Elasticsearch 断路器报错了,怎么办?
Posted 铭毅天下Elasticsearch
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Elasticsearch 断路器报错了,怎么办?相关的知识,希望对你有一定的参考价值。
的情况下,采取措施减少内存压力。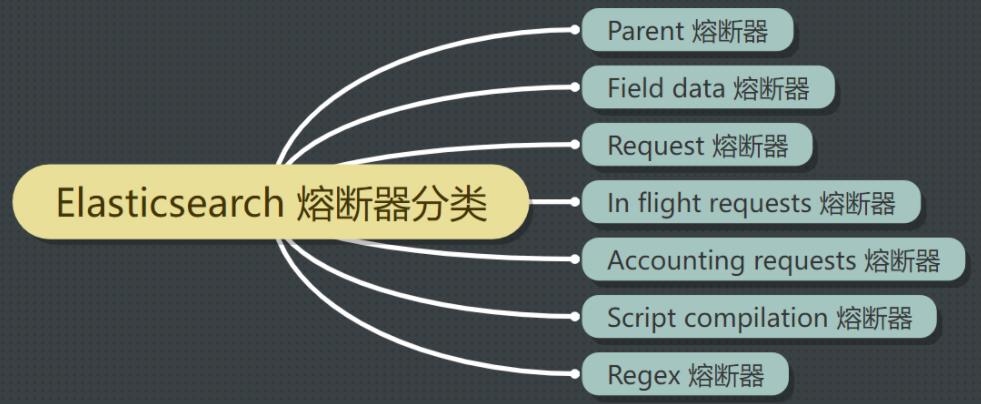
左右。Gif 动图如下:
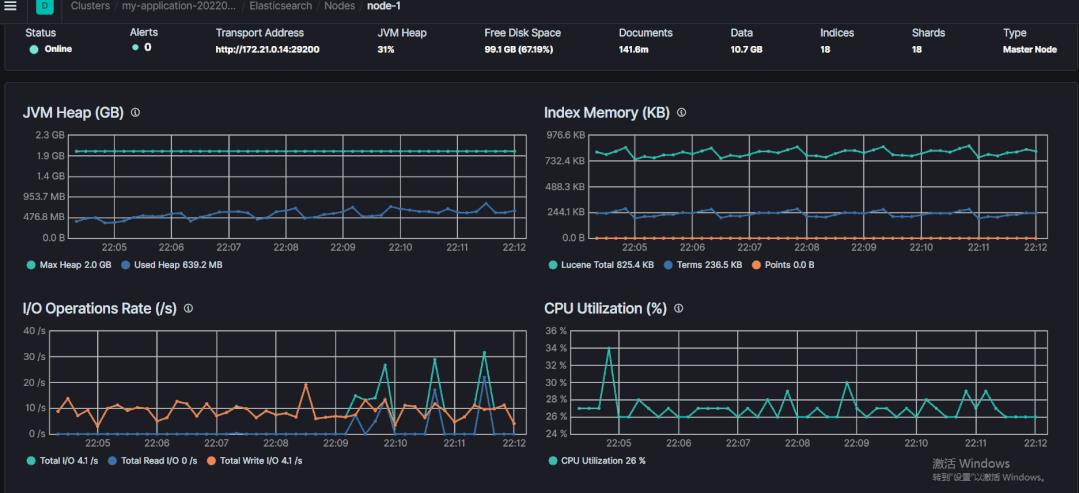
API 来获得每个节点的当前堆内存使用率 的内存压力。并触发了 断路器,请考虑禁用它并使用关键字字段 keyword 代替。断路器并且不能禁用 缓存。清理缓存的命令如下:
POST _cache/clear?fielddata=true
更多缓存相关的操作,推荐阅读:
Elasticsearch 缓存深入详解
6、小结提前知道哪些常见问题容易导致熔断器报错,能有效的指导实战工作、避免实战环境出现类似错误。
你的实战环境有没有遇到类似错误,如何解决的呢?欢迎留言交流。
参考https://www.elastic.co/guide/en/elasticsearch/reference/current/fix-common-cluster-issues.html
https://www.elastic.co/guide/en/elasticsearch/reference/current/circuit-breaker.html
推荐
更短时间更快习得更多干货!
已带领88位球友通过 Elastic 官方认证!

