从零打造 Instagram Posted 2022-01-27 DeepNoMind
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从零打造 Instagram相关的知识,希望对你有一定的参考价值。
Instagram是全球最大的照片、视频分享社区,如果让我们自己设计一个Instagram这样的服务,应该怎么做呢?这篇文章解析了Instagram的功能和架构,从中我们可以看到设计一个内容分享服务所需要关注的部分。原文:Instagram System Architecture[1]
Instagram是一个免费的照片和视频分享社交网络,有很多人每天在上面分享故事,记录生活中的点点滴滴。
功能性需求 用户可以上传照片和视频
用户可以查看照片和视频
用户可以根据照片标题进行搜索
用户可以关注/取消关注其他用户
用户可以通过搜索栏搜索用户id
为关注的每个用户创建信息流
可以把照片存档
可以通过聊天窗口分享故事
可以拉黑/限制其他用户
可以在其他用户的帖子下面点赞和评论
用户可以发帖
非功能性需求 高可扩展性
高一致性
高可用性
高可靠性
用户数据应该是持久化的(任何上传的照片都不应该丢失)
生成信息流的最大延迟是150毫秒
接下来我们做一下系统容量估算 。
假设注册用户 = 5亿
30%的活跃用户 = 1.5亿
注册名人人数 = 10k
读请求数 = 100 *上传(写)请求数
高峰时刻,假设平均流量 = X,目标处理上限是6X
活跃用户:
每周发帖3次,每个帖子包含1 MB的图片和文本
每个帖子至少收到10个赞和2-3条评论
关注100个用户,有50个粉丝
每天刷新2次信息流
名人:
每周发帖2次,每个帖子包含大于500K的图片和文本
每个帖子至少收到50K个赞和至少1K条评论
拥有500万粉丝
每天刷新2次信息流
每秒请求数(QPS):
发帖
Create_post_avg = (150 Million + 10 K) * 2 / (724 60*60) = 496/s
Create_post_peak = 496/s*6 = 3k/s
点赞
like_post_avg = (150 million10 +10K 50K) * 2 / (724 60*60) = 6.6 k/s
like_post_peak = 6.6 k/s*6 = 40 k/s
评论
comment_post_avg = (150 million * 2 + 10K * 1K) = 1k/s
Comment_post_peak = 1k/s * 6 = 6k/s
关注信息流
get_follow_feed_avg = (150 million + 10K) * 2 / (2460 60) = 3.5k/s
get_follow_feed_peak = 3.5k/s * 6 = 21.8 k/s
数据量
