日订单量达到100万单后,我们做了订单中心重构
Posted 技术琐话
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了日订单量达到100万单后,我们做了订单中心重构相关的知识,希望对你有一定的参考价值。
作者简介:曾任职于阿里巴巴,每日优鲜等互联网公司,任技术总监。最近很多读者朋友留言,希望“二马”多写一些实际工作经历以及工作中遇到的问题和技术解决方案。应大家要求,本文介绍一次订单中心重构的经历。
背景
几年前我曾经服务过的一家电商公司,随着业务增长我们每天的订单量很快从30万单增长到了100万单,订单总量也突破了一亿。当时用的mysql数据库。根据监控,我们的每秒最高订单量已经达到了2000笔(不包括秒杀,秒杀TPS已经上万了。秒杀我们有一套专门的解决方案,详见《秒杀系统设计~亿级用户》)。不过,直到此时,订单系统还是单库单表,幸好当时数据库服务器配置不错,我们的系统才能撑住这么大的压力。
业务量还在快速增长,再不重构系统早晚出大事,我们花了一天时间快速制定了重构方案。
重构?说这么高大上,不就是分库分表吗?的确,就是分库分表。不过除了分库分表,还包括管理端的解决方案,比如运营,客服和商务需要从多维度查询订单数据,分库分表后,怎么满足大家的需求?分库分表后,上线方案和数据不停机迁移方案都需要慎重考虑。为了保证系统稳定,还需要考虑相应的降级方案。
为什么要分库分表?
当数据库产生性能瓶颈:IO瓶颈或CPU瓶颈。两种瓶颈最终都会导致数据库的活跃连接数增加,进而达到数据库可承受的最大活跃连接数阈值。终会导致应用服务无连接可用,造成灾难性后果。可以先从代码,sql,索引几方面进行优化。如果这几方面已经没有太多优化的余地,就该考虑分库分表了。
磁盘读IO瓶颈。由于热点数据太多,数据库缓存完全放不下,查询时会产生大量的磁盘IO,查询速度会比较慢,这样会导致产生大量活跃连接,最终可能会发展成无连接可用的后果。可以采用一主多从,读写分离的方案,用多个从库分摊查询流量。或者采用分库+水平分表(把一张表的数据拆成多张表来存放,比如订单表可以按user_id来拆分)的方案。
第二种:磁盘写IO瓶颈。由于数据库写入频繁,会产生频繁的磁盘写入IO操作,频繁的磁盘IO操作导致产生大量活跃连接,最终同样会发展成无连接可用的后果。这时只能采用分库方案,用多个库来分摊写入压力。再加上水平分表的策略,分表后,单表存储的数据量会更小,插入数据时索引查找和更新的成本会更低,插入速度自然会更快。
SQL问题。如果SQL中包含join,group by,order by,非索引字段条件查询等增加CPU运算的操作,会对CPU产生明显的压力。 这时可以考虑SQL优化,创建适当的索引,也可以把一些计算量大的SQL逻辑放到应用中处理。
单表数据量太大。由于单张表数据量过大,比如超过一亿,查询时遍历树的层次太深或者扫描的行太多,SQL效率会很低,也会非常消耗CPU。这时可以根据业务场景水平分表。
分库分表方案
分库分表主要有两种方案:
利用MyCat,KingShard这种代理中间件分库分表。好处是和业务代码耦合度很低,只需做一些配置即可,接入成本低。缺点是这种代理中间件需要单独部署,所以从调用链路上又多了一层。而且分库分表逻辑完全由代理中间件管理,对于程序员完全是黑盒,一旦代理本身出问题(比如出错或宕机),会导致无法查询和存储相关业务数据,引发灾难性的后果。如果不熟悉代理中间件源码,排查问题会非常困难。曾经有公司使用MyCat,线上发生故障后,被迫修改方案,三天三夜才恢复系统。CTO也废了!
利用Sharding-Jdbc,TSharding等以Jar包形式呈现的轻量级组件分库分表。缺点是,会有一定的代码开发工作量,对业务有一些侵入性。好处是对程序员透明,程序员对分库分表逻辑的把控会更强,一旦发生故障,排查问题会比较容易。
稳妥起见,我们选用了第二种方案,使用更轻量级的Sharding-Jdbc。
做系统重构前,我们首先要确定重构的目标,其次要对未来业务的发展有一个预期,这个可以找相关业务负责人了解。根据目标和业务预期来确定重构方案。例如,我们希望经过本次重构,系统能支撑两年,两年内不再大改。业务方预期两年内日单量达到1000万。相当于两年后日订单量要翻10倍。
根据上面的数据,我们分成了16个数据库。按日订单量1000万来算,每个库平均的日订单量就是62.5万(1000万/16),每秒最高订单量理论上在1250左右( 2000*(62.5/100) )。这样数据库的压力基本上是可控的,而且基本不会浪费服务器资源。
每个库分了16张表,即便按照每天1000万的订单量,两年总单量是73亿(73亿=1000万*365*2),每个库的数据量平均是4.56亿(4.56亿=73亿/16),每张表的数据量平均是2850万(2850万=4.56亿/16)。可以看到未来两到三年每张表的数据量也不算多,完全在可控范围。
分库分表主要是为了用户端下单和查询使用,按user_id的查询频率最高,其次是order_id。所以我们选择user_id做为sharding column,按user_id做hash,将相同用户的订单数据存储到同一个数据库的同一张表中。这样用户在网页或者App上查询订单时只需要路由到一张表就可以获取用户的所有订单了,这样就保证了查询性能。
另外我们在订单ID(order_id)里掺杂了用户ID(user_id)信息。简单来说,order_id的设计思路就是,将order_id分为前后两部分,前面的部分是user_id,后面的部分是具体的订单编号,两部分组合在一起就构成了order_id。这样我们很容易从order_id解析出user_id。通过order_id查询订单时,先从order_id中解析出user_id,然后就可以根据user_id路由到具体的库表了。
另外,数据库分成16个,每个库分16张表还有一个好处。16是2的N次幂,所以hash值对16取模的结果与hash值和16按位“与运算”的结果是一样的。我们知道位运算基于二进制,跨过各种编译和转化直接到最底层的机器语言,效率自然远高于取模运算。
有读者可能会问,查询直接查数据库,会不会有性能问题?是的。所以我们在上层加了Redis,Redis做了分片集群,用于存储活跃用户最近50条订单。这样一来,只有少部分在Redis查不到订单的用户请求才会到数据库查询订单,这样就减小了数据库查询压力,而且每个分库还有两个从库,查询操作只走从库,进一步分摊了每个分库的压力。
有读者可能会问,为什么没采用一致性hash方案?用户查询最近50条之前的订单怎么办?请继续往后看!
