分享 2 个 Go1.18 新特性的官方教程
Posted 脑子进煎鱼了
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分享 2 个 Go1.18 新特性的官方教程相关的知识,希望对你有一定的参考价值。
大家好,我是煎鱼。
最近官方更新了一篇新博文《Two New Tutorials for 1.18[1]》,用于面向有一些复杂和理解难度的新特性进行分享和教学。

今天煎鱼就整理了内容,文末有获取在线和离线教程的方式,方便大家进行快速的学习和理解。
泛型特性第一个新教程《Tutorial: Getting started with generics[2]》:

该教程将帮助你开始使用泛型,引导你创建一个可以处理多种类型的泛型函数,并从你的代码中调用它。

一旦创建了一个泛型函数后,就需要了解类型约束,并为你的函数编写一些约束。也可以考虑看看 GopherCon 关于《Generics[3]》的讲座,以学习更多。
模糊测试第二个新教程《Tutorial: Getting started with fuzzing[4]》:
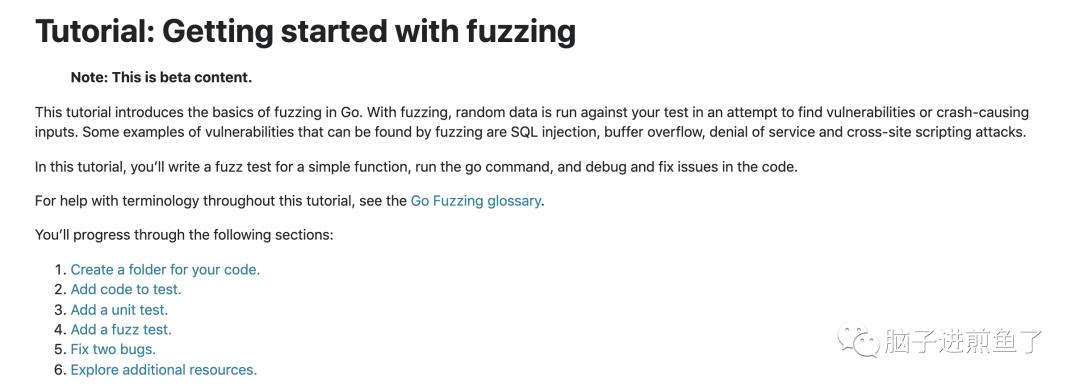
该教程将帮助你开始进行模糊处理。演示了模糊分析如何在你的代码中发现错误,并介绍了诊断和修复问题的过程。
在本教程中,将编写有一些 BUG 的代码,并使用模糊分析来寻找、修复和验证使用 Go 命令的 BUG。
总结Go1.18 Beta1 已经在前段时间发布,在本月(2月份)很快就会发布 Go 1.18,也就是泛型即将要正式问世了。
这个新版本包含一些 Go 的全新概念,想必官方对社区接受度也有一定的担忧,为此发布了两个新教程来帮助大家了解这些即将推出的功能。建议大家都看看!
可以在这个公众号回复【118】,会有离线版的 Go 官方教程获取。
未关注的需关注:
也可以直接根据下方的参考链接访问外网在线查看。
学起来!
参考资料Two New Tutorials for 1.18: https://go.dev/blog/tutorials-go1.18
[2]Tutorial: Getting started with generics: https://go.dev/doc/tutorial/generics
[3]Generics: https://www.youtube.com/watch?v=35eIxI_n5ZM&t=1755s
[4]Tutorial: Getting started with fuzzing: https://go.dev/doc/tutorial/fuzz
关注煎鱼,获取业内第一手消息和知识 Go 1.18 版本新特性详解!

