端到端机器学习:从数据收集到部署
Posted ChallengeHub
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了端到端机器学习:从数据收集到部署相关的知识,希望对你有一定的参考价值。
在本文中,我们将完成构建和部署机器学习应用程序的必要步骤。在开始之前,让我们看一下将要构建的应用程序:
在上面视频展示中,该Web应用程序允许用户通过撰写评论来评估某个品牌。在书写时,用户将实时查看其输入的情感分数以及建议的等级1至5。
如果建议的评分不反映其观点,则用户可以更改评分,然后提交。
您可以将其视为具有品牌情感评论模型的app,该模型可以建议用户随后进行调整和调整的评分。
要构建此应用程序,经历以下几个步骤,后面会逐一讲解:
使用Selenium和Scrapy收集和收集客户评论数据
使用PyTorch在此数据上训练深度学习情绪分类器
使用Dash构建交互式Web应用程序
设置REST API和Postgres数据库
使用Docker Compose对应用程序进行Docker化
部署到AWS
1 使用Selenium和Scrapy从Trustpilot抓取数据
为了训练一个情感分类器,我们需要数据。我们当然可以下载用于情感分析任务的开源数据集,比如Amazon极性或IMDB电影评论,但出于本教程的目的,我们将构建自己的数据集。我们将从Trustpilot获取客户评论。
Trustpilot.com是一家消费者评论网站,于2007年在丹麦成立。它提供全球企业的评论,每个月有近100万条新评论被发布。
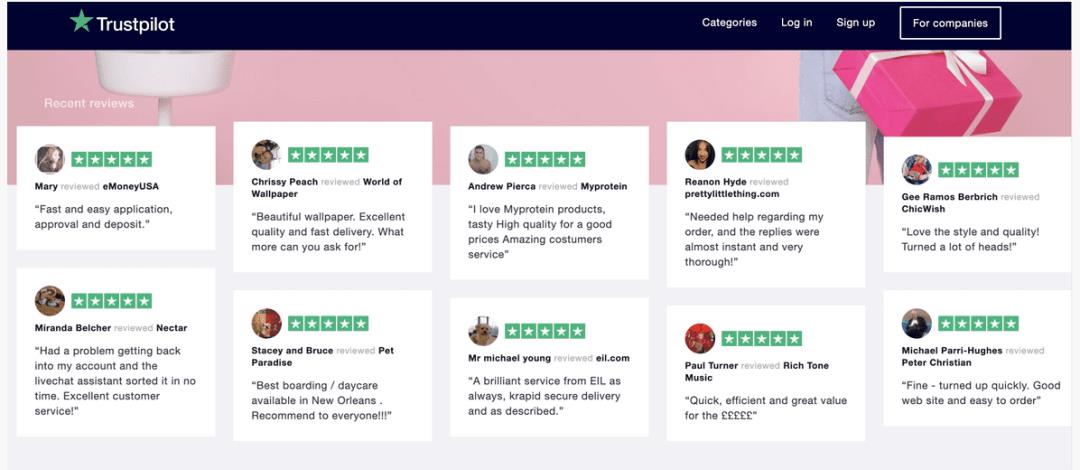
Trustpilot是一个有趣的来源,因为每个客户评论都与一些星星相关联。
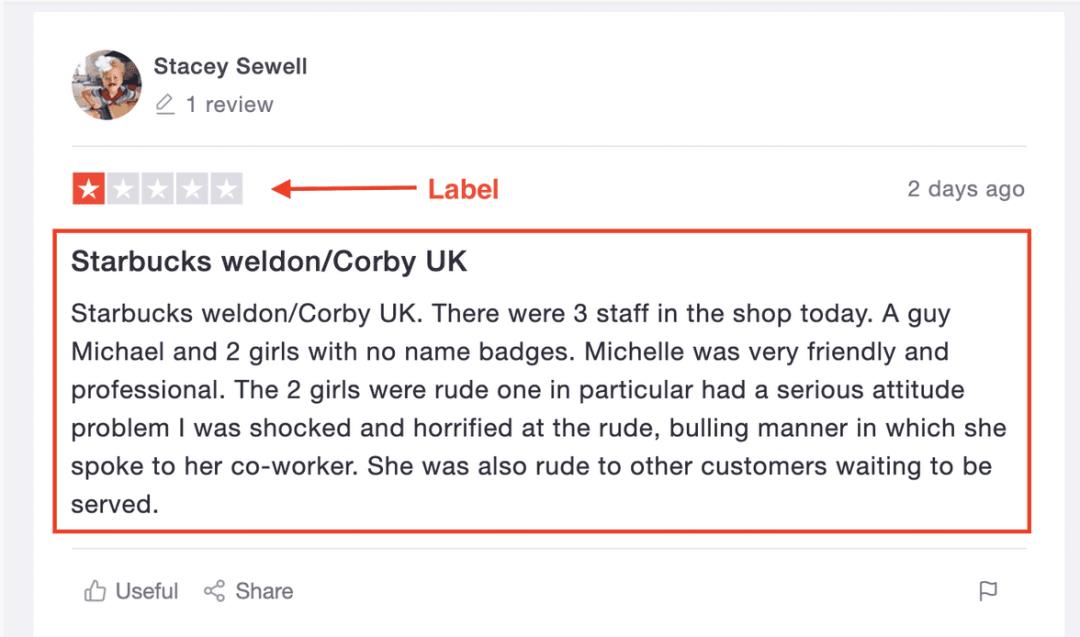
1星和2星差评❌
3星中等评价⚠️
4星和5星好评✅
要从Trustpilot抓取客户评论,我们首先必须了解网站的结构。Trustpilot按业务类别进行网页界面排版。
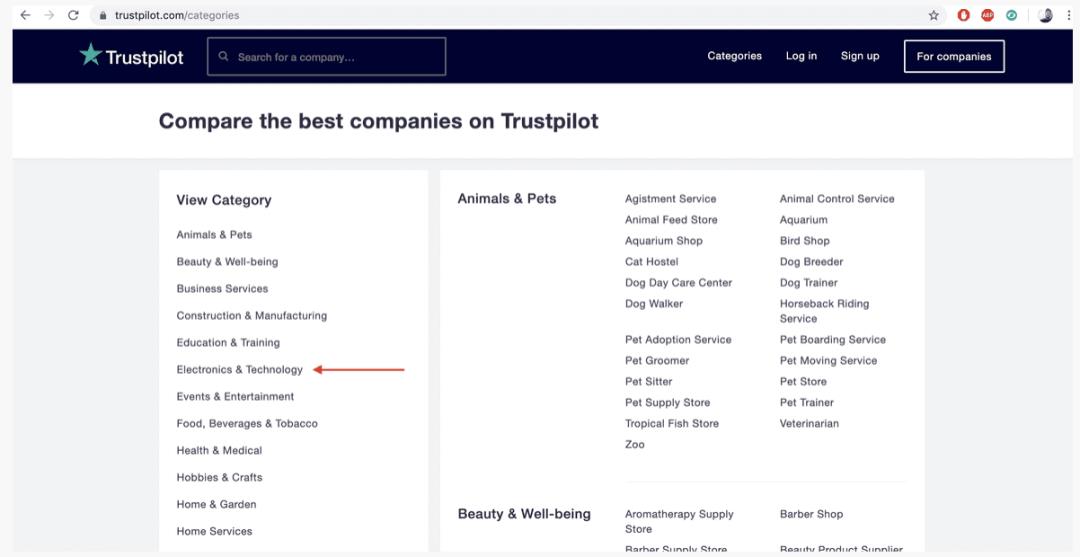
每个类别划分为子类别。
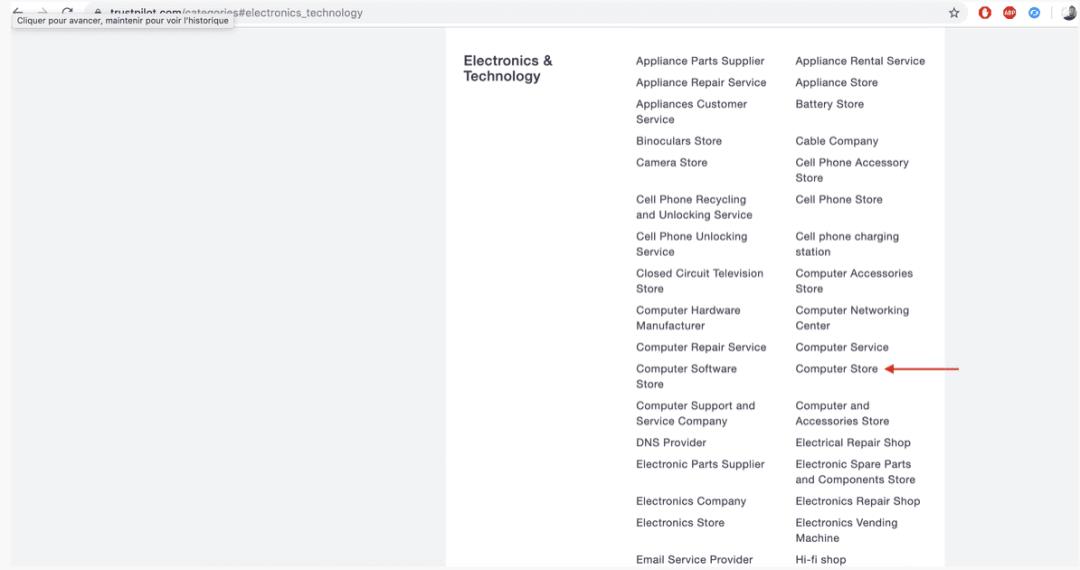
每个子类别划分为公司。
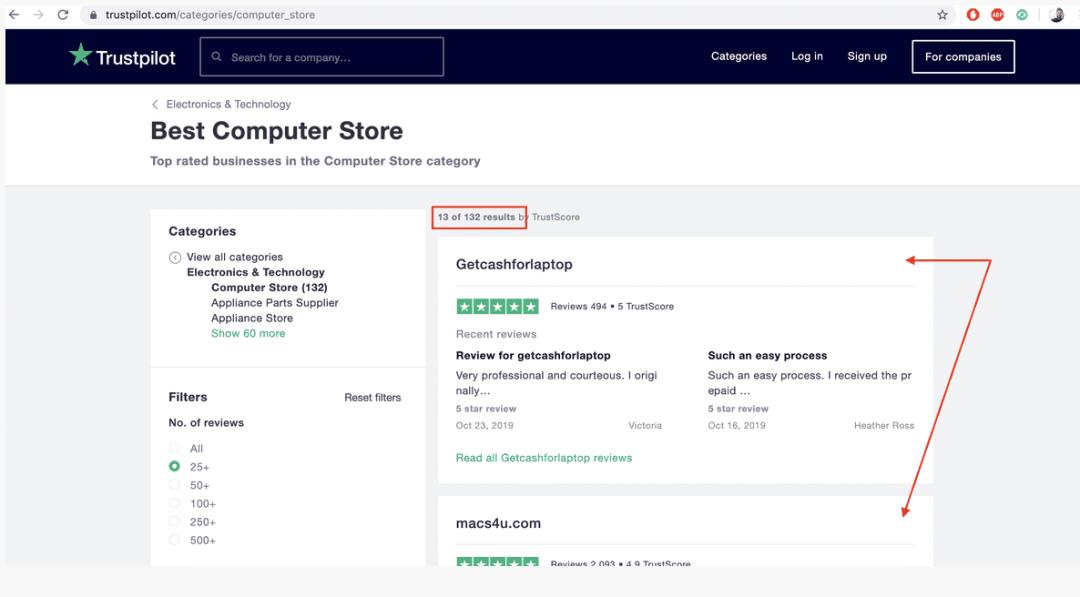
然后,每家公司都有自己的一套评论,通常会散布在许多页面上。
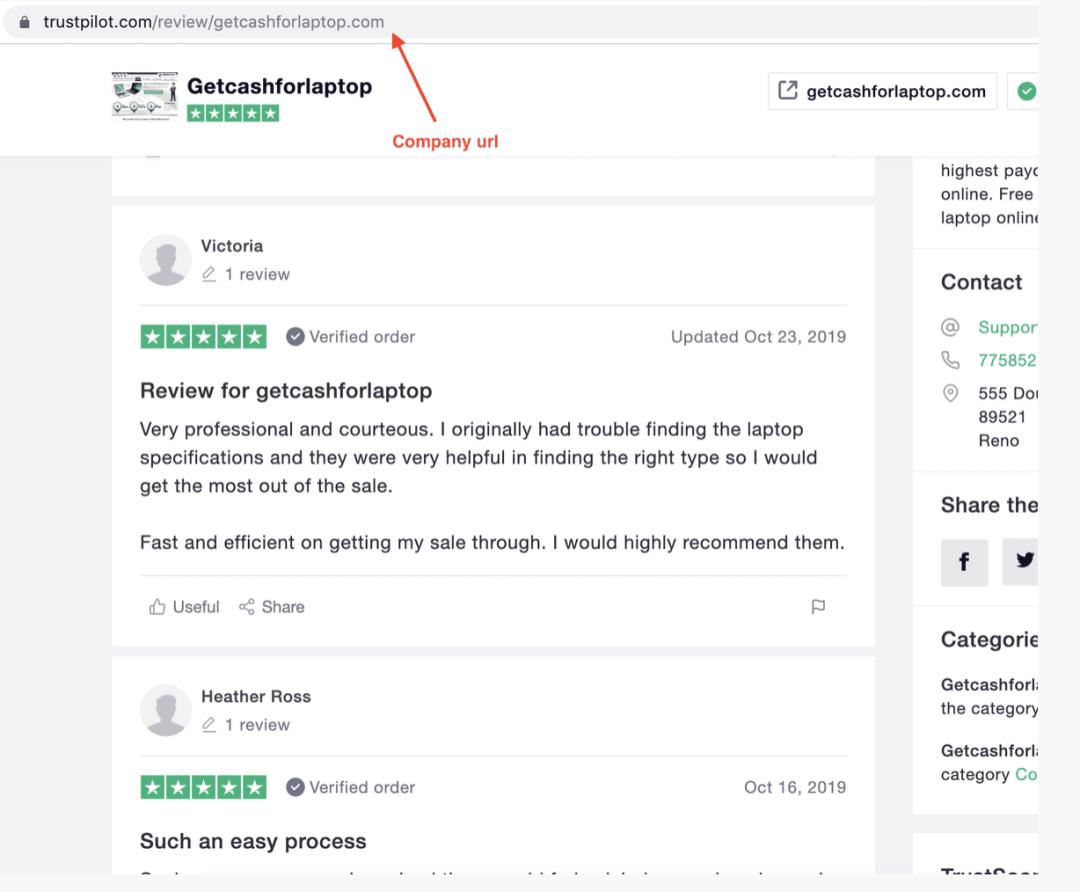
如您所见,这是一个自上而下的树结构。为了抽取评论,我们将分两步进行。
步骤1️⃣:使用Selenium获取每个公司页面的URL
步骤2️⃣:使用Scrapy从每个公司页面中提取评论
【步骤1: 使用Selenium抓取公司url】
所有Selenium代码都可以从这个记事本获得并运行
我们首先使用Selenium是因为呈现每个公司url的网站内容是动态的,这意味着不能从页面源直接访问它。它是通过Ajax调用在网站前端呈现的。Selenium在提取这类数据方面做得很好:它模拟了一个解释javascript呈现内容的浏览器。发布后,它会点击每个类别,缩小到每个子类别,然后逐个搜索所有公司,提取它们的url。完成后,脚本将这些url保存到CSV文件中。让我们看看这是如何做到的:我们将首先导入Selenium依赖项以及其他实用程序包。
import json