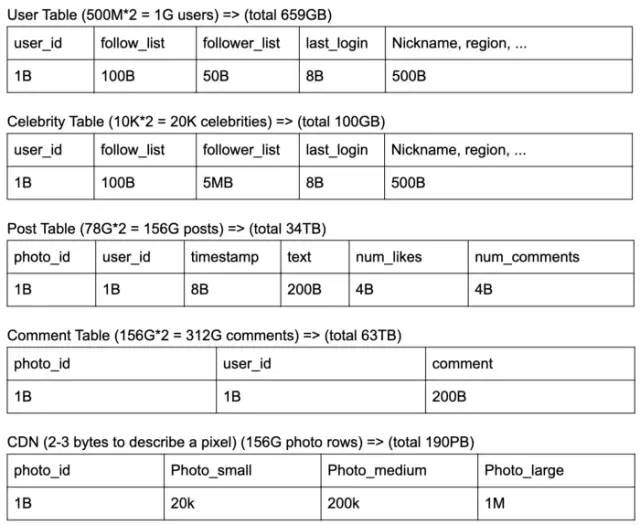
64base([‘a-z’,‘A-Z’,‘0–9’,‘-’,‘_’])编码的user_id,需要5 bits ~ 1Byte
500 Million + 10K * 5 bits ~ 1 Byte = 1G user
容量估计:
每天上传的活跃用户 = 100万
每天上传的照片 = 500万张
每天每秒上传的照片 = 57张照片
平均照片大小 = 150 KB
每天存储开销 = 500万* 150KB = 716GB
数据保存10年,所需存储容量为716 GB * 365 * 10年 = 2553 TB ≈ 2.6 PB
日活跃用户查看 = 1000万
每小时的信息流产生量为1000万,即2800 RPS(每秒请求数)。
如果用户每天搜索一次,那就是每天1000万次搜索,也就是115个RPS。
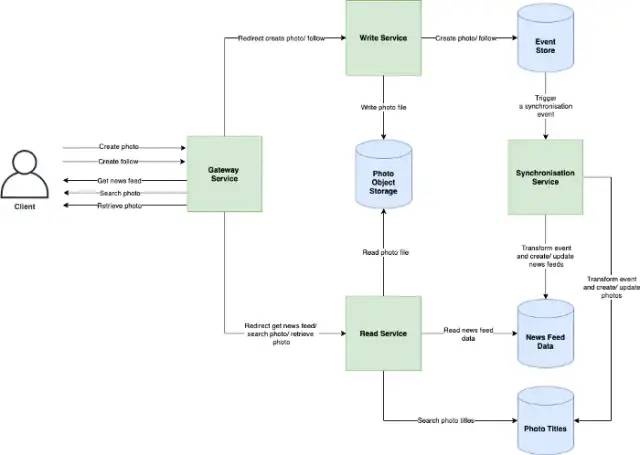
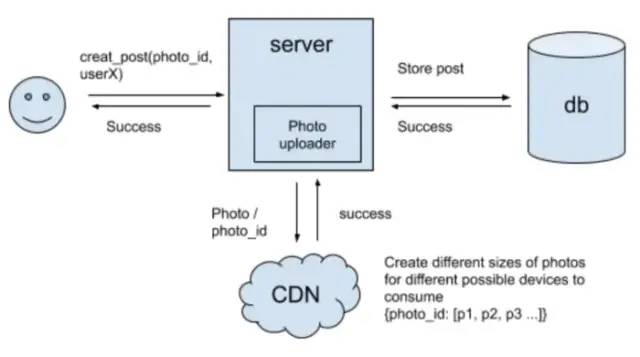
系统组件设计 上传照片和视频 = 写操作
查看照片和视频 = 读操作
读写比 = 20:80
Web服务器可以同时支持1000个活动连接
200个连接会被写操作占用,写入(上传)会使连接长时间保持打开状态
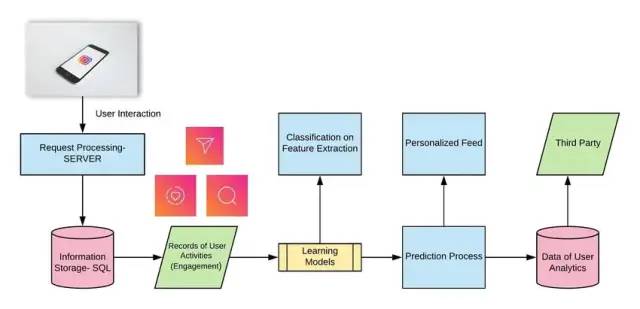
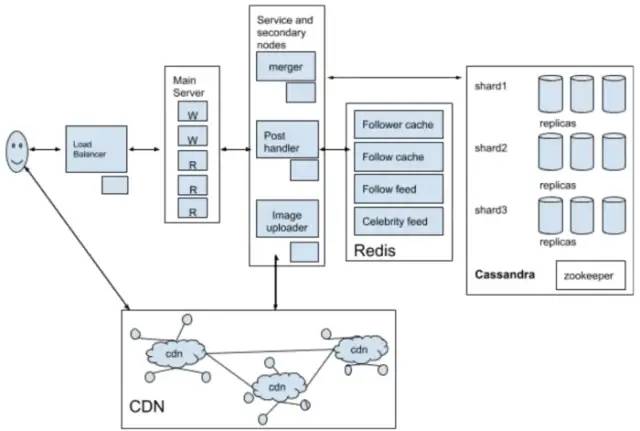
因此,更好的方法是用2个数据库分别处理读写操作。此外,分离照片的读写请求可以帮助我们独立的扩展和优化每个过程。下图显示了读写的过程。
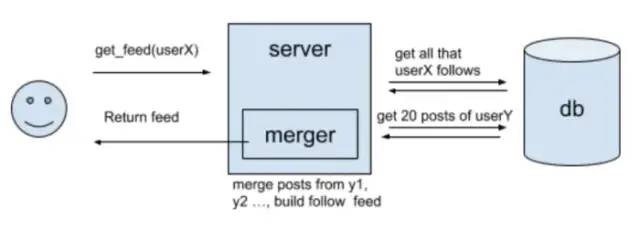
1. 信息流生成服务(News Feed Generation services) 为用户更新所关注的用户的最新帖子
每个用户的信息流都是独一无二的,组合非常复杂
为了生成新的信息流,系统必须获取这些照片的元数据(喜欢、评论、时间、位置等),并将其传递给排名算法,以决定哪些照片应该根据元数据安排在信息流中
后端需要同时查询大量的表,然后使用预定义的参数对它们进行排序,这种方法将导致更高的延迟,需要大量的时间来生成新的信息流
因此,可以采用预生成的信息流。创建专门用于生成每个用户独有信息流的服务器,并将其结果存储在单独的信息流表中。当用户点击更新时,直接从数据库中读取信息流并显示给用户。
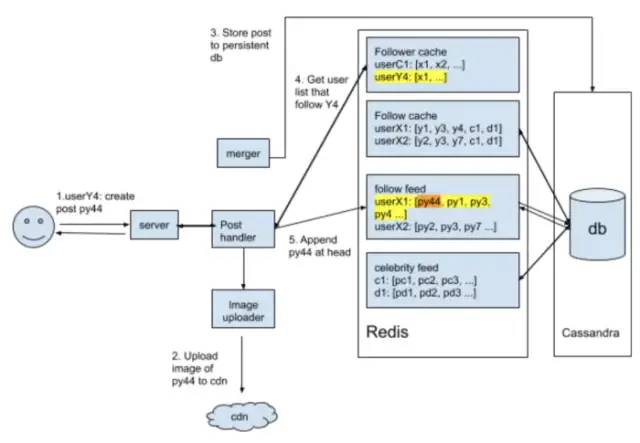
2. 提供信息流(Serving the News Feed) 推模式(Push) — 当用户上传了新的照片/视频,他/她的所有粉丝都会获得更新。如果用户关注了很多人或名人,服务器就必须非常频繁的向用户推送更新。
拉模式(Pull) — 用户主动刷新他们的信息流(向服务器发出一个拉取请求)。在用户刷新之前,新帖子是不可见的。
