腾讯高级研究员33页PPT详解构建图像识别系统的方法!
Posted 智东西公开课
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了腾讯高级研究员33页PPT详解构建图像识别系统的方法!相关的知识,希望对你有一定的参考价值。
导读
2019年4月13日,腾讯高级研究员冀永楠从构建图像识别系统的方法切入,讲述腾讯云人脸识别、文字识别、人脸核身等技术能力原理与行业应用,为各位开发者带来了一场人工智能领域的技术开拓实践之旅。
自我介绍一下,我叫冀永楠,毕业于诺丁汉大学计算机系,我一直做图像相关和机器学习不同领域的应用,目前在腾讯云的大数据AI产品中心担任高级研究员的职位,我今天跟大家简单介绍一下关于计算机视觉的一些基本原理和应用。
简单来讲,计算机视觉就是先通过一些方法把一些现实中的东西转化为图像,通过对图像做分析,得到一些我们想要的结果。最常见的图像其实就是我们拍照,常见的这种任务分为物体识别、对象的检测、对象的追踪、语义上的分割,还有三维重建、知识问答等等,最后通过这些组合来完成我们经常常见的人脸识别的这些任务。
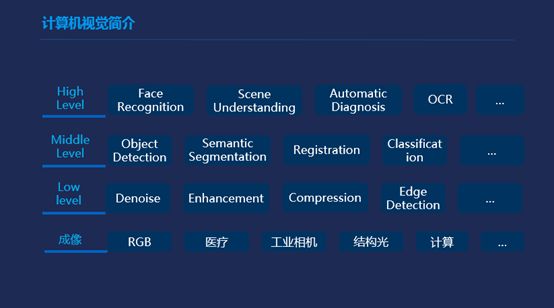
我这边把整个图像从成像到实际的应用层分这么四层,最基本的是一个成像层,因为现在腾讯也是要做产业互联网,其实在互联网领域的时候,我们最常用的图像是视频和普通的RGB图像,进入产业互联网之后就会接触不同的成像方式,比如工业相机的成像,还有比较火的3D人脸模型之后用3D的结构光、TOF等等这种图像成像方式。在上面,我们这是一个成像的输入图,它的输入往往是一些采集过来的信号,它的输出一般是图像或者人可以看懂的东西。
再往上,会对这些图像进行一般的简单的分析,大部分都是一些几何性的,这些东西就能提出一些几何的点、线、面这些特征,这是低等级的特征或者低等级的处理方式。再往上会构建出一些物体的检测、物体的分割、还有配准。
还有一些高等级的应用,Face Recognition等等这些。
