探秘前端 CRDT 实时协作库 Yjs 工程实现
Posted 前端瓶子君
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了探秘前端 CRDT 实时协作库 Yjs 工程实现相关的知识,希望对你有一定的参考价值。
基础库为前端应用带来了奇妙的可能性:只需要一个 API 与 backbone 几乎一样简单的 model 层,你的应用就能自然地获得对多人协作场景下并发更新的支持。这背后隐藏着怎样的黑魔法呢?本文希望以当下代表前端 CRDT 库性能巅峰的 为例,向大家直观地展示 how CRDT works。
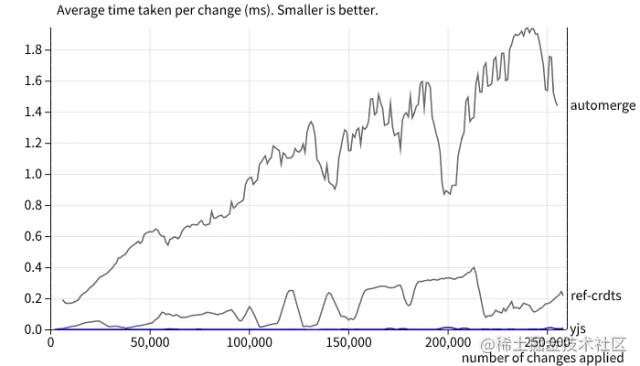 (图为 Yjs 和其他前端主流 CRDT 库的性能对比,Yjs 对应底部的蓝线)
(图为 Yjs 和其他前端主流 CRDT 库的性能对比,Yjs 对应底部的蓝线)
本文会从 Yjs 的工程实现出发,介绍一个典型的工业级 CRDT 库是如何实现以下能力的:
作为一份科普性的介绍,本文不会动辄甩出大段晦涩的源码,也不会涉及多少抽象的数学知识。阅读时只需了解数据结构方面的计算机基础即可。
在实际介绍 Yjs 内部概念前,我们该如何直观地了解 CRDT 库的使用方式呢?Yjs 对使用者提供了如 和 等常用数据类型(即所谓的 会被序列化编码后分发,而基于 CRDT 算法的保证,只要每个客户端最终都能接收到全部的 item,那么不论客户端以何种顺序接收到这些 item,它们都能重建出完全一致的文档状态。
基于上述手段实现的 CRDT 结构是 CRDT 流派中的一种,可以将其称为 的逻辑时间戳,可以认为这就是个从零开始递增的计数器。它的更新规则非常简单:
发生本地事件时, localClock += 1。在接收到远程事件时, localClock = max(remoteClock, localClock) + 1。这种机制看似简单,但实际上使我们获得了数学上性质良好的全序结构。这意味着只要再配合比较 clientID 的大小,即可令任意两个 item 之间均可对比获得逻辑上的先后关系,这对保证 CRDT 算法的正确性相当重要。但相关数学理论并非本文重点,在此不再展开。
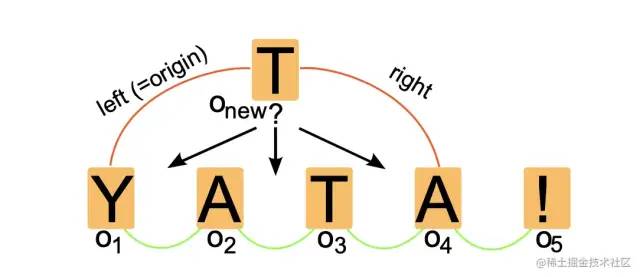
我们可以借助文本编辑的例子来理解这种 list CRDT 的工作方式。在未经任何优化的朴素情况下,这种结构要求我们把每个字符插入操作都建模为一个 item,也就是每个字符都携带了一个逻辑时间戳 ID:
88BF2B75-CA88-4B67-86B6-F6E390C1C370.png 在上面的例子中,
Y A T A !这几个字符每个都对应一个 item(或者说一次字符插入的 operation)。它们通过left和right字段连接在一起。在插入新字符T的时候,Yjs 就会根据 item 的 ID 在链表中查找合适的插入位置,将新字符对应的 item 接入链表中。另外同个用户持续追加的文字也会被合并成length很长的单个 item,避免大量碎片化对象的性能问题。注意,在文档的高频增删过程中,并不是所有 item 都会持续存在于链表中。但由于 CRDT 的冲突解决需要依赖历史 item 的元数据,我们并不能直接将历史上的 item 硬删除,至多只能移除掉该 item 对应的 YModel 内容(为此 Yjs 特别设计了 对象来将废弃的 YModel 替换为空结构,相当于一种墓碑机制)。这就带来了下一个问题:该使用怎样的数据结构来存储文档内所有的 item 呢?
