数据分析终极一问:指标波动多大才算是异常?
Posted 网易有数
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据分析终极一问:指标波动多大才算是异常?相关的知识,希望对你有一定的参考价值。
导读:
先举个例子,体温37.4度vs体温36.5度,只有2.5%的波动,可如果有人在测温点被发现体温37.4度,估计马上就被拉走做核酸。为啥?因为人们不是怕2.5%的波动,而是怕新冠!
所以:指标波动不可怕,指标波动代表的业务场景才可怕!脱离业务场景谈指标波动就是耍流氓。
在各种业务指标中,数据往往不是静止不变的,尤其是当一些核心的指标发生了变化、波动时,就需要判断这样的波动是否属于异常的情况。那么波动了多大才能算是异常?本文将结合一些实际业务场景,来说明数据波动的异常判别方法。
指标数据波动,是各种业务场景下都会遇见的情况,如每日GMV、每日订单量等,都是在不断变化的。大多数情况下,变化是“正常”的波动,但有一些波动,源于突然发生的外部原因或其他未被预期的因素,导致其表现出不同于正常模式的异常状态。若能准确地识别异常波动,从而做出波动预警,并及时应对,就能一定程度上保证所关心的业务场景系统的整体稳定性。
波动类型
数据波动绕不开时间特性。业务中最常遇到的就是今天的指标是什么样子?过去几天是什么趋势?未来一段时间会怎么样的变化?数据+时间构成了波动的两个基本属性。
根据时间的不同特征,常见的波动类型有:
一次性波动:偶发的、突然性的波动。一般是由于短期、突发的事件而影响的指标的波动,比如说某头部主播在某次直播里上了严选的商品、某明星的同款商品在严选有库存等,就会造成订单量临时性的超出预期的上涨。
这样的波动影响时间短,往往几天的时间便会恢复正常波动。举个单量的例子,在大促期间都是单量的爆发期,大促即为一次“偶发事件”,此时单量的波动即为一次性波动。其具有如下的特征图:
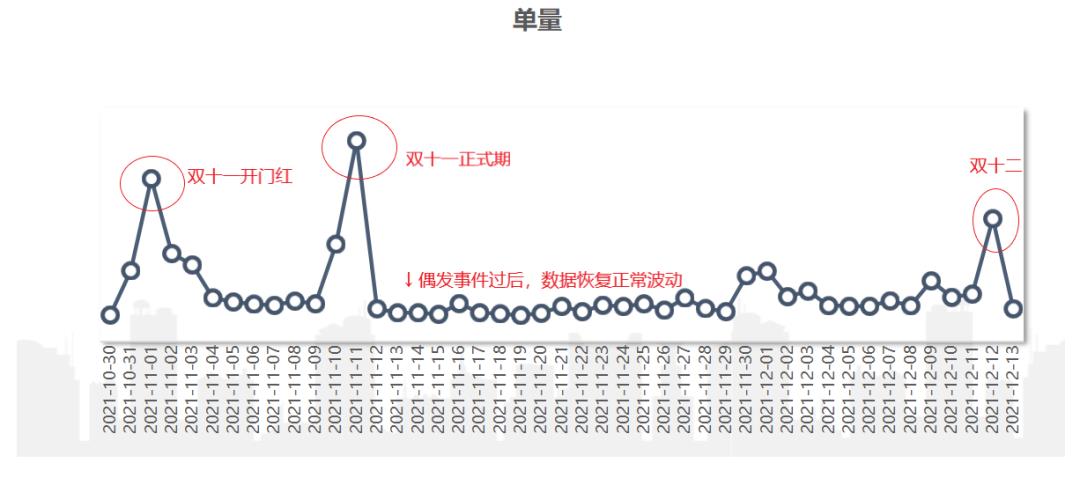
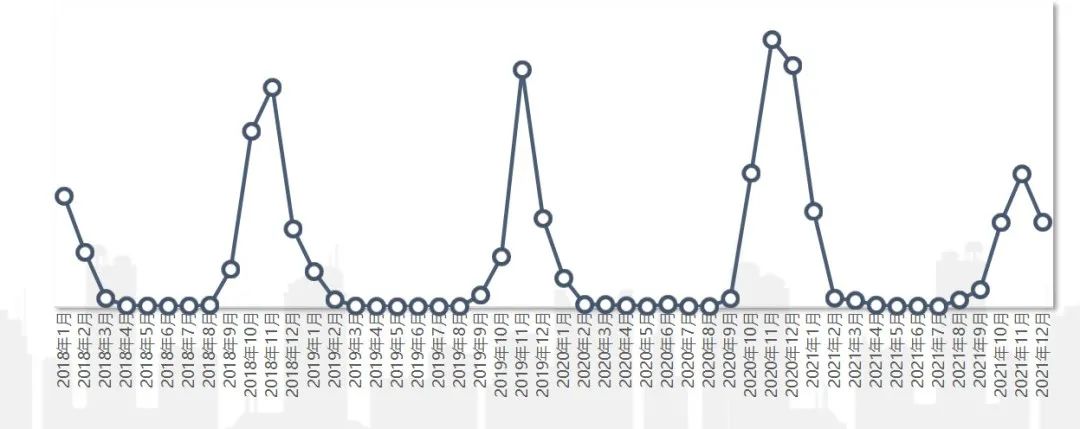
周期性波动:这种波动和时间节点强相关,且经常以周或者季、年为循环节点。如羽绒服秋冬季节卖的比较好,到了春天销量就下降,夏天几乎没有销量,且每年几乎都是这样。
