来自未来,2022 年的前端人都在做什么?
Posted 字节前端 ByteFE
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了来自未来,2022 年的前端人都在做什么?相关的知识,希望对你有一定的参考价值。
常年保持榜首位置,但是在 2021 年 Q4 被 Python 反超(很可能是因为分流了一部分人去使用 TypeScript),而 TypeScript 持续保持上涨态势,受到更多前端开发者的青睐,可以想象在未来 TypeScript 将大有可为。还没有尝试过 vite 的小伙伴何不试试这款不需要做任何编译的神器,说不定它帮你省下的时间可以让你在午后悠闲的喝一杯咖啡
package-lock.json 文件后,二者的差距就很小了,也没有非用不可的场景,而它自带支持 Monorepo 的功能也很难说比 lerna 更好用。等进行数据可视化的显示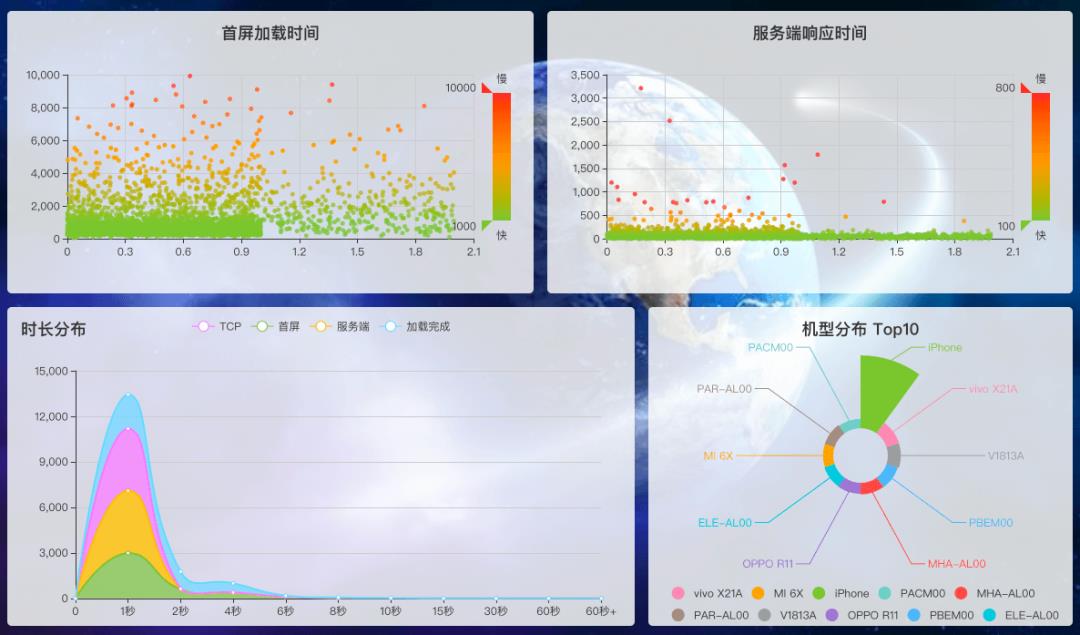
也可以用可视化的手段去解释模型,辅助算法同学调参。最简单的一个应用前端同学肯定非常熟悉,我们来看下图:
目前提到人工智能,和前端密切相关的几个 JS 类库有:
tensorflow.js Node 的 tvnet 算法,可以提取视频中的稠密光流高性能计算:
大家可能发现一个问题,一般的 tensorflow 模型动辄几百兆,在前端怎么跑呢?这就不得不提到 MobileNet,这是针对于移动端模型提出的神经网络架构,能极大地减少模型参数量,同理也能用到浏览器端上。
在较早的 2017 年,一篇关于图像转代码的 Pix2Code 论文掀起了业内激烈讨论的波澜,讲述如何从设计原型直接生成源代码。随后社区也不断涌现出基于此思想的类似 Screenshot2Code 的作品,2018 年微软 AI Lab 开源了草图转代码 工具 Sketch2Code,同年年底,设计稿智能生成前端代码的新秀 Yotako 也初露锋芒, 机器学习首次以不可小觑的姿态正式进入了前端开发者的视野。
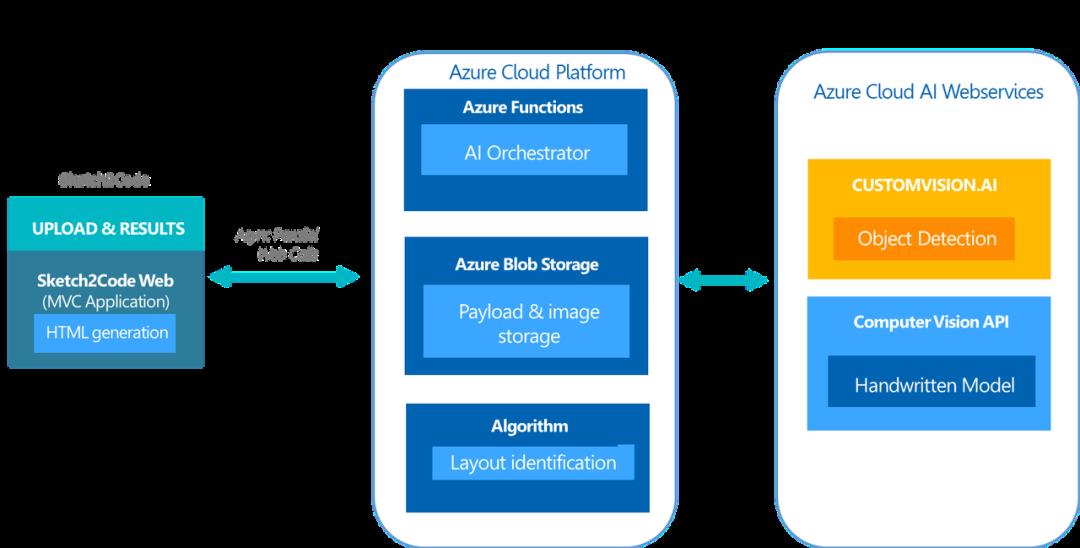
Sketch2Code 架构
阿里的 imgcook 可以通过识别设计稿(Sketch / PSD /图片)智能生成 React、Vue、Flutter、小程序等不同种类的代码,并在同年双 11 大促中自动生成了 79.34% 的前端代码,智能生成代码不再只是一个线下实验产品,而是真正产生了价值。
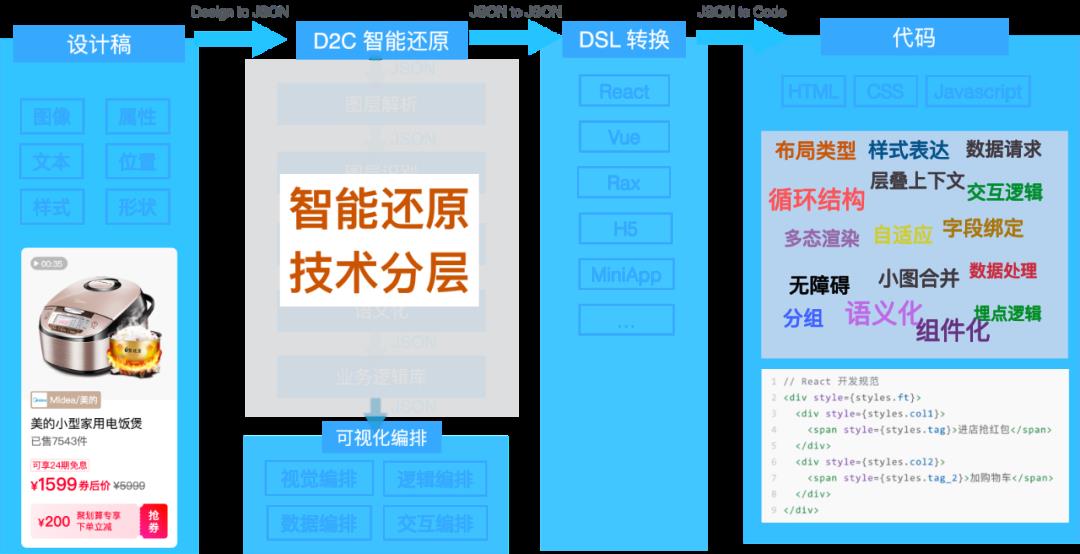
imgcook 代码生成过程
目前 Imgcook 官网已有 31,913 位用户上传了 92,333 个页面,累计生成了 67,787,814 行代码,阿里双 11 代码可用率达 79%,数据比较可观,根据目前现状分析,imgcook 能力在营销活动页面生产方面表现更好。
2022 年随着低代码和图形化技术的逐步完善,2 者会相互完善和成就彼此。使用者通过 AI 实现页面的还原然后再通过低代码平台对页面进行调整,整个过程基本上不写什么代码就可以完成整个页面的搭建,搭建页面真的会变得特别简单。
多端跨平台解决方案的优劣。可以把 DevOps 理解为一个过程、方法与系统的总称。在业务的快速迭代持续交互过程中 DevOps 的作用十分明显。得益于其诱人的优势,DevOps 已经成为目前软件开发中不可缺少的因素。根据 信通院携手华为云 DevCloud 发布中国 DevOps 现状调查报告(2021 年)调查结果显示,企业对研发运营一体化(DevOps)能力成熟度评估的关注程度持续上涨。调查还显示,63.64%的受访者对 DevOps 能力成熟度评估感兴趣,相比 2020 年增长近一成。所以 2022 年 DevOps 或许还是会从以下几个方面值得关注。
微服务架构:微服务架构可以将一个应用分成需要更小的服务,这让整个开发过程具有很高的敏捷性和可拓展性 与 Kubernetes 相结合:Kubernetes 是一种开源容器编排系统,容器技术的日益普及是 DevOps 出现的因素之一。使用 Kubernetes DevOps,软件开发人员和运维团队可以快速实时地相互交换大量的应用程序,大大提高了生产力 DevSecOps( DevOps + Security ):安全问题一直都是各个公司最重要的事情,所以肯定会被重视。如果安全能与 CI/CD 工具集成,能在开发阶段持续的监控和修复安全漏洞,那么会很大程度的提高交付的速度和质量 。「Data-TnS-FE」部门为公司全球化产品的内容安全业务提供各类能力,其目标是从用户/业务视角出发,结合技术赋能于业务,打造更多普适便捷的业务中台、基础架构、解决方案等,为团队所有业务的运作提供稳定、高效、易用的能力支撑。
https://css-tricks.com/comparing-the-new-generation-of-build-tools/https://insights.stackoverflow.com/survey/2021#most-loved-dreaded-and-wanted-webframe-love-dread 探索低代码的未来.pdf: https://bytedance.feishu.cn/file/boxcnvKV03brRBnDRM3ZEElL3Kg 国内外低代码平台交流: https://github.com/taowen/awesome-lowcode 2021 中国低代码市场研究报告: https://pdf.dfcfw.com/pdf/H3_AP202108051508251387_1.pdf?1628205916000.pdf 