LMU「自然语言处理现代方法」最新书,176页pdf概述NLP进展
Posted 专知
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了LMU「自然语言处理现代方法」最新书,176页pdf概述NLP进展相关的知识,希望对你有一定的参考价值。
推荐一本自然语言处理现代方法新书!
近年来,自然语言处理的研究方法取得了一些突破。这些突破来源于两个新的建模框架以及在计算和词汇资源的可用性的改进。在这个研讨会小册子中,我们将回顾这些框架,以一种可以被视为现代自然语言处理开端的方法论开始:词嵌入。我们将进一步讨论将嵌入式集成到端到端可训练方法中,即卷积神经网络和递归神经网络。这本小册子的第二章将讨论基于注意力的模型的影响,因为它们是最近大多数最先进的架构的基础。因此,我们也将在本章中花很大一部分时间讨论迁移学习方法在现代自然语言处理中的应用。最后一章将会是一个关于自然语言生成的说明性用例,用于评估最先进的模型的训练前资源和基准任务/数据集。
https://compstat-lmu.github.io/seminar_nlp_ss20/
在过去的几十年里,人工智能技术的重要性和应用不断得到关注。在当今时代,它已经与构成人类塑造环境的大部分环境密不可分。因此,商业、研究和开发、信息服务、工程、社会服务和医学等无数部门已经不可逆转地受到人工智能能力的影响。人工智能有三个主要领域组成了这项技术:语音识别、计算机视觉和自然语言处理(见Yeung (2020))。在这本书中,我们将仔细研究自然语言处理(NLP)的现代方法。
这本小册子详细介绍了用于自然语言处理的现代方法,如深度学习和迁移学习。此外,本研究亦会研究可用于训练自然语言处理任务的资源,并会展示一个将自然语言处理应用于自然语言生成的用例。
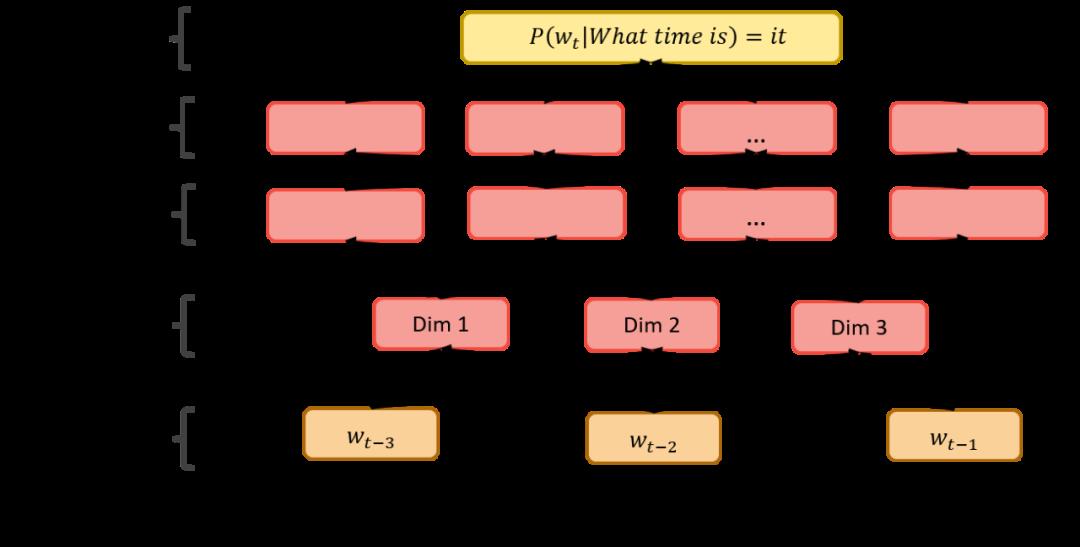
为了分析和理解人类语言,自然语言处理程序需要从单词和句子中提取信息。由于神经网络和其他机器学习算法需要数字输入来进行训练,因此应用了使用密集向量表示单词的词嵌入。这些通常是通过有多个隐藏层的神经网络学习的,深度神经网络。为了解决容易的任务,可以应用简单的结构神经网络。为了克服这些简单结构的局限性,采用了递归和卷积神经网络。因此,递归神经网络用于学习不需要预先定义最佳固定维数的序列的模型,卷积神经网络用于句子分类。第二章简要介绍了NLP中的深度学习。第三章将介绍现代自然语言处理的基础和应用。在第四章和第五章中,将解释和讨论递归神经网络和卷积神经网络及其在自然语言处理中的应用。
