如何一步步提升Go内存缓存性能
Posted GoCN
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何一步步提升Go内存缓存性能相关的知识,希望对你有一定的参考价值。
ecache是一款极简设计、高性能、并发安全、支持分布式一致性的轻量级内存缓存,支持LRU和LRU-2两种模式基于真实的度量。——《重构——改善现有代码的设计》P69
哪怕你完全了解系统,也请实际度量它的性能,不要臆测。臆测会让你学到一些东西,但十有八九你是错的。
思路我期望能够有一个仓库,每次优化以后,都能横向比较同类库之间的性能,并且通过直观的柱状图之类的图表展示出来,于是有了benchplus/gocache项目,它是一个持续基准测试的项目。
第一版我设计了写入和读取整型、写入1K/1M数据、写入小对象(bigcache和freecache需要序列化)、写满以后继续写入整型等用例。第二版又增加了并发读写、GC耗时、命中率、内存占用等用例。
brew install graphviz运行一次ecache的测试用例
sh>
GO111MOUDLE=off go test -bench=BenchmarkGetInt_ecache ecache_test.go -cpuprofile=cpu.prof剖析结果文件
sh>
go tool pprof benchplus.test cpu.prof
交互模式下:(pprof) svg分析生成的svg图
bigcache读取整型值的性能在 80ns/op 左右,但是ecache在第一版只能跑出 100ns/op 左右的性能。hashCode占了总耗时的50%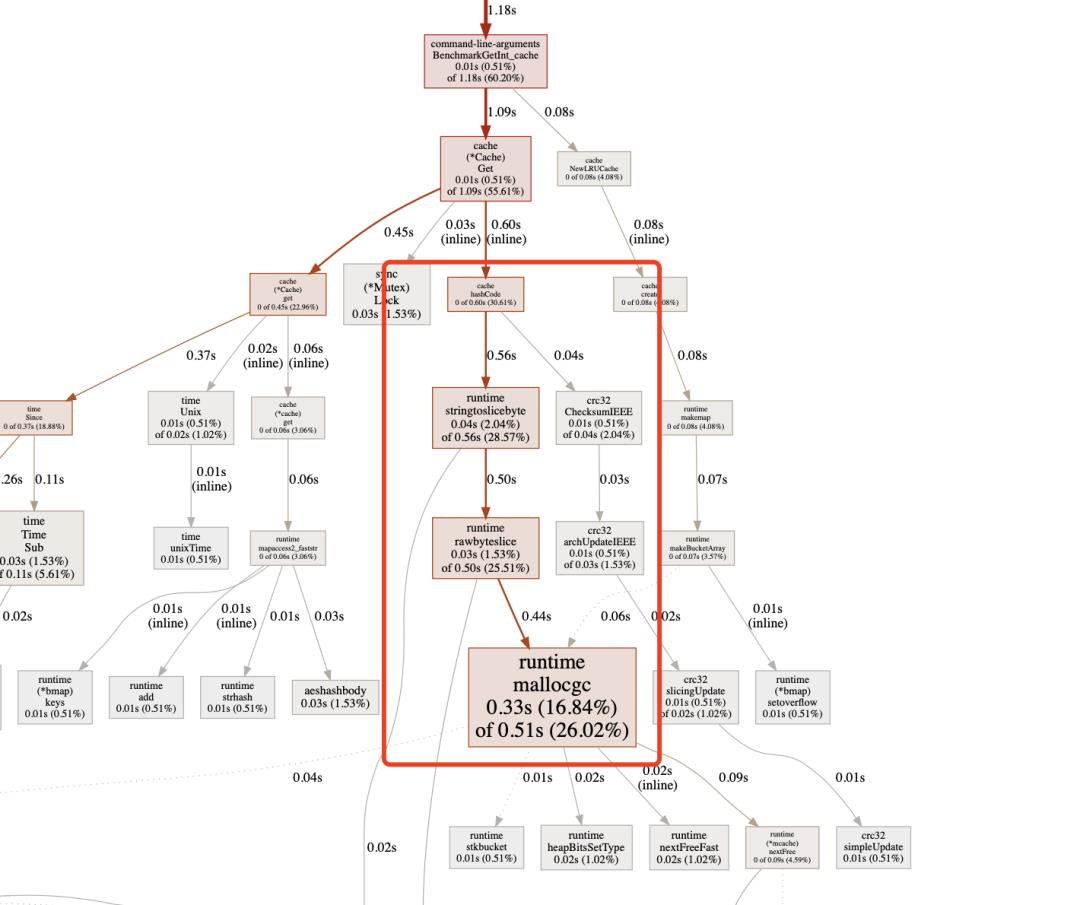
分析剖析结果,发现大部分时间花在了string转[]byte产生临时对象的产生和销毁上
优化思路:换一种hash方法,按照以前的经验,BKRD和AP的分布性比较好,BKRD实现更简单,性能也不错,所以选择BKRD替代CRC32【commit-0e7aaaae】
func hashBKRD(s string) (hash int32)
