134 python|第七部分:数据库
Posted 缓缓而行
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了134 python|第七部分:数据库相关的知识,希望对你有一定的参考价值。
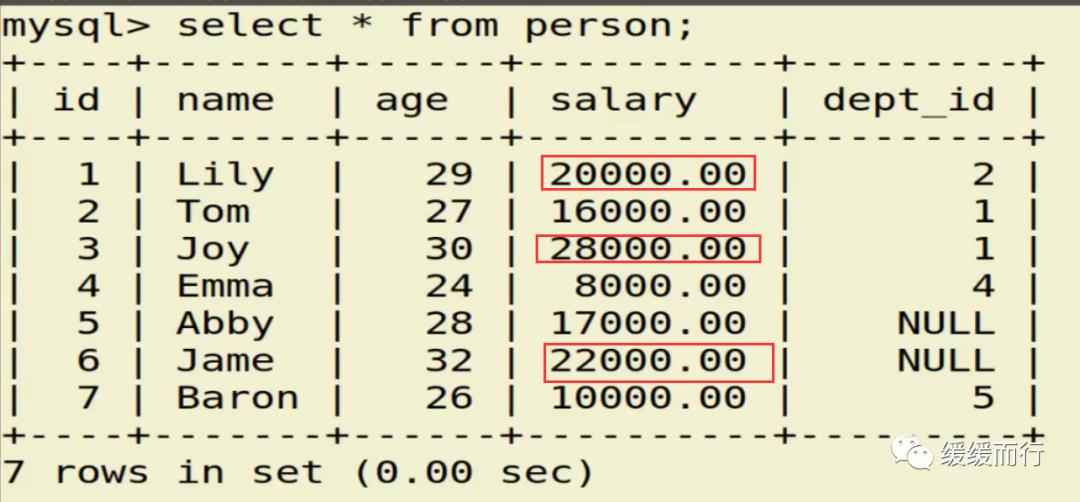
databases; 2.char表示定长字符串,默认存储1个字节,table 表名(字段名 数据类型 约束,...,表名; 注:表的字段约束 UNSIGNED: 设置数字为无符号 NOT NULL: 设置字段不为空。操作数据库时,如果该字段为空,会报错 DEFAULT: 设置一个字段的默认值 COMMENT: 增加字段说明 AUTO_INCREMENT: 定义列为自增的属性,一般用于主键,数值会自动加1 PRIMARY KEY: 定义列为主键,主键的值不能重复,且不能为空database 库名 [character set utf8]; 库名; database(); n 代表字符的个数,而非字节个数 create table 表名; table 表名;
