Flink 1.13 StateBackend 与 CheckpointStorage 拆分
Posted 大数据生态
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink 1.13 StateBackend 与 CheckpointStorage 拆分相关的知识,希望对你有一定的参考价值。

Apache Flink 的持久化对许多用户来说都是一个谜。用户最常见反复提问的问题就是不理解 State、StateBackend 以及快照之间的关系。通过学习可以解答我们的一些困惑,但是这个问题如此常见,我们认为 Flink 的用户 API 应该设计的更友好一些。在过去几年中,我们经常会听到如下误解:
我们使用 RocksDB 是因为我们不需要容错。
我们不使用 RocksDB 是因为我们不想管理外部数据库。
RocksDB 可以直接读写 S3 或者 HDFS(相对于本地磁盘)
FsStateBackend 会溢写到磁盘,并且与本地文件系统有关系
将 RocksDB 指向网络附加存储,认为 StateBackend 需要容错
邮件列表中的很多问题非常能代表用户在哪里遇到问题,关键是其中许多问题都不是来自新用户!当前的 StateBackend 抽象对于我们许多用户来说太复杂了。所有这些问题的共同点就是误解了数据如何在 TM 上本地存储状态与 Checkpoint 如何持久化状态之间的关系。本文的目的就是介绍 StateBackend 与 Checkpoint 持久化剥离的原因、怎么剥离以及用户怎么迁移。
2. 现状在 Flink 1.13 版本之前,StateBackend 有两个功能:
提供状态的访问、查询;
如果开启了 Checkpoint,会周期性的向远程持久化存储上传数据和返回元数据给 JobManager。
以上两个功能是混在一起的,即把状态存储(如何在 TM 上本地存储和访问状态)和 Checkpoint 持久化(Checkpoint 如何持久化状态)笼统的混在一起,导致初学者对此感觉很混乱,很难理解,如下图所示。
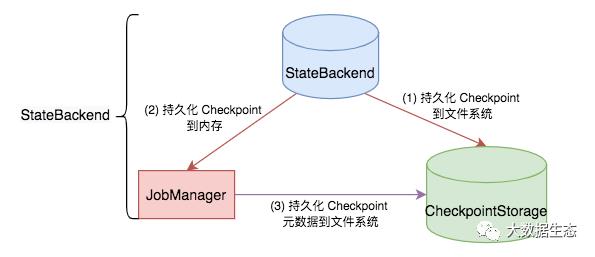
Flink 提供了三个开箱即用的 StateBackend:MemoryStateBackend、FsStateBackend 以及 RocksDBStateBackend,如下图所示。MemoryStateBackend 和 FsStateBackend 根据写出的 Checkpoint 位置来命名的(MemoryStateBackend 把 Checkpoint 数据存储到 JobManager 内存上,FsStateBackend 存储到文件系统上),但是它们都使用相同的内存数据结构在本地存储状态(状态数据都存储在内存上)。RocksDBStateBackend 是基于在本地存储状态数据的位置来命名的(状态数据存储在 RocksDB 上),同时它还快照到持久化文件系统中(Checkpoint 数据持久化到文件系统中)。
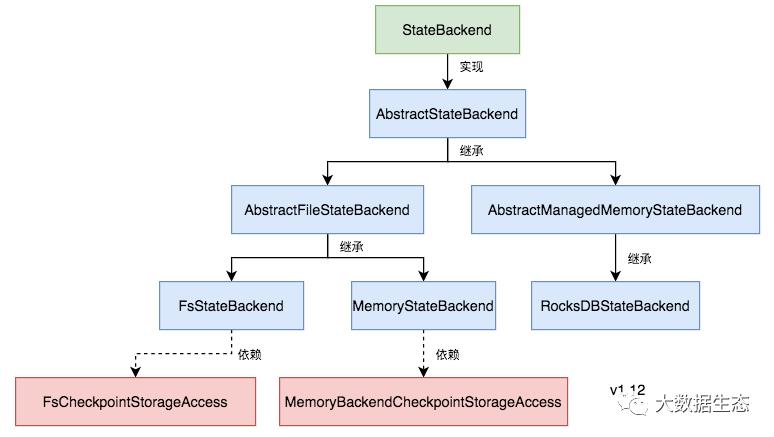
光从命名上来看,StateBackend 就已经比较混乱了,有的是基于写出的 Checkpoint 位置来命名,有的却是基于在本地存储状态数据的位置来命名。从 StateBackend 名称上,我们无法直接判断它的实际作用。
上面从命名的角度看 StateBackend 会让我们产生困惑,现在我们从 StateBackend 实现的角度来看待这个问题:StateBackend 接口因融合过多的功能而过载。目前包含四个方法:
|
旧版本的 FsStateBackend 等价于使用 HashMapStateBackend 和 FileSystemCheckpointStorage。
(1) flink-conf.yaml 配置:
HashMapStateBackend()); |
参考:
https://cwiki.apache.org/confluence/display/FLINK/FLIP-142%3A+Disentangle+StateBackends+from+Checkpointing
Flink 1.13,State Backend 优化及生产实践分享
Flink JDBC Connector:Flink 与数据库集成最佳实践
