SpringBoot 如何统计监控 SQL运行情况?
Posted Java项目开发
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SpringBoot 如何统计监控 SQL运行情况?相关的知识,希望对你有一定的参考价值。
如同以前 c3p0、dbcp 数据源可以设置数据源连接初始化大小、最大连接数、等待时间、最小连接数 等一样,Druid 数据源同理可以进行设置;
配置 Druid web 监控 filter(WebStatFilter): 这个过滤器的作用就是统计 web 应用请求中所有的数据库信息,比如 发出的 sql 语句,sql 执行的时间、请求次数、请求的 url 地址、以及seesion 监控、数据库表的访问次数 等等。
配置 Druid 后台管理 Servlet(StatViewServlet): Druid 数据源具有监控的功能,并提供了一个 web 界面方便用户查看,类似安装 路由器 时,人家也提供了一个默认的 web 页面;需要设置 Druid 的后台管理页面的属性,比如 登录账号、密码 等;
注意:
Druid Spring Boot Starter 配置属性的名称完全遵照 Druid,可以通过 Spring Boot 配置文件来配置Druid数据库连接池和监控,如果没有配置则使用默认值。
application.yml
和 org.springframework.boot.autoconfigure.jdbc.DataSourceProperties中找到;默认禁用 StatFilter,可以将其 enabled 设置为 true 来启用它。进行获取;DruidStatManagerFacade#getDataSourceStatDataList 该方法可以获取所有数据源的监控数据,
除此之外 DruidStatManagerFacade 还提供了一些其他方法,可以按需选择使用。
@RestController
@RequestMapping(value = "/druid")
public class DruidStatController
@GetMapping("/stat")
public Object druidStat()
// 获取数据源的监控数据
return DruidStatManagerFacade.getInstance().getDataSourceStatDataList();

怎么接私活?这个渠道你100%有用!请收藏! 
喜欢文章,点个在看 
Spring Boot 如何统计监控 SQL 运行情况?写得太好了。。。
来源:juejin.cn/post/7062506923194581029
1 基本概念
Druid 是Java语言中最好的数据库连接池。
虽然 HikariCP 的速度稍快,但是,Druid能够提供强大的监控和扩展功能,也是阿里巴巴的开源项目。
Druid是阿里巴巴开发的号称为监控而生的数据库连接池,在功能、性能、扩展性方面,都超过其他数据库连接池,包括DBCP、C3P0、BoneCP、Proxool、JBoss DataSource等等等,秒杀一切。
Druid 可以很好的监控 DB 池连接和 SQL 的执行情况,天生就是针对监控而生的 DB 连接池。
Spring Boot 默认数据源 HikariDataSource 与 JdbcTemplate中已经介绍 Spring Boot 2.x 默认使用 Hikari 数据源,可以说 Hikari 与 Driud 都是当前 Java Web 上最优秀的数据源。
而Druid已经在阿里巴巴部署了超过600个应用,经过好几年生产环境大规模部署的严苛考验!
