2022春节贺岁档电影开分,水门桥不理想,四海崩了!用Python一探究竟
Posted Python小二
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了2022春节贺岁档电影开分,水门桥不理想,四海崩了!用Python一探究竟相关的知识,希望对你有一定的参考价值。
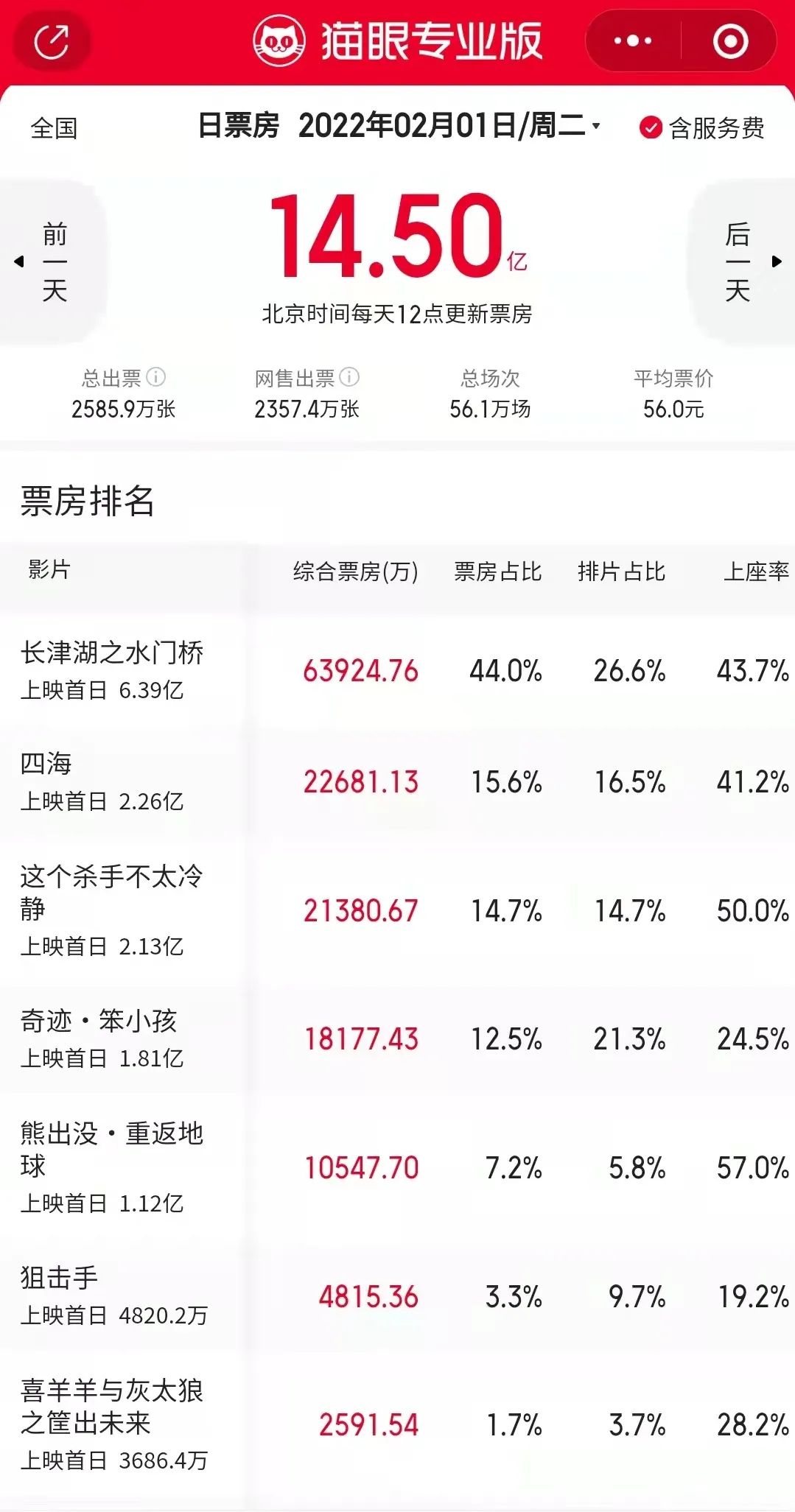
尽管受到疫情影响,部分地区被迫关闭了电影院,但从大年初一中国影史第二单日总票房的数据来看,2022 年春节期间大家的观影热情还是十分高涨的。
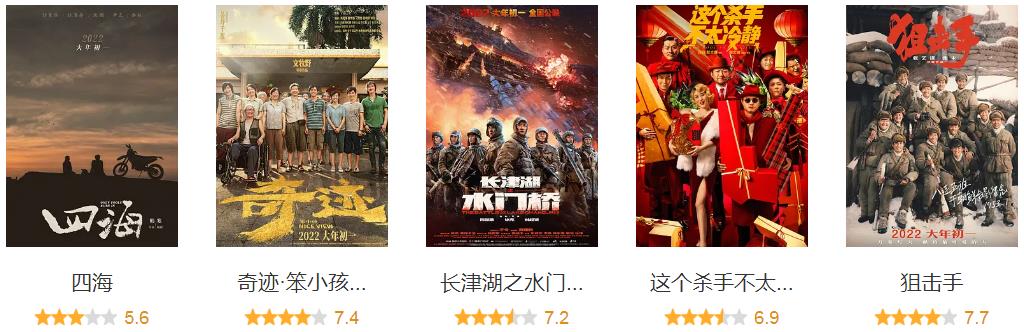
大年初一上映当天,从票房数据来看,《长津湖之水门桥》一马当先,《四海》《这个杀手不太冷静》《奇迹·笨小孩》你追我赶,动画片《熊出没》表现强势,《狙击手》令人遗憾。
目前,几部真人电影豆瓣已经开分了。
本文我们用 Python 爬取这几部豆瓣开分的电影评论,爬取的具体分析过程这里就不说了,不了解的可以参考一下:豆瓣影评爬取参考,主要实现代码如下:
def spider():
url = \'https://accounts.douban.com/j/mobile/login/basic\'
headers = "User-Agent": \'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0)\'
# 龙岭迷窟网址,为了动态翻页,start 后加了格式化数字,短评页面有 20 条数据,每页增加 20 条
url_comment = \'https://movie.douban.com/subject/35215390/comments?start=%d&limit=20&sort=new_score&status=P\'
data =
\'ck\': \'\',
\'name\': \'用户名\',
\'password\': \'密码\',
\'remember\': \'false\',
\'ticket\': \'\'
session = requests.session()
session.post(url=url, headers=headers, data=data)
# 初始化 4 个 list 分别存用户名、评星、时间、评论文字
users = []
stars = []
times = []
content = []
# 抓取 500 条,每页 20 条,这也是豆瓣给的上限
for i in range(0, 500, 20):
# 获取 html
data = session.get(url_comment % i, headers=headers)
# 状态码 200 表是成功
print(\'第\', i, \'页\', \'状态码:\',data.status_code)
# 暂停 0-1 秒时间,防止IP被封
time.sleep(random.random())
# 解析 HTML
selector = etree.HTML(data.text)
# 用 xpath 获取单页所有评论
comments = selector.xpath(\'//div[@]\')
# 遍历所有评论,获取详细信息
for comment in comments:
# 获取用户名
user = comment.xpath(\'.//h3/span[2]/a/text()\')[0]
# 获取评星
star = comment.xpath(\'.//h3/span[2]/span[2]/@class\')[0][7:8]
# 获取时间
date_time = comment.xpath(\'.//h3/span[2]/span[3]/@title\')
# 有的时间为空,需要判断下
if len(date_time) != 0:
date_time = date_time[0]
date_time = date_time[:10]
else:
date_time = None
# 获取评论文字
comment_text = comment.xpath(\'.//p/span/text()\')[0].strip()
# 添加所有信息到列表
users.append(user)
stars.append(star)
times.append(date_time)
content.append(comment_text)
# 用字典包装
comment_dic = \'user\': users, \'star\': stars, \'time\': times, \'comments\': content
# 转换成 DataFrame 格式
comment_df = pd.DataFrame(comment_dic)
# 保存数据
comment_df.to_csv(\'data.csv\')
有了评论数据,我们再通过词云直观的感受一下,主要代码实现如下:
df = pd.read_csv("comment.csv", index_col = 0)
cts_list = df[\'comments\'].values.tolist()
cts_str ="".join([str(i).replace(\'\\n\', \'\').replace(\' \', \'\') for i in cts_list])
stop_words = []
with open(\'stop_words.txt\', \'r\', encoding=\'utf-8\') as f:
lines = f.readlines()
for line in lines:
stop_words.append(line.strip())
# jieba 分词
word_list = jieba.cut(cts_str)
words = []
for word in word_list:
if word not in stop_words:
words.append(word)
cts_str = \',\'.join(words)
print(cts_str)
stylecloud.gen_stylecloud(text=cts_str, max_words=300,
collocations=False,
font_path="SIMLI.TTF",
icon_name="fas fa-arrow-circle-right",
size=800,
output_name="comment.png")
Image(filename="comment.png")
首先我们来看《四海》,《四海》的口碑为什么没有纵横四海?看看观众怎么说的:

接着看《这个杀手不太冷静》,作为一部喜剧片,豆瓣这个评分还算可以,看看观众怎么说的:

再接着看《长津湖之水门桥》,目前评分是低于第一部的,看看观众怎么说的:

再接着看《奇迹·笨小孩》,评分和票房都算是中规中矩,看看观众怎么说的:

再接着看《狙击手》,国师父女指导,票房不佳,评分暂列第一,看看观众怎么说的:

源码已经打包整理好了,有需要的小伙伴可以在公众号Python数据分析之美后台回复m2022直接获取~
Python 学习手册
Pandas 学习大礼包
100+ Python 爬虫项目
Python 数据分析入门手册
100 道 Python 经典练习题
70 个 Python 经典实用练手项目
20张高清数据分析(Python)全知识地图
14 张 Python 速查表玩转数据分析&可视化&机器学习
2018票房破600亿,不再单纯依赖商业片
在2018年的最后关头,中国电影票房终于突破600亿。不过相比2016年的455亿到2017年558亿的涨幅,600亿这个关口比较像是意料之中的事情。但尽管如此,从今年下半年开始,电影票房经历了一次大的动荡,暑期档、国庆档到现在贺岁档的表现,看上去强片如云,但票房上呈现出来的状态则较为疲软。
遥想2014年年末,当时中国电影票房的目标是300亿。本想借由贺岁档上映电影,姜文执导的《一步之遥》突破历史,因为上一部姜文电影《让子弹飞》曾刷新中国电影票房当时的纪录。谁料一语成谶,最终仅差六亿,真的是“一步之遥”。到了2015年,中国电影票房在一中一外两部电影的引领下,突破了438亿。高类型化合家欢电影《捉妖记》,和好莱坞知名IP《速度与激情7》携手共同突破20亿单片票房纪录。2016年,华语票房最高纪录提升到了30亿,2017年到了50亿的高门槛。
这几年的票房情况,2018年的数据为截至12月29日的票房,加上12月30日的票房,全年总票房已超过600亿。图源淘票票专业版
今年虽然没有再创票房纪录的新高,但突破30亿票房的电影有三部,春节档的《红海行动》《唐人街探案2》,暑期档的《我不是药神》。突破20亿票房的电影有两部,春节档的《捉妖记2》,暑期档的《西虹市首富》(剩下一部突破20亿票房的是国外影片《复仇者联盟3:无限战争》)。这五部高票房的电影,虽然都诞生在兵家必争的档期,但是类型各不相同。有较为传统的喜剧,好莱坞式的商业片,也有更为偏向现实主义题材的创作。从某种程度上来说,反映出中国观众整体电影欣赏水平的提高。
年度票房冠军《红海行动》剧照。图源网络
另外一个值得关注的现象是,女导演作品在2018年获得了更多的市场关注。以李芳芳导演的《无问西东》,刘若英导演的《后来的我们》,苏伦导演的《超时空同居》,以及郑芬芬导演的《快把我哥带走》四部电影为代表。《无问西东》在贺岁档上映,是一部偏文艺的影片,获得了7.54亿票房。《后来的我们》在五一档前上映,刷新了华语电影女导演票房纪录,拿下13.61亿票房。《超时空同居》正面迎击《复仇者联盟3》,拿下8.99亿票房。《快把我哥带走》挤进暑期档,以黑马之姿拿下3.75亿票房。相比去年张艾嘉导演的文艺片《相爱相亲》1800万票房,徐静蕾导演的商业片《绑架者》9565万票房来说,女导演群体在市场上开始真正崛起了。
从左至右,分别为《无问西东》导演李芳芳,《后来的我们》导演刘若英,《超时空同居》导演苏伦,以及《快把我哥带走》 导演郑芬芬。图/视觉中国
另外,往年大家抨击的鲜肉流量明星主演烂片获得高票房现象,好像在今年有所缓解。大多数观众更为注重类型的吸引力,导演的手法,以及故事的魅力上,而不是单纯为了看明星而去电影院。中国观众的观影出发点,在根本上有了一定程度的变化。《无名之辈》这样的“无名”导演加“无名”演员的作品可以达到7亿票房,《找到你》这样较为纯粹的女性电影也可以有2亿票房。
当然,部分产业乱象依然存在。例如拿IP借尸还魂的《爱情公寓》,在“虚假广告”的情况下,还有5亿票房。以及号称高投资的《阿修罗》,在院线几日游后,因为票房过低退档。
票房虽然不是万能的,有很多好电影,在市场上没有获得相对应的成绩,但是相较这些电影的投资来说,已经足本。另外一部分电影,票房看上去不够漂亮,但极具讨论度,曲高和寡了一点,也算是有所得。
在新的一年,中国电影可能会更为两极分化。艺术的片子进入市场更多,但是引发的讨论度、票房成绩更为散点式。商业片的类型化也会更为成熟,并成为取得高票房的制胜法宝。
以上是关于2022春节贺岁档电影开分,水门桥不理想,四海崩了!用Python一探究竟的主要内容,如果未能解决你的问题,请参考以下文章