导语 | 本文推选自腾讯云开发者社区-【技思广益 · 腾讯技术人原创集】专栏。该专栏是腾讯云开发者社区为腾讯技术人与广泛开发者打造的分享交流窗口。栏目邀约腾讯技术人分享原创的技术积淀,与广泛开发者互启迪共成长。本文作者是腾讯后台开发工程师Johns。
本文主要探析Go 1.18版本新特性,希望本文能对此方面感兴趣的开发者们提供一些经验和帮助。
Go官方在今年315悄悄发布了Golang 1.18版本。Go 1.18是一个大型版本,其中包括新功能、性能改进以及我们对该语言的最大更改。最重要的3个特性如下:
泛型Generics: 引入了对使用参数化类型的泛型代码的新支持, 达到了算法可复用的目的。
模糊测试Fuzzing: 提供了一种自动化测试的选择, Go是第一个将模糊测试完全集成到其标准工具链中的主要语言。
Workspaces: 解决go mod遗留下来的本地多模块开发依赖问题。
其次还包括CPU性能提升20%,但是由于支持了泛型,对比1.17版本Go1.18编译时间可能会慢15-18%。

如何升级GO 1.18
注意: 我这边测试的是Linux环境,为了测试我这边特意安装保留之前的Go1.17版本,在此基础上再安装个Go1.18。
其次,升级go版本需要考虑开发IDE是否支持,目前我使用的Goland最新版只能支持到Go1.17,换成1.18会出现各种报错。
# 查看当前go版本和位置
go version && which go
# go version go1.17.7 linux/amd64
# /usr/bin/go
# 之前是直接使用的yum install go安装的
# 下载1.18版本
wget https://go.dev/dl/go1.18.3.linux-amd64.tar.gz
# 解压&移动
tar -C /tmp/ -xzf go1.18.3.linux-amd64.tar.gz
sudo mv /tmp/go /usr/local/go18
# 往文件写入命令
cat << EOF >/usr/local/go18/bin/go18
unset GOROOT
go env -w GOROOT="/usr/local/go18/"
/usr/local/go18/bin/go \\$@
EOF
# 查看文件里面的命令内容
cat /usr/local/go18/bin/go18
# unset GOROOT
# go env -w GOROOT="/usr/local/go18/"
# /usr/local/go18/bin/go $@
# 建立软连接
sudo ln -s /usr/local/go18/bin/go18 /usr/local/bin/go18
# 查看go版本
go18 version && go version
#go version go1.18.3 linux/amd64
#go version go1.17.7 linux/amd64
新特性之泛型
泛型是静态语言中的一种编程方式。这种编程方式可以让算法不再依赖于某个具体的数据类型,而是通过将数据类型进行参数化,以达到算法可复用的目的。
(一)使用场景
在Ian Lance Taylor的When To Use Generics中列出了泛型的典型使用场景,归结为三种主要情况:
使用内置的容器类型,如slices、maps和channels,堆、栈、队列、链表。
实现通用的数据结构,如linked list或tree。
编写一个函数,其实现对许多类型来说都是一样的,比如一个排序函数。
(二)实现原理
Go的泛型的提案Type Parameters Proposal提到了一些主流语言对于泛型3种不同的实现方式:
程序侧实现: 比如C语言,增加了程序员的负担,需要曲折的实现,但是不对增加语言的复杂性。
编译器实现: 比如C++编程语言,增加了编译器的负担,可能会产生很多冗余的代码,重复的代码还需要编译器斟酌删除,编译的文件可能非常大。Rust的泛型也属于这一类。
运行时实现: 比如Java,将一切装箱成Object进行类型擦除。虽然代码没啥冗余了,空间节省了,但是需要装箱拆箱操作,代码效率低。
GO语言的泛型则是基于编译器实现的,Go语言本身就是一门静态编译型语言,在运行时实现”泛型“对它来说比较困难,而它作为新起的一门语言又不想把这么复杂的工作交给程序员去维护;在具体的实现方式上,主要分为以下3种:
字典
在编译时生成一组实例化的字典,在实例话一个泛型函数的时候会使用字典进行蜡印(stencile)。
当为泛型函数生成代码的时候,会生成唯一的一块代码,并且会在参数列表中增加一个字典做参数,就像方法会把receiver当成一个参数传入。字典包含为类型参数实例化的类型信息。字典在编译时生成,存放在只读的data section中,当然字段可以当成第一个参数,或者最后一个参数,或者放入一个独占的寄存器。
当然这种方案还有依赖问题,比如字典递归的问题,更重要的是,它对性能可能有比较大的影响,比如一个实例化类型int,x=y可能通过寄存器复制就可以了,但是泛型必须通过memmove。
蜡印
这种方案和上面的字典方案正好相反。
比如下面一个泛型方法:
func f[T1, T2 any](x int, y T1) T2
...
如果有两个不同的类型实例化的调用:
var a float64 = f[int, float64](7, 8.0)
var b structf int = f[complex128, structf int](3, 1+1i)那么这个方案会生成两套代码:
func f1(x int, y int) float64
... identical bodies ...
func f2(x int, y complex128) structf int
... identical bodies ...