import time
from bs4 import BeautifulSoup
import requests
import pandas as pd
from selenium import webdriver
from selenium.common.exceptions import NoSuchElementException
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
from tqdm import tqdm_notebook
base_url = "https://trustpilot.com"
def get_soup(url):
return BeautifulSoup(requests.get(url).content, 'lxml')
我们首先获取每个类别内嵌套的子类别url。打开浏览器并检查源代码,就会发现位于div对象中的22个类别块(右边),它们的class属性等于category-object
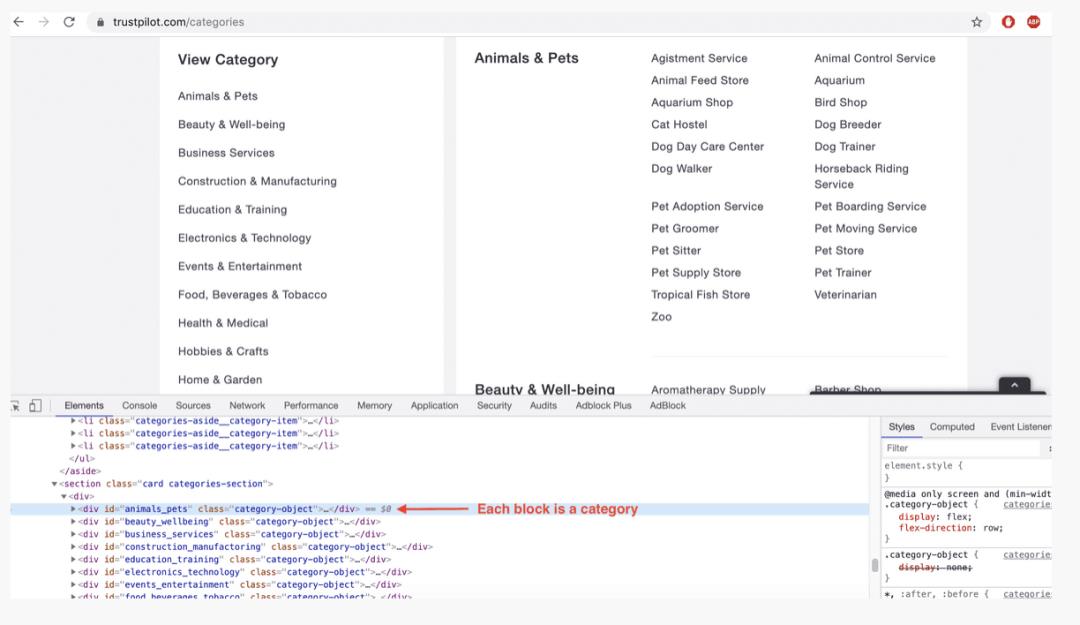
每个类别都有自己的一组子类别。它们位于类属性为child-category的div对象中。我们感兴趣的是找到这些子类别的url。
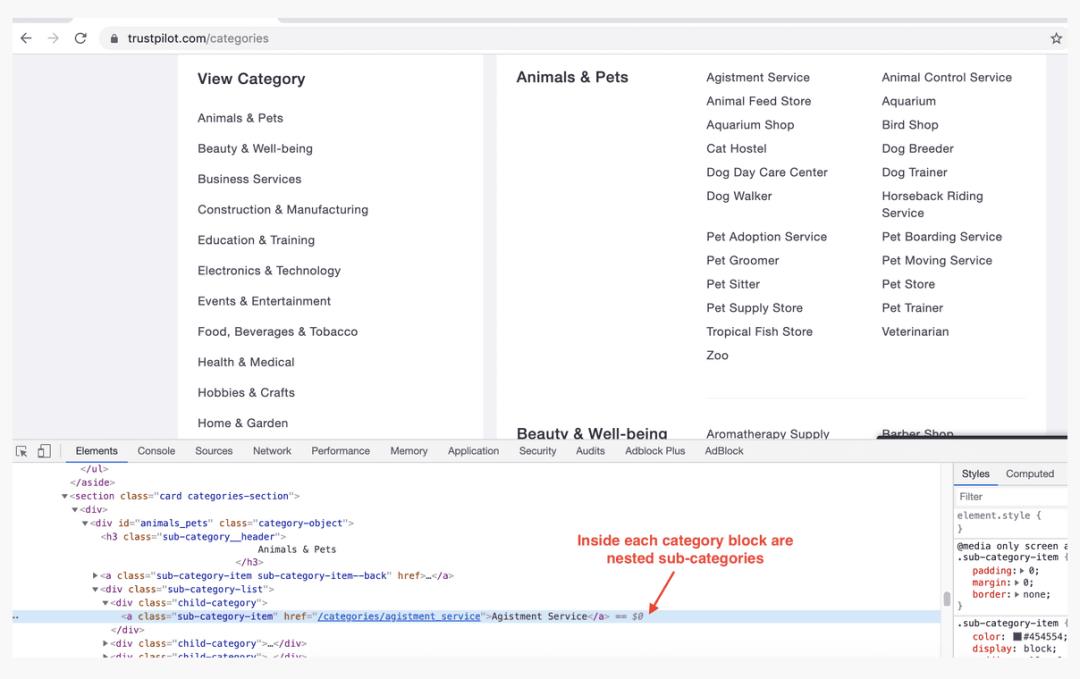
data = {}
soup = get_soup(base_url + '/categories')
for category in soup.findAll('div', {'class': 'category-object'}):
name = category.find('h3', {'class': 'sub-category__header'}).text
name = name.strip()
data[name] = {}
sub_categories = category.find('div', {'class': 'sub-category-list'})
for sub_category in sub_categories.findAll('div', {'class': 'child-category'}):
sub_category_name = sub_category.find('a', {'class': 'sub-category-item'}).text
sub_category_uri = sub_category.find('a', {'class': 'sub-category-item'})['href']
data[name][sub_category_name] = sub_category_uri
接下来是selenium部分:我们需要循环遍历每个子类别的公司并获取它们的url。 公司在每个子类别中是这样显示的:
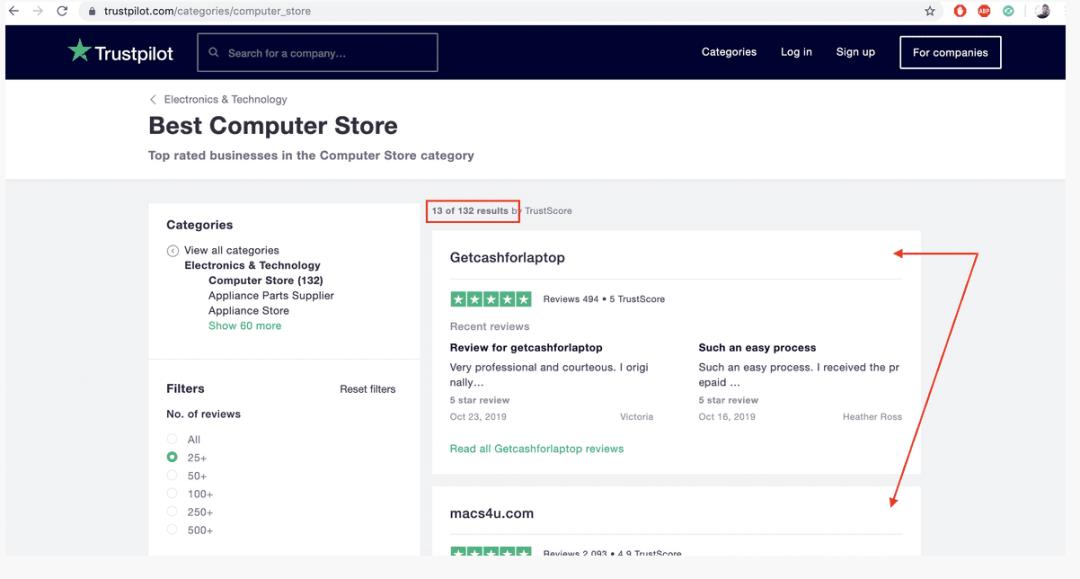
def extract_company_urls_form_page():
a_list = driver.find_elements_by_xpath('//a[@class="category-business-card card"]')
URLs = [a.get_attribute('href') for a in a_list]
dedup_urls = list(set(URLs))
return dedup_urls
