贝壳大数据任务调度DAG体系设计实践
Posted 大数据生态
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了贝壳大数据任务调度DAG体系设计实践相关的知识,希望对你有一定的参考价值。


文章作者:林家宝 贝壳 工程师
内容来源:作者投稿
出品平台:DataFunTalk
数据因为连接而产生更大的价值!这是大数据时代的底层色彩,所以稍有规模的公司都会组建自己的数据团队来专门的为数据服务。任务调度系统解决的就是数据的连接管理问题!(以下简称:调度。)它就像是一条高速公路与加油站、而数据则是路上的车辆,时不时的需要加油才能驶离这条公路。
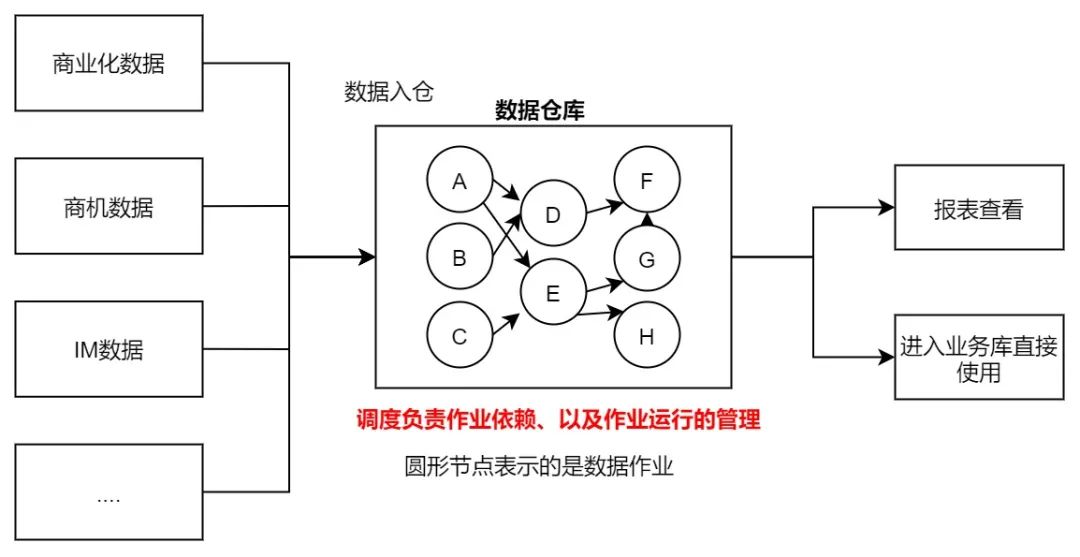
这套流程的核心就是作业调度管理和数据的ETL ( Extract,Transform,Load )、调度就是解决哪些作业先运行以及如何运行的问题。在业界有一些知名的开源系统,比如Azkaban,Airflow以及最近的 DolphinScheduler ( 也叫EasyScheduler )。
它们底层对于DAG的设计基于各自的系统特性都各不相同、对于其中关键的难点『跨周期的任务依赖』的处理方式也不同。但基本都是需要对跨周期依赖的节点进行特殊处理,例如airflow的ExternalTaskSensor以及DolphinScheduler的Dependent节点。
而目前业界还存在着一种非常灵活的跨周期依赖体系,但目前的可查的资料比较少,所以笔者根据自己的工作实践与理解将这个设计写成了这篇文章。二者的优劣暂时不比较,先看看它是怎么做到的吧。
在这个存储和计算如此廉价的时代,企业是能够承担在数据仓库中存储所有历史数据的成本的,这就意味着在需要的时候可以对历史数据进行重新的处理来响应新的变化 ( 简单来说就是,计算逻辑变化需要重刷数据,这个过程叫做数据回填Backfilling )。
但是存储的数据量过多带来的是查询分析性能的下降,遵循Hive SQL的以下最佳实践 "filter early and often","project only the fields that are needed" 改善性能最有效的措施就是将数据分区。按照什么分区呢?
生产实践中一般按照时间进行分区(大部分的表通常是按照天进行增量分区),这暗合了数据的变更周期也同时能够满足业务方看数据的需求。例子如下:
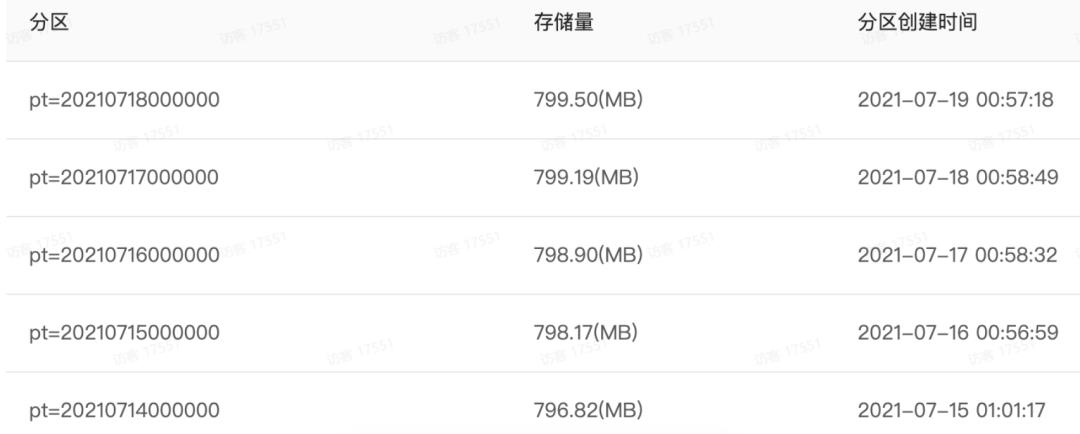
往表里写数据时也很简单,需要将数据写入该表的确切某个分区中,例如只往pt = 20210718000000分区写数据而不是把整张表覆盖了。而什么时候可以往哪个表的哪个分区写数据就是调度系统的核心了,在调度中使用任务作为基本的操作实体,表和任务是存在关联关系的、一般一个任务中只允许往一个表中写数据。
在下面这个例子中任务A会和dwd.tb4表有唯一的映射,一般表名与任务名实际是趋同的。(数仓的建模规范中每一层有专门的称呼 类似于 stg->ods->dw->olap,这里不深入讨论。)
Task-A的配置:
insert overwrite table dwd.tb4 partition(pt=2021071700000)select xxx from stg.tb1join stg.tb2join stg.tb3....where stg.tb1.pt=\'2021071700000\'stg.tb2.pt=\'2021071500000\'stg.tb3.pt=\'2021071600000\'....
Task-A实际要做的事情:

但数据需要根据时间,写入不同的分区。总不能每天改一次任务的配置,一般的会想到用hive自带的时间函数,例如current_date等进行操作,这样就能够获取动态的时间了。
insert overwrite table dwd.tb4 partition(pt=date_sub(current_date,1))select xxx from stg.tb1join stg.tb2join stg.tb3....where stg.tb1.pt= date_sub(current_date,1)stg.tb2.pt= date_sub(current_date,3)stg.tb3.pt= date_sub(current_date,2)....它延伸出来的问题就是,假如指标的计算逻辑发生了变化,用户更改了逻辑后需要把原本的历史数据一起重刷(也就是数据回填),那么就会出现历史的运行时间是 2020.07.17,date_sub (current_date,1)表示的是2020.07.16,现在于2021.07.17重刷之前的数据,那么date_sub(current_date,1)表示的就是2021.07.16。二者表现的时间相隔了一年,写入的分区也完全不一样!
这样刷出来的数据自然都是错误的了,因为它的来源与去向依赖了具体的运行时间,而运行时间本身就是不固定的。这里的时间不止是时间,还表示具体某一个部分的数据分区标志!所以我们需要引入时间参数以及参考时间的概念。关于时间参数这里给出几个例子:
| -1d | 昨天 |
| 0ws | 本周一 |
| 0we | 本周末 |
| -1ws | 前一周周一 |
| -1ms | 前一月一号 |
insert overwrite table dwd.tb4 partition(pt=\'$-1d_pt\')select xxx from stg.tb1join stg.tb2join stg.tb3....where stg.tb1.pt=\'$-1d_pt\'stg.tb2.pt=\'$-3d_pt\'stg.tb3.pt=\'$-2d_pt\'....
而参考时间如何定义生成?这个问题下个小节回答。
1. 核心设计
在系统中运行的所有作业都有周期,这种与时间关联的周期性作业,我们定义为任务。
任务:用户在产品页面进行配置的产物 ( 需要设定运行周期,用crontab表示 )
版本:任务的一个运行周期内只会有一个版本( 版本号就是上文中的参考时间 )
实例:版本的某一时刻只会有一个实例在运行( 防止计算逻辑冲突与保留刷数历史 )
参考时间:版本的版本号是通过任务的运行周期进行计算得出。一旦计算完毕就不会进行更改,运行时会将该参考时间与用户的sql一起传入程序,最终会生成一个用户平常写的sql(直接指定具体数据分区)进入底层运行。
计算过程:例如 crontab=0 0 * * * 表示的是每天0点运行,每一天就有一个周期、那么该任务的版本号就会有20210717000000、20210716000000、20210715000000 .....。
细心的同学会发现版本号与写入的目标表数据分区之间存在着gap,版本号作为参考时间而insert进表分区的则是用户输入的时间参数,例如上述例子中的 -1d_pt。这就表示任务的版本与表的数据分区实际上并不是完全对应的,它是一种错位关系。但是可以通过计算得出,这点非常的关键!
例如一般的天级别任务(每天运行一次),都是写入对应表昨天的分区,那么它们版本与表数据分区之间的gap=1。这也是大多数离线作业的常规做法。
到这里调度就任务-版本-数据分区-时间参数之间的就可以具现出来了。