由于任意 item 均可用 ID 来排序,因此一种选择是使用 B 树这样具备对数级优良插入和删除时间复杂度的数据结构,将所有的 item 维护在一棵平衡二叉树中。但实践中 Yjs 选择了一种更简单直接的方案,即为每个 client 分配一个扁平的 item 数组,相应的结构被称为 /
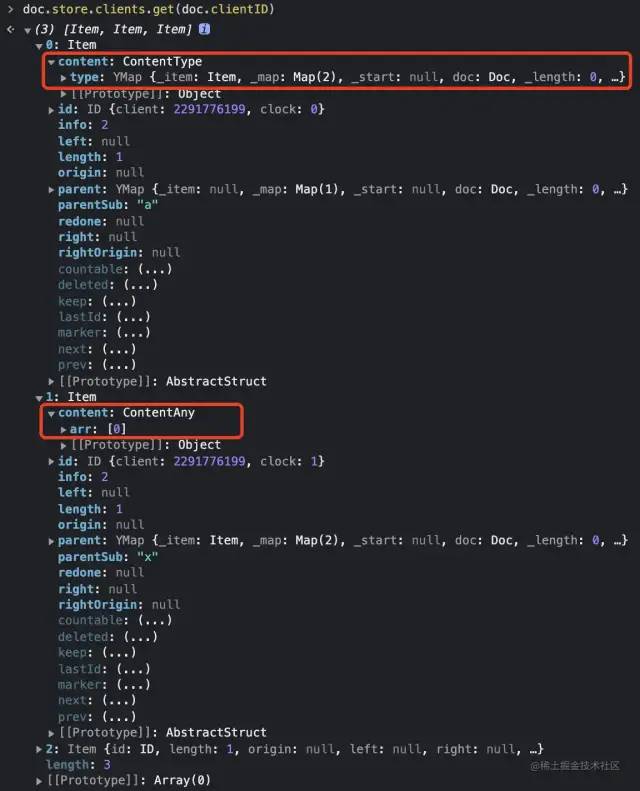
right/ID等 CRDT 字段的容器,其中具体的 YModel(或者说 AbstractType)数据会存储在item.content字段中,另外还有parent和parentSub字段会用于辅助表达 YMap 等嵌套结构的父子关系。其整体结构如下所示:ACC56D75-80BD-4D22-9967-C9E27834844B.png 由于
item.content也能携带任意的 YMap 等 AbstractType 数据,这样就自然地支持了数据的嵌套。基于这种链式结构,此时一份 YMap 就对应于一系列的 entry,其中每个 key 都使用逻辑时间轴上最新的数据为当前状态,而这个 key 下其他更早的状态所对应的 item 都会被标记为删除。为了优化本地插入的速度,Yjs 还设计了额外的缓存机制。如果在文档中任意位置随机插入新字符,这时新字符对应的 item 理论上需要 O(N) 的时间复杂度才能插入链表中。但实际上,大多数插入操作都会跟随在用户最后编辑的光标位置。因此 Yjs 默认会缓存 10 个最近的插入位置供快速匹配,在内部实现中这被称为 skip list(作者认为这一缓存机制是受到了跳表的启发)或 fast search marker。
在熟悉了基本的数据结构设计后,我们就可以进一步理解 Yjs 所设计的冲突解决机制了。
和right字段,还有这两个字段:origin字段存储 item 在插入时的左侧节点。rightOrigin字段存储 item 在插入时的右侧节点。每个 item 在插入文档时都需要执行其
integrate方法,核心的冲突解决算法就在这里用到了上述这些字段,一共仅有约 20 行:来提供开箱即用的历史记录管理功能。在个人之前的知乎回答中,的 getter 来检查),但 item 中并没有记录关于删除操作的更多信息:在 item 中不会记录它时何时被删除,或是被哪个用户删除了。 在 StructStore 中也不会记录删除操作。 在删除发生后,本地的 clock 不会递增。 那么,删除操作的信息是在哪里建模的呢?Yjs 引入了 的概念,可以记录逻辑时间轴上某段时间内(或者说某次 transaction 中)所有被删除的 item,这份数据也会独立于 item 分发。换句话说,Yjs 中的删除操作被设计成了独立于双向链表的结构。在前面关于 item 双向链表的介绍中,我们讨论的还是一个 operation-based CRDT。但在处理删除操作时,Yjs 的设计则相当于一种更简单的 的概念,这是 Yjs 中用于构建事件系统的抽象。每次更新对应的 transaction 都包括两份数据:
这次更新所插入的 item。 这次更新所删除 item 的 DeleteSet。 在网络上实际分发的二进制增量更新数据,就是序列化编码后的 transaction。可以认为 transaction 既会用于编码更新,也是撤销重做操作对应的粒度。基于上述数据结构,可以发现只要做两件事就可以撤销掉一次 transaction:
将这次 transaction 所插入的 item 标记为删除。 将这次更新所删除的 item 标记为恢复。 由于这个过程并不需要新增新的 item,因此这样一来,连续的撤销重做操作在理论上就相当于只需持续分发轻量级 DeleteSet 即可。由于 DeleteSet 的结构非常轻(例如在记录了真实用户 LaTeX 论文编辑过程的 benchmark 数据集中,18.2 万次插入和 7.7 万次删除后仅生成了 4.5KB 的 DeleteSet),这种设计就进一步贴近了「零开销抽象」,因为撤销重做时并没有创造出任何未知的新数据。
不过,个人认为这种设计虽然能起到更极致的优化效果,但也让维护变得更加困难了。如 UndoManager 之前一个难以修复的问题就是「连续撤销 3 次内可重做返回原始状态,4 次以上则可能丢失字段」。这一问题的根源在于当时的实现对 item 复原的逻辑有问题,可能无法连续右移找到应被恢复的正确 item 位置。虽然针对该问题个人已经提交修复 的 tuple。
在同步文档状态时,Yjs 划分了两个阶段:
阶段一:某个客户端可以发送自己本地的 state vector,向远程客户端获取缺失的文档 update 数据。 阶段二:远程客户端可以使用各自的本地 clock 计算出该客户端所需的 item 对象,并进一步编码生成包含了所有未同步状态的最小 update 数据。 理论上,我们可以为 Yjs 配套支持 WebSocket 之外的更多网络协议,当前 Yjs 也已经支持了 这样面向分布式 Web 的新协议。但与网络协议相关的内容并不在 Yjs 主仓库中,可以参见 项目。
论文介绍了 Yjs 的算法设计与正确性证明。记录了 Yjs 的关键内部结构,其中很多内容对本文有帮助。 由 Yjs 作者 Kevin Jahns 介绍了他实现的若干关键优化。 是 OT 库 ShareDB 作者 Seph Gentle 撰写的博文,深度剖析了 CRDT 工程性能改进的历程。 是 Seph 为了解 Yjs 而邀请 Kevin 做的视频访谈,虽然很长但相当有启发。 个人的 分享介绍了 Yjs 的项目接入实践。 由于 Yjs 背后 CRDT 极佳的去中心化性质,它在 Web 3.0 时代或许有机会成为某种形式的前端基础设施。从它的案例中我们可以感受到,学术研究成果的实用化并非一蹴而就,更有赖于大量具体的工程细节处理与针对性优化,这背后仍然绕不开基础的数据结构和算法等计算机基础知识。并且相对于经典的 OT,近年来 CRDT 的流行或许也属于一次潜在的范式转移(paradigm shift),这对前端开发者们意味着全新的机遇。希望本文对感兴趣的同学能有所帮助。
关于本文
来源:doodlewind