检查下一页按钮是否存在的功能:
def go_next_page():
try:
button = driver.find_element_by_xpath('//a[@class="button button--primary next-page"]')
return True, button
except NoSuchElementException:
return False, None
现在我们用一个无头Chromedriver初始化Selenium。这可以防止Selenium打开窗口,从而加速抓取。
options = Options()
options.add_argument('--headless')
options.add_argument('--no-sandbox')
options.add_argument('start-maximized')
options.add_argument('disable-infobars')
options.add_argument("--disable-extensions")
prefs = {"profile.managed_default_content_settings.images": 2}
options.add_experimental_option("prefs", prefs)
driver = webdriver.Chrome('./driver/chromedriver', options=options)
timeout = 3
timeout变量是Selenium等待页面完全加载的时间(以秒为单位)。现在我们开始抓取。在良好的互联网连接下,这大约需要50分钟。
company_urls = {}
for category in tqdm_notebook(data):
for sub_category in tqdm_notebook(data[category], leave=False):
company_urls[sub_category] = []
url = base_url + data[category][sub_category] + "?numberofreviews=0&timeperiod=0&status=all"
driver.get(url)
try:
element_present = EC.presence_of_element_located(
(By.CLASS_NAME, 'category-business-card card'))
WebDriverWait(driver, timeout).until(element_present)
except:
pass
next_page = True
c = 1
while next_page:
extracted_company_urls = extract_company_urls_form_page()
company_urls[sub_category] += extracted_company_urls
next_page, button = go_next_page()
if next_page:
c += 1
next_url = base_url + data[category][sub_category] + "?numberofreviews=0&timeperiod=0&status=all" + f'&page={c}'
