听说:分布式ID不能全局递增?
Posted 架构摆渡人
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了听说:分布式ID不能全局递增?相关的知识,希望对你有一定的参考价值。
点击上方蓝字“设为星标”
大家好,我是【架构摆渡人】,一只十年的程序猿。这是实践经验系列的第十一篇文章,这个系列会给大家分享很多在实际工作中有用的经验,如果有收获,还请分享给更多的朋友。
前面有篇文章我们讲到用时间来代替自增ID进行分页排序,原因是因为接入了分布式ID,但是分布式ID不能够保证有序,只能保证全局唯一。
那么今天我们一起来探讨下,究竟能不能实现有序的分布式ID呢?

分布式ID的实现方式
号段模式是目前用的比较多的实现分布式ID的方式,号段模式通过预先获取一段范围,然后全部在内存中进行ID的分发,性能极高。
采用号段模式实现的开源框架也有很多,比如美团的Leaf,滴滴的Tinyid。对号段模式实现原理不了解的小伙伴可以查看下面的地址进行深入学习。号段模式想要实现递增比较难,文章后面我们一起聊聊有没有什么方式能够实现。
Leaf: https://github.com/Meituan-Dianping/Leaf
Tinyid: https://github.com/didi/tinyid
Snowflake 是 Twitter 开源的分布式ID生成算法,在国内用的也比较多。比如百度开源的uid-generator就是基于Snowflake算法进行改进。
uid-generator:https://github.com/baidu/uid-generator
Snowflake生成ID性能很好,而且也满足递增的要求。不过依赖机器上的时间,如果时间不一致就会有重复的问题。
Redis 可以直接使用Incr命令进行数字的递增,从而实现自增的ID。如果使用Redis实现分布式ID需要进行ID的持久化,否则重启后就没了会出现重复的问题。
