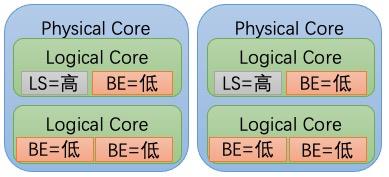
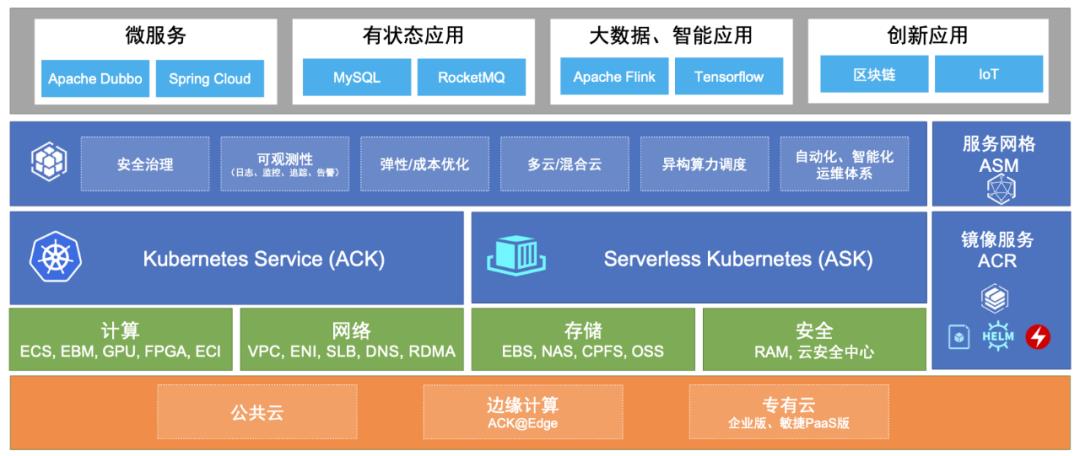
CPU Burst Kubernetes 为容器资源管理提供了 Limit(约束)的语义描述,对于 CPU 这类分时复用型的资源,当容器指定了 CPU Limit,操作系统会按照一定的时间周期约束资源使用。例如对于 CPU Limit = 2 的容器,操作系统内核会限制容器在每 100 ms 周期内最多使用 200 ms 的 CPU 时间片。
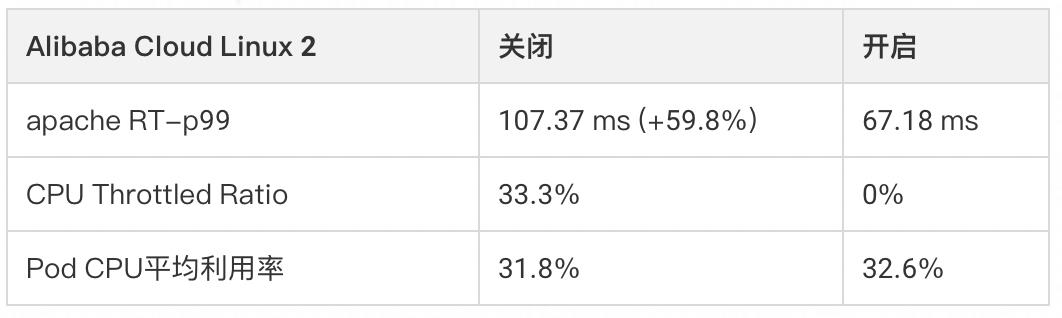
下图展示了一台 4 核节点、某 CPU Limit = 2 的 Web 服务类容器,在收到请求(req)后各线程(Thread)的 CPU 资源分配情况。可以看出,即使容器在最近 1s 内整体的 CPU 利用率较低,受 CPU Throttled 机制的影响,Thread 2 仍需要等待下一个周期才能继续将 req 2 处理完成,进而导致请求的响应时延(RT)变大,这通常就是容器 RT 长尾现象严重的原因之一。
CPU Burst 机制可以有效解决延迟敏感性应用的 RT 长尾问题,允许容器在空闲时积累一些 CPU 时间片,用于满足突发时的资源需求,提升容器性能表现,目前阿里云容器服务 ACK 已经完成了对 CPU Burst 机制的全面支持。对于尚未支持 CPU Burst 策略的内核版本,ACK 也会通过类似的原理,监测容器 CPU Throttle 状态,并动态调节容器的 CPU Limit,实现与内核 CPU Burst 策略类似的效果。 CPU 拓扑感知调度 随着宿主机硬件性能的提升,单节点的容器部署密度进一步提升,进程间的 CPU 争用,跨 NUMA 访存等问题也逐渐加剧,严重影响了应用性能表现。在多核节点下,进程在运行过程中经常会被迁移到其不同的核心,考虑到有些应用的性能对 CPU 上下文切换比较敏感,kubelet 提供了 static 策略,允许 Guarantee 类型 Pod 独占 CPU 核心。但该策略尚有以下不足之处:
策略对节点内所有 Pod 全部生效,而 CPU 绑核并不是”银弹“,需要支持 Pod 粒度的精细化策略。