小程序: https://developers.weixin.qq.com/ebook?action=get_post_info&docid=0000e82f924ca0bb00869a5de5ec0a) 底层框架: https://developers.weixin.qq.com/ebook?action=get_post_info&docid=0000e82f924ca0bb00869a5de5ec0a 同层渲染: https://developers.weixin.qq.com/community/develop/article/doc/000c4e433707c072c1793e56f5c813 Taro 对比原生: https://docs.taro.zone/blog/2020-04-27-taro-vs-jd#%E6%80%A7%E8%83%BD%E5%AF%B9%E6%AF%94 跨端框架横评对比: https://juejin.cn/post/6844904118901817351 Taro: https://docs.taro.zone/blog/2020-01-02-gmtc uniapp: https://v.qq.com/x/page/r0886mn8v6l.html 
WebGPU,前端可视化的未来。
来自 「米兰的小铁匠」 同学的分享
一、什么是WebGPU
1.1 WebGL的恩怨情仇
先跟大家分享一波科技圈的八卦,感受一下WebGL是多么的不容易吧。
OpenGL由Khronos Group组织在1992年的时候推出,距离现在已经30年了。
OpenGL ES 是由Khronos Group在2003年针对手机、PDA和游戏主机等嵌入式设备设计的。
OpenGL ES 2.0 诞生于2007年3月,3.0版本则诞生于2012年8月,3.1版本是2014年3月,最后一个正式版 3.2 则是2015年8月。之后将会以扩展的形式添加新功能,相对应的,OpenGL 的绝唱 4.6版本 发布于2017年7月。
2009年,Khronos成立了WebGL工作组,成员包括Apple、Google、Mozilla、Opera等。
2011年的时候,WebGL 1.0版本正式推出,它是基于OpenGL ES 2.0版本发布的。
2013年的时候,WebGL工作组开始着手定制WebGL 2.0规范,但是直到2017年2月,2.0标准才正式被发布并被Google/Mozilla支持。WebGL 2.0 基于 OpenGL ES 3.0版本。
这之后,又有一些 OpenGL ES 3.1 特性被引入到WebGL 2.0版本中,作为extension形式由各个浏览器自行实现。
2021年9月,距离标准发布已经过去了四年半,Apple才官方宣布支持WebGL 2.0版本。
Apple曾经的掌门人Steve Jobs曾经力挺OpenGL ES,认为开放即未来,对Flash嗤之以鼻,谁知道老爷子走了以后,Apple采用了自研的图形框架Metal,从开放走向闭环。
提到Metal,当代呈现出图形框架三足鼎立的局势,即Apple的「Metal」、Khronos的「Vulkan」(没错,新开个了个号)、Windows的「DirectX 12」,全面释放了GPU的可编程能力**。**也就是这么几年的时间,计算机图形学发生了翻天覆地的变化,OpenGL的思想越来越跟不上时代了。
另外根据贝壳大佬在GMTC上的分享,Chrome运行的WebGL并没有用OpenGL引擎,而是由Angle(https://github.com/google/angle)这个库转化为本地的图形编程接口,比如Windows转化为DirectX,Apple转化为Metal来绘制的。
不过OpenGL仍然没有完全过时,虽然3A级别游戏大作不太可能继续采用OpenGL构建,但是简单场景、嵌入式图形领域,科研行业等等,OpenGL仍然是最舒服的选择。
1.2 WebGPU PK WebGLNext
2016年6月,Google 产生了使用新API来代替WebGL的想法,称之为 WebGL Next。
2017年1月,Khronos Group 举办了WebGL Next研讨会,Chromium一马当先,展示了可以基于OpenGL和Metal独立运行的新图形系统原型,同时Apple和Mozilla也分别展示了自己的原型,三者都非常类似于Metal Api。
次月,Apple就向W3C提交了一个名为 WebGPU 的技术概念验证方案,基于Metal图形开放接口,最终W3C采纳了 WebGPU 这个名字作为下一代标准,Apple的提案进入了正式的小组提案中。
3月,Mozilla向Khronos Group提交了基于Vulkan的名为WebGL Next提案。
2018年6月,Chrome团队宣布着手实现WebGPU,这意味着Khronos的失败,WebGPU胜出,大家以后还是团结在W3C的周围。
按照预期,工作组希望在2021年底发布WebGPU 1.0 标准,不过目前只有草案。
WebGPU 1.0 草案:https://www.w3.org/standards/types#WD
1.3 WebGPU 的特性
直接和Vulkan、Metal、Direct3D 12等高性能的本地图形标准库对标
这意味着WebGPU将会是一个对高性能GPU的桥接层,只要按照这套标准就可以实现一个利用GPU的工具库,它的着色器是一套符合Vulkan SPIR-V 的二进制规范,只要是按照这个规范的产物,加上一个支持GPU的运行时,这会有相当大的潜力。
像WebAssembly当初也是被设计为浏览器可执行的二进制格式,但是随后在Server端获取了更广泛的应用,已经具备替代Docker的潜力了。
