最佳实践 | 什么是好的日志记录实践?
Posted Flink
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了最佳实践 | 什么是好的日志记录实践?相关的知识,希望对你有一定的参考价值。

作为软件开发人员,我们在使用某些库或框架时都遇到过那些烦人的、不太有用的错误消息:“无法解析配置文件”、“缺少此操作的权限”等。好的,好的,所以显然出了点问题;但究竟是什么?什么配置文件?哪些权限?你应该怎么做?缺少此类信息的错误消息很快就会产生挫败感和无助感。
那么什么是好的错误信息呢?对我来说,它归结为应通过错误消息传达的三条信息:
背景:是什么导致了错误?失败时代码试图做什么?
错误本身:到底是什么失败了?
缓解:为了克服错误需要做什么?
让我们深入探讨一下这些个别方面。在我们开始之前,让我澄清一下这是关于由库或框架代码创建的错误消息,例如以异常消息的形式,或以写入某个日志文件的消息的形式。这意味着这些错误消息的消费者通常是其他软件开发人员(在应用程序开发过程中遇到由 3rd 方依赖项引发的错误),或者是操作人员(在运行应用程序时遇到错误)。
这与面向用户的错误消息形成对比,应该应用其他指导和规则(特别是关于安全问题)。例如,您通常不应在面向用户的消息中公开任何实现细节,而对于此处讨论的错误消息类型来说,这并不是什么大问题——或者相反,它甚至可能是可取的。
语境
在某种程度上,一条错误消息讲述了一个故事。和每一个好故事一样,你需要建立一些关于它的一般背景的背景。对于错误消息,这应该告诉接收者有问题的代码在失败时试图做什么。鉴于此,上面的第一个示例“Couldn\'t parse config file”在某种程度上解决了这个方面(而且只有这个方面),但可能还不够。例如,知道文件的确切名称将非常有用:
无法解析配置文件:/etc/sample-config.properties"
使用Debezium的一个示例,我在日常工作中正在开发的开源变更数据捕获平台,第二条消息可以这样读,并带有一些关于发生了什么的上下文:
回到与处理某些输入或配置文件相关的错误消息,打印绝对路径可能是个好主意。如果文件系统资源以相对路径的形式提供,这有助于识别当前工作目录周围的错误假设,或者任何其他用作解析相对路径的根目录。另一方面,特别是在多租户或 SaaS 场景的情况下,您可能会将文件系统布局视为机密的实现细节,您可能更愿意不将其透露给您运行的未知代码。什么是最好的取决于你的具体情况。
如果某些框架支持不同类型的文件,则有问题的文件的特定类型也应该是消息的一部分:“Couldn\'t parse entity mapping file... ”。如果错误与文件内容的特定部分有关,则显示行号和/或行本身是个好主意。
就如何传达错误的上下文而言,它可以是消息本身的一部分,如上所示。许多日志框架还支持映射诊断上下文(MDC) 的概念,该映射用于将任意键/值对传播到日志消息中。因此,如果您的消息要显示在日志中,那么为 MDC 设置上下文信息会非常有用。例如,在 Debezium 中,这用于传播受影响连接器的名称,允许 Kafka Connect 用户区分源自部署到同一 Connect 集群的不同连接器的日志消息。
| 就通过日志消息传播上下文信息而言(与 CLI 工具打印的错误消息相反), 结构化日志记录(通常以 JSON 的形式)简化了任何下游处理。通过将上下文信息放入结构化日志条目的单独属性中,消费者可以轻松过滤消息,根据其内容仅摄取特定的消息子集等。 |
在异常的情况下,导致根本原因的异常链也是一个重要的上下文信息。因此,我建议始终记录整个异常链,而不是捕获异常并仅记录一些替代消息。
错误本身
然后进入下一部分,描述实际错误本身。这就是您应该以简洁的方式描述确切发生的事情的地方。继续上面的例子,第一条消息,包括上下文和错误描述可以这样写:
无法解析配置文件:/etc/sample-config.properties;给定快照模式“nevr”无效
对于第二个:
未能创建数据的初始快照;数据库用户 \'snapper\' 缺少所需的权限
除此之外,这里没有太多可说的;努力提高效率:使消息尽可能长,尽可能短。一个想法可能是使用不同的消息变体来处理相同类型的错误,一个更短的错误,一个更长的错误。使用哪一个可以通过日志级别或某种“详细”标志来控制。Java 开发人员可能会发现 Cédric Champeau 的jdoctor库对实现这一点很有用。就个人而言,我还没有使用过这种方法,但对于特定情况可能值得付出努力。
减轻
在确定了失败的背景以及究竟出了什么问题之后,最后——通常也是最有趣的——部分是对用户如何克服错误的描述。他们需要采取什么行动来避免它?这可以像在配置文件示例中告诉用户约束和/或有效值一样简单(即类似于测试失败消息,显示预期值和实际值):
无法解析配置文件:/etc/sample-config.properties;给定快照模式 \'nevr\' 无效(必须是 \'initial\'、\'always\'、\'never\' 之一)
如果出现权限问题,您可以澄清需要哪些权限:
无法拍摄数据库快照:数据库用户“snapper”缺少所需的权限“SELECT”、“REPLICATION”
或者,如果需要更长的缓解策略,您可以在参考文档中指向一个(稳定的!)URL,该 URL 提供了所需的信息:
如果需要进行一些配置更改(例如数据库或 IAM 权限),如果您以“可执行”形式共享该信息,您的用户会更加喜欢您,例如作为他们可以简单复制的 GRANT 语句或特定于供应商的 CLI 调用比如aws iam attach-role-policy --policy-arn arn:aws:iam::aws:policy/SomePolicy --role-name SomeRole。
说到错误消息中引用的外部资源,最好将唯一的错误代码作为消息的一部分(例如 Oracle 的 ORA 代码,或WildFly 及其组件产生的错误消息)。然后使用您最喜欢的搜索引擎可以轻松找到相应的资源(由您自己提供或外部提供,例如在 StackOverflow 上的答案中)。将对您自己的规范资源的引用添加到错误消息本身的奖励积分:
(这是一个虚构的例子,我们目前没有在 Debezium 中使用这种方法;但我可能应该考虑购买 dbz.codes 域
深度 | API 设计最佳实践的思考
阿里妹导读:API 是模块或者子系统之间交互的接口定义。好的系统架构离不开好的 API 设计,而一个设计不够完善的 API 则注定会导致系统的后续发展和维护非常困难。
接下来,阿里巴巴研究员谷朴将给出建议,什么样的 API 设计是好的设计?好的设计该如何做?

作者简介:张瓅玶 (谷朴),阿里巴巴研究员,负责阿里云容器平台集群管理团队。本科和博士毕业于清华大学。
前言
API 设计面临的挑战千差万别,很难有处处适用的准则,所以在讨论原则和最佳实践时,无论这些原则和最佳实践是什么,一定有适应的场景和不适应的场景。因此我们在下文中不仅提出一些建议,也尽量去分析这些建议在什么场景下适用,这样我们也可以有针对性地采取例外的策略。
为什么去讨论这些问题? API 是软件系统的核心,而软件系统的复杂度 Complexity 是大规模软件系统能否成功最重要的因素。但复杂度 Complexity 并非某一个单独的问题能完全败坏的,而是在系统设计尤其是API设计层面很多很多小的设计考量一点点叠加起来的(John Ousterhout老爷子说的Complexity is incremental【8】)。
成功的系统不是有一些特别闪光的地方,而是设计时点点滴滴的努力积累起来的。
范围
