腾讯山海网关的高性能高可用网络架构
Posted 鹅厂架构师
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了腾讯山海网关的高性能高可用网络架构相关的知识,希望对你有一定的参考价值。

导语
腾讯山海网关(Tencent GateWay,简称TGW)包括腾讯云负载均衡(Cloud Load Balancer, 简称CLB)和弹性公网IP(Elastic IP, 简称EIP)核心产品,以及边界网关等多个产品,在腾讯被广泛使用。Region EIP作为山海网关的一部分,是腾讯公网接入的桥头堡,为CVM(Cloud Virtual Machine,简称CVM),CLB等产品提供公网多运营商统一接入,具备可靠性高,扩展能力强,性能高,抗攻击能力强等特点。
山海网关是腾讯云网络的一个核心组件,也经过了多次演进,演进过程中我们始终思考的是:如何在不增加成本的情况下为用户持续提供更可靠,更快速的网络。得到的答案则是要求技术团队不断地采用新技术,新架构,来满足更高转发能力,更高稳定性等需求。
/
本文主要探讨RegionEIP的高性能高可用网络架构。目前RegionEIP根据数据面设备类型分为两种:X86架构和P4架构,前者是通用的X86服务器,后者是支持P4(Programming Protocol-Independent Packet Processors,简称P4)的可编程交换机(基于Tofino芯片)。从整个系统设计来看,两种架构的控制面与数据面通信协议都一样,对管控而言管理上没有任何区别。
我们先来介绍下X86架构,再讲P4架构。
X86网络架构
通常我们把一台X86服务器称为LD(Load Distributor,简称LD)。如图1所示,一个RegionEIP X86集群横跨两个园区,每个园区4台LD设备。一个集群中所有的LD设备都配置相同的转发规则,即数据流走任何一台LD,流量都可以被正确转发。

