从输入网址到内容返回解析|前端工程师需要掌握这些知识
Posted 好未来技术
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从输入网址到内容返回解析|前端工程师需要掌握这些知识相关的知识,希望对你有一定的参考价值。

https = fs = options = key: fs.readFileSync( cert: fs.readFileSync( res.writeHead( res.end( 外网IP:default_server; / Host X-Real-IP X-Forwarded-For https://abcdef; /etc/apache2/ssl/nginx-cert.crt; /etc/apache2/ssl/private.key;
使用带有负载平衡的多个服务器组件,取代单一的组件,可以通过冗余提高可靠性。负载平衡服务通常是由专用软件和硬件来完成。主要作用是将大量作业合理地分摊到多个操作单元上进行执行,用于解决互联网架构中的高并发和高可用的问题。

图:4层负载均衡与7层负载均衡
05
应用服务过程
应用服务可以是通过网关链接的微服务,也可以是一个自带网关的应用。Web服务器由于要同时为多个客户提供服务,就必须使用某种方式来支持这种多任务的服务方式。一般情况下可以有以下三种方式来选择,多进程方式、多线程方式及异步方式。其中,多进程方式中服务器对一个客户要使用一个进程来提供服务,由于在操作系统中,生成一个进程需要进程内存复制等额外的开销,这样在客户较多时的性能就会降低。为了克服这种生成进程的额外开销,可以使用多线程方式或异步方式。在多线程方式中,使用进程中的多个线程提供服务, 由于线程的开销较小,性能就会提高。事实上,不需要任何额外开销的方式还是异步方式,它使用非阻塞的方式与每个客户通信,服务器使用一个进程进行轮询就行了。
5.1 传统的方式
传统的方式是内核提供硬件驱动、通信,资源分配(进程)、系统调用的能力,我们的应用部署在操作系统上。例如,在操作系统上安装启动 apache,通过用 ssh 连接服务器部署具体的应用资源。一般情况下,web server本身能够处理一些静态请求,静态请求通常是一些html、CSS、javascript等静态文件,这种文件里面写什么就会显示什么。如果存在内容是有php或者golang写的,web server就会往后端的application(应用服务器)上转,这些application(应用服务器)就会按照微服的一些功能将他划分开,这个就看用户是需要查看图片还是需要上传资料,如果是需要上传资源就存放到后端的数据库服务中,如果是要查看图片我们就直接响应给用户,如果是要生成订单我们还要将这些订单信息写到数据库中,数据库写完之后后端服务器再把这个请求返回给web server。

图:传统应用部署
5.2 虚拟化的方式
虚拟化技术是一套解决方案,完整的情况需要CPU、主板芯片组、Bios和软件的支持,通过虚拟化技术可以将一台计算机虚拟为多台逻辑计算机。在一台计算机上同时运行多个逻辑计算机,每个逻辑计算机可运行不同的操作系统,并且应用程序都可以在相互独立的空间内运行而互不影响,从而显著提高计算机的工作效率。
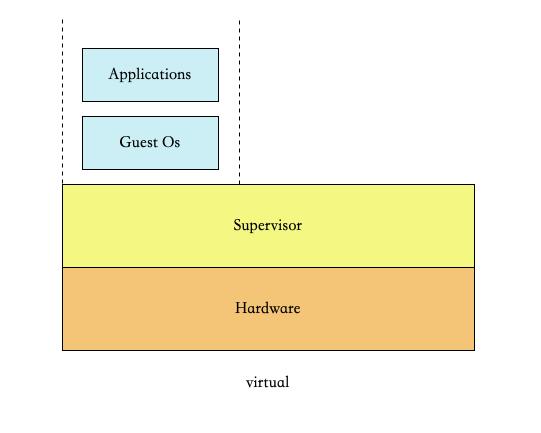
图:传统虚拟化部署
在传统虚拟化方法中,同一台物理机的每个逻辑计算机可运行不同的操作系统,这些guest OS完全不会看到实际的硬件为何,只能使用由Superv isor(Supervisor是用Python开发的一套通用的进程管理程序)所提供的所有虚拟硬件。
5.3 容器化应用的方式
我印象里,早期的前端工程师都是非常了解操作系统的,因为部署代码和运行应用要涉及到很多基础的知识,随着容器化技术的发展,现在部署这部分越来越简单,更加方便弹性扩容,你只需要将你的项目和依赖包(基础镜像)打成一个带有启动指令的项目镜像,然后在服务器创建一个容器,让镜像在容器内运行,就可以实现项目的部署了。
传统虚拟化方式是在硬件层面实现虚拟化,需要有额外的虚拟机管理应用和虚拟机操作系统层。Docker容器化是在操作系统层面上实现虚拟化,直接复用本地主机的操作系统,因此更加轻量级。

