面渣逆袭:线程池夺命连环十八问
Posted 三分恶
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了面渣逆袭:线程池夺命连环十八问相关的知识,希望对你有一定的参考价值。
大家好,我是老三,很高兴又和大家见面。线程池是面试必问的知识点,这节我们来对线面试官,搞透线程池。
简单理解,它就是一个管理线程的池子。它帮我们管理线程,避免增加创建线程和销毁线程的资源损耗。因为线程其实也是一个对象,创建一个对象,需要经过类加载过程,销毁一个对象,需要走GC垃圾回收流程,都是需要资源开销的。 提高响应速度。 如果任务到达了,相对于从线程池拿线程,重新去创建一条线程执行,速度肯定慢很多。 重复利用。 线程用完,再放回池子,可以达到重复利用的效果,节省资源。 2. 能说说工作中线程池的应用吗?
之前我们有一个和第三方对接的需求,需要向第三方推送数据,引入了多线程来提升数据推送的效率,其中用到了线程池来管理线程。
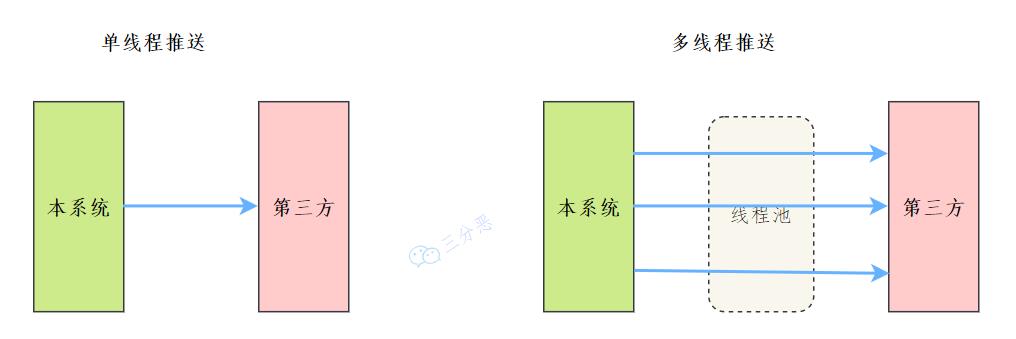
业务示例 主要代码如下:
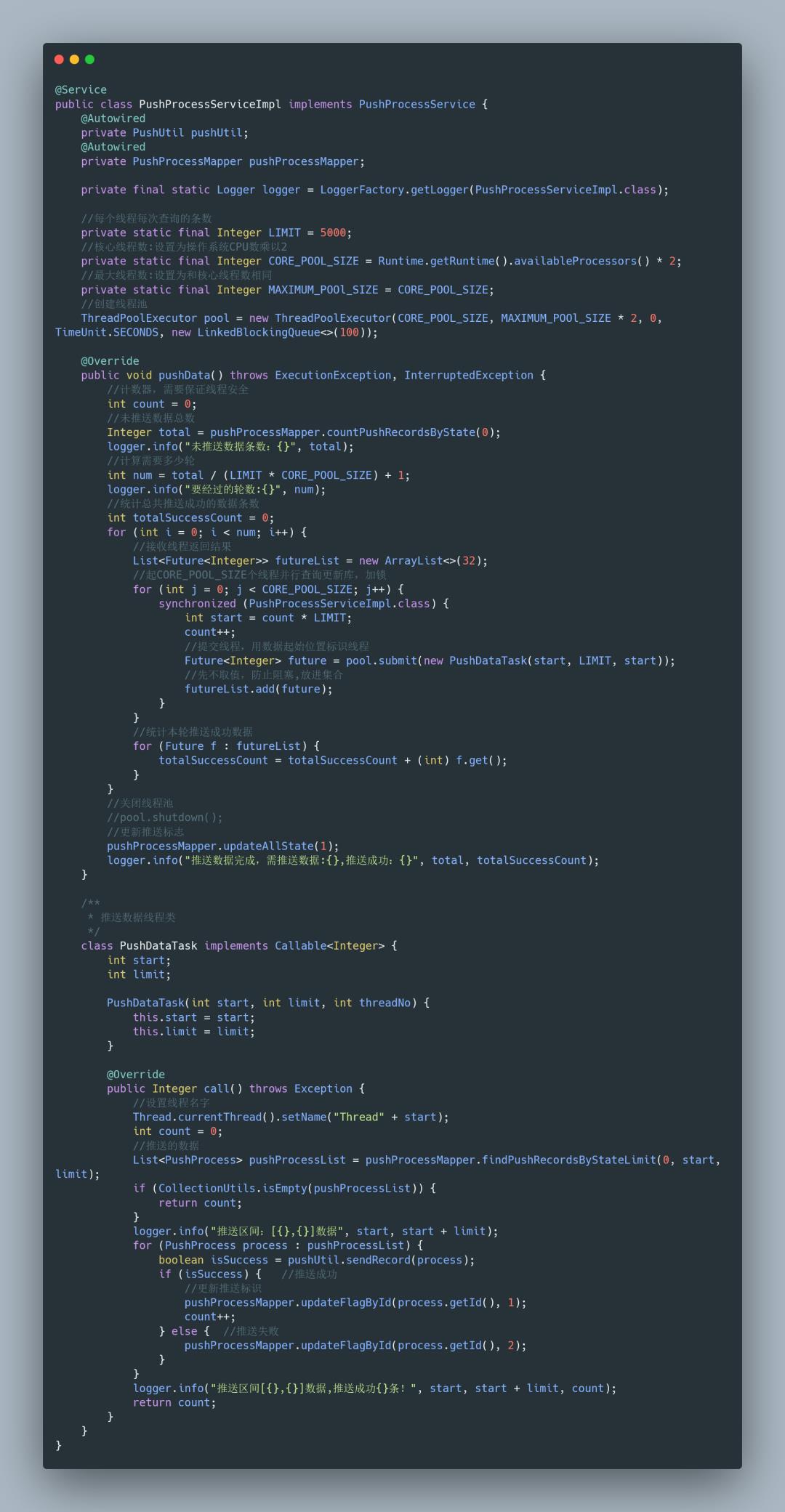
主要代码 完整可运行代码地址:https://gitee.com/fighter3/thread-demo.git
线程池的参数如下:
corePoolSize:线程核心参数选择了CPU数×2
maximumPoolSize:最大线程数选择了和核心线程数相同
keepAliveTime:非核心闲置线程存活时间直接置为0
unit:非核心线程保持存活的时间选择了 TimeUnit.SECONDS 秒
workQueue:线程池等待队列,使用 LinkedBlockingQueue阻塞队列
同时还用了synchronized 来加锁,保证数据不会被重复推送:
synchronized (PushProcessServiceImpl.class)
ps:这个例子只是简单地进行了数据推送,实际上还可以结合其他的业务,像什么数据清洗啊、数据统计啊,都可以套用。
3.能简单说一下线程池的工作流程吗?
用一个通俗的比喻:
有一个营业厅,总共有六个窗口,现在开放了三个窗口,现在有三个窗口坐着三个营业员小姐姐在营业。
老三去办业务,可能会遇到什么情况呢?
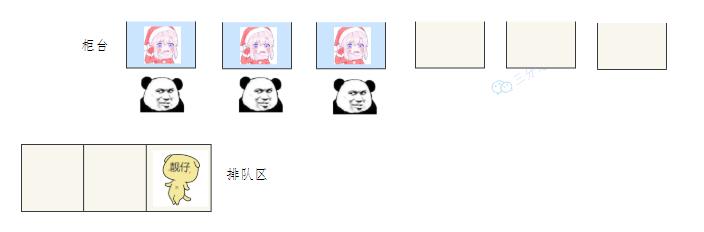
老三发现有空间的在营业的窗口,直接去找小姐姐办理业务。