混合模式(Hybrid Approach) — 对拥有大量粉丝的名人用户应用拉模式,普通用户采用推模式。
3. 负载均衡(Load Balancing) 将流量分流到一组服务器中,从而提高网站或应用程序的响应和可用性
使用最小带宽法
该算法将选择流量最小的服务器(以每秒兆位(Mbps)计算)提供服务
部署在客户端和服务器或服务器和数据库之间
数据架构
数据库设计 1. 用户相关数据
User ID (主键):唯一的用户ID,便于全局区分用户
Name :用户名
Email :用户邮件地址
Password :用户密码,用于用户登录
Create Date :用户注册时间
2. 照片相关数据(AWS S3)
photo id (主键):10字节长度的唯一照片id,用于标识每一张照片
UserId :上传照片的用户id
Path :存放照片的对象存储路径/URL
Latitude & Longitude(纬度和经度) :存储这些信息来找到照片的位置
Date & time(日期和时间) :照片上传的日期和时间戳
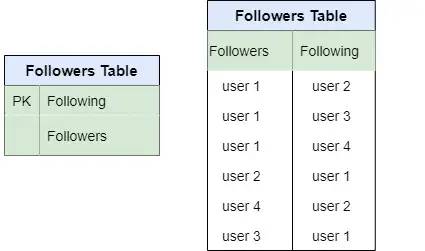
3. 用户关注和粉丝相关数据
Following :该用户所关注的所有用户的UserId
Followers :关注该用户的所有用户的UserId
因此,我们需要两种不同的数据库:mysql
数据模型
典型查询 :
获取用户X关注的所有用户——为用户X发送信息流
获取所有关注用户X的用户——将用户X的帖子推送到关注者的信息流中
获取所有活跃用户(为活跃用户提供缓存的关注者信息流)
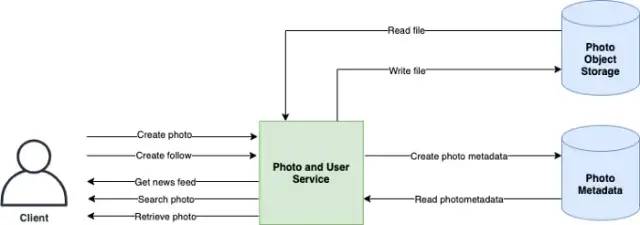
接口/API create_post(user_id, image, text, timestamp) -> success/failure
comment_post(user_id, post_id, comment, timestamp) -> success/failure
like_post(user_id, post_id, timestamp) -> success/failure
get_follow_feed(user_id, timestamp) -> list of newest posts from user follow list, ordered by time, limit 20
get_profile_feed(user_id, user2_id, timestamp) -> list of newest posts from user2, ordered by time, limit 20
系统架构
发帖
信息流
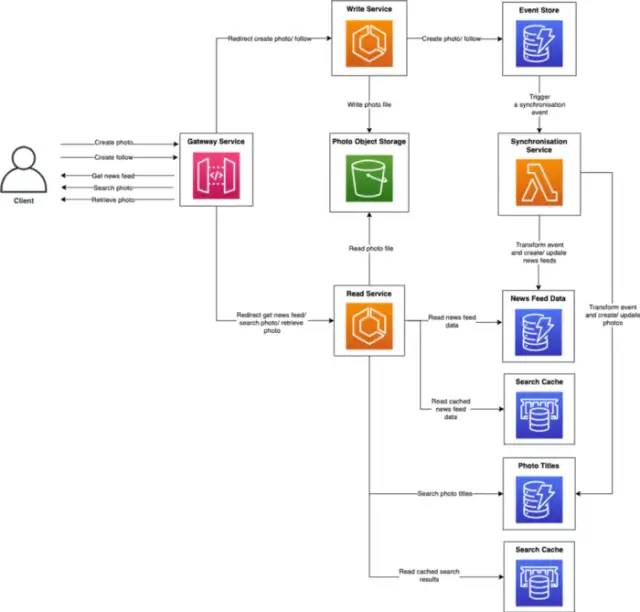
进一步细化
发帖
信息流
延伸阅读:
Instagram Engineering: https://medium.com/@InstagramEng
Instagram System Design: https://youtu.be/da7mdMz0g0g
Designing Instagram: https://www.educative.io/courses/grokking-the-system-design-interview/m2yDVZnQ8lG
Design Photo Sharing Platform - Instagram: https://techtakshila.com/system-design-interview/chapter-4/
Designing Instagram: https://www.codercrunch.com/design/634265/designing-instagram
Designing Instagram Architecture: https://nlogn.in/designing-instagram-architecture-system-design/
System Design Analysis of Instagram: https://towardsdatascience.com/system-design-analysis-of-instagram-51cd25093971
References:
你好,我是俞凡,在Motorola做过研发,现在在Mavenir做技术工作,对通信、网络、后端架构、云原生、DevOps、CICD、区块链、AI等技术始终保持着浓厚的兴趣,平时喜欢阅读、思考,相信持续学习、终身成长,欢迎一起交流学习。
前言 大家好,好久不发文章了。(快一个月了- -)最近有很多学习的新知识想和大家分享,但无奈最近项目蛮忙的,很多文章写了一半搁置在了笔记里,待以后慢慢补充发布。
本文主要是通过实际代码讲解,帮助你一步步搭建一个简易的秒杀系统。从而快速的了解秒杀系统的主要难点,并且迅速上手实际项目。
我对秒杀系统文章的规划:
从零开始打造简易秒杀系统:乐观锁防止超卖
从零开始打造简易秒杀系统:令牌桶限流
从零开始打造简易秒杀系统:Redis 缓存
从零开始打造简易秒杀系统:消息队列异步处理订单
…
秒杀系统 秒杀系统介绍 秒杀系统相信网上已经介绍了很多了,我也不想黏贴很多定义过来了。
废话少说,秒杀系统主要应用在商品抢购的场景,比如:
电商抢购限量商品
卖周董演唱会的门票
火车票抢座
…
秒杀系统抽象来说就是以下几个步骤:
用户选定商品下单
校验库存
扣库存
创建用户订单
用户支付等后续步骤…
听起来就是个用户买商品的流程而已嘛,确实,所以我们为啥要说他是个专门的系统呢。。
为什么要做所谓的“系统” 如果你的项目流量非常小,完全不用担心有并发的购买请求,那么做这样一个系统意义不大。
