数据库存储选型经验总结
Posted 淘系技术
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据库存储选型经验总结相关的知识,希望对你有一定的参考价值。

工作中总是遇到数据存储相关的Bug工单,新需求开发设计中也多多少少会有数据模型设计和存储相关的问题。经过几次存储方案设计选型和讨论后发现需要有更全面的思考框架。
日常开发中常用的存储方案选型很多都是“拿来主义”的,凭借着经验、习惯选用,但对它们的细节特性或约束少有研究。
除了手边会用的存储方案,也应该关注市面上更合适的存储方案。
一定的技术预研和储备能够帮助未来更好的技术方案设计。
故写了这篇文章,抛出我的总结和思考,希望日后可以将一些更先进 (合适) 的技术引入业务开发中,助力业务发展。
存储选型的目的还是为了我们的使用场景和用户服务,因此在选型前需要回答自己一些 业务指标 & 技术指标 方面的问题,以便于我们清楚存储选型的应用环境。
用户量:用户量预估多少?几百几万还是几亿?
数据量:数据量预估多少?日均增量能有多少?
读写偏好:数据是读多一些还是写多一些?
数据场景:强事务型还是分析型需求?
运行性能要求:并发量是多少?高峰、平均、低谷分别预估是多少?
数据库的分类方式非常多样,因参考维度不同而存在较大差异,下面是常见的一些分类。
| 数据库类型 | 常见数据库 |
|---|---|
关系型 | mysql、Oracle、DB2、SQLServer 等。 |
非关系型 | Hbase、Redis、MongodDB 等。 |
行式存储 | MySQL、Oracle、DB2、SQLServer 等。 |
列式存储 | Hbase、ClickHouse 等。 |
分布式存储 | Cassandra、Hbase、MongodDB 等。 |
键值存储 | Memcached、Redis、MemcacheDB 等。 |
图形存储 | Neo4J、TigerGraph 等。 |
文档存储 | MongoDB、CouchDB 等。 |
容易理解
可由二维表结构来逻辑表达,相对网状、层次等其他模型更加容易被理解。严格遵循数据格式与长度规范,数据以行为单位,一行数据表示一个实体信息,每一行数据的属性都是相同的。操作方便
通用的 SQL 语言使得操作关系型数据库非常方便,支持 join 等复杂查询,Sql + 二维关系是关系型数据库最无可比拟的优点,这种易用性非常贴近开发者。事务特性
支持 ACID 特性,可以维护数据之间的一致性,这是使用关系数据库非常重要的一个理由,例如同银行转账,张三转给李四 100 块钱,张三扣 100 元,李四加 100 元,而且必须同时成功或者同时失败,否则就会造成用户的资损。数据稳定
数据持久化到磁盘,没有丢失数据风险。服务稳定
最常用的关系型数据库产品 MySql、Oracle 服务器性能卓越,服务稳定,通常很少出现宕机异常。
高并发下数据库瓶颈明显
数据按行存储,即使只针对其中某一列进行运算,也会将整行数据从存储设备中读入内存,导致 IO 较高。写入 / 更新频繁的情况下,数据库往往会出现 CPU 飙高、Sql 执行慢、客户端报数据库连接池不够等异常情况,且性能瓶颈通过加 CPU、换固态硬盘、继续买服务器加数据库做分库等方式处理ROI不高,受限于其本身的特点,可能花了很多钱都未必能达到想要的效果。因此例如万人秒杀这种场景,我们绝对不可能通过数据库直接去扣减库存,需要做好流量漏斗。为维护索引付出的代价大
为了提供丰富的查询能力,通常热点表都会有多个二级索引,一旦有了二级索引,数据的新增必然伴随着所有二级索引的新增,数据的更新也必然伴随着所有二级索引的更新,这不可避免地降低了关系型数据库的读写能力,且索引越多读写能力越差。除了数据文件不可避免地占空间外,索引占的空间其实也并不少。为维护数据一致性付出的代价大