stat:Druid内置提供一个StatFilter,用于统计监控信息。wall:Druid防御SQL注入攻击的WallFilter就是通过Druid的SQL Parser分析。Druid提供的SQL Parser可以在JDBC层拦截SQL做相应处理,比如说分库分表、审计等。log4j2:这个就是 日志记录的功能,可以把sql语句打印到log4j2 供排查问题。
2 添加依赖
pom.xml
<!-- 阿里巴巴的druid数据源 -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.23</version>
</dependency>
<!-- mysql8 驱动-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
<!--使用 log4j2 记录日志-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-log4j2</artifactId>
</dependency>
<!--
mybatis,引入了 SpringBoot的 JDBC 模块,
所以,默认是使用 hikari 作为数据源
-->
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>2.1.3</version>
<exclusions>
<!-- 排除默认的 HikariCP 数据源 -->
<exclusion>
<groupId>com.zaxxer</groupId>
<artifactId>HikariCP</artifactId>
</exclusion>
</exclusions>
</dependency>
3 配置相关属性
配置Druid数据源(连接池): 如同以前 c3p0、dbcp 数据源可以设置数据源连接初始化大小、最大连接数、等待时间、最小连接数 等一样,Druid 数据源同理可以进行设置;
配置 Druid web 监控 filter(WebStatFilter): 这个过滤器的作用就是统计 web 应用请求中所有的数据库信息,比如 发出的 sql 语句,sql 执行的时间、请求次数、请求的 url 地址、以及seesion 监控、数据库表的访问次数 等等。
配置 Druid 后台管理 Servlet(StatViewServlet): Druid 数据源具有监控的功能,并提供了一个 web 界面方便用户查看,类似安装 路由器 时,人家也提供了一个默认的 web 页面;需要设置 Druid 的后台管理页面的属性,比如 登录账号、密码 等;
注意:
Druid Spring Boot Starter 配置属性的名称完全遵照 Druid,可以通过 Spring Boot 配置文件来配置Druid数据库连接池和监控,如果没有配置则使用默认值。
application.yml
########## 配置数据源 (Druid)##########
spring:
datasource:
########## JDBC 基本配置 ##########
username: xxx
password: xxx
driver-class-name: com.mysql.cj.jdbc.Driver # mysql8 的连接驱动
url: jdbc:mysql://127.0.0.1:3306/test?serverTimezone=Asia/Shanghai
platform: mysql # 数据库类型
type: com.alibaba.druid.pool.DruidDataSource # 指定数据源类型
########## 连接池 配置 ##########
druid:
# 配置初始化大小、最小、最大
initial-size: 5
minIdle: 10
max-active: 20
# 配置获取连接等待超时的时间(单位:毫秒)
max-wait: 60000
# 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒
time-between-eviction-runs-millis: 2000
# 配置一个连接在池中最小生存的时间,单位是毫秒
min-evictable-idle-time-millis: 600000
max-evictable-idle-time-millis: 900000
# 用来测试连接是否可用的SQL语句,默认值每种数据库都不相同,这是mysql
validationQuery: select 1
# 应用向连接池申请连接,并且testOnBorrow为false时,连接池将会判断连接是否处于空闲状态,如果是,则验证这条连接是否可用
testWhileIdle: true
# 如果为true,默认是false,应用向连接池申请连接时,连接池会判断这条连接是否是可用的
testOnBorrow: false
# 如果为true(默认false),当应用使用完连接,连接池回收连接的时候会判断该连接是否还可用
testOnReturn: false
# 是否缓存preparedStatement,也就是PSCache。PSCache对支持游标的数据库性能提升巨大,比如说oracle
poolPreparedStatements: true