本文偏重于一般性的API设计,并更适用于远程调用(RPC或者HTTP/RESTful的API),但是这里没有特别讨论RESTful API特有的一些问题。
另外,本文在讨论时,假定了客户端直接和远程服务端的API交互。在阿里,由于多种原因,通过客户端的 SDK 来间接访问远程服务的情况更多一些。这里并不讨论 SDK 带来的特殊问题,但是将 SDK 提供的方法看作远程 API 的代理,这里的讨论仍然适用。
API 设计准则:什么是好的 API
在这一部分,我们试图总结一些好的 API 应该拥有的特性,或者说是设计的原则。这里我们试图总结更加基础性的原则。所谓基础性的原则,是那些如果我们很好地遵守了就可以让 API 在之后演进的过程中避免多数设计问题的原则。
提供清晰的思维模型 provides a good mental model
为什么这一点重要?因为 API 的设计本身最关键的难题并不是让客户端与服务端软件之间如何交互,而是设计者、维护者、API使用者这几个程序员群体之间在 API 生命周期内的互动。一个 API 如何被使用,以及API本身如何被维护,是依赖于维护者和使用者能够对该 API 有清晰的、一致的认识。这非常依赖于设计者提供了一个清晰易于理解的模型。这种状况实际上是不容易达到的。
就像下图所示,设计者心中有一个模型,而使用者看到和理解的模型可能是另一个模式,这个模式如果比较复杂的话,使用者使用的方式又可能与自己理解的不完全一致。 对于维护者来说,问题是类似的。
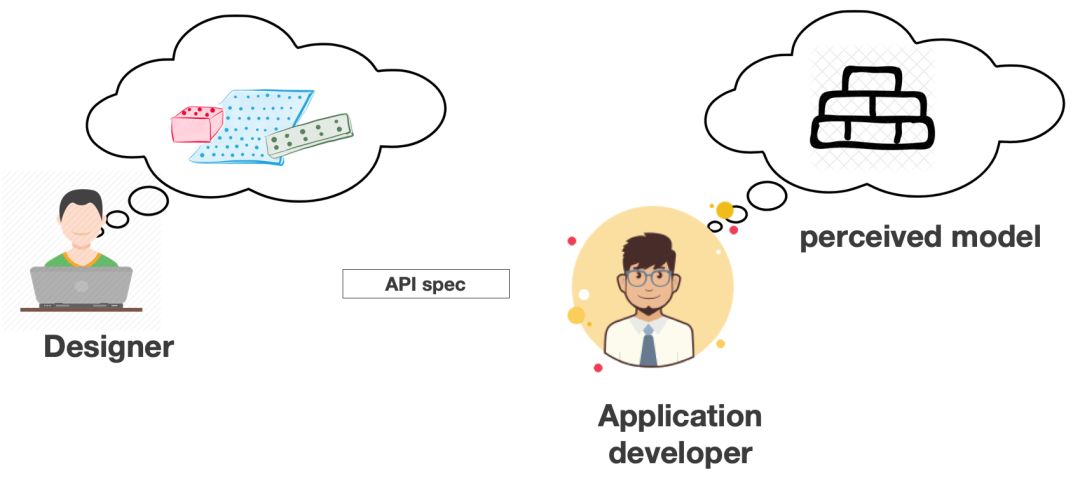
而好的 API 让维护者和使用者能够很容易理解到设计时要传达的模型。带来理解、调试、测试、代码扩展和系统维护性的提升 。
图片来源:
https://medium.com/@copyconstruct/effective-mental-models-for-code-and-systems-7c55918f1b3e
好的例子:很多基础设施领域的 API 都提供了非常好的正面的设计典型,如后面会重点提到的 Posix File API,就提供了非常清晰明了的 mental model。
不好的例子:String 是软件中常见的类型,但是在一些 String 类库的实现中,我们会看到设计者为了某些方便,提供了以数组方式访问字符串的 API,这类 API 容易让使用者形成字符串 = array of chars 的模型印象,而这样的印象在一些特殊场景实际是不成立的(例如 Unicode 编码等形态)。
简单 is simple
“Make things as simple as possible, but no simpler.” 在实际的系统中,尤其是考虑到系统随着需求的增加不断地演化,我们绝大多数情况下见到的问题都是过于复杂的设计,在 API 中引入了过多的实现细节(见下一条),同时也有不少的例子是Oversimplification 引起的,一些不该被合并的改变合并了,导致设计很不合理。
过于简单化的例子:过去曾经见过一个系统,将一个用户的资源账户模型的 account balance 和 transactions 都简化为用 transactions 一个模型来表达,逻辑在于 account balance 可以由历史的 transactions 累计得到。但是这样的过于简化的模型设计带来了很多的问题,尤其在引入分期付款、预约交易等概念之后,暴露了很多复杂的逻辑给一些只需要获取简单信息的客户端(如计算这个用户是否还有足够的余额交易变得和很多业务逻辑耦合),属于典型的模型过度简化带来的设计复杂度上升的案例。
容许多个实现 allows multiple implementations