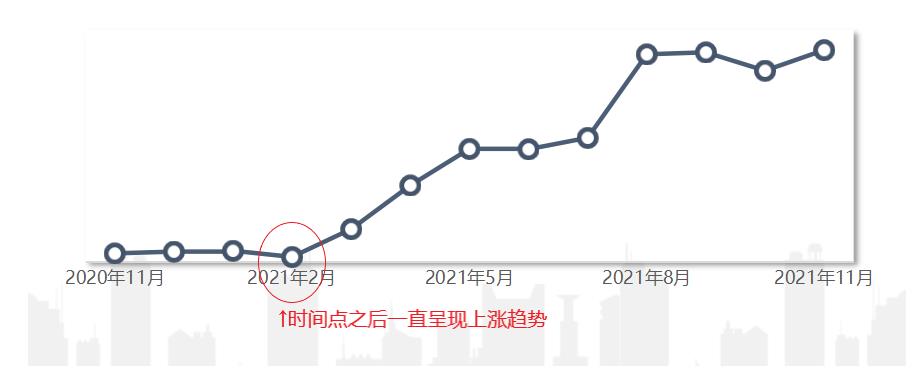
持续性波动:从某一时间开始,指标一直呈现上涨/下降趋势。如从今年4月开始,浴室香氛品类的销售量一直呈现上涨趋势,这就属于持续性波动。而持续性波动背后的原因往往是更深刻的,如订单结构的变化、环境因素的影响,从而出现了这种持续性趋势。
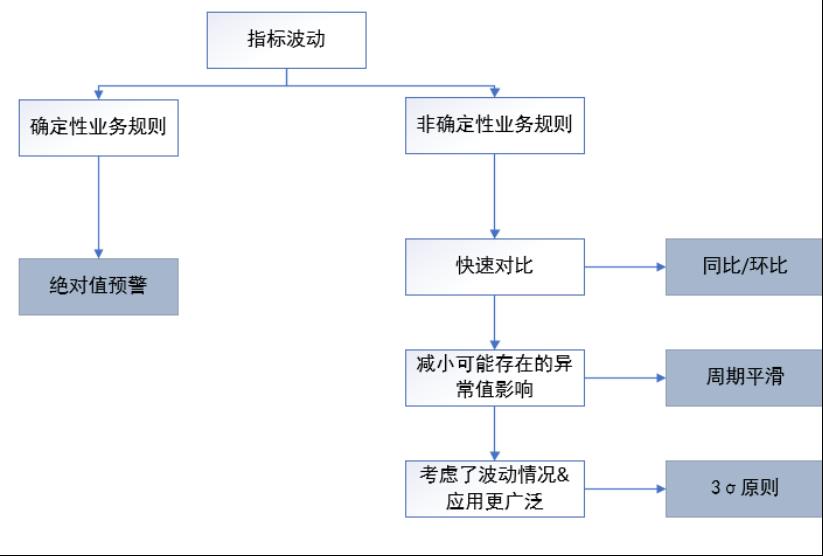
异常识别
那么什么样的波动可以看作是“异常”呢?异常识别也可以认为是异常检测。这里主要从绝对值预警、相对值预警两个方面来说明。
2.1 绝对值预警
绝对值预警,即是通过设定一定的阈值,当指标低于/高于阈值的时候,就认为此时指标波动为异常,并进行预警。
举个例子,严选作为一个品牌,毛利是其核心的一个指标。对毛利可设置绝对值预警:当毛利为负时,就认为此时是异常的情况,需要探究其发生的原因,并解释这种异常的波动。通过对毛利的绝对值预警,严选及时发现了部分用户利用咖啡机进行薅羊毛、从而导致咖啡机毛利为负的行为,并完善了规则减少了严选的损失。
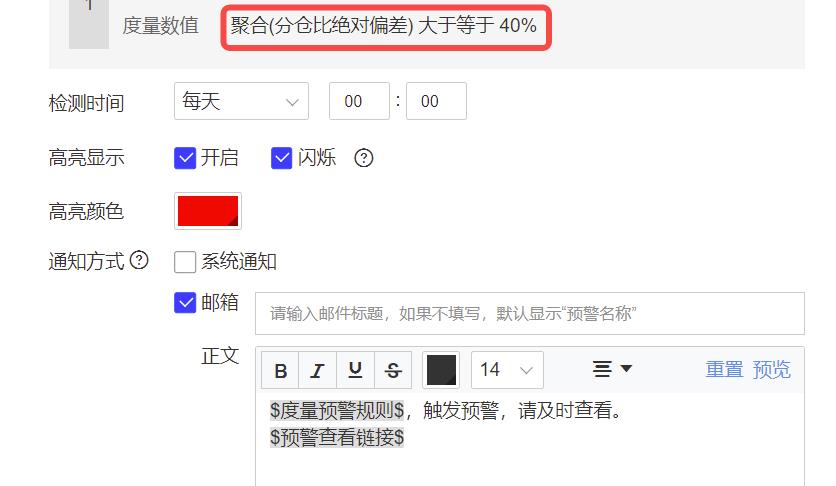
不仅可以设置低于某一个定值,也可以当指标高于某一定值的时候进行预警,比如在供应链中,某个大仓的分仓比高于40%,就会导致仓库负荷过重从而影响生产。
绝对值预警往往是一次性的波动,这样的异常判定比较简单,只需要设定对应的阈值即可。而阈值的设定可以根据具体的业务的不同和规则而变化。
目前在有数BI中可以直接设置绝对值预警:
2.2 相对值预警
然而实际业务中,绝对的阈值只能提供一个“底线”。除了一些非常确定性的业务场景外,在其他情况下,过高的“底线”就会导致误报,过低的“底线”可能会漏掉很多需要预警的情况。于是作为绝对值预警的补充,相对值预警可以根据历史数据及波动情况,来判断当前的波动是否为异常。
(1)同比环比
同比环比是业务场景中比较常用的一种异常检测方式,利用当前时间周期与前一个时间周期(同比)和过去的同一个时间周期(同比)比较,超过一定的阈值即认为该点是异常的。实际中常用周/日环比、年同比来进行比较。

如上图,(1)的数据为所要判断的值。当(1)的数值为百分比时,如来源于主站订单的比例,则同比环比一般为:
环比:(1)-(2) pt
同比:(1)-(3) pt