2. 作业管理
作业的管理主要分为任务之间依赖关系的建立,以及确保任务按照这个依赖关系从最上游一直有序的运行到最下游。
3. 依赖关系的建立
任务之间的依赖其实就是sql中 insert overwrite 的目标表,依赖了select from的几张数据源表。以上文中提到的sql为例,依赖关系如下:

这样的依赖关系很容易就可以提取出来、因为来源与去向都很明确。但还记得吗、我们具体运行的时候是精确到了表的分区的。所以实际运行时的依赖关系应该是这样的:

运行时依赖关系中是包含了更细粒度的分区的,在调度中体现为运行时依赖关系关联到了版本上,而不是用户直接接触的任务。
所以调度需要解决的核心问题就是:用户只能配置任务间的依赖关系,而更细粒度的版本间的依赖是每天动态生成的。需要有一个工具能够在任务和版本之间搭起关联的桥!
结合sql中的pt,表数据分区与实际运行版本的关联特性,推出offset与cnt这个工具,它们是用于描述下游与上游的依赖参数。
offset = 以距离上游最新的版本相隔 offset 个版本为原点
cnt = 从offset确定的原点开始、往右数cnt个版本都是需要依赖的
对于最新版本的理解是:今天0点该任务的第一个版本(因为存在小时级任务,一天会有24个版本),对于小时级任务来说,就是0点的版本为原点。对于其他周期的任务来说、就是今天唯一生成的版本为原点(如果今天没有生成版本,就往昨天去看,以此类推)
在人类理解的依赖关系中,口语的表达就是A任务依赖B任务的前两个版本。offset和cnt是偏向数学概念,帮助程序来自动计算,也是我们人类去更清晰准确的理解任务间动态依赖关系的途径,像上面的A任务依赖B任务的前两个版本,数学表达形式A->B(-2,2),如果是前三个版本中的前两个 A->B(-3,2)。
应用这个工具,上述例子对于dwd.tb4(任务周期为天)就可以表述为:隐性条件-1d表示为昨天0点的分区,如果任务是小时级的则-1d表示它前24个小时的分区。
逻辑链条是:下游用到了上游具体的哪个数据分区,而具体这个数据分区是由任务的哪个版本写进去的。
任务 | 任务周期 | 数据分区与版本的gap | offset | cnt | 解释--理解这两个参数的重要核心 |
stg.tb1 | 小时 | 1 | -23 | 1 | -1d表示的是昨天零点的数据分区。stg.tb1昨天有24个版本,哪一个版本是往昨天0点的数据分区写数据?答案是昨天1点的版本、所以offset=-23 |
stg.tb2 | 天 | 2 | -1 | 1 | -3d表示为前3天0点的分区,数据分区与版本之间的gap是2、所以是昨天的版本在往-3d的分区写数据、所以offset=-1 |
stg.tb3 | 天 | 3 | 1 | 1 | -2d表示前2天0点的分区、数据分区与版本之间的gap是3、所以理论上是明天的版本会往-2d分区里面写数据、offset=1 |
可以看到对于stg.tb3这个任务的配置会比较奇怪,但是按照上述给出的背景(包括任务周期,dwd依赖的pt,数据分区与版本的gap)来看,想要使用这个表-2d_pt的数据,只能等到它明天的版本运行完成才可以。例如今天是2021.07.22,那么就需要等到2021.07.23这个版本完成才会写入它-2d_pt的数据。
对于周级别的乃至月级别任务,只要使用的时间参数是对应的周期,那么就和天级别的依赖设置相同。但当这种大周期的任务和小周期任务混搭的时候,总是有用户摸不着头脑。
offset锚定之后,cnt的计算很简单,就不细说了。目前线上运行的实际情况比较复杂,很多时候需要人工的调整参数才行。例如有的任务一周只在周一和周五运行,有些任务需要依赖上个月同一天的数据(到但是任务每天都运行),只能人理解了这些逻辑之后才能够写出正确的配置。
这套体系只能解决95%的配置问题,还有少数的需求需要专业的同学指导。
4. DAG图运行节奏
运行时依赖关系建立完毕,之后自然是与具体的运行顺序进行绑定。我们的预期就是任务按照最开始的源头进行触发,然后一层层一个个的按照依赖关系的顺序运行。这个涉及到版本的生命周期建设与管理:这个部分倒是更偏向于程序的设计,不像上一部分那样会有数学意义上的理解。比较简单。
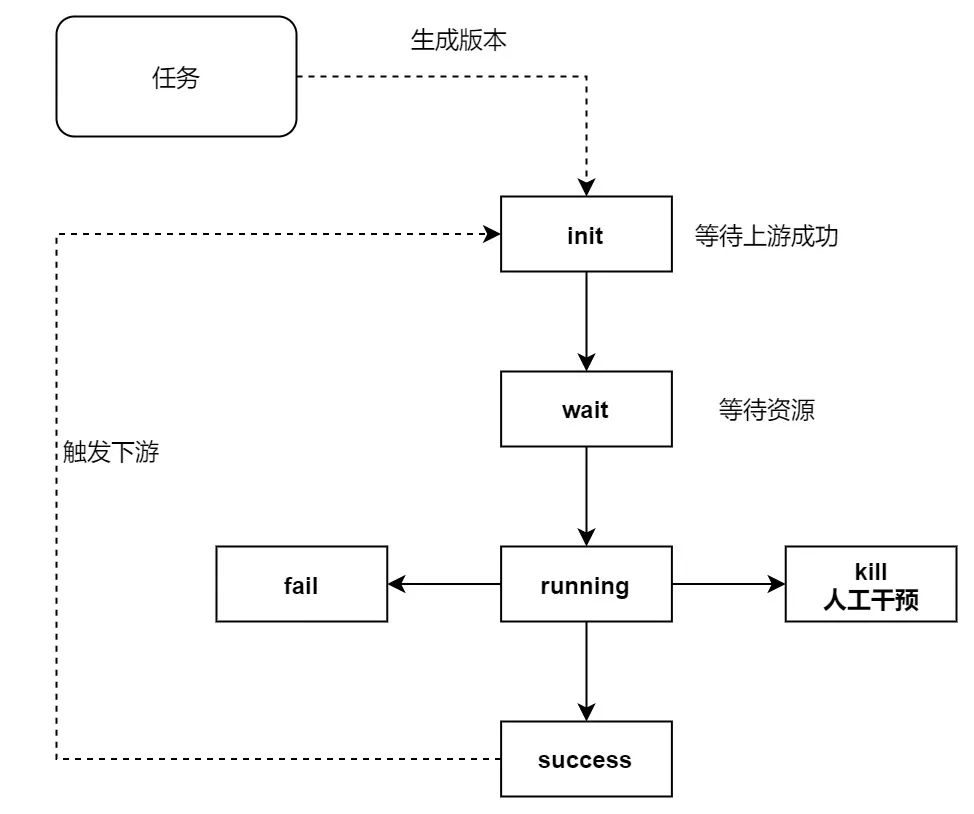
运行成功的版本添加一个trigger,会尝试触发它的下游版本进入运行状态。而这时下游节点本身会开展check行为,去判断它的所有上游是否已经完成。期间注意多个上游同时完成,同时触发的锁问题之外没啥值得注意的点。