数据一致性是关系型数据库的核心,但是同样为了维护数据一致性的代价也是非常大的。我们都知道 SQL 标准为事务定义了不同的隔离级别,从低到高依次是读未提交、读已提交、可重复度、串行化,事务隔离级别越低,可能出现的并发异常越多,但是通常而言能提供的并发能力越强。那么为了保证事务一致性,数据库就需要提供并发控制与故障恢复两种技术,前者用于减少并发异常,后者可以在系统异常的时候保证事务与数据库状态不会被破坏。对于并发控制,其核心思想就是加锁,无论是乐观锁还是悲观锁,只要提供的隔离级别越高,那么读写性能必然越差。水平扩展后带来的种种问题难处理
随着业务规模扩大,一种方式是对数据库做分库,做了分库之后,数据迁移(1 个库的数据按照一定规则打到 2 个库中)、跨库 join、分布式事务处理都是需要考虑的问题,尤其是分布式事务处理,业界当前都没有特别好的解决方案。表结构扩展不方便
由于数据库存储的是结构化数据,因此表结构 schema 是固定的,扩展不方便,如果需要修改表结构,需要执行 DDL(data definition language)语句修改,修改期间会导致锁表,部分服务不可用。全文搜索功能弱
例如 like “% 中国真伟大 %”,只能搜索到“2019 年中国真伟大,爱祖国”,无法搜索到“中国真是太伟大了” 这样的文本,即不具备分词能力,且 like 查询在“% 中国真伟大” 这样的搜索条件下,无法命中索引,将会导致查询效率大大降低。
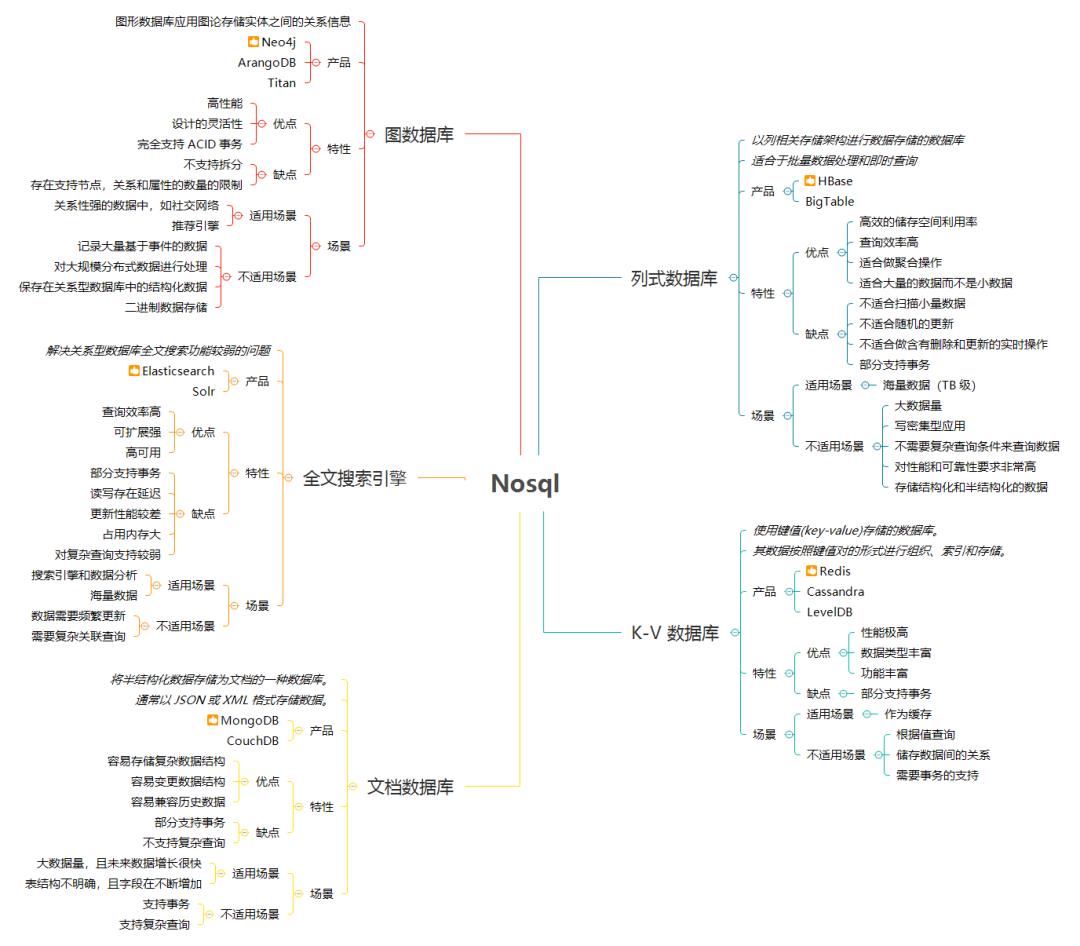
NoSql 的全称为 Not Only SQL,泛指非关系型数据库,是对关系型数据库的一种补充,特别注意补充这两个字,这意味着 NoSql 与关系型数据库并不是对立关系,二者各有优劣,取长补短,在合适的场景下选择合适的存储引擎才是正确的做法。下面看一下常用的 NoSql 及他们的代表产品,并对每种 NoSql 的优缺点和适用场景做一下分析,便于熟悉每种 NoSql 的特点,方便技术选型。
KV 型 NoSql 顾名思义就是以键值对形式存储的非关系型数据库,是最简单、最容易理解也是大家最熟悉的一种 NoSql。Redis、MemCache 是其中的代表,Redis 又是 KV 型 NoSql 中应用最广泛的 NoSql,KV 型数据库以 Redis 为例,最大的优点总结下来主要有两点:
数据基于内存,读写效率高
KV型数据,时间复杂度为O(1),查询速度快
因此,KV 型 NoSql 最大的优点就是高性能,利用 Redis 自带的 BenchMark 做基准测试,TPS 可达到 10 万的级别,性能非常强劲。同样的 Redis 也有所有 KV 型 NoSql 都有的比较明显的缺点:
只能根据K查V,无法根据V查K
查询方式单一,只有KV的方式,不支持条件查询,多条件查询唯一的做法就是数据冗余,但这会极大的浪费存储空间
内存是有限的,无法支持海量数据存储
由于KV型NoSql的存储是基于内存的,会有丢失数据的风险(有持久化存储方案)
综上所述,KV 型 NoSql 最合适的场景就是缓存的场景:读远多于写
读取能力强
没有持久化的需求,可以容忍数据丢失
针对那些读远多于写的数据,引入一层缓存,每次读从缓存中读取,缓存中读取不到,再去数据库中取,取完之后再写入到缓存,对数据做好失效机制通常就没有大问题了。通常来说,缓存是性能优化的第一选择也是见效最明显的方案。
▐ 搜索型 NoSql(代表 —-ElasticSearch)
传统关系型数据库主要通过索引来达到快速查询的目的,但是在全文搜索的场景下,索引是无能为力的,like 查询一来无法满足所有模糊匹配需求,二来使用限制太大且使用不当容易造成慢查询,搜索型 NoSql 的诞生正是为了解决关系型数据库全文搜索能力较弱的问题,ElasticSearch 是搜索型 NoSql 的代表产品。
