性能达到线性的提升, VLAD-CTR模型的测试具有相同的结果。YOLO V3优化后1机1卡有2.5倍的性能提升,1机8卡有7.2倍的提升。
今天主要和大家分享了三部分的内容,第一部分内容是介绍了腾讯的Angel机器学习平台和其在深度学习方向上的拓展和应用,第二部分的内容是介绍了腾讯广告推荐系统的特点和常用模型,最后一部分的内容介绍了Angel深度学习在腾讯广告推荐系统中的应用,模型训练和优化,以及取得的效果。
今天的分享就到这里,谢谢大家。
在文末分享、点赞、在看,给个三连击呗~~
嘉宾介绍:

郭跃超
腾讯 | 应用研究员
会员推荐:
DataFun会员计划重磅发布!多重权益加持,为你筑就数据科学家之路!扫码了解更多:
文章推荐:
关于我们:
以上是关于蓝昶:谷歌分布式机器学习优化实践的主要内容,如果未能解决你的问题,请参考以下文章