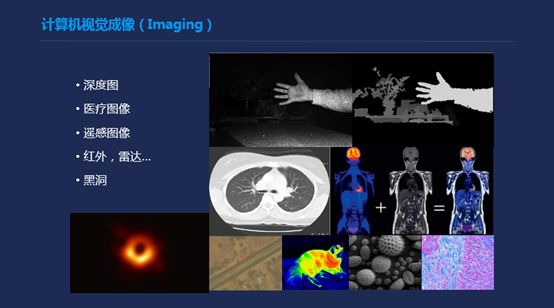
先从成像简单讲,最近这几种我们常见的成像方式,除了RGB之外,上面有红外,还有距离的成像,下面是CT成像,它本身的成像方式是通过感测器,绕一个物体一周,根据信号计算出这个物体内部对于X光的吸收程度所产生的一个成像。医疗成像,它本身的成像方式是我要摄入一些有放射性的东西,并且从外部感受这些东西,所产生的密度,叠加在原有的CT成像上。再往下是有一个红外广谱,这两个是放大的图像方式。
遥感图像,它比较大的特点是它的频谱比较宽一点,它的通道会比普通通道多一点。最后一个比较火的黑洞,当然大家可能最近比较热的一个话题,因为刚开始的时候我看新闻的时候,第一张黑洞的照片,其实我希望的会是一种类似这种照片,但其实往往得到这个图片,在我们来看更像一个map,它是根据很多的数据不断的去搜集这个数据之后,然后在建立了一个物理模型,再通过这些数据训练这些模型,得到这么一个能源的图。
这就是我们现在目前为止比较常见的一些成像的方式吧,那么在接触任何解决方案的时候,其实无论是做医疗也好,或者现在做多媒体,还是说做天文,各种领域的图像的解决方案里面,往往了解成像过程是第一步,这个会告诉你看到的图像是什么,还有传统的解决方案是什么,无论你想把AI或者模型应用到这里面,这都是建立整个系统理解的第一步。
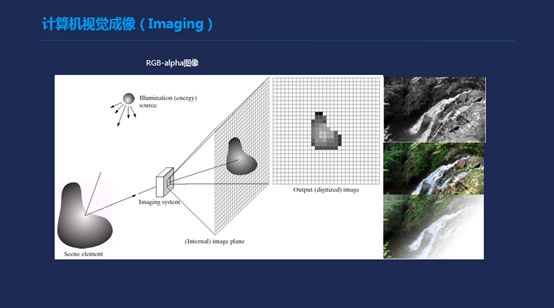
我们最常见的图片,它的成像方式就比较简单一点,可能大家都知道有一个光源,照射到物体之后产生反光,反光通过成像系统,比如相机,它会映射到一个传感器上,在传感器上产生强度信号,如果有三重传感器就会产生RGB的图像,现在很多的格式里还有α,α就是一个透明度的图像。那么之前的话,记得英特尔做过一个应用,把某一个数据和它所形成的图像进行一个maping,这个也在很多的相机里有一些专业的暗光相机里进行使用。