5. 设计的优缺点
对比DolphinScheduler的跨周期依赖的设计,它把跨周期的依赖本身当作单独的任务去对待,不断的check上游是否完成。这种设计相对而言会比较的笨重一点,但优点是好理解。
文章中给出方案的优缺点如下:
优点:这种设计能够很通用的适应各种语言和架构,任务的依赖配置非常的灵活,面对各种夸周期的依赖。诸如天任务依赖周任务,周任务依赖月任务等等复杂的场景都能解决。
缺点:理解成本比较高,用户配置起来比较吃力。(所以系统的维护人员一般需要提供自动化的接口,通过解析sql来完成依赖间offset和cnt的配置),但也很难做到完全的自动化,覆盖率在95%以上。
笔者从实践问题出发,一步步还原出核心设计面临的场景,个人觉得还是比较通熟易懂的。要是觉得文章写的不错的,点个赞吧!
▌参考文章:
https://medium.com/@rchang/a-beginners-guide-to-data-engineering-the-series-finale-2cc92ff14b0
https://medium.com/@rchang/a-beginners-guide-to-data-engineering-part-ii-47c4e7cbda71
https://medium.com/@rchang/a-beginners-guide-to-data-engineering-part-i-4227c5c457d7
今天的分享就到这里,谢谢大家。
在文末分享、点赞、在看,给个3连击呗~
分享嘉宾:

福利下载:
互联网核心应用算法宝藏书PPT电子版下载!
大数据典藏版合集PPT电子书下载!
活动推荐:

关于我们:
[005]大数据
[005]大数据
?
已使用 Microsoft OneNote 2013 创建。
以上是关于贝壳大数据任务调度DAG体系设计实践的主要内容,如果未能解决你的问题,请参考以下文章