管理端技术方案
分库分表后,不同用户的订单数据散落在不同的库和表中,如果需要根据用户ID之外的其他条件查询订单。例如,运营同学想从后台查出某天iphone7的订单量,就需要从所有数据库的表中查出数据然后在聚合到一起。这样代码实现非常复杂,而且查询性能也会很差。所以我们需要一种更好的方案来解决这个问题。
我们采用了ES(Elastic Search)+HBase组合的方案,将索引与数据存储隔离。可能参与条件检索的字段都会在ES中建一份索引,例如商家,商品名称,订单日期等。所有订单数据全量保存到HBase中。我们知道HBase支持海量存储,而且根据rowkey查询速度超快。而ES的多条件检索能力非常强大。可以说,这个方案把ES和HBase的优点发挥地淋漓尽致。
看一下该方案的查询过程:先根据输入条件去ES相应的索引上查询符合条件的rowkey值,然后用rowkey值去HBase查询,后面这一步查询速度极快,查询时间几乎可以忽略不计。如下图:
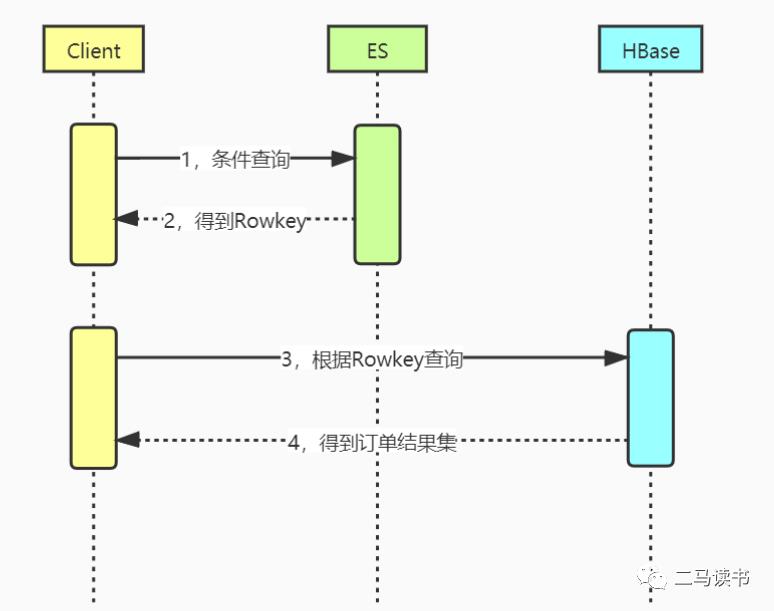
该方案,解决了管理端通过各种字段条件查询订单的业务需求,同时也解决了商家端按商家ID和其他条件查询订单的需求。如果用户希望查询最近50条订单之前的历史订单,也同样可以用这个方案。
每天产生数百万的订单数据,如果管理后台想查到最新的订单数据,就需要频繁更新ES索引。在海量订单数据的场景下,索引频繁更新会不会对ES产生太大压力?
ES索引有一个segment(片段)的概念。ES把每个索引分成若干个较小的 segment 片段。每一个 segement 都是一个完整的倒排索引,在搜索查询时会依次扫描相关索引的所有 segment。每次 refresh(刷新索引) 的时候,都会生成一个新的 segement,因此 segment 实际上记录了索引的一组变化值。由于每次索引刷新只涉及个别segement片段,更新索引的成本就很低了。所以,即便默认的索引刷新(refresh)间隔只有1秒钟,ES也能从容应对。不过,由于每个 segement 的存储和扫描都需要占用一定的内存和CPU等资源,因此ES后台进程需要不断的进行segement合并来减少 segement 的数量,从而提升扫描效率以及降低资源消耗。
Mysql中的订单数据需要实时同步到Hbase和ES中。同步方案是什么?