低level呈现的以De-noise为主,黑的地方黑,暗的地方暗,一般是线性影射,映射到人的可见范围内。这个过程是非常常见的,甚至这个可以单做成一个小工具来调,所以我们看到医疗图像一般它的深度是2048的,压缩在一个图上是完全看不见的,或者经常是截取其中一部分来看你具体想要看的位置是什么,想看的器官是什么。像这种去噪,是一个非常常见的应用,因为几乎所有的系统都会有噪声。

到中一层就涉及到一部分物体里面的内容,包括分类,classification和Localization,我认为这个图像里到底有几个我的前景目标,你图像的数据数量没有多少,直接指望用一个分类方法就搞定的话这是不太现实的,这是你在拆解问题没有拆解好的话,你在后面用其它的底层技术方法去弥补的话往往会于事无补而且会浪费很多时间纠结在这上面。有时候反过来讲,这是拆解问题导致后期的中层问题弥补不了的。反过来你在成像时候遇到的一些问题,你用中层的技术也是弥补不了的。比如我以前做的医疗图像,经常出现CT里面放一个金属,整个图片就坏掉了,那个金属会非常亮,把周围的射线全部吸走,这时候在后处理里建模是基本无用的。
我们现在其实有很多的问题,常见的问题上在GItHub上或者开源社区上都会有一些端到端的,如果不做这些分解的话,结果怎么提都提不上去。
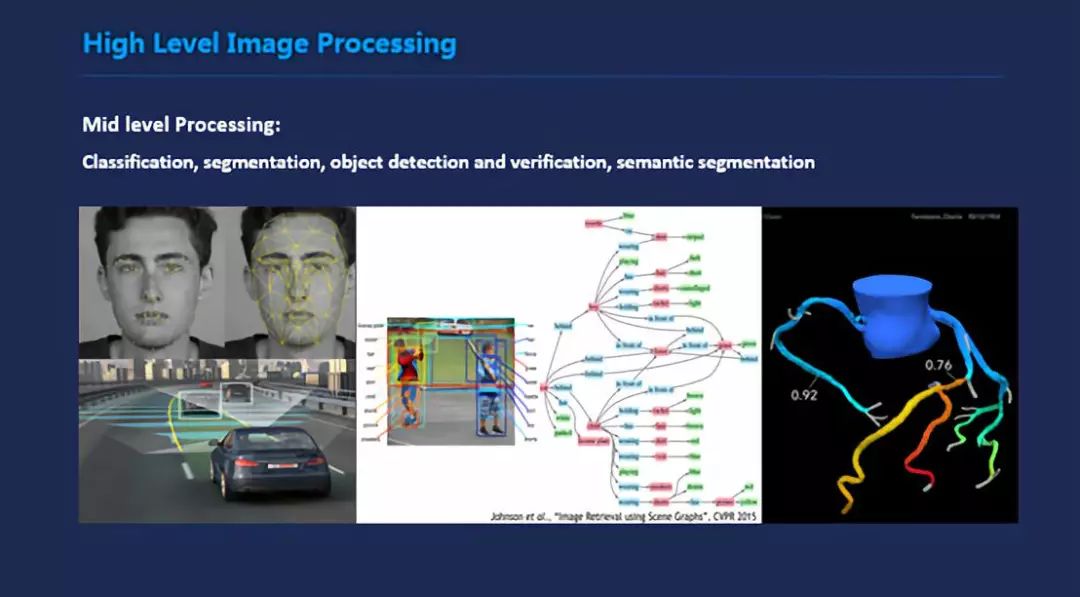
这是高等级的图像应用,比如人脸识别、自动驾驶,还有中间那个图是图像中的物体和语言的一种对应关系。右面是一个冠状动脉的标注,如果心脏有问题去医院的话会先扫一个CT,会重建出你的八根冠状动脉,之后根据狭窄情况再去考虑是否下支架,这个过程原来是手动的,必须医生一根一根看,看完之后给出诊断,现在有计算机辅助的,有一个公司是专门做这一部分。

讲完分层,再讲一下不同层面所对应的方法,图象处理方法,像我比较早接触是2000年上下,那个时候还没有深度学习,那个时候讲到图像,大部分都是讲图像滤波器,滤波器就是常见的空间滤波器、频率滤波器、傅里叶、小波滤波器,后来用对称等等,这是低层的方法。中层的方法,就是涉及各种各样的Feature,通过Feature加分类器,再给一个表现,要么是图片,要么是通过滑窗截取到的一小片图片,然后再放到分类器里面看它是不是你想要的目标,当时基本上是这样做的。