图1 X86网络架构示意图
RegionEIP是无状态的网络转发场景,其整个高可用体系包括以下几个方面:
1
园区容灾
通过在园区间发布不同的大小段网络,形成园区互备,即跨AZ机房容灾。
举个例子,以EIP 10.0.0.1/24网段为例,管控在园区1发布10.0.0.1/25和10.0.0.128/25两个网段,将园区1作为主SET;园区2发布10.0.0.1/24网段,作为备SET,如表1所示。当管控探测程序发现主SET中4台LD都故障时,直接撤销LD上的路由发布,流量通过最长掩码匹配收敛至备SET,切换时间约3-5秒。
设备名称 | 所在位置 | 主/备属性 | 网段 |
LD1 | 园区1 | 主 | 10.0.0.1/25; 10.0.0.128/25 |
LD2 | 园区1 | 主 | 10.0.0.1/25; 10.0.0.128/25 |
LD3 | 园区1 | 主 | 10.0.0.1/25; 10.0.0.128/25 |
LD4 | 园区1 | 主 | 10.0.0.1/25; 10.0.0.128/25 |
LD5 | 园区2 | 备 | 10.0.0.1/24 |
LD6 | 园区2 | 备 | 10.0.0.1/24 |
LD7 | 园区2 | 备 | 10.0.0.1/24 |
LD8 | 园区2 | 备 | 10.0.0.1/24 |
表1 10.0.0.1/24网段发布示例表
其次,网段的大小属性是交替发布的,以保证两个园区的网段数量相对均衡。举例,整个集群对外发布100网段,编号依次为1到100,那么奇数编号的网段在园区1发布小网段作为主SET,在园区2发布大网段作为备SET;偶数编号的网段则相反。
2
上下双联
园区内LD与接入交换机的组网,无论外网侧还是内网侧,都是双联结构,保证单个接入交换机故障时,流量经由另一台接入交换机进入LD,业务流量不受影响。
3
电源容灾
园区内4台LD分布在机房不同的列,每列独立供电,保证单台LD因电源故障时,业务流量由其他LD接管。
4
网口容灾
单台LD设备上有2个外网口,分别是eth2和eth3;2个内网口,分别是eth0和eth1。管控探测程序会对每个网口进行周期性探测,当单个外网口或单个内网口故障时,探测程序会发出告警。此时故障网口不再引流,由另一个正常网口接管流量,流量无损,这种场景下不会隔离设备。
5
设备容灾
在第4点的基础上当管控探测程序发现2个外网口或2个内网口故障时,探测程序会发出告警并隔离设备,停止BGP路由通告,流量切入其他LD,保证业务流量不受损,即园区内设备容灾。
在流量限速方面,RegionEIP X86集群采用的是基于DPDK技术的“分布式反馈算法”,通过周期性地“采样”-“计算配额”-“分发配额”三步原理来实现流量限速和计费。从原理可以看到“分布式反馈算法”存在某些缺陷,比如无法预测流量的来临,当流量突发时,第一波流量会被“漏放”,导致限速不理想;反馈式算法存在时延,因为每次分发的限速配额实际上是根据过去一段时间计算得到的,并不能很好反映当前的流量模型。
在此背景下,同时结合硬件卸载,网络可编程新技术趋势,为了更好地配合公司的业务发展和技术储备,RegionEIP产品引入了搭载Tofino芯片的可编程交换机作为数据面转发设备。Tofino芯片本身具备限速特性,结合P4可编程语言的灵活性,在RegionEIP场景下可以实现更加精准的限速。
P4网络架构介绍
P4可编程交换机的PPS性能很强,能够线速转发,制约单机性能的瓶颈主要是交换机的DRAM和TCAM资源。相比DPDK跑在X86服务器上内存64G起步,512G 也常见,而交换机芯片上的内存资源就相对要少很多。
为了突破单机的资源瓶颈,我们设计了Pipeline折叠的方案,将单机容量翻了4倍。