我们利用Canal实时获取Mysql库表中的增量订单数据,然后把订单数据推到消息队列RocketMQ中,消费端获取消息后把数据写到Hbase,并在ES更新索引。
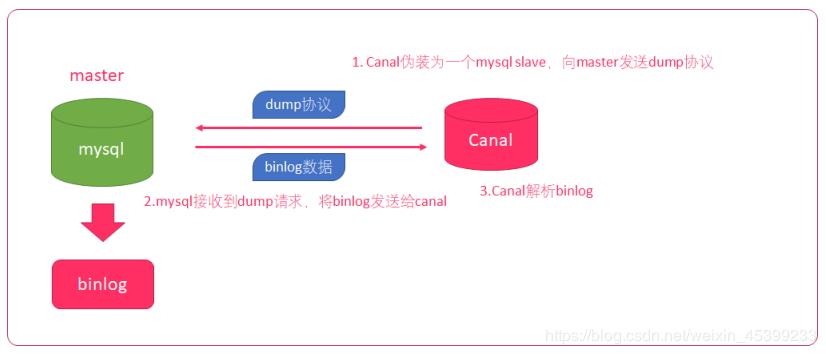
图片来源于网络
上面是Canal的原理图,
1,Canal模拟mysql slave的交互协议,把自己伪装成mysql的从库
2,向mysql master发送dump协议
3. mysql master收到dump协议,发送binary log给slave(Canal)
4. Canal解析binary log字节流对象,根据应用场景对binary log字节流做相应的处理
为了保证数据一致性,不丢失数据。我们使用了RocketMQ的事务型消息,保证消息一定能成功发送。另外,在Hbase和ES都操作成功后才做ack操作,保证消息正常消费。
不停机数据迁移
在互联网行业,很多系统的访问量很高,即便在凌晨两三点也有一定的访问量。由于数据迁移导致服务暂停,是很难被业务方接受的!下面就聊一下在用户无感知的前提下,我们的不停机数据迁移方案!
数据迁移过程我们要注意哪些关键点呢?第一,保证迁移后数据准确不丢失,即每条记录准确而且不丢失记录;第二,不影响用户体验,尤其是访问量高的C端业务需要不停机平滑迁移;第三,保证迁移后的系统性能和稳定性。
常用的数据迁移方案主要包括:挂从库,双写以及利用数据同步工具三种方案。下面分别做一下介绍。
挂从库
在主库上建一个从库。从库数据同步完成后,将从库升级成主库(新库),再将流量切到新库。
这种方式适合表结构不变,而且空闲时间段流量很低,允许停机迁移的场景。一般发生在平台迁移的场景,如从机房迁移到云平台,从一个云平台迁移到另一个云平台。大部分中小型互联网系统,空闲时段访问量很低。在空闲时段,几分钟的停机时间,对用户影响很小,业务方是可以接受的。所以我们可以采用停机迁移的方案。步骤如下:
1,新建从库(新数据库),数据开始从主库向从库同步。
2,数据同步完成后,找一个空闲时间段。为了保证主从数据库数据一致,需要先停掉服务,然后再把从库升级为主库。如果访问数据库用的是域名,直接解析域名到新数据库(从库升级成的主库),如果访问数据库用的是IP,将IP改成新数据库IP。
3,最后启动服务,整个迁移过程完成。
这种迁移方案的优势是迁移成本低,迁移周期短。缺点是,切换数据库过程需要停止服务。我们的并发量比较高,而且又做了分库分表,表结构也变了,所以不能采取这种方案!
双写
老库和新库同时写入,然后将老数据批量迁移到新库,最后流量切换到新库并关闭老库读写。
这种方式适合数据结构发生变化,不允许停机迁移的场景。一般发生在系统重构时,表结构发生变化,如表结构改变或者分库分表等场景。有些大型互联网系统,平常并发量很高,即便是空闲时段也有相当的访问量。几分钟的停机时间,对用户也会有明显的影响,甚至导致一定的用户流失,这对业务方来说是无法接受的。所以我们需要考虑一种用户无感知的不停机迁移方案。
聊一下我们的具体迁移方案,步骤如下:
代码准备。在服务层对订单表进行增删改的地方,要同时操作新库(分库分表后的数据库表)和老库,需要修改相应的代码(同时写新库和老库)。准备迁移程序脚本,用于做老数据迁移。准备校验程序脚本,用于校验新库和老库的数据是否一致。
开启双写,老库和新库同时写入。注意:任何对数据库的增删改都要双写;对于更新操作,如果新库没有相关记录,需要先从老库查出记录,将更新后的记录写入新库;为了保证写入性能,老库写完后,可以采用消息队列异步写入新库。
利用脚本程序,将某一时间戳之前的老数据迁移到新库。注意:1,时间戳一定要选择开启双写后的时间点,比如开启双写后10分钟的时间点,避免部分老数据被漏掉;2,迁移过程遇到记录冲突直接忽略,因为第2步的更新操作,已经把记录拉到了新库;3,迁移过程一定要记录日志,尤其是错误日志,如果有双写失败的情况,我们可以通过日志恢复数据,以此来保证新老库的数据一致。
第3步完成后,我们还需要通过脚本程序检验数据,看新库数据是否准确以及有没有漏掉的数据
数据校验没问题后,开启双读,起初给新库放少部分流量,新库和老库同时读取。由于延时问题,新库和老库可能会有少量数据记录不一致的情况,所以新库读不到时需要再读一遍老库。然后再逐步将读流量切到新库,相当于灰度上线的过程。遇到问题可以及时把流量切回老库
读流量全部切到新库后,关闭老库写入(可以在代码里加上热配置开关),只写新库
迁移完成,后续可以去掉双写双读相关无用代码。

利用数据同步工具
我们可以看到上面双写的方案比较麻烦,很多数据库写入的地方都需要修改代码。有没有更好的方案呢?