当时的分割方法,还有level-set,就是用一个函数限制它的变化方法,实际上我们大部分接触到分割,大部分想要的分割结果都是比较规整的,这种规整程度用什么描述?可以用level-set函数表述,也可以用其他,大部分都是采用这种思路。
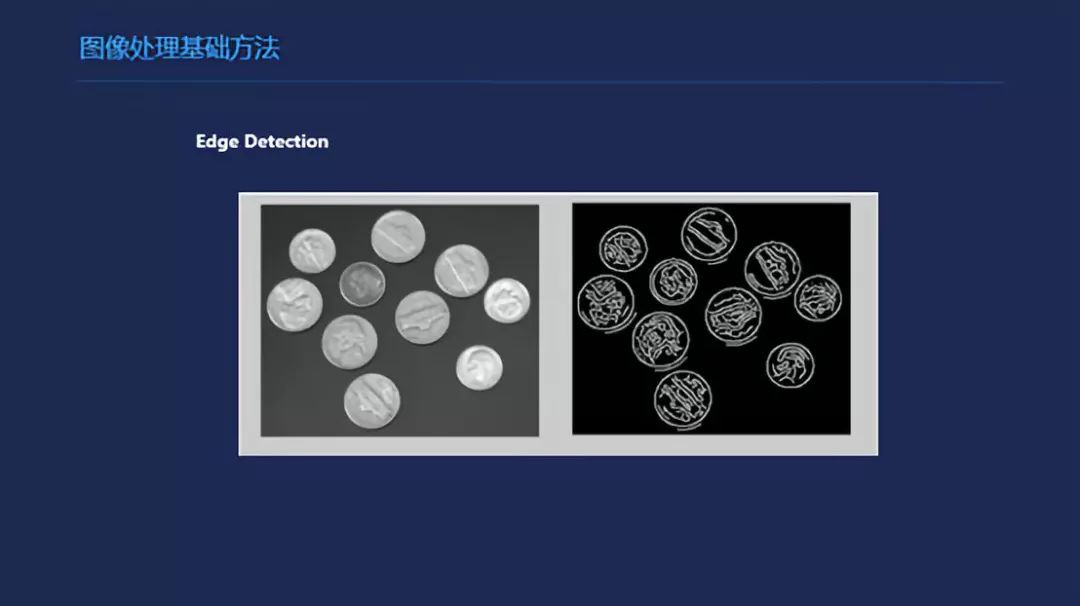
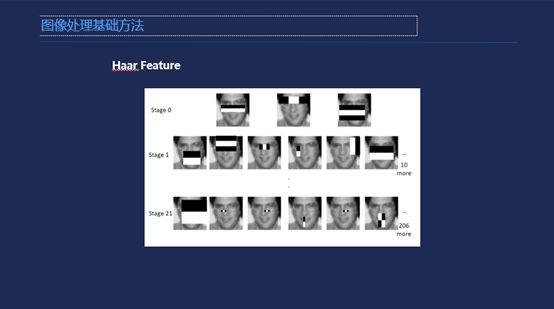
简单介绍几个图像数据的Feature,这是边缘的Feature,它要求在一个简单的场景下做到一个非常稳定的效果,那么它本身映射到一个高危空间里,这个空间维度并不是那么高也并不是那么复杂,但是我就要求它的稳定性比较好,基本上都是采用这种简单的方法来处理。Haar Feature这是最早用来做图像检测的,它设计了几个Haar Feature进行分类,然后检测出人脸。

局部对称性,这是当你需要检测的物体有一定对称性的时候,比如检测一个股骨头,股骨头大部分圆的,这个时候用对称性会给一定的加分。

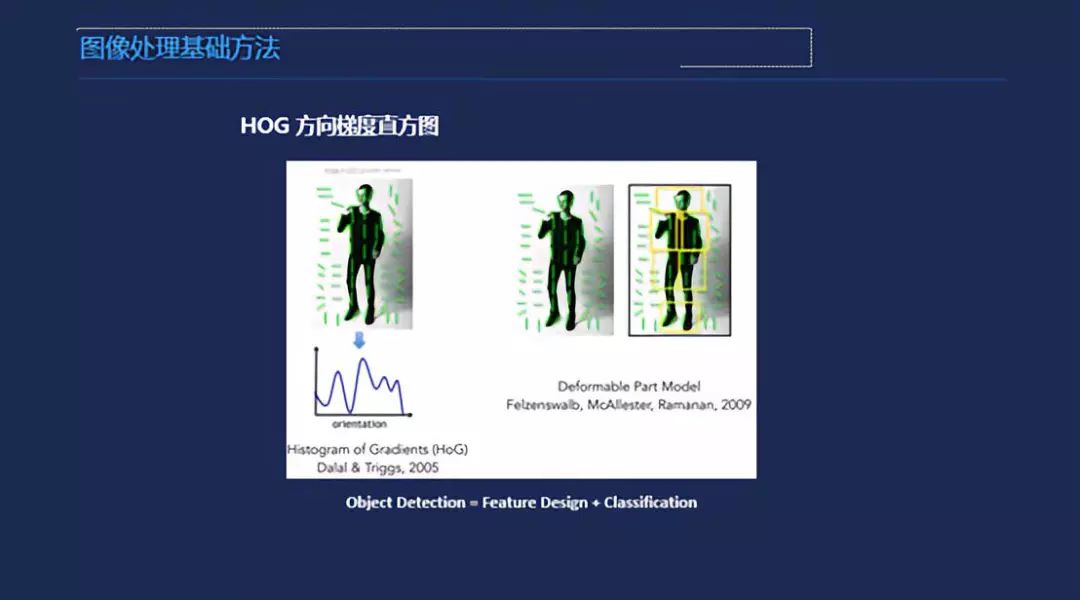
SIFT是最早一个把SIFT引入到Feature里面的,它能把你的目标物体,当你的拍摄角度不一样的时候,它是第一个能做到有效的对应关系的。到后来的话,当时很多的检测和分类的算法里面都会加入这个Feature,之后的很长时间都是用HoG的Feature。一个整体的部分,比如一个人,可能不太可能只用一个part来描述,因为经常是组合性的,其实最简单的,人的手经常是在不同位置上的,完全用一个不可能区隔的,所以在那时候是最好的一个检测效果。

刚才上面讲的是目标检测的传统方法,后面这两个主要是分割的方法。分割方法最常见的是分水岭方法,其实就是抽一个维度,其实和一个图也没有太大本质的区别,然后根据条件看出不同的区域。到后来的话还会有其他的,比如极大稳定区域,它定义了一种极大稳定区域的度量,就是这个区域内怎么算极大稳定,在这个极大稳定区域里它的均一性好一点。