直击RocketMQ面试现场
Posted 35岁程序员那些事
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了直击RocketMQ面试现场相关的知识,希望对你有一定的参考价值。

参与方式

关注公众号:35岁程序员那些事,后台回复关键词“参与抽奖”,获取抽奖链接,点击抽奖。 中奖之后,可以联系笔者的微信号或者公众号后台回复关键词“联系笔者”,获取联系方式。
在微服务架构下,分布式事务一直是痛点和难点。Seata是阿里巴巴开源的分布式事务中间件,致力于以高效且对业务无侵入的方式,解决在微服务场景下面临的分布式事务问题。
本书作者是阿里巴巴GTS创始人和Seata作者,结合其多年在分布式事务领域设计、研发和应用的经验,深入浅出地阐述了分布式事务技术基础、Seata AT模式、TCC模式、RPC设计、事务协调器技术的原理,并给出了两个开发实例(AT模式和TCC模式)。
本书可以为微服务系统架构师、研发人员解决核心业务实际问题提供思路,也适合分布式技术相关专业的学生阅读,帮助他们建立分布式事务的知识框架。
如上书籍只是笔者列举的一些资源,如果中奖的技术人的书架上已经入驻了上述书籍,可以通过“微信”和笔者联系。
公众号初衷
知识输出是笔者的初衷,借助知识输出,能够认识更多的牛人,能够和牛人沟通,也是自己技术提升的一个机会。
本人微信ID,如有需要惠请联系
一路向北

人间灯火无不休,爱与山水与春
----无题

面试现场亲身经历,直击58同城一面,面经分享
哈喽,大家好,这周参见了
58同城的一二面在这里还原一下面试现场,顺便分享面试经验
本期是一面
点赞收藏准备好,都是干货
投递简历
一条是在Boss直聘上投的简历,一开始显示的是安居客,原因小伙伴们可以思考一下。
初看hr的头像特像我一个朋友,当时就觉得有戏,果不其然。
“请问有面试过58同城、安居客或者车欢欢之类的技术岗位吗”
“没有”
“那我们约个时间远程面试吧”
“好的”