因为编译f时是不知道它的实例化类型的,只有在调用它时才知道它的实例化的类型,所以需要在调用时编译f。对于相同实例化类型的多个调用,同一个package下编译器可以识别出来是一样的,只生成一个代码就可以了,但是不同的package就不简单了,这些函数表标记为DUPOK,所以链接器会丢掉重复的函数实现。
这种策略需要更多的编译时间,因为需要编译泛型函数多次。因为对于同一个泛型函数,每种类型需要单独的一份编译的代码,如果类型非常多,编译的文件可能非常大,而且性能也比较差。
混合方案(GC Shape Stenciling)
混合前面的两种方案。
对于实例类型的shape相同的情况,只生成一份代码,对于shape类型相同的类型,使用字典区分类型的不同行为。
类型的shape是它对内存分配器/垃圾回收器呈现的方式,包括它的大小、所需的对齐方式、以及类型哪些部分包含指针。
接下来我们用一个例子,看看Go泛型的方案是具体实现的:
package main
import (
"fmt"
"time"
)
// PrtintString 简单的打印
func PrtintA(t string)
return fmt.Println(s)
// PrtintString 简单的打印
func PrtintString[T any](t T) string
return fmt.Sprintf("%v", t)
func main()
PrtintA("test")
PrtintString(0)
PrtintString(int32(0))
PrtintString(uint32(0))
PrtintString(uint64(0))
PrtintString("hello")
PrtintString(struct)
PrtintString(time.Now())
通过go tool compile -N -l -S main.go发现,go还是使用的第二种方案,虽然泛型的方法使用了dict来存放,通过类型shape来找到具体的调用方法:
...
0x0024 00036 (main.go:19) CALL "".PrtintA(SB)
0x0029 00041 (main.go:20) LEAQ ""..dict.PrtintString[int](SB), AX
0x0030 00048 (main.go:20) XORL BX, BX
0x0032 00050 (main.go:20) CALL "".PrtintString[go.shape.int_0](SB)
0x0037 00055 (main.go:21) LEAQ ""..dict.PrtintString[int32](SB), AX
0x003e 00062 (main.go:21) XORL BX, BX
0x0040 00064 (main.go:21) CALL "".PrtintString[go.shape.int32_0](SB)
0x0045 00069 (main.go:22) LEAQ ""..dict.PrtintString[uint32](SB), AX
0x004c 00076 (main.go:22) XORL BX, BX
0x004e 00078 (main.go:22) CALL "".PrtintString[go.shape.uint32_0](SB)
0x0053 00083 (main.go:23) LEAQ ""..dict.PrtintString[uint64](SB), AX
0x005a 00090 (main.go:23) XORL BX, BX
0x005c 00092 (main.go:23) NOP
0x0060 00096 (main.go:23) CALL "".PrtintString[go.shape.uint64_0](SB)
0x0065 00101 (main.go:24) LEAQ ""..dict.PrtintString[string](SB), AX
0x006c 00108 (main.go:24) LEAQ go.string."hello"(SB), BX
0x0073 00115 (main.go:24) MOVL $5, CX
0x0078 00120 (main.go:24) CALL "".PrtintString[go.shape.string_0](SB)
0x007d 00125 (main.go:25) LEAQ ""..dict.PrtintString[struct ](SB), AX
0x0084 00132 (main.go:25) CALL "".PrtintString[go.shape.struct _0](SB)
...本质上这是一种结合了第一种方案和第二种方案结合后的变种,但它又区别于我们介绍过的第三种方案。
实践使用
语法
在实践前,我们必须对泛型的语法进行了解,泛型的使用规范如下图所示:
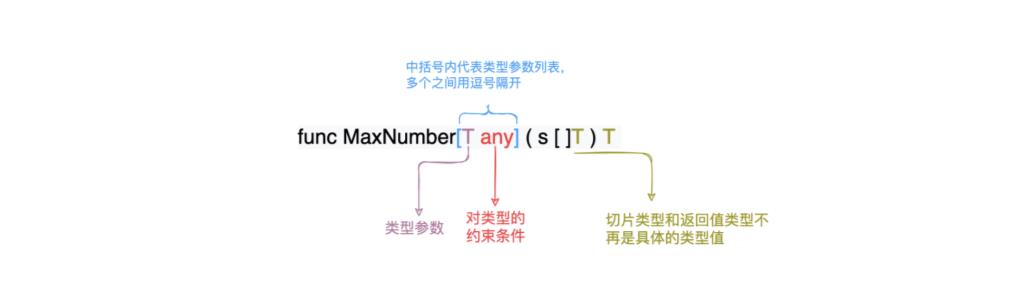
其中T表示类型参数,any其实是对T的一种约束,类型参数和约束定义完成后,我们就可以在我们的参数和返回值中使用了。
下面以实现一个返回数字类型的最大值的函数为例,讲一下泛型的基本使用步骤: 定义类型参数T,添加约束,实例化类型参数。

类型参数的约束