我们还可以利用Canal,DataBus等工具做数据同步。以阿里开源的Canal为例。
利用同步工具,就不需要开启双写了,服务层也不需要编写双写的代码,直接用Canal做增量数据同步即可。相应的步骤就变成了:
代码准备。准备Canal代码,解析binary log字节流对象,并把解析好的订单数据写入新库。准备迁移程序脚本,用于做老数据迁移。准备校验程序脚本,用于校验新库和老库的数据是否一致。
运行Canal代码,开始增量数据(线上产生的新数据)从老库到新库的同步。
利用脚本程序,将某一时间戳之前的老数据迁移到新库。注意:1,时间戳一定要选择开始运行Canal程序后的时间点(比如运行Canal代码后10分钟的时间点),避免部分老数据被漏掉;3,迁移过程一定要记录日志,尤其是错误日志,如果有些记录写入失败,我们可以通过日志恢复数据,以此来保证新老库的数据一致。
第3步完成后,我们还需要通过脚本程序检验数据,看新库数据是否准确以及有没有漏掉的数据
数据校验没问题后,开启双读,起初给新库放少部分流量,新库和老库同时读取。由于延时问题,新库和老库可能会有少量数据记录不一致的情况,所以新库读不到时需要再读一遍老库。逐步将读流量切到新库,相当于灰度上线的过程。遇到问题可以及时把流量切回老库
读流量全部切到新库后,将写入流量切到新库(可以在代码里加上热配置开关。注:由于切换过程Canal程序还在运行,仍然能够获取老库的数据变化并同步到新库,所以切换过程不会导致部分老库数据无法同步新库的情况)
关闭Canal程序
迁移完成。
扩容缩容方案
需要对数据重新hash取模,再将原来多个库表的数据写入扩容后的库表中。整体扩容方案和上面的不停机迁移方案基本一致。采用双写或者Canal等数据同步方案都可以。
更好的分库分表方案
通过前面的描述,不难看出我们的分库分表方案有一些缺陷,比如采用hash取模的方式会产生数据分布不均匀的情况,扩容缩容也非常麻烦。
这些问题可以用一致性hash方案解决。基于虚拟节点设计原理的一致性hash可以让数据分布更均匀。
而且一致性hash采用环形设计思路,在增减节点时,使得数据迁移的成本会更低,只需要迁移临近节点的数据。不过需要扩容时基本上要成倍扩容,在hash环上每个节点间隙都增加新的节点,这样才能分摊所有原有节点的访问和存储压力。
由于篇幅原因,这里不详细介绍一致性hash了,网上有很多相关资料,大家有兴趣可以仔细研究一下。
降级方案
在大促期间订单服务压力过大时,可以将同步调用改为异步消息队列方式,来减小订单服务压力并提高吞吐量。
大促时某些时间点瞬间生成订单量很高。我们采取异步批量写数据库的方式,来减少数据库访问频次,进而降低数据库的写入压力。详细步骤:后端服务接到下单请求,直接放进消息队列,订单服务取出消息后,先将订单信息写入Redis,每隔100ms或者积攒10条订单,批量写入数据库一次。前端页面下单后定时向后端拉取订单信息,获取到订单信息后跳转到支付页面。用这种异步批量写入数据库的方式大幅减少了数据库写入频次,从而明显降低了订单数据库写入压力。不过,因为订单是异步写入数据库的,就会存在数据库订单和相应库存数据暂时不一致的情况,以及用户下单后不能及时查到订单的情况。因为毕竟是降级方案,可以适当降低用户体验,我们保证数据最终一致即可。根据系统压力情况,可以在大促开始时开启异步批量写的降级开关,大促结束后再关闭降级开关。流程如下图:

原创不易,如果感觉本文对您有帮助,有劳“转发分享”或“在看”!让更多人收获知识和经验!
作者简介:曾任职于阿里巴巴,每日优鲜等互联网公司,任技术总监,15年电商互联网经历。
高并发场景下,百万级订单量系统的分库分表重构经历
一、背景
几年前我曾经服务过的一家电商公司,随着业务增长我们每天的订单量很快从30万单增长到了100万单,订单总量也突破了一亿。当时用的MySQL数据库。根据监控,我们的每秒最高订单量已经达到了2000笔(不包括秒杀,秒杀TPS已经上万了。秒杀我们有一套专门的解决方案,详见)。不过,直到此时,订单系统还是单库单表,幸好当时数据库服务器配置不错,我们的系统才能撑住这么大的压力。
业务量还在快速增长,再不重构系统早晚出大事,我们花了一天时间快速制定了重构方案。
重构?说这么高大上,不就是分库分表吗?的确,就是分库分表。不过除了分库分表,还包括管理端的解决方案,比如运营,客服和商务需要从多维度查询订单数据,分库分表后,怎么满足大家的需求?分库分表后,上线方案和数据不停机迁移方案都需要慎重考虑。为了保证系统稳定,还需要考虑相应的降级方案。
二、为什么要分库分表?