支持GPU Compute Shader,支持GPU通用计算
这意味着在浏览器端可以用GPU跑计算任务了,不光可以用来绘制图形,还可以利用GPU并行计算能力来做更多的算法,像大数排序,机器学习等任务有可能放在浏览器端实现。
自定义的着色器语言 WGSL
WGSL(WebGPU Shading Language)是全新的一门语言,WebGPU设计这门语言时大量参考了Vulkan SPIR-V,因为版权、利益分配等问题,最终决定新造一门语言,一门混合Rust、TypeScript、Metal的编程语言,之前用WebGL的同学应该知道着色器是用GLSL编写的,没关系,最终只要有工具转为Vulkan SPIR-V 二进制程序即可。
目前WGSL还没有定最终版本,学习成本也比GLSL要大一些。
更好的架构设计
WebGPU摆脱了状态机机制,新增 Pipeline、Renderpass、CommandEncoder 等对象。
WebGPU对应的JavaScript对象,实际操作的就是GPU内部对象。
所有的WebGPU方法都是Promise,异步代码会交给GPU来实现,外层不需关心。
更好的TypeScript类型支持。
更好的性能
重中之重,我们看一下benchmark
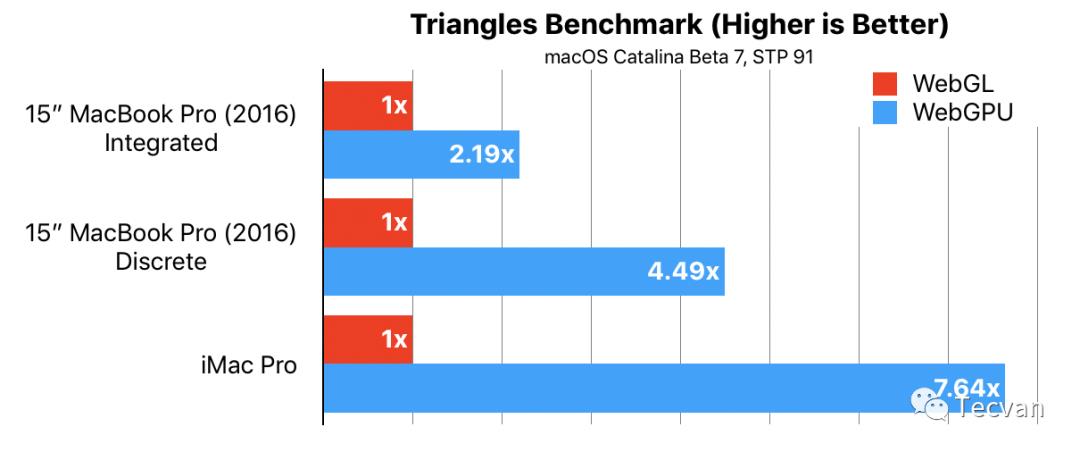
这是在维持60fps下,能画出的最多三角形,可以看出显卡的潜力被释放出来了。
还有一个babylon的例子(搬自知乎)
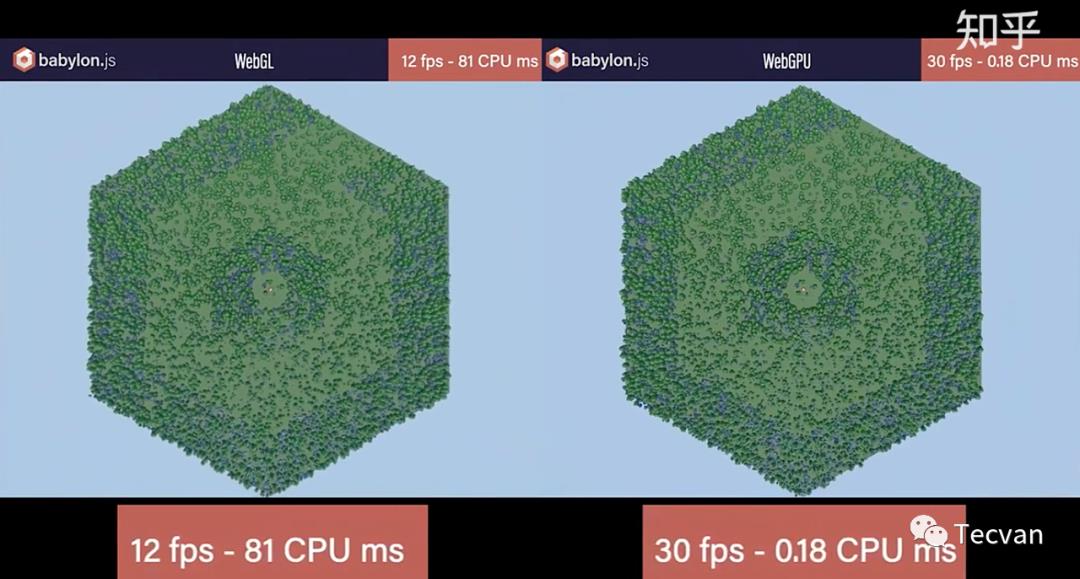
这个场景有1000多个没有实例化的树,每一颗树都有一次drawcall,使用WebGL,CPU成为巨大的瓶颈,每一帧需要花费81ms,而使用WebGPU,CPU一帧只需要花费0.18ms,减少CPU耗时意味能给GPU留出更多的运行时间,这是WebGPU强大的一点。
1.4 体验WebGPU
目前Chrome正式版没有开启WebGPU,我们需要下载金丝雀版本:https://www.google.com/chrome/canary/
然后输入 chrome://flags/,找到#enable-unsafe-webgpu并打开
目前three.js和babylon等主流Web库都已支持WebGPU,可以查看一下Demo:
ThreeJS: https://threejs.org/examples/?q=webgpu#webgpu_compute
BabylonJS: https://playground.babylonjs.com/ 右上角选择 webgpu
学习实例:https://austin-eng.com/webgpu-samples/samples/helloTriangle
文章搜集:https://github.com/mikbry/awesome-webgpu
二、动手写一个WebGPU程序
由于目前WebGPU尚不稳定,所以我们目前还没有必要花特别多的精力来学习,我们基于webgpu-samples来做一些简单的学习。源代码参考:https://github.com/austinEng/webgpu-samples/
2.1 初始化
相比于WebGL画图至少要10多个API调用,WebGPU的使用八股文还是少了很多。
首先创建一个adapter
const adapter = await navigator.gpu.requestAdapter(option);
注意如果不支持WebGPU的浏览器,gpu对像是undefined,需要做好异常处理。
这里的adapter就是显示适配器的意思,通俗来说就叫显卡,每个适配器标志着一个硬件加速器(例如 GPU 或 CPU)实例和一个浏览器在该硬件加速器之上对 WebGPU 的实现。
这个方法接受一个option,目前如下:
powerPreference: 'low-power' | 'high-performance'
powerPreference表示需要采用哪一种耗电类型的显卡,low-power一般是自带的集成显卡,它性能较差但是更加省电,而high-performance表示采用更高性能的独立显卡。WebGPU推荐开发者尽量使用低耗电的GPU,除非绝对需要再使用独显。
接下来,我们拿到具体设备
const device = await adapter.requestDevice();
这个设备是一个实例化的对象,同一个adapter可以共享device实例,设备可以创建缓存,纹理,渲染管线,着色器模块等等。
创建一个WebGPU Canvas Context实例
const context = canvas.getContext('webgpu');
然后我们需要拿到canvas能绘制的最精细的像素
const size = [
canvas.clientWidth * devicePixelRatio,
canvas.clientHeight * devicePixelRatio
]
然后需要声明图像色彩格式,比如brga8unorm,即用8位无符号整数和rgba来表示颜色,从adapter中也能直接获取
const format = context.getPreferredFormat(adapter);
将参数配置化写入context中
context.configure(
device,
format,
size,
usage: GPUTextureUsage.RENDER_ATTACHMENT | GPUTextureUsage.COPY_SRC
)