下面我们列出了Go官方支持的预定义的类型约束,其中~主要用来表示底层类型一致,例如type MyInt int 和int底层都是int类型,如果不使用~,那么类型实例化时就不能使用MyInt类型。
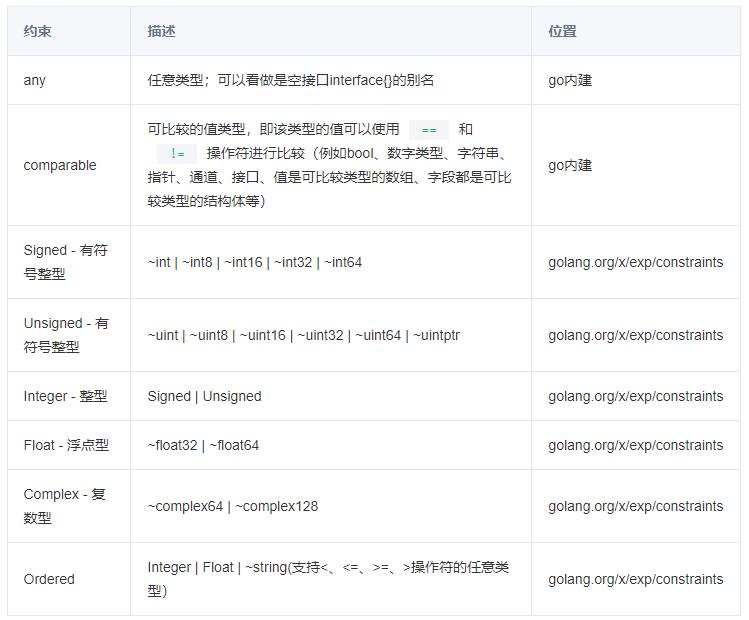
除了使用官方的内建约束,还可以使用自定义的接口的方式来约束。
// 自定义类型约束接口StringableFloat
type MyFloat interface
~float32 | ~float64 // 底层是float32或float64的类型就能满足该约束
func Max[T MyFloat](s []T) T
var zero T
if len(s) == 0
return zero
var max T
max = s[0]
for _, v := range s[1:]
max = v
if v > max
max = v
return max
更多实践
案例1: 实现一个简单的缓存特定的几类结构系统:
type Category struct
ID int32
Name string
Slug string
type Post struct
ID int32
Categories []Category
Title string
Text string
Slug string
type cacheable interface
Category | Post
FreshCache() error
func (c *cache[T]) Set(key string, value T)
c.data[key] = value
func (c *cache[T]) Get(key string) (v T)
if v, ok := c.data[key]; ok
return v
return
func New[T cacheable](cacheTicker *time.Ticker) *cache[T]
c := cache[T]
c.data = make(map[string]T)
return &c
package main
import (
"fmt"
)
func main()
// create a new category
category := Category
ID: 1,
Name: "Go Generics",
Slug: "go-generics",
// create cache for Category struct
cc := New[Category]()
// add category to cache
cc.Set(category.Slug, category)
fmt.Printf("cp get:%+v\\n", cc.Get(category.Slug))
// create a new post
post := Post
ID: 1,
Categories: []Category
ID: 1, Name: "Go Generics", Slug: "go-generics",
,
Title: "Generics in Golang structs",
Text: "Here go's the text",
Slug: "generics-in-golang-structs",
// create cache for blog.Post struct
cp := New[Post]()
// add post to cache
cp.Set(post.Slug, post)
fmt.Printf("cp get:%+v\\n", cp.Get(post.Slug))
案例2: 实现一个简单的队列:
// 这里类型约束使用了空接口,代表的意思是所有类型都可以用来实例化泛型类型 Queue[T] (关于接口在后半部分会详细介绍)
type Queue[T interface] struct
elements []T
// 将数据放入队列尾部
func (q *Queue[T]) Put(value T)
q.elements = append(q.elements, value)
// 从队列头部取出并从头部删除对应数据
func (q *Queue[T]) Pop() (T, bool)
var value T
if len(q.elements) == 0
return value, true
value = q.elements[0]
q.elements = q.elements[1:]
return value, len(q.elements) == 0
// 队列大小
func (q Queue[T]) Size() int
return len(q.elements)
func main()
var q1 Queue[int] // 可存放int类型数据的队列
q1.Put(1)
q1.Put(2)
q1.Put(3)
q1.Pop() // 1
q1.Pop() // 2
q1.Pop() // 3
var q2 Queue[string] // 可存放string类型数据的队列
q2.Put("A")
q2.Put("B")

新特性之Fuzzing
模糊测试(fuzz testing,fuzzing)是一种软件测试技术。其核心思想是將自动或半自动生成的随机数据输入到一个程序中,并监视程序异常,如崩溃,断言(assertion)失败,以发现可能的程序错误,比如内存泄漏、SQL 注入、拒绝服务和跨站点脚本攻击。