https://juejin.cn/post/7049148428609126414
最后欢迎关注【前端瓶子君】✿✿ヽ(°▽°)ノ✿ 回复「算法」,加入前端编程源码算法群,每日一道面试题(工作日),第二天瓶子君都会很认真的解答哟! 回复「交流」,吹吹水、聊聊技术、吐吐槽! 回复「阅读」,每日刷刷高质量好文! 如果这篇文章对你有帮助,「在看」是最大的支持 》》面试官也在看的算法资料《《 “在看和转发”就是最大的支持 前端协作流程
前面的话
在拿到交互原型或视觉稿以后,前端工程师要能够灵活应用前端知识技能,完成相应的功能。在实际的企业环境中,不只是有前端工程师,更多的场景和项目是通过团队多人协作完成的。作为前端工程师如何与团队中其他角色进行协作呢?本文将详细介绍前端工程师协作流程
Web系统
在介绍协作流程之前,首先简单地了解Web系统的结构
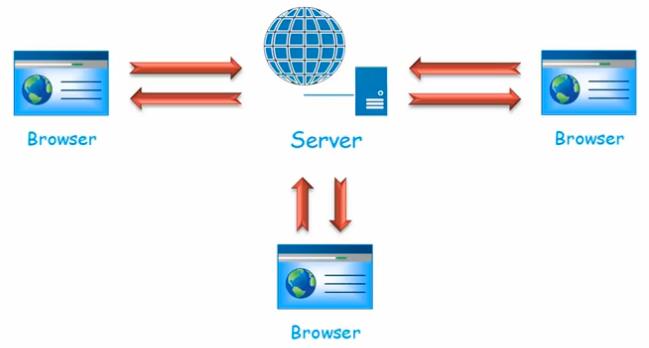
从宏观上来说,Web系统是部署在服务器上用于为web客户端提供服务的系统。不同的Web客户端根据不同的需求,发送请求到服务器上部署的Web系统上。Web系统根据需求,返回相应的结果,最后,通过Web客户端展示给用户
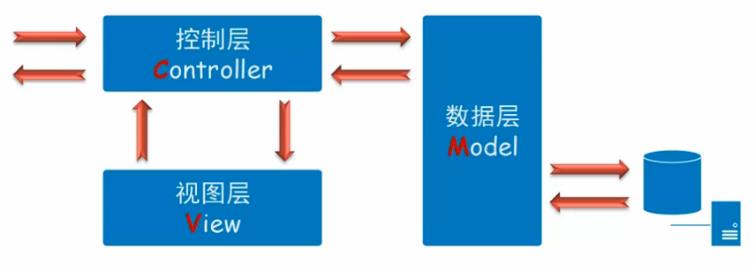
Web系统在服务器上的组织结构一般为MVC架构,MVC分别代表数据层、视图层和控制层
数据层(Model):封装数据管理操作(如数据的CRUD)
视图层(View):展示数据模型,提供人机交互
控制层(Controller):处理用户请求,委托数据层进行数据相关操作,并选择合适的视图层返回给用户
当Web客户端向服务器发起请求时,服务器的Web系统要做如下处理
1、客户端发送请求,服务器Web系统的控制层接受到请求,并进行解析
2、控制层请求数据层进行数据的相关操作
3、数据层根据需求筛选出相关的数据模型,并返回给控制层
4、控制层将收集的数据模型转交给合适的视图层进行模板整合
5、视图层将数据模型和模板整合之后生成页面代码,返回给控制层
6、控制层将结果返回给Web客户端进行展示
在Web系统的各个分层结构中,与前端密切相关的是视图层。接下来,从技术栈角度,来介绍视图层的内容
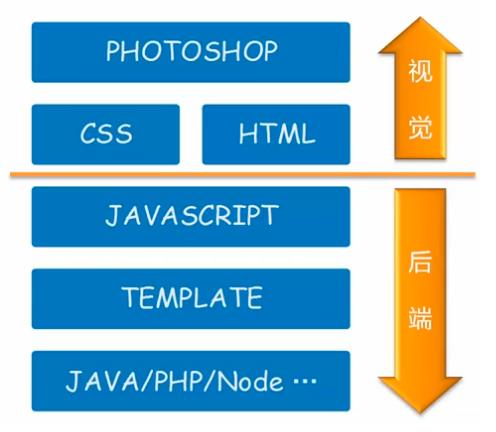
下面是用于完成视图层需要掌握的知识技能图,每个知识技能都具备了完成视图层某一部分的能力
photoshop:切图 html+css:页面制作 javascript:前端交互逻辑 template:结构与数据分离和整合 java/php/Node:后端业务逻辑前端工程师职位出现之前,是一个美工的职位,需要使用photoshop、html和CSS来进行切图和页面制作
随着ajax的出现,产品的用户体验有了更高的要求,web系统也变得越来越复杂,这种协作方式的弊端就越来越明显
首先,从工作方式来看,美工输出的静态页面交给后端之后,转换成模板。这样,一个相同的内容以两种不同的形式存在,并且由两个技能差距较大的角色维护,这样就为复杂系统的后期维护带来了隐患