既然要持久化,那就避免不了使用AOF或者RDB实现持久化。使用RDB可能会丢失数据,导致ID重复发生。使用AOF肯定要配置刷数据的模式为always,每次操作记录都同步到硬盘上,这样才能保证数据不丢失,但是性能较差。当然Redis 4.0还有混合模式(AOF+RDB)可以用也是一种不错的选择。
无论是单机还是集群环境下,某个key必定会路由到某一个节点。虽然Redis单机也能支持10万基本的QPS,假设你的ID需求超过了这个量级,这块就会成为瓶颈,因为你要保证自增,没办法水平扩容。
号段模式想有序怎么办?
号段模式数据不会丢失,性能高,是一个很优秀的方案。但是号段模式没办法实现全局的递增ID,如果要实现全局递增,那么就不能拆分,得有一个固定的节点,所有请求都从这个节点获取ID才行。但是号段模式就是分段的特性,通过分段可以实现水平扩展,提升性能。
号段模式只能实现局部递增,比如我订单表接入了分布式ID,如果用号段模式,那么就会出现我下第一单的ID是20001,接着下第二单,ID可能就是10003。如果此时用的是ID降序排序,就会出现顺序错乱的问题,这也是之前文章里面为什么要用高精度的时间来排序。
这种情况下,是否只要保证同一个用户下的数据是递增的就可以,这就是局部递增。如果要想实现局部递增需要考虑下面几个问题:
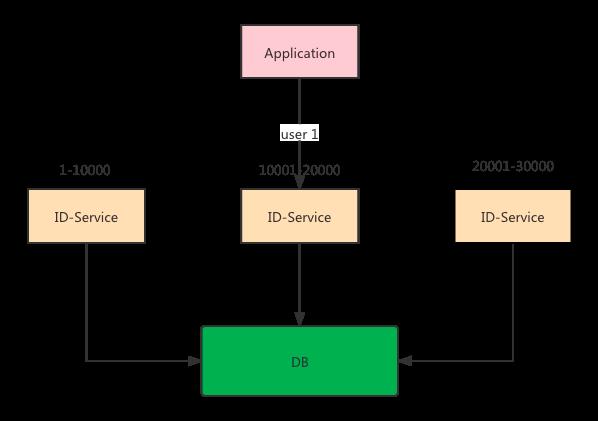
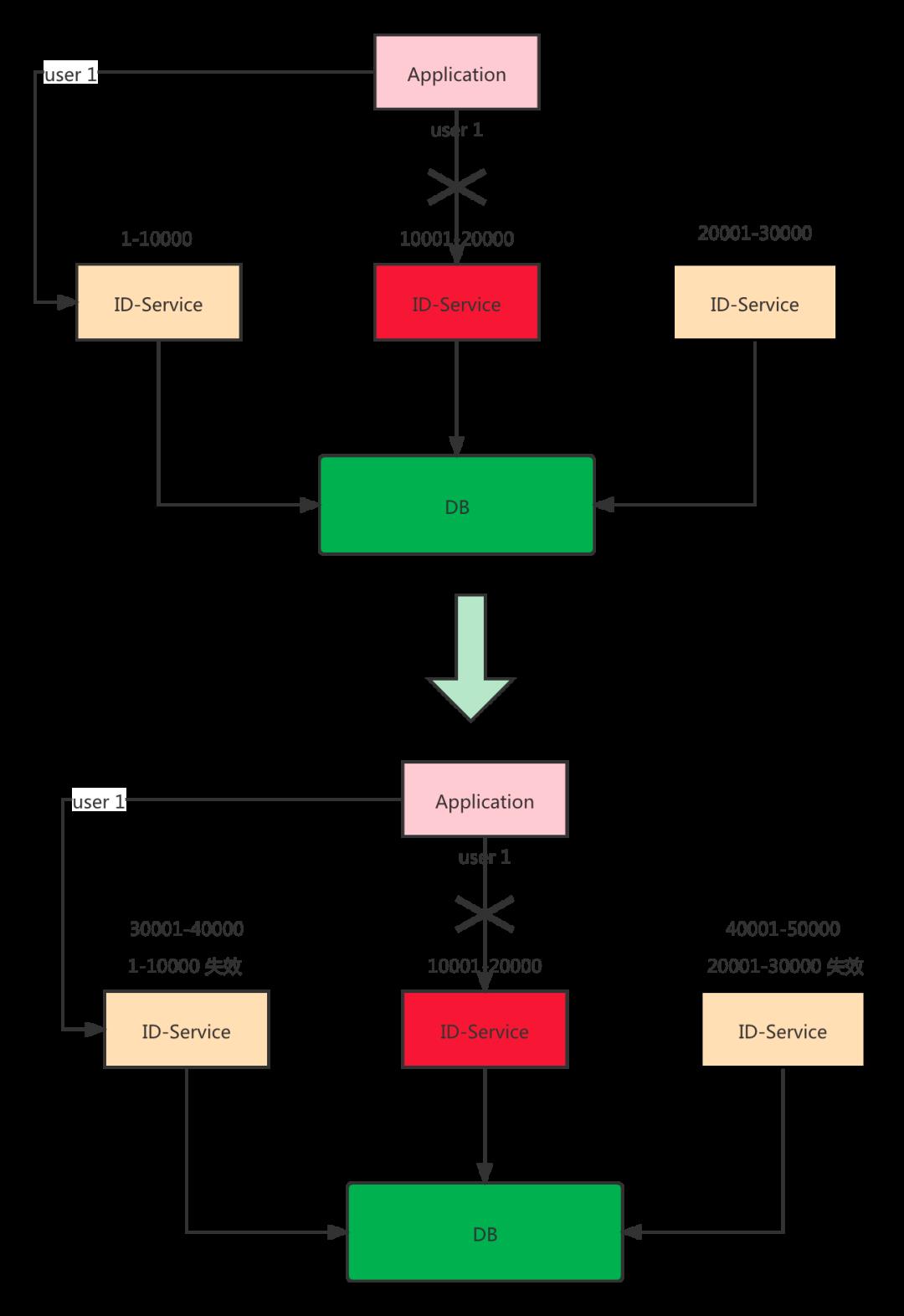
假设用户A一直是路由到 id-service-b 上面,此时 id-service-b 挂掉了,那就需要重新找个新的节点进行路由,问题来了,路由到新的节点,假设是 id-service-c。
而此时 id-service-c 上面的ID 段可能比 id-service-b大,如果大的话就没问题,还是递增。如果小的话就有问题了呀,所以这个问题要解决。
如何解决上面的问题呢?