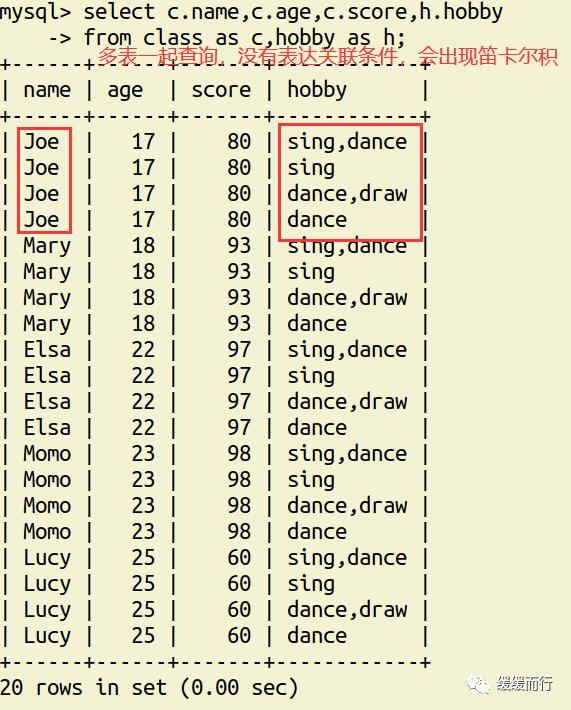
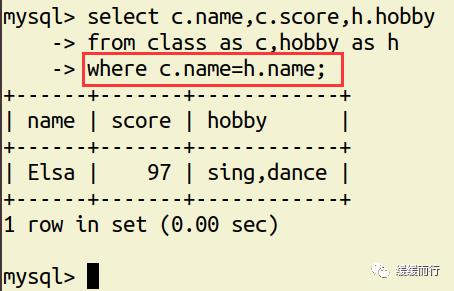
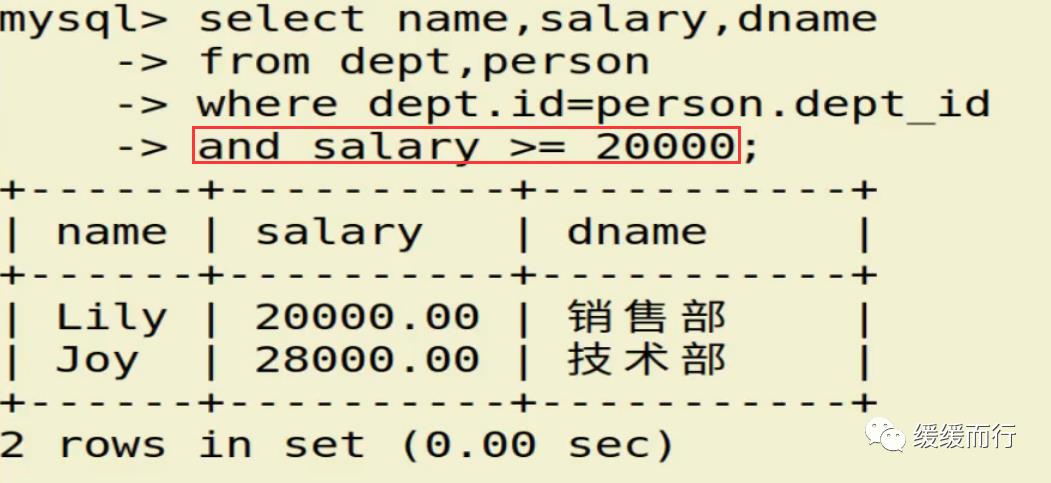
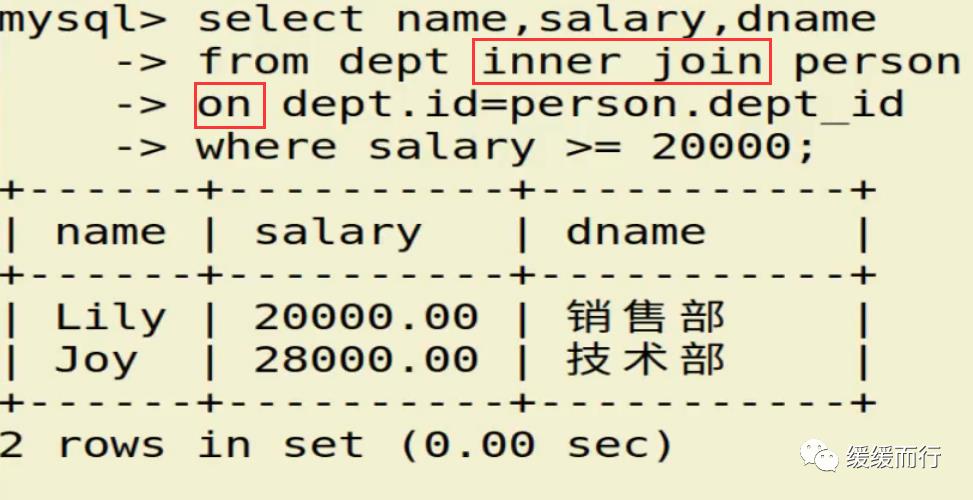
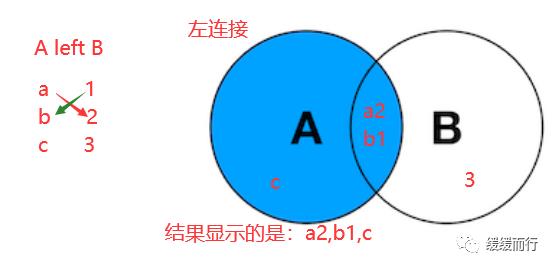
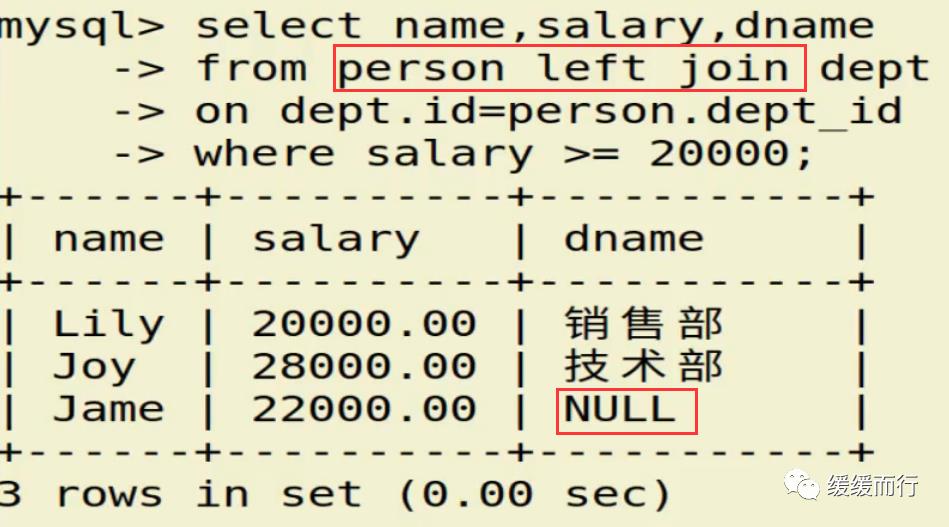
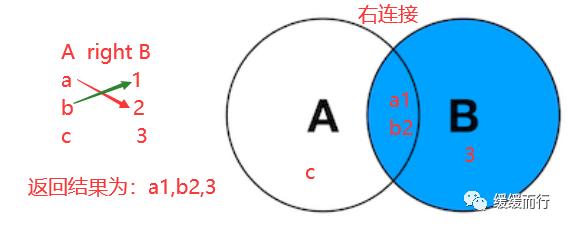
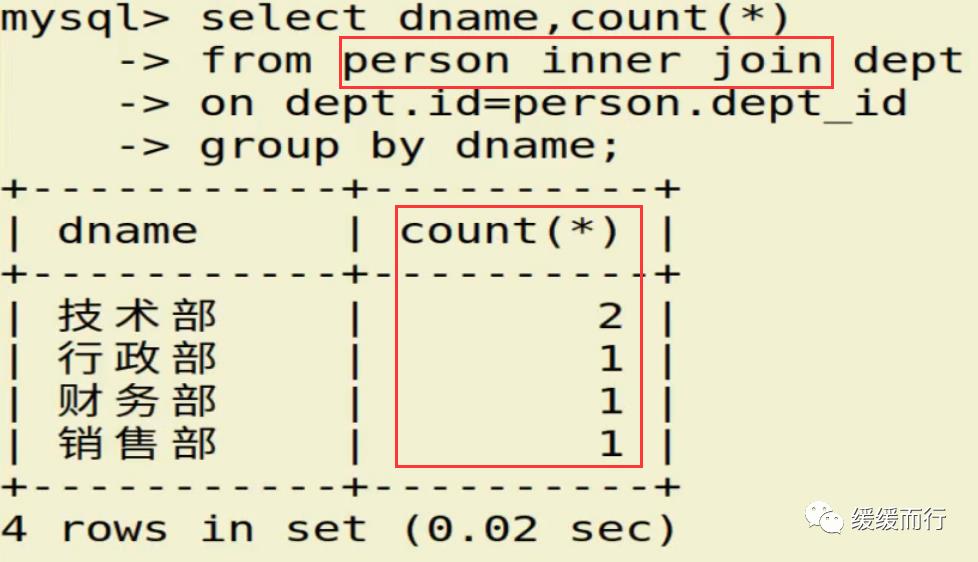
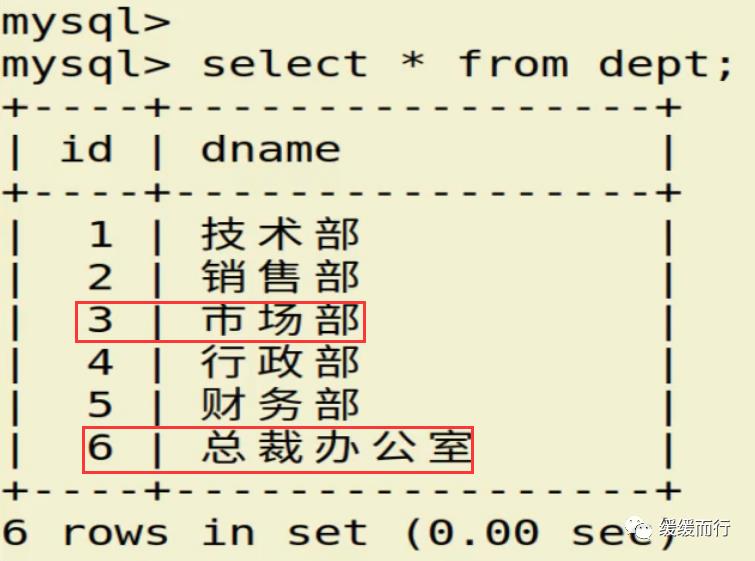
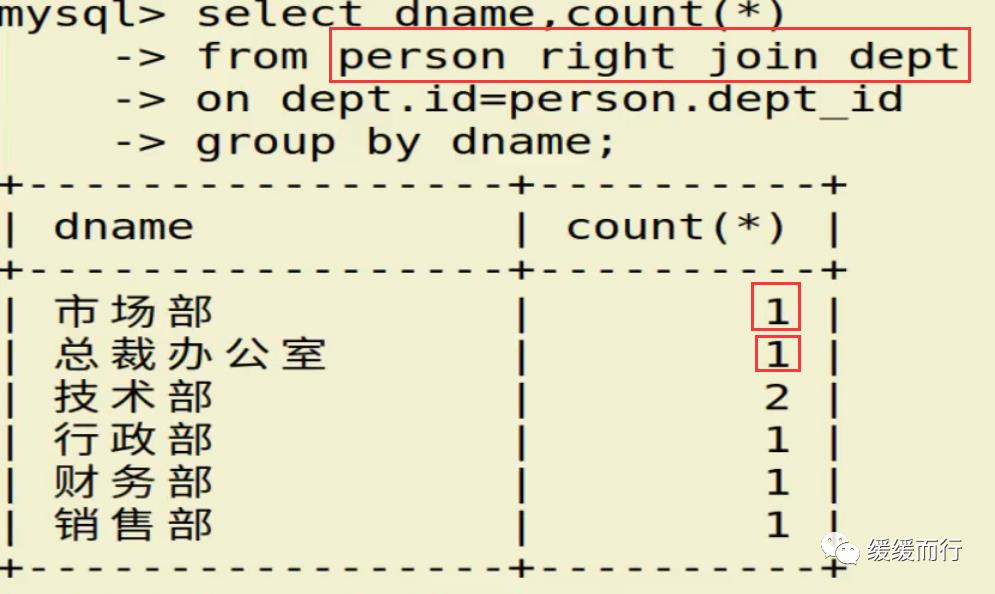
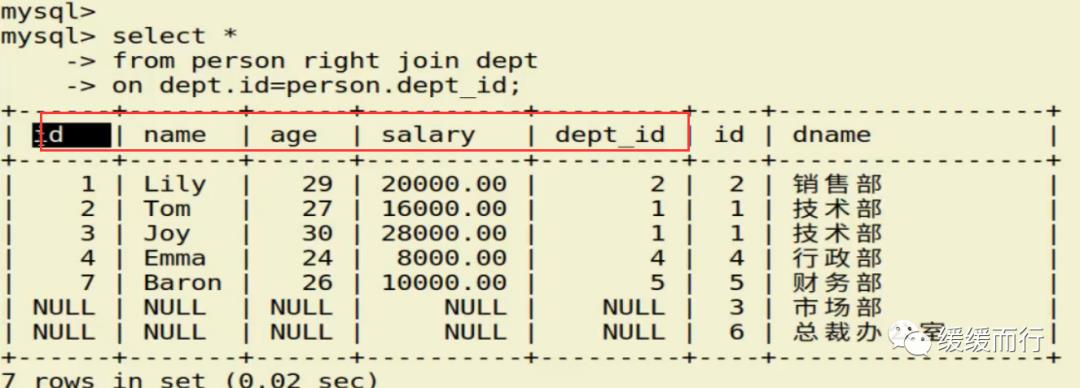