网络架构方面,一个RegionEIP P4集群横跨两个园区,共8台P4可编程交换机,每个园区4台。每台P4设备上联4台WC(Wan Core,外网核心交换机),每个连接是 2 x 100G 的接线方式;下联4台LC(Lan Core,内网核心交换机),每个连接也是 2 x 100G 的接线方式,如图2所示。因此单台P4具备外网800G,内网800G的吞吐量,每个园区上下各3.2T的吞吐量。注意:集群支持横向扩容,最多支持8台P4设备,实际运营可根据可靠性要求选择2-8台。
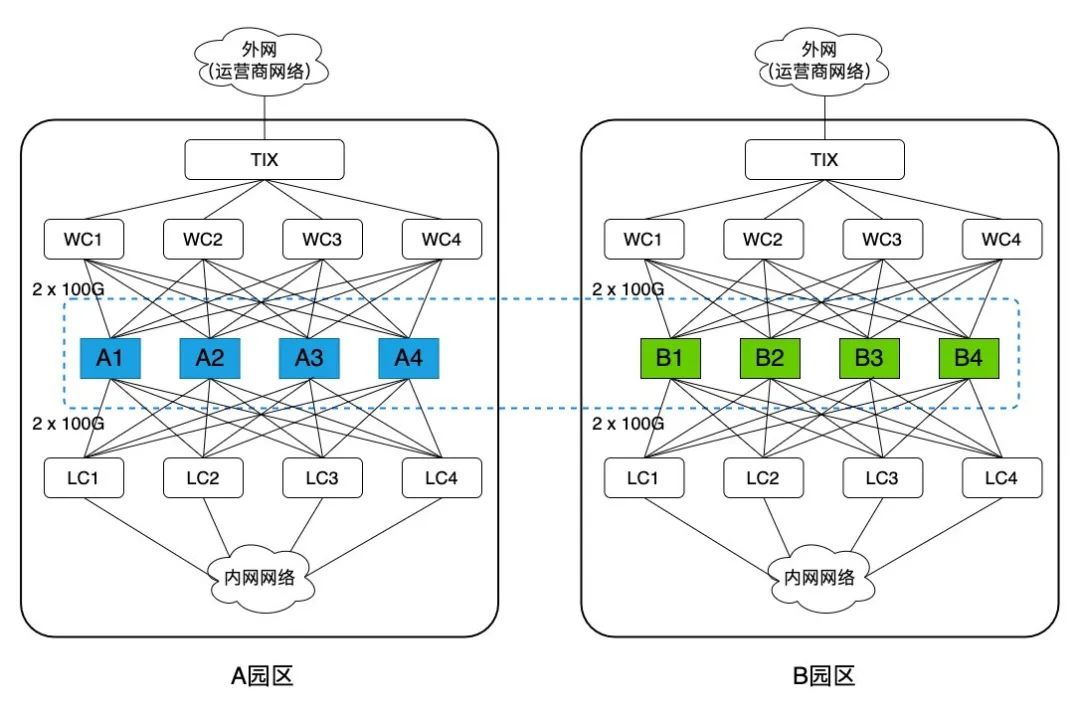
图2 RegionEIP P4集群网络架构示意图
和X86集群一样,P4集群也是通过园区间发布不同的大小段网络,形成园区互备,做园区间容灾。
那么园区内的4台设备如何做设备间容灾呢?这个问题在设计之初也有很多思路。比如继续使用大小段来区分设备,但是随着网段的增加,设备的增加,这种两层大小段组成的优先级其复杂度会非常高,不便于管理和维护;其次网段不断的裂变,BGP通告给上下联交换机的网段也在不断增加,而交换机每个端口能够收敛的路由条目是有限的,造成路由发布瓶颈。
其实BGP本身就有很多路由优选的手段和方法,比如MED,as-path等。若使用MED,优选MED最小的路径,但是只能在一个AS域配置,一般用于管理一个AS域内多个出口的优先级。若使用as-path,BGP优先经过AS数量较小的路径,而且as-path可以跨AS域。最终我们选择用as-path来实现四级路由优先级,保证同一个EIP网段的流量只会经过单台P4设备处理。
简单来说就是对于同一个网段N1,园区内的4台P4设备均发布N1网段,但是每台设备设置不同的优先级(通过as-path区分),由优先级的高低来决定N1网段进入哪台设备。以表2四级路由优先级为例(表中优先级顺序为1>2>3>4),N1网段流量进入A1, N2网段进入A3, N3网段进入A2, N4网段进入A4。
网段 | A1 | A2 | A3 | A4 |
N1 | 1 | 2 | 3 | 4 |
N2 | 3 | 4 | 1 | 2 |
N3 | 2 | 1 | 4 | 3 |
N4 | 4 | 3 | 2 | 1 |
表2 四级路由优先级示意图
此外,四级路由优先级也是园区内设备间容灾的一种手段。以表2中的优先级为例,当A1发生故障被隔离后,N1网段由次高优先级的A2设备承载,如下图3所示。
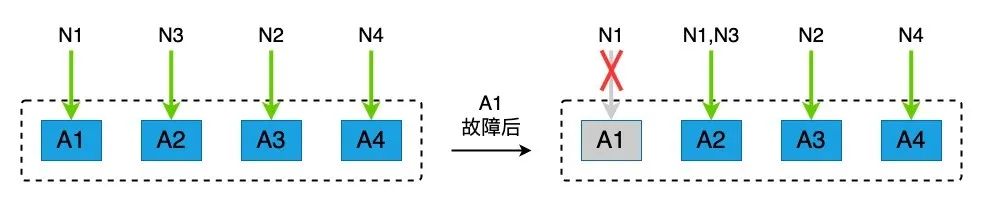
图3 四级路由优先级设备容灾示意图
最后,网段的四级优先级属性也是交替发布的,通过推演可知,每12个网段为一轮进行优先级属性设置,可以保证每台设备网段数量相对均衡。
P4集群是交换机组网形态,单台设备网口数量众多,为此在网口层面我们做了精细化网口容灾管理。在设计网口容灾方案时,有2种方案可以考虑,下面分别介绍下。
方案1:根据WAN/LAN网口属性,将其分为两组,组内网口做ECMP,如图4所示。
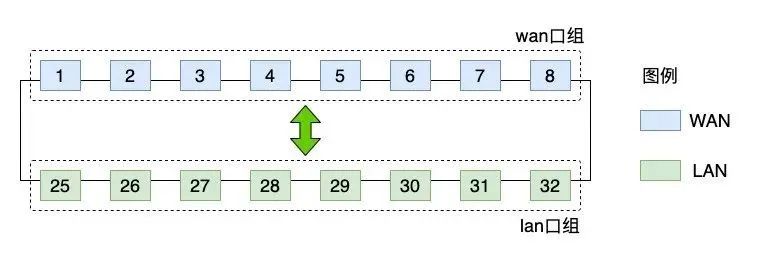
图4 网口流量出入示意图
以入方向流量为例。流量从WAN口组任一网口进入交换机,经过P4设备的业务逻辑处理从LAN口组中一网口出去。具体是哪个LAN口,可以根据数据流的特征(比如源目IP,协议,源目端口五元组)哈希决定,以此来实现网口等价哈希。
假设某条特定流从WAN组6口进入,经过处理后从LAN组26口出去。如果此时26口发生故障,管控探测程序将其从LAN组剔除,通过哈希重新计算从28口出去,如图5所示。这种网口容灾方式解耦了WAN口与LAN口的绑定关系。LAN组内网口故障时,组内网口做等价哈希,只影响本侧引流,WAN组并不需要感知该变化。反之,出方向流量也是一样。