在 WebGL 中,我们拥有一个默认的帧缓冲(Default Frame Buffer),如果不做任何其他操作,那么当我们执行绘制命令(draw call)的时候,所有绘制的内容都会填充到默认帧缓冲中,而显卡会把这个默认的帧缓冲直接提交给显示器,並显示在显示器中。
这会带来两个问题:
如果渲染过慢,显示器会取走未完成的图像,渲染出隔离的图像
如果渲染过快,GPU在等待显示器取图,造成性能浪费。
参考:https://gavinkg.github.io/ILearnVulkanFromScratch-CN/mdroot/%E6%A6%82%E5%BF%B5%E6%B1%87%E6%80%BB/%E4%BA%A4%E6%8D%A2%E9%93%BE.html
解决第一个问题办法是应用双缓冲区技术,即用一个缓冲区缓存上次渲染好的内容,极其类似React Fiber的双缓存,看来技术都是相通的。解决第二个问题可以继续应用三重缓冲,充分榨干显卡性能。
这个configure的作用主要是关联context和device实例,内部会做缓冲区实现(因为要跟显示器做交互嘛),size是绘制图像的大小,usage是图像用途,一般是固定搭配,表示需要向外输出图像。
2.2 指令编码器
创建一个指令编码器 CommandEncoder
const cmdEncoder = device.createCommandEncoder();
指令编码器,它的作用是把你需要让 GPU 执行的指令写入到 GPU 的指令缓冲区(Command Buffer)中,例如我们要在渲染通道中输入顶点数据、设置背景颜色、绘制(draw call)等等。
创建一个渲染通道 RenderPass
const renderPassDescriptor =
colorAttachments: [
view: context.getCurrentTexture().createView(),
loadValue: r: 0.0, g: 0.0, b: 0.0, a: 1.0 ,
storeOp: 'store',
,
],
;
colorAttachments是必填字段,用于储存(或者临时储存)图像信息,我们通常只会把渲染通道的结果存成一份,也就是只渲染到一个目标中,但是在某些高级渲染技巧中,我们需要把渲染结果储存成多份,也就是渲染到多个目标上,因此类型是一个数组。
下面的view,表示在哪里储存当前通道渲染的图像数据,我们指定使用context创建一个二进制数组来表示。loadValue可以理解为背景颜色,storeOp表示储存时的操作,可选为'store'储存 或者 'clear' 清除数据,默认就用store。
还有一个可选字段depthStencilAttachment表示附加在当前渲染通道用于储存渲染通道的深度信息和模板信息的附件,因为我们只绘制二维图形,所以不需要处理深度、遮挡、混合这些事情。
让指令编码器开启渲染管道
const renderPassEncoder = cmdEncoder.beginRenderPass(renderPassDescriptor);
这里让cmd和renderpass产生了关联,接下来就可以运行pipeline了
2.3 渲染管线
创建渲染管线(pipeline)是最复杂的一个步骤,在这里会应用我们的着色器程序。
着色器分为「顶点着色器」和「片元着色器」,对于不了解的同学可以简单解释下**。**
顶点着色器是对传入的图形的顶点进行计算,比如我们要画一个三角形,我们就要把三角形三个顶点通过着色器代码计算出来。
片元着色器是对顶点计算出来的面进行着色,比如我们要画一个红色的三角形,那片元着色器就应该输出红色。
我们可以先不用理解着色器是如何编写的,下面会做一些解释,先看JS API。
最简单的场景下,我们只需要配置如下
const pipeline = device.createRenderPipeline(
vertex:
module: device.createShaderModule(
code: triangleVertWGSL, // 顶点着色器代码
),
entryPoint: 'main', // 入口函数
,
fragment:
module: device.createShaderModule(
code: redFragWGSL, // 片元着色器代码
),
entryPoint: 'main', // 入口函数
targets: [
format: format, // 即上文的最终渲染色彩格式
,
],
,
primitive: // 绘制模式
topology: 'triangle-list', // 按照三角形绘制
,
);
其中着色器部分会在之后讲解,绘制模式支持绘制为点、线、重复连线、三角形、重复三角形,大部分情况下我们只使用triangle-list就可以了。
将pipeline和passencoder产生关联
renderPassEncoder.setPipeline(pipeline);
开始绘制
renderPassEncoder.draw(3, 1, 0, 0);
这里四个参数分别解释如下:
第一个:需要绘制的顶点数量,三角形当然是3个顶点
第二个:需要绘制几个实例,我们绘制一个就好
第三个:起始顶点位置
第四个:先绘制第几个实例
宣布绘制结束
renderPassEncoder.endPass();
这行代码表示当前的渲染通道已经结束了,不再向 GPU 发送指令。
结束指令编码器并提交数据
device.queue.submit([commandEncoder.finish()])
这行代码结束当前指令编码器,并将所有指令提交给GPU设备的默认队列。
完毕了,一切顺利的话,我们终于绘制出了一个三角形

怎么样,是不是很简单?