全文搜索的原理是倒排索引,我们看一下什么是倒排索引。要说倒排索引我们先看下什么是正排索引,传统的正排索引是文档 –> 关键字的映射,例如”Tom is my friend” 这句话,会将其切分为”Tom”、”is”、”my”、”friend” 四个单词,在搜索的时候对文档进行扫描,符合条件的查出来。这种方式原理非常简单,但是由于其检索效率太低,基本没什么实用价值。
倒排索引则完全相反,它是关键字 –> 文档的映射,举例来说,现在这里有四个短句:
"Tom is Tom"
"Tom is my friend"
"Thank you, Betty"
"Tom is Betty\'s husband"
搜索引擎会根据一定的分词规则将一句话切成 N 个关键字,并以关键字的维度维护关键字在每个文本中的出现次数。这样下次搜索”Tom” 的时候,由于 Tom 这个词语在”Tom is Tom”、”Tom is my friend”、”Tom is Betty’s husband” 三句话中都有出现,因此这三条记录都会被检索出来,且由于”Tom is Tom” 这句话中”Tom” 出现了 2 次,因此这条记录对”Tom” 这个单词的匹配度最高,最先展示。这就是搜索引擎倒排索引的基本原理,假设某个关键字在某个文档中出现,那么倒排索引中有两部分内容:
文档ID
在该文档中出现的位置情况
可以举一反三,我们搜索”Betty Tom” 这两个词语也是一样,搜索引擎将”Betty Tom” 切分为”Tom”、”Betty” 两个单词,根据开发者指定的满足率,比如满足率 = 50%,那么只要记录中出现了两个单词之一的记录都会被检索出来,再按照匹配度进行展示。
搜索型 NoSql 以 ElasticSearch 为例,它的优点为:
支持分词场景、全文搜索,这是区别于关系型数据库最大特点
支持条件查询,支持聚合操作,类似关系型数据库的Group By,但是功能更加强大,适合做数据分析
数据写文件无丢失风险,在集群环境下可以方便横向扩展,可承载PB级别的数据
高可用,自动发现新的或者失败的节点,重组和重新平衡数据,确保数据是安全和可访问的
同样,ElasticSearch 也有比较明显的缺点:
性能全靠内存来顶,也是使用的时候最需要注意的点,非常吃硬件资源、吃内存,大数据量下64G + SSD基本是标配,相同的配置多一倍内存,一个月差不多就要多花好多钱。至于ElasticSearch内存主要用在以下几个地方:
a. Indexing Buffer----ElasticSearch基于Luence,Lucene的倒排索引是先在内存里生成,然后定期以Segment File的方式刷磁盘的,每个Segment File实际就是一个完整的倒排索引
b. Segment Memory----倒排索引前面说过是基于关键字的,Lucene在4.0后会将所有关键字以FST这种数据结构的方式将所有关键字在启动的时候全量加载到内存,加快查询速度,官方建议至少留系统一半内存给Lucene
c. 各类缓存----Filter Cache、Field Cache、Indexing Cache等,用于提升查询分析性能,例如Filter Cache用于缓存使用过的Filter的结果集
d. Cluter State Buffer----ElasticSearch被设计为每个Node都可以响应用户请求,因此每个Node的内存中都包含有一份集群状态的拷贝,一个规模很大的集群这个状态信息可能会非常大读写之间有延迟,写入的数据差不多1s样子会被读取到(数据写入时需要维护很多索引)
数据结构灵活性不高,字段一旦建立就没法修改类型了,假如建立的数据表某个字段没有加全文索引,想加上,那么只能把整个表删了再重建。