图5 某特定流量网口出入示意图(方案1)
方案2:WAN/LAN网口配对使用,探测程序感知配对关系,网口故障时成对撤销邻居发布。
由数据面规定WAN口与LAN口一一配对使用,流量从某个网口进,经过业务逻辑处理从固定端口出,如图6中的虚线框所示,流量由1口进,25口出,反向同理。

图6 网口配对使用示意图
这种方案下,假设某条特定流从6口进,30口出。当探测程序发现30口发生故障,直接撤销6口和30口的BGP邻居,从而使2个网口不再引流,由上下联交换机将流量切到其他网口,如图7所示。

图7某特定流量网口出入示意图(方案2)
由此可知方案2的设计下如果1个网口故障,上下联都减少1个BPG邻居,进而上下行吞吐量都减少100G。
尽管两个方案都可以实现目标,但各有优劣,对比如下:
方案名称 | 优势 | 劣势 |
方案1 | 探测程序不需要感知网口的映射关系,单侧网口故障,只影响本侧BGP引流 | a.如果组内哈希不均,可能导致网口流量不均,单网口发送队列缓存报文增加,延时增加,甚至丢包 b.网口故障后,上下行收敛比不再满足1:1 c.报文出口不可控,不便于运维管理和故障定位 |
方案2 | a.网口配对使用,不存在哈希不均问题 b.内外网收敛比永远都是1:1 | 探测程序需要感知网口的配对关系 |
综合考虑后,我们选择了方案2,一方面为了保证流量内外收敛比1:1,另一方面固定网口配对使用便于运维管理和问题定位。其次,在此网口容灾基础上配置单机网口故障阈值,当网口故障数目超过阈值时,直接隔离设备,停止路由发布。最后,整个网口探测是毫秒级,一旦探测失败,主动撤销邻居,以保证网口秒级容灾。
综上所述,可以发现RegionEIP产品的两套网络架构实际上是一脉相承的,都具备强转发,高稳定等能力。
从运营方面,P4可编程交换机通过Pipeline折叠突破了单机资源瓶颈,提高了单集群业务承载能力,对于用户而言,具体使用哪套架构是无感知的;
从成本方面,P4的网络架构设计中跨过接入交换机,直连核心交换机,节省了部分成本;
从容灾方面,通过多上下联,四级路由优先级,网口容灾等手段对高可用方案做了优化和升级。
关于云架平网关
网关研发是腾讯云架平核心业务之一,为腾讯云内外部客户以及自营业务提供高质量的网络接入服务,解决业务跨网互通,统一接入等问题。我们致力于用技术力量持续为客户提供更快,更强,更稳定的网络服务,帮助客户提升网络体验,较低成本。
2、精通TCP/IP协议栈,熟悉网络数据包分析,具备端到端网络分析能力;
3、熟悉DPDK,FPGA,P4等数据面技术;
4、熟悉Linux内核,具备内核开发经验;
5、具备良好的沟通表能力及团队协作精神、有较强的主动性、责任心与执行能力;
扫码添加 “鹅厂架构师小客服” ,成功通过后可进入【鹅厂架构师圈】,与技术爱好者、技术关注者分享交流,共同进步成长,欢迎大家!↓↓↓

关于我们
出品:腾讯云网关TGW团队subond;
责任编辑:cathy
技术分享:关注微信公众号 【鹅厂架构师】
腾讯云架构师出品的《MySQL性能优化和高可用架构实践》针不戳
作为最流行的开源数据库软件之一,MySQL数据库软件已经广为人知了。当前很火的Facebook、腾讯、淘宝等大型网站都在使用MySQL的数据库。
互联网行业的多数业务场景有非常明显的特点:用户量大、引发 数据容量大、并发高、业务复杂度适中。MySQL数据库产品初期的定位 就是Web应用的数据服务,故几乎所有互联网企业都使用MySQL数据库
产品,有很多企业几乎全部使用MySQL提供的数据服务。
这本《MySQL性能优化和高可用架构实践》从企业实战的角度纵观整个MySQL生态体系,将两大关键技术有机融合,并对比了多种方案, 为读者展现了多种在两个本质上矛盾的特性之间取得平衡的精妙方法,对理论架构与企业实战都有丰富的指导意义。阅读本书,你可以站在对数据领域有多年深耕经验的作者肩膀上,汲取作者的实践经验与心血总结,从作者的角度理解和认识数据技术,一步赶上云与智能时代的数据技术发展前沿。
本书分为13章,详解MySQL 5.7数据库体系结构,InnoDB存储引 擎,MySQL事务和锁,性能优化,服务器全面优化、性能监控,以及MySQL主从复制、PXC、MHA、MGR、Keepalived+双主复制等高可用集群架构的设计与实践过程,并介绍海量数据分库分表和Mycat中间件的实战操作。