当然费了这么大工夫只画了个三角形,但是主要是理解WebGPU的设计理念,举一反三。相比下来WebGL的绘制比它还要更复杂一点。
三、着色器 WGSL 入门
完整的语法说明可以参考官方文档:https://gpuweb.github.io/gpuweb/wgsl
这里只针对上面的例子进行简要的解释
3.1 顶点着色器
我们先看一下代码
[[stage(vertex)]]
fn main([[builtin(vertex_index)]] VertexIndex : u32)
-> [[builtin(position)]] vec4<f32>
var pos = array<vec2<f32>, 3>(
vec2<f32>(0.0, 0.5),
vec2<f32>(-0.5, -0.5),
vec2<f32>(0.5, -0.5));
return vec4<f32>(pos[VertexIndex], 0.0, 1.0);
这里的双中括号,对应于WGSL的Attribute概念,用来进行对属性进行注解。
第1行,stage(vertex)是内置关键词,用来声明这是顶点着色器。
第2行,定义了名字为main的函数,对应上文中的entryPoint。
我们看一下参数,这里用了builtin(xx)来对变量进行注解,builtin的意思就是将变量关联到内置参数中(类似GLSL中的gl_xxx),详细参考官方文档。变量名字为VertexIndex,类型为u32,无符号32位整数。
builtin(vertex_index) 表示当前顶点的下标位置
第3行,定义此函数返回值类型
builtin(position)类似于gl_Position,即计算后顶点的最后位置。类型为vec4<f32>,即四元32位浮点类型。
第4行,进入函数体了,这里定义一个名字为pos的数组变量,元素类型为vec<f32>,数组长度为3。
第5-7行分别定义数组成员,也就是三角形三个顶点位置,这里和WebGL一样,坐标取值在[0.0, 1.0]之间。
第9行,根据传入的下标VertexIndex,找到刚才定义数组具体值并返回,之前draw函数指定有3个顶点,这个顶点着色器就会运行3次,就能获取三个不同顶点了。
3.2 片元着色器
先直接上代码
[[stage(fragment)]]
fn main() -> [[location(0)]] vec4<f32>
return vec4<f32>(1.0, 0.0, 0.0, 1.0);
第1行,类似地,应用了stage(fragment)来声明这是片元着色器。
第2行,定义了入口main函数,因为我们只渲染一个最基本的红色,不需要任何参数。
返回类型中,需要显式使用[[location(0)]]表示第一个返回的元素是vec4<f32>类型。这是为了用下标的方式获取定义的任意元素。
第3行,返回了一个vec4<f32>类型的元素,其中第1个元素(即R分量)为1.0,即把红色拉满,最后一个元素(即Alpha分量)为1.0,即把不透明度为100%。
其本质与GLSL并没有太大的区别,只是语法略显拗口,上手难度较高。
好了,我们终于把WGSL的大致用法说完了,我们还没有涉及到更复杂的应用,比如顶点着色器向片元着色器传值,内置函数,UV映射,复杂的数据绑定,内外的数据传递,后处理等等,这些等着WGSL语法成熟以后,我会慢慢再写一篇文章总结。
参考资料:
https://mp.weixin.qq.com/s/4LfaNHP77s9n9SghucYoaA
https://github.com/hjlld/LearningWebGPU
https://gpuweb.github.io/gpuweb/wgsl/#attributes
https://gpuweb.github.io/gpuweb/wgsl/#builtin-variables
以上是关于来自未来,2022 年的前端人都在做什么?的主要内容,如果未能解决你的问题,请参考以下文章
「Data-TnS-FE」部门为公司全球化产品的内容安全业务提供各类能力,其目标是从用户/业务视角出发,结合技术赋能于业务,打造更多普适便捷的业务中台、基础架构、解决方案等,为团队所有业务的运作提供稳定、高效、易用的能力支撑。
https://css-tricks.com/comparing-the-new-generation-of-build-tools/https://insights.stackoverflow.com/survey/2021#most-loved-dreaded-and-wanted-webframe-love-dread 探索低代码的未来.pdf: https://bytedance.feishu.cn/file/boxcnvKV03brRBnDRM3ZEElL3Kg 国内外低代码平台交流: https://github.com/taowen/awesome-lowcode 2021 中国低代码市场研究报告: https://pdf.dfcfw.com/pdf/H3_AP202108051508251387_1.pdf?1628205916000.pdf 小程序: https://developers.weixin.qq.com/ebook?action=get_post_info&docid=0000e82f924ca0bb00869a5de5ec0a) 底层框架: https://developers.weixin.qq.com/ebook?action=get_post_info&docid=0000e82f924ca0bb00869a5de5ec0a 同层渲染: https://developers.weixin.qq.com/community/develop/article/doc/000c4e433707c072c1793e56f5c813 Taro 对比原生: https://docs.taro.zone/blog/2020-04-27-taro-vs-jd#%E6%80%A7%E8%83%BD%E5%AF%B9%E6%AF%94 跨端框架横评对比: https://juejin.cn/post/6844904118901817351 Taro: https://docs.taro.zone/blog/2020-01-02-gmtc uniapp: https://v.qq.com/x/page/r0886mn8v6l.html
WebGPU,前端可视化的未来。
来自 「米兰的小铁匠」 同学的分享
一、什么是WebGPU
1.1 WebGL的恩怨情仇
先跟大家分享一波科技圈的八卦,感受一下WebGL是多么的不容易吧。
OpenGL由Khronos Group组织在1992年的时候推出,距离现在已经30年了。
OpenGL ES 是由Khronos Group在2003年针对手机、PDA和游戏主机等嵌入式设备设计的。
OpenGL ES 2.0 诞生于2007年3月,3.0版本则诞生于2012年8月,3.1版本是2014年3月,最后一个正式版 3.2 则是2015年8月。之后将会以扩展的形式添加新功能,相对应的,OpenGL 的绝唱 4.6版本 发布于2017年7月。
2009年,Khronos成立了WebGL工作组,成员包括Apple、Google、Mozilla、Opera等。
2011年的时候,WebGL 1.0版本正式推出,它是基于OpenGL ES 2.0版本发布的。
2013年的时候,WebGL工作组开始着手定制WebGL 2.0规范,但是直到2017年2月,2.0标准才正式被发布并被Google/Mozilla支持。WebGL 2.0 基于 OpenGL ES 3.0版本。
这之后,又有一些 OpenGL ES 3.1 特性被引入到WebGL 2.0版本中,作为extension形式由各个浏览器自行实现。
2021年9月,距离标准发布已经过去了四年半,Apple才官方宣布支持WebGL 2.0版本。
Apple曾经的掌门人Steve Jobs曾经力挺OpenGL ES,认为开放即未来,对Flash嗤之以鼻,谁知道老爷子走了以后,Apple采用了自研的图形框架Metal,从开放走向闭环。
提到Metal,当代呈现出图形框架三足鼎立的局势,即Apple的「Metal」、Khronos的「Vulkan」(没错,新开个了个号)、Windows的「DirectX 12」,全面释放了GPU的可编程能力**。**也就是这么几年的时间,计算机图形学发生了翻天覆地的变化,OpenGL的思想越来越跟不上时代了。
另外根据贝壳大佬在GMTC上的分享,Chrome运行的WebGL并没有用OpenGL引擎,而是由Angle(https://github.com/google/angle)这个库转化为本地的图形编程接口,比如Windows转化为DirectX,Apple转化为Metal来绘制的。
