阿里技术专家详解 DDD 系列- Domain Primitive
Posted 淘系技术
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了阿里技术专家详解 DDD 系列- Domain Primitive相关的知识,希望对你有一定的参考价值。

(phone == || !isValidPhoneNumber(phone)) String[](i = String prefix = phone.substring( (Arrays.asList(areas).contains(prefix)) String 这两个概念加起来,构造成了本文标题的Domain Primitive(DP)。 User Name(Address(PhoneNumber(User @NotNull Name name, 4 Name(PhoneNumber(Address("浙江省杭州市余杭区文三西路969号")); 通过以上 4 步,就能让你的代码变得更加简洁、优雅、健壮、安全。你还在等什么?今天就去尝试吧! 链接: ① https://martinfowler.com/bliki/AnemicDomainModel.html END 你可能还喜欢 点击下方图片即可阅读 大促背后的流量利器|手淘push升级 比你更懂你 阿里工程师谈,什么是好的代码? “一次编码、到处运行”,淘宝云端一体化探索 Entity(实体)这个词在计算机领域的最初应用可能是来自于Peter Chen在1976年的“The Entity-Relationship Model - Toward a Unified View of Data"(ER模型),用来描述实体之间的关系,而ER模型后来逐渐的演变成为一个数据模型,在关系型数据库中代表了数据的储存方式。 如何知道你的模型是贫血的呢?可以看一下你代码中是否有以下的几个特征: 而贫血模型的缺陷是非常明显的: 虽然贫血模型有很大的缺陷,但是在我们日常的代码中,我见过的99%的代码都是基于贫血模型,为什么呢?我总结了以下几点: 但是可能最核心的原因在于,实际上我们在日常开发中,混淆了两个概念: 所以,解决这个问题的根本方案,就是要在代码里严格区分Data Model和Domain Model,具体的规范会在后文详细描述。在真实代码结构中,Data Model和 Domain Model实际上会分别在不同的层里,Data Model只存在于数据层,而Domain Model在领域层,而链接了这两层的关键对象,就是Repository。 在传统的数据库驱动开发中,我们会对数据库操作做一个封装,一般叫做Data Access Object(DAO)。DAO的核心价值是封装了拼接SQL、维护数据库连接、事务等琐碎的底层逻辑,让业务开发可以专注于写代码。但是在本质上,DAO的操作还是数据库操作,DAO的某个方法还是在直接操作数据库和数据模型,只是少写了部分代码。在Uncle Bob的《代码整洁之道》一书里,作者用了一个非常形象的描述: 从上面的描述我们能看出来,数据库在本质上属于”硬件“,DAO 在本质上属于”固件“,而我们自己的代码希望是属于”软件“。但是,固件有个非常不好的特性,那就是会传播,也就是说当一个软件强依赖了固件时,由于固件的限制,会导致软件也变得难以变更,最终让软件变得跟固件一样难以变更。 在上面的这段简单代码里,该对象依赖了DAO,也就是依赖了DB。虽然乍一看感觉并没什么毛病,但是假设未来要加一个缓存逻辑,代码则需要改为如下: 这时,你会发现因为插入的逻辑变化了,导致在所有的使用数据的地方,都需要从1行代码改为至少3行。而当你的代码量变得比较大,然后如果在某个地方你忘记了查缓存,或者在某个地方忘记了更新缓存,轻则需要查数据库,重则是缓存和数据库不一致,导致bug。当你的代码量变得越来越多,直接调用DAO、缓存的地方越来越多时,每次底层变更都会变得越来越难,越来越容易导致bug。这就是软件被“固化”的后果。 在讲Repository规范之前,我们需要先讲清楚3种模型的区别,Entity、Data Object (DO)和Data Transfer Object (DTO): 在实际开发中DO、Entity和DTO不一定是1:1:1的关系。一些常见的非1:1关系如下: 由于现在从一个对象变为3+个对象,对象间需要通过转化器(Converter/Mapper)来互相转化。而这三种对象在代码中所在的位置也不一样,简单总结如下: 我们能看出来通过抽象出一个Assembler/Converter对象,我们能把复杂的转化逻辑都收敛到一个对象中,并且可以很好的单元测试。这个也很好的收敛了常见代码里的转化逻辑。 虽然Assembler/Converter是非常好用的对象,但是当业务复杂时,手写Assembler/Converter是一件耗时且容易出bug的事情,所以业界会有多种Bean Mapping的解决方案,从本质上分为动态和静态映射。 