因此,搜索型 NoSql 最适用的场景就是有条件搜索尤其是全文搜索的场景,作为关系型数据库的一种替代方案,通常搜索型 NoSql 也会作为一层前置缓存,来对关系型数据库进行保护。
另外,搜索型数据库还有一种特别重要的应用场景。我们可以想,一旦对数据库做了分库分表后,原来可以在单表中做的聚合操作、统计操作是否统统失效?例如我把订单表分 16 个库,1024 张表,那么订单数据就散落在 1024 张表中,我想要统计昨天浙江省单笔成交金额最高的订单是哪笔如何做?我想要把昨天的所有订单按照时间排序分页展示如何做?这就是搜索型 NoSql 的另一大作用了,我们可以把分表之后的数据统一打在搜索型 NoSql 中,利用搜索型 NoSql 的搜索与聚合能力完成对全量数据的查询。
▐ 列式 NoSql(代表 —-HBase)
列式 NoSql 和关系型数据库一样都有主键的概念,区别在于关系型数据库是按照行组织的数据,数据字段即使没有值同样占空间,列式存储完全是另一种方式,它是按列进行数据组织的,好处在于:
查询时只有指定的列会被读取,不会读取所有列
存储上节约空间,空值不会被存储,一列中有时候会有很多重复数据(尤其是枚举数据,性别、状态等字段),这类数据可压缩
列数据被组织到一起,一次磁盘 IO 可以将一列数据一次性读取到内存中
大数据时代最具代表性的技术之一 HBase 就是列式 NoSQL 的产品实现,其优点主要是:
海量数据存储,PB 级别数据随便存,底层基于 HDFS(Hadoop 文件系统),数据持久化
读写性能好,只要没有滥用造成数据热点,读写基本没任何问题
横向扩展在关系型数据库及非关系型数据库中都是最方便的之一,只需要添加新机器就可以实现数据容量的线性增长,且可用在廉价服务器上,节省成本
可存储结构化或者半结构化的数据
本身没有单点故障,可用性高
列数理论上无限制,HBase 本身只对列族数量有要求,建议 1~3 个
缺点主要表现在:
HBase 是 Hadoop 生态的一部分,因此它本身是一款比较重的产品,依赖很多 Hadoop 组件,数据规模不大没必要用,运维还是有点复杂的。
不支持分页查询,因为统计不了数据总数。
KV 式存储,条件查询很弱,HBase 在 Scan 扫描一批数据的情况下还是提供了前缀匹配这种 API 的,条件查询除非定义多个 RowKey 做数据冗余。
因此 HBase 比较适用于 KV 型存储且未来无法预估数据增长量的场景,另外 HBase 使用还是需要一定的经验,主要体现在 RowKey 的设计上。
▐ 文档型 NoSql(代表 —-MongoDB)
文档型 NoSql 指的是将半结构化数据存储为文档的一种 NoSql,文档型 NoSql 通常以 JSON 或者 XML 格式存储数据,因此文档型 NoSql 是没有 Schema 的,由于没有 Schema 的特性,我们可以随意地存储与读取数据,因此文档型 NoSql 的出现是解决关系型数据库表结构扩展不方便的问题的。
MongoDB 是文档型 NoSql 的代表产品,同时也是所有 NoSql 产品中的明星产品之一,它的很多概念与关系数据库类似,因此,对于 MongDB,我们只需要理解成一个 Free-Schema 的关系型数据库就好了,其优点主要是:
没有预定义的字段,扩展字段容易
相较于关系型数据库,读写性能优越,命中二级索引的查询不会比关系型数据库慢,对于非索引字段的查询则是全面胜出
缺点在于:
不支持事务操作,虽然 Mongodb4.0 之后宣称支持事务,但是效果待观测
多表之间的关联查询不支持(虽然有嵌入文档的方式),join 查询还是需要多次操作
空间占用较大,这个是 MongDB 的设计问题,空间预分配机制 + 删除数据后空间不释放,只有用 db.repairDatabase () 去修复才能释放