当数据库产生性能瓶颈:IO瓶颈或CPU瓶颈。两种瓶颈最终都会导致数据库的活跃连接数增加,进而达到数据库可承受的最大活跃连接数阈值。
终会导致应用服务无连接可用,造成灾难性后果。可以先从代码,sql,索引几方面进行优化。如果这几方面已经没有太多优化的余地,就该考虑分库分表了。
第一种:磁盘读IO瓶颈。由于热点数据太多,数据库缓存完全放不下,查询时会产生大量的磁盘IO,查询速度会比较慢,这样会导致产生大量活跃连接,最终可能会发展成无连接可用的后果。可以采用一主多从,读写分离的方案,用多个从库分摊查询流量。或者采用分库+水平分表(把一张表的数据拆成多张表来存放,比如订单表可以按user_id来拆分)的方案;
第二种:磁盘写IO瓶颈。由于数据库写入频繁,会产生频繁的磁盘写入IO操作,频繁的磁盘IO操作导致产生大量活跃连接,最终同样会发展成无连接可用的后果。这时只能采用分库方案,用多个库来分摊写入压力。再加上水平分表的策略,分表后,单表存储的数据量会更小,插入数据时索引查找和更新的成本会更低,插入速度自然会更快。
SQL问题。如果SQL中包含join,group by,order by,非索引字段条件查询等增加CPU运算的操作,会对CPU产生明显的压力。这时可以考虑SQL优化,创建适当的索引,也可以把一些计算量大的SQL逻辑放到应用中处理;
单表数据量太大。由于单张表数据量过大,比如超过一亿,查询时遍历树的层次太深或者扫描的行太多,SQL效率会很低,也会非常消耗CPU。这时可以根据业务场景水平分表。
三、分库分表方案
分库分表主要有两种方案:
利用MyCat,KingShard这种代理中间件分库分表。好处是和业务代码耦合度很低,只需做一些配置即可,接入成本低。缺点是这种代理中间件需要单独部署,所以从调用连路上又多了一层。而且分库分表逻辑完全由代理中间件管理,对于程序员完全是黑盒,一旦代理本身出问题(比如出错或宕机),会导致无法查询和存储相关业务数据,引发灾难性的后果。如果不熟悉代理中间件源码,排查问题会非常困难。曾经有公司使用MyCat,线上发生故障后,被迫修改方案,三天三夜才恢复系统。CTO也废了!
利用Sharding-Jdbc,TSharding等以Jar包形式呈现的轻量级组件分库分表。缺点是,会有一定的代码开发工作量,对业务有一些侵入性。好处是对程序员透明,程序员对分库分表逻辑的把控会更强,一旦发生故障,排查问题会比较容易。
稳妥起见,我们选用了第二种方案,使用更轻量级的Sharding-Jdbc。
做系统重构前,我们首先要确定重构的目标,其次要对未来业务的发展有一个预期。这个可以找相关业务负责人了解,根据目标和业务预期来确定重构方案。例如,我们希望经过本次重构,系统能支撑两年,两年内不再大改。业务方预期两年内日单量达到1000万,相当于两年后日订单量要翻10倍。
根据上面的数据,我们分成了16个数据库。按日订单量1000万来算,每个库平均的日订单量就是62.5万(1000万/16),每秒最高订单量理论上在1250左右( 2000*(62.5/100) )。这样数据库的压力基本上是可控的,而且基本不会浪费服务器资源。
每个库分了16张表,即便按照每天1000万的订单量,两年总单量是73亿(73亿=1000万*365*2),每个库的数据量平均是4.56亿(4.56亿=73亿/16),每张表的数据量平均是2850万(2850万=4.56亿/16)。可以看到未来两到三年每张表的数据量也不算多,完全在可控范围。
分库分表主要是为了用户端下单和查询使用,按user_id的查询频率最高,其次是order_id。所以我们选择user_id做为sharding column,按user_id做hash,将相同用户的订单数据存储到同一个数据库的同一张表中。这样用户在网页或者App上查询订单时只需要路由到一张表就可以获取用户的所有订单了,这样就保证了查询性能。
另外我们在订单ID(order_id)里掺杂了用户ID(user_id)信息。简单来说,order_id的设计思路就是,将order_id分为前后两部分,前面的部分是user_id,后面的部分是具体的订单编号,两部分组合在一起就构成了order_id。这样我们很容易从order_id解析出user_id。通过order_id查询订单时,先从order_id中解析出user_id,然后就可以根据user_id路由到具体的库表了。
另外,数据库分成16个,每个库分16张表还有一个好处。16是2的N次幂,所以hash值对16取模的结果与hash值和16按位“与运算”的结果是一样的。我们知道位运算基于二进制,跨过各种编译和转化直接到最底层的机器语言,效率自然远高于取模运算。
有读者可能会问,查询直接查数据库,会不会有性能问题?是的。所以我们在上层加了Redis,Redis做了分片集群,用于存储活跃用户最近50条订单。这样一来,只有少部分在Redis查不到订单的用户请求才会到数据库查询订单,这样就减小了数据库查询压力,而且每个分库还有两个从库,查询操作只走从库,进一步分摊了每个分库的压力。
有读者可能还会问,为什么没采用一致性hash方案?用户查询最近50条之前的订单怎么办?请继续往后看!