摘要:Flink 1.11 引入了 CDC,在此基础上, JDBC Connector 也发生比较大的变化,本文由 Apache Flink Contributor,阿里巴巴高级开发工程师徐榜江(雪尽)分享,主要介绍 Flink 1.11 JDBC Connector 的最佳实践。大纲如下:
JDBC connector
JDBC Catalog
JDBC Dialect
Demo
Tips:点击下方链接可查看作者原版 PPT 及分享视频:
https://flink-learning.org.cn/developers/flink-training-course3/
JDBC-Connector 的重构
JDBC-Connector 的重构
FLINK-15782 :Rework JDBC Sinks[1] (重写 JDBC Sink)
FLINK-17537:Refactor flink-jdbc connector structure[2] (重构 flink-jdbc 连接器的结构)
FLIP-95: New TableSource and TableSink interfaces[3] (新的 TableSource 和 TableSink 接口)
FLIP-122:New Connector Property Keys for New Factory[4](新的连接器参数)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
FLIP-87:Primary key Constraints in Table API[5] (Table API 接口中的主键约束问题)
JDBC Catalog
JDBC Catalog
// The supported methods by Postgres Catalog.PostgresCatalog.databaseExists(String databaseName)PostgresCatalog.listDatabases()PostgresCatalog.getDatabase(String databaseName)PostgresCatalog.listTables(String databaseName)PostgresCatalog.getTable(ObjectPath tablePath)PostgresCatalog.tableExists(ObjectPath tablePath)
JDBC Dialect
JDBC Dialect
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
https://ci.apache.org/projects/flink/flink-docs-release-1.11/zh/dev/table/connectors/jdbc.html#data-type-mapping
|
|
|
|
|
|
|
|
|
实践 Demo
实践 Demo
-
Flink standalone 环境准备并在提供的地址下载好对应的安装包和 connector jar。 -
测试数据准备,通过拉起容器运行已经打包好的镜像。其中 Kafka 中的 changelog 数据是通过 debezium connector 抓取的 MySQL orders表 的 binlog。 -
通过 SQL Client 编写 SQL 作业,分别创建 Flink 订单表,维表,用户表,产品表,并创建 Function UDF。从 PG Catalog 获取结果表信息之后,把作业提交至集群执行运行。 -
测试 CDC 数据同步和维表 join,通过新增订单、修改订单、删除订单、维表数据更新等一系列操作验证 CDC 在 Flink 上如何运行以及写入结果表。
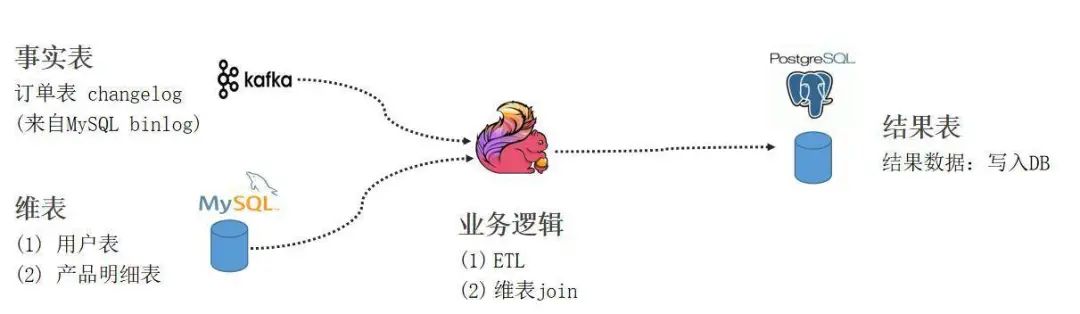
https://github.com/leonardBang/flink-sql-etl
问答环节
问答环节
https://issues.apache.org/jira/browse/FLINK-16681
总结
总结
参考链接:
 Flink Forward Asia 2020 议题征集中
Flink Forward Asia 2020 议题征集中
(点击可了解更多议题投递详情)
以上是关于Flink 1.13 StateBackend 与 CheckpointStorage 拆分的主要内容,如果未能解决你的问题,请参考以下文章