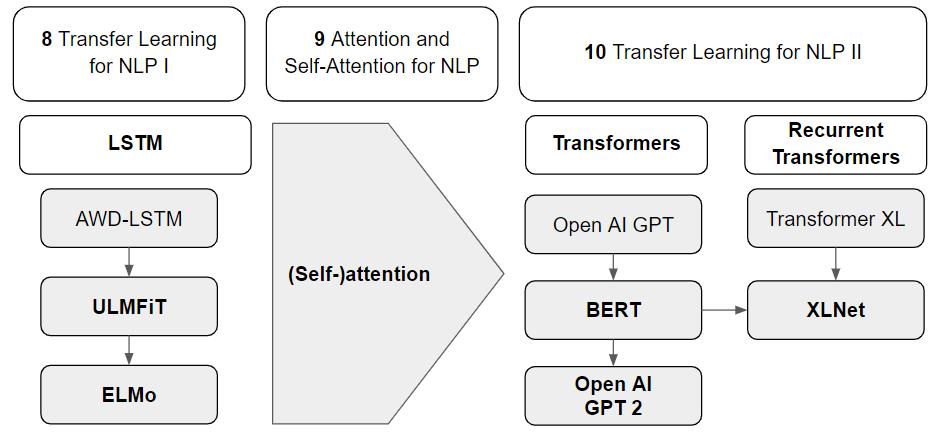
迁移学习是每个任务或领域的学习模型的替代选择。在这里,可以使用相关任务或领域的现有标记数据来训练模型,并将其应用到感兴趣的任务或领域。这种方法的优点是不需要在目标域中进行长时间的训练,并且可以节省训练模型的时间,同时仍然可以(在很大程度上)获得更好的性能。迁移学习中使用的一个概念是注意力,它使解码器能够注意到整个输入序列,或自注意,它允许一个Transformer 模型处理所有输入单词,并建模一个句子中所有单词之间的关系,这使得快速建模一个句子中的长期依赖性成为可能。迁移学习的概念将在小册子的第6章简要介绍。第七章将通过ELMo、ULMFiT和GPT模型来描述迁移学习和LSTMs。第八章将详细阐述注意力和自注意力的概念。第九章将迁移学习与自注意力相结合,介绍了BERT模型、GTP2模型和XLNet模型。
为NLP建模,需要资源。为了找到任务的最佳模型,可以使用基准测试。为了在基准实验中比较不同的模型,需要诸如精确匹配、Fscore、困惑度或双语评估替补学习或准确性等指标。小册子的第十章简要介绍了自然语言处理的资源及其使用方法。第11章将解释不同的指标,深入了解基准数据集SQuAD、CoQa、GLUE和SuperGLUE、AQuA-Rat、SNLI和LAMBADA,以及可以找到资源的预训练模型和数据库,如“带代码的论文”和“大坏的NLP数据库”。
在小册子的最后一章中,介绍了生成性NLP处理自然语言生成,从而在人类语言中生成可理解的文本。因此,不同的算法将被描述,聊天机器人和图像字幕将被展示,以说明应用的可能性。
本文对自然语言处理中各种方法的介绍是接下来讨论的基础。小册子的各个章节将介绍现代的NLP方法,并提供了一个更详细的讨论,以及各种示例的潜力和限制。

专知便捷查看
后台回复“NLP176” 可以获取《LMU「自然语言处理现代方法」最新书,176页pdf概述NLP进展》专知下载链接索引

以上是关于LMU「自然语言处理现代方法」最新书,176页pdf概述NLP进展的主要内容,如果未能解决你的问题,请参考以下文章