(一)使用场景
单元测试/变异测试 模糊测试可以用来弥补单元测试的缺陷,可以用来评估测试用例质量。
自动化测试 模糊测试是一种自动化测试技术,避免了开发人员编写测试用例的成本和开销。
(二)实现原理
Fuzzing引擎算法中,测试用例的生成方式主要有2种:
1)基于变异:根据已知数据样本通过变异的方法生成新的测试用例。
2)基于生成:根据已知的协议或接口规范进行建模,生成测试用例。
一般Fuzzing工具中,都会综合使用这两种生成方式。
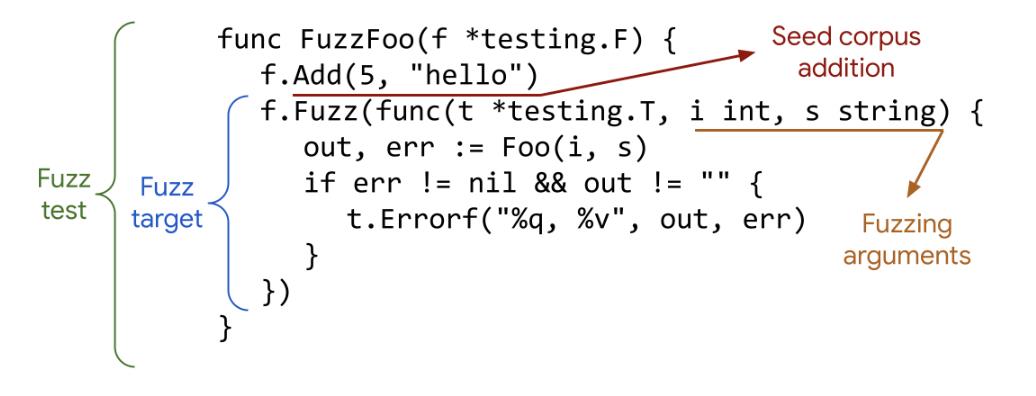
基于变异的算法核心要求是学习已有的数据模型,基于已有数据及对数据的分析,再生成随机数据做为测试用例。
如下图基于给定的一个输入5,“hello”作为随机的种子,Fuzz会自动生成测试用例,然后不停地测试。
(三)实践使用
语法规范
实践前我们先看一下模糊测试必须遵循的规则。
模糊测试必须是一个名为like的函数FuzzXxx,它只接受a*testing.F并且没有返回值。
模糊测试必须在*_test.go文件中才能运行。
模糊目标必须是一个方法调用,它(*testing.F).Fuzz接受a*testing.T作为第一个参数,然后是模糊参数。没有返回值。
每个模糊测试必须恰好有一个模糊目标。
所有种子语料库条目必须具有与模糊测试参数相同的类型,并且顺序相同。这适用于 (*testing.F).Add对模糊测试的testdata/fuzz目录中的任何语料库文件的调用。
模糊测试参数只能是以下类型:
string,[]byte
int, int8, int16,int32/ rune,int64
uint,uint8/byte,uint16,uint32,uint64
float32,float64
bool
启动说明
# go test -fuzz=FuzzTestName
$ go test -fuzz FuzzFoo
fuzz: elapsed: 0s, gathering baseline coverage: 0/192 completed
fuzz: elapsed: 0s, gathering baseline coverage: 192/192 completed, now fuzzing with 8 workers
fuzz: elapsed: 3s, execs: 325017 (108336/sec), new interesting: 11 (total: 202)
fuzz: elapsed: 6s, execs: 680218 (118402/sec), new interesting: 12 (total: 203)
fuzz: elapsed: 9s, execs: 1039901 (119895/sec), new interesting: 19 (total: 210)
fuzz: elapsed: 12s, execs: 1386684 (115594/sec), new interesting: 21 (total: 212)
PASS
ok foo 12.692s
# elapsed表示从开始模糊测试到现在经过了多少时间, execs表示执行的用例数其他可选参数:
-fuzztime: fuzz目标在退出前将执行的总时间或迭代次数,默认为无限期。
-fuzzminimizetime:在每次最小化尝试期间执行模糊目标的时间或迭代次数,默认为60秒。-fuzzminimizetime 0您可以通过设置模糊测试时完全禁用最小化。
-parallel: 一次运行的模糊测试进程的数量,默认值$GOMAXPROCS。目前,在fuzzing期间设置-cpu无效。
案例演示
下面使用官方的一个反转的字符串案例来演示一下具体使用,新增项目fuzz_demo,并在fuzz_demo里面新建文件reverse.go:
func Reverse(s string) string
b := []byte(s)
for i, j := 0, len(b)-1; i < len(b)/2; i, j = i+1, j-1
b[i], b[j] = b[j], b[i]
return string(b)
新建main.go,内容如下:
package main
import "fmt"
func main()
input := "The quick brown fox jumped over the lazy dog"
rev := Reverse(input)
doubleRev := Reverse(rev)
fmt.Printf("original: %q\\n", input)
fmt.Printf("reversed: %q\\n", rev)
fmt.Printf("reversed again: %q\\n", doubleRev)
目录结构如下:
fuzz_demo
.
├── main.go
├── reverse.go
└── reverse_test.go运行main,得到如下结果,看上去没啥问题。
go run ../fuzz_demo/
original: "The quick brown fox jumped over the lazy dog"
reversed: "god yzal eht revo depmuj xof nworb kciuq ehT"