其次,为了提升用户的体验,系统的人机交互变得越来越复杂。因此,前端所需的专业化技能也越来越高,这时再由后端来兼做前端的工作显然已经无法满足需求
最后,Web产品的一个重要特性就是更新非常快。因此,需要分工协作方式快速响应需求的变更。而在这种分工模式下,一个需求必须由视觉和后端共同来完成,很大程序降低了需求的响应速度
因此,在整个技术环境的推动和项目实际需求的驱动下,前端工程师的职位就出现了。有了前端工程师之后,分工模式发生了变化
视觉工程师完成视觉稿,输出视觉稿给前端;后端工程师完成后端的主要业务逻辑,给前端提供数据和接口;剩下的工作都由前端工程师来完成,包括切图、页面制作、前端交互逻辑、模板转换等工作
在这种模式下,各个角色输出的内容完整,且相互独立,互相之间没有耦合性,各个角色专注的也是自己领域内的技能,产品的各个部分都可以做到极致,也更容易产出高质量的产品
随着Web技术的进一步发展,如Nodejs的出现,使得javascript脚本也可以运行在服务器上。既然控制层是为视图层服务的,控制层的业务逻辑很大程度也取决于视图层的交互需求。这样,控制层也可以由前端工程师来负责。这样的话,前端也会涉及到部分后端相关的业务逻辑
这样使前端工程师可以在后期转换成全栈工程师(Fullstack Developer)。当然,这种分工模式还处于探索实践的阶段
角色定义
由前面的Web系统得知,完成一个Web系统,至少需要三种角色的相互协作:视觉工程师、前端工程师、后端工程师
视觉工程师需要精通视觉相关的技术,主要负责交互原型到视觉稿的转化
前端工程师需要精通Web开发技术,主要负责系统前端交互逻辑
后端工程师需要精通后端开发技术,主要负责系统后端业务逻辑,为前端提供数据和接口服务的支持
作为前端工程师需要完成系统前端交互逻辑,需要具备PHOTOSHOP、HTML、CSS、JAVASCRIPT、TEMPLATE、Node等技能
如果每个技能都进行深入研究,需要大量的精力和相关的经验。考虑到不同角色的协作效率,前端部分根据其偏重方向的差异再做切分
前端又可再细分为页面工程师和前端工程师。前者偏重于视觉稿的还原和页面的制作,更注重和视觉工程师的协作;后者则偏重于前端交互逻辑的实现,更多的与后端工程师进行协作
页面工程师技能要求如下
精通切图技术 (Photoshop) 精通页面制作 (CSS,HTML) 熟悉前端开发技术 (JavaScript,Template) 了解后端开发技术 (Java,Node...)前端工程师技能要求如下
精通页面制作 (CSS,HTML) 精通前端开发技术 (JavaScript,Template) 熟悉切图技术 (Photoshop) 熟悉后端开发技术 (Java,Node...)【项目开发时间】
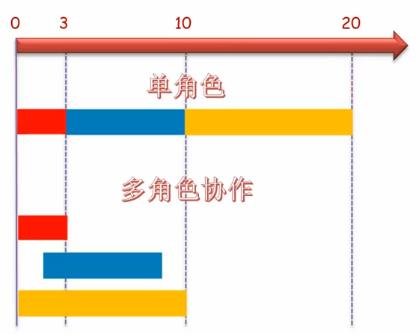
以一个单角色开发一个项目的时间为20天为例,则各个角色时间分工可能如下所示