四、管理端技术方案
分库分表后,不同用户的订单数据散落在不同的库和表中,如果需要根据用户ID之外的其他条件查询订单。例如,运营同学想从后台查出某天iphone7的订单量,就需要从所有数据库的表中查出数据然后在聚合到一起。这样代码实现非常复杂,而且查询性能也会很差。所以我们需要一种更好的方案来解决这个问题。
我们采用了ES(Elastic Search)+HBase组合的方案,将索引与数据存储隔离。可能参与条件检索的字段都会在ES中建一份索引,例如商家,商品名称,订单日期等。所有订单数据全量保存到HBase中。我们知道HBase支持海量存储,而且根据rowkey查询速度超快。而ES的多条件检索能力非常强大。可以说,这个方案把ES和HBase的优点发挥地淋漓尽致。
看一下该方案的查询过程:先根据输入条件去ES相应的索引上查询符合条件的rowkey值,然后用rowkey值去HBase查询,后面这一步查询速度极快,查询时间几乎可以忽略不计。如下图:
该方案,解决了管理端通过各种字段条件查询订单的业务需求,同时也解决了商家端按商家ID和其他条件查询订单的需求。如果用户希望查询最近50条订单之前的历史订单,也同样可以用这个方案。
每天产生数百万的订单数据,如果管理后台想查到最新的订单数据,就需要频繁更新ES索引。在海量订单数据的场景下,索引频繁更新会不会对ES产生太大压力?
ES索引有一个segment(片段)的概念。ES把每个索引分成若干个较小的 segment 片段。每一个 segement 都是一个完整的倒排索引,在搜索查询时会依次扫描相关索引的所有 segment。每次 refresh(刷新索引) 的时候,都会生成一个新的 segement,因此 segment 实际上记录了索引的一组变化值。由于每次索引刷新只涉及个别segement片段,更新索引的成本就很低了。所以,即便默认的索引刷新(refresh)间隔只有1秒钟,ES也能从容应对。不过,由于每个 segement 的存储和扫描都需要占用一定的内存和CPU等资源,因此ES后台进程需要不断的进行segement合并来减少 segement 的数量,从而提升扫描效率以及降低资源消耗。
Mysql中的订单数据需要实时同步到Hbase和ES中,那么同步方案是什么?
我们利用Canal实时获取Mysql库表中的增量订单数据,然后把订单数据推到消息队列RocketMQ中,消费端获取消息后把数据写到Hbase,并在ES更新索引。
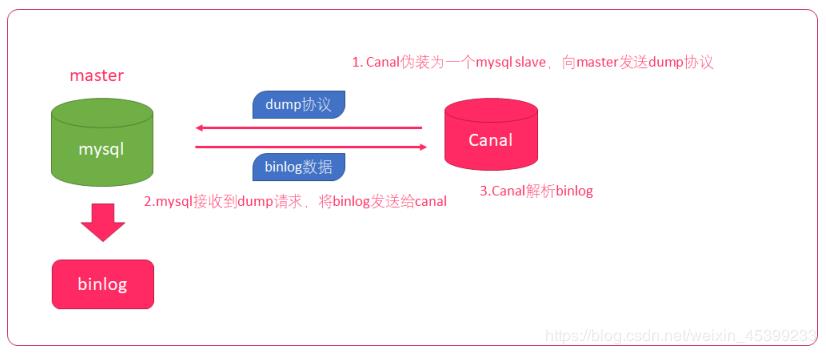
图片来源于网络
上面是Canal的原理图,
Canal模拟mysql slave的交互协议,把自己伪装成mysql的从库;
向mysql master发送dump协议;
mysql master收到dump协议,发送binary log给slave(Canal);
Canal解析binary log字节流对象,根据应用场景对binary log字节流做相应的处理。
为了保证数据一致性,不丢失数据。我们使用了RocketMQ的事务型消息,保证消息一定能成功发送。另外,在Hbase和ES都操作成功后才做ack操作,保证消息正常消费。
五、不停机数据迁移
在互联网行业,很多系统的访问量很高,即便在凌晨两三点也有一定的访问量。由于数据迁移导致服务暂停,是很难被业务方接受的!下面就聊一下在用户无感知的前提下,我们的不停机数据迁移方案!
数据迁移过程我们要注意哪些关键点呢?
第一,保证迁移后数据准确不丢失,即每条记录准确而且不丢失记录;
第二,不影响用户体验,尤其是访问量高的C端业务需要不停机平滑迁移;
第三,保证迁移后的系统性能和稳定性。
常用的数据迁移方案主要包括:挂从库,双写以及利用数据同步工具三种方案。下面分别做一下介绍。
在主库上建一个从库。从库数据同步完成后,将从库升级成主库(新库),再将流量切到新库。
这种方式适合表结构不变,而且空闲时间段流量很低,允许停机迁移的场景。一般发生在平台迁移的场景,如从机房迁移到云平台,从一个云平台迁移到另一个云平台。大部分中小型互联网系统,空闲时段访问量很低。在空闲时段,几分钟的停机时间,对用户影响很小,业务方是可以接受的。
所以我们可以采用停机迁移的方案。步骤如下:
新建从库(新数据库),数据开始从主库向从库同步;
数据同步完成后,找一个空闲时间段。为了保证主从数据库数据一致,需要先停掉服务,然后再把从库升级为主库。如果访问数据库用的是域名,直接解析域名到新数据库(从库升级成的主库),如果访问数据库用的是IP,将IP改成新数据库IP;
最后启动服务,整个迁移过程完成。
这种迁移方案的优势是迁移成本低,迁移周期短。缺点是,切换数据库过程需要停止服务。我们的并发量比较高,而且又做了分库分表,表结构也变了,所以不能采取这种方案!