而当(1)的数值为非百分比时,如来源于主站的订单数量时:
环比:((1)-(2))/(2) %
同比:((1)-(3))/(3) %
根据值得正负来判断是上涨还是下降。通过与上周/昨天和去年同期的数据表现进行对比,计算波动值,再将波动值和阈值进行对比,从而得到当前时刻数值是否在正常的波动中(阈值的设定方法在后面介绍)。
如在上述的周期性波动的例子中,在11月环比波动都会较大,这时设置同比波动预警会比设置环比波动预警更为合理。于是在波动判别中,需要注意业务实际背景。
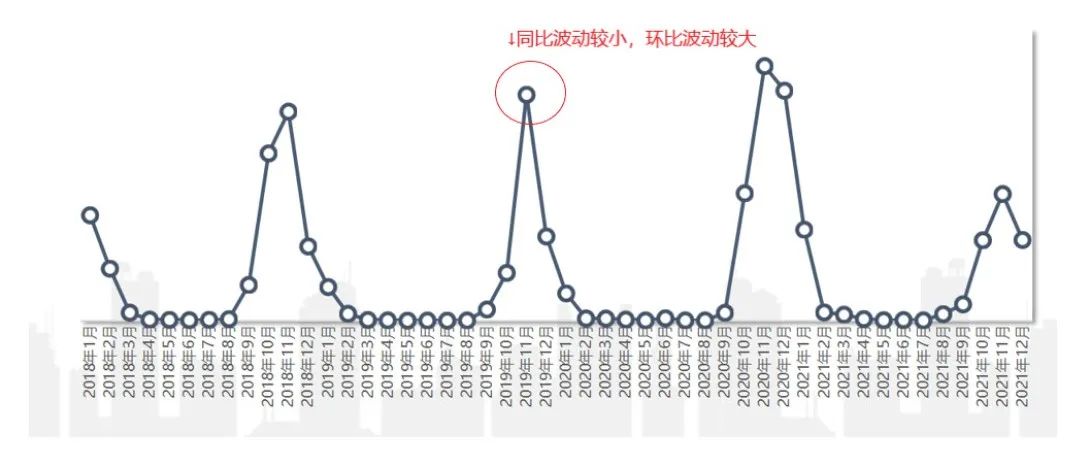
(2)周期平滑
同比/环比仅使用1~2个时间点的数据,容易受到数据本身质量的影响:当历史同期或上个周期的数据本身就是“异常”的时候,用“异常”的数据来判断是否“异常”就不太合适。
一个很自然的想法就是将所参考的时间点拓展,利用多个时间点的周期数据进行平滑,得到当前时刻指标的对比值。如:
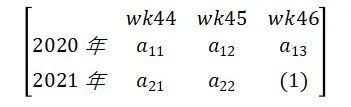
则比较值:
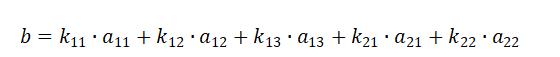
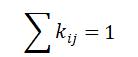
其中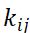 为平滑系数,当都为相同的值的时候,此时即为平均值。也可越靠近所研究时间点,赋予更高的平滑系数。所选的时间点可以根据业务需求自行定义。
为平滑系数,当都为相同的值的时候,此时即为平均值。也可越靠近所研究时间点,赋予更高的平滑系数。所选的时间点可以根据业务需求自行定义。
利用比较值b和所研究的值(1)对比,超过一定的阈值即可认为是“异常”,其波动需要关注。
(3)假设检验(3σ原则)
前面提到比较值需要和所研究的值进行对比,通过阈值来判断波动是否异常。阈值的定义方法和预警方法类似,分为绝对值阈值和自适应(相对值)阈值。
绝对值阈值:根据历史正常情况下的数据波动情况,计算比较值和所研究的值之间的差异情况,从而定义一个上/下限值,即为阈值。
自适应阈值:根据数据波动情况而变化的阈值,其理论基础为假设检验和大数定律,来判断是否为异常。
不妨假设当前时间点的指标数据为b,历史用于对比的指标数据为:
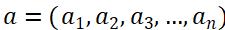
其中:
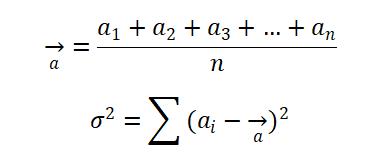
分别表示对比数据的平均水平和波动情况。则根据大数定律和假设检验,当
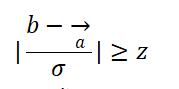
即可认为当前时间点的指标数据为异常波动。其中z为置信水平所对应的值,如当z=1.96时,置信水平为95%,即可认为在100次的波动下,有95次是在正常范围内波动的(置信水平及其对应的值可参考标准正态分布表)。当z=2.58,置信水平为99%,即为著名的“3σ原则”。
3.3 其他方法
除了以上所介绍的一些常用的、便捷的方法外,也可以通过时间序列、算法模型等来判断异常值。异常值判别是比较常见的研究场景,但由于实操的复杂性,这里仅做一个介绍。
(1)时间序列
业务上的数据往往具有时间属性,如单量随时间的变化、GMV随时间的变化等。那么在时间序列中,通过异常检测的方法,也可以对当前波动是否异常做出判断。常用的方法有:
平均法:移动平均、加权移动平均、指数加权移动平均、累加移动平均等。和上述的“周期平均”的方法类似,可自定义窗口大小和加权系数。
ARIMA模型:自回归移动平均模型(ARIMA)是时间序列中一个基础模型,利用过去的几个数据点来生成下一个数据点的预测,并在过程中加入一些随机变量。使用该模型需要确定ARIMA所需的参数,即需要对数据点进行拟合。利用拟合后的方程确定下一个时间点的数据的区间,从而判断当前波动是否为异常。
此外还有ESD、S-ESD、S-H-ESD、STL分解等算法,来检测异常点。
(2)算法模型
基于分类方法:根据历史已有的数据,将其分为正常、异常的两类,之后产生的新的观测值,就可以使用分类的方法去判断新的观测值是否为异常。如使用距离判别的K-means算法、SVM算法等。
神经网络方法:可以对具有时间特性进行建模的LSTM算法、用卷积神经网络来做时间序列分类的Time Le-Net,以及各种的监督式模型,都是能够对异常数据进行识别的算法。
总结
在实际应用中,还需要结合业务背景来进行方法的选择。一般来说,判断异常的主要方法有:
九数,网易严选数据分析师,负责严选供应链仓配域的分析工作。
最新的推文无法在第一时间看到?