页面制作:15%(3天) 前端逻辑:35%(7天) 后端逻辑:50%(20天)而如果采用多角色开发,页面开始制作时,后端工程师可以开始梳理后端的业务逻辑。当页面有输出时,前端工程师可以开始进行前端的业务逻辑。整个项目大概缩短了50%的开发时间
采用多角色开发,大大提高了项目的开发效率。要注意的是,多角色开发会比单人开发增加了沟通成本。这时,就需要按照一定的协作流程来减少沟通成本
协作流程
按照一定的流程和规范可以明确各个角色和其对应的职责,以及结果输出的时间,这样可以大大减少角色间的沟通成本
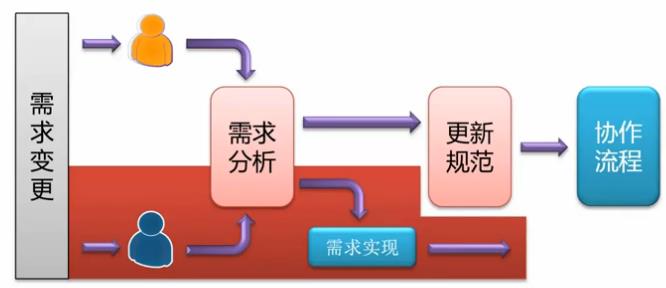
Web系统至少需要视觉工程师、前端工程师、后端工程师这三个角色的分工协作。当得到交互原型和视觉稿时,首先,前端工程师和后端工程师进行沟通,确定页面入口规范、同步数据规范和异步接口规范。而与此同时,页面工程师根据视觉稿进行相关的页面制作;接下来,前端工程师和后端工程师并行开发。后端工程师根据同步数据规范实现一些配置、控制层相关的业务逻辑,根据异步接口规范,实现接口服务。前端工程师根据页面入口规范和同步数据规范实现系统架构,当页面工程师有页面输出时,实现模板层的业务逻辑,根据异步接口规范进行具体的一些业务逻辑的实现;当前后端功能开发完成之后,进行联调操作;最后测试并上线
根据上面的说明,有3个规范的输出,包括页面入口规范、同步数据规范和异步接口规范
页面入口规范定义系统对外可访问入口和配置信息
同步数据规范定义系统对模板文件的预填数据信息
异步接口规范定义前后端异步数据交互的接口信息
【维护流程】
项目除了需要前期的开发之外,还需要后期的维护。在维护的过程中,需要遵循以下流程
当得到需求变更后,前、后端工程师都要进行需求分析,如果该需求仅仅需要前端的简单实现,则前端工程师进行需求实现;如果需求涉及到规范上的改动,就需要更新规范,然后遵循协作流程,来完成项目的需求变更
项目进行稳定期后,大部分需求变更都仅仅需要前端工程师的需求实现。所以,可以快速的响应需求变更
职责说明
下面总结各个角色的职责和具体任务
【页面工程师职责】
1、切图、图片优化
2、规范页面格式、保证页面质量、处理浏览器兼容性问题,以及各个端的页面呈现
3、页面制作、优化页面效果与结构
4、具备一定的业务逻辑的相关技能,使其输出的效果和结构更加适合前端工程师做业务逻辑开发
5、完成简单的前端业务逻辑开发,比如广告页、活动专题页等。针对包含大量的页面制作以及少量的页面特效的这类项目,页面工程师就可以直接完成
【前端工程师职责】
1、主导制定前、后端分离规范,输出三个核心规范,包括页面入口规范、同步数据规范和异步接口规范
2、主导前、后端联调对接测试
3、系统前端设计架构、满足一定的非功能性需求,包括性能、可扩展性等
4、完成系统前端的业务逻辑实现、优化实现逻辑
【后端工程师职责】
1、协助定制前后端分离规范
2、协作前后端联调对接测试
3、完成后端系统架构及业务逻辑实现
角色与人的关系?
角色与人之间不一定需要一一对应,前端工程师和页面工程师可能是同一个人,全栈工程师则有能力包揽一切
以上是关于探秘前端 CRDT 实时协作库 Yjs 工程实现的主要内容,如果未能解决你的问题,请参考以下文章