for i := 0; i < len(s); i++
hash = hash*131 + int32(s[i])
return hash
time.Now()占了总耗时的33%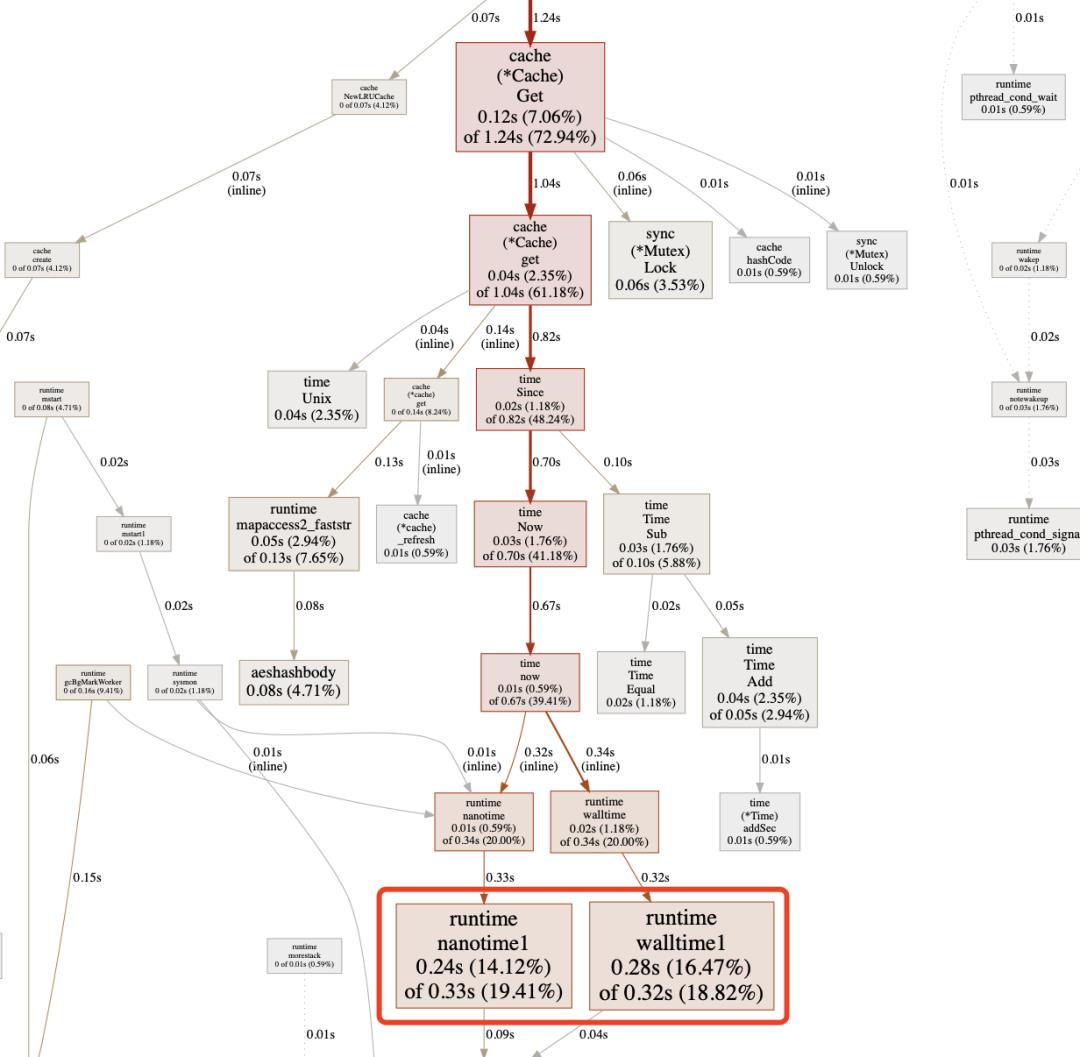
优化思路:由于内部只需要时间戳,并且缓存系统要求的时间戳并不一定那么精准,所以考虑用维护一个全局时间戳的方式来优化————短期自增(每100ms)、定期校准(约1s)
time.Now()【代码版本快照】改为内部计时器【commit-8dc1fa7d】,获取当前时间使用内部的now()方法可直接获得时间戳,而不再需要使用会产生临时对象的time.Now().UnixNano()
内部计时器最初采用time.Timer实现,实际测试发现定时器会受系统压力影响,精度无法保证,后改为time.Sleep【commit-92245e4b】
var clock = time.Now().UnixNano()
func now() int64 return atomic.LoadInt64(&clock)
func init()
go func()
for
atomic.StoreInt64(&clock, time.Now().UnixNano()) // 每秒校准
for i := 0; i < 9; i++
time.Sleep(100 * time.Millisecond)
atomic.AddInt64(&clock, int64(100*time.Millisecond))
time.Sleep(100 * time.Millisecond)
()
本次优化完成以后,读取整型性能提升至40ns/op,从设计的指标来看,ecache的数据都已名列前茅
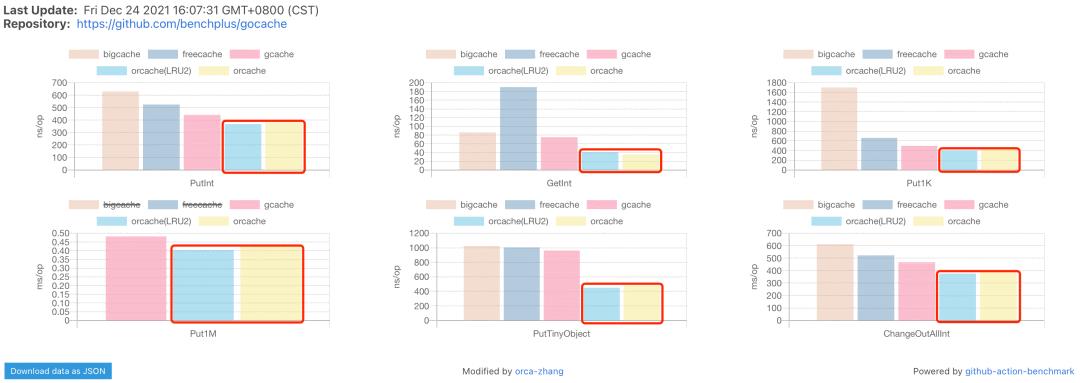
虽然通过bigcache提供的bench,得到的数据比bigcache本身要好(后分析可能是因为在平时写入时把GC耗时分担到了总耗时,而bench里没有总耗时统计),但是随后又添加的并发读写测试和GC测试中发现ecache优势不明显,比如写整型值的GC耗时是当时最快的bigcache(80ms左右)的2倍多(200ms左右),写1K数据的GC耗时是当时最快的freecache的3倍多。