但如果你的系统要像12306那样,接受高并发访问和下单的考验,那么你就需要一套完整的流程保护措施,来保证你系统在用户流量高峰期不会被搞挂了。(就像12306刚开始网络售票那几年一样)
这些措施有什么呢:
我们先从“防止超卖”开始吧 毕竟,你网页可以卡住,最多是大家没参与到活动,上网口吐芬芳,骂你一波。但是你要是卖多了,本该拿到商品的用户可就不乐意了,轻则投诉你,重则找漏洞起诉赔偿。让你吃不了兜着走。
不能再说下去了,我这篇文章可是打着实战文章的名头,为什么我老是要讲废话啊啊啊啊啊啊。
上代码。
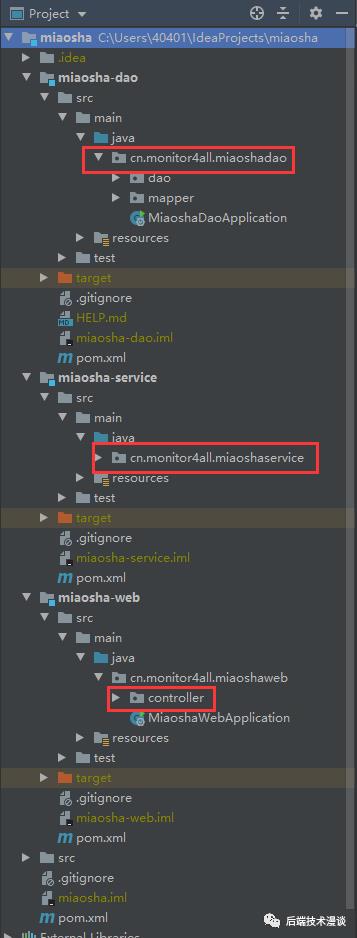
说好的做“简易”的秒杀系统,所以我们只用最简单的SpringBoot项目
建立“简易”的数据库表结构 一开始我们先来张最最最简易的结构表,参考了crossoverjie的秒杀系统文章。
等未来我们需要解决更多的系统问题,再扩展表结构。
一张库存表stock,一张订单表stock_order
-- ---------------------------- -- Table structure for stock -- ---------------------------- DROP TABLE IF EXISTS `stock` ;CREATE TABLE `stock` (`id` int (11 ) unsigned NOT NULL AUTO_INCREMENT,`name` varchar (50 ) NOT NULL DEFAULT '' COMMENT '名称' ,`count` int (11 ) NOT NULL COMMENT '库存' ,`sale` int (11 ) NOT NULL COMMENT '已售' ,`version` int (11 ) NOT NULL COMMENT '乐观锁,版本号' ,KEY (`id` )ENGINE =InnoDB DEFAULT CHARSET =utf8;-- ---------------------------- -- Table structure for stock_order -- ---------------------------- DROP TABLE IF EXISTS `stock_order` ;CREATE TABLE `stock_order` (`id` int (11 ) unsigned NOT NULL AUTO_INCREMENT,`sid` int (11 ) NOT NULL COMMENT '库存ID' ,`name` varchar (30 ) NOT NULL DEFAULT '' COMMENT '商品名称' ,`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '创建时间' ,KEY (`id` )ENGINE =InnoDB DEFAULT CHARSET =utf8;通过HTTP接口发起一次购买请求 代码中我们采用最传统的Spring MVC+Mybaits的结构