目前没发现 MongoDB 有关系型数据库例如 MySql 的 Navicat 这种成熟的运维工具
总而言之,MongDB 的使用场景很大程度上可以对标关系型数据库,但是比较适合处理那些没有 join、没有强一致性要求且表 Schema 会常变化的数据。
通过以上讨论分析我们心中已经有了一个基本的选型框架指导,实际上在数据库选型时回答自己两个核心问题就好了:
什么时候选用关系型数据库,什么时候选用非关系型数据库
选用非关系型数据库的话,使用哪种非关系型数据库
NoSQL 数据库都是通过牺牲了 ACID 特性来获取更高性能的,假设表数据有很强的事务特性需求,那么这类数据是不适合放在非关系型数据库。此外,选用 NoSQL 数据库时也要根据公司技术栈框架、业务特性、运维成本等多方面考虑是否采纳。
关系型数据库和 NoSQL 数据库的选型,往往需要考虑几个指标:
数据量
并发量
实时性
一致性要求
读写分布和类型
安全性
运维成本
常见软件系统数据库选型参考如下:
中后台管理型系统 - 如运营系统,数据量少,并发量小,首选关系型数据库。
大流量系统 - 如电商单品页,后台考虑选关系型数据库,前台考虑选内存型数据库。
日志型系统 - 原始数据考虑选列式数据库,日志搜索考虑选搜索引擎。
搜索型系统 - 例如站内搜索,非通用搜索,如商品搜索,后台考虑选关系型数据库,前台考虑选搜索引擎。
事务型系统 - 如库存,交易,记账,考虑选关系型数据库 + K-V 数据库(作为缓存)+ 分布式事务。
离线计算 - 如大量数据分析,考虑选列式数据库或关系型数据库。
实时计算 - 如实时监控,可以考虑选内存型数据库或者列式数据库。
设计实践中,要基于需求、业务驱动架构,无论选用 RDB/NoSQL, 一定是以需求为导向,最终数据存储方案必然是各种权衡的综合性设计。
我们是阿里巴巴淘系技术部的新品平台技术团队, 依托于淘系大数据正在建立一套完整的涵盖消费者洞察、宏观及细分市场分析、竞争分析、市场策略研究、产品创新机制等的新品研发和创新孵化平台, 为品牌、商家及行业提供规模化的新品孵化和运营能力, 沉淀新品孵化机制和运营策略, 最终建立起一套基于大数据驱动的从市场研究、新品研发到新品投放营销的全链路新品运营平台。发送邮件到tianhang.th#alibaba-inc.com(发送邮件时,请把#替换成@)
Go 本地缓存选型对比及原理总结
提到本地缓存大家都不陌生,只要是个有点经验的后台开发人员,都知道缓存的作用和弊端。本篇文章我们就来简单聊聊在 golang 做业务开发的过程中,本地缓存的一些可选的开源方案。分析它们的特点,以及内部的实现原理。
1、本地缓存需求分析
首先来梳理一下业务开发过程中经常面临的本地缓存的一些需求。我们一般做缓存就是为了能提高系统的读写性能,缓存的命中率越高,也就意味着缓存的效果越好。其次本地缓存一般都受限于本地内存的大小,所有全量的数据一般存不下。那基于这样的场景:
- 一方面是想缓存的数据越多,则命中率理论上也会随着缓存数据的增多而提高;
- 另外一方面是想,既然所有的数据存不下那就想办法利用有限的内存存储有限的数据。
这些有限的数据需要是经常访问的,同时有一定时效性(不会频繁改变)的。基于这两个点展开,我们一般对本地缓存会要求其满 足支持过期时间、支持淘汰策略。最后再使用自动管理内存的语言例如 golang 等开发时,还需要考虑在加入本地缓存后引发的 GC 问题。
分析完我们日常本地缓存的诉求,再结合我们日常开发用到的 golang 语言,我们可以提炼得到 golang 本地缓存组件必须具备以下几个能力:

分析清楚了我们的需求,也明确了我们需要的能力。那自然优先考虑 golang 内置的标准库中是否存在这样的组件可以直接使用呢?