这个原则看上去更具体,也是我非常喜欢的一个原则。Sanjay Ghemawat 常常提到该原则。一般来说,在讨论 API 设计时常常被提到的原则是解耦性原则或者说松耦合原则。然而相比于松耦合原则,这个原则更加有可核实性:如果一个 API 自身可以有多个完全不同的实现,一般来说这个API已经有了足够好的抽象,那么一般也不会出现和外部系统耦合过紧的问题。因此这个原则更本质一些。
举个例子,比如我们已经有一个简单的 API
QueryOrderResponse queryOrder(string orderQuery)但是有场景需求希望总是读取到最新更新数据,不接受缓存,于是工程师考虑。
QueryOrderResponse queryOrder(string orderQuery, boolean useCache)
增加一个字段 useCache 来判断如何处理这样的请求。
这样的改法看上去合理,但实际上泄漏了后端实现的细节(后端采用了缓存),后续如果采用一个新的不带缓存的后端存储实现,再支持这个 useCache 的字段就很尴尬了。
在工程中,这样的问题可以用不同的服务实例来解决,通过不同访问的 endpoint 配置来区分。
最佳实践
本部分则试图讨论一些更加详细、具体的建议,可以让 API 的设计更容易满足前面描述的基础原则。
想想优秀的API例子:POSIX File API
如果说 API 的设计实践只能列一条的话,那么可能最有帮助的和最可操作的就是这一条。本文也可以叫做“通过 File API 体会 API 设计的最佳实践”。
所以整个最佳实践可以总结为一句话:“想想 File API 是怎么设计的。”
首先回顾一下 File API 的主要接口(以C为例,很多是 Posix API,选用比较简单的I/O接口为例【1】:
int open(const char *path, int oflag, .../*,mode_t mode */);int close (int filedes);int remove( const char *fname );ssize_t write(int fildes, const void *buf, size_t nbyte);ssize_t read(int fildes, void *buf, size_t nbyte);
File API 为什么是经典的好 API 设计?
File API 已经有几十年历史(从1988年算起,已30年),尽管期间硬件软件系统的发展经历了好几代,这套 API 核心保持了稳定。这是极其了不起的。
API 提供了非常清晰的概念模型,每个人都能够很快理解这套API背后的基础概念:什么是文件,以及相关联的操作(open, close, read, write),清晰明了;
支持很多的不同文件系统实现,这些系统实现甚至于属于类型非常不同的设备,例如磁盘、块设备、管道(pipe)、共享内存、网络、终端 terminal 等等。这些设备有的是随机访问的,有的只支持顺序访问;有的是持久化的有的则不是。然而所有不同的设备不同的文件系统实现都可以采用了同样的接口,使得上层系统不必关注底层实现的不同,这是这套 API 强大的生命力的表现。
例如同样是打开文件的接口,底层实现完全不同,但是通过完全一样的接口,不同的路径以及 Mount 机制,实现了同时支持。其他还有 Procfs, pipe 等。
int open(const char *path, int oflag, .../*,mode_t mode */);
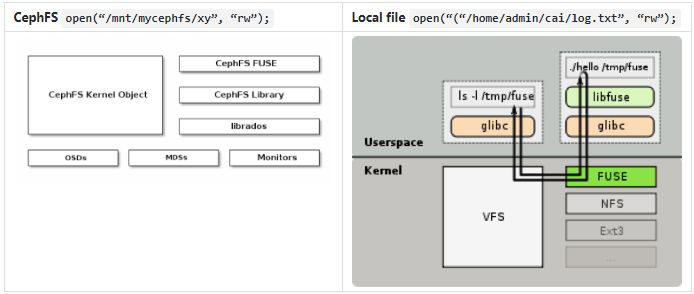
上图中,cephfs 和本地文件系统,底层对应完全不同的实现,但是上层 client 可以不用区分对待,采用同样的接口来操作,只通过路径不同来区分。
基于上面的这些原因,我们知道 File API 为什么能够如此成功。事实上,它是如此的成功以至于今天的 *-nix 操作系统,everything is filed based.