这里因为我没准备好,还推迟了一次时间,挺不好意思的,但建议大家如果感觉储备不足,可以抓紧找面试题恶补一下。
一面
一面面试官长得很像我当初培训班的老师,瞬间亲切了许多。
简单做个自我介绍吧
面试官您好,我目前就职于去哪儿网,负责公司内部财务,OA,监控系统的开发和维护。……
这里就不赘述一条的经历了,嘱咐大家几点吧
- 介绍自己时简单流畅,最好提前写个草稿。
- **对自己过往经历的好与坏要适度介绍。**比如好的地方比如公司背景不用说那么多,大家都懂,太张扬面试官容易为难你;不好的比如一条频繁跳槽,这个不要想着避讳,一定会问你,索性自己解释,可以说
目前的业务不利于业务发展,和预期不符,及时止损 - 可以简单介绍自己做过的项目,引导面试官去问你相关问题,掌握节奏。
说说你做过的你觉得技术性比较高的项目吧
这种面试官是比较好的,让你自己说最熟悉的,这时候就可以把你准备好的东西讲出来了。
因为涉及公司机密,项目就不详细说了,同样几点嘱咐,关于如何准备项目
- 项目要有一定的技术深度,什么,没有怎么办?抄!网上有很多高并发的项目,比如如何设计一个秒杀系统,拿过来,把里面的知识理解透了就可以。
- 最好准备两个,以防面试官出其不意。
- 除了公司内,自己最好有一些开源项目,不需要多高深,主要是让面试官看到你在不停的学习,像一条一样写一些博客也是可以的。
动态代理是如何实现的,有哪几种,什么区别呢?
一般这块都会从AOP开始问,然后就开始连环炮,问的你脑瓜子嗡嗡的。
来看看应该怎么回答
首先,代理是说不接触真实要访问的对象,而是通过访问代理对象达到目的,好比代理商。
代理类和被代理类实现共同的接口,所以在访问者看来两者没有丝毫的区别
代理又分为静态代理和动态代理。
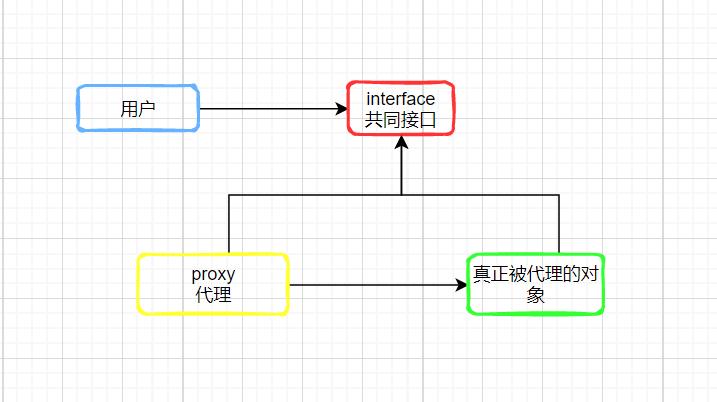
静态代理:由程序员创建代理类或特定工具自动生成源代码再对其编译。在程序运行前代理类的.class文件就已经存在了。
动态代理:在程序运行时动态创建而成。分为以下两种。
jdk动态代理
利用反射机制生成一个实现代理接口的匿名类,在调用具体方法前调用InvokeHandler来处理。
cglib动态代理
利用ASM(开源的Java字节码编辑库,操作字节码)开源包,将代理对象类的class文件加载进来,通过修改其字节码生成子类来处理。
区别
JDK代理只能对实现接口的类生成代理;
CGlib是针对类实现代理,对指定的类生成一个子类,并覆盖其中的方法,这种通过继承类的实现方式,不能代理``final`修饰的类。
性能
JDK代理使用的是反射机制实现aop的动态代理,CGLIB代理使用字节码处理框架asm,通过修改字节码生成子类。所以
jdk动态代理的方式创建代理对象效率较高,执行效率较低;
cglib创建效率较低,执行效率高;
即使不问,也要自己说,加分点。
了解常用的垃圾回收器吗,比如CMS,G1。
垃圾回收器几乎也是必问
CMS基于标记-清楚算法,先根据引用计数法或可达性分析标记垃圾。然后再清楚垃圾,会产生空间碎片,降低堆空间的利用率。
连环炮开始
可达性分析什么?
什么可以作为GC ROOT?
CMS具体过程是什么样的?
CMS哪些步骤是并发的,哪些串行的?
什么是浮动垃圾?
有什么优点和缺点?
是不是又懵了?看看怎么回答
过程
- 初始标记(STW initial mark)
STW:停止虚拟机正在执行的任务,暂停整个JVM,根据可达性分析标记垃圾
- 并发标记(Concurrent marking)
继续向下追溯标记,应用程序的线程和并发标记的线程并发执行,所以用户不会感受到停顿。
- 并发预清理(Concurrent precleaning)
排除掉进入老年代的对象,缓解重新标记的压力,减少停顿。
- 重新标记(STW remark)
暂停虚拟机,收集器线程扫描在CMS堆中剩余的对象。扫描从"跟对象"开始向下追溯,并处理对象关联。
- 并发清理(Concurrent sweeping)
清理垃圾,并行的。
- 并发重置(Concurrent reset)
重置CMS数据结构
缺点
- 产生空间碎片。 CMS不对堆空间整理压缩节约了垃圾回收的停顿时间,但也带来的堆空间的浪费。
- 消耗更多的CPU资源
- 降低堆空间的利用率
浮动垃圾
由于 CMS 并发清理阶段用户线程还在运行着,伴随程序运行自然就还会有新的垃圾不断产生,这一部分垃圾出现在标记过程之后,CMS无法在当次收集中处理掉它们,只好留待下一次GC时清理。
应用场景
1.对停顿比较严格,能提供较大的内存和cpu
2.存活对象较多
还不错,G1呢,如何分区的?
和CMS对比一下?
G1采取了不同的策略来解决并行、串行和CMS收集器的碎片、暂停时间不可控等问题—G1将整个堆分成相同大小的分区或称为Region
收集整体是使用标记-整理,Region之间基于复制算法,GC后会将存活对象复制到可用分区(未分配的分区),所以不会产生空间碎片。
分区过程
MIN_REGION_SIZE:允许的最小的REGION_SIZE,即1M,不可能比1M还小;
MAX_REGION_SIZE:允许的最大的REGION_SIZE,即32M,不可能比32M更大;限制最大REGION_SIZE是为了考虑GC时的清理效果;
TARGET_REGION_NUMBER:JVM对堆期望划分的REGION数量,而不是实际划分的REGION数量(重点);
计算HR size的逻辑主要在setup_heap_region_size函数中
1.计算初始堆内存和最大堆内存的平均值average_heap_size
2.取HR size下限(1MB)和average_heap_size / 2048的最大值,赋值给region_size
3.region_size按2的幂次对齐
4.根据region_size计算卡表的大小
G1的优缺点
缺点
region 大小和大对象很难保证一致,这会导致空间的浪费;特别大的对象是可能占用超过一个 region 的。并且,region 太小不合适,会令你在分配大对象时更难找到连续空间,这是一个长久存在的情况。
优点
1、可根据用户设置停顿时间,制定回收计划(但是也可能存在超出用户的停顿时间). — 最主要的目标
2、局部上来看是基于“复制”算法实现的,无磁盘碎片。
3、对GC停顿可以做更好的预测
关于G1能问的问题还有很多,建议大家花时间好好研究一下
还有一些比较新的垃圾回收器知道吗,比如``ZGC`
这个一条也没听过,以后专门出一期讲一下。
什么是服务熔断?
如何判断什么时候需要熔断?
服务熔断
服务熔断可以理解为电路中的保险丝,一旦失败的调用次数达到我们设置的阈值,熔断器打开,禁止访问服务,返回一个fallback,比如“服务正忙,请稍后访问”;
那要怎么恢复呢?
可以设计了一个时钟选项,默认的时钟达到了一定时间(这个时间一般设置成平均故障处理时间,也就是MTTR),到了这个时间,进入半熔断状态;
半熔断状态,允许定量的服务请求,如果调用都成功(或一定比例)则认为恢复了,关闭熔断器,否则认为还没好,又回到熔断器打开状态;
一般服务熔断的实现都是通过Hystrix组件。
核心类是HystrixCommand,在整个机制中,Command负责了核心的服务熔断和降级的处理,子类要实现的方法主要有两个:
run方法:实现依赖的逻辑,或者说是实现微服务之间的调用;
getFallBack方法:实现服务降级处理逻辑,只做熔断处理的则可不实现;