图:传统虚拟化vs容器化
可以将Docker容器理解为一种轻量级的沙盒,每个容器内运行着一个应用,不同的容器相互隔离,容器之间也可以通过网络互相通信。Docker 包含三个基本概念,分别是镜像(Image)、容器(Container)和仓库(Repository)。
docker镜像是使用Dockerfile脚本,将你的应用以及应用的依赖包构建而成的一个应用包,它通常带有该应用的启动命令。而这些命令会在容器启动时被执行,也就是说你的应用在启动容器时被启动,一次构建,多处移植使用,再配合shell等脚本语言实现脚本化一键部署。
容器:通常是指 linux 容器,采用轻量的虚拟化技术(namespace、cgroup、rootfs)来规划资源,是一组特殊的进程。Docker 提供标准的接口(OCI)来管理和运行容器,核心思想就是如何将应用整合到容器中,并且能在容器中实际运行。
仓库:用来存储docker镜像,通过镜像的ID唯一标识了镜像。你可以把你的docker镜像通过push命令推送到docker仓库,然后就可以在任何能使用docker命令的地方通过pull命令把这个镜像拉取下来。
在容器化方案中,容器是一组特殊的进程,容器共享宿主机的内核,容器通过镜像来实现应用的可移植性和一致性。服务器就是容器的宿主机,docker容器与宿主机之间是相互隔离的。也可以理解成,镜像是基础,容器是镜像使用者,仓库是镜像的管理员。

图:镜像和容器与仓库的关系
Docker有这么一种机制,在构建镜像时,它可以依赖一个父镜像作为底层镜像,与当前正要被构建的镜像一起打包,从而构建成一个全新的镜像。而这个被用作依赖的父镜像,就是基础镜像。比如,通常我们开发一个nodejs应用,它不是随处可运行的,它的运行需要依赖操作系统环境和nodejs运行环境。因此,一个单纯的node项目镜像是无法运行起来的,它需要依赖一个基础镜像,这个基础镜像就是nodejs镜像,nodejs镜像内包含了操作系统环境和nodejs环境。
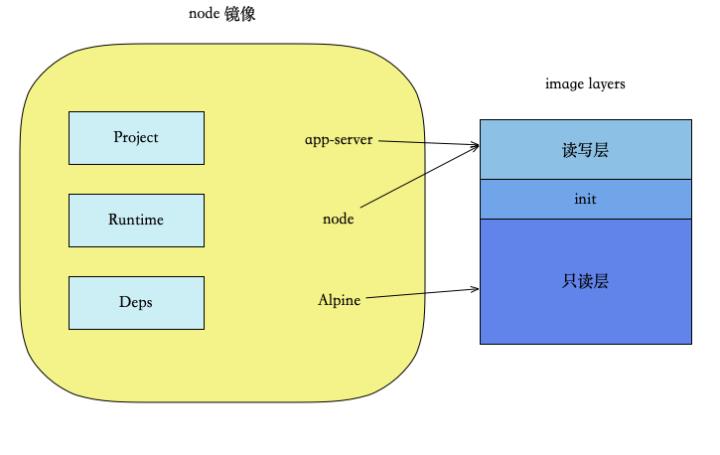
图:node镜像
总之,Docker 通过 Dockerfile 来对环境进行描述,通过镜像进行交付,使用时不再需要关注环境不一致相关的问题。如火如荼的docker,现已被很多大公司所采用。同时docker也成为了实现serverless(无服务器架构)服务的基础架构。包括阿里云,亚马逊在内的云计算服务商都采用了docker来打造serverless服务平台。
5.4 Kubernetes的方式
待应用程序分散在云,虚拟机和服务器之间。手动管理应用程序不再是可行的选择。如果规模变大或者在生产中如何进行容器编排,部署扩容机制如何?
在容器编排领域,比较著名的主要有Kubernetes、Mesos 及 Docker 自家的 Swarm。Kubernetes 是一个可扩展的用于容器化应用程序编排管理的平台,它工作在容器层而不是硬件层,提供复杂作业中集群管理、容器编排、任务调度,还提供了一些与 PasS 类似或者共同的功能,比如部署,扩容,监控,负载均衡,日志记录等。
Kubernetes 架构是一个比较典型的二层架构和 Server-Client 架构。Master 作为中央的管控节点,会去与 Node 进行一个连接。客户端(比如UI/CLI等)只会和 Master 进行连接,把希望的状态或者想执行的命令下发给 Master,Master 会把这些命令或者状态下发给相应的节点,进行最终的执行。Kubernetes 的 Node 是真正运行业务负载的,每个业务负载会以 Pod 的形式运行。一个 Pod 中运行一个或者多个容器,真正去运行这些 Pod 的组件的是叫做kubelet,也就是 Node 上最为关键的组件,它通过 API Server 接收到所需要 Pod 运行的状态。