尽管我们有了一个非常好的例子 File API,但是要设计一个能够长期保持稳定的 API是一项及其困难的事情,因此仅有一个好的参考还不够,下面再试图展开去讨论一些更细节的问题。
Document well 写详细的文档
写详细的文档,并保持更新。 关于这一点,其实无需赘述,现实是,很多API的设计和维护者不重视文档的工作。
在一个面向服务化/Micro-service 化架构的今天,一个应用依赖大量的服务,而每个服务 API 又在不断的演进过程中,准确的记录每个字段和每个方法,并且保持更新,对于减少客户端的开发踩坑、减少出问题的几率,提升整体的研发效率至关重要。
Carefully define the "resource" of your API 仔细的定义“资源”
如果适合的话,选用“资源”加操作的方式来定义。今天很多的 API 都可以采用这样一个抽象的模式来定义,这种模式有很多好处,也适合于 HTTP 的 RESTful API 的设计。但是在设计 API 时,一个重要的前提是对 Resource 本身进行合理的定义。什么样的定义是合理的? Resource 资源本身是对一套 API 操作核心对象的一个抽象Abstraction。
抽象的过程是去除细节的过程。在我们做设计时,如果现实世界的流程或者操作对象是具体化的,抽象的 Object 的选择可能不那么困难,但是对于哪些细节应该包括,是需要很多思考的。例如对于文件的API,可以看出,文件 File 这个 Resource(资源)的抽象,是“可以由一个字符串唯一标识的数据记录”。这个定义去除了文件是如何标识的(这个问题留给了各个文件系统的具体实现),也去除了关于如何存储的组织结构(again,留给了存储系统)细节。
虽然我们希望API简单,但是更重要的是选择对的实体来建模。在底层系统设计中,我们倾向于更简单的抽象设计。有的系统里面,域模型本身的设计往往不会这么简单,需要更细致的考虑如何定义 Resource。一般来说,域模型中的概念抽象,如果能和现实中的人们的体验接近,会有利于人们理解该模型。选择对的实体来建模往往是关键。结合域模型的设计,可以参考相关的文章,例如阿白老师的文章【2】。
Choose the right level of abstraction 选择合适的抽象层
与前面的一个问题密切相关的,是在定义对象时需要选择合适的 Level of abstraction (抽象的层级)。不同概念之间往往相互关联。仍然以 File API 为例。在设计这样的 API 时,选择抽象的层级的可能的选项有多个,例如:
文本、图像混合对象
“数据块” 抽象
”文件“抽象
这些不同的层级的抽象方式,可能描述的是同一个东西,但是在概念上是不同层面的选择。当设计一个 API 用于与数据访问的客户端交互时,“文件 File “是更合适的抽象,而设计一个 API 用于文件系统内部或者设备驱动时,数据块或者数据块设备可能是合适的抽象,当设计一个文档编辑工具时,可能会用到“文本图像混合对象”这样的文件抽象层级。
又例如,数据库相关的 API 定义,底层的抽象可能针对的是数据的存储结构,中间是数据库逻辑层需要定义数据交互的各种对象和协议,而在展示(View layer)的时候需要的抽象又有不同【3】。

Naming and identification of the resource 命名与标识
当 API 定义了一个资源对象,下面一般需要的是提供命名/标识( Naming and identification )。在 naming/ID 方面,一般有两个选择(不是指系统内部的 ID,而是会暴露给用户的):
用free-form string作为ID(string nameAsId)
用结构化数据表达naming/ID
何时选择哪个方法,需要具体分析。采用 Free-form string 的方式定义的命名,为系统的具体实现留下了最大的自由度。带来的问题是命名的内在结构(如路径)本身并非API强制定义的一部分,转为变成实现细节。如果命名本身存在结构,客户端需要有提取结构信息的逻辑,这是一个需要做的平衡。
例如文件 API 采用了 free-form string 作为文件名的标识方式,而文件的 URL 则是文件系统具体实现规定。这样,就容许 Windows 操作系统采用 "D:\Documents\File.jpg" 而 Linux 采用 "/etc/init.d/file.conf" 这样的结构了。而如果文件命名的数据结构定义为:
{disk: string,path: string}
这样结构化的方式,透出了 "disk" 和 "path" 两个部分的结构化数据,那么这样的结构可能适应于 Windows 的文件组织方式,而不适应于其他文件系统,也就是说泄漏了实现细节。
如果资源 Resource 对象的抽象模型自然包含结构化的标识信息,则采用结构化方式会简化客户端与之交互的逻辑,强化概念模型。这时牺牲掉标识的灵活度,换取其他方面的优势。例如,银行的转账账号设计,可以表达为:
{account: numberrouting: number}
这样一个结构化标识,由账号和银行间标识两部分组成,这样的设计含有一定的业务逻辑在内,但是这部分业务逻辑是被描述的系统内在逻辑而非实现细节,并且这样的设计可能有助于具体实现的简化以及避免一些非结构化的字符串标识带来的安全性问题等。因此在这里结构化的标识可能更适合。
另一个相关的问题是,何时应该提供一个数字 unique ID ? 这是一个经常遇到的问题。有几个问题与之相关需要考虑:
是否已经有结构化或者字符串的标识可以唯一、稳定标识对象?如果已经有了,那么就不一定需要 numerical ID;
64位整数范围够用吗?