reversed again: "The quick brown fox jumped over the lazy dog"下面为Reverse写一个单元测试reverse_test.go:
package main
import (
"testing"
)
func TestReverse(t *testing.T)
testcases := []struct
in, want string
"Hello, world", "dlrow ,olleH",
" ", " ",
"!12345", "54321!",
for _, tc := range testcases
rev := Reverse(tc.in)
if rev != tc.want
t.Errorf("Reverse: %q, want %q", rev, tc.want)
运行单测并没有发现有什么问题:
$ go test
PASS
ok example/fuzz 0.013s但是Reverse方法真的没有问题吗? 我们在reverse_test.go中新增一个模糊测试:
func FuzzReverse(f *testing.F)
testcases := []string"Hello, world", " ", "!12345"
for _, tc := range testcases
f.Add(tc) // Use f.Add to provide a seed corpus
f.Fuzz(func(t *testing.T, orig string)
rev := Reverse(orig)
doubleRev := Reverse(rev)
if orig != doubleRev
t.Errorf("Before: %q, after: %q", orig, doubleRev)
if utf8.ValidString(orig) && !utf8.ValidString(rev)
t.Errorf("Reverse produced invalid UTF-8 string %q", rev)
)
运行FuzzReverse模糊测试,查看是否有任何随机生成的字符串输入会导致失败。这是使用go test新标志执行的-fuzz:
[root]# go18 test -fuzz=Fuzz
fuzz: elapsed: 0s, gathering baseline coverage: 0/3 completed
fuzz: elapsed: 0s, gathering baseline coverage: 3/3 completed, now fuzzing with 8 workers
fuzz: elapsed: 0s, execs: 526 (7126/sec), new interesting: 3 (total: 6)
--- FAIL: FuzzReverse (0.07s)
--- FAIL: FuzzReverse (0.00s)
reverse_test.go:36: Reverse produced invalid UTF-8 string "\\xbb\\xac\\xe7"
Failing input written to testdata/fuzz/FuzzReverse/a9d86b0e4e93269adeeaa8df903415915f5979f1c2d2b8bb02311f0a72e6c8fb
To re-run:
go test -run=FuzzReverse/a9d86b0e4e93269adeeaa8df903415915f5979f1c2d2b8bb02311f0a72e6c8fb
FAIL
exit status 1
FAIL generic_test 0.082s# 我们查看一下用例的内容, 看一下具体时哪个用例有问题
[root@VM-74-225-centos ~/go/src/generic_test]# cat testdata/fuzz/FuzzReverse/a9d86b0e4e93269adeeaa8df903415915f5979f1c2d2b8bb02311f0a72e6c8fb
go test fuzz v1
string("笻")问题诊断
我们看到, 导致我们异常的是“笻” ,整个fuzz种子语料库使用字符串,其中每个字符都是一个字节。但是,“笻”等字符可能需要几个字节。因此,逐字节反转字符串将使多字节字符无效, 这种情况在计算字符串长度的是否也会遇到。因此我们需要将字节变成rune后再进行反转,修改Reverse方法的实现:
func Reverse(s string) string
r := []rune(s)
for i, j := 0, len(r)-1; i < len(r)/2; i, j = i+1, j-1
r[i], r[j] = r[j], r[i]
return string(r)
修改后继续执行测试:
[root@VM-74-225-centos ~/go/src/generic_test]# go18 test -fuzz=Fuzz
fuzz: elapsed: 0s, gathering baseline coverage: 0/7 completed
fuzz: minimizing 38-byte failing input file