# 要启用PSCache,必须配置大于0,当大于0时, poolPreparedStatements自动触发修改为true,
# 在Druid中,不会存在Oracle下PSCache占用内存过多的问题,
# 可以把这个数值配置大一些,比如说100
maxOpenPreparedStatements: 20
# 连接池中的minIdle数量以内的连接,空闲时间超过minEvictableIdleTimeMillis,则会执行keepAlive操作
keepAlive: true
# Spring 监控,利用aop 对指定接口的执行时间,jdbc数进行记录
aop-patterns: "com.springboot.template.dao.*"
########### 启用内置过滤器(第一个 stat必须,否则监控不到SQL)##########
filters: stat,wall,log4j2
# 自己配置监控统计拦截的filter
filter:
# 开启druiddatasource的状态监控
stat:
enabled: true
db-type: mysql
# 开启慢sql监控,超过2s 就认为是慢sql,记录到日志中
log-slow-sql: true
slow-sql-millis: 2000
# 日志监控,使用slf4j 进行日志输出
slf4j:
enabled: true
statement-log-error-enabled: true
statement-create-after-log-enabled: false
statement-close-after-log-enabled: false
result-set-open-after-log-enabled: false
result-set-close-after-log-enabled: false
########## 配置WebStatFilter,用于采集web关联监控的数据 ##########
web-stat-filter:
enabled: true # 启动 StatFilter
url-pattern: /* # 过滤所有url
exclusions: "*.js,*.gif,*.jpg,*.png,*.css,*.ico,/druid/*" # 排除一些不必要的url
session-stat-enable: true # 开启session统计功能
session-stat-max-count: 1000 # session的最大个数,默认100
########## 配置StatViewServlet(监控页面),用于展示Druid的统计信息 ##########
stat-view-servlet:
enabled: true # 启用StatViewServlet
url-pattern: /druid/* # 访问内置监控页面的路径,内置监控页面的首页是/druid/index.html
reset-enable: false # 不允许清空统计数据,重新计算
login-username: root # 配置监控页面访问密码
login-password: 123
allow: 127.0.0.1 # 允许访问的地址,如果allow没有配置或者为空,则允许所有访问
deny: # 拒绝访问的地址,deny优先于allow,如果在deny列表中,就算在allow列表中,也会被拒绝
上述配置文件的参数可以在 com.alibaba.druid.spring.boot.autoconfigure.properties.DruidStatProperties 和 org.springframework.boot.autoconfigure.jdbc.DataSourceProperties中找到;
3.1 如何配置 Filter
可以通过 spring.datasource.druid.filters=stat,wall,log4j ...的方式来启用相应的内置Filter,不过这些Filter都是默认配置。如果默认配置不能满足需求,可以放弃这种方式,通过配置文件来配置Filter,下面是例子。
# 配置StatFilter
spring.datasource.druid.filter.stat.enabled=true
spring.datasource.druid.filter.stat.db-type=h2
spring.datasource.druid.filter.stat.log-slow-sql=true
spring.datasource.druid.filter.stat.slow-sql-millis=2000
# 配置WallFilter
spring.datasource.druid.filter.wall.enabled=true
spring.datasource.druid.filter.wall.db-type=h2
spring.datasource.druid.filter.wall.config.delete-allow=false
spring.datasource.druid.filter.wall.config.drop-table-allow=false