中心调度并不感知节点实际的 CPU 分配情况,无法在集群范围内选择到最优组合。
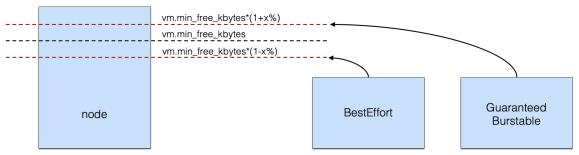
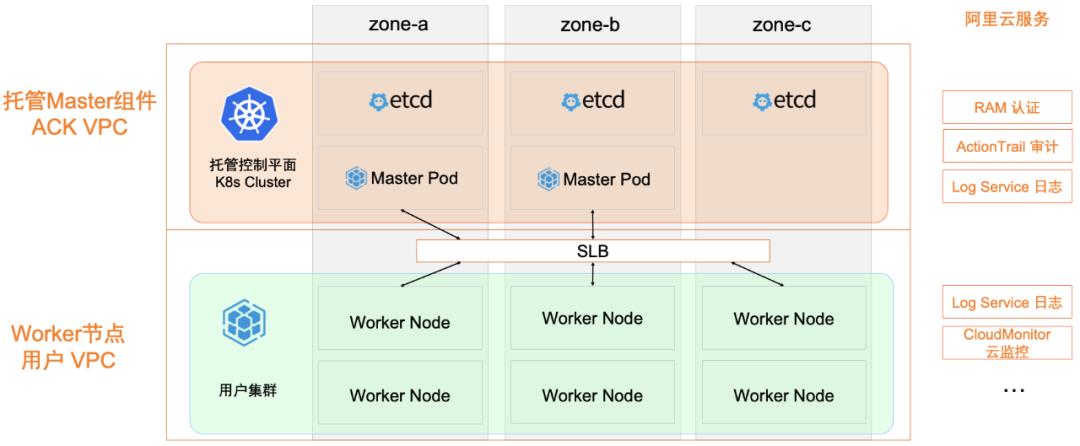
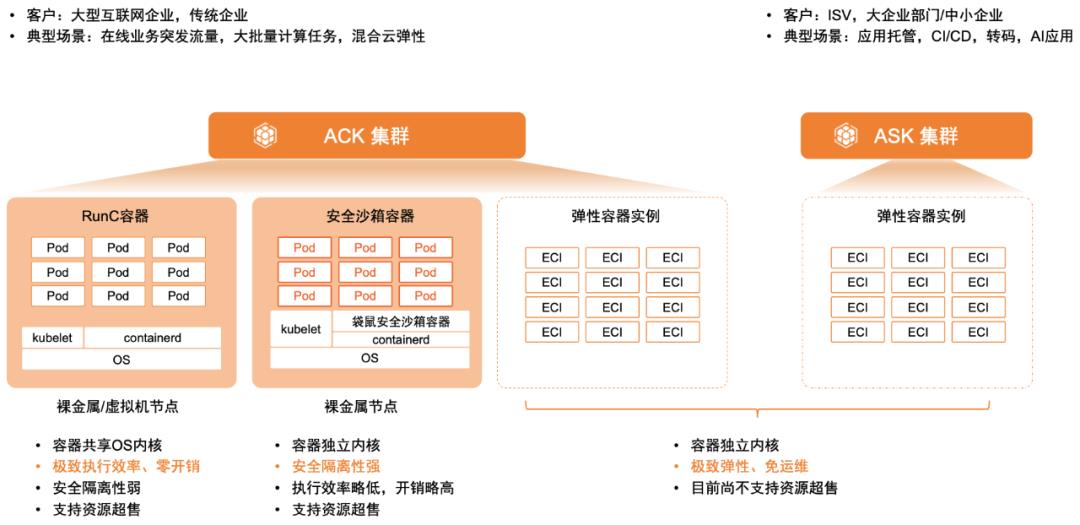
阿里云容器服务 ACK 基于 Scheduling framework 实现了拓扑感知调度以及灵活的绑核策略,针对 CPU 敏感型的工作负载可以提供更好的性能。ACK 拓扑感知调度可以适配所有 QoS 类型,并支持在 Pod 维度按需开启,同时可以在全集群范围内选择节点和 CPU 拓扑的最优组合。 弹性资源限制(reclaimed-resource) 如资源模型中的描述,节点 reclaimed-resource 的资源总量会跟随高优先级容器实际的资源用量动态变化,在节点侧,为了保障 LS 容器的运行质量,BE 容器实际可用 CPU 数量同样受 LS 容器负载的影响。 如上图所示,当 LS 容器资源用量上涨时,受负载水位红线的限制,BE 容器可用的 CPU 数量相应减少,在系统层面会体现在容器 cgroup 分组的 CPU 绑定范围,以及 CPU 时间片的分配限制。 内核Group Identity
Alibaba Cloud Linux 2 从内核版本 kernel-4.19.91-24.al7 开始支持 Group Identity 功能,通过为容器设置不同的身份标识,可以区分容器中进程任务的优先级。内核在调度不同优先级的任务时有以下特点:
高优先级任务的唤醒延迟最小化。
低优先级任务不对高优先级任务造成性能影响。主要体现在:
低优先级任务的唤醒不会对高优先级任务造成性能影响。
低优先级任务不会通过 SMT 调度器共享硬件 unit(超线程场景)而对高优先级任务造成性能影响。
Group Identity 功能可以对每一个容器设置身份标识,以区分容器中的任务优先级。Group Identity 核心是双红黑树设计,在 CFS(Completely Fair Scheduler)调度队列的单红黑树基础上,新增了一颗低优先级的红黑树,用于存放低优先级任务。
系统内核在调度包含具有身份标识的任务时,会根据不同的优先级做相应处理。具体说明如下表:
更多关于内核 Group Identity 能力的详细描述,可参见官网文档:https://help.aliyun.com/document_detail/338407.html LLC 及 MBA 隔离 在神龙裸金属节点环境,容器可用的 CPU 缓存(Last Level Cache,LLC)及 内存带宽(Memory Bandwidth Allocation,MBA)可以被动态调整。通过对 BE 容器进程的细粒度资源限制,可以进一步避免对 LS 容器产生性能干扰。 2 内存资源质量
全局最低水位线分级
在 Linux 内核中,全局内存回收对系统性能影响很大。特别是时延敏感型业务(LS)和资源消耗型(BE)任务共同部署时,资源消耗型任务时常会瞬间申请大量的内存,使得系统的空闲内存触及全局最低水位线(global wmark_min),引发系统所有任务进入直接内存回收的慢速路径,进而导致延敏感型业务的性能抖动。在此场景下,无论是全局 kswapd 后台回收还是 memcg 后台回收,都将无法处理该问题。 基于上述场景下的问题,Alibaba Cloud Linux 2 新增了 memcg 全局最低水位线分级功能。在 global wmark_min 的基础上,将 BE 的 global wmark_min 上移,使其提前进入直接内存回收。将 LS 的 global wmark_min 下移,使其尽量避免直接内存回收。这样当 BE 任务瞬间申请大量内存的时候,会通过上移的global wmark_min 将其短时间抑制,避免 LS 发生直接内存回收。等待全局 kswapd 回收一定量的内存后,再解除 BE 任务的短时间抑制。
CPU 资源满足度 前文介绍了多种针对低优先级离线容器的 CPU 资源压制能力,可以有效保障 LS 类型业务的资源使用。然而在 CPU 被持续压制的情况下,BE 任务自身的性能也会受到影响,将其驱逐重调度到其他空闲节点反而可以使任务更快完成。此外,若 BE 任务在受压制时持有了内核全局锁这类资源,CPU 持续无法满足可能会导致优先级反转,影响 LS 应用的性能。 因此,差异化 SLO 套件提供了基于 CPU 资源满足度的驱逐能力,当 BE 类型容器的资源满足度持续低于一定水位时,使用 reclaimed 资源的容器会按从低到高的优先级被依次驱逐。 内存阈值水位