fuzz: elapsed: 0s, gathering baseline coverage: 4/7 completed
--- FAIL: FuzzReverse (0.03s)
--- FAIL: FuzzReverse (0.00s)
reverse_test.go:33: Before: "\\xd8", after: "�"
Failing input written to testdata/fuzz/FuzzReverse/5f644fdcef1c73a8103274829865beba68d8087129b886a825d1bba632f4358e
To re-run:
go test -run=FuzzReverse/5f644fdcef1c73a8103274829865beba68d8087129b886a825d1bba632f4358e
FAIL
exit status 1
FAIL generic_test 0.029s仔细查看反转的字符串以发现错误。在Go中,字符串是字节的只读切片,并且可以包含无效的UTF-8字节。原始字符串是一个带有一个字节的字节切片,'\\x91'.当输入字符串设置为时[]rune,Go将字节切片编码为UTF-8,并将字节替换为UTF-8 字符�。当我们将替换的UTF-8字符与输入字节切片进行比较时,它们显然不相等。
于是需要继续调整实现,避免非法的unicode输入:
func Reverse(s string) (string, error)
if !utf8.ValidString(s)
return s, errors.New("input is not valid UTF-8")
r := []rune(s)
for i, j := 0, len(r)-1; i < len(r)/2; i, j = i+1, j-1
r[i], r[j] = r[j], r[i]
return string(r), nil
调整单元测试和Fuzz测试实现:
package main
import (
"testing"
"unicode/utf8"
)
func TestReverse(t *testing.T)
testcases := []struct
in, want string
"Hello, world", "dlrow ,olleH",
" ", " ",
"!12345", "54321!",
for _, tc := range testcases
rev, _ := Reverse(tc.in)
if rev != tc.want
t.Errorf("Reverse: %q, want %q", rev, tc.want)
func FuzzReverse(f *testing.F)
testcases := []string"Hello, world", " ", "!12345"
for _, tc := range testcases
f.Add(tc) // Use f.Add to provide a seed corpus
f.Fuzz(func(t *testing.T, orig string)
rev, err1 := Reverse(orig)
if err1 != nil
return
doubleRev, err2 := Reverse(rev)
if err2 != nil
return
if orig != doubleRev
t.Errorf("Before: %q, after: %q", orig, doubleRev)
if utf8.ValidString(orig) && !utf8.ValidString(rev)
t.Errorf("Reverse produced invalid UTF-8 string %q", rev)
)
之后执行测试:
[root]# go18 test -fuzz=Fuzz -fuzztime 10s
fuzz: elapsed: 0s, gathering baseline coverage: 0/40 completed
fuzz: elapsed: 0s, gathering baseline coverage: 40/40 completed, now fuzzing with 8 workers
fuzz: elapsed: 3s, execs: 424692 (141504/sec), new interesting: 1 (total: 41)
fuzz: elapsed: 6s, execs: 824495 (133183/sec), new interesting: 1 (total: 41)
fuzz: elapsed: 9s, execs: 1227987 (134614/sec), new interesting: 1 (total: 41)
fuzz: elapsed: 10s, execs: 1364282 (122256/sec), new interesting: 1 (total: 41)
PASS
ok generic_test 10.122s自此我们就演示完了如何使用Fuzz实现自动化测试从而发现程序中隐藏的bug。

新特性之WorkSpaces
(一)背景
在go1.12以前,我们知道golang的依赖包管理仅仅只是可用而已。go1.12之后,go mod才真正解决了依赖包管理的核心问题。但是它真的完全没有问题了吗?