目前为以下 Filter 提供了配置支持,根据(spring.datasource.druid.filter.*)进行配置。
- StatFilter
- WallFilter
- ConfigFilter
- EncodingConvertFilter
- Slf4jLogFilter
- Log4jFilter
- Log4j2Filter
- CommonsLogFilter
不想使用内置的 Filters,要想使自定义 Filter 配置生效需要将对应 Filter 的 enabled 设置为 true ,Druid Spring Boot Starter 默认禁用 StatFilter,可以将其 enabled 设置为 true 来启用它。
4 监控页面
(1)启动项目后,访问/druid/login.html来到登录页面,输入用户名密码登录

(2)数据源页面 是当前DataSource配置的基本信息,上述配置的Filter可以在里面找到,如果没有配置Filter(一些信息会无法统计,例如“SQL监控”,会无法获取JDBC相关的SQL执行信息)
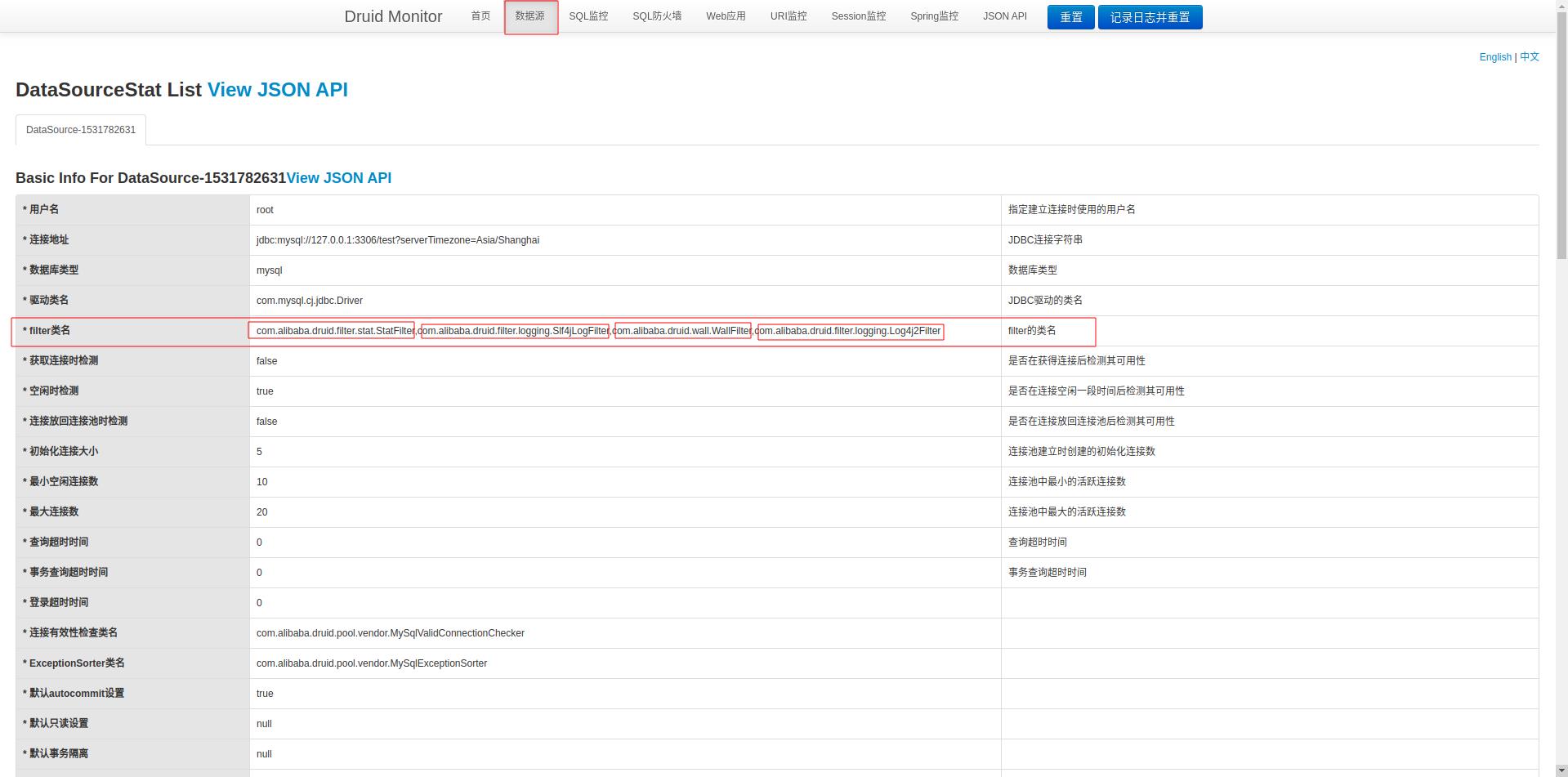
(3) SQL监控页面,统计了所有SQL语句的执行情况

(4)URL监控页面,统计了所有Controller接口的访问以及执行情况

(5)Spring 监控页面,利用aop 对指定接口的执行时间,jdbc数进行记录

(6)SQL防火墙页面
druid提供了黑白名单的访问,可以清楚的看到sql防护情况。
(7)Session监控页面
可以看到当前的session状况,创建时间、最后活跃时间、请求次数、请求时间等详细参数。
(8)JSONAPI 页面
通过api的形式访问Druid的监控接口,api接口返回Json形式数据。
5 sql监控
配置 Druid web 监控 filter(WebStatFilter)这个过滤器,作用就是统计 web 应用请求中所有的数据库信息,比如 发出的 sql 语句,sql 执行的时间、请求次数、请求的 url 地址、以及seesion 监控、数据库表的访问次数 等等。
spring:
datasource:
druid:
########## 配置WebStatFilter,用于采集web关联监控的数据 ##########
web-stat-filter:
enabled: true # 启动 StatFilter
url-pattern: /* # 过滤所有url
exclusions: "*.js,*.gif,*.jpg,*.png,*.css,*.ico,/druid/*" # 排除一些不必要的url
session-stat-enable: true # 开启session统计功能
session-stat-max-count: 1000 # session的最大个数,默认100
6 慢sql记录
有时候,系统中有些SQL执行很慢,我们希望使用日志记录下来,可以开启Druid的慢SQL记录功能
spring:
datasource:
druid:
filter:
stat:
enabled: true # 开启DruidDataSource状态监控
db-type: mysql # 数据库的类型
log-slow-sql: true # 开启慢SQL记录功能
slow-sql-millis: 2000 # 默认3000毫秒,这里超过2s,就是慢,记录到日志
启动后,如果遇到执行慢的SQL,便会输出到日志中
7 spring 监控
访问之后spring监控默认是没有数据的;
这需要导入SprngBoot的AOP的Starter
<!--SpringBoot 的aop 模块-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-aop</artifactId>
</dependency>
需要在 application.yml 配置:
Spring监控AOP切入点,如com.springboot.template.dao.*,配置多个英文逗号分隔
spring.datasource.druid.aop-patterns="com.springboot.template.dao.*"
8 去 Ad(广告)
访问监控页面的时候,你可能会在页面底部(footer)看到阿里巴巴的广告
原因:引入的druid的jar包中的common.js(里面有一段js代码是给页面的footer追加广告的)
如果想去掉,有两种方式:
(1) 直接手动注释这段代码
如果是使用Maven,直接到本地仓库中,查找这个jar包
要注释的代码:
// this.buildFooter();
common.js的位置:
com/alibaba/druid/1.1.23/druid-1.1.23.jar!/support/http/resources/js/common.js
(2) 使用过滤器过滤
注册一个过滤器,过滤common.js的请求,使用正则表达式替换相关的广告内容
@Configuration
@ConditionalOnWebApplication
@AutoConfigureAfter(DruidDataSourceAutoConfigure.class)