老库和新库同时写入,然后将老数据批量迁移到新库,最后流量切换到新库并关闭老库读写。
这种方式适合数据结构发生变化,不允许停机迁移的场景。一般发生在系统重构时,表结构发生变化,如表结构改变或者分库分表等场景。有些大型互联网系统,平常并发量很高,即便是空闲时段也有相当的访问量。几分钟的停机时间,对用户也会有明显的影响,甚至导致一定的用户流失,这对业务方来说是无法接受的。
所以我们需要考虑一种用户无感知的不停机迁移方案,聊一下我们的具体迁移方案,步骤如下:
代码准备。在服务层对订单表进行增删改的地方,要同时操作新库(分库分表后的数据库表)和老库,需要修改相应的代码(同时写新库和老库)。准备迁移程序脚本,用于做老数据迁移。准备校验程序脚本,用于校验新库和老库的数据是否一致;
开启双写,老库和新库同时写入。注意:1、任何对数据库的增删改都要双写;对于更新操作,如果新库没有相关记录,需要先从老库查出记录,将更新后的记录写入新库;2、为了保证写入性能,老库写完后,可以采用消息队列异步写入新库;
利用脚本程序,将某一时间戳之前的老数据迁移到新库。注意:1、时间戳一定要选择开启双写后的时间点,比如开启双写后10分钟的时间点,避免部分老数据被漏掉;2、迁移过程遇到记录冲突直接忽略,因为第2步的更新操作,已经把记录拉到了新库;3、迁移过程一定要记录日志,尤其是错误日志,如果有双写失败的情况,我们可以通过日志恢复数据,以此来保证新老库的数据一致;
第3步完成后,我们还需要通过脚本程序检验数据,看新库数据是否准确以及有没有漏掉的数据;
数据校验没问题后,开启双读,起初给新库放少部分流量,新库和老库同时读取。由于延时问题,新库和老库可能会有少量数据记录不一致的情况,所以新库读不到时需要再读一遍老库。然后再逐步将读流量切到新库,相当于灰度上线的过程。遇到问题可以及时把流量切回老库;
读流量全部切到新库后,关闭老库写入(可以在代码里加上热配置开关),只写新库;
迁移完成,后续可以去掉双写双读相关无用代码。
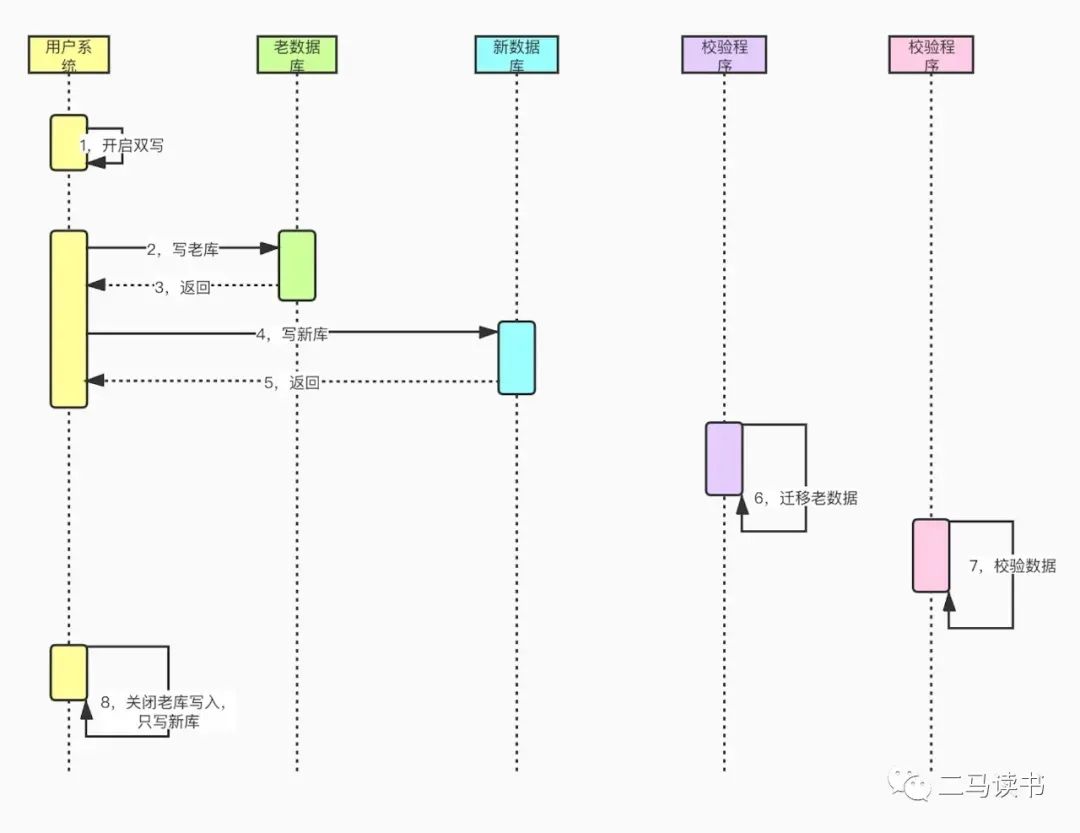
我们可以看到上面双写的方案比较麻烦,很多数据库写入的地方都需要修改代码。有没有更好的方案呢?