不过OpenGL仍然没有完全过时,虽然3A级别游戏大作不太可能继续采用OpenGL构建,但是简单场景、嵌入式图形领域,科研行业等等,OpenGL仍然是最舒服的选择。
1.2 WebGPU PK WebGLNext
2016年6月,Google 产生了使用新API来代替WebGL的想法,称之为 WebGL Next。
2017年1月,Khronos Group 举办了WebGL Next研讨会,Chromium一马当先,展示了可以基于OpenGL和Metal独立运行的新图形系统原型,同时Apple和Mozilla也分别展示了自己的原型,三者都非常类似于Metal Api。
次月,Apple就向W3C提交了一个名为 WebGPU 的技术概念验证方案,基于Metal图形开放接口,最终W3C采纳了 WebGPU 这个名字作为下一代标准,Apple的提案进入了正式的小组提案中。
3月,Mozilla向Khronos Group提交了基于Vulkan的名为WebGL Next提案。
2018年6月,Chrome团队宣布着手实现WebGPU,这意味着Khronos的失败,WebGPU胜出,大家以后还是团结在W3C的周围。
按照预期,工作组希望在2021年底发布WebGPU 1.0 标准,不过目前只有草案。
WebGPU 1.0 草案:https://www.w3.org/standards/types#WD
1.3 WebGPU 的特性
直接和Vulkan、Metal、Direct3D 12等高性能的本地图形标准库对标
这意味着WebGPU将会是一个对高性能GPU的桥接层,只要按照这套标准就可以实现一个利用GPU的工具库,它的着色器是一套符合Vulkan SPIR-V 的二进制规范,只要是按照这个规范的产物,加上一个支持GPU的运行时,这会有相当大的潜力。
像WebAssembly当初也是被设计为浏览器可执行的二进制格式,但是随后在Server端获取了更广泛的应用,已经具备替代Docker的潜力了。
支持GPU Compute Shader,支持GPU通用计算
这意味着在浏览器端可以用GPU跑计算任务了,不光可以用来绘制图形,还可以利用GPU并行计算能力来做更多的算法,像大数排序,机器学习等任务有可能放在浏览器端实现。
自定义的着色器语言 WGSL
WGSL(WebGPU Shading Language)是全新的一门语言,WebGPU设计这门语言时大量参考了Vulkan SPIR-V,因为版权、利益分配等问题,最终决定新造一门语言,一门混合Rust、TypeScript、Metal的编程语言,之前用WebGL的同学应该知道着色器是用GLSL编写的,没关系,最终只要有工具转为Vulkan SPIR-V 二进制程序即可。
目前WGSL还没有定最终版本,学习成本也比GLSL要大一些。
更好的架构设计
WebGPU摆脱了状态机机制,新增 Pipeline、Renderpass、CommandEncoder 等对象。
WebGPU对应的JavaScript对象,实际操作的就是GPU内部对象。
所有的WebGPU方法都是Promise,异步代码会交给GPU来实现,外层不需关心。
更好的TypeScript类型支持。
更好的性能
重中之重,我们看一下benchmark
这是在维持60fps下,能画出的最多三角形,可以看出显卡的潜力被释放出来了。
还有一个babylon的例子(搬自知乎)
这个场景有1000多个没有实例化的树,每一颗树都有一次drawcall,使用WebGL,CPU成为巨大的瓶颈,每一帧需要花费81ms,而使用WebGPU,CPU一帧只需要花费0.18ms,减少CPU耗时意味能给GPU留出更多的运行时间,这是WebGPU强大的一点。
1.4 体验WebGPU
目前Chrome正式版没有开启WebGPU,我们需要下载金丝雀版本:https://www.google.com/chrome/canary/
然后输入 chrome://flags/,找到#enable-unsafe-webgpu并打开
目前three.js和babylon等主流Web库都已支持WebGPU,可以查看一下Demo:
ThreeJS: https://threejs.org/examples/?q=webgpu#webgpu_compute
BabylonJS: https://playground.babylonjs.com/ 右上角选择 webgpu
学习实例:https://austin-eng.com/webgpu-samples/samples/helloTriangle
文章搜集:https://github.com/mikbry/awesome-webgpu
二、动手写一个WebGPU程序
由于目前WebGPU尚不稳定,所以我们目前还没有必要花特别多的精力来学习,我们基于webgpu-samples来做一些简单的学习。源代码参考:https://github.com/austinEng/webgpu-samples/
2.1 初始化
相比于WebGL画图至少要10多个API调用,WebGPU的使用八股文还是少了很多。
首先创建一个adapter
const adapter = await navigator.gpu.requestAdapter(option);
注意如果不支持WebGPU的浏览器,gpu对像是undefined,需要做好异常处理。
这里的adapter就是显示适配器的意思,通俗来说就叫显卡,每个适配器标志着一个硬件加速器(例如 GPU 或 CPU)实例和一个浏览器在该硬件加速器之上对 WebGPU 的实现。
这个方法接受一个option,目前如下:
powerPreference: 'low-power' | 'high-performance'
powerPreference表示需要采用哪一种耗电类型的显卡,low-power一般是自带的集成显卡,它性能较差但是更加省电,而high-performance表示采用更高性能的独立显卡。WebGPU推荐开发者尽量使用低耗电的GPU,除非绝对需要再使用独显。
接下来,我们拿到具体设备
const device = await adapter.requestDevice();
这个设备是一个实例化的对象,同一个adapter可以共享device实例,设备可以创建缓存,纹理,渲染管线,着色器模块等等。
创建一个WebGPU Canvas Context实例
const context = canvas.getContext('webgpu');
然后我们需要拿到canvas能绘制的最精细的像素
const size = [
canvas.clientWidth * devicePixelRatio,
canvas.clientHeight * devicePixelRatio
]
然后需要声明图像色彩格式,比如brga8unorm,即用8位无符号整数和rgba来表示颜色,从adapter中也能直接获取
const format = context.getPreferredFormat(adapter);
将参数配置化写入context中
context.configure(
device,
format,
size,
usage: GPUTextureUsage.RENDER_ATTACHMENT | GPUTextureUsage.COPY_SRC
)
在 WebGL 中,我们拥有一个默认的帧缓冲(Default Frame Buffer),如果不做任何其他操作,那么当我们执行绘制命令(draw call)的时候,所有绘制的内容都会填充到默认帧缓冲中,而显卡会把这个默认的帧缓冲直接提交给显示器,並显示在显示器中。
这会带来两个问题:
如果渲染过慢,显示器会取走未完成的图像,渲染出隔离的图像
如果渲染过快,GPU在等待显示器取图,造成性能浪费。
参考:https://gavinkg.github.io/ILearnVulkanFromScratch-CN/mdroot/%E6%A6%82%E5%BF%B5%E6%B1%87%E6%80%BB/%E4%BA%A4%E6%8D%A2%E9%93%BE.html
解决第一个问题办法是应用双缓冲区技术,即用一个缓冲区缓存上次渲染好的内容,极其类似React Fiber的双缓存,看来技术都是相通的。解决第二个问题可以继续应用三重缓冲,充分榨干显卡性能。
这个configure的作用主要是关联context和device实例,内部会做缓冲区实现(因为要跟显示器做交互嘛),size是绘制图像的大小,usage是图像用途,一般是固定搭配,表示需要向外输出图像。
2.2 指令编码器
创建一个指令编码器 CommandEncoder
const cmdEncoder = device.createCommandEncoder();