它本身是要把图像分为几块进行检测,但后来发现这个东西做分割也蛮好的,现在OCR这种传统仍然常用的,因为OCR尤其在一些场景下,比如广告牌,广告牌会给一个比较强的背景反射,比如白墙加红字或者黑墙加白字,它的目标区域是非常稳定的,用它做一个初步的检测结果,效果往往是非常好的。

还有一个是ASM,主观形状模型,其实很多思想在后面深度学习领域里面仍然被使用,像这个ASM以及后来这一系列的想法。它的主要想法是在分割的时候大概知道分割区域的格式是什么样,设计一个变化的范围,分割的接口不会太多的超出这个范围。像这个人脸的话,当时的人脸分割,比如我可以采集十个人脸或者更多的一百个人脸,把一百个人脸都做一个很好的标注,建一个人脸的模型。做一千个人脸,做一个平均的人脸,现在也有亚洲人长什么样、非洲人长什么样,美洲人长什么样,其实基本就是这样,取平均值,然后做一个平滑,形成这么一个人脸的效果。
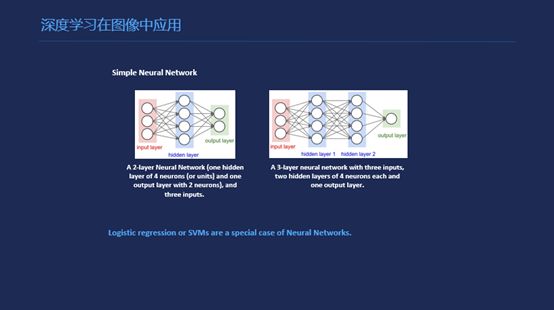
深度学习在图像中的应用,在2011、2012年前后逐渐流行起来,早期的时候深度学习是达不到这样一个深度,我们当时称之为MOP,MOP当时用的时候效果并不好。有几个原因吧,第一个是当时训练不了太深,非线性拟合做不了那么高的高度,第二是训练难度比较大,每次训练结果和前次都不一样,为了弥补这个缺陷,统计上得到一个一致的结果,比如随机N个初始条件然后开始训练,这样的话最后的效果并没有好,训练的时间反而很长。
那么到后来,因为在图像上加入了卷积神经网络GPU的技术,还有一些关键性的技术,使得第一它的训练可以训练更深,可以得到更高的拟合性。第二是不需要对最后的结果影响并不那么大,在此之后又一个使它应用比较广泛的前提是,我们有了很多的预训练的网络,这样的话其实使我们现在很多做计算机视觉的人都能有幸站在巨人的肩膀上,开发自己的应用。但是因为巨人随时会撤掉了,我们希望能做一个什么呢,希望做一个有一定高度的平台,这个平台就不用考虑平台会不会倒的问题,大家会稳稳站在上面开发自己的应用。
