Elasticsearch 集群状态变成黄色或者红色,怎么办?
Posted 铭毅天下Elasticsearch
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Elasticsearch 集群状态变成黄色或者红色,怎么办?相关的知识,希望对你有一定的参考价值。
GET _cluster/allocation/explain?filter_path=index,node_allocation_decisions.node_name,node_allocation_decisions.deciders.*
"index": "order_info",
"shard": 0,
"primary": false
上面的几个参数解释如下:

explanation 就是根本原因。如下 head 插件和 Kibana 都能看的更为明显。


本质原因就是:只有一个节点,但是设置了副本,导致了主分片可以分片正常,副本分片无法分配。进而导致:集群健康状态是黄色。如何修复,下文会给出答案。
4、修复非健康集群状态方案汇总分片变得未分配的原因有很多种。下文概述了最常见的原因及其解决方案。
4.1 重新启用分片分配适用场景:节点重启过或者设置过禁用分片分配,但之后忘记设置重新分配策略,Elasticsearch 将无法分配分片。
需要手动更新集群设置才可以实现重新分配。
PUT _cluster/settings
"persistent" :
"cluster.routing.allocation.enable" : null
当数据节点下线或特定原因宕机导致离开集群时,分片通常会变成未分配状态。造成这种情况的原因很多,比如:连接问题;比如:硬件故障问题等。
当这些故障解决后,下线节点重新加入集群,然后,Elasaticsearch 将自动分配之前因节点下线等原因导致的未分配的分片。
为了避免在上述问题上浪费资源,Elasticsearch 默认将分配延迟一分钟。根据业务实际需要,比如:因升级内存而下线数据节点的场景,可以将该延时值调大。
参考命令行如下:
PUT _all/_settings
"settings":
"index.unassigned.node_left.delayed_timeout": "5m"
如果已恢复节点并且不想等待延迟期,则可以调用不带参数的集群 reroute API 来启动分配过程。该进程在后台异步运行。
POST _cluster/reroute
分片分配设置错误可能会导致主分片无法分配。这些设置包括但不限于:
索引层面的分片分配设置;
集群层面的分片分配设置;
集群层面的感知(awareness)分片分配设置。
GET order_info/_settings?flat_settings=true&include_defaults=true
GET _cluster/settings?flat_settings=true&include_defaults=true
注意:
更多参数设置,推荐阅读:https://www.elastic.co/guide/en/elasticsearch/reference/current/common-options.html
https://www.elastic.co/guide/en/elasticsearch/reference/current/cluster-get-settings.html
4.4 减少副本设置为了防止硬件故障,Elasticsearch 不会将副本分配给与其主分片相同的节点。
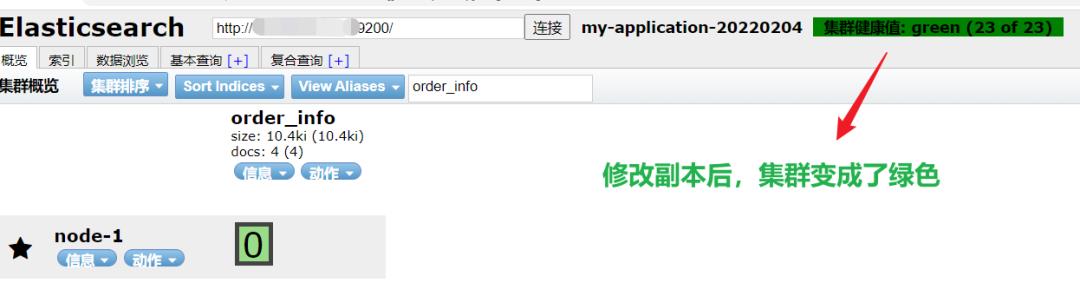
如果没有其他数据节点可用于分配副本分片,则该副本分片保持未分配状态。如开篇截图的黄色集群状态,本质就是这个原因。要解决此问题,你可以:
PS:为了保证集群线上业务的高可用性,建议每个主节点至少保留一个副本。
如下是集群层面的设置,设置后对整个集群生效。
PUT _settings
"index.number_of_replicas": 0
Elasticsearch 使用 low disk watermark 低磁盘警戒水位线来确保数据节点有足够的磁盘空间来接收分片。
默认情况下,Elasticsearch 不会将分片分配给磁盘使用率超过 85% 的节点。要检查节点的当前磁盘空间,请使用 cat allocation API。
GET _cat/allocation?v=true&h=node,shards,disk.*

如果你的节点磁盘空间不足,你通常有如下四个细化方案:
方案 1:升级节点以增加磁盘空间。
方案 2:删除不需要的索引以释放空间。
(1)如果你使用 ILM 索引生命周期管理,则可以更新生命周期策略以使用可搜索快照或添加删除阶段。
(2)如果你不再需要搜索数据,可以使用快照将其历史数据存储在集群外。
PS:这里强调的删除索引,delete 操作,不是删除数据的 delete_by_query 操作,切记!
方案 3:如果你不再写入索引,请使用强制合并 API( force merge API ) 或 ILM 的强制合并操作将其段合并为更大的段。
POST order_info/_forcemerge

PUT order_index_ext
"settings":
"number_of_shards": 5,
"number_of_replicas": 0
POST order_index_ext/_bulk
"index":"_id":1
"title":"just testing..."
"index":"_id":2
"title":"just testing..."
"index":"_id":3
"title":"just testing..."
PUT order_index_ext/_settings
"index.blocks.write":"true"
POST order_index_ext/_shrink/order_shrink_index

具体设置,参考如下:
PUT _cluster/settings
"persistent":
"cluster.routing.allocation.disk.watermark.low": "30gb"
分片分配需要 JVM 堆内存。高 JVM 内存压力可能会触发停止分片分配并使分片未分配的断路器(出现内存熔断现象)。
推荐阅读:Elasticsearch JVM 堆内存使用率飙升,怎么办?
4.7 主分片丢失情况的恢复策略如果包含主分片的节点因故障或其他原因下线,Elasticsearch 通常可以使用另一个节点上的副本替换它。
如果包含主分片的节点无法恢复或其副本不存在或无法恢复(这是比较极端的情况),则需要从快照或原始数据源重新添加丢失的数据。
注意啦,前方高能!!!
仅当节点不再可能成功恢复时才使用此选项。因为:此过程分配一个空的主分片。如果节点稍后重新加入集群,Elasticsearch 将用这个较新的空分片中的数据覆盖其主分片,从而导致数据丢失。
使用集群重新路由 reroute API 手动将未分配的主分片分配给同一角色中的另一个数据节点。将参数 accept_data_loss 设置为 true。
POST _cluster/reroute
"commands": [
"allocate_empty_primary":
"index": "order_info",
"shard": 0,
"node": "node-1",
"accept_data_loss": "true"
]
之前也有多篇文章介绍集群非健康状态修复,如下:
干货 | Elasticsearch 集群健康值红色终极解决方案
干货 | Elasticsearch集群黄色原因的终极探秘
Elasticsearch 集群故障排查及修复指南
本篇结合最新官方文档解读,更为全面和具体。
实战环节如果遇到类似问题,建议参考本文,从上到下逐一排查,直至解决。
你在实战环节肯定也遇到集群非健康状态问题,你是如何解决的呢?欢迎留言写下你的实战思考。
1. https://www.elastic.co/guide/en/elasticsearch/reference/current/fix-common-cluster-issues.html
2.https://www.elastic.co/guide/en/elasticsearch/reference/current/cluster-get-settings.html