@ConditionalOnProperty(name = "spring.datasource.druid.stat-view-servlet.enabled",
havingValue = "true", matchIfMissing = true)
public class RemoveDruidAdConfig
/**
* 方法名: removeDruidAdFilterRegistrationBean
* 方法描述 除去页面底部的广告
* @param properties com.alibaba.druid.spring.boot.autoconfigure.properties.DruidStatProperties
* @return org.springframework.boot.web.servlet.FilterRegistrationBean
*/
@Bean
public FilterRegistrationBean removeDruidAdFilterRegistrationBean(DruidStatProperties properties)
// 获取web监控页面的参数
DruidStatProperties.StatViewServlet config = properties.getStatViewServlet();
// 提取common.js的配置路径
String pattern = config.getUrlPattern() != null ? config.getUrlPattern() : "/druid/*";
String commonJsPattern = pattern.replaceAll("\\\\*", "js/common.js");
final String filePath = "support/http/resources/js/common.js";
//创建filter进行过滤
Filter filter = new Filter()
@Override
public void init(FilterConfig filterConfig) throws ServletException
@Override
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain) throws IOException, ServletException
chain.doFilter(request, response);
// 重置缓冲区,响应头不会被重置
response.resetBuffer();
// 获取common.js
String text = Utils.readFromResource(filePath);
// 正则替换banner, 除去底部的广告信息
text = text.replaceAll("<a.*?banner\\"></a><br/>", "");
text = text.replaceAll("powered.*?shrek.wang</a>", "");
response.getWriter().write(text);
@Override
public void destroy()
;
FilterRegistrationBean registrationBean = new FilterRegistrationBean();
registrationBean.setFilter(filter);
registrationBean.addUrlPatterns(commonJsPattern);
return registrationBean;
两种方式都可以,建议使用的是第一种,从根源解决
9 获取 Druid 的监控数据
Druid 的监控数据可以在 开启 StatFilter 后,通过 DruidStatManagerFacade 进行获取;
DruidStatManagerFacade#getDataSourceStatDataList 该方法可以获取所有数据源的监控数据,
除此之外 DruidStatManagerFacade 还提供了一些其他方法,可以按需选择使用。
@RestController
@RequestMapping(value = "/druid")
public class DruidStatController
@GetMapping("/stat")
public Object druidStat()
// 获取数据源的监控数据
return DruidStatManagerFacade.getInstance().getDataSourceStatDataList();
近期热文推荐:
1.1,000+ 道 Java面试题及答案整理(2022最新版)
4.别再写满屏的爆爆爆炸类了,试试装饰器模式,这才是优雅的方式!!
觉得不错,别忘了随手点赞+转发哦!
以上是关于SpringBoot 如何统计监控 SQL运行情况?的主要内容,如果未能解决你的问题,请参考以下文章
Spring Boot 如何统计监控 SQL 运行情况?写得太好了。。。
Spring Boot 如何统计监控 SQL 运行情况?写得太好了。。。
Spring Boot 如何统计监控 SQL 运行情况?写得太好了。。。
SpringBoot 监控统计:SQL监控慢SQL记录Spring监控去广告