回忆一下, 在本地进行多模块开发的时候,我们为了解决一些本地依赖,或是定制化代码。会在go.mod文件中使用replace做替换。
如下代码:
replace golang.org/x/net => /Users/guirongguo/go/awesomeProject问题就在这里:
本地路径:所设定的replace本质上转换的是本地的路径,也就是每个人都不一样。
仓库依赖:文件修改是会上传到Git仓库的,不小心传上去了,影响到其他开发同学,又或是每次上传都得重新改回去。
其次我们可能会在本地同时开发多个库(项目库、工具库、第三方库)并且之间还有依赖关系, 这个时候你会发现, 如果不提交代码, 那么下面代码就跑不起来。
package main
import (
"github.com/guirongguo/utils"
)
func main()
utils.PrintFish()
执行go mod tidy你会发现程序跑不起来,哪怕你本地的库其实已经开发好了。
在社区的多轮反馈下,Michael Matloob提出了提案《Proposal: Multi-Module Workspaces in cmd/go》进行了大量的讨论和实施,在 Go1.18正式落地。
(二)WorkSpaces模式
多Module WorkSpaces模式,其本质上还是为了解决本地开发的诉求。由于go.mod文件是与项目强关联的,基本都会上传到Git仓库中,很难在go.mod上操作。所以就需要额外搞一个go.work出来,纯放在本地使用,方便快捷。
go.work文件的生成也很简单,命令行使用说明如下:
Usage:
go work <command> [arguments]
The commands are:
edit edit go.work from tools or scripts
init initialize workspace file
sync sync workspace build list to modules
use add modules to workspace file
Use "go help work <command>" for more information about a command.当前我们的项目目录如下:
awesomeProject
├── mod
│ ├── go.mod // 子模块
│ └── main.go
└── tools
├── string_utils.go
└── go.mod // 子模块进入项目目录,我们使用go work init ./mod ./tools来初始化一个新的工作区,同时加入需要的的子模块。
cd awesomeProject
go work init ./mod ./tools
tree
awesomeProject
.
├── mod
│ ├── go.mod // 子模块
│ └── main.go
├── go.work // 工作区
└── tools
├── string_utils.go
└── go.mod // 子模块生成的go.work文件内容:
go 1.18
use (
./mod
./tools
)GO1.18在进行依赖解析时,会优先解析go.work的内容,然后再解析go mod,go.work只会留在本地,不会做远程提交。
go.work 文件内共支持三个指令:
go:声明go版本号,主要用于后续新语义的版本控制。go run -workfile=off main.go。
use:声明应用所依赖模块的具体文件路径,路径可以是绝对路径或相对路径,可以在应用命目录外均可。
replace:声明替换某个模块依赖的导入路径,优先级高级 go.mod 中的 replace 指令。若想要禁用工作区模式,可以通过-workfile=off指令来指定。例如:
go run -workfile=off main.go
总结
本文详细介绍了GO1.18发布的3个核心特性: 泛型,Fuzzing测试, Workspaces。
其中泛型解决了算法复用的问题;Fuzzing完善了测试方面的支持,提供了一个自动化测试的方案的选择;Workspaces解决了go mod遗留下来的本地多模块开发依赖问题。
除了这3个主要特性,其实还有很多细节这里没有展开介绍,例如对CPU性能的优化,核心库的细微调整,感兴趣的同学可以阅读一下官方的发布说明:《Go 1.18 Release Notes》
参考资料:
1.《Go 1.18 is released!》
2.《Tutorial: Getting started with generics》
3.《深入浅出Go泛型之泛型使用三步曲》
4.《Tutorial: Getting started with fuzzing》
5.《Go Fuzzing》
6.《Go1.18 新特性:多Module工作区模式》
7.《Go 1.18 Release Notes》
作者简介

Johns
腾讯云开发者社区【技思广益·腾讯技术人原创集】作者
腾讯后台开发工程师,喜欢读书、编程、看电影,比较喜欢研究有意思的技术。
推荐阅读

👇点击「阅读原文」,注册成为社区创作者,认识大咖,打造你的技术影响力!
以上是关于分享 2 个 Go1.18 新特性的官方教程的主要内容,如果未能解决你的问题,请参考以下文章