我们还可以利用Canal,DataBus等工具做数据同步。以阿里开源的Canal为例。
利用同步工具,就不需要开启双写了,服务层也不需要编写双写的代码,直接用Canal做增量数据同步即可。相应的步骤就变成了:
代码准备。准备Canal代码,解析binary log字节流对象,并把解析好的订单数据写入新库。准备迁移程序脚本,用于做老数据迁移。准备校验程序脚本,用于校验新库和老库的数据是否一致;
运行Canal代码,开始增量数据(线上产生的新数据)从老库到新库的同步;
利用脚本程序,将某一时间戳之前的老数据迁移到新库。注意:1,时间戳一定要选择开始运行Canal程序后的时间点(比如运行Canal代码后10分钟的时间点),避免部分老数据被漏掉;3,迁移过程一定要记录日志,尤其是错误日志,如果有些记录写入失败,我们可以通过日志恢复数据,以此来保证新老库的数据一致;
第3步完成后,我们还需要通过脚本程序检验数据,看新库数据是否准确以及有没有漏掉的数据;
数据校验没问题后,开启双读,起初给新库放少部分流量,新库和老库同时读取。由于延时问题,新库和老库可能会有少量数据记录不一致的情况,所以新库读不到时需要再读一遍老库。逐步将读流量切到新库,相当于灰度上线的过程。遇到问题可以及时把流量切回老库;
读流量全部切到新库后,将写入流量切到新库(可以在代码里加上热配置开关:由于切换过程Canal程序还在运行,仍然能够获取老库的数据变化并同步到新库,所以切换过程不会导致部分老库数据无法同步新库的情况);
关闭Canal程序;
迁移完成。
六、扩容缩容方案
需要对数据重新hash取模,再将原来多个库表的数据写入扩容后的库表中。整体扩容方案和上面的不停机迁移方案基本一致。采用双写或者Canal等数据同步方案都可以。
七、更好的分库分表方案
通过前面的描述,不难看出我们的分库分表方案有一些缺陷,比如采用hash取模的方式会产生数据分布不均匀的情况,扩容缩容也非常麻烦。
这些问题可以用一致性hash方案解决。基于虚拟节点设计原理的一致性hash可以让数据分布更均匀。
而且一致性hash采用环形设计思路,在增减节点时,使得数据迁移的成本会更低,只需要迁移临近节点的数据。不过需要扩容时基本上要成倍扩容,在hash环上每个节点间隙都增加新的节点,这样才能分摊所有原有节点的访问和存储压力。
由于篇幅原因,这里不详细介绍一致性hash了,网上有很多相关资料,大家有兴趣可以仔细研究一下。
八、降级方案
在大促期间订单服务压力过大时,可以将同步调用改为异步消息队列方式,来减小订单服务压力并提高吞吐量。
大促时某些时间点瞬间生成订单量很高。我们采取异步批量写数据库的方式,来减少数据库访问频次,进而降低数据库的写入压力。
详细步骤:后端服务接到下单请求,直接放进消息队列,订单服务取出消息后,先将订单信息写入Redis,每隔100ms或者积攒10条订单,批量写入数据库一次。前端页面下单后定时向后端拉取订单信息,获取到订单信息后跳转到支付页面。
用这种异步批量写入数据库的方式大幅减少了数据库写入频次,从而明显降低了订单数据库写入压力。
不过,因为订单是异步写入数据库的,就会存在数据库订单和相应库存数据暂时不一致的情况,以及用户下单后不能及时查到订单的情况。因为毕竟是降级方案,可以适当降低用户体验,我们保证数据最终一致即可。
根据系统压力情况,可以在大促开始时开启异步批量写的降级开关,大促结束后再关闭降级开关。流程如下图:
2020 DAMS中国数据智能管理峰会即将于10月30日在上海举办,部分精彩议题先睹为快:
腾讯《腾讯游戏大数据资产管理实战:元数据管理与数据治理》
京东《京东EB级全域大数据平台建设和治理之路》
阿里《大规模容器云基础设施环境架构、管理与运维》
工商银行《DevOps转型的探索与实践》
中国银联《从自研演进看分布式数据库》
民生银行《开源数据库MySQL在民生银行的应用实践》
平安银行《“传统+互联网”混合CMDB及运营中台实践》
中国联通《大数据资产管理平台的设计、研发、运营实践》
AWS《基于数据湖构建云上的数据分析架构》
今日头条《字节跳动数据治理实践》
苏宁《苏宁大规模智能告警收敛与告警根因的实践》
滴滴《万亿级消息队列Kafka在滴滴的实践》
以上是关于日订单量达到100万单后,我们做了订单中心重构的主要内容,如果未能解决你的问题,请参考以下文章