我们可以将前端应用、业务逻辑容器化,部署在 K8s 集群上,并根据应用负载配置 HPA 水平伸缩。 在后端数据层,我们可以利用 PolarDB 这样的云原生数据库。PolarDB 采用存储和计算分离架构,支持水平扩展。同等规格下是 MySQL 性能的7倍,并且相较于 MySQL 能够节省一半成本。 此外是系统化的高可用设计:
利用 AZ 级别的反亲和性,我们可以将应用的副本实例部署在不同 AZ。
通过 SLB 负载均衡接入在不同 AZ 的应用入口。
PolarDB 数据库默认提供了跨 AZ 高可用。
这样我们可以保障整个系统具备 AZ 级别的可用性,可以容忍一个 AZ 的失效。 此外,阿里云的高可用服务 AHAS,提供了架构感知的能力,可以对系统的拓扑结构进行可视化。而且它提供了应用巡检能力,帮助我们定位可用性问题。比如应用副本数是否满足可用性需求,RDS 数据库实例是否开启了多可用区容灾等等。 多维度可观测性
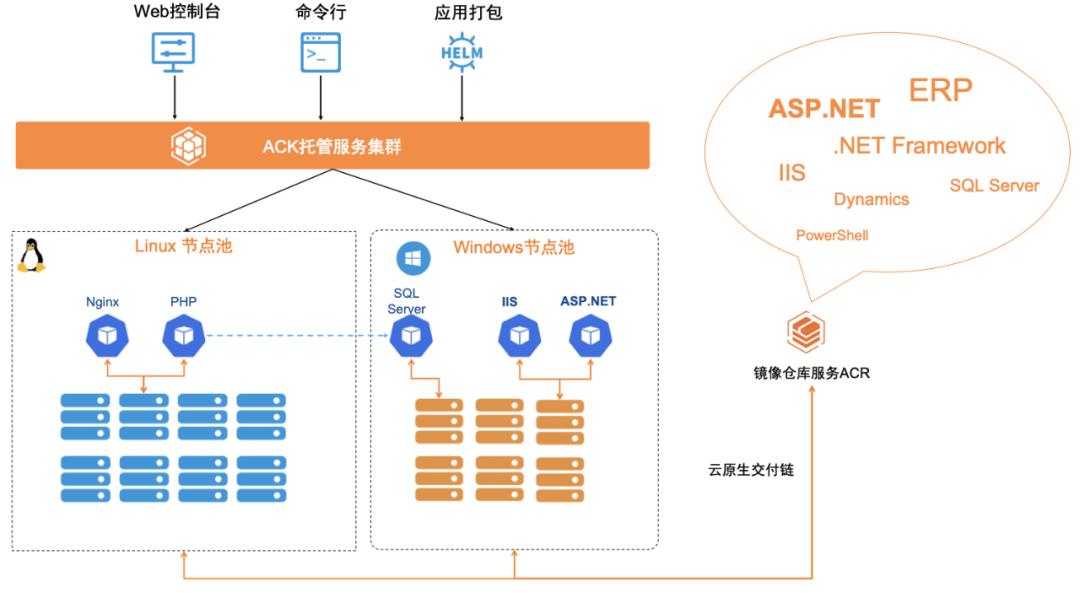
我们来谈一下对 Windows 容器的支持。在现今企业中,Windows 操作系统依然占据半壁江山,其市场份额达 60% 之多。企业还有有大量的 Windows 应用,比如 ERP,CRM,ASP.Net 网站等。利用 Windows 容器和 Kubernetes,可以让 .Net 应用在代码不重写的情况下实现容器化交付,充分利用云上的弹性、敏捷等能力,实现业务应用的快速迭代和伸缩。 ACK 支持 Windows 2019,在 K8s 容器集群中: 1)为 Linux 和 Windows 应用提供了一致的用户体验和统一的能力。
支持 CPU、内存、存储卷等资源调度和编排
支持无状态/有状态等多种不同应用负载
2)支持 Linux 和 Windows 应用在集群中的混合部署和互连互通,比如我们可以让运行在 Linux 节点的 PHP 应用访问运行在 Windows 节点的 SQL Server 数据库。 我们已经在支持了聚石塔电商平台和 supET 工业互联网平台支持了很多 ISV 来对 Windows 应用进行云原生化改造、升级。 阿里云容器服务的演进方向 下面我们快速介绍一下阿里云在云原生方面的产品市场策略。我们可以总结为三条: 新基石:容器技术是用户使用云资源的新界面,云原生技术是释放云价值的最短路径