Elasticsearch使用真实内存断路器提高节点弹性

1.概述
转载:https://www.elastic.co/cn/blog/improving-node-resiliency-with-the-real-memory-circuit-breaker
您肯定想确保这一点:即使网站面临巨大负载,Elasticsearch 也能可靠地处理您的搜索流量。由于 Elasticsearch 是一个分布式系统,所以其在最初开始设计时便将弹性考虑在内,以应对个别节点发生故障的情况。事实上,我们在 Elasticsearch 7.0.0 中已经实施了全新且经过巨大改进的集群协调算法。
我们在构建 Elasticsearch 中的单独节点时也已将弹性考虑在内。如果您向某个节点发送过多请求,或者如果您的请求过大,节点可能会将您的请求推回。这一操作是借助断路器实现的。断路器位于请求处理路径中的特定节点,例如当网络请求进入节点时,或者在执行聚合之前。主要目的是避免OutOfMemoryError(内存不足)问题,具体做法是通过提前预估某个请求是否会致使节点超出已配置的上限,如果超出的话,便拒绝请求,从而避免发生故障。除了针对单独方面的断路器(例如所有的传输中 (in-flight) 请求断路器或者字段数据断路器)之外,Elasticsearch 还有一个会整体查看所有断路器的“父级断路器”。如果某个请求虽然在单独断路器的限度之内,但却会致使系统超过全部断路器的整体上限,此时 Elasticsearch 便可通过“父级断路器”拒绝此请求。
要跟踪每一次分配情况是不切实际的,所以断路器只能跟踪已经明确预留的内存,有时并不能提前预估出准确的内存使用量。这意味着断路器只是一套“尽力而为”机制,尽管其在预防节点超载方面具有一定弹性,节点仍然有可能会遇到 OutOfMemoryError 问题。堆内存越小,这一机制造成的问题就越严重,这是因为未跟踪内存的相对开销就越大。
构建一个更好的断路器(并进行测试)
如果在断路器中预留内存的时候便能知道节点所使用的准确内存量,结果会怎样呢?如果这样的话,我们便可根据当时的系统实际状态(而非根据所有断路器的当前预留内存得出的预估值)拒绝请求。我们在 Elasticsearch 7.0. 中新推出的真实内存断路器便恰恰做到了这一点。这是父级断路器的一种备选实施方案,它会使用 JVM 中的一项功能来衡量当前内存使用量,而非仅计算当前跟踪的内存。尽管这一操作与将几个数字简单相加比起来耗时要长一些,但衡量内存使用量仍然是一种非常节省时间的操作:在微型基准测试中,我们观察到开销介于 400 到 900 纳秒之间。 我们在不同条件下开展了大量实验以测试真实内存断路器的效果。在其中一种情形下,我们针对仅配置有 256MB 堆内存的节点运行了一次全文本索引基准测试。尽管 Elasticsearch 的早期版本不能承担这一工作负载并几乎立即出现内存不足情况,但真实内存断路器却将请求推回而且 Elasticsearch 可承担这一负载。请注意,Elasticsearch 在这种情况下会返回一个错误响应,至于是否实施相应的退避和重试机制,具体取决于客户端。当然,我们是假设您已在使用我们的某个官方语言客户端,所以才这样简要叙述的。.NET、Ruby、Python 和 Java 客户端都已经实施了这些重试策略,并且还提供扩展程序以处理批量索引。
在另一个实验中,我们执行了一个聚合操作,在一个 16 GB 堆内存的节点上故意产生大量的桶,数量高得离谱。和之前类似,Elasticsearch 的早期版本遇到了内存不足的问题,但是这一聚合操作运行了将近半小时之后才出现错误消息。相反,使用真实内存断路器之后,节点提供了一个响应,且所用时间仅为一分钟多一点或者大约二十分钟,具体取决于我们是否允许部分结果。基于多次实验的结果,我们将新断路器的默认值设置为总可用堆内存的 95%。这意味,Elasticsearch 最多允许使用 95% 的堆内存,只有达到该限值后真实内存断路器才会跳闸。
我们看一下这个示例:客户端发送了一个批量请求,这个请求的规模很小,可以通过所有其他检查,但是由于其会导致节点超过上限,所以真实内存断路器仍会跳闸。此节点配置的堆内存为 128MB,这意味着父级断路器的 95% 上限为 117.5MB。如果发送这个请求的话,节点将会回应 HTTP 429,并提供下列详细信息:
{
'error': {
'type': 'circuit_breaking_exception',
'reason': '[parent] Data too large, data for [<http_request>] would be [123848638/118.1mb], which is larger than the limit of [123273216/117.5mb], real usage: [120182112/114.6mb], new bytes reserved: [3666526/3.4mb]',
'bytes_wanted':123848638,
'bytes_limit':123273216,
'durability':'TRANSIENT'
},
'status':429
}
我们可以看到断路器同时显示这是一个瞬时故障,并且客户端可以基于这一线索稍后重新尝试这一请求。至于故障是永久问题还是瞬时问题,这取决于所有断路器的预留内存。每个断路器类型都有一个相关的时限;如果大部分预留内存是由跟踪瞬时内存使用量的断路器所预留的,则真实内存断路器会将此视为瞬时故障,否则会视为永久故障。
总结
尽管在某些情形下 Elasticsearch 节点仍有可能会遇到内存不足问题,但 Elasticsearch 中的真实内存断路器可以基于实际测得的内存使用量(而非仅计算由断路器跟踪的内存)进行背压,从而大幅提升单独节点的弹性。在我们的实验中,Elasticsearch 能够承担的工作负载远远超过之前的版本,所以此版本能够大幅提升工作负载高峰期间您的生产集群的弹性。如想试用新的真实内存断路器,欢迎下载最新的 7.0 公测版, take it for a spin, and give us some feedback。
本文顶部的图片是由 Kiran Raja Bahadur SRK 基于 CC BY-NC-ND 2.0 许可提供的(原始来源)。
以上是关于Elasticsearch 断路器报错了,怎么办?的主要内容,如果未能解决你的问题,请参考以下文章