很遗憾,没有。golang 中内置的可以直接用来做本地缓存的无非就是 map 和 sync.Map。而这两者中,map 是非并发安全的数据结构,在使用时需要加锁;而 sync.Map 虽然是线程安全的。但是需要在并发读写时加锁。此外二者均无法支持数据的过期和淘汰,同时在存储大量数据时,又会产生比较频繁的 GC 问题,更严重的情况下导致线上服务无法稳定运行。
既然标准库中没有我们满足上述需求的本地缓存组件,那我们就想只有两种解决方案了
- 业界是否有开源成熟的方案可供选择
- 业界无可用组件时,自己动手写一个
那首先面临的第一个问题就是方案的调研和选型,没有合适的方案时自己再来动手构建。下面我们就来给大家介绍下 golang 中哪些可以直接来使用的本地缓存组件吧。
2、golang 本地缓存组件概览
golang 中本地缓存方案可选的有如下一些:
- freecache
- bigcache
- fastcache
- offheap
- groupcache
- ristretto
下面通过笔者一段时间的调研和研究,将 golang 可选的开源本地缓存组件汇总为下表,方便大家在方案选型时作参考。

在上述方案中,freecache、bigcache、fastcache、ristretto、groupcache 这几个大家根据实际的业务场景首选,offheap 有定制需求时可考虑。
通过上表的总结,个人想再此再谈几点关于本地缓存组件的理解:
(1)上述本地缓存组件中,实现零 GC 的方案主要就两种:
- 无 GC:分配堆外内存(Mmap)
- 避免 GC:map 非指针优化(map[uint64]uint32)或者采用 slice 实现一套无指针的 map
- 避免 GC:数据存入[]byte slice(可考虑底层采用环形队列封装循环使用空间)
(2)实现高性能的关键在于:
- 数据分片(降低锁的粒度)
上述几种缓存组件每种组件的实现都是 1 和 2 的几个分支的组合。下面我们大概给大家介绍每种组件的核心原理。
主流缓存组件实现原理剖析
在本节中我们会重点分析下 freecache、bigcache、fastcache、offheap 这几个组件内部的实现原理。
2.1 freecache 实现原理
首先分析下 freecache 的内部实现原理。在 freecache 中它通过 segment 来进行对数据分片,freecache 内部包含 256 个 segment,每个 segment 维护一把互斥锁,每一条 kv 数据进来后首先会根据 k 进行计算其 hash 值,然后根据 hash 值决定当前的这条数据落入到哪个 segment 中。
对于每个 segment 而言,它由索引、数据两部分构成。