动态映射方案包括比较原始的 BeanUtils.copyProperties、能通过xml配置的Dozer等,其核心是在运行时根据反射动态赋值。动态方案的缺陷在于大量的反射调用,性能比较差,内存占用多,不适合特别高并发的应用场景。 所以在这里我给用Java的同学推荐一个库叫MapStruct(MapStruct官网)。MapStruct通过注解,在编译时静态生成映射代码,其最终编译出来的代码和手写的代码在性能上完全一致,且有强大的注解等能力。如果你的IDE支持,甚至可以在编译后看到编译出来的映射代码,用来做check。在这里我就不细讲MapStruct的用法了,具体细节请见官网。 用了MapStruct之后,会节省大量的成本,让代码变得简洁如下: 在使用了MapStruct后,你只需要标注出字段不一致的情况,其他的情况都通过Convention over Configuration帮你解决了。还有很多复杂的用法我就不一一指出了。 上文曾经讲过,传统Data Mapper(DAO)属于“固件”,和底层实现(DB、Cache、文件系统等)强绑定,如果直接使用会导致代码“固化”。所以为了在Repository的设计上体现出“软件”的特性,主要需要注意以下三点: 我们先定义一个基础的 Repository 基础接口类,以及一些Marker接口类: 业务自己的接口只需要在基础接口上进行扩展,举个订单的例子: 每个业务需要根据自己的业务场景来定义各种查询逻辑。 这里需要再次强调的是Repository的接口是在Domain层,但是实现类是在Infrastructure层。 先举个Repository的最简单实现的例子。注意OrderRepositoryImpl在Infrastructure层: 从上面的实现能看出来一些套路:所有的Entity/Aggregate会被转化为DO,然后根据业务场景,调用相应的DAO方法进行操作,事后如果需要则把DO转换回Entity。代码基本很简单,唯一需要注意的是save方法,需要根据Aggregate的ID是否存在且大于0来判断一个Aggregate是否需要更新还是插入。 以上是关于阿里技术专家详解 DDD 系列- Domain Primitive的主要内容,如果未能解决你的问题,请参考以下文章 阿里技术专家详解 DDD 系列- Domain Primitive 阿里技术专家详解DDD系列 第三讲 - Repository模式
Long userId;
String name;
String phone;
String address;
Long repId;
SalesRepRepository salesRepRepo;
UserRepository userRepo;
User
ValidationException
(name == || name.length() == ValidationException(
(phone == || !isValidPhoneNumber(phone))
ValidationException(
String areaCode = String[] areas = String[] (i = String prefix = phone.substring( (Arrays.asList(areas).contains(prefix))
areaCode = prefix;
SalesRep rep = salesRepRepo.findRep(areaCode);
User user = User();
user.name = name;
user.phone = phone;
user.address = address;
(rep != user.repId = rep.repId;
userRepo.save(user);
String pattern = phone.matches(pattern);
ValidationException((phone == || !isValidPhoneNumber(phone) || !isValidCellNumber(phone))
ValidationException((phone == ValidationException((!isValidPhoneNumber(phone))
ValidationException( @NotNull @NotBlank String name,
@NotNull @Pattern(regexp = String phone,
@NotNull String address
);
User
ValidationUtils.validateName(name); ValidationUtils.validatePhone(phone);
ValidationUtils.validateAddress(address);
...