从剖析结果来看,重点方向在三个方面
双链表节点实现成不需要产生临时节点指针的形式
用一次性预分配的连续区域存储节点
用索引列表来表达双链表
type node struct
k string
v value
expireAt int64 // 纳秒时间戳,为0说明被标记删除
type cache struct
dlnk [][2]uint16 // 双链表索引列表,第0个元素存储尾节点索引,头节点索引,其他元素存前序节点索引,后继节点索引
m []node // 预分配连续空间内存
hmap map[string]uint16 // <key,dlnk中的位置>
last uint16 // 没有满时,分配到的位置
一些取巧的设计
last字段和连续节点空间的容量比较来判断是否分配满if c.last == uint16(cap(c.m)) // 分配满了
dlnk用n+1个元素来存储索引,每个元素都是前序节点索引, 后继节点索引dlnk[0]存储的是尾节点索引,头节点索引adjust方法,通过参数就能实现将元素移动到头部还是尾部的功能ajust(x, p, n)移动到头部ajust(x, n, p)移动到尾部调整完效果还不错,mallogc缩短了、_refresh时候的gcWriteBarrier也不见了
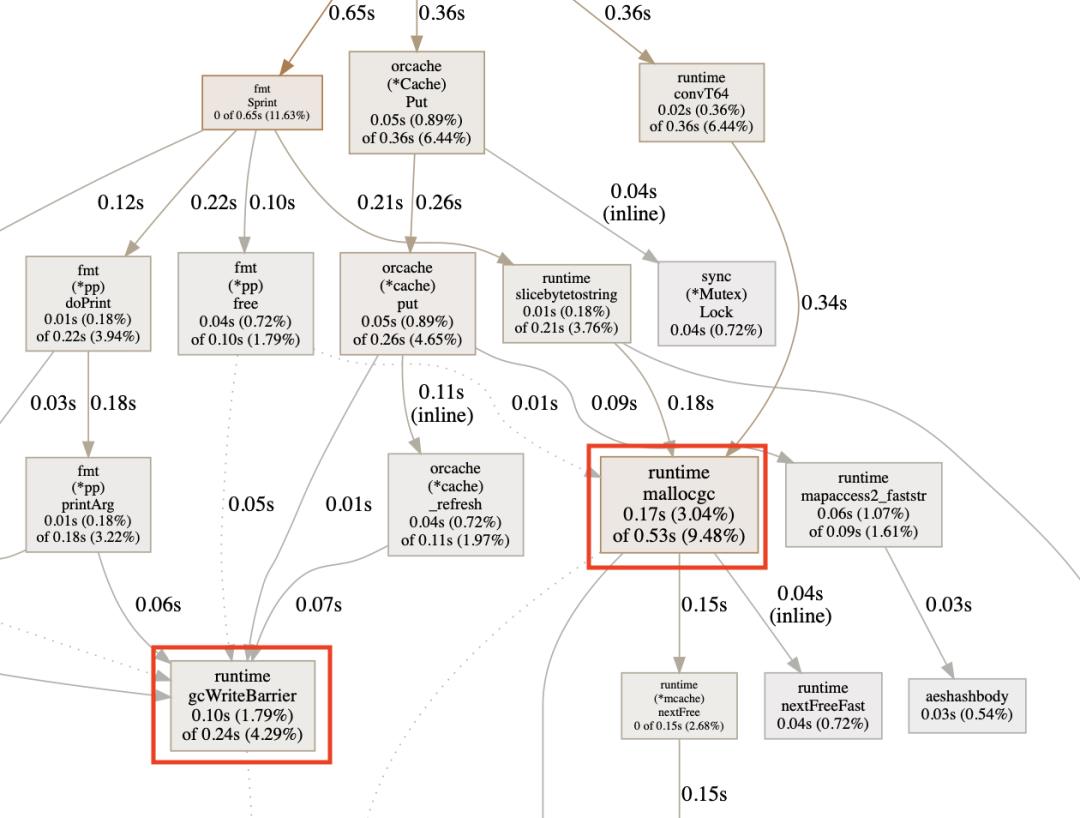
interface的问题还没有解决,尝试直接用int64存储value,性能好很多,比bigcache要快,但是这并不是ecache设计的初衷,我们期望能够适应不同场景,并且能存储不同类型的对象
先尝试用一个包装器把interface类型和int64类型分开放置
type value struct
v *interface // 存放任意类型
i int64 // 存放整型
但是性能差很多,剖析发现是包装以后的临时对象太多,于是尝试用1000大小的ringbuffer实现了一个对象池,优化了分配性能,结果能和bigcache相同了,感兴趣的可以了解一下源码