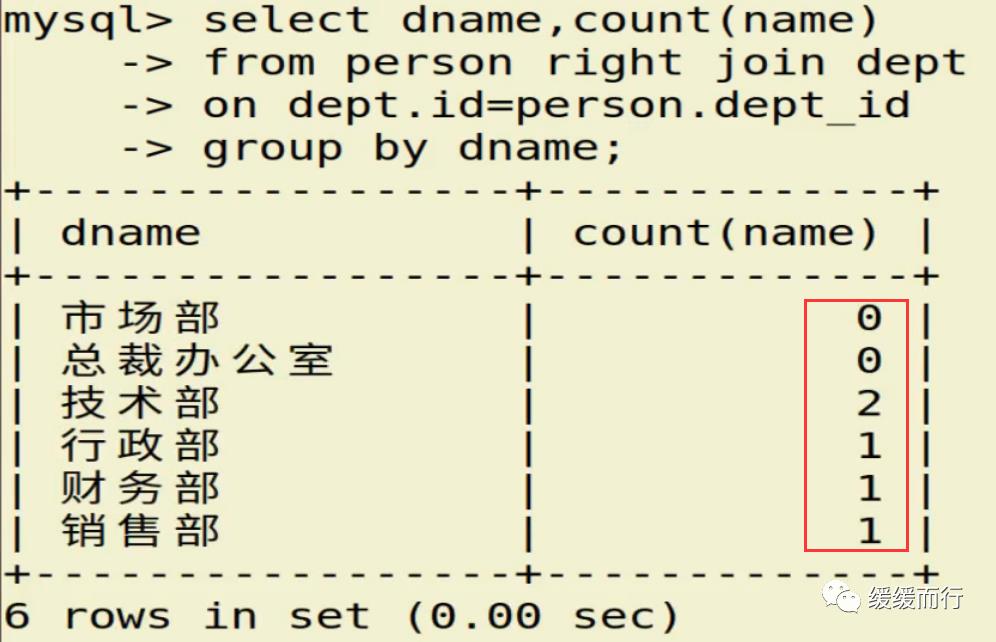
from 表名 where 条件表名 执行动作; alter table 表名 drop 字段名; 缺点 :占用数据库物理存储空间,当对表中数据更新时,索引需要动态维护,降低数据写入效率 注: 1. 通常我们只在tbl_name (主表主键) :数据级联更新 on delete cascade on update cascade 10.3 E-R模型图 01.概念 E-R模型(Entry-Relationship)即 实体-关系数据模型,用于数据库设计。 用简单的图(E-R图)反映了现实世界中存在的事物或数据以及他们之间的关系。 实体 描述客观事物的概念;表示方法 :矩形框 属性 实体具有的某种特性;表示方法 :椭圆形 关系 实体之间的联系;分为一对多关联(1:n) 和多对多关联(m:n) 实例:图书、作家和出版社之间的E-R模型图 10.4 表关联查询 SELECT 字段列表 FROM 表1 INNER JOIN 表2 ON 表1.字段 = 表2.