索引:其中索引最简单的方式采用 map 来维护,例如 map[uint64]uint32 这种。而 freecache 并没有采用这种做法,而是通过采用 slice 来底层实现一套无指针的 map,以此避免 GC 扫描。
数据:数据采用环形缓冲区来循环使用,底层采用[]byte 进行封装实现。数据写入环形缓冲区后,记录写入的位置 index 作为索引,读取时首先读取数据 header 信息,然后再读取 kv 数据。
在 freecache 中数据的传递过程是:freecache->segment->(slot,ringbuffer)
下图是 freecache 的内部实现框架图。
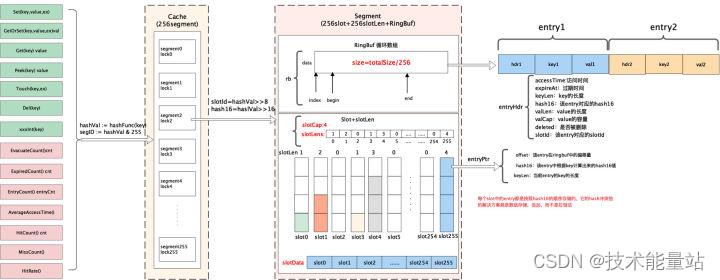
总结: freecache 通过利用数据分片减小锁的粒度,然后再存储时索引并没有采用内置的 map 来维护而是采用自建 map 减少指针来避免 GC,同时数据存储时采用预先分配内存然后后边循环使用。通过上述两种方法保证了在堆上分配内存同时减少 GC 对系统性能的影响。
2.2 bigcache 实现原理
bigcache 和 freecache 类似,也是一个零 GC、高性能的 cache 组件,但是它的实现和 freecache 还是有些差异,这儿有篇英文博客介绍 bigcache 设计原理的,内容稍长感兴趣的可以阅读下,下面我们介绍一下 bigcache 的实现原理。
bigcache 同样是采用分片的方式构成,一个 bigcache 对象包含 2^n 个 cacheShard 对象,默认是 1024 个。每个 cacheShard 对象维护着一把 sync.RWLock 锁(读写锁)。所有的数据会分散到不同的 cacheShard 中。
每个 cacheShard 同样由索引和数据构成。索引采用 map[uint64]uint32 来存储,数据采用 entry([]byte)环形队列存储。索引中存储的是该条数据在 entryBuffer 写入的位置 pos。每条 kv 数据按照 TLV 的格式写入队列。
不过值得注意的是,和 bigcache 和 freecache 不同的一点在于它的环形队列可以自动扩容。同时 bigcache 中数据的过期是通过全局的时间窗口维护的,每个单独的 kv 无法设置不同的过期时间。
下面是 bigcache 的内容实现原理框架图。

总结:bigcache 思路和 freecache 大体相同,只不过在索引存储时更为巧妙,直接采用内置的 map 结构加上基础数据类型来实现。同时底层存储数据的队列也可以根据空间大小来决定是否扩容。唯一的缺陷是无法针对每个 key 进行设置不同的过期时间。这个个人认为如果想用 bigcache 同时想要这个特性,可以进行二次开发一下。
通过性能测试数据来看,bigcache 性能要比 freecache 稍微好一点。大家可以思考下他们性能的差异可能会在哪里呢?