以前的推文还需要复杂漫长的翻阅?
进入“网易有数”公众号介绍页,点击右上角
“设为星标”!
置顶公众号,从此消息不迷路

到底多大才算高并发?
一、什么是高并发
定义:
高并发(High Concurrency)是使用技术手段使系统可以并行处理很多请求。
关键指标:
-响应时间(Response Time)
-吞吐量(Throughput)
-每秒查询率QPS(Query Per Second)
-每秒事务处理量TPS(Transaction Per Second)
-同时在线用户数量
关键指标的维度:
-平均,如:小时平均、日平均、月平均
-Top百分数TP(Top Percentile),如:TP50、TP90、TP99、TP4个9
-最大值
-趋势
「并发」由于在互联网架构中,已经从机器维度上升到了系统架构层面,所以和「并行」已经没有清晰的界限。「并」(同时)是其中的关键。由于「同时」会引发多久才叫同时的问题,将时间扩大,又根据不同业务关注点不同,引申出了引申指标。
引申指标:
-活跃用户数,如:日活DAU(Daily Active User)、月活MAU(Monthly Active Users)
-点击量PV(Page View)
-访问某站点的用户数UV(Unique Visitor)
-独立IP数IP(Internet Protocol)
-日单量
二、多大算高并发
这个问题的答案不是一个数字。来看两个场景:
场景1:
木头同学去一家创业公司面试。这个公司做的产品还没有上线,面试官小熊之前就职过公司的产品都没有什么量。
小熊:“有高并发经验吗?”
木头:“我们服务单机QPS2000+,线上有4台机器负载均衡。”
这时候小熊心里的表情大概是:

但是如果小熊就职的公司是美团之类的。那这这时候小熊心里的表情大概是:

场景2:
固态硬盘SSD(Solid State Disk)说:我读取和写入高达 1000MB/秒
mysql说:我单机TPS10000+
nginx说:我单机QPS10W+
静儿说:给我一台56核200G高配物理机,我可以创建一个单机QPS1000W

不在同一维度,没有任何前提,无法比较谁更牛。“我的系统算不算高并发?”这个问题就如同一个女孩子爱问的问题:“我美不美?”
三、高并发的本质
俗话说:「没有对比就没有伤害」。算不算高并发,这个问题的答案需要加对比和前提。
对比包括:
-业界:在业界同类产品中并发量处于什么位置。举个栗子??,美团外卖的日单量是千万级别,一个系统日单量在百万,虽然差一个数量级,但是相比大多数公司已经很不错。
-自身:在自身系统中,并发问题是否已经是系统的瓶颈?如果是,这么这个瓶颈怎么打破?如果不是,那当初架构设计的时候是怎么保证并发不是问题的?(别告诉我:是通过系统没有访问量来保证的[擦汗])。
前提包括:
-业务复杂度:举个栗子??,访问百度首页的时间基本就是看自己家的网速,通常情况下都是点一下就看到结果了。而扫描二维码支付,通常需要等很久,虽然这可能已经是业界最牛的支付公司出品了。
-配置:用高配物理机得出的数据和最老最低配的虚拟器上的出来的结果是无法比较的。通常的配置有:cpu、内存、磁盘、带宽、网卡
高并发的本质不是「多大算高并发」的一个数字,而是从架构上、设计上、编码上怎么来保证或者解决由并发引起的问题。当别人问你:“做过高并发吗?”回答者完全可以描述自己系统的各项指标,然后开始叙述自己对系统中对预防、解决并发问题作出的思考和行动。
四、总结
过程大于结果,方向大于方法。
相关阅读:
以上是关于数据分析终极一问:指标波动多大才算是异常?的主要内容,如果未能解决你的问题,请参考以下文章
R语言plotly可视化:可视化箱图数据点自定义设置箱图中数据点的显示方式添加抖动数据点无异常数据点(whisker轴须边界包含所有数据)可疑异常值为数据点异常值为数据点(outlier)