需要《MySQL性能优化和高可用架构实践》文档的小伙伴,点赞+转发之后【点击此处】即可免费获取!
第1章 MySQL架构介绍
- 1.1 MySQL简介
- 1.2 MySQL主流的分支版本
- 1.3 MySQL存储引擎
- 1.4 MySQL逻辑架构
- 1.5 MySQL物理文件体系结构


第2章 InnoDB存储引擎体系结构
- 2.1 缓冲池
- 2.2 change buffer
- 2.3 自适应哈希索引
- 2.4 redo log buffer
- 2.5 double write
- 2.6 InnoDB后台线程
- 2.7 redo log
- 2.8 undo log
- 2.9 Query Cache


第3章 MySQL事务和锁
- 3.1 MySQL事务概述
- 3.2 MySQL事务隔离级别
- 3.3 InnoDB的锁机制介绍
- 3.4 锁等待和死锁
- 3.5 锁问题的监控

第4章 SQL语句性能优化
- 4.1 MySQL查询过程
- 4.2 创建高性能索引
- 4.3 慢SQL语句优化思路
- 4.4 索引使用的原则及案例分析

第5章 MySQL服务器全面优化
- 5.1 MySQL 5.7 InnoDB存储引擎增强特性
- 5.2 硬件层面优化
- 5.3 Linux操作系统层面优化
- 5.4 MySQL配置参数优化
- 5.5 MySQL设计规范


需要《MySQL性能优化和高可用架构实践》文档的小伙伴,点赞+转发之后【点击此处】即可免费获取!
第6章 MySQL性能监控
- 6.1 监控图表的指导意义
- 6.2 Lepus数据库监控系统实战


第7章 MySQL主从复制详解
- 7.1 主从复制的概念和用途
- 7.2 主从复制的原理及过程描述
- 7.3 主从复制的重点参数解析
- 7.4 主从复制的部署架构
- 7.5 异步复制
- 7.6 半同步复制
- 7.7 GTID复制
- 7.8 多源复制
- 7.9 主从复制故障处理
- 7.10 主从延迟解决方案和并行复制


第8章 PXC高可用解决方案
- 8.1 PXC概述
- 8.2 PXC的实现原理
- 8.3 PXC集群的优缺点
- 8.4 PXC中的重要概念
- 8.5 PXC集群部署实战
- 8.6 PXC集群状态监控
- 8.7 PXC集群的适用场景和维护总结


第9章 基于MHA实现的MySQL自动故障转移集群
- 9.1 MHA简介
- 9.2 MHA原理
- 9.3 MHA的优缺点
- 9.4 MHA工具包的功能
- 9.5 MHA集群部署实战

第10章 MySQL Group Replication
- 10.1 MGR概述
- 10.2 MGR基本原理
- 10.3 MGR服务模式
- 10.4 MGR的注意事项
- 10.5 MGR部署实战
- 10.6 MGR的监控
- 10.7 MGR的主节点故障无感知切换

第11章 Keepalived+双主复制的高可用架构
- 11.1 Keepalived+双主架构介绍
- 11.2 Keepalived介绍
- 11.3 双主+Keepalived集群搭建

第12章 数据库分库分表与中间件介绍
- 12.1 关系数据库的架构演变
- 12.2 分库分表带来的影响
- 12.3 常见的分库分表中间件介绍


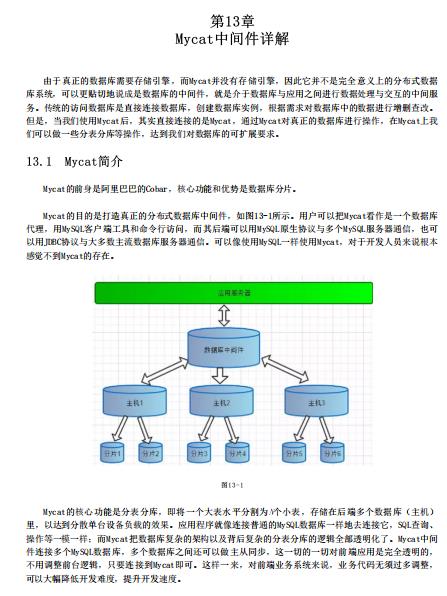
第13章 Mycat中间件详解
- 13.1 Mycat简介
- 13.2 Mycat核心概念
- 13.3 Mycat安装部署
- 13.4 Mycat配置文件详解
- 13.5 Mycat分库分表实战
- 13.6 Mycat读写分离实战

需要《MySQL性能优化和高可用架构实践》文档的小伙伴,点赞+转发之后【点击此处】即可免费获取!
以上是关于腾讯山海网关的高性能高可用网络架构的主要内容,如果未能解决你的问题,请参考以下文章