2.3 fastcache 实现原理
本节介绍下 fastcache 的实现原理,根据 fastcache 官方文档介绍,它的灵感来自于 bigcache。所以整体的思路和 bigcache 很类似,数据通过 bucket 进行分片。fastcache 由 512 个 bucket 构成。每个 bucket 维护一把读写锁。在 bucket 内部数据同理是索引、数据两部分构成。索引用 map[uint64]uint64 存储。数据采用 chunks 二维的切片(二维数组)存储。不过值得注意的是 fastcache 有一个很大的特性是,它的内存分配是在堆外分配的,而不是在堆上分配的。堆外分配的内存。这样做也就避免了 golang GC 的影响。下图是 fastcache 内部实现框架图。
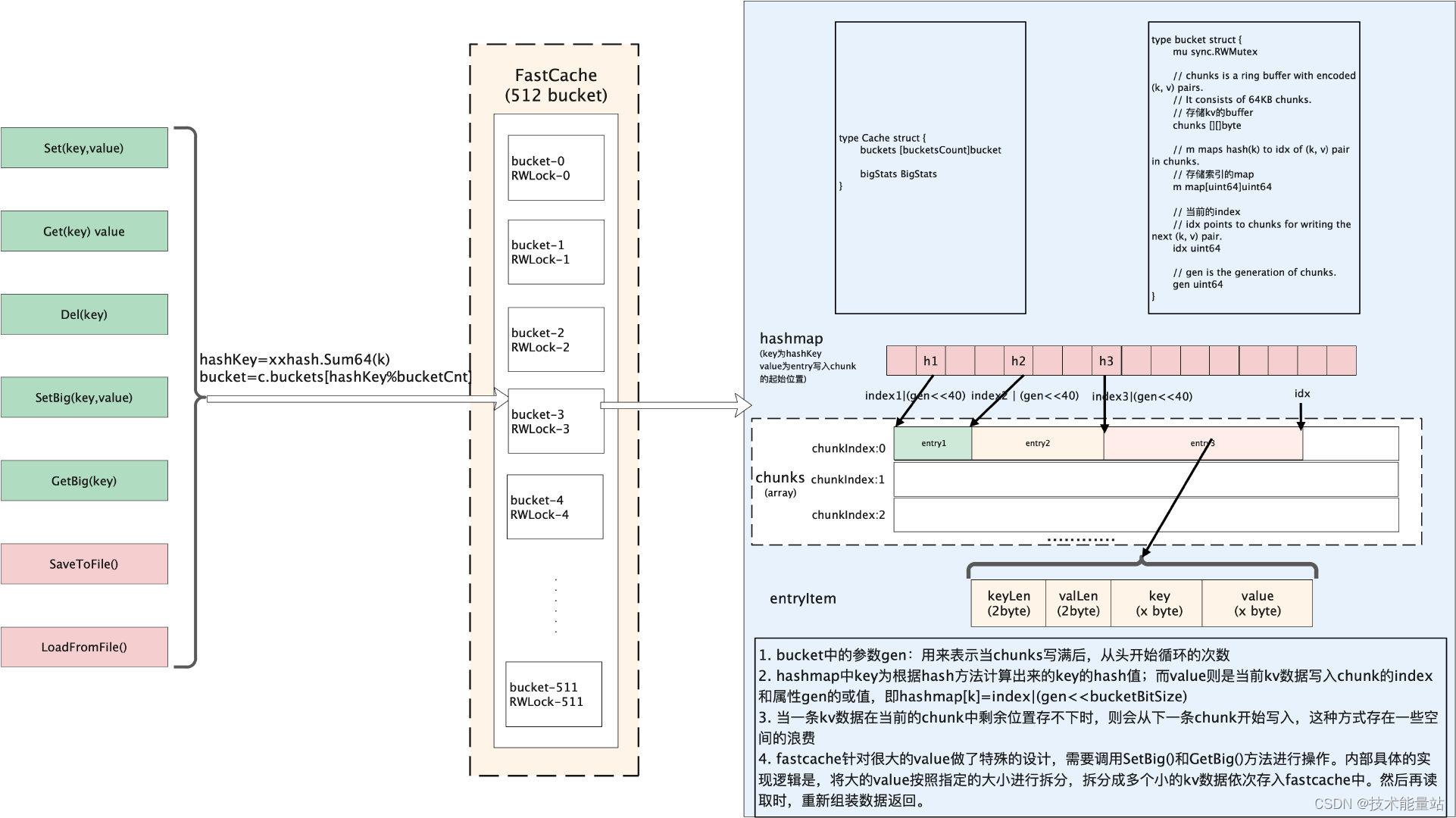
总结: fastcache 一方面充分利用了分片来降低锁的粒度,另一方面在索引存储时采用了对 map 的优化,同时在分配内存时,直接从堆外申请内存,自己实现了分配和释放内存的逻辑。通过上述手段使得 GC 的影响降到了最低。fastcache 唯一的缺陷是官方提供的版本没有提供针对 kv 数据的过期时间这个特性。所以如果需要这个特性的话,需要自己动手二次开发。整体从性能上来看是比 bigcache 和 freecache 都更优。
2.4 offheap 实现原理
本节介绍下 offheap 的相关内容,offheap 其实功能就比较简单了,就是一个基于堆外内存构建的哈希表。它通过直接调用系统调用函数来分配内存。然后在内部通过数组来实现哈希表。实现过程中当发生哈希冲突时,它是采用探测法来解决。由于是在堆外分配的内存上构建的哈希表。导致它的 GC 开销非常的小。下图是 offheap 的内部实现框架图。

总结:offheap 内部由于是采用探测法解决哈希冲突的,所以当哈希冲突严重时数据删除、查询都会带来非常复杂的处理流程。而且性能也会有一些损耗。可以作为学习和研究的项目还是非常不错的。
3. 总结
本文主要从日常需求出发,分析了日常业务过程中对本地缓存的需求,再调研了业界可选的一些组件并进行了对比,希望对本地缓存选型上起到一些参考和帮助。最后再对其中比较重要的几个组件如 freecache、bigcache、fastcache、offheap 等做了内部实现的简单介绍。上述内容只是从架构层面展开介绍,后续有时间再从源码层面做一些分析。由于篇幅限制本篇内容并未对 map、sync.Map、go-cache、groupcache 进行介绍。感兴趣的读者可以自行搜索资料进行阅读。如果大致理解了上述原理的童鞋也可以自己动手实践起来,造个轮子看看。
以上是关于数据库存储选型经验总结的主要内容,如果未能解决你的问题,请参考以下文章