直接办理 老三发现没有空闲的窗口,就在排队区排队等。
排队等待 老三发现没有空闲的窗口,等待区也满了,蚌埠住了,经理一看,就让休息的小姐姐赶紧回来上班,等待区号靠前的赶紧去新窗口办,老三去排队区排队。小姐姐比较辛苦,假如一段时间发现他们可以不用接着营业,经理就让她们接着休息。
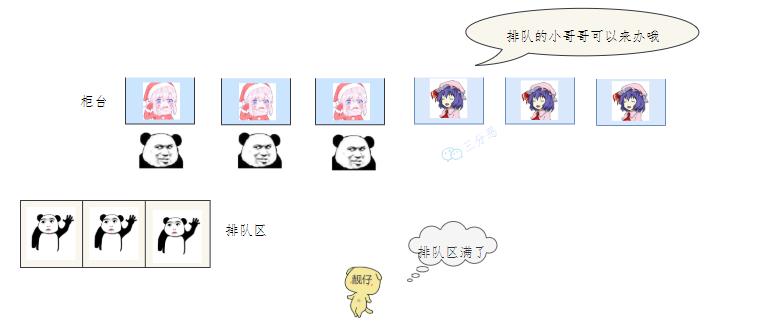
排队区满 老三一看,六个窗口都满了,等待区也没位置了。老三急了,要闹,经理赶紧出来了,经理该怎么办呢?
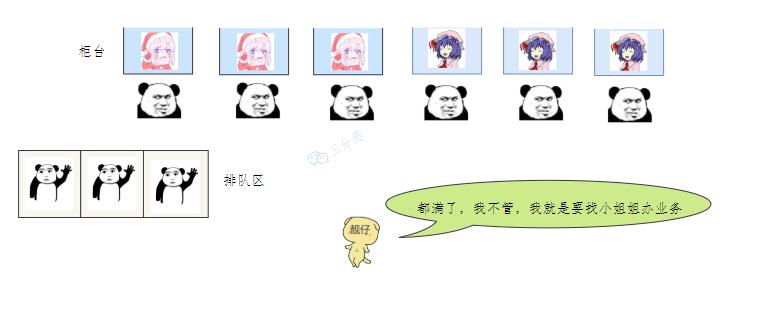
等待区,排队区都满 ❝我们银行系统已经瘫痪
谁叫你来办的你找谁去
看你比较急,去队里加个塞
今天没办法,不行你看改一天
上面的这个流程几乎就跟 JDK 线程池的大致流程类似,
❝营业中的 3个窗口对应核心线程池数:corePoolSize 总的营业窗口数6对应:maximumPoolSize 打开的临时窗口在多少时间内无人办理则关闭对应:unit 排队区就是等待队列:workQueue 无法办理的时候银行给出的解决方法对应:RejectedExecutionHandler threadFactory 该参数在 JDK 中是 线程工厂,用来创建线程对象,一般不会动。
所以我们线程池的工作流程也比较好理解了:
线程池刚创建时,里面没有一个线程。任务队列是作为参数传进来的。不过,就算队列里面有任务,线程池也不会马上执行它们。 当调用 execute() 方法添加一个任务时,线程池会做如下判断:
如果正在运行的线程数量小于 corePoolSize,那么马上创建线程运行这个任务; 如果正在运行的线程数量大于或等于 corePoolSize,那么将这个任务放入队列; 如果这时候队列满了,而且正在运行的线程数量小于 maximumPoolSize,那么还是要创建非核心线程立刻运行这个任务; 如果队列满了,而且正在运行的线程数量大于或等于 maximumPoolSize,那么线程池会根据拒绝策略来对应处理。 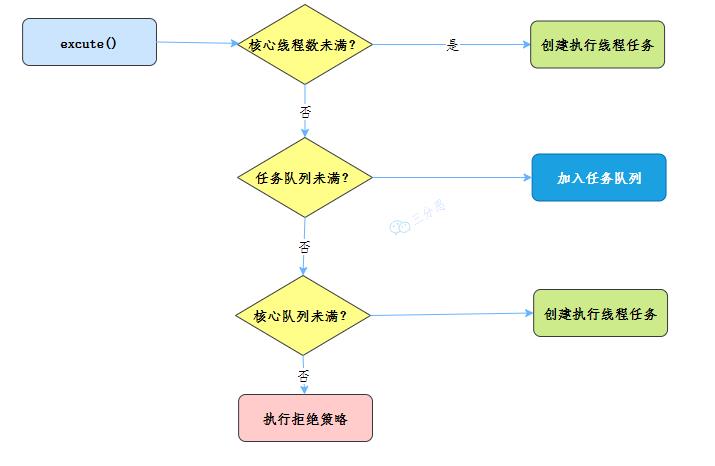
线程池执行流程 当一个线程完成任务时,它会从队列中取下一个任务来执行。
当一个线程无事可做,超过一定的时间(keepAliveTime)时,线程池会判断,如果当前运行的线程数大于 corePoolSize,那么这个线程就被停掉。所以线程池的所有任务完成后,它最终会收缩到 corePoolSize 的大小。
4.线程池主要参数有哪些?
corePoolSize
此值是用来初始化线程池中核心线程数,当线程池中线程池数< corePoolSize时,系统默认是添加一个任务才创建一个线程池。当线程数 = corePoolSize时,新任务会追加到workQueue中。
maximumPoolSize
maximumPoolSize表示允许的最大线程数 = (非核心线程数+核心线程数),当BlockingQueue也满了,但线程池中总线程数 < maximumPoolSize时候就会再次创建新的线程。
keepAliveTime
非核心线程 =(maximumPoolSize - corePoolSize ) ,非核心线程闲置下来不干活最多存活时间。
unit
线程池中非核心线程保持存活的时间的单位
TimeUnit.DAYS; 天 TimeUnit.HOURS; 小时 TimeUnit.MINUTES; 分钟 TimeUnit.SECONDS; 秒 TimeUnit.MILLISECONDS; 毫秒 TimeUnit.MICROSECONDS; 微秒 TimeUnit.NANOSECONDS; 纳秒 workQueue
线程池等待队列,维护着等待执行的Runnable对象。当运行当线程数= corePoolSize时,新的任务会被添加到workQueue中,如果workQueue也满了则尝试用非核心线程执行任务,等待队列应该尽量用有界的。
threadFactory
创建一个新线程时使用的工厂,可以用来设定线程名、是否为daemon线程等等。
handler
corePoolSize、workQueue、maximumPoolSize都不可用的时候执行的饱和策略。
5.线程池的拒绝策略有哪些?
类比前面的例子,无法办理业务时的处理方式,帮助记忆:
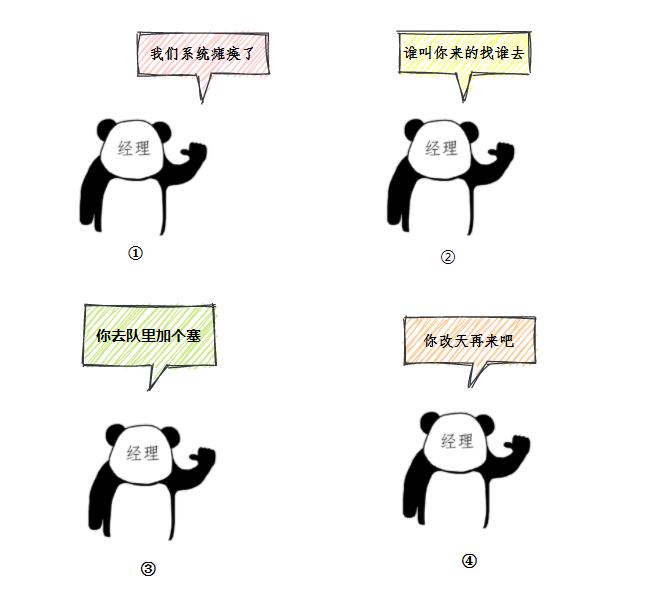
四种策略 AbortPolicy :直接抛出异常,默认使用此策略 CallerRunsPolicy:用调用者所在的线程来执行任务 DiscardOldestPolicy:丢弃阻塞队列里最老的任务,也就是队列里靠前的任务 DiscardPolicy :当前任务直接丢弃 想实现自己的拒绝策略,实现RejectedExecutionHandler接口即可。
6.线程池有哪几种工作队列?
常用的阻塞队列主要有以下几种:
ArrayBlockingQueue:ArrayBlockingQueue(有界队列)是一个用数组实现的有界阻塞队列,按FIFO排序量。 LinkedBlockingQueue:LinkedBlockingQueue(可设置容量队列)是基于链表结构的阻塞队列,按FIFO排序任务,容量可以选择进行设置,不设置的话,将是一个无边界的阻塞队列,最大长度为Integer.MAX_VALUE,吞吐量通常要高于ArrayBlockingQuene;newFixedThreadPool线程池使用了这个队列 DelayQueue:DelayQueue(延迟队列)是一个任务定时周期的延迟执行的队列。根据指定的执行时间从小到大排序,否则根据插入到队列的先后排序。newScheduledThreadPool线程池使用了这个队列。 PriorityBlockingQueue:PriorityBlockingQueue(优先级队列)是具有优先级的无界阻塞队列 SynchronousQueue:SynchronousQueue(同步队列)是一个不存储元素的阻塞队列,每个插入操作必须等到另一个线程调用移除操作,否则插入操作一直处于阻塞状态,吞吐量通常要高于LinkedBlockingQuene,newCachedThreadPool线程池使用了这个队列。 7.线程池提交execute和submit有什么区别?
execute 用于提交不需要返回值的任务
threadsPool.execute(new Runnable()
@Override public void run()
// TODO Auto-generated method stub
);
submit()方法用于提交需要返回值的任务。线程池会返回一个future类型的对象,通过这个 future对象可以判断任务是否执行成功,并且可以通过future的get()方法来获取返回值
Future<Object> future = executor.submit(harReturnValuetask);
try Object s = future.get(); catch (InterruptedException e)
// 处理中断异常
catch (ExecutionException e)
// 处理无法执行任务异常
finally
// 关闭线程池 executor.shutdown();
8.线程池怎么关闭知道吗?
可以通过调用线程池的shutdown或shutdownNow方法来关闭线程池。它们的原理是遍历线程池中的工作线程,然后逐个调用线程的interrupt方法来中断线程,所以无法响应中断的任务可能永远无法终止。
shutdown() 将线程池状态置为shutdown,并不会立即停止:
❝停止接收外部submit的任务 内部正在跑的任务和队列里等待的任务,会执行完 等到第二步完成后,才真正停止
shutdownNow() 将线程池状态置为stop。一般会立即停止,事实上不一定:
❝和shutdown()一样,先停止接收外部提交的任务 忽略队列里等待的任务 尝试将正在跑的任务interrupt中断 返回未执行的任务列表
shutdown 和shutdownnow简单来说区别如下:
❝shutdownNow()能立即停止线程池,正在跑的和正在等待的任务都停下了。这样做立即生效,但是风险也比较大。shutdown()只是关闭了提交通道,用submit()是无效的;而内部的任务该怎么跑还是怎么跑,跑完再彻底停止线程池。
9.线程池的线程数应该怎么配置?
线程在Java中属于稀缺资源,线程池不是越大越好也不是越小越好。任务分为计算密集型、IO密集型、混合型。
❝计算密集型:大部分都在用CPU跟内存,加密,逻辑操作业务处理等。 IO密集型:数据库链接,网络通讯传输等。
计算密集型一般推荐线程池不要过大,一般是CPU数 + 1,+1是因为可能存在页缺失(就是可能存在有些数据在硬盘中需要多来一个线程将数据读入内存)。如果线程池数太大,可能会频繁的 进行线程上下文切换跟任务调度。获得当前CPU核心数代码如下:
Runtime.getRuntime().availableProcessors();
IO密集型:线程数适当大一点,机器的Cpu核心数*2。 混合型:可以考虑根据情况将它拆分成CPU密集型和IO密集型任务,如果执行时间相差不大,拆分可以提升吞吐量,反之没有必要。
当然,实际应用中没有固定的公式,需要结合测试和监控来进行调整。
10.有哪几种常见的线程池?
主要有四种,都是通过工具类Excutors创建出来的,阿里巴巴《Java开发手册》里禁止使用这种方式来创建线程池。
newFixedThreadPool (固定数目线程的线程池)
newCachedThreadPool (可缓存线程的线程池)
newSingleThreadExecutor (单线程的线程池)
newScheduledThreadPool (定时及周期执行的线程池)
11.能说一下四种常见线程池的原理吗?
前三种线程池的构造直接调用ThreadPoolExecutor的构造方法。
newSingleThreadExecutor public static ExecutorService newSingleThreadExecutor(ThreadFactory threadFactory)
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(),
threadFactory));
线程池特点
核心线程数为1 最大线程数也为1 阻塞队列是无界队列LinkedBlockingQueue,可能会导致OOM keepAliveTime为0 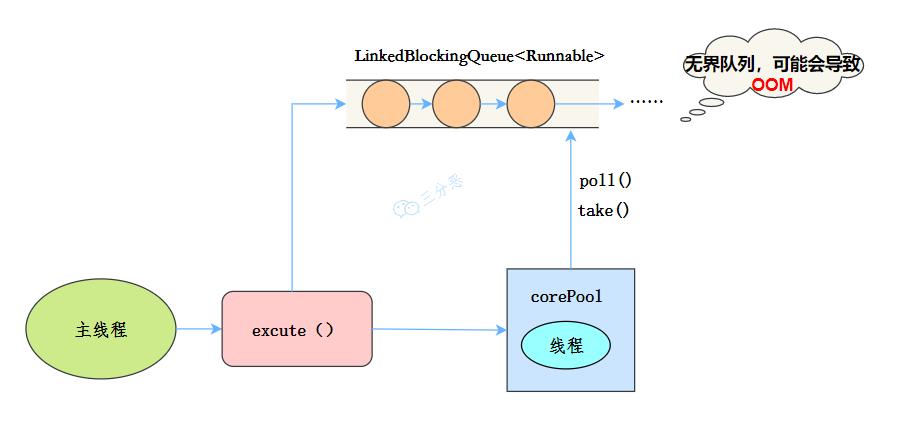
SingleThreadExecutor运行流程 工作流程:
提交任务 线程池是否有一条线程在,如果没有,新建线程执行任务 如果有,将任务加到阻塞队列 当前的唯一线程,从队列取任务,执行完一个,再继续取,一个线程执行任务。 适用场景
适用于串行执行任务的场景,一个任务一个任务地执行。
newFixedThreadPool public static ExecutorService newFixedThreadPool(int nThreads, ThreadFactory threadFactory)
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(),
threadFactory);
线程池特点:
核心线程数和最大线程数大小一样 没有所谓的非空闲时间,即keepAliveTime为0 阻塞队列为无界队列LinkedBlockingQueue,可能会导致OOM 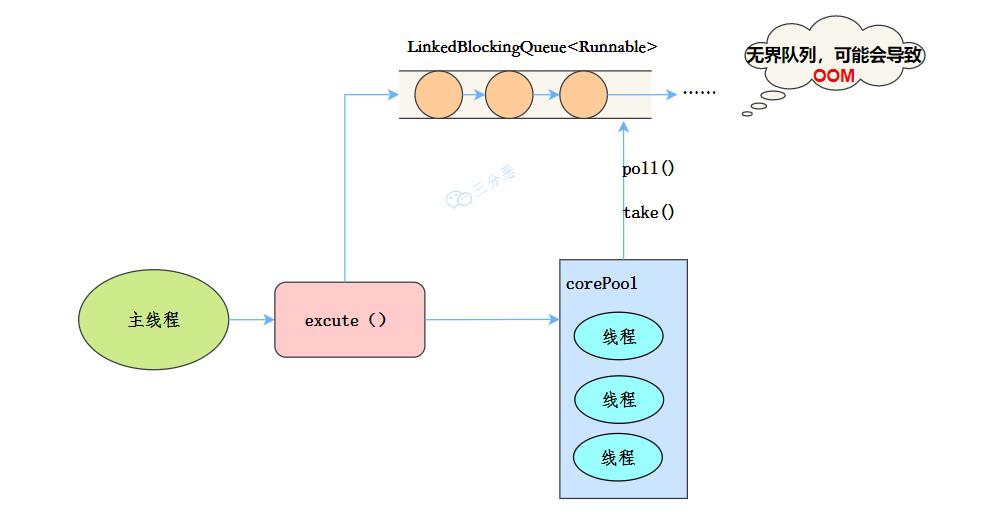
FixedThreadPool 工作流程:
提交任务 如果线程数少于核心线程,创建核心线程执行任务 如果线程数等于核心线程,把任务添加到LinkedBlockingQueue阻塞队列 如果线程执行完任务,去阻塞队列取任务,继续执行。 使用场景
FixedThreadPool 适用于处理CPU密集型的任务,确保CPU在长期被工作线程使用的情况下,尽可能的少的分配线程,即适用执行长期的任务。
newCachedThreadPool public static ExecutorService newCachedThreadPool(ThreadFactory threadFactory)
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>(),
threadFactory);
线程池特点:
核心线程数为0 最大线程数为Integer.MAX_VALUE,即无限大,可能会因为无限创建线程,导致OOM 阻塞队列是SynchronousQueue 非核心线程空闲存活时间为60秒 当提交任务的速度大于处理任务的速度时,每次提交一个任务,就必然会创建一个线程。极端情况下会创建过多的线程,耗尽 CPU 和内存资源。由于空闲 60 秒的线程会被终止,长时间保持空闲的 CachedThreadPool 不会占用任何资源。
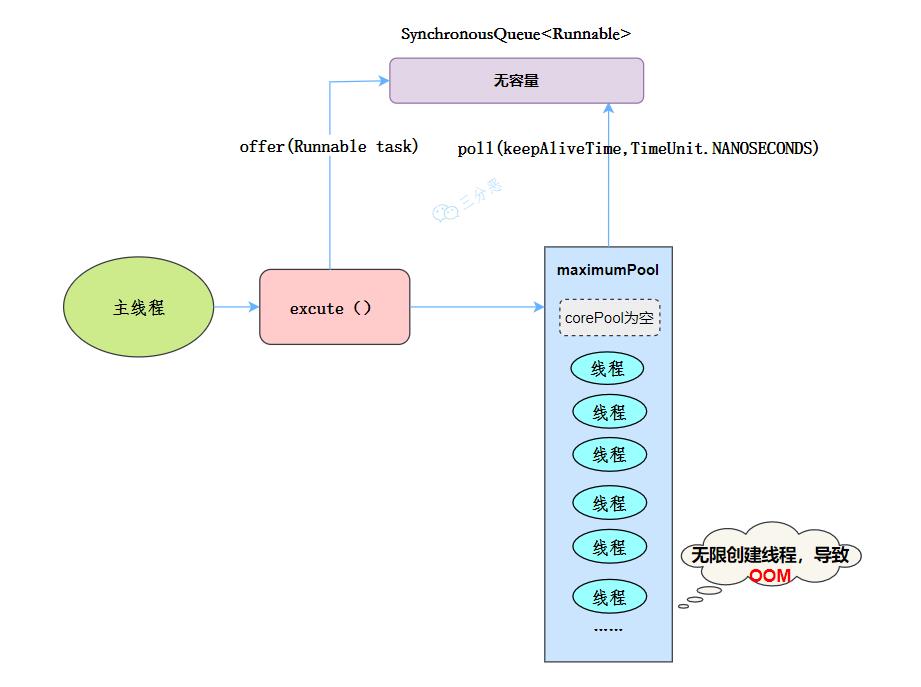
CachedThreadPool执行流程 工作流程:
提交任务 因为没有核心线程,所以任务直接加到SynchronousQueue队列。 判断是否有空闲线程,如果有,就去取出任务执行。 如果没有空闲线程,就新建一个线程执行。 执行完任务的线程,还可以存活60秒,如果在这期间,接到任务,可以继续活下去;否则,被销毁。 适用场景
用于并发执行大量短期的小任务。
newScheduledThreadPool public ScheduledThreadPoolExecutor(int corePoolSize)
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue());
线程池特点
最大线程数为Integer.MAX_VALUE,也有OOM的风险 阻塞队列是DelayedWorkQueue keepAliveTime为0 scheduleAtFixedRate() :按某种速率周期执行 scheduleWithFixedDelay():在某个延迟后执行 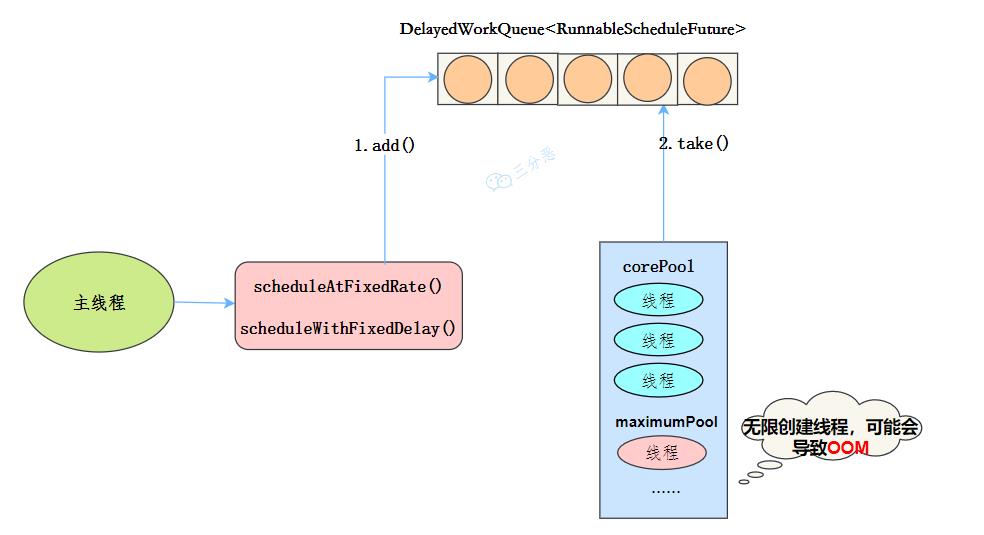
ScheduledThreadPool执行流程 工作机制
线程从DelayQueue中获取已到期的ScheduledFutureTask(DelayQueue.take())。到期任务是指ScheduledFutureTask的time大于等于当前时间。 线程执行这个ScheduledFutureTask。 线程修改ScheduledFutureTask的time变量为下次将要被执行的时间。 线程把这个修改time之后的ScheduledFutureTask放回DelayQueue中(DelayQueue.add())。 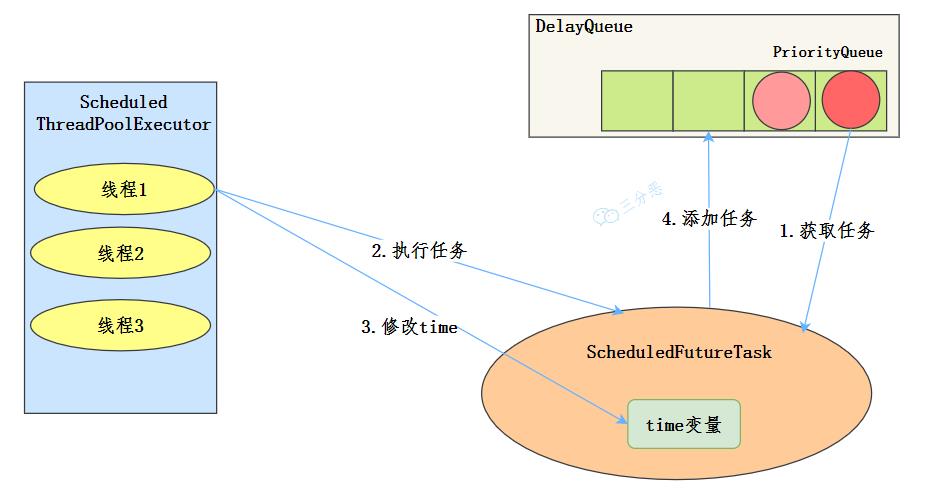
ScheduledThreadPoolExecutor执行流程 使用场景
周期性执行任务的场景,需要限制线程数量的场景
12.使用无界队列的线程池会导致什么问题吗?
例如newFixedThreadPool使用了无界的阻塞队列LinkedBlockingQueue,如果线程获取一个任务后,任务的执行时间比较长,会导致队列的任务越积越多,导致机器内存使用不停飙升,最终导致OOM。
13.线程池异常怎么处理知道吗?
在使用线程池处理任务的时候,任务代码可能抛出RuntimeException,抛出异常后,线程池可能捕获它,也可能创建一个新的线程来代替异常的线程,我们可能无法感知任务出现了异常,因此我们需要考虑线程池异常情况。
常见的异常处理方式:
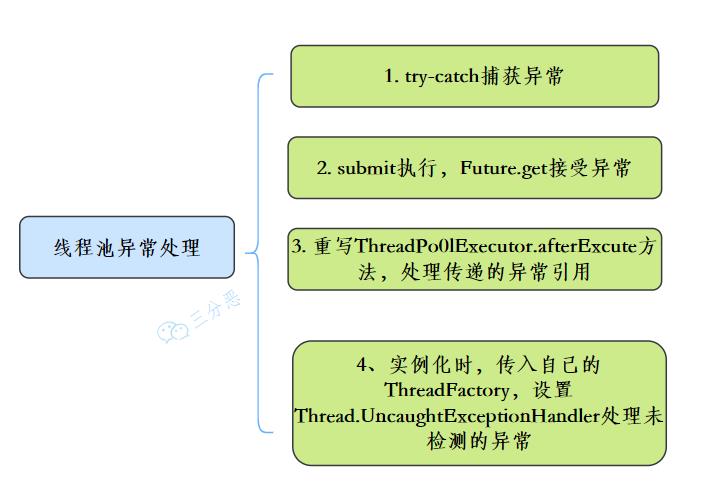
线程池异常处理 14.能说一下线程池有几种状态吗?
线程池有这几个状态:
RUNNING,SHUTDOWN,STOP,TIDYING,TERMINATED。
//线程池状态
private static final int RUNNING = -1 << COUNT_BITS;
private static final int SHUTDOWN = 0 << COUNT_BITS;
private static final int STOP = 1 << COUNT_BITS;
private static final int TIDYING = 2 << COUNT_BITS;
private static final int TERMINATED = 3 << COUNT_BITS;
线程池各个状态切换图:
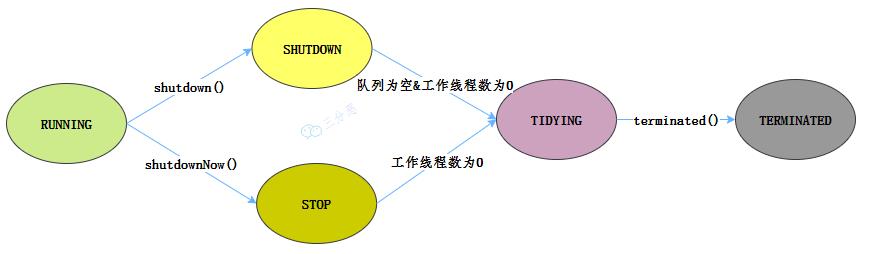
线程池状态切换图 RUNNING
该状态的线程池会接收新任务,并处理阻塞队列中的任务; 调用线程池的shutdown()方法,可以切换到SHUTDOWN状态; 调用线程池的shutdownNow()方法,可以切换到STOP状态; SHUTDOWN
该状态的线程池不会接收新任务,但会处理阻塞队列中的任务; 队列为空,并且线程池中执行的任务也为空,进入TIDYING状态; STOP
该状态的线程不会接收新任务,也不会处理阻塞队列中的任务,而且会中断正在运行的任务; 线程池中执行的任务为空,进入TIDYING状态; TIDYING
该状态表明所有的任务已经运行终止,记录的任务数量为0。 terminated()执行完毕,进入TERMINATED状态 TERMINATED
该状态表示线程池彻底终止 15.线程池如何实现参数的动态修改?
线程池提供了几个 setter方法来设置线程池的参数。