driver.get(next_url)
try:
element_present = EC.presence_of_element_located(
(By.CLASS_NAME, 'category-business-card card'))
WebDriverWait(driver, timeout).until(element_present)
except:
pass
consolidated_data = []
for category in data:
for sub_category in data[category]:
for url in company_urls[sub_category]:
consolidated_data.append((category, sub_category, url))
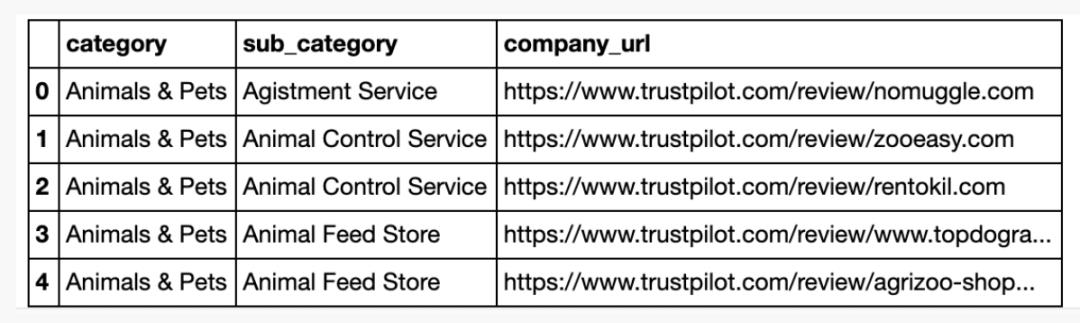
df_consolidated_data = pd.DataFrame(consolidated_data, columns=['category', 'sub_category', 'company_url'])
df_consolidated_data.to_csv('./exports/consolidate_company_urls.CSV', index=False)
收集的数据展示如下,下面我们将从url中抽取评论:
【步骤2:用Scrapy爬虫客户评论】
所有的scrapy代码都可以在这个文件夹中找到
通过下面这个命令重启一个项目
cd src/scraping/scrapy
scrapy startproject trustpilot
scrapy/
scrapy.cfg # deploy configuration file
trustpilot/ # project's Python module, you'll import your code from here
__init__.py
items.py # project items definition file
middlewares.py # project middlewares file
pipelines.py # project pipelines file
settings.py # project settings file
spiders/ # a directory where you'll later put your spiders
__init__.py
为了构建我们的scraper,我们必须在spiders文件夹中创建一个蜘蛛。我们将它命名为scraper.py,并修改settings.py中的一些参数,我们不会更改其他文件。
它从公司网址开始
它会经过每个客户的文本,并产生包含以下项目的数据字典
评论:文字评论
评分:星数(1至5)
url_website:Trustpilot上的公司URL
company_name:正在审查的公司名称
company_website:正在审核的公司的网站
company_logo:正在审核的公司徽标的URL
如果有下一页,它将移至下一页
import re
import pandas as pd
import scrapy
class Pages(scrapy.Spider):
name = "trustpilot"
company_data = pd.read_csv('../selenium/exports/consolidate_company_urls.CSV')