图:K8s简单架构
06
总结
从用户输入域名到收到数据,发生了很多的事情,虽然对于用户而言感觉到的反馈的越少越好,但是对于工程师而言越多实践越能了解其中的细节。缓存是如何被利用的?缓存失效会导致多少资源的消耗?对于简化部署、提供伸缩性、灵活性,选择怎样的底层基础设施在不同量级的业务应用上遇到的问题也表现不同,知道的越多,遇到问题才越有信心去解决。
参考资料
TCP、HTTP协议HTTP请求完整过程:https://blog.csdn.net/m0_46195271/article/details/109035832
WEB服务访问的过程:
https://blog.csdn.net/eagle89/article/details/77891314
正常情况下一次web服务的访问过程:
https://blog.csdn.net/Dou_Hua_Hua/article/details/108868920
Docker应用容器化(将应用程序部署到容器中):
http://c.biancheng.net/view/3159.html
Java Web架构篇之API网关:
https://blog.csdn.net/zangdaiyang1991/article/details/92573264
什么是docker镜像?:
https://www.zhihu.com/question/27561972
Docker中文文档 Image镜像:
http://www.dockerinfo.net/image%e9%95%9c%e5%83%8f
虚拟化介绍及Docker与传统虚拟化有什么区别:
https://blog.csdn.net/qq_39626154/article/details/96572340
Docker与虚拟化(虚拟机区别):
https://blog.csdn.net/lisheng19870305/article/details/112329235
七张图了解Kubernetes内部的架构:
https://zhuanlan.zhihu.com/p/149403551
Kubernetes 架构及核心概念
https://www.cnblogs.com/kkbill/p/13031518.html

我知道你“在看”哟~
从输入网址到页面显示经历了什么
一,解析域名转换成对应的公网的IP地址
二,根据公网IP通过互联网路由到对应的服务器上
三,建立可靠的TCP数据连接;
四,服务器对该URL中的请求进行处理分发,逐步返回一个完整的html;
五,浏览器或者客户端对该HTML进行渲染;
具体内容:
一,解析域名转换成对应的公网的IP地址
1,使用DNS服务,将域名解析为Ip地址:
a,递归查询
b,迭代查询
从客户端到本地DNS服务器是属于递归查询,而DNS服务器之间就是的交互查询就是迭代查询
2,解析顺序
a,浏览器缓存
当用户通过浏览器访问某域名时,浏览器首先会在自己的缓存中查找是否有该域名对应的IP地址(若曾经访问过该域名且没有清空缓存便存在);
b,系统缓存
当浏览器缓存中无域名对应IP则会自动检查用户计算机系统Hosts文件DNS缓存是否有该域名对应IP;
c,路由器缓存
当浏览器及系统缓存中均无域名对应IP则进入路由器缓存中检查,以上三步均为客户端的DNS缓存;
d,ISP(互联网服务提供商)DNS缓存
当在用户客服端查找不到域名对应IP地址,则将进入ISP DNS缓存中进行查询。比如你用的是电信的网络,则会进入电信的DNS缓存服务器中进行查找;
e,根域名服务器
当以上均未完成,则进入根服务器进行查询。全球仅有13台根域名服务器,1个主根域名服务器,其余12为辅根域名服务器。根域名收到请求后会查看区域文件记录,若无则将其管辖范围内顶级域名(如.com)服务器IP告诉本地DNS服务器;
(10台在美国,各一台在英国,瑞典,日本)
f,顶级域名服务器
顶级域名服务器收到请求后查看区域文件记录,若无则将其管辖范围内主域名服务器的IP地址告诉本地DNS服务器;
g,主域名服务器
主域名服务器接受到请求后查询自己的缓存,如果没有则进入下一级域名服务器进行查找,并重复该步骤直至找到正确纪录;
h,保存结果至缓存
本地域名服务器把返回的结果保存到缓存,以备下一次使用,同时将该结果反馈给客户端,客户端通过这个IP地址与web服务器建立链接。
二,根据公网IP通过互联网路由到对应的服务器上
根据路由表内容查询数据转发路径:
目标网络的IP地址:32位,这里在上文提到,是目标网络的IP地址而非目标计算机的IP地址
目标网络的子网掩码:32位,即子网掩码
下一跳IP地址:32位,如果目标网络需经过多个路由器,下一跳即使下一个路由器的IP地址
离出接口名字:路由器会提供多个接口,每个接口通向不同的网段,所以表项中需要提供该项,即使确定IP分组从哪一个接口发出去,离出接口只是标识本路由器的信息,没有过多的全局含义
度量:从该路由器到达目标网络的代价,这个属性反映这一路径的优劣,由于路由协议的不同,该项具体数据形式也不同,常见的有跳数(途径路由器的数量),当前往返时间,最窄链路带宽等等
三,建立可靠的TCP数据连接
三次握手,四次分手
四,服务器对该URL中的请求进行处理分发,逐步返回一个完整的html;
五,浏览器或者客户端对该HTML进行渲染;
以上是关于从输入网址到内容返回解析|前端工程师需要掌握这些知识的主要内容,如果未能解决你的问题,请参考以下文章