不过最终没有使用,因为灵机一动,发现node的value字段,不用对象指针(单纯栈对象拷贝赋值)和用指针加ringbuffer性能是一样的(好险!差点就变复杂了
AVG内存缓存清理,提升你手机性能
小伙伴们大家晚上好,小编作为职业玩机党,手机下载一些app软件是必不可少的,但下载的软件越多,垃圾文件肯定也多,对手机性能是一大伤害,而且电池也用不久,于是小编分享一款专业的内存及缓存清理工具,同时可以根据用户自己的设置按照天或者周进行固定清除,从而使手机运行更流畅,节省宝贵空间并帮助提升设备性能和速度!有些小伙伴手机可能性能卡顿或者是电池不耐用,可以来试试它。
AVG Cleaner Pro「AVG内存缓存清理」可以快速擦除、清除和清理您的浏览器、缩略图、空文件夹、各种缓存……,以及从设备的内存和 SD 卡中识别和删除不需要的 RAM 缓存的应用程序数据。整理手机,清理储存空间让您的手机运行更快更顺畅,并提升速度和性能。

1、轻松两步就能为更重要的内存腾出空间。自动识别不需要的照片和类似照片,只需点击一下,就可以找到您所有几乎重复的、暗色的,模糊或质量差的照片。
2、轻松清理您的浏览器、剪贴板、应用商店和电子邮件,查看并轻松清理超过 5 MB 的媒体文件和文档。
3、应用会根据最近一次使用时间接收每周顾问有关“很少使用的应用程序”的通知,您就可以选择想要保留和想要移除的应用程序。通过强制停止耗用 RAM 的正运行应用程序,以完全停止其活动,包括后台进程和通知,直至您主动将其再次启动,以节约 RAM 空间,提升运行速度。
4、电池优化:省电助手可以帮助您查看耗电项并轻松关掉不需要的项,从而为节约电量,提升设备续航能力。电池配置文件可在车内、电量不足、家里、办公之间进行选择,当然您也可以手动添加自己的配置文件,让手机以您想要的方式运行。
应用下载

关键词“app176”获取资源

免责声明:暗转列机旗下软件均来源于网络,仅作学习和交流,请勿用于任何商业或其他非法用途,如有侵权请联系责编删除!
收集不易,若对你有所帮助,别忘了点个在看哦
以上是关于如何一步步提升Go内存缓存性能的主要内容,如果未能解决你的问题,请参考以下文章