start_urls = company_data['company_url'].unique().tolist()
def parse(self, response):
company_logo = response.xpath('//img[@class="business-unit-profile-summary__image"]/@src').extract_first()
company_website = response.xpath("//a[@class='badge-card__section badge-card__section--hoverable']/@href").extract_first()
company_name = response.xpath("//span[@class='multi-size-header__big']/text()").extract_first()
comments = response.xpath("//p[@class='review-content__text']")
comments = [comment.xpath('.//text()').extract() for comment in comments]
comments = [[c.strip() for c in comment_list] for comment_list in comments]
comments = [' '.join(comment_list) for comment_list in comments]
ratings = response.xpath("//div[@class='star-rating star-rating--medium']//img/@alt").extract()
ratings = [int(re.match('d+', rating).group(0)) for rating in ratings]
for comment, rating in zip(comments, ratings):
yield {
'comment': comment,
'rating': rating,
'url_website': response.url,
'company_name': company_name,
'company_website': company_website,
'company_logo': company_logo
}
next_page = response.css('a[data-page-number=next-page] ::attr(href)').extract_first()
if next_page is not None:
request = response.follow(next_page, callback=self.parse)
yield request
在启动scraper之前,必须在seetings.py中改变一些代码:
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Configure maximum concurrent requests performed by Scrapy (default: 16)
CONCURRENT_REQUESTS = 32
#Export to CSV