字段; SELECT 字段列表 FROM 表1 LEFT(RIGHT) JOIN 表2 ON 表1.字段 = 表2.字段; 注: 1.尽量把数据量大的表放在前面,作为基准表 2.外连接又分成左连接和右连接 3.A left join B 和 B right join A 两种情况返回的结果是一样的,程序员更习惯用左连接。 查询两张表都有的字段时,如果不注明属于那张表,会报错 注:两张表如果已经建立了外键约束关系,where后表示关联的字段基本上就是外键。没有建立外键约束关系的两张表同样也可以进行多表查询,找到关联字段即可。 多表查询工资大于2w的,查询到的结果和真实情况并不相符 原因在于: 1.表关系和条件筛选都在where中 混乱 2.部分数据信息可能筛选不到(部门设置为NULL的员工工资) 2.内连接 内连接的写法有效解决了简单多表查询存在的第一个问题 3.左连接 在本题中,左连接(要根据实际问题分析,也可能是右连接能够解决,不管是左还是右,都属于外连接)的写法解决了简单多表查询的两个问题,显示了左表的全部和右表中与左表匹配的项。 4.右连接 需求:获取每个部门的人数 通过内连接的方式来做会发现如果某个部门人数为0 ,这个部门是不会显示的 3和6并没有显示出来 试试右连接能不能把所有部门显示出来,发现虽然显示了,但是计数出现了问题,这两个部门人数实际为0,显示却是1 问题出来count(*)上,括号内填*表示的是统计所有记录的数量,这题可以把*改成其他字段,比如name等其他字段 现在的显示是没问题的 下期预告:数据库(下) 参考资料 花样早餐展位 使用: = 3.在终端查看存储记录 花样早餐 以上是关于134 python|第七部分:数据库的主要内容,如果未能解决你的问题,请参考以下文章添加字段 修改数据类型 alter table 表名 字段名 新数据类型; 修改字段名 alter table 表名change 旧字段名 新字段名 新数据类型; 日期时间函数 column_name;[ conditions ]
ORDER BY column1, column2column1, column2,.....columnN
FROM table_name