areaCode = prefix;
SalesRep rep = salesRepRepo.findRep(areaCode);
(i = String prefix = phone.substring( (isAreaCode(prefix))
prefix;
String[] areas = String[] Arrays.asList(areas).contains(prefix);
String number;
String
number;
(number == ValidationException( (isValid(number))
ValidationException(
String
(i = String prefix = number.substring( (isAreaCode(prefix))
prefix;
String[] areas = String[] Arrays.asList(areas).contains(prefix);
String pattern = number.matches(pattern);
UserId userId;
Name name;
PhoneNumber phone;
Address address;
RepId repId;
User @NotNull Name name,
@NotNull PhoneNumber phone,
@NotNull Address address
)
SalesRep rep = salesRepRepo.findRep(phone.getAreaCode());
User user = User();
user.name = name;
user.phone = phone;
user.address = address;
(rep != user.repId = rep.repId;
userRepo.saveUser(user);
@NotNull PhoneNumber phone,
@NotNull Address address
) userRepo.save(user);
BankService.transfer(money,
BigDecimal amount;
Currency currency;
BankService.transfer(money, recipientId);
(money.getCurrency().equals(targetCurrency))
BankService.transfer(money, recipientId);
BigDecimal rate = ExchangeService.getRate(money.getCurrency(), targetCurrency);
BigDecimal targetAmount = money.getAmount().multiply(BigDecimal(rate));
Money targetMoney = Money(targetAmount, targetCurrency);
BankService.transfer(targetMoney, recipientId);
BigDecimal rate;
Currency from;
Currency to;
Money
notNull(fromMoney);
isTrue( BigDecimal targetAmount = fromMoney.getAmount().multiply(rate);
Money(targetAmount, to);
ExchangeRate rate = ExchangeService.getRate(money.getCurrency(), targetCurrency);
Money targetMoney = rate.exchange(money);
BankService.transfer(targetMoney, recipientId);
(name == || name.length() == ValidationException(
(phone == || !isValidPhoneNumber(phone))
ValidationException(
String areaCode = String[] areas = String[] (i = String prefix = phone.substring( (Arrays.asList(areas).contains(prefix))
areaCode = prefix;
SalesRep rep = salesRepRepo.findRep(areaCode);
User ValidationException
Name _name = Name(name);
PhoneNumber _phone = PhoneNumber(phone);
Address _address = Address(address);
SalesRep rep = salesRepRepo.findRep(_phone.getAreaCode());
User
SalesRep rep = salesRepRepo.findRep(phone.getAreaCode());


阿里技术专家详解DDD系列 第三讲 - Repository模式
为什么要用 Repository
实体模型 vs. 贫血模型
而2006年的JPA标准,通过@Entity等注解,以及Hibernate等ORM框架的实现,让很多Java开发对Entity的理解停留在了数据映射层面,忽略了Entity实体的本身行为,造成今天很多的模型仅包含了实体的数据和属性,而所有的业务逻辑都被分散在多个服务、Controller、Utils工具类中,这个就是Martin Fowler所说的的Anemic Domain Model(贫血领域模型)。Repository的价值
举个软件很容易被“固化”的例子:private OrderDAO orderDAO;
public Long addOrder(RequestDTO request)
// 此处省略很多拼装逻辑
OrderDO orderDO = new OrderDO();