FEED_FORMAT = "CSV"
FEED_URI = "comments_trustpilot_en.CSV"
scraper忽略机器人。使用32个并发请求,并将数据导出为CSV格式的文件:comments_trustpilot_en.CSV,接下来启动scraper:
cd src/scraping/scrapy
scrapy crawl trustpilot2 用PyTorch训练一个情感分类器
这里使用基于字符的CNN,要训练字符级别的CNN,将在src/training/文件夹下找到所需的所有文件。
这是此文件夹中代码的结构:
train.py:用于训练模型
predict.py:用于测试和推断
src:包含以下内容的文件夹:
model.py:实际的CNN模型(模型初始化和转发方法
dataloader.py:负责处理后将数据传递给训练的脚本
utils.py:一组用于文本预处理的功能(URL /#/ user_@删除)
要训练我们的分类器,请运行以下命令:
cd src/training/
python train.py --data_path ./data/tp_amazon.CSV
--validation_split 0.1
--label_column rating
--text_column comment
--max_length 1014
--dropout_input 0
--group_labels 1
--balance 1
--ignore_center 0
--model_name en_trustpilot
--log_every 250
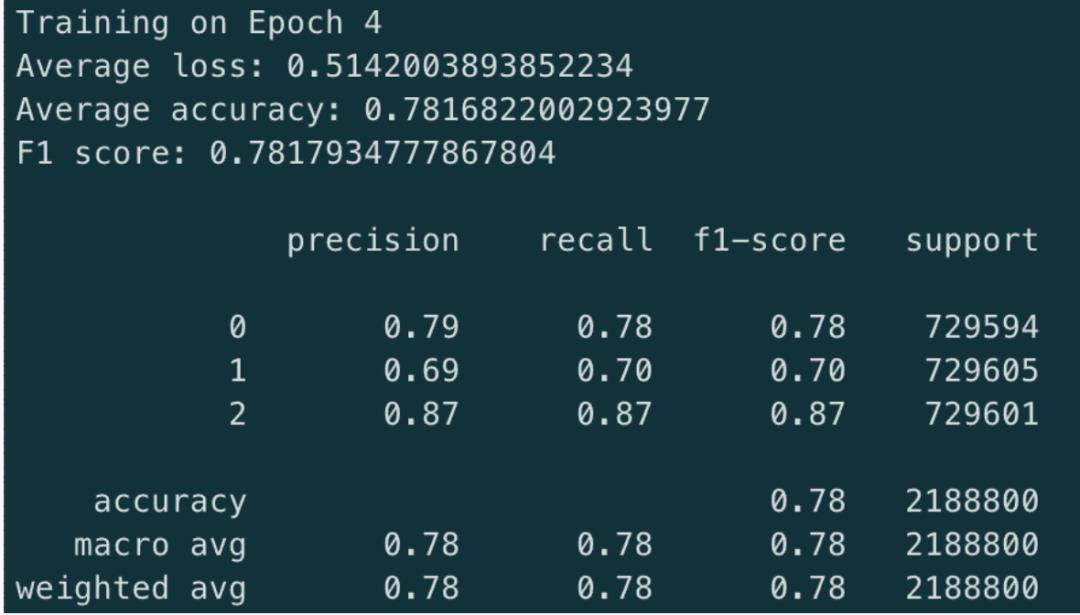
2.1 模型表现
训练集上,最佳模型的指标展示:
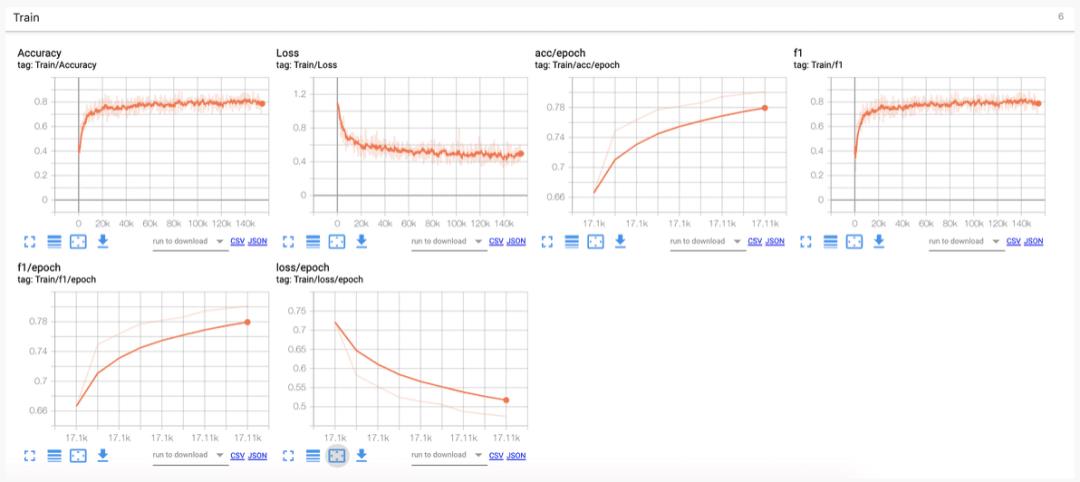
训练集的日志:
验证集的日志:
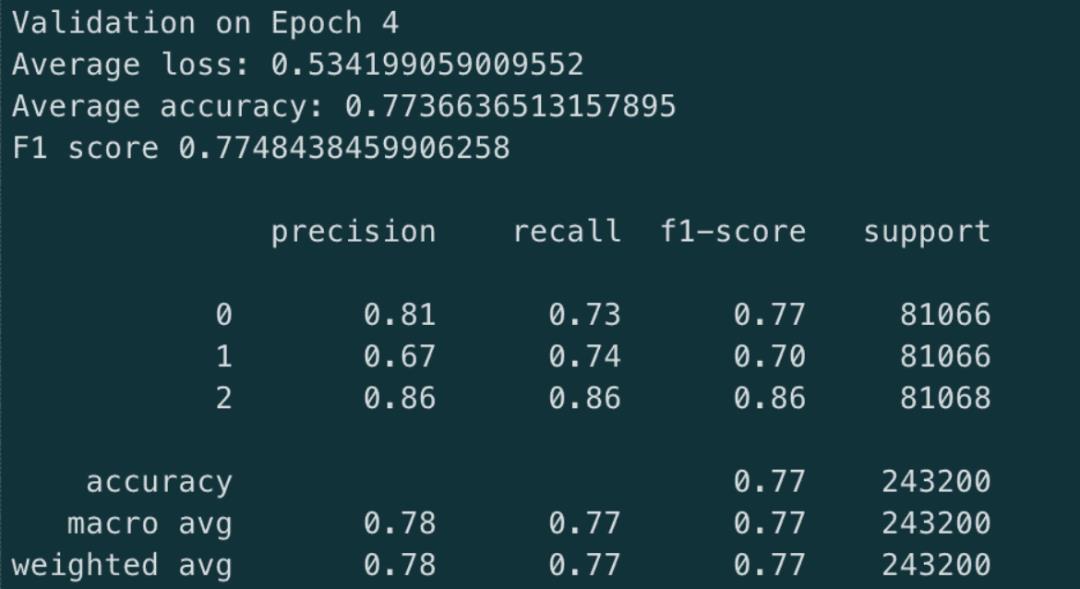
验证集日志:
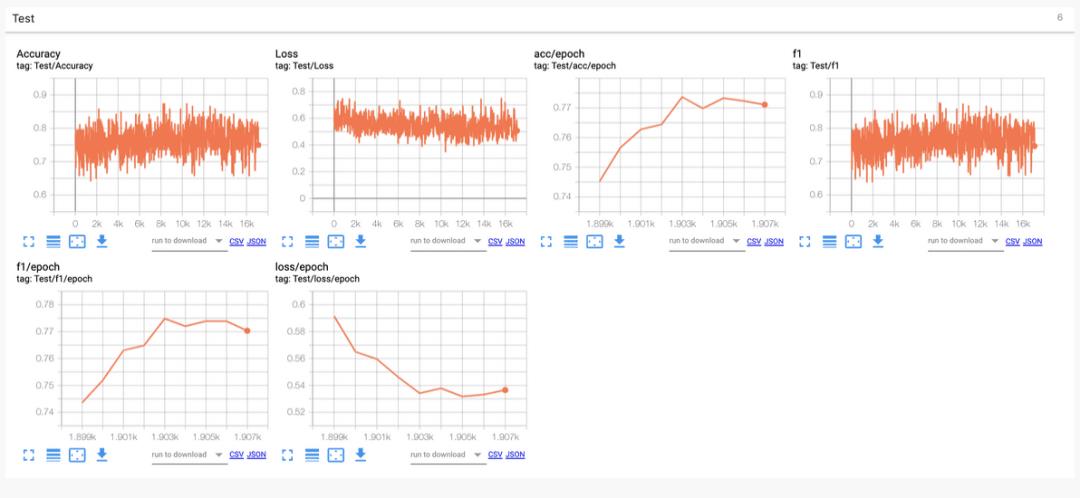
在上述的结果展示中,可以发现;
模型在不断减少的损失中正在学习并正确收敛
该模型非常擅长识别好坏评论。不过,它在中等评论中的表现略低。
三分类问题比二分类问题困难。如果您关注二分类问题,则可以达到95%的准确性;但是训练3分类器的优势是可以识别出有趣的评论。
3 使用Dash、Flask、PostgreSQL构建交互式Web应用程序
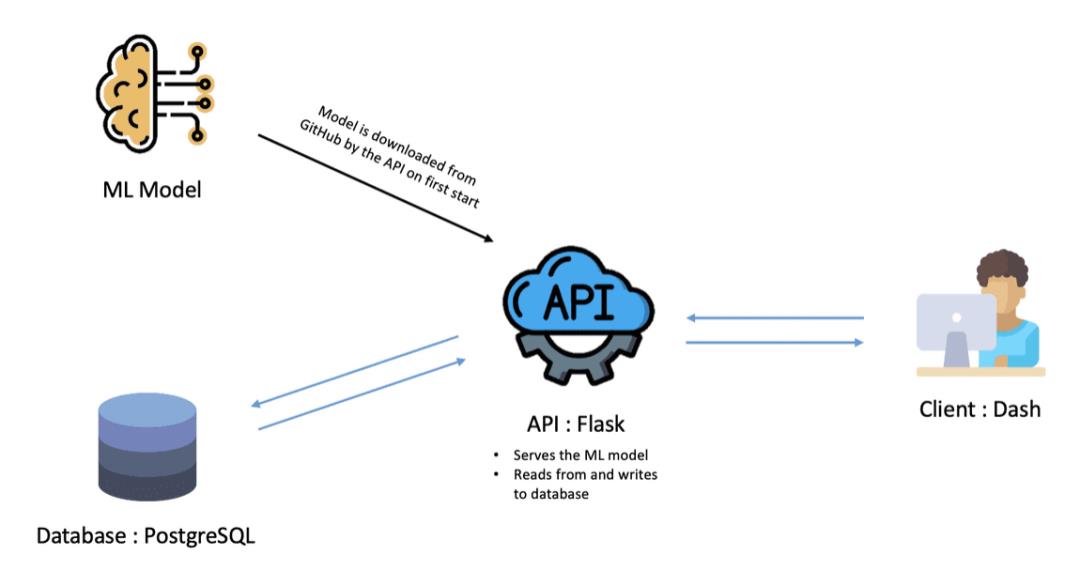
图:应用程序架构
4 Docker Compose应用程序
Docker是一种流行的工具,可简化使用容器构建,部署和运行应用程序的过程。容器使我们可以打包应用程序需要的所有东西,例如库和其他依赖项,并将它们作为一个单独的包打包。这样,我们的应用程序可以在任何计算机上运行,并且具有相同的行为。
Docker还提供了一个很棒的工具来管理多容器应用程序:docker-compose。通过Compose,您可以使用YAML文件来配置应用程序的服务。然后,使用一个命令,就可以从配置中创建并启动所有服务。
这是运行两个服务(web和redis)Docker Compose的简单示例:
version: '3'
services:
web:
build: .
ports:
- "5000:5000"
redis:
image: "redis:alpine"