WHERE [condition]不显示字段重复值 注::加快数据检索速度,提高查找效率 dept( primary auto_increment,person(primary auto_increment,person (PRIMARY AUTO_INCREMENT,dept_fk dept(person dept_fkdept(athlete(primary auto_increment,item(primary auto_increment,athlete_item(primary auto_increment,athlete(item(athlete_item ranking tinyint;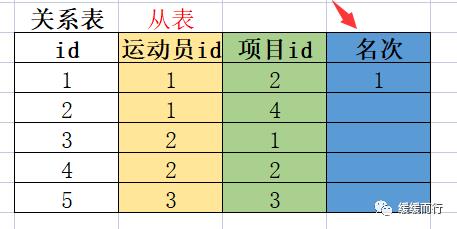


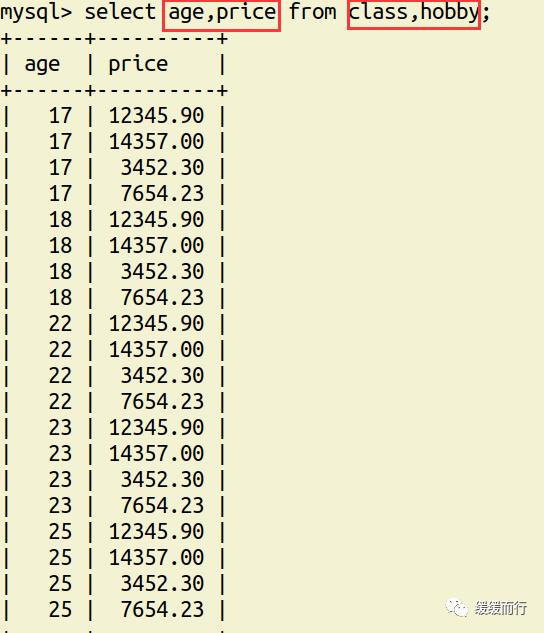
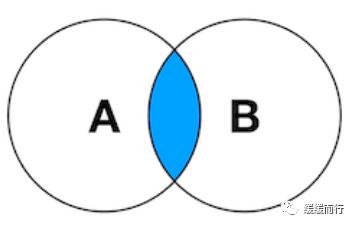