orderDAO.insertOrder(orderDO);
return orderDO.getId();
public void updateOrder(OrderDO orderDO, RequestDTO updateRequest)
orderDO.setXXX(XXX); // 省略很多
orderDAO.updateOrder(orderDO);
public void doSomeBusiness(Long id)
OrderDO orderDO = orderDAO.getOrderById(id);
// 此处省略很多业务逻辑
private OrderDAO orderDAO;
private Cache cache;
public Long addOrder(RequestDTO request)
// 此处省略很多拼装逻辑
OrderDO orderDO = new OrderDO();
orderDAO.insertOrder(orderDO);
cache.put(orderDO.getId(), orderDO);
return orderDO.getId();
public void updateOrder(OrderDO orderDO, RequestDTO updateRequest)
orderDO.setXXX(XXX); // 省略很多
orderDAO.updateOrder(orderDO);
cache.put(orderDO.getId(), orderDO);
public void doSomeBusiness(Long id)
OrderDO orderDO = cache.get(id);
if (orderDO == null)
orderDO = orderDAO.getOrderById(id);
// 此处省略很多业务逻辑
所以,我们需要一个模式,能够隔离我们的软件(业务逻辑)和固件/硬件(DAO、DB),让我们的软件变得更加健壮,而这个就是Repository的核心价值。模型对象代码规范
对象类型
模型对象之间的关系
复杂的Entity拆分多张数据库表:常见的原因在于字段过多,导致查询性能降低,需要将非检索、大字段等单独存为一张表,提升基础信息表的检索效率。常见的案例如商品模型,将商品详细描述等大字段单独保存,提升查询性能:

多个关联的Entity合并一张数据库表:这种情况通常出现在拥有复杂的Aggregate Root - Entity关系的情况下,且需要分库分表,为了避免多次查询和分库分表带来的不一致性,牺牲了单表的简洁性,提升查询和插入性能。常见的案例如主子订单模型:

从复杂Entity里抽取部分信息形成多个DTO:这种情况通常在Entity复杂,但是调用方只需要部分核心信息的情况下,通过一个小的DTO降低信息传输成本。同样拿商品模型举例,基础DTO可能出现在商品列表里,这个时候不需要复杂详情:

合并多个Entity为一个DTO:这种情况通常为了降低网络传输成本,降低服务端请求次数,将多个Entity、DP等对象合并序列化,并且让DTO可以嵌套其他DTO。同样常见的案例是在订单详情里需要展示商品信息:
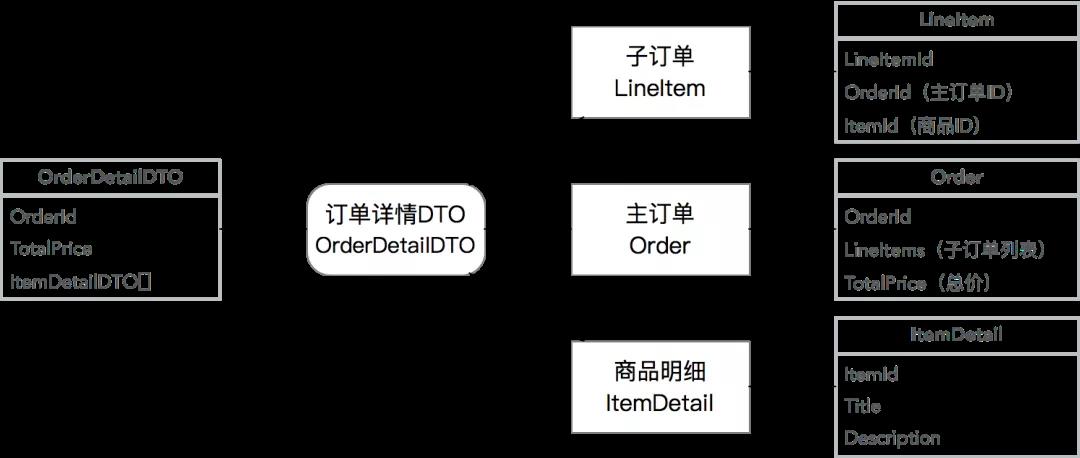
模型所在模块和转化器

如果是手写一个Assembler,通常我们会去实现2种类型的方法,如下;Data Converter的逻辑和此类似,略过。
public class DtoAssembler
// 通过各种实体,生成DTO
public OrderDTO toDTO(Order order, Item item)
OrderDTO dto = new OrderDTO();
dto.setId(order.getId());
dto.setItemTitle(item.getTitle()); // 从多个对象里取值,且字段名称不一样
dto.setDetailAddress(order.getAddress.getDetail()); // 可以读取复杂嵌套字段
// 省略N行
return dto;
// 通过DTO,生成实体
public Item toEntity(ItemDTO itemDTO)
Item entity = new Item();
entity.setId(itemDTO.getId());
// 省略N行
return entity;
在调用方使用时是非常方便的(请忽略各种异常逻辑):public class Application
private DtoAssembler assembler;
private OrderRepository orderRepository;
private ItemRepository itemRepository;
public OrderDTO getOrderDetail(Long orderId)
Order order = orderRepository.find(orderId);
Item item = itemRepository.find(order.getItemId());
return assembler.toDTO(order, item); // 原来的很多复杂转化逻辑都收敛到一行代码了
@org.mapstruct.Mapper
public interface DtoAssembler // 注意这里变成了一个接口,MapStruct会生成实现类
DtoAssembler INSTANCE = Mappers.getMapper(DtoAssembler.class);
// 在这里只需要指出字段不一致的情况,支持复杂嵌套
@Mapping(target = "itemTitle", source = "item.title")
@Mapping(target = "detailAddress", source = "order.address.detail")
OrderDTO toDTO(Order order, Item item);
// 如果字段没有不一致,一行注解都不需要
Item toEntity(ItemDTO itemDTO);