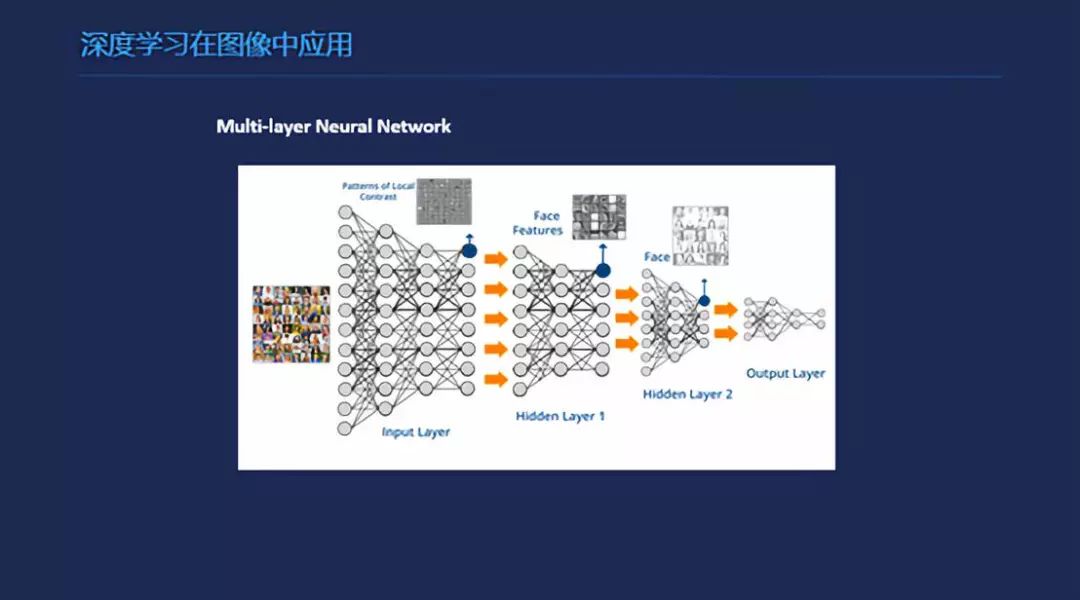
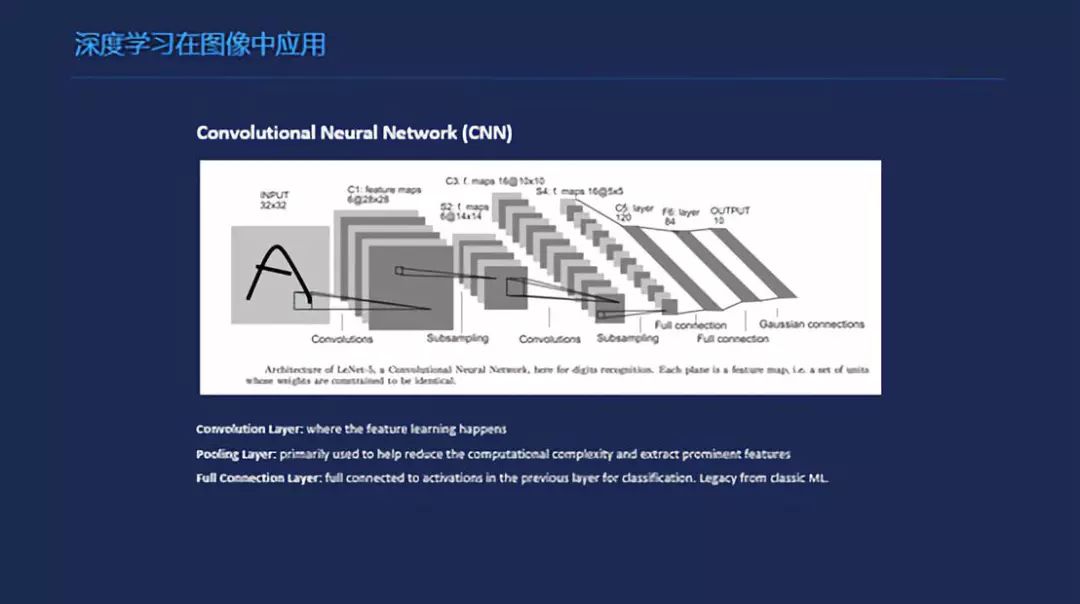
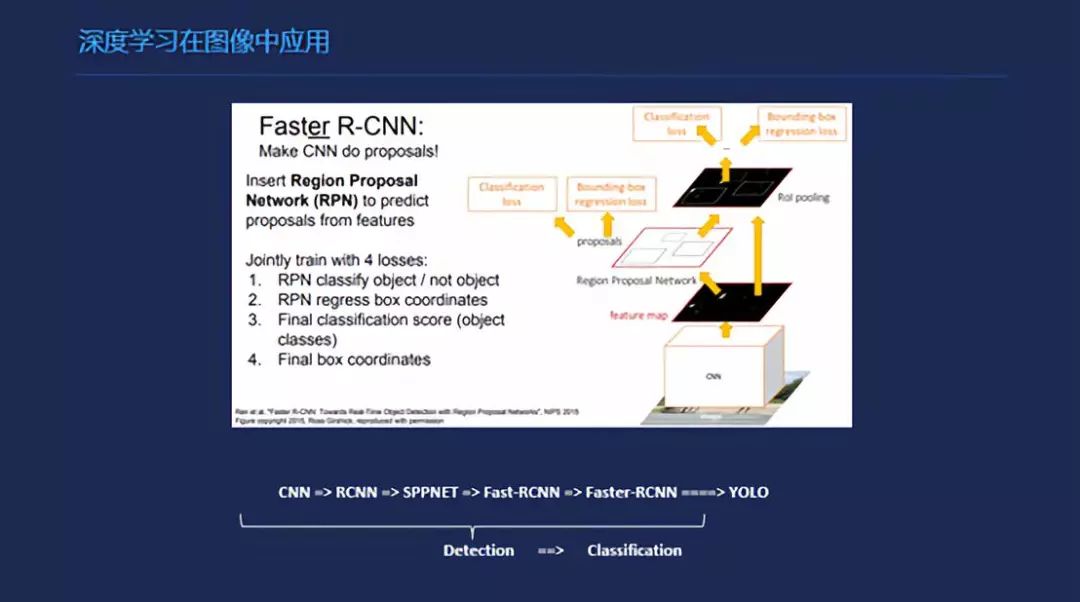
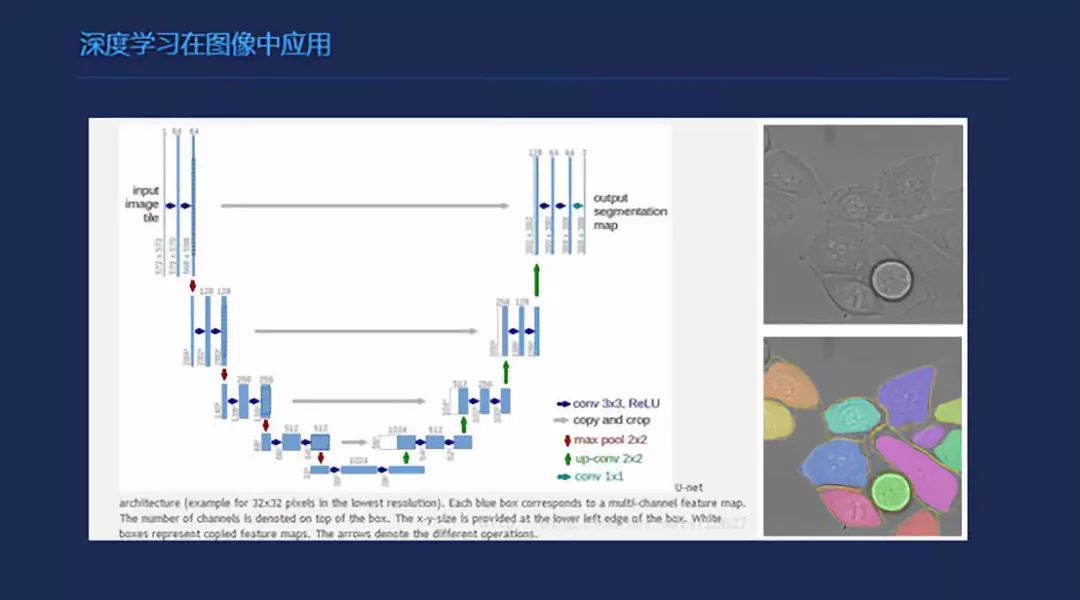
深度学习在图像中的应用,前面是特征层,到后面会有一些比较高一级的特征,到后来会进行一个全连接,再进行分类。简单的说,分类的话是最简单的一个网络吧,就是卷积之后加几个全链接,输出就可以了。在检测上的话,除了一个基本的网络之外,会加一些proposal这一部分的结构。在分割上,我觉得最早的,让我印象比较好的第一个是U型网络,其实现在有很多也在用这个思想。
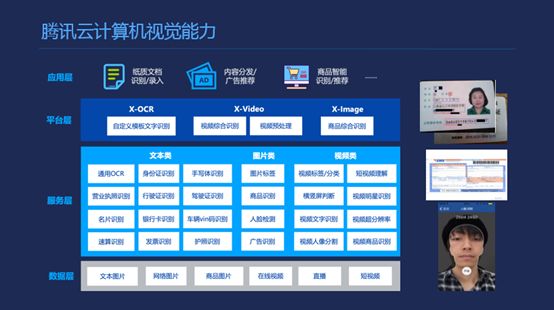
最后讲一下腾讯云的能力,腾讯云,我们其实开放的大部分是高等级结果层,主要分三块,OCR、Video、Image。包括人脸上我们会输出一些人脸的检测点,现在已经开放一百个标注点了,根据这些标注点可以做一些自己的应用,我们也希望或者在有余力的情况下开发一些更偏下游的,让开发者有更多的开用工具,这样开发的自由度更高一点,但坦率讲这个对我们工作压力是非常大的。在底层,像平台这一面,平台更多的是虚拟机,一些计算资源,计算资源上搭了一些通用的软件,这部分应该还是比较容易获得的,现在一个是从下往上,另一个角度从上往下,争取把结果进行一个更好的覆盖,开发者从粗粒度到细粒度的工具,能够开发出我们更想要的应用场景。
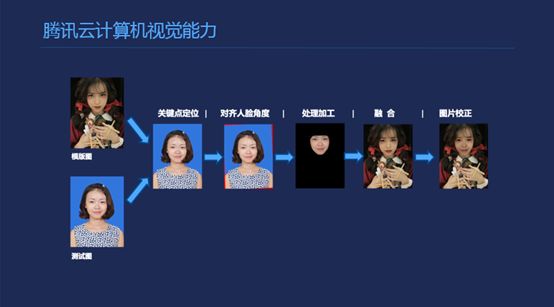
这是一个例子,我们做一个人脸融合,把一张模板的图片和一个用户的图片揉合在一起,先是定位,之后是配准,之后把脸部分割出来,融合是没有进行开放也不太好开放的地方,这里涉及到一些渲染的方法,再加上光照的广大,形成最后的融合图。