结构如下图:
Controller层代码 提供一个HTTP接口: 参数为商品的Id
@RequestMapping ("/createWrongOrder/{sid}" )@ResponseBody String createWrongOrder(@PathVariable int sid) {"购买物品编号sid=[{}]" , sid);int id = 0 ;try {"创建订单id: [{}]" , id);catch (Exception e) {"Exception" , e);return String .valueOf(id);Service层代码 @Override public int createWrongOrder (int sid) throws Exception //校验库存 //扣库存 //创建订单 int id = createOrder(stock);return id;private Stock checkStock (int sid) if (stock.getSale().equals(stock.getCount())) {throw new RuntimeException("库存不足" );return stock;private int saleStock (Stock stock) 1 );return stockService.updateStockById(stock);private int createOrder (Stock stock) new StockOrder();int id = orderMapper.insertSelective(order);return id;发起并发购买请求 我们通过JMeter(https://jmeter.apache.org/) 这个并发请求工具来模拟大量用户同时请求购买接口的场景。
注意:POSTMAN并不支持并发请求,其请求是顺序的,而JMeter是多线程请求。希望以后PostMan能够支持吧,毕竟JMeter还在倔强的用Java UI框架。毕竟是亲儿子呢。
如何通过JMeter进行压力测试,请参考下文,讲的非常入门但详细,包教包会:
https://www.cnblogs.com/stulzq/p/8971531.html
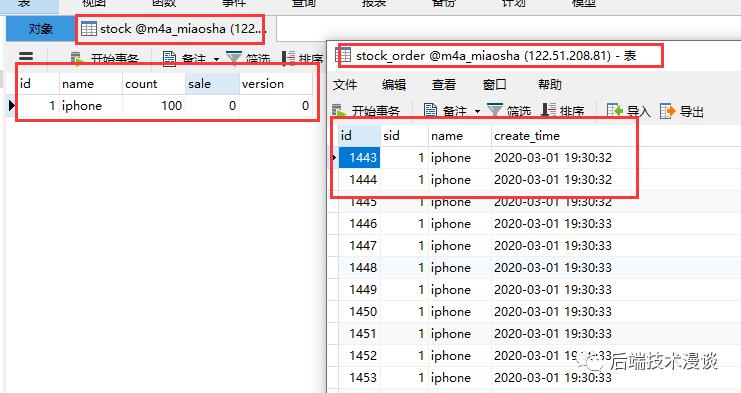
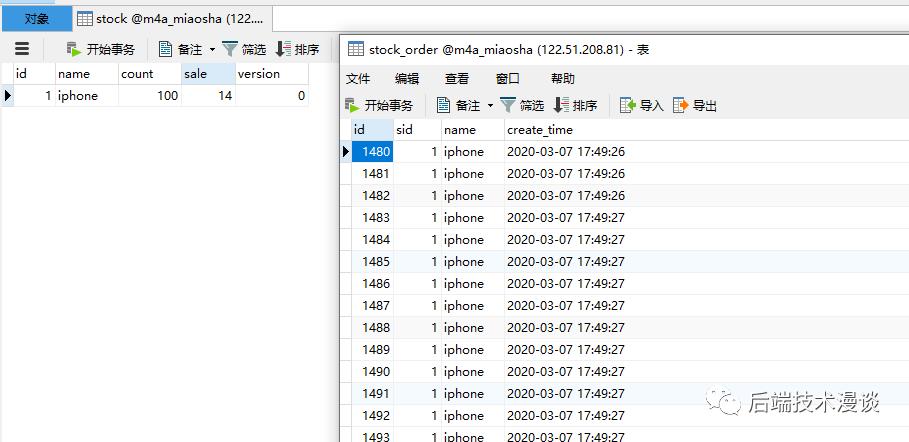
我们在表里添加一个Iphone,库存100。(请忽略订单表里的数据,开始前我清空了)
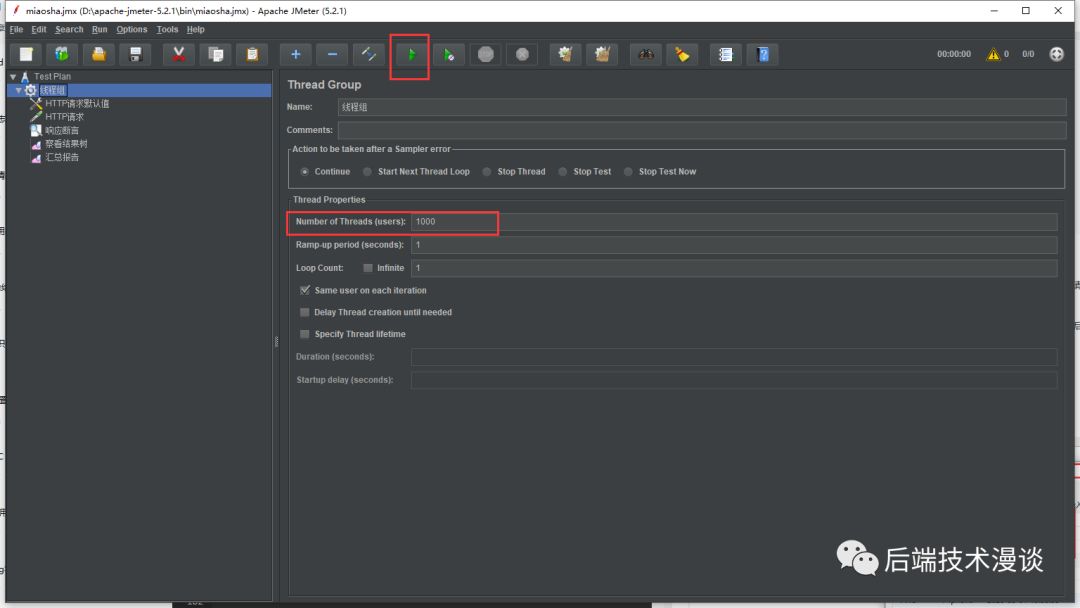
在JMeter里启动1000个线程,无延迟同时访问接口。模拟1000个人,抢购100个产品的场景。点击启动:
你猜会卖出多少个呢,先想一想。。。
答案是:
卖出了14个,库存减少了14个,但是每个请求Spring都处理了,创建了1000个订单。
我这里该夸Spring强大的并发处理能力,还是该骂MySQL已经是个成熟的数据库,却都不会自己锁库存?
避免超卖问题:更新商品库存的版本号 为了解决上面的超卖问题,我们当然可以在Service层给更新表添加一个事务,这样每个线程更新请求的时候都会先去锁表的这一行(悲观锁),更新完库存后再释放锁。可这样就太慢了,1000个线程可等不及。
我们需要乐观锁。
一个最简单的办法就是,给每个商品库存一个版本号version字段
我们修改代码:
Controller层 /**@param sid@return @RequestMapping("/createOptimisticOrder/{sid}" ) @ResponseBody public String createOptimisticOrder(@PathVariable int sid) {try {"购买成功,剩余库存为: [{}]" , id);catch (Exception e) {"购买失败:[{}]" , e.getMessage());return "购买失败,库存不足" ;return String.format("购买成功,剩余库存为:%d" , id);Service层 @Override public int createOptimisticOrder (int sid) throws Exception //校验库存 //乐观锁更新库存 //创建订单 int id = createOrder(stock);return stock.getCount() - (stock.getSale()+1 );private void saleStockOptimistic (Stock stock) "查询数据库,尝试更新库存" );int count = stockService.updateStockByOptimistic(stock);if (count == 0 ){throw new RuntimeException("并发更新库存失败,version不匹配" ) ;Mapper <update id="updateByOptimistic" parameterType="cn.monitor4all.miaoshadao.dao.Stock" >set >1 ,1 ,set >WHERE id = #{id,jdbcType=INTEGER} AND version = #{version,jdbcType=INTEGER} 我们在实际减库存的SQL操作中,首先判断version是否是我们查询库存时候的version,如果是,扣减库存,成功抢购。如果发现version变了,则不更新数据库,返回抢购失败。
发起并发购买请求 这次,我们能成功吗?