服务降级
服务熔断返回fallback就是服务降级的过程。比如某明星发布一条重大新闻,有人直接就可以刷出页面,有人返回系统忙。这是因为为了维持系统的高可用,采取的牺牲部分用户的体验,弃车保帅的思想。
线程wait和block的状态有什么区别?
用过线程池吗?
有哪些参数?
阻塞队列怎么选择?
线程数怎么设置?
这里线程池的知识一定要了解。
wait:
线程主动放弃CPU,等待被唤醒。
block:
线程被动阻塞。只有当前释放锁,他才有可能获取锁。
线程池的数量怎么设置
先看一个生产设置线程池的代码
ThreadPoolExecutor poolExecutor = new ThreadPoolExecutor(
2,
5,
0L,
TimeUnit.MILLISECONDS,
new LinkedBlockingDeque<>(3),
Executors.defaultThreadFactory(),
new ThreadPoolExecutor.AbortPolicy()
);

mysql用过吧,索引底层结构是什么,有什么好处?
间隙锁了解吗
索引,面试必问,B+树,必考,而且能问的你怀疑人生。看看怎么回答。
B+树的优点
1.B+ 树非叶子节点上是不存储数据的,仅存储键值。
这样的好处就是可以存储更多的键值,使树变得矮而胖。减少IO的次数。
2.B+ 树索引的所有数据均存储在叶子节点,而且数据是按照顺序排列的。
这样的好处是对于范围查找和排序以及去重变得简单,B+ 树中各个页之间是通过双向链表连接的,叶子节点中的数据是通过单向链表连接的。
间隙锁
间隙锁(Gap Lock)是Innodb在可重复读提交下为了解决幻读问题时引入的锁机制。锁的是索引叶子节点的next指针。举个简单的例子。
BEGIN;
/* 查询 id 在 7 - 11 范围的数据并加记录锁 */
SELECT * FROM `test` WHERE `id` BETWEEN 5 AND 7 FOR UPDATE;
在开启一个事务
/* 事务3插入一条 id = 4,name = '小白' 的数据 */
INSERT INTO `test` (`id`, `name`) VALUES (4, '小白'); # 正常执行
/* 事务4插入一条 id = 6,name = '小东' 的数据 */
INSERT INTO `test` (`id`, `name`) VALUES (6, '小东'); # 阻塞
结论
- 对于指定查询某一条记录的加锁语句,如果该记录不存在,会产生记录锁和间隙锁,如果记录存在,则只会产生记录锁,如:WHERE
id= 5 FOR UPDATE; - 对于查找某一范围内的查询语句,会产生间隙锁,如:WHERE
idBETWEEN 5 AND 7 FOR UPDATE;
间隙锁属于比较重要有比较冷门的知识,要仔细看,加分项
好,那我今天的问题就这些了,我们这面一共是4面,一到两天会约您二面,你还有什么问题要问我吗?
好的,谢谢您,想问一下,这面主要是负责什么业务呢?
主要是风控方向,到时三面的经理会和你详细说。
好的,我这没有问题了.
那我们今天就到这,拜拜
好的,谢谢您,再见
以上,就是一面的全部过程,其实问的问题比这要多,都是由浅入深。只是给需要面试的同学一个参考。
面试心态
最后聊聊面试心态,其实面试并不能衡量一个人的技术好坏,所以对于面试的成败,希望大家都看得轻一些,主要是通过面试能和大佬交流,学知识为主。
希望大家都能面试顺利。
我是一条,一个在互联网摸爬滚打的程序员。
道阻且长,行则将至。大家的 【点赞,收藏,关注】 就是一条创作的最大动力,我们下期见!
以上是关于直击RocketMQ面试现场的主要内容,如果未能解决你的问题,请参考以下文章