个人感觉这个问题不太好解决,因为路由到某一个节点的用户是N,也不可能对这些用户现有的ID进行查询,判断是否大于即将路由的服务的ID段。整个逻辑太复杂了。
有一个简单的方式,就是当有固定路由需求的ID要进行路由切换的时候,全局加锁(此时并发量大的话会影响使用方的RT),将这个ID对应的所有段都清除,这样重新路由的时候就又申请了新的段,新的段肯定大于之前的段,也就是递增。
总结
总结
其实要想实现某个需求,背后的方式有很多。如何去选择适合,最优的方案这个是比较考验大家平时的积累和技术的广度。你得知道每种方案的原理是什么,差异点在哪,哪种成本更低,哪种能够完全符合业务需求。
原创:架构摆渡人(公众号ID:jiagoubaiduren),欢迎分享,转载请保留出处。
如何在分布式场景下生成全局唯一 ID ?
全局唯一:这是最基本的要求,不能重复;
递增:有些特殊场景是必须递增的,比如事务版本号,后面生成的 ID 一定要大于前面的 ID;有些场景递增比不递增要好,因为递增有利于数据库索引的性能;
高可用:如果是生成唯一 ID 的系统或服务,那么一定会有大量的调用,那么保证其高可用就非常关键了;
信息安全:如果 ID 是连续的,那么很容易被恶意操作或泄密,比如订单号是连续的,那么很容易就被看出来一天的单量大概是多少;
另外考虑到存储压力,ID 当然是越短越好。

优点:理解起来最容易,实现起来也最简单。
缺点:也非常明显了,每种数据库的实现不同,如果数据库需要迁移的话比较麻烦;最大的问题是性能问题,并发量到一定级别的时候这个方法估计会很难满足性能需求;另外通过数据库自增生成的 ID 携带的信息太少,只能起到一个标识的作用,同时自增 ID 也是连续的。
{"_id": ObjectId("5d47ca7528021724ac19f745")}
3.2 之前的版本(包括 3.2):4 字节时间戳 + 3 字节机器标识符 + 2 字节进程 ID + 3字节随机计数器
3.2 之后版本:4 字节时间戳 + 5 字节随机值 + 3 字节递增计数器
优点:性能高于数据库;可以使用集群部署;ID 内自带一些含义,比如时间戳;
缺点:和数据库一样,需要引入对应的组件/软件,增加了系统的复杂度;最关键的是,这两种方案都意味着生成全局唯一 ID 的系统(服务),会成为一个单点,在软件架构中,单独就意味着风险;如果这个服务出现问题,那么所有依赖于这个服务的系统都会崩溃掉。
Version 2:DCE 安全的 UUID,把 Version 1 中的时间戳前 4 位置换为 POSIX 的 UID 或 GID ;高度唯一。
Version 3:基于名字的 UUID(MD5),通过计算名字和名字空间的 MD5 散列值得到;一定范围内唯一。
Version 4: 随机 UUID,根据随机数或伪随机数生成 UUID;有一定概率重复。
Version 5:基于名字的UUID(SHA1),和 Version 3 类似,只是散列值计算使用SHA1算法;一定范围内唯一。
public class CreateUUID {
public static void main(String[] args) {
String uuid = UUID.randomUUID().toString();
uuid = UUID.randomUUID().toString().replaceAll("-","");
System.out.println("uuid : " + uuid);
}
}
优点:本地生成,没有网络消耗,不需要第三方组件(也就没有单点的风险),生成比较简单,性能好。
缺点:长度长,不利于存储,并且没有排序,相对来说还会影响性能(比如 MySQL 的 InnoDB 引擎,如果 UUID 作为数据库主键,其无序性会导致数据位置频繁变动)。
1 bit :不使用,固定是 0;
41 bit :时间戳(毫秒),数值范围是:0 至 2的41次方 - 1;转换成年的话,大约是 69 年;
10 bit :机器 ID ;5 位机房 ID + 5 位机器 ID;(服务集群数量比较小的时候,可以手动配置,服务规模大的话,可以采用第三方组件进行自动配置,比如美团的 Leaf-snowflake,就是通过 ZooKeeper 的持久顺序节点做为机器 ID)
12 bit : 序列号,用来记录同一个毫秒内生成的不同 ID。
优点:本地生成,没有网络消耗,不需要第三方组件(也就没有单点的风险),一定范围内唯一(基本可以满足大部分场景),性能好,按时间戳递增(趋势递增);
缺点:依赖于机器时钟,同一台机器如果把时间回拨,生成的 ID 就会有重复的风险。
@Resource
private UidGenerator uidGenerator;
@Test
public void testSerialGenerate() {
// Generate UID
long uid = uidGenerator.getUID(); System.out.println(uidGenerator.parseUID(uid));
}
以上是关于听说:分布式ID不能全局递增?的主要内容,如果未能解决你的问题,请参考以下文章