我们先看一下如何dockerized我们的app
首先,我们将项目分成三个容器,每个容器负责应用程序的一个服务db
api
dash
version: '3'
services:
db:
image: postgres
environment:
- POSTGRES_DB=postgres
- POSTGRES_USER=postgres
- POSTGRES_PASSWORD=password
volumes:
- ~/pgdata:/var/lib/postgresql/data
restart: always
api:
build:
context: src/api
dockerfile: Dockerfile
environment:
- ENVIRONMENT=prod
- POSTGRES_HOST=db
- POSTGRES_PORT=5432
- POSTGRES_DB=postgres
- POSTGRES_USER=postgres
- POSTGRES_PASSWORD=password
depends_on:
- db
restart: always
dash:
build:
context: src/dash
dockerfile: Dockerfile
ports:
- "8050:8050"
environment:
- ENVIRONMENT=prod
- API_URL=http://api:5000/api
depends_on:
- api
restart: always
db
db:
image: postgres # official postgres image
environment:
- POSTGRES_DB=postgres
- POSTGRES_USER=postgres
- POSTGRES_PASSWORD=password
volumes:
- ~/pgdata:/var/lib/postgresql/data
restart: always
api
api:
build:
context: src/api
dockerfile: Dockerfile
environment:
- ENVIRONMENT=prod
- POSTGRES_HOST=db
- POSTGRES_PORT=5432
- POSTGRES_DB=postgres
- POSTGRES_USER=postgres
- POSTGRES_PASSWORD=password
depends_on:
- db
restart: always
dash
dash:
build:
context: src/dash
dockerfile: Dockerfile
ports:
- "8050:8050"
environment:
- ENVIRONMENT=prod
- API_URL=http://api:5000/api
depends_on:
- api
restart: always
5 部署到AWS
首先让我们看一下我们设计的全局部署架构: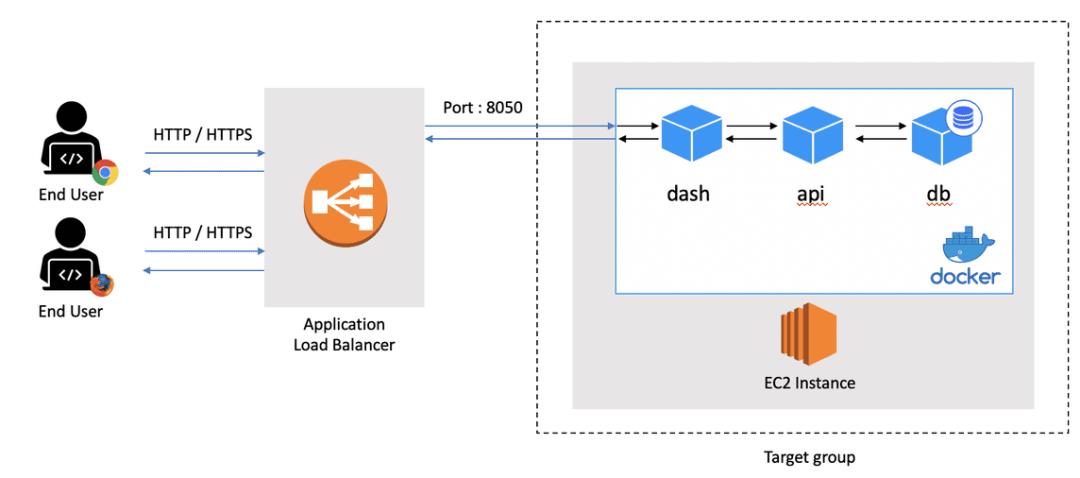
当用户从浏览器访问reviews.ai2prod.com时,会将请求发送到DNS服务器,然后将其重定向到负载平衡器。负载平衡器将其请求重定向到目标组内的EC2实例。最终,当docker-compose在端口8050上接收到请求时,它将其重定向到Dash容器。
5.1 在EC2实例上部署应用