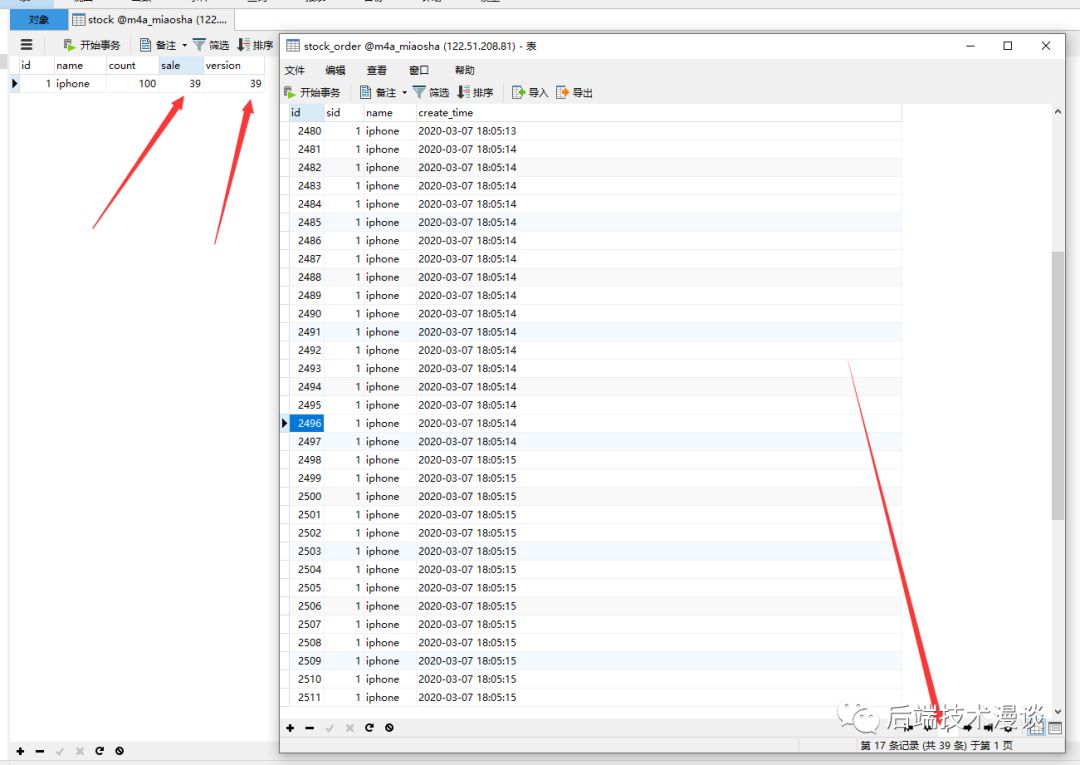
再次打开JMeter,把库存恢复为100,清空订单表,发起1000次请求。
这次的结果是:
卖出去了39个,version更新为了39,同时创建了39个订单。我们没有超卖,可喜可贺。
由于并发访问的原因,很多线程更新库存失败了,所以在我们这种设计下,1000个人真要是同时发起购买,只有39个幸运儿能够买到东西,但是我们防止了超卖。
手速快未必好,还得看运气呀!
OK,今天先到这里,之后我们继续一步步完善这个简易的秒杀系统,它总有从树苗变成大树的那一天!
源码 我会随着文章的更新,一直同步更新项目代码,欢迎关注:
https://github.com/qqxx6661/miaosha
参考
https://cloud.tencent.com/developer/article/1488059
https://juejin.im/post/5dd09f5af265da0be72aacbd
https://crossoverjie.top/%2F2018%2F05%2F07%2Fssm%2FSSM18-seconds-kill%2F
关注我 我是一名后端开发工程师。
主要关注后端开发,数据安全,物联网,边缘计算方向,欢迎交流。
各大平台都可以找到我
Github:@qqxx6661
CSDN:@Rude3knife
知乎:@后端技术漫谈
简书:@蛮三刀把刀
掘金:@蛮三刀把刀
原创博客主要内容 个人公众号:后端技术漫谈
公众号:后端技术漫谈.jpg
如果文章对你有帮助,不妨收藏,转发,在看起来~