还有一个案例,是最近工业性的一个应用案例,现在用的手机屏幕的生产线是一个高自动化的生产线系统,涉及的人力非常少,用他们的话说只要机器不坏我们是不进去的,唯一涉及到人的部分,可能就是看它有没有缺陷的部分。这个缺陷的部分,像黑点、光斑的部分是缺陷的部分。
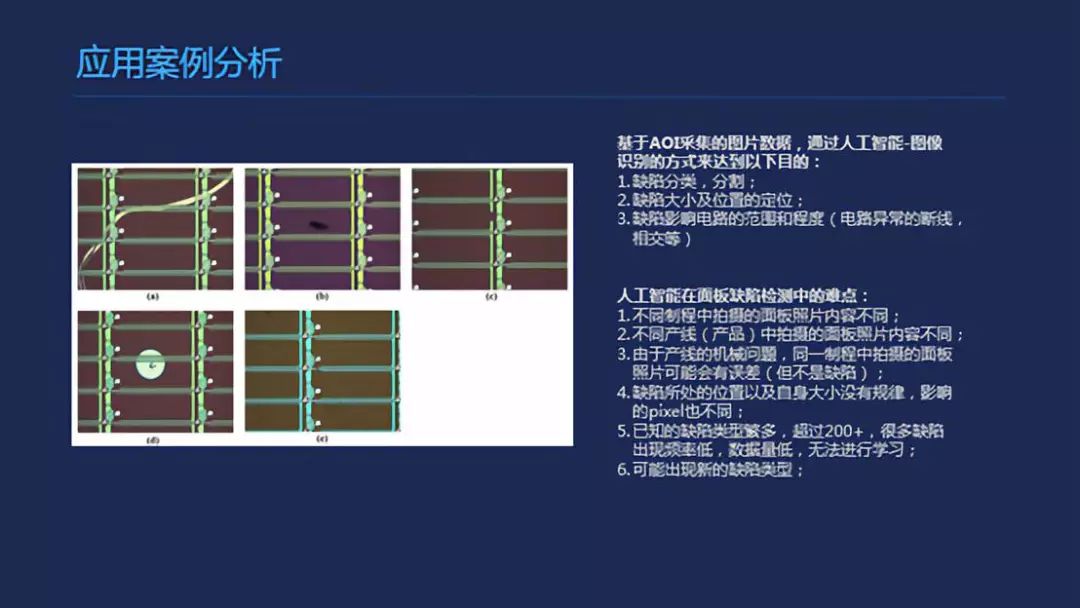
这一块主要的问题,要解决这个视觉应用的话,第一个问题是你能看到的,其实一个切入点是你需要把你几个缺陷部分和背景度相分离出来,至于背景后面的分析,其实用传统的一些方法可能更为可靠一些,因为背景基本上变化范围非常少,而且你让他怎么变化,可能产生的变化因素是什么,比如聚焦、失焦,产品的更迭,这样是可以有预备而来的。而且他们在高维空间里可以找到一个映射空间把它的前景和背景进行一个有效的分离。

最后是给希望在图象和计算机视觉进行进一步学习的同学们一点意见吧,介绍给大家这几本书,第三本书可以构建出一个图像分析的框架,第二本是讲深度神经网络的,包括在图像上的一些应用。上面有一些课程,他们在Youtobe上有一些课程,对编程能力和解决实际问题还是有很大帮助的。
Q:我看到您最后给我们推荐机器视觉的入门资料,我很想问一下,您觉得机器视觉和计算机视觉的区别在哪儿?或者您觉得它是一个东西吗?
A:这个很有意思,你去找机器视觉,可能发现现在机器视觉都偏向在工业上的应用,所以更多的是采用一些比较传统的方法。计算机视觉我觉得应该比这种所谓定义的视觉范围广一些的,至于他们俩是不是同样的东西,很多的学术名称都不是互斥的,都包括很多共同的东西,也包括有差异性的东西,那么在机器视觉上,至少实际应用里提到机器视觉的话你会得到一批厂商,他们主要服务的对象是谁谁谁。你提到计算机视觉的时候,会得到另外一些,包括苹果、微软、英特尔,这是另外一个圈子。所以从这个角度上是有一定分类的,但如果从技术角度或者从从业者的角度,或者从一个学习者的角度来讲,他们有很多东西是共性的。
Q:冀老师您好,我想问您两个问题,第一个问题是就技术方面来看,您会觉得计算机视觉,像图像分类或者是目标检测已经到达一个稳定水平了吗?