JDK 线程池参数设置接口来源参考[7] 这里主要有两个思路:
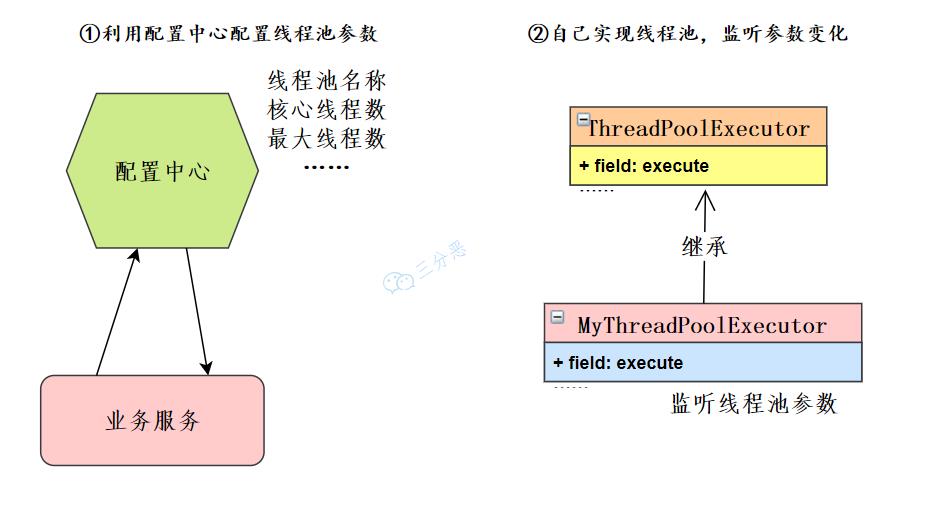
动态修改线程池参数 在我们微服务的架构下,可以利用配置中心如Nacos、Apollo等等,也可以自己开发配置中心。业务服务读取线程池配置,获取相应的线程池实例来修改线程池的参数。
如果限制了配置中心的使用,也可以自己去扩展ThreadPoolExecutor,重写方法,监听线程池参数变化,来动态修改线程池参数。
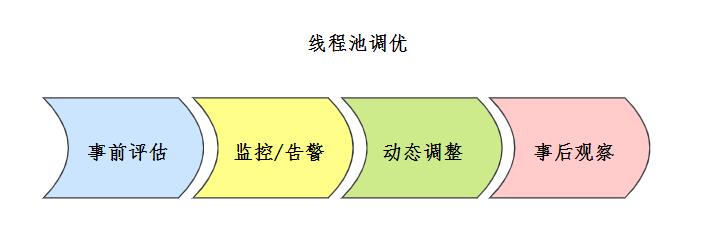
16.线程池调优了解吗?
线程池配置没有固定的公式,通常事前会对线程池进行一定评估,常见的评估方案如下:

线程池评估方案 来源参考[7] 上线之前也要进行充分的测试,上线之后要建立完善的线程池监控机制。
事中结合监控告警机制,分析线程池的问题,或者可优化点,结合线程池动态参数配置机制来调整配置。
事后要注意仔细观察,随时调整。
线程池调优 具体的调优案例可以查看参考[7]美团技术博客。
17.你能设计实现一个线程池吗?
⭐这道题在阿里的面试中出现频率比较高
线程池实现原理可以查看 要是以前有人这么讲线程池,我早就该明白了! ,当然,我们自己实现, 只需要抓住线程池的核心流程-参考[6]:
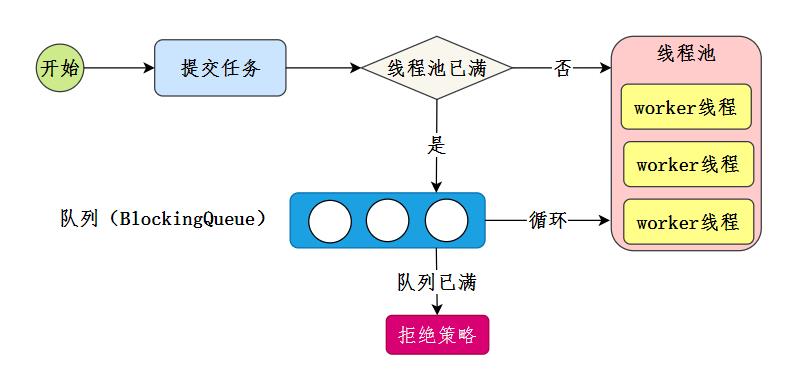
线程池主要实现流程 我们自己的实现就是完成这个核心流程:
线程池中有N个工作线程 把任务提交给线程池运行 如果线程池已满,把任务放入队列 最后当有空闲时,获取队列中任务来执行 实现代码[6]:
public class MyThreadPoolExecutor implements Executor
//记录线程池中线程数量
private final AtomicInteger ctl = new AtomicInteger(0);
//核心线程数
private volatile int corePoolSize;
//最大线程数
private volatile int maximumPoolSize;
//阻塞队列
private final BlockingQueue<Runnable> workQueue;
public MyThreadPoolExecutor(int corePoolSize, int maximumPoolSize, BlockingQueue<Runnable> workQueue)
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
/**
* 执行
*
* @param command
*/
@Override
public void execute(Runnable command)
//工作线程数
int c = ctl.get();
//小于核心线程数
if (c < corePoolSize)
//添加任务失败
if (!addWorker(command))
//执行拒绝策略
reject();
return;
//任务队列添加任务
if (!workQueue.offer(command))
//任务队列满,尝试启动线程添加任务
if (!addWorker(command))
reject();
/**
* 饱和拒绝
*/
private void reject()
//直接抛出异常
throw new RuntimeException("Can not execute!ctl.count:"
+ ctl.get() + "workQueue size:" + workQueue.size());
/**
* 添加任务
*
* @param firstTask
* @return
*/
private boolean addWorker(Runnable firstTask)
if (ctl.get() >= maximumPoolSize) return false;
Worker worker = new Worker(firstTask);
//启动线程
worker.thread.start();
ctl.incrementAndGet();
return true;
/**
* 线程池工作线程包装类
*/
private final class Worker implements Runnable
final Thread thread;
Runnable firstTask;
public Worker(Runnable firstTask)
this.thread = new Thread(this);
this.firstTask = firstTask;
@Override
public void run()
Runnable task = firstTask;
try
//执行任务
while (task != null || (task = getTask()) != null)
task.run();
//线程池已满,跳出循环
if (ctl.get() > maximumPoolSize)
break;
task = null;
finally
//工作线程数增加
ctl.decrementAndGet();
/**
* 从队列中获取任务
*
* @return
*/
private Runnable getTask()
for (; ; )
try
System.out.println("workQueue size:" + workQueue.size());
return workQueue.take();
catch (InterruptedException e)
e.printStackTrace();
//测试
public static void main(String[] args)
MyThreadPoolExecutor myThreadPoolExecutor = new MyThreadPoolExecutor(2, 2,
new ArrayBlockingQueue<Runnable>(10));
for (int i = 0; i < 10; i++)
int taskNum = i;
myThreadPoolExecutor.execute(() ->
try
Thread.sleep(1500);
catch (InterruptedException e)
e.printStackTrace();
System.out.println("任务编号:" + taskNum);
);
这样,一个实现了线程池主要流程的类就完成了。
18.单机线程池执行断电了应该怎么处理?
我们可以对正在处理和阻塞队列的任务做事务管理或者对阻塞队列中的任务持久化处理,并且当断电或者系统崩溃,操作无法继续下去的时候,可以通过回溯日志的方式来撤销正在处理的已经执行成功的操作。然后重新执行整个阻塞队列。
也就是:阻塞队列持久化;正在处理任务事务控制;断电之后正在处理任务的回滚,通过日志恢复该次操作;服务器重启后阻塞队列中的数据再加载。
参考:
[1]. 《Java并发编程的艺术》
[2]. 《Java并发编程实战》
[3]. 讲真 这次绝对让你轻松学习线程池:https://mp.weixin.qq.com/s/dTMH1TdxiCKy5yotQ7u7cA)
[4]. 面试必备:Java线程池解析:https://juejin.cn/post/6844903889678893063
[5]. 面试官问:“在项目中用过多线程吗?”你就把这个案例讲给他听!:https://juejin.cn/post/6936457087505399821
[6]. 小傅哥 《Java面经手册》
[7]. Java线程池实现原理及其在美团业务中的实践:https://tech.meituan.com/2020/04/02/java-pooling-pratice-in-meituan.html
corePoolSize:线程核心参数选择了CPU数×2
maximumPoolSize:最大线程数选择了和核心线程数相同
keepAliveTime:非核心闲置线程存活时间直接置为0
unit:非核心线程保持存活的时间选择了 TimeUnit.SECONDS 秒
workQueue:线程池等待队列,使用 LinkedBlockingQueue阻塞队列
synchronized (PushProcessServiceImpl.class)
我们银行系统已经瘫痪
谁叫你来办的你找谁去
看你比较急,去队里加个塞
今天没办法,不行你看改一天
营业中的 3个窗口对应核心线程池数:corePoolSize 总的营业窗口数6对应:maximumPoolSize 打开的临时窗口在多少时间内无人办理则关闭对应:unit 排队区就是等待队列:workQueue 无法办理的时候银行给出的解决方法对应:RejectedExecutionHandler threadFactory 该参数在 JDK 中是 线程工厂,用来创建线程对象,一般不会动。
当一个线程完成任务时,它会从队列中取下一个任务来执行。
当一个线程无事可做,超过一定的时间(keepAliveTime)时,线程池会判断,如果当前运行的线程数大于 corePoolSize,那么这个线程就被停掉。所以线程池的所有任务完成后,它最终会收缩到 corePoolSize 的大小。
corePoolSize时,系统默认是添加一个任务才创建一个线程池。当线程数 = corePoolSize时,新任务会追加到workQueue中。maximumPoolSize表示允许的最大线程数 = (非核心线程数+核心线程数),当BlockingQueue也满了,但线程池中总线程数 < maximumPoolSize时候就会再次创建新的线程。Runnable对象。当运行当线程数= corePoolSize时,新的任务会被添加到workQueue中,如果workQueue也满了则尝试用非核心线程执行任务,等待队列应该尽量用有界的。corePoolSize、workQueue、maximumPoolSize都不可用的时候执行的饱和策略。threadsPool.execute(new Runnable()
@Override public void run()
// TODO Auto-generated method stub
);
Future<Object> future = executor.submit(harReturnValuetask);
try Object s = future.get(); catch (InterruptedException e)
// 处理中断异常
catch (ExecutionException e)
// 处理无法执行任务异常
finally
// 关闭线程池 executor.shutdown();
shutdown或shutdownNow方法来关闭线程池。它们的原理是遍历线程池中的工作线程,然后逐个调用线程的interrupt方法来中断线程,所以无法响应中断的任务可能永远无法终止。停止接收外部submit的任务 内部正在跑的任务和队列里等待的任务,会执行完 等到第二步完成后,才真正停止
和shutdown()一样,先停止接收外部提交的任务 忽略队列里等待的任务 尝试将正在跑的任务interrupt中断 返回未执行的任务列表
shutdownNow()能立即停止线程池,正在跑的和正在等待的任务都停下了。这样做立即生效,但是风险也比较大。shutdown()只是关闭了提交通道,用submit()是无效的;而内部的任务该怎么跑还是怎么跑,跑完再彻底停止线程池。
计算密集型:大部分都在用CPU跟内存,加密,逻辑操作业务处理等。 IO密集型:数据库链接,网络通讯传输等。
Runtime.getRuntime().availableProcessors();
newFixedThreadPool (固定数目线程的线程池)
newCachedThreadPool (可缓存线程的线程池)
newSingleThreadExecutor (单线程的线程池)
newScheduledThreadPool (定时及周期执行的线程池)
public static ExecutorService newSingleThreadExecutor(ThreadFactory threadFactory)
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(),
threadFactory));
public static ExecutorService newFixedThreadPool(int nThreads, ThreadFactory threadFactory)
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(),
threadFactory);
public static ExecutorService newCachedThreadPool(ThreadFactory threadFactory)
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>(),
threadFactory);
public ScheduledThreadPoolExecutor(int corePoolSize)
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue());
//线程池状态
private static final int RUNNING = -1 << COUNT_BITS;
private static final int SHUTDOWN = 0 << COUNT_BITS;
private static final int STOP = 1 << COUNT_BITS;
private static final int TIDYING = 2 << COUNT_BITS;
private static final int TERMINATED = 3 << COUNT_BITS;
在我们微服务的架构下,可以利用配置中心如Nacos、Apollo等等,也可以自己开发配置中心。业务服务读取线程池配置,获取相应的线程池实例来修改线程池的参数。
如果限制了配置中心的使用,也可以自己去扩展ThreadPoolExecutor,重写方法,监听线程池参数变化,来动态修改线程池参数。
public class MyThreadPoolExecutor implements Executor
//记录线程池中线程数量
private final AtomicInteger ctl = new AtomicInteger(0);
//核心线程数
private volatile int corePoolSize;
//最大线程数
private volatile int maximumPoolSize;
//阻塞队列
private final BlockingQueue<Runnable> workQueue;
public MyThreadPoolExecutor(int corePoolSize, int maximumPoolSize, BlockingQueue<Runnable> workQueue)
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
/**
* 执行
*
* @param command
*/
@Override
public void execute(Runnable command)
//工作线程数
int c = ctl.get();
//小于核心线程数
if (c < corePoolSize)
//添加任务失败
if (!addWorker(command))
//执行拒绝策略
reject();
return;
//任务队列添加任务
if (!workQueue.offer(command))
//任务队列满,尝试启动线程添加任务
if (!addWorker(command))
reject();
/**
* 饱和拒绝
*/
private void reject()
//直接抛出异常
throw new RuntimeException("Can not execute!ctl.count:"
+ ctl.get() + "workQueue size:" + workQueue.size());
/**
* 添加任务
*
* @param firstTask
* @return
*/
private boolean addWorker(Runnable firstTask)
if (ctl.get() >= maximumPoolSize) return false;
Worker worker = new Worker(firstTask);
//启动线程
worker.thread.start();
ctl.incrementAndGet();
return true;
/**
* 线程池工作线程包装类
*/
private final class Worker implements Runnable
final Thread thread;
Runnable firstTask;
public Worker(Runnable firstTask)
this.thread = new Thread(this);
this.firstTask = firstTask;
@Override
public void run()
Runnable task = firstTask;
try
//执行任务
while (task != null || (task = getTask()) != null)
task.run();
//线程池已满,跳出循环
if (ctl.get() > maximumPoolSize)
break;
task = null;
finally
//工作线程数增加
ctl.decrementAndGet();
/**
* 从队列中获取任务
*
* @return
*/
private Runnable getTask()
for (; ; )
try
System.out.println("workQueue size:" + workQueue.size());
return workQueue.take();
catch (InterruptedException e)
e.printStackTrace();
//测试
public static void main(String[] args)
MyThreadPoolExecutor myThreadPoolExecutor = new MyThreadPoolExecutor(2, 2,
new ArrayBlockingQueue<Runnable>(10));
for (int i = 0; i < 10; i++)
int taskNum = i;
myThreadPoolExecutor.execute(() ->
try
Thread.sleep(1500);
catch (InterruptedException e)
e.printStackTrace();
System.out.println("任务编号:" + taskNum);
);
我们可以对正在处理和阻塞队列的任务做事务管理或者对阻塞队列中的任务持久化处理,并且当断电或者系统崩溃,操作无法继续下去的时候,可以通过回溯日志的方式来撤销
正在处理的已经执行成功的操作。然后重新执行整个阻塞队列。

要是以前有人这么讲线程池,我早就该明白了!

Executors:为什么阿里不待见我?

面试官:如何实现扫码登录功能?

面试字节,被操作系统问挂了

华强买瓜•程序员版
面渣逆袭:Java集合连环三十问
大家好,我是老三。上期发布了一篇:面渣逆袭:HashMap追魂二十三问,反响很好!

围观群众纷纷表示👇
不写,是不可能不写的,只有卷才能维持了生活这样子。
当然,我写的这一系列,不是背诵版,是理解版,很多地方都是在讲原理,内容也比较充足,死记硬背很难,大家一定要去理解性地去记忆。
这一篇,除了把之前的HashMap一些小错误进行修正,我还把相对“比较”简单的List也给请了进来,帮大家降降曲线,找找信心——用谢,留下赞就行。😀
引言
1.说说有哪些常见集合?
集合相关类和接口都在java.util中,主要分为3种:List(列表)、Map(映射)、Set(集)。
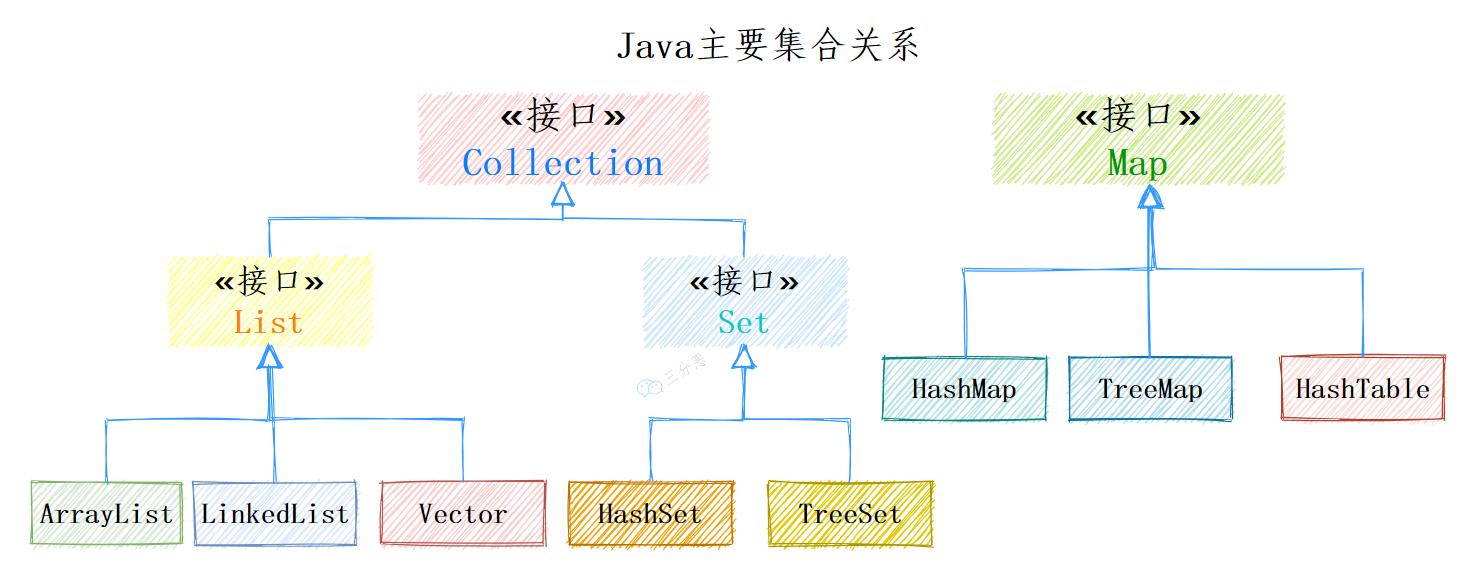
其中Collection是集合List、Set的父接口,它主要有两个子接口:
List:存储的元素有序,可重复。Set:存储的元素无序,不可重复。
Map是另外的接口,是键值对映射结构的集合。
List
List,也没啥好问的,但不排除面试官剑走偏锋,比如面试官也看了我这篇文章。
2.ArrayList和LinkedList有什么区别?
**(1)**数据结构不同
- ArrayList基于数组实现
- LinkedList基于双向链表实现

(2) 多数情况下,ArrayList更利于查找,LinkedList更利于增删
-
ArrayList基于数组实现,get(int index)可以直接通过数组下标获取,时间复杂度是O(1);LinkedList基于链表实现,get(int index)需要遍历链表,时间复杂度是O(n);当然,get(E element)这种查找,两种集合都需要遍历,时间复杂度都是O(n)。
-
ArrayList增删如果是数组末尾的位置,直接插入或者删除就可以了,但是如果插入中间的位置,就需要把插入位置后的元素都向前或者向后移动,甚至还有可能触发扩容;双向链表的插入和删除只需要改变前驱节点、后继节点和插入节点的指向就行了,不需要移动元素。