部署过程的第一步就是启动一个实例来部署我们的应用程序。
为此,请转到AWS Console的EC2页面,然后单击“启动实例”。
您将需要选择一个AMI。我们使用了Amazon Linux 2,但是您可以选择任何基于Linux的实例。
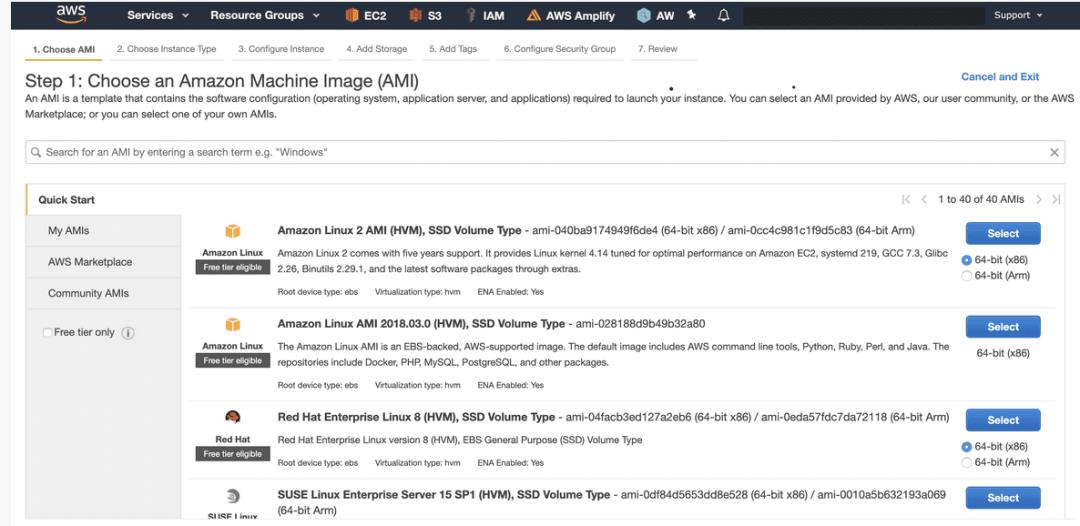
然后,您需要选择一个实例类型。我们选择了t3a.large,但您可以选择较小的t3a.large。
您还需要配置一个安全组,以便可以进入实例,并访问运行dash应用程序的8050端口。这样做如下:
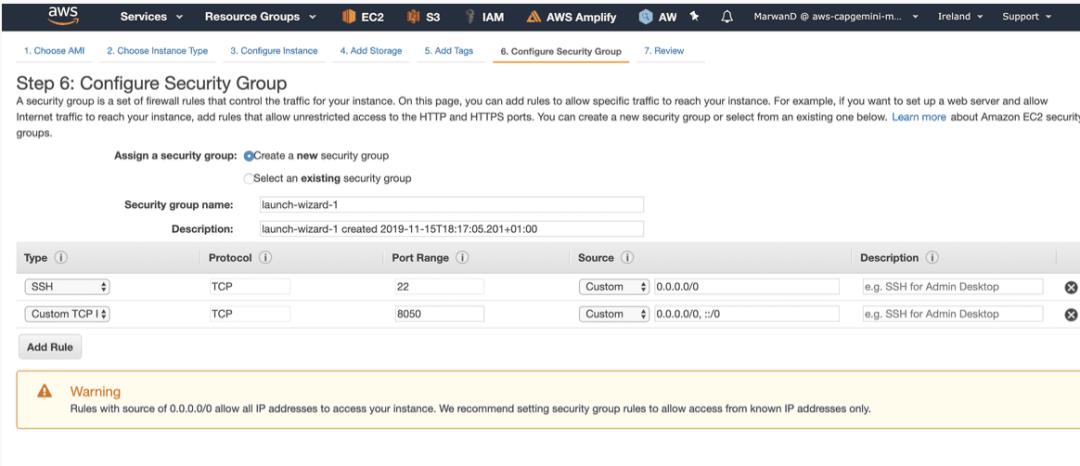
现在我们有了实例,开始启动:
ssh -i path/to/key.pem ec2-user@public-ip-addresssudo yum update -y
sudo amazon-linux-extras install docker
sudo service docker start
sudo usermod -a -G docker ec2-user需要注销并重新登录,然后安装docker compose:
sudo curl -L "https://github.com/docker/compose/releases/download/1.24.1/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
sudo chmod +x /usr/local/bin/docker-compose$ docker-compose --version
docker-compose version 1.24.1, build 4667896bsudo yum install git
git clone https://github.com/MarwanDebbiche/post-tuto-deployment.gitcd post-tuto-deployment
docker-compose up --build -d6 下一步
在构建此应用程序时,我们想到了许多没有来得及成功添加的改进。
特别是,我们希望:
为管理页面和GET /api/reviews路由添加服务器端分页。
通过身份验证保护管理员页面。
使用Kubernetes或Amazon ECS将应用程序部署在容器集群上,而不是在单个EC2实例上。
与Travis CI一起使用连续部署
对数据库使用托管服务,例如RDD
7 结论
在整个教程中,您学习了如何通过数据收集和抓取,模型训练,Web应用程序开发,Docker和部署来从头开始构建机器学习应用程序。
该应用程序的每个模块都是独立包装的,可轻松用于其他类似用例。
参考文献
https://www.ahmedbesbes.com/blog/end-to-end-machine-learning
https://github.com/MarwanDebbiche/post-tuto-deployment/blob/master/src/scraping/selenium/scrape_website_urls.ipynb
https://github.com/MarwanDebbiche/post-tuto-deployment/tree/master/src/scraping/scrapy

以上是关于端到端机器学习:从数据收集到部署的主要内容,如果未能解决你的问题,请参考以下文章