指令编码器,它的作用是把你需要让 GPU 执行的指令写入到 GPU 的指令缓冲区(Command Buffer)中,例如我们要在渲染通道中输入顶点数据、设置背景颜色、绘制(draw call)等等。
创建一个渲染通道 RenderPass
const renderPassDescriptor =
colorAttachments: [
view: context.getCurrentTexture().createView(),
loadValue: r: 0.0, g: 0.0, b: 0.0, a: 1.0 ,
storeOp: 'store',
,
],
;
colorAttachments是必填字段,用于储存(或者临时储存)图像信息,我们通常只会把渲染通道的结果存成一份,也就是只渲染到一个目标中,但是在某些高级渲染技巧中,我们需要把渲染结果储存成多份,也就是渲染到多个目标上,因此类型是一个数组。
下面的view,表示在哪里储存当前通道渲染的图像数据,我们指定使用context创建一个二进制数组来表示。loadValue可以理解为背景颜色,storeOp表示储存时的操作,可选为'store'储存 或者 'clear' 清除数据,默认就用store。
还有一个可选字段depthStencilAttachment表示附加在当前渲染通道用于储存渲染通道的深度信息和模板信息的附件,因为我们只绘制二维图形,所以不需要处理深度、遮挡、混合这些事情。
让指令编码器开启渲染管道
const renderPassEncoder = cmdEncoder.beginRenderPass(renderPassDescriptor);
这里让cmd和renderpass产生了关联,接下来就可以运行pipeline了
2.3 渲染管线
创建渲染管线(pipeline)是最复杂的一个步骤,在这里会应用我们的着色器程序。
着色器分为「顶点着色器」和「片元着色器」,对于不了解的同学可以简单解释下**。**
顶点着色器是对传入的图形的顶点进行计算,比如我们要画一个三角形,我们就要把三角形三个顶点通过着色器代码计算出来。
片元着色器是对顶点计算出来的面进行着色,比如我们要画一个红色的三角形,那片元着色器就应该输出红色。
我们可以先不用理解着色器是如何编写的,下面会做一些解释,先看JS API。
最简单的场景下,我们只需要配置如下
const pipeline = device.createRenderPipeline(
vertex:
module: device.createShaderModule(
code: triangleVertWGSL, // 顶点着色器代码
),
entryPoint: 'main', // 入口函数
,
fragment:
module: device.createShaderModule(
code: redFragWGSL, // 片元着色器代码
),
entryPoint: 'main', // 入口函数
targets: [
format: format, // 即上文的最终渲染色彩格式
,
],
,
primitive: // 绘制模式
topology: 'triangle-list', // 按照三角形绘制
,
);
其中着色器部分会在之后讲解,绘制模式支持绘制为点、线、重复连线、三角形、重复三角形,大部分情况下我们只使用triangle-list就可以了。
将pipeline和passencoder产生关联
renderPassEncoder.setPipeline(pipeline);
开始绘制
renderPassEncoder.draw(3, 1, 0, 0);
这里四个参数分别解释如下:
第一个:需要绘制的顶点数量,三角形当然是3个顶点
第二个:需要绘制几个实例,我们绘制一个就好
第三个:起始顶点位置
第四个:先绘制第几个实例
宣布绘制结束
renderPassEncoder.endPass();
这行代码表示当前的渲染通道已经结束了,不再向 GPU 发送指令。
结束指令编码器并提交数据
device.queue.submit([commandEncoder.finish()])
这行代码结束当前指令编码器,并将所有指令提交给GPU设备的默认队列。
完毕了,一切顺利的话,我们终于绘制出了一个三角形
怎么样,是不是很简单?
当然费了这么大工夫只画了个三角形,但是主要是理解WebGPU的设计理念,举一反三。相比下来WebGL的绘制比它还要更复杂一点。
三、着色器 WGSL 入门
完整的语法说明可以参考官方文档:https://gpuweb.github.io/gpuweb/wgsl
这里只针对上面的例子进行简要的解释
3.1 顶点着色器
我们先看一下代码
[[stage(vertex)]]
fn main([[builtin(vertex_index)]] VertexIndex : u32)
-> [[builtin(position)]] vec4<f32>
var pos = array<vec2<f32>, 3>(
vec2<f32>(0.0, 0.5),
vec2<f32>(-0.5, -0.5),
vec2<f32>(0.5, -0.5));
return vec4<f32>(pos[VertexIndex], 0.0, 1.0);
这里的双中括号,对应于WGSL的Attribute概念,用来进行对属性进行注解。
第1行,stage(vertex)是内置关键词,用来声明这是顶点着色器。
第2行,定义了名字为main的函数,对应上文中的entryPoint。
我们看一下参数,这里用了builtin(xx)来对变量进行注解,builtin的意思就是将变量关联到内置参数中(类似GLSL中的gl_xxx),详细参考官方文档。变量名字为VertexIndex,类型为u32,无符号32位整数。
builtin(vertex_index) 表示当前顶点的下标位置
第3行,定义此函数返回值类型
builtin(position)类似于gl_Position,即计算后顶点的最后位置。类型为vec4<f32>,即四元32位浮点类型。
第4行,进入函数体了,这里定义一个名字为pos的数组变量,元素类型为vec<f32>,数组长度为3。
第5-7行分别定义数组成员,也就是三角形三个顶点位置,这里和WebGL一样,坐标取值在[0.0, 1.0]之间。
第9行,根据传入的下标VertexIndex,找到刚才定义数组具体值并返回,之前draw函数指定有3个顶点,这个顶点着色器就会运行3次,就能获取三个不同顶点了。
3.2 片元着色器
先直接上代码
[[stage(fragment)]]
fn main() -> [[location(0)]] vec4<f32>
return vec4<f32>(1.0, 0.0, 0.0, 1.0);
第1行,类似地,应用了stage(fragment)来声明这是片元着色器。
第2行,定义了入口main函数,因为我们只渲染一个最基本的红色,不需要任何参数。
返回类型中,需要显式使用[[location(0)]]表示第一个返回的元素是vec4<f32>类型。这是为了用下标的方式获取定义的任意元素。
第3行,返回了一个vec4<f32>类型的元素,其中第1个元素(即R分量)为1.0,即把红色拉满,最后一个元素(即Alpha分量)为1.0,即把不透明度为100%。
其本质与GLSL并没有太大的区别,只是语法略显拗口,上手难度较高。
好了,我们终于把WGSL的大致用法说完了,我们还没有涉及到更复杂的应用,比如顶点着色器向片元着色器传值,内置函数,UV映射,复杂的数据绑定,内外的数据传递,后处理等等,这些等着WGSL语法成熟以后,我会慢慢再写一篇文章总结。
参考资料:
https://mp.weixin.qq.com/s/4LfaNHP77s9n9SghucYoaA
https://github.com/hjlld/LearningWebGPU
https://gpuweb.github.io/gpuweb/wgsl/#attributes
https://gpuweb.github.io/gpuweb/wgsl/#builtin-variables
以上是关于来自未来,2022 年的前端人都在做什么?的主要内容,如果未能解决你的问题,请参考以下文章
来自 「米兰的小铁匠」 同学的分享
WebGPU 1.0 草案:https://www.w3.org/standards/types#WD
直接和Vulkan、Metal、Direct3D 12等高性能的本地图形标准库对标
支持GPU Compute Shader,支持GPU通用计算
自定义的着色器语言 WGSL
更好的架构设计
更好的性能
chrome://flags/,找到#enable-unsafe-webgpu并打开ThreeJS: https://threejs.org/examples/?q=webgpu#webgpu_compute