A:在一些通用的场景还是比较稳定的,换句话说调用的接口,得到的结果是能满足百分之六七十、七八十的场景,在一些特定的场景,更像是端到端的解决方案,我们现在已经开放的接口恐怕很难达到一个很好的效果,总结来讲,一些通用的场景或者一些通用的问题,绝大多数场景给一个方案,给一个平台,那么这个是比较稳定的。对于一些差异化的场景,只靠这些开放平台肯定是不够的。
Q:可以检测出哪个阶段产生缺陷吗?
A:因为生产阶段有不同的站点,可以通过站点之前进行回溯,避免产生资源浪费。还有多少种,我只能说这个种数,要求的种数是非常多的,至少上百种吧。我们现在理论上正在做的过程,有一部分是成熟的,有一部分不太成熟。
Q:我现在在做一个特殊字符的识别,我现在遇到一个问题,我没有那么多的训练数据,它给了我一部分测试数据,但每个字符只有一百个,就算全部拿来训练也达不到那种效果。我的训练数据非常少,我想问一下怎么生成那种数据,尽量和测试数据能达到那种效果。
A:其实你遇到的问题,我们经常遇到,我们做一个东西,给你十个例子,又不告诉你上下文,又不告诉你到底用在什么位置。从这个角度来讲,我会做什么,我们会跟需求方,无论需求方是客户还是产品经理聊这个到底干吗用?这个字符所产生可能的范围是什么样的。
Q:我们现在做那个字符是学生用手写了一个数字,画了一个圈,问题是他给我的图里,有的是可以把圈全部截到里面去,有的就截一半的圈。
A:就是一个数字的手写体。
Q:又加了一个圈,但会有干扰。
A:这个还好,这个问题不是特别大。
Q:我想问一下生成这个问题。
A:生成的话,你可以采用不同的,比如是不是都是手写的?还是也有印刷的?也有印刷的。我觉得你还是新定义一个sgop(音),看它的变数是什么,再去仿照一些样本。如果这个sgop定义不了的话,效果肯定不好,这是必然的,所以先看一下到底想解决这个问题的范围、边界在哪里。
PPT下载
以上是关于腾讯高级研究员33页PPT详解构建图像识别系统的方法!的主要内容,如果未能解决你的问题,请参考以下文章
技术大牛详解利用图像识别和边缘AI计算提升架空输电线路巡检效率附42页PPT下载