注意,这个地方可能会出陷阱,LinkedList更利于增删更多是体现在平均步长上,不是体现在时间复杂度上,二者增删的时间复杂度都是O(n)
**(3)**是否支持随机访问
- ArrayList基于数组,所以它可以根据下标查找,支持随机访问,当然,它也实现了RandmoAccess 接口,这个接口只是用来标识是否支持随机访问。
- LinkedList基于链表,所以它没法根据序号直接获取元素,它没有实现RandmoAccess 接口,标记不支持随机访问。
**(4)**内存占用,ArrayList基于数组,是一块连续的内存空间,LinkedList基于链表,内存空间不连续,它们在空间占用上都有一些额外的消耗:
- ArrayList是预先定义好的数组,可能会有空的内存空间,存在一定空间浪费
- LinkedList每个节点,需要存储前驱和后继,所以每个节点会占用更多的空间
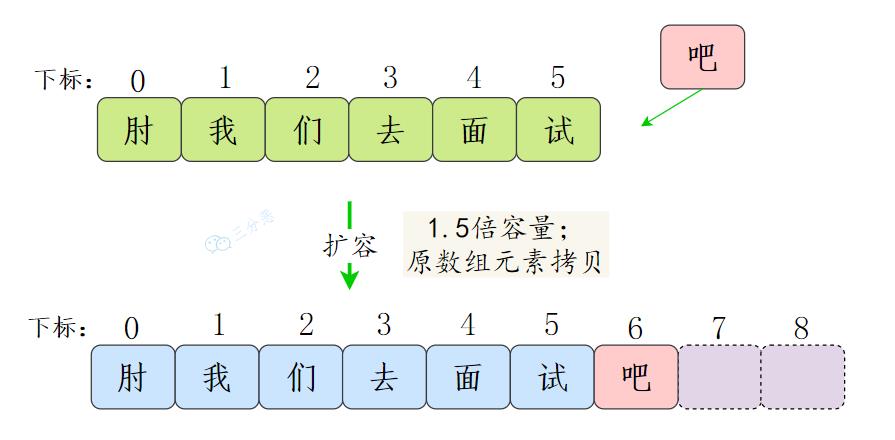
3.ArrayList的扩容机制了解吗?
ArrayList是基于数组的集合,数组的容量是在定义的时候确定的,如果数组满了,再插入,就会数组溢出。所以在插入时候,会先检查是否需要扩容,如果当前容量+1超过数组长度,就会进行扩容。
ArrayList的扩容是创建一个1.5倍的新数组,然后把原数组的值拷贝过去。
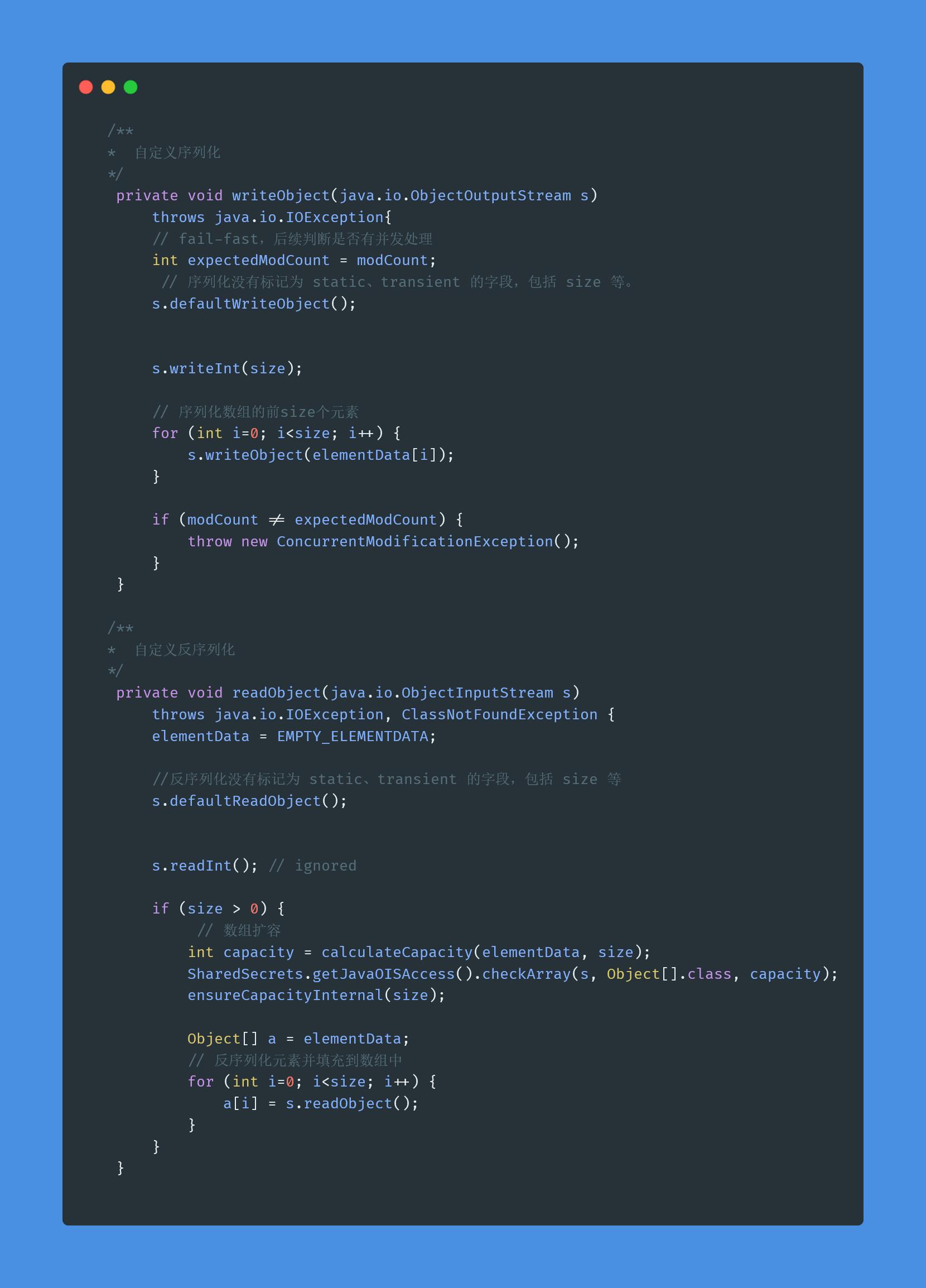
4.ArrayList怎么序列化的知道吗? 为什么用transient修饰数组?
ArrayList的序列化不太一样,它使用transient修饰存储元素的elementData的数组,transient关键字的作用是让被修饰的成员属性不被序列化。
为什么最ArrayList不直接序列化元素数组呢?
出于效率的考虑,数组可能长度100,但实际只用了50,剩下的50不用其实不用序列化,这样可以提高序列化和反序列化的效率,还可以节省内存空间。
那ArrayList怎么序列化呢?
ArrayList通过两个方法readObject、writeObject自定义序列化和反序列化策略,实际直接使用两个流ObjectOutputStream和ObjectInputStream来进行序列化和反序列化。
5.快速失败(fail-fast)和安全失败(fail-safe)了解吗?
快速失败(fail—fast):快速失败是Java集合的一种错误检测机制
- 在用迭代器遍历一个集合对象时,如果线程A遍历过程中,线程B对集合对象的内容进行了修改(增加、删除、修改),则会抛出Concurrent Modification Exception。
- 原理:迭代器在遍历时直接访问集合中的内容,并且在遍历过程中使用一个
modCount变量。集合在被遍历期间如果内容发生变化,就会改变modCount的值。每当迭代器使用hashNext()/next()遍历下一个元素之前,都会检测modCount变量是否为expectedmodCount值,是的话就返回遍历;否则抛出异常,终止遍历。 - 注意:这里异常的抛出条件是检测到 modCount!=expectedmodCount 这个条件。如果集合发生变化时修改modCount值刚好又设置为了expectedmodCount值,则异常不会抛出。因此,不能依赖于这个异常是否抛出而进行并发操作的编程,这个异常只建议用于检测并发修改的bug。
- 场景:java.util包下的集合类都是快速失败的,不能在多线程下发生并发修改(迭代过程中被修改),比如ArrayList 类。
安全失败(fail—safe)
- 采用安全失败机制的集合容器,在遍历时不是直接在集合内容上访问的,而是先复制原有集合内容,在拷贝的集合上进行遍历。
- 原理:由于迭代时是对原集合的拷贝进行遍历,所以在遍历过程中对原集合所作的修改并不能被迭代器检测到,所以不会触发Concurrent Modification Exception。
- 缺点:基于拷贝内容的优点是避免了Concurrent Modification Exception,但同样地,迭代器并不能访问到修改后的内容,即:迭代器遍历的是开始遍历那一刻拿到的集合拷贝,在遍历期间原集合发生的修改迭代器是不知道的。
- 场景:java.util.concurrent包下的容器都是安全失败,可以在多线程下并发使用,并发修改,比如CopyOnWriteArrayList类。
6.有哪几种实现ArrayList线程安全的方法?
fail-fast是一种可能触发的机制,实际上,ArrayList的线程安全仍然没有保证,一般,保证ArrayList的线程安全可以通过这些方案:
- 使用 Vector 代替 ArrayList。(不推荐,Vector是一个历史遗留类)
- 使用 Collections.synchronizedList 包装 ArrayList,然后操作包装后的 list。
- 使用 CopyOnWriteArrayList 代替 ArrayList。
- 在使用 ArrayList 时,应用程序通过同步机制去控制 ArrayList 的读写。
7.CopyOnWriteArrayList了解多少?
CopyOnWriteArrayList就是线程安全版本的ArrayList。
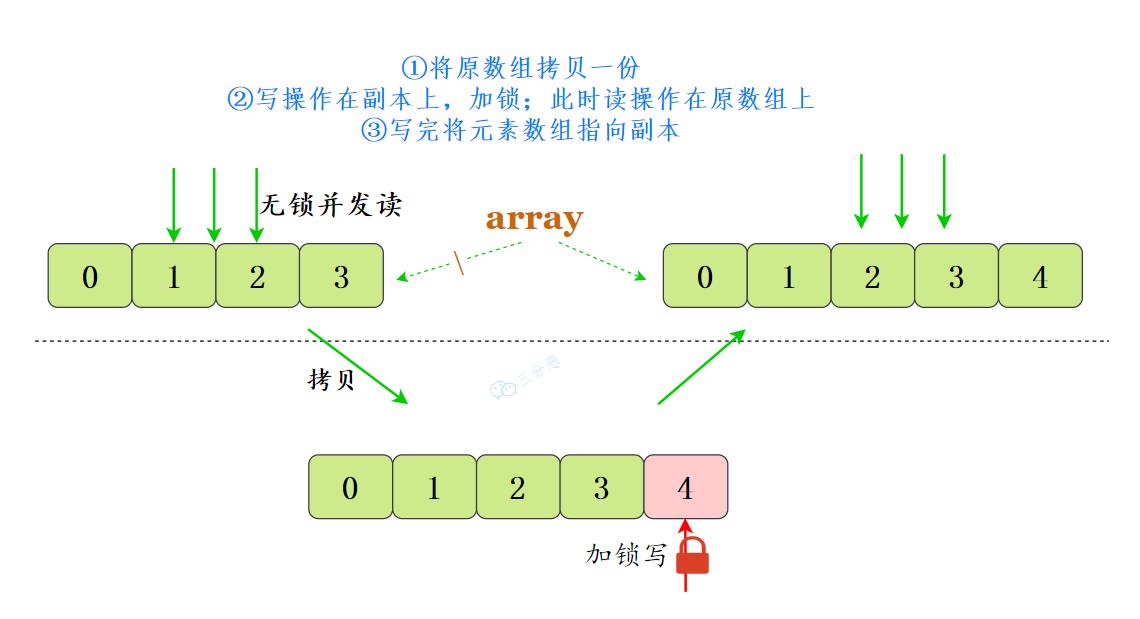
它的名字叫CopyOnWrite——写时复制,已经明示了它的原理。
CopyOnWriteArrayList采用了一种读写分离的并发策略。CopyOnWriteArrayList容器允许并发读,读操作是无锁的,性能较高。至于写操作,比如向容器中添加一个元素,则首先将当前容器复制一份,然后在新副本上执行写操作,结束之后再将原容器的引用指向新容器。
Map
Map中,毫无疑问,最重要的就是HashMap,面试基本被盘出包浆了,各种问法,一定要好好准备。
8.能说一下HashMap的数据结构吗?
JDK1.7的数据结构是数组+链表,JDK1.7还有人在用?不会吧……
说一下JDK1.8的数据结构吧:
JDK1.8的数据结构是数组+链表+红黑树。
数据结构示意图如下:
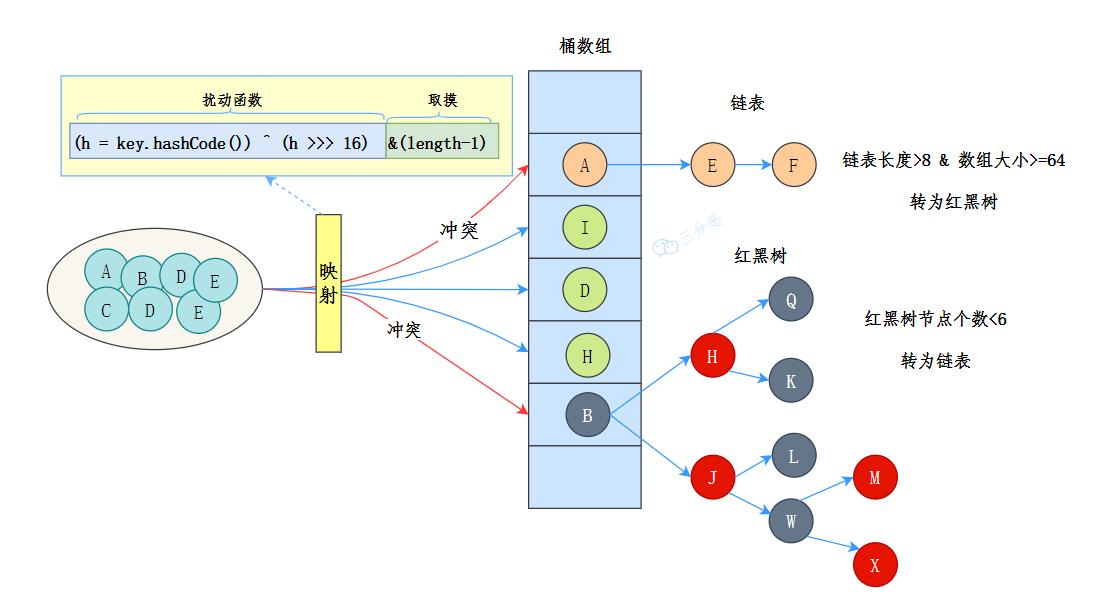
其中,桶数组是用来存储数据元素,链表是用来解决冲突,红黑树是为了提高查询的效率。
- 数据元素通过映射关系,也就是散列函数,映射到桶数组对应索引的位置
- 如果发生冲突,从冲突的位置拉一个链表,插入冲突的元素
- 如果链表长度>8&数组大小>=64,链表转为红黑树
- 如果红黑树节点个数<6 ,转为链表
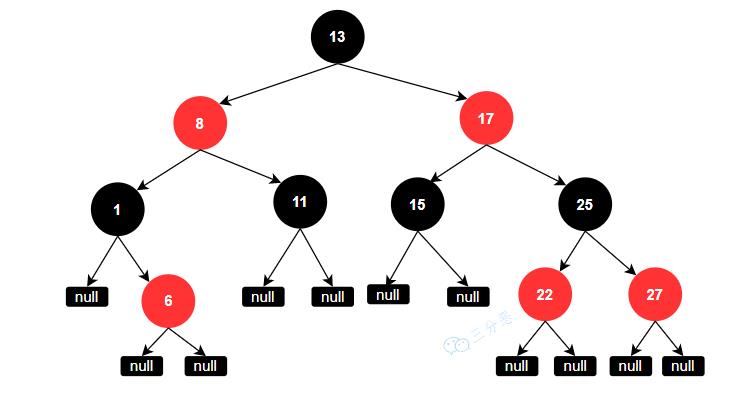
9.你对红黑树了解多少?为什么不用二叉树/平衡树呢?
红黑树本质上是一种二叉查找树,为了保持平衡,它又在二叉查找树的基础上增加了一些规则:
- 每个节点要么是红色,要么是黑色;
- 根节点永远是黑色的;
- 所有的叶子节点都是是黑色的(注意这里说叶子节点其实是图中的 NULL 节点);
- 每个红色节点的两个子节点一定都是黑色;
- 从任一节点到其子树中每个叶子节点的路径都包含相同数量的黑色节点;
之所以不用二叉树:
红黑树是一种平衡的二叉树,插入、删除、查找的最坏时间复杂度都为 O(logn),避免了二叉树最坏情况下的O(n)时间复杂度。
之所以不用平衡二叉树:
平衡二叉树是比红黑树更严格的平衡树,为了保持保持平衡,需要旋转的次数更多,也就是说平衡二叉树保持平衡的效率更低,所以平衡二叉树插入和删除的效率比红黑树要低。
10.红黑树怎么保持平衡的知道吗?
红黑树有两种方式保持平衡:旋转和染色。
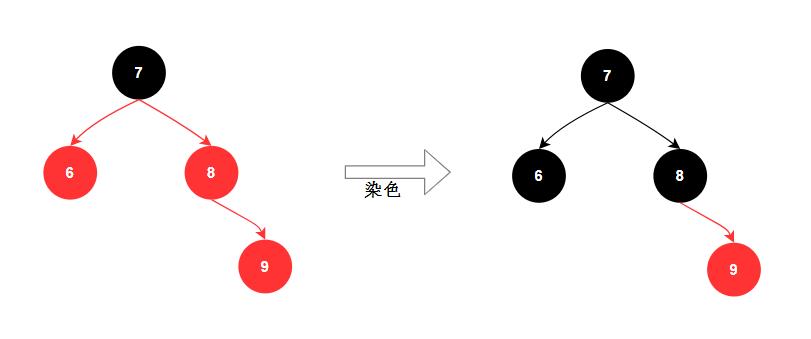
- 旋转:旋转分为两种,左旋和右旋
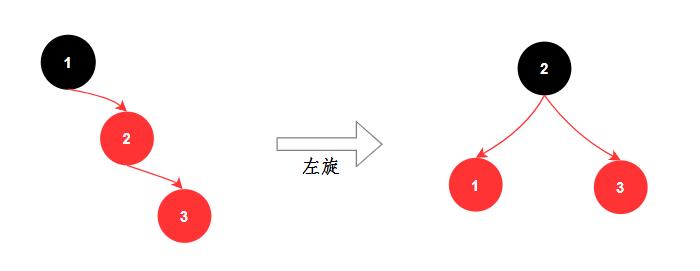
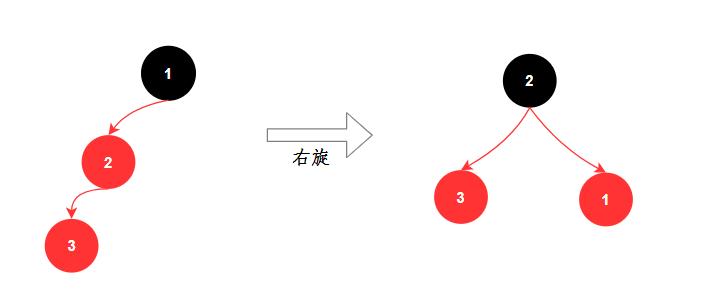
- 染⾊:
11.HashMap的put流程知道吗?
先上个流程图吧:

-
首先进行哈希值的扰动,获取一个新的哈希值。
(key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); -
判断tab是否位空或者长度为0,如果是则进行扩容操作。
if ((tab = table) == null || (n = tab.length) == 0) n = (tab = resize()).length; -
根据哈希值计算下标,如果对应小标正好没有存放数据,则直接插入即可否则需要覆盖。
tab[i = (n - 1) & hash]) -
判断tab[i]是否为树节点,否则向链表中插入数据,是则向树中插入节点。
-
如果链表中插入节点的时候,链表长度大于等于8,则需要把链表转换为红黑树。
treeifyBin(tab, hash); -
最后所有元素处理完成后,判断是否超过阈值;
threshold,超过则扩容。
12.HashMap怎么查找元素的呢?
先看流程图:
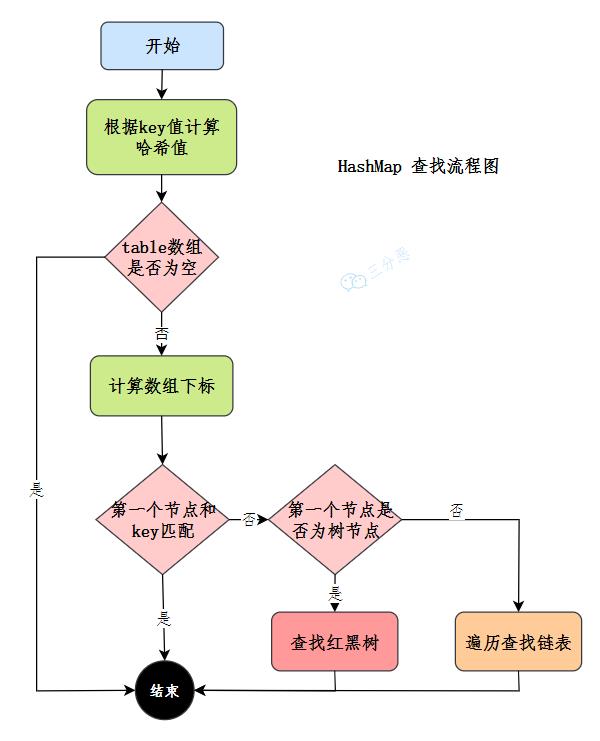
HashMap的查找就简单很多:
- 使用扰动函数,获取新的哈希值
- 计算数组下标,获取节点
- 当前节点和key匹配,直接返回
- 否则,当前节点是否为树节点,查找红黑树
- 否则,遍历链表查找
13.HashMap的哈希/扰动函数是怎么设计的?
HashMap的哈希函数是先拿到 key 的hashcode,是一个32位的int类型的数值,然后让hashcode的高16位和低16位进行异或操作。
static final int hash(Object key)
int h;
// key的hashCode和key的hashCode右移16位做异或运算
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
这么设计是为了降低哈希碰撞的概率。
14.为什么哈希/扰动函数能降hash碰撞?
因为 key.hashCode() 函数调用的是 key 键值类型自带的哈希函数,返回 int 型散列值。int 值范围为 -2147483648~2147483647,加起来大概 40 亿的映射空间。
只要哈希函数映射得比较均匀松散,一般应用是很难出现碰撞的。但问题是一个 40 亿长度的数组,内存是放不下的。
假如 HashMap 数组的初始大小才 16,就需要用之前需要对数组的长度取模运算,得到的余数才能用来访问数组下标。
源码中模运算就是把散列值和数组长度 - 1 做一个 “与&” 操作,位运算比取余 % 运算要快。
bucketIndex = indexFor(hash, table.length);
static int indexFor(int h, int length)
return h & (length-1);
顺便说一下,这也正好解释了为什么 HashMap 的数组长度要取 2 的整数幂。因为这样(数组长度 - 1)正好相当于一个 “低位掩码”。与 操作的结果就是散列值的高位全部归零,只保留低位值,用来做数组下标访问。以初始长度 16 为例,16-1=15。2 进制表示是0000 0000 0000 0000 0000 0000 0000 1111。和某个散列值做 与 操作如下,结果就是截取了最低的四位值。
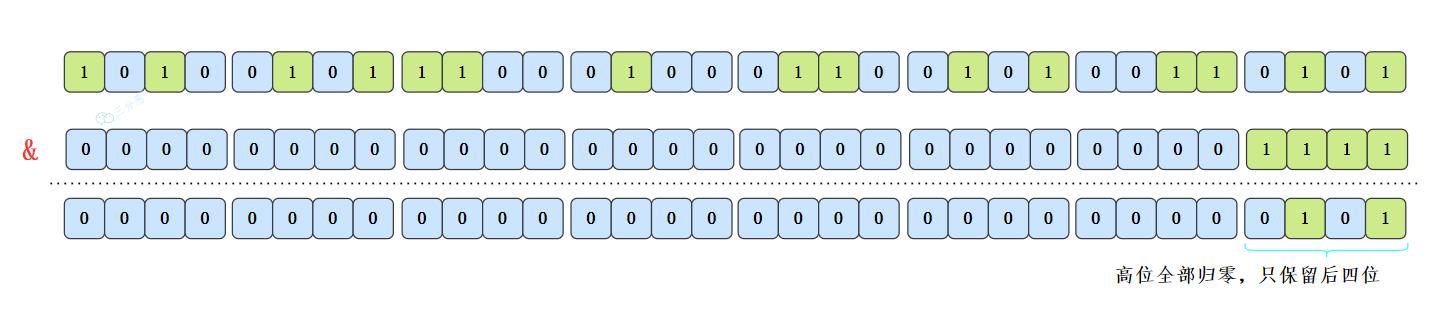
这样是要快捷一些,但是新的问题来了,就算散列值分布再松散,要是只取最后几位的话,碰撞也会很严重。如果散列本身做得不好,分布上成等差数列的漏洞,如果正好让最后几个低位呈现规律性重复,那就更难搞了。
这时候 扰动函数 的价值就体现出来了,看一下扰动函数的示意图:
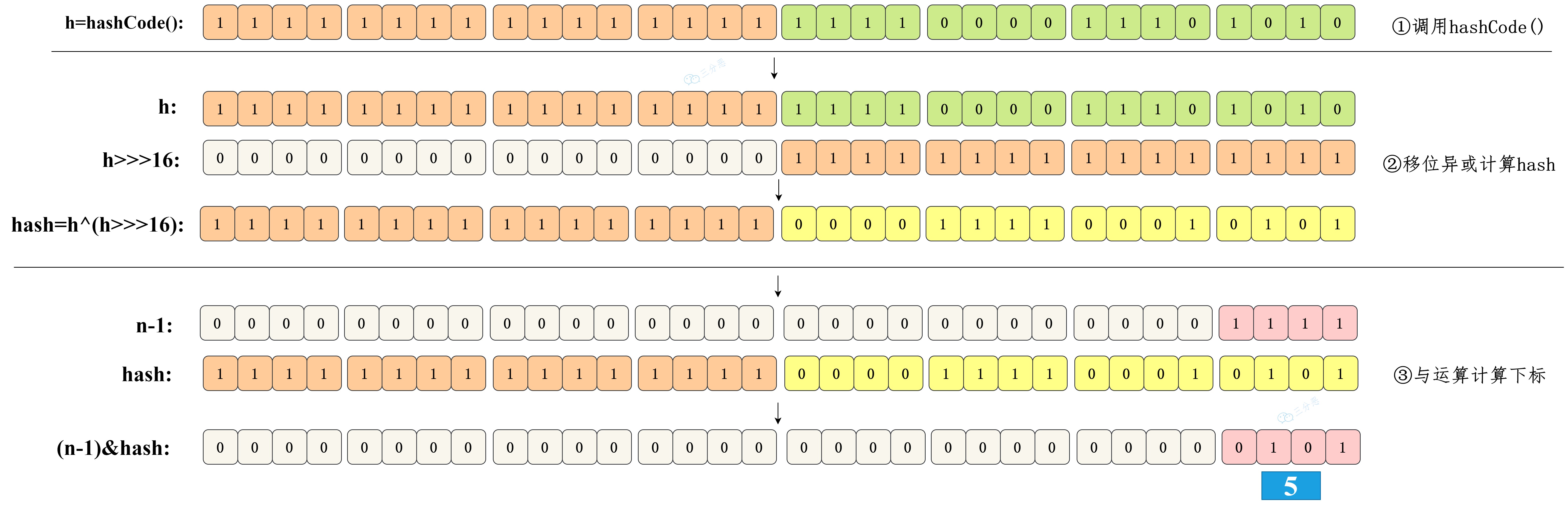
右移 16 位,正好是 32bit 的一半,自己的高半区和低半区做异或,就是为了混合原始哈希码的高位和低位,以此来加大低位的随机性。而且混合后的低位掺杂了高位的部分特征,这样高位的信息也被变相保留下来。
15.为什么HashMap的容量是2的倍数呢?
- 第一个原因是为了方便哈希取余:
将元素放在table数组上面,是用hash值%数组大小定位位置,而HashMap是用hash值&(数组大小-1),却能和前面达到一样的效果,这就得益于HashMap的大小是2的倍数,2的倍数意味着该数的二进制位只有一位为1,而该数-1就可以得到二进制位上1变成0,后面的0变成1,再通过&运算,就可以得到和%一样的效果,并且位运算比%的效率高得多
HashMap的容量是2的n次幂时,(n-1)的2进制也就是1111111***111这样形式的,这样与添加元素的hash值进行位运算时,能够充分的散列,使得添加的元素均匀分布在HashMap的每个位置上,减少hash碰撞。
- 第二个方面是在扩容时,利用扩容后的大小也是2的倍数,将已经产生hash碰撞的元素完美的转移到新的table中去
我们可以简单看看HashMap的扩容机制,HashMap中的元素在超过负载因子*HashMap大小时就会产生扩容。

16.如果初始化HashMap,传一个17的值new HashMap<>,它会怎么处理?
简单来说,就是初始化时,传的不是2的倍数时,HashMap会向上寻找离得最近的2的倍数,所以传入17,但HashMap的实际容量是32。
我们来看看详情,在HashMap的初始化中,有这样⼀段⽅法;
public HashMap(int initialCapacity, float loadFactor)
...
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
- 阀值 threshold ,通过⽅法
tableSizeFor进⾏计算,是根据初始化传的参数来计算的。 - 同时,这个⽅法也要要寻找⽐初始值⼤的,最⼩的那个2进制数值。⽐如传了17,我应该找到的是32。
static final int tableSizeFor(int cap)
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
- MAXIMUM_CAPACITY = 1 << 30,这个是临界范围,也就是最⼤的Map集合。
- 计算过程是向右移位1、2、4、8、16,和原来的数做
|运算,这主要是为了把⼆进制的各个位置都填上1,当⼆进制的各个位置都是1以后,就是⼀个标准的2的倍数减1了,最后把结果加1再返回即可。
以17为例,看一下初始化计算table容量的过程:

17.你还知道哪些哈希函数的构造方法呢?
HashMap里哈希构造函数的方法叫:
- 除留取余法:H(key)=key%p(p<=N),关键字除以一个不大于哈希表长度的正整数p,所得余数为地址,当然HashMap里进行了优化改造,效率更高,散列也更均衡。
除此之外,还有这几种常见的哈希函数构造方法:
-
直接定址法
直接根据
key来映射到对应的数组位置,例如1232放到下标1232的位置。 -
数字分析法
取
key的某些数字(例如十位和百位)作为映射的位置 -
平方取中法
取
key平方的中间几位作为映射的位置 -
折叠法
将
key分割成位数相同的几段,然后把它们的叠加和作为映射的位置
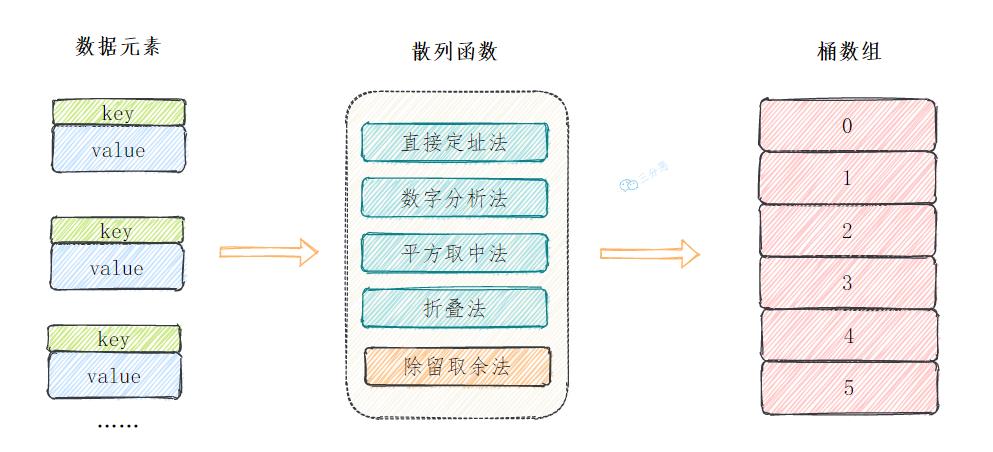
18.解决哈希冲突有哪些方法呢?
我们到现在已经知道,HashMap使用链表的原因为了处理哈希冲突,这种方法就是所谓的:
- 链地址法:在冲突的位置拉一个链表,把冲突的元素放进去。
除此之外,还有一些常见的解决冲突的办法:
-
开放定址法:开放定址法就是从冲突的位置再接着往下找,给冲突元素找个空位。
找到空闲位置的方法也有很多种:
- 线行探查法: 从冲突的位置开始,依次判断下一个位置是否空闲,直至找到空闲位置
- 平方探查法: 从冲突的位置x开始,第一次增加
1^2个位置,第二次增加2^2…,直至找到空闲的位置 - ……
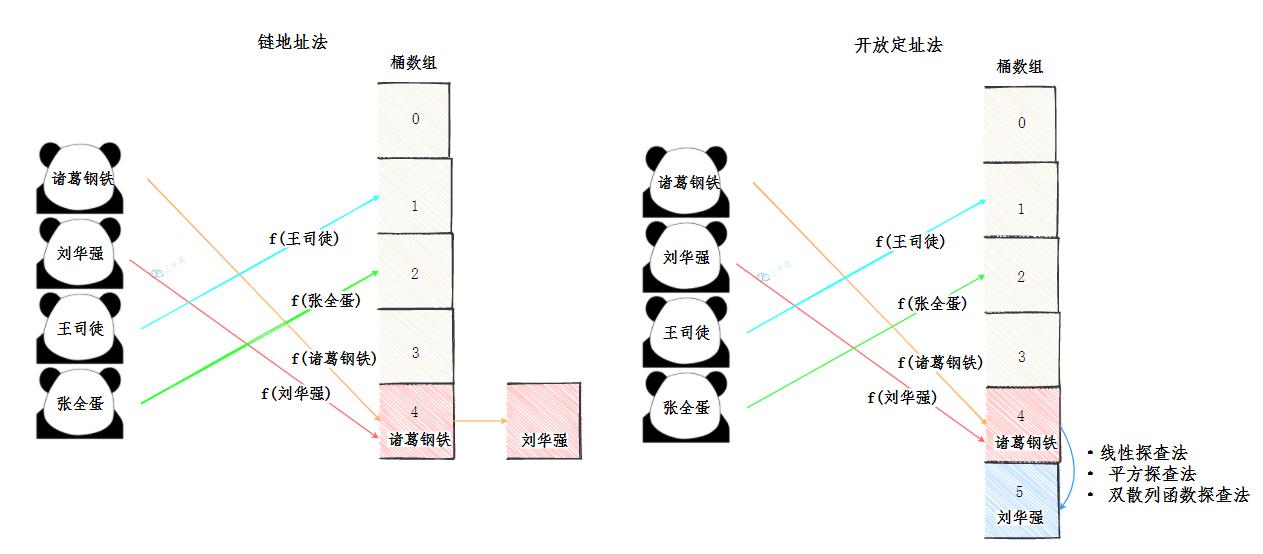
- 再哈希法:换种哈希函数,重新计算冲突元素的地址。
- 建立公共溢出区:再建一个数组,把冲突的元素放进去。
19.为什么HashMap链表转红黑树的阈值为8呢?
树化发生在table数组的长度大于64,且链表的长度大于8的时候。
为什么是8呢?源码的注释也给出了答案。
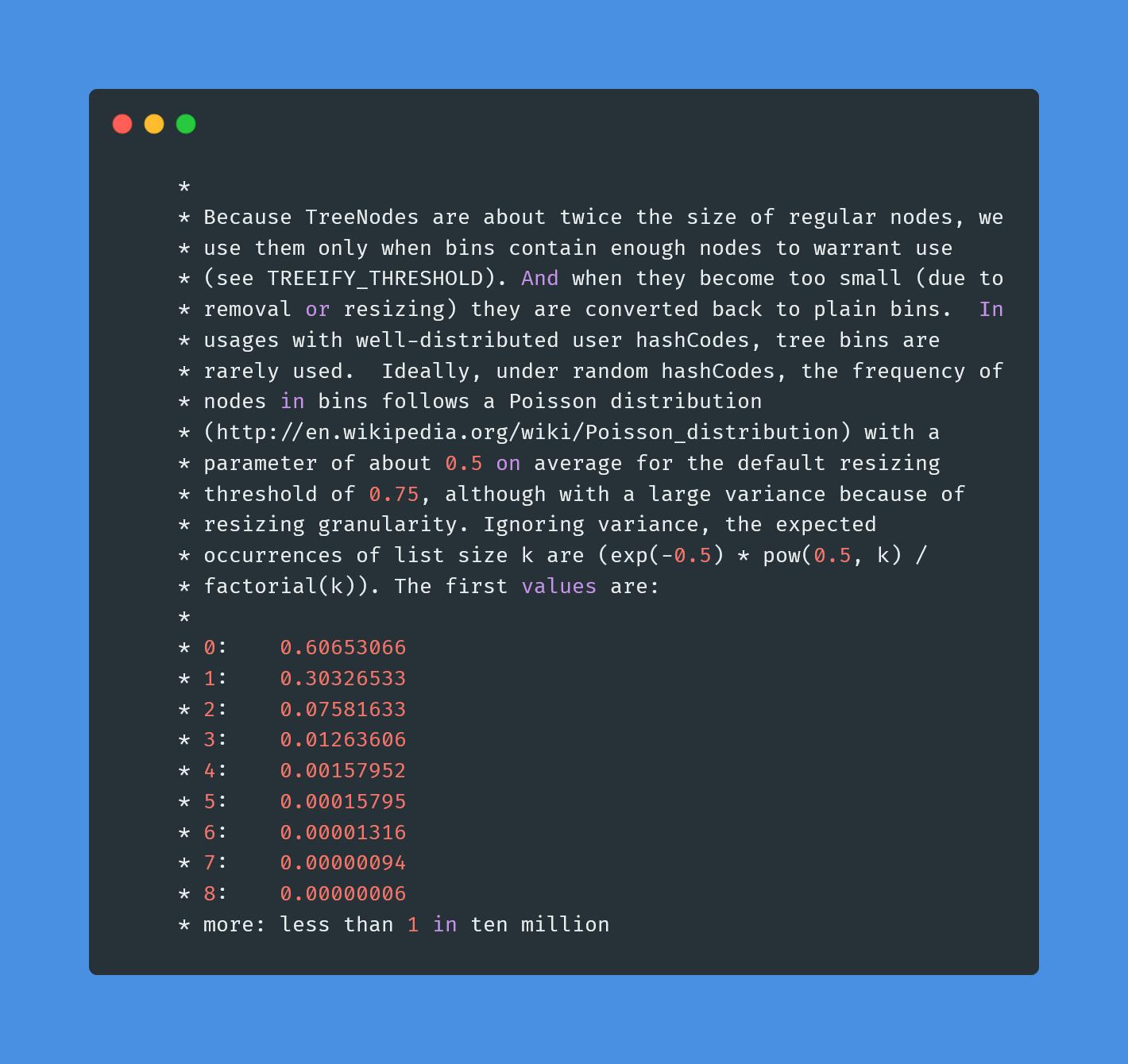
红黑树节点的大小大概是普通节点大小的两倍,所以转红黑树,牺牲了空间换时间,更多的是一种兜底的策略,保证极端情况下的查找效率。
阈值为什么要选8呢?和统计学有关。理想情况下,使用随机哈希码,链表里的节点符合泊松分布,出现节点个数的概率是递减的,节点个数为8的情况,发生概率仅为0.00000006。
至于红黑树转回链表的阈值为什么是6,而不是8?是因为如果这个阈值也设置成8,假如发生碰撞,节点增减刚好在8附近,会发生链表和红黑树的不断转换,导致资源浪费。
20.扩容在什么时候呢?为什么扩容因子是0.75?
为了减少哈希冲突发生的概率,当当前HashMap的元素个数达到一个临界值的时候,就会触发扩容,把所有元素rehash之后再放在扩容后的容器中,这是一个相当耗时的操作。

而这个临界值threshold就是由加载因子和当前容器的容量大小来确定的,假如采用默认的构造方法:
临界值(threshold )= 默认容量(DEFAULT_INITIAL_CAPACITY) * 默认扩容因子(DEFAULT_LOAD_FACTOR)
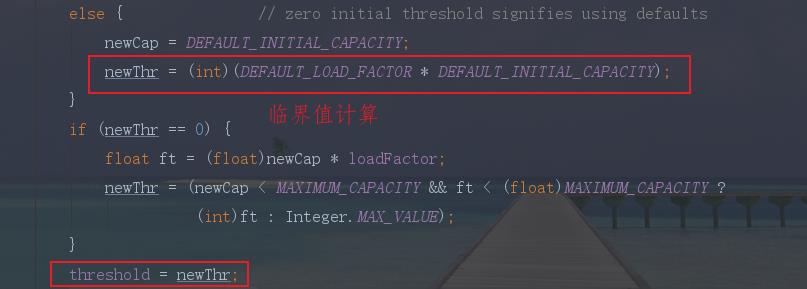
那就是大于16x0.75=12时,就会触发扩容操作。
那么为什么选择了0.75作为HashMap的默认加载因子呢?
简单来说,这是对空间成本和时间成本平衡的考虑。
在HashMap中有这样一段注释:

我们都知道,HashMap的散列构造方式是Hash取余,负载因子决定元素个数达到多少时候扩容。
假如我们设的比较大,元素比较多,空位比较少的时候才扩容,那么发生哈希冲突的概率就增加了,查找的时间成本就增加了。
我们设的比较小的话,元素比较少,空位比较多的时候就扩容了,发生哈希碰撞的概率就降低了,查找时间成本降低,但是就需要更多的空间去存储元素,空间成本就增加了。
21.那扩容机制了解吗?
HashMap是基于数组+链表和红黑树实现的,但用于存放key值的桶数组的长度是固定的,由初始化参数确定。
那么,随着数据的插入数量增加以及负载因子的作用下,就需要扩容来存放更多的数据。而扩容中有一个非常重要的点,就是jdk1.8中的优化操作,可以不需要再重新计算每一个元素的哈希值。
因为HashMap的初始容量是2的次幂,扩容之后的长度是原来的二倍,新的容量也是2的次幂,所以,元素,要么在原位置,要么在原位置再移动2的次幂。
看下这张图,n为table的长度,图a表示扩容前的key1和key2两种key确定索引的位置,图b表示扩容后key1和key2两种key确定索引位置。

元素在重新计算hash之后,因为n变为2倍,那么n-1的mask范围在高位多1bit(红色),因此新的index就会发生这样的变化:

所以在扩容时,只需要看原来的hash值新增的那一位是0还是1就行了,是0的话索引没变,是1的化变成原索引+oldCap,看看如16扩容为32的示意图:
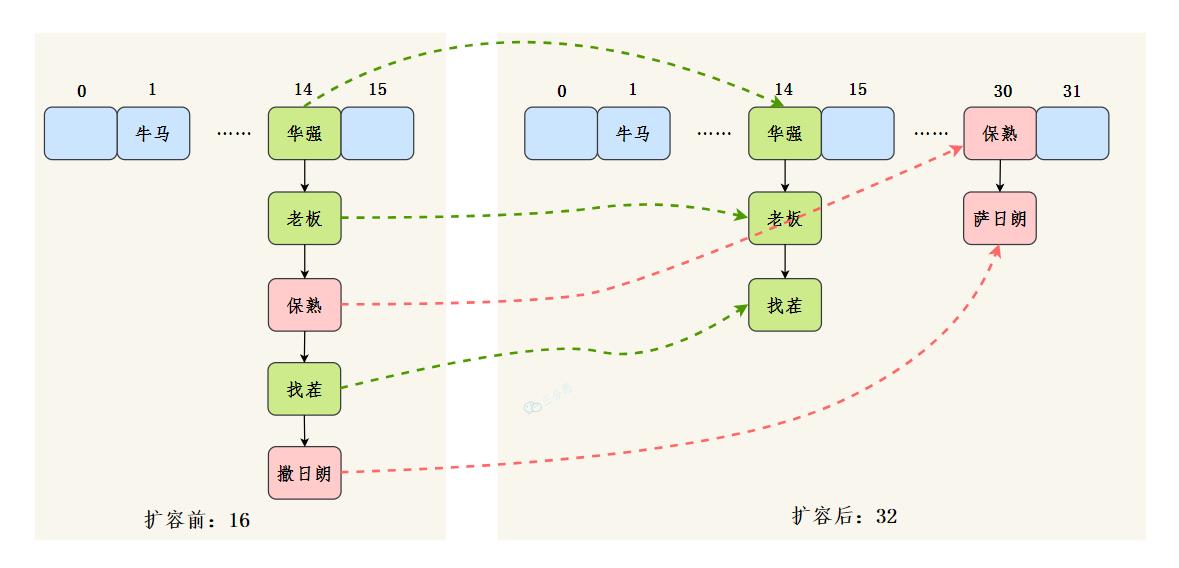
扩容节点迁移主要逻辑:

22.jdk1.8对HashMap主要做了哪些优化呢?为什么?
jdk1.8 的HashMap主要有五点优化:
-
数据结构:数组 + 链表改成了数组 + 链表或红黑树
原因:发生 hash 冲突,元素会存入链表,链表过长转为红黑树,将时间复杂度由O(n)降为O(logn) -
链表插入方式:链表的插入方式从头插法改成了尾插法
简单说就是插入时,如果数组位置上已经有元素,1.7 将新元素放到数组中,原始节点作为新节点的后继节点,1.8 遍历链表,将元素放置到链表的最后。
原因:因为 1.7 头插法扩容时,头插法会使链表发生反转,多线程环境下会产生环。 -
扩容rehash:扩容的时候 1.7 需要对原数组中的元素进行重新 hash 定位在新数组的位置,1.8 采用更简单的判断逻辑,不需要重新通过哈希函数计算位置,新的位置不变或索引 + 新增容量大小。
原因:提高扩容的效率,更快地扩容。 -
扩容时机:在插入时,1.7 先判断是否需要扩容,再插入,1.8 先进行插入,插入完成再判断是否需要扩容;
-
散列函数:1.7 做了四次移位和四次异或,jdk1.8只做一次。
原因:做 4 次的话,边际效用也不大,改为一次,提升效率。
23.你能自己设计实现一个HashMap吗?
这道题快手常考。
不要慌,红黑树版咱们多半是写不出来,但是数组+链表版还是问题不大的,详细可见: 手写HashMap,快手面试官直呼内行!。
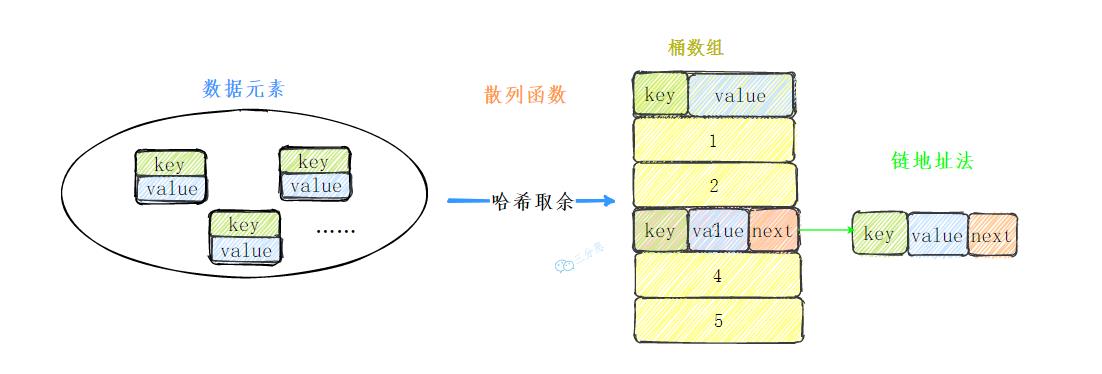
整体的设计:
- 散列函数:hashCode()+除留余数法
- 冲突解决:链地址法
- 扩容:节点重新hash获取位置
完整代码:

24.HashMap 是线程安全的吗?多线程下会有什么问题?
HashMap不是线程安全的,可能会发生这些问题:
-
多线程下扩容死循环。JDK1.7 中的 HashMap 使用头插法插入元素,在多线程的环境下,扩容的时候有可能导致环形链表的出现,形成死循环。因此,JDK1.8 使用尾插法插入元素,在扩容时会保持链表元素原本的顺序,不会出现环形链表的问题。
-
多线程的 put 可能导致元素的丢失。多线程同时执行 put 操作,如果计算出来的索引位置是相同的,那会造成前一个 key 被后一个 key 覆盖,从而导致元素的丢失。此问题在 JDK 1.7 和 JDK 1.8 中都存在。
-
put 和 get 并发时,可能导致 get 为 null。线程 1 执行 put 时,因为元素个数超出 threshold 而导致 rehash,线程 2 此时执行 get,有可能导致这个问题。这个问题在 JDK 1.7 和 JDK 1.8 中都存在。
25.有什么办法能解决HashMap线程不安全的问题呢?
Java 中有 HashTable、Collections.synchronizedMap、以及 ConcurrentHashMap 可以实现线程安全的 Map。
- HashTable 是直接在操作方法上加 synchronized 关键字,锁住整个table数组,粒度比较大;
- Collections.synchronizedMap 是使用 Collections 集合工具的内部类,通过传入 Map 封装出一个 SynchronizedMap 对象,内部定义了一个对象锁,方法内通过对象锁实现;
- ConcurrentHashMap 在jdk1.7中使用分段锁,在jdk1.8中使用CAS+synchronized。
26.能具体说一下ConcurrentHashmap的实现吗?
ConcurrentHashmap线程安全在jdk1.7版本是基于分段锁实现,在jdk1.8是基于CAS+synchronized实现。
1.7分段锁
从结构上说,1.7版本的ConcurrentHashMap采用分段锁机制,里面包含一个Segment数组,Segment继承于ReentrantLock,Segment则包含HashEntry的数组,HashEntry本身就是一个链表的结构,具有保存key、value的能力能指向下一个节点的指针。
实际上就是相当于每个Segment都是一个HashMap,默认的Segment长度是16,也就是支持16个线程的并发写,Segment之间相互不会受到影响。

put流程
整个流程和HashMap非常类似,只不过是先定位到具体的Segment,然后通过ReentrantLock去操作而已,后面的流程,就和HashMap基本上是一样的。
- 计算hash,定位到segment,segment如果是空就先初始化
- 使用ReentrantLock加锁,如果获取锁失败则尝试自旋,自旋超过次数就阻塞获取,保证一定获取锁成功
- 遍历HashEntry,就是和HashMap一样,数组中key和hash一样就直接替换,不存在就再插入链表,链表同样操作
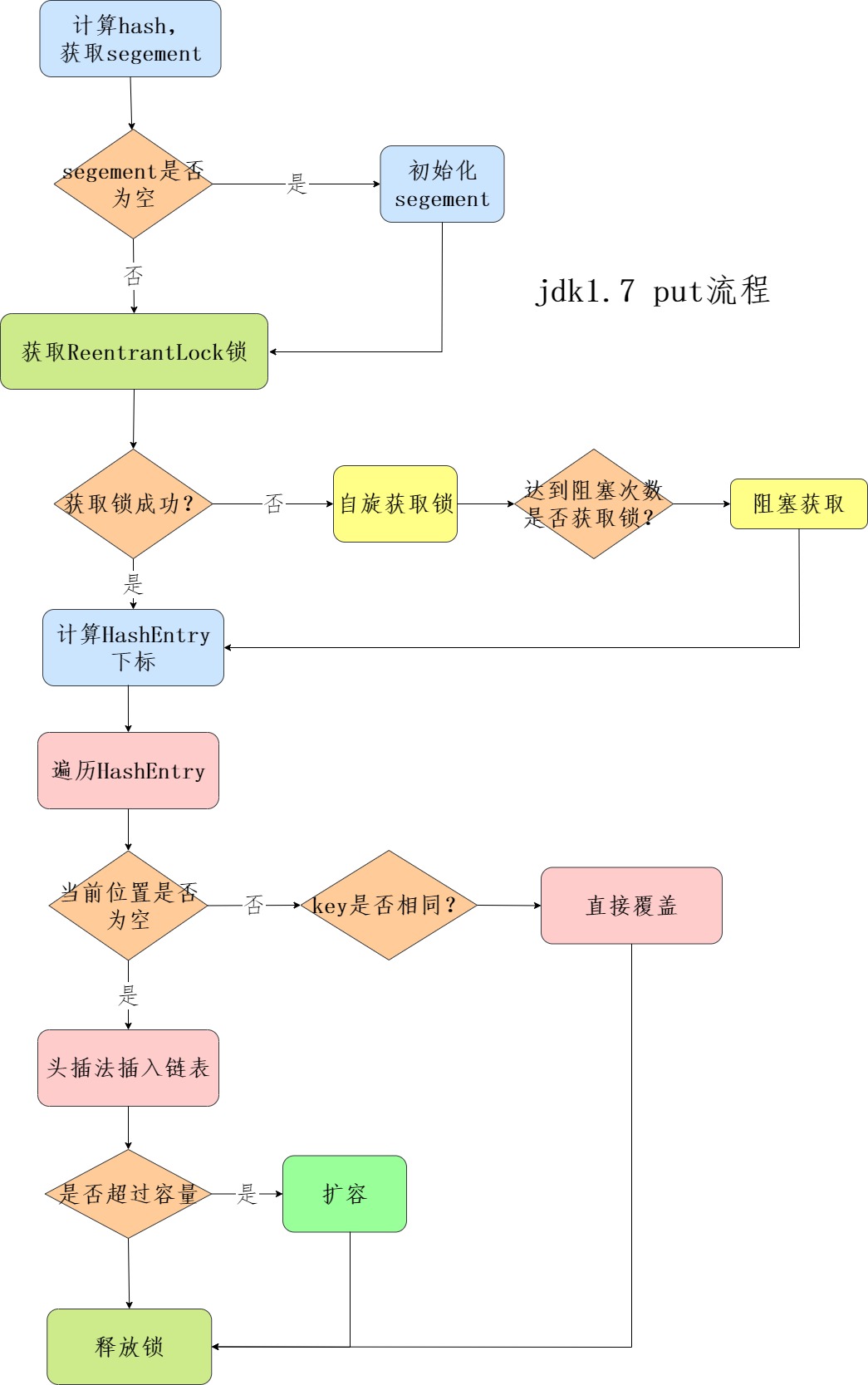
get流程
get也很简单,key通过hash定位到segment,再遍历链表定位到具体的元素上,需要注意的是value是volatile的,所以get是不需要加锁的。
1.8 CAS+synchronized
jdk1.8实现线程安全不是在数据结构上下功夫,它的数据结构和HashMap是一样的,数组+链表+红黑树。它实现线程安全的关键点在于put流程。
put流程
- 首先计算hash,遍历node数组,如果node是空的话,就通过CAS+自旋的方式初始化
tab = initTable();
node数组初始化:
private final Node<K,V>[] initTable()
Node<K,V>[] tab; int sc;
while ((tab = table) == null || tab.length == 0)
//如果正在初始化或者扩容
if ((sc = sizeCtl) < 0)
//等待
Thread.yield(); // lost initialization race; just spin
else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) //CAS操作
try
if ((tab = table) == null || tab.length == 0)
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
table = tab = nt;
sc = n - (n >>> 2);
finally
sizeCtl = sc;
break;
return tab;
2.如果当前数组位置是空则直接通过CAS自旋写入数据
static final <K,V> boolean casTabAt(Node<K,V>[] tab, int i,
Node<K,V> c, Node<K,V> v)
return U.compareAndSwapObject(tab, ((long)i << ASHIFT) + ABASE, c, v);
- 如果hash==MOVED,说明需要扩容,执行扩容
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
final Node<K,V>[] helpTransfer(Node<K,V>[] tab, Node<K,V> f)
Node<K,V>[] nextTab; int sc;
if (tab != null && (f instanceof ForwardingNode) &&
(nextTab = ((ForwardingNode<K,V>)f).nextTable) != null)
int rs = resizeStamp(tab.length);
while (nextTab == nextTable && table == tab &&
(sc = sizeCtl) < 0)
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || transferIndex <= 0)
break;
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1))
transfer(tab, nextTab);
break;
return nextTab;
return table;
- 如果都不满足,就使用synchronized写入数据,写入数据同样判断链表、红黑树,链表写入和HashMap的方式一样,key hash一样就覆盖,反之就尾插法,链表长度超过8就转换成红黑树
synchronized (f)
……

get查询
get很简单,和HashMap基本相同,通过key计算位置,table该位置key相同就返回,如果是红黑树按照红黑树获取,否则就遍历链表获取。
27.HashMap 内部节点是有序的吗?
HashMap是无序的,根据 hash 值随机插入。如果想使用有序的Map,可以使用LinkedHashMap 或者 TreeMap。
28.讲讲 LinkedHashMap 怎么实现有序的?
LinkedHashMap维护了一个双向链表,有头尾节点,同时 LinkedHashMap 节点 Entry 内部除了继承 HashMap 的 Node 属性,还有 before 和 after 用于标识前置节点和后置节点。
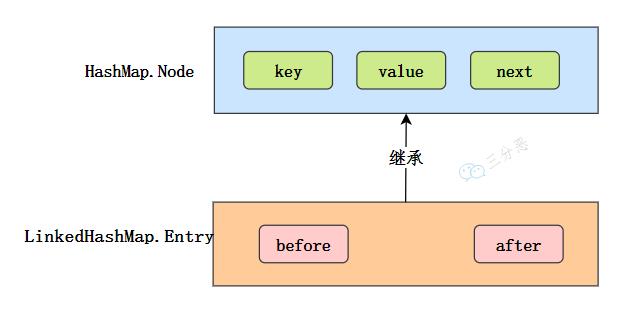
可以实现按插入的顺序或访问顺序排序。

29.讲讲 TreeMap 怎么实现有序的?
TreeMap 是按照 Key 的自然顺序或者 Comprator 的顺序进行排序,内部是通过红黑树来实现。所以要么 key 所属的类实现 Comparable 接口,或者自定义一个实现了 Comparator 接口的比较器,传给 TreeMap 用于 key 的比较。
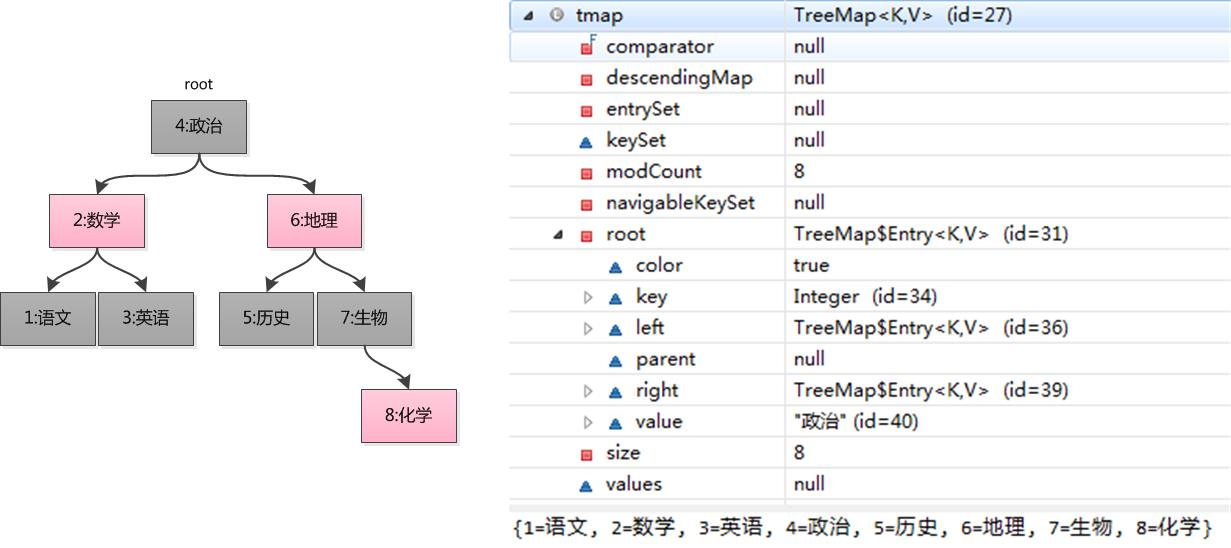
Set
Set面试没啥好问的,拿HashSet来凑个数。
30.讲讲HashSet的底层实现?
HashSet 底层就是基于 HashMap 实现的。( HashSet 的源码⾮常⾮常少,因为除了 clone() 、 writeObject() 、 readObject() 是 HashSet⾃⼰不得不实现之外,其他⽅法都是直接调⽤ HashMap 中的⽅法。
HashSet的add方法,直接调用HashMap的put方法,将添加的元素作为key,new一个Object作为value,直接调用HashMap的put方法,它会根据返回值是否为空来判断是否插入元素成功。
public boolean add(E e)
return map.put(e, PRESENT)==null;
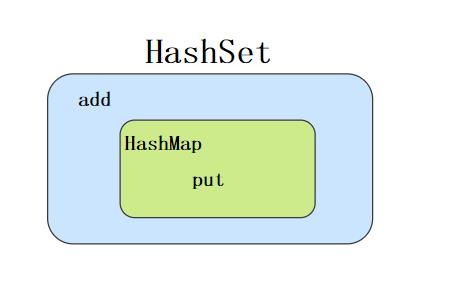
而在HashMap的putVal方法中,进行了一系列判断,最后的结果是,只有在key在table数组中不存在的时候,才会返回插入的值。
if (e != null) // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
参考:
[1]. 一个HashMap跟面试官扯了半个小时以上是关于面渣逆袭:线程池夺命连环十八问的主要内容,如果未能解决你的问题,请参考以下文章