BabylonJS: https://playground.babylonjs.com/ 右上角选择 webgpu
学习实例:https://austin-eng.com/webgpu-samples/samples/helloTriangle
文章搜集:https://github.com/mikbry/awesome-webgpu
首先创建一个adapter
const adapter = await navigator.gpu.requestAdapter(option);gpu对像是undefined,需要做好异常处理。显卡,每个适配器标志着一个硬件加速器(例如 GPU 或 CPU)实例和一个浏览器在该硬件加速器之上对 WebGPU 的实现。option,目前如下:powerPreference: 'low-power' | 'high-performance'low-power一般是自带的集成显卡,它性能较差但是更加省电,而high-performance表示采用更高性能的独立显卡。WebGPU推荐开发者尽量使用低耗电的GPU,除非绝对需要再使用独显。接下来,我们拿到具体设备
const device = await adapter.requestDevice();创建一个WebGPU Canvas Context实例
const context = canvas.getContext('webgpu');然后我们需要拿到canvas能绘制的最精细的像素
const size = [
canvas.clientWidth * devicePixelRatio,
canvas.clientHeight * devicePixelRatio
]然后需要声明图像色彩格式,比如brga8unorm,即用8位无符号整数和rgba来表示颜色,从adapter中也能直接获取
const format = context.getPreferredFormat(adapter);将参数配置化写入context中
context.configure(
device,
format,
size,
usage: GPUTextureUsage.RENDER_ATTACHMENT | GPUTextureUsage.COPY_SRC
)如果渲染过慢,显示器会取走未完成的图像,渲染出隔离的图像
如果渲染过快,GPU在等待显示器取图,造成性能浪费。
参考:https://gavinkg.github.io/ILearnVulkanFromScratch-CN/mdroot/%E6%A6%82%E5%BF%B5%E6%B1%87%E6%80%BB/%E4%BA%A4%E6%8D%A2%E9%93%BE.html
configure的作用主要是关联context和device实例,内部会做缓冲区实现(因为要跟显示器做交互嘛),size是绘制图像的大小,usage是图像用途,一般是固定搭配,表示需要向外输出图像。创建一个指令编码器 CommandEncoder
const cmdEncoder = device.createCommandEncoder();创建一个渲染通道 RenderPass
const renderPassDescriptor =
colorAttachments: [
view: context.getCurrentTexture().createView(),
loadValue: r: 0.0, g: 0.0, b: 0.0, a: 1.0 ,
storeOp: 'store',
,
],
;colorAttachments是必填字段,用于储存(或者临时储存)图像信息,我们通常只会把渲染通道的结果存成一份,也就是只渲染到一个目标中,但是在某些高级渲染技巧中,我们需要把渲染结果储存成多份,也就是渲染到多个目标上,因此类型是一个数组。view,表示在哪里储存当前通道渲染的图像数据,我们指定使用context创建一个二进制数组来表示。loadValue可以理解为背景颜色,storeOp表示储存时的操作,可选为'store'储存 或者 'clear' 清除数据,默认就用store。depthStencilAttachment表示附加在当前渲染通道用于储存渲染通道的深度信息和模板信息的附件,因为我们只绘制二维图形,所以不需要处理深度、遮挡、混合这些事情。让指令编码器开启渲染管道
const renderPassEncoder = cmdEncoder.beginRenderPass(renderPassDescriptor);最简单的场景下,我们只需要配置如下
const pipeline = device.createRenderPipeline(
vertex:
module: device.createShaderModule(
code: triangleVertWGSL, // 顶点着色器代码
),
entryPoint: 'main', // 入口函数
,
fragment:
module: device.createShaderModule(
code: redFragWGSL, // 片元着色器代码
),
entryPoint: 'main', // 入口函数
targets: [
format: format, // 即上文的最终渲染色彩格式
,
],
,
primitive: // 绘制模式
topology: 'triangle-list', // 按照三角形绘制
,
);triangle-list就可以了。将pipeline和passencoder产生关联
renderPassEncoder.setPipeline(pipeline);开始绘制
renderPassEncoder.draw(3, 1, 0, 0);宣布绘制结束
renderPassEncoder.endPass();结束指令编码器并提交数据
device.queue.submit([commandEncoder.finish()])[[stage(vertex)]]
fn main([[builtin(vertex_index)]] VertexIndex : u32)
-> [[builtin(position)]] vec4<f32>
var pos = array<vec2<f32>, 3>(
vec2<f32>(0.0, 0.5),
vec2<f32>(-0.5, -0.5),
vec2<f32>(0.5, -0.5));
return vec4<f32>(pos[VertexIndex], 0.0, 1.0);
第1行,stage(vertex)是内置关键词,用来声明这是顶点着色器。
第2行,定义了名字为main的函数,对应上文中的entryPoint。
builtin(xx)来对变量进行注解,builtin的意思就是将变量关联到内置参数中(类似GLSL中的gl_xxx),详细参考官方文档。变量名字为VertexIndex,类型为u32,无符号32位整数。builtin(vertex_index) 表示当前顶点的下标位置第3行,定义此函数返回值类型
builtin(position)类似于gl_Position,即计算后顶点的最后位置。类型为vec4<f32>,即四元32位浮点类型。第4行,进入函数体了,这里定义一个名字为pos的数组变量,元素类型为vec<f32>,数组长度为3。
第5-7行分别定义数组成员,也就是三角形三个顶点位置,这里和WebGL一样,坐标取值在[0.0, 1.0]之间。
第9行,根据传入的下标VertexIndex,找到刚才定义数组具体值并返回,之前draw函数指定有3个顶点,这个顶点着色器就会运行3次,就能获取三个不同顶点了。
[[stage(fragment)]]
fn main() -> [[location(0)]] vec4<f32>
return vec4<f32>(1.0, 0.0, 0.0, 1.0);
stage(fragment)来声明这是片元着色器。main函数,因为我们只渲染一个最基本的红色,不需要任何参数。[[location(0)]]表示第一个返回的元素是vec4<f32>类型。这是为了用下标的方式获取定义的任意元素。vec4<f32>类型的元素,其中第1个元素(即R分量)为1.0,即把红色拉满,最后一个元素(即Alpha分量)为1.0,即把不透明度为100%。参考资料:
https://mp.weixin.qq.com/s/4LfaNHP77s9n9SghucYoaA
https://github.com/hjlld/LearningWebGPU
https://gpuweb.github.io/gpuweb/wgsl/#attributes
https://gpuweb.github.io/gpuweb/wgsl/#builtin-variables