模型规范总结
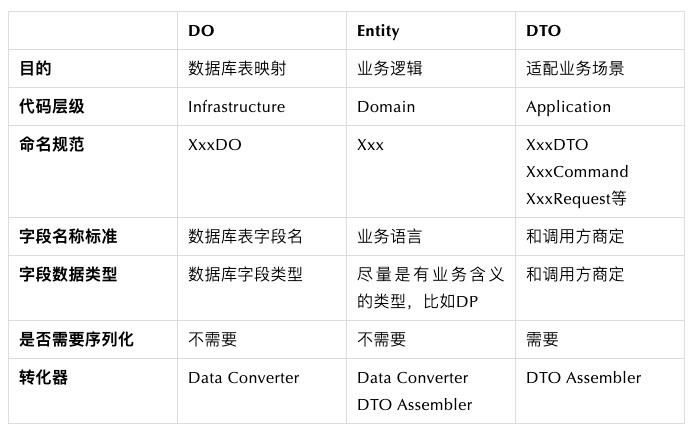
从使用复杂度角度来看,区分了DO、Entity、DTO带来了代码量的膨胀(从1个变成了3+2+N个)。但是在实际复杂业务场景下,通过功能来区分模型带来的价值是功能性的单一和可测试、可预期,最终反而是逻辑复杂性的降低。Repository代码规范
接口规范
public interface Repository<T extends Aggregate<ID>, ID extends Identifier>
/**
* 将一个Aggregate附属到一个Repository,让它变为可追踪。
* Change-Tracking在下文会讲,非必须
*/
void attach(@NotNull T aggregate);
/**
* 解除一个Aggregate的追踪
* Change-Tracking在下文会讲,非必须
*/
void detach(@NotNull T aggregate);
/**
* 通过ID寻找Aggregate。
* 找到的Aggregate自动是可追踪的
*/
T find(@NotNull ID id);
/**
* 将一个Aggregate从Repository移除
* 操作后的aggregate对象自动取消追踪
*/
void remove(@NotNull T aggregate);
/**
* 保存一个Aggregate
* 保存后自动重置追踪条件
*/
void save(@NotNull T aggregate);
// 聚合根的Marker接口
public interface Aggregate<ID extends Identifier> extends Entity<ID>
// 实体类的Marker接口
public interface Entity<ID extends Identifier> extends Identifiable<ID>
public interface Identifiable<ID extends Identifier>
ID getId();
// ID类型DP的Marker接口
public interface Identifier extends Serializable
// 代码在Domain层
public interface OrderRepository extends Repository<Order, OrderId>
// 自定义Count接口,在这里OrderQuery是一个自定义的DTO
Long count(OrderQuery query);
// 自定义分页查询接口
Page<Order> query(OrderQuery query);
// 自定义有多个条件的查询接口
Order findInStore(OrderId id, StoreId storeId);
Repository基础实现
// 代码在Infrastructure层
@Repository // Spring的注解
public class OrderRepositoryImpl implements OrderRepository
private final OrderDAO dao; // 具体的DAO接口
private final OrderDataConverter converter; // 转化器
public OrderRepositoryImpl(OrderDAO dao)
this.dao = dao;
this.converter = OrderDataConverter.INSTANCE;
@Override
public Order find(OrderId orderId)
OrderDO orderDO = dao.findById(orderId.getValue());
return converter.fromData(orderDO);
@Override
public void remove(Order aggregate)
OrderDO orderDO = converter.toData(aggregate);
dao.delete(orderDO);
@Override
public void save(Order aggregate)
if (aggregate.getId() != null && aggregate.getId().getValue() > 0)
// update
OrderDO orderDO = converter.toData(aggregate);
dao.update(orderDO);
else
// insert
OrderDO orderDO = converter.toData(aggregate);
dao.insert(orderDO);
aggregate.setId(converter.fromData(orderDO).getId());
@Override
public Page<Order> query(OrderQuery query)
List<OrderDO> orderDOS = dao.queryPaged(query);
long count = dao.count(query);
List<Order> result = orderDOS.stream().map(converter::fromData).collect(Collectors.toList());
return Page.with(result, query, count);
@Override
public Order findInStore(OrderId id, StoreId storeId)
OrderDO orderDO = dao.findInStore(id.getValue(), storeId.getValue());
return converter.fromData(orderDO);
这里通过OrderDataConverter,实现DO和Entity之间的转换,向下使用DO进行持久化交互,向上使用Entity和业务域交互。