表关联查询 类型 语法 简单多表查询 select 字段1,字段2... from 表1,表2... [where 条件] 多表数据联合查询 内连接 只会查到符合条件的记录,结果和表关联查询一样,官方更推荐内连接查询 左(右)连接 左连接:左表全部显示,显示右表中与左表匹配的项。右连接相反 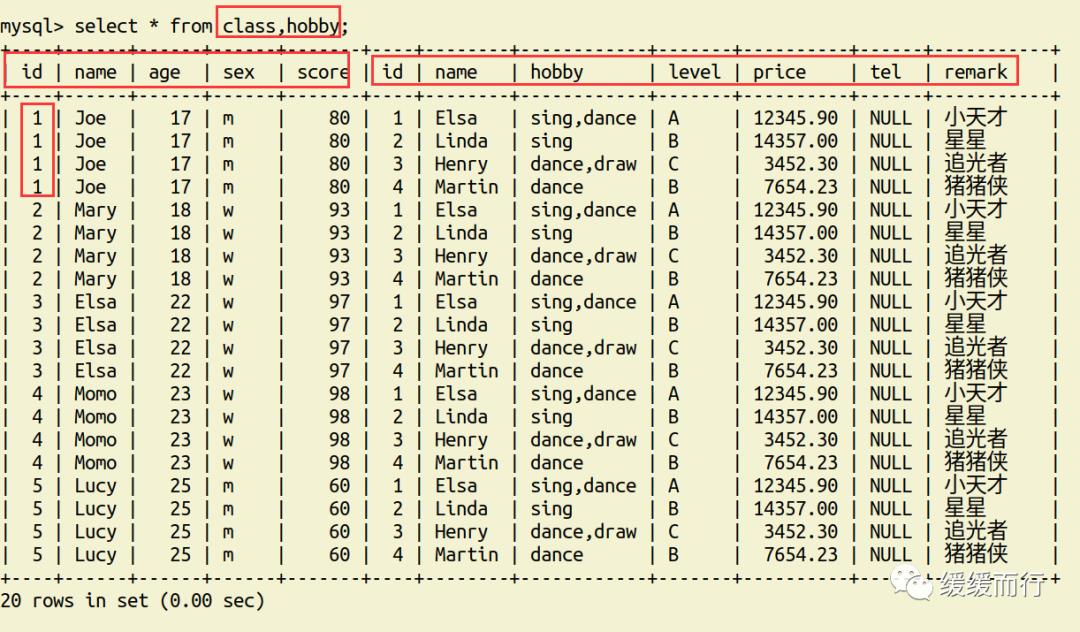



135 python|第七部分:数据库
"host": "localhost", "port": 3306, "user": "root", "password": "123456", "database": "dict", "charset": "utf8"= = = = #用正则表达式获取( += ( data = [] fr = open( line data += re.findall( fr.close() data data = sql= __name_== dict = Dict() dict.insert_words() dict.close() print(row) data = fr.read() fw.write(image)cur.close()db.close()