数字 ID 可能不是那么用户友好,对于用户来讲数字的 ID 会有帮助吗?
如果这些问题都有答案而且不是什么阻碍,那么使用数字 ID 是可以的,否则要慎用数字ID。
Conceptually what are the meaningful operations on this resource? 对于该对象来说,什么操作概念上是合理的?
在确定下来了资源/对象以后,我们还需要定义哪些操作需要支持。这时,考虑的重点是“ 概念上合理(Conceptually reasonable)”。换句话说,operation + resource 连在一起听起来自然而然合理(如果 Resource 本身命名也比较准确的话。当然这个“如果命名准确”是个 big if,非常不容易做到)。操作并不总是CRUD(create, read, update, delete)。
例如,一个 API 的操作对象是额度(Quota ),那么下面的操作听上去就比较自然:
Update quota(更新额度),transfer quota(原子化的转移额度)
但是如果试图 Create Quota,听上去就不那么自然,因额度这样一个概念似乎表达了一个数量,概念上不需要创建。额外需要思考一下,这个对象是否真的需要创建?我们真正需要做的是什么?
For update operations, prefer idempotency whenever feasible 更新操作,尽量保持幂等性
Idempotency 幂等性,指的是一种操作具备的性质,具有这种性质的操作可以被多次实施并且不会影响到初次实施的结果“the property of certain operations in mathematics and computer science whereby they can be applied multiple times without changing the result beyond the initial application.”【3】
很明显 Idempotency 在系统设计中会带来很多便利性,例如客户端可以更安全地重试,从而让复杂的流程实现更为简单。但是 Idempotency 实现并不总是很容易。
Create 类型的 idempotency 创建的 Idempotency,多次调用容易出现重复创建,为实现幂等性,常见的做法是使用一个 client-side generated de-deduplication token(客户端生成的唯一ID),在反复重试时使用同一个Unique ID,便于服务端识别重复。
Update类型的Idempotency,更新值(update)类型的API,应该避免采用"Delta"语义,以便于实现幂等性。对于更新类的操作,我们再简化为两类实现方式: Incremental(数量增减),如 IncrementBy (3)这样的语义;SetNewTotal(设置新的总量)。
IncrementBy 这样的语义重试的时候难以避免出错,而 SetNewTotal(3)(总量设置为x)语义则比较容易具备幂等性。
当然在这个例子里面,也需要看到,IncrementBy 也有优点,即多个客户请求同时增加的时候,比较容易并行处理,而 SetTotal 可能导致并行的更新相互覆盖(或者相互阻塞)。
这里,可以认为 更新增量和_设置新的总量_这两种语义是不同的优缺点,需要根据场景来解决。如果必须优先考虑并发更新的情景,可以使用_更新增量_的语义,并辅助以 Deduplication token 解决幂等性。
Delete 类型 idempotency : Delete 的幂等性问题,往往在于一个对象被删除后,再次试图删除可能会由于数据无法被发现导致出错。这个行为一般来说也没什么问题,虽然严格意义上不幂等,但是也无副作用。如果需要实现Idempotency,系统也采用了 Archive->Purge 生命周期的方式分步删除,或者持久化 Purge log 的方式,都能支持幂等删除的实现。
Compatibility 兼容
API的变更需要兼容,兼容,兼容!重要的事情说三遍。这里的兼容指的是向后兼容,而兼容的定义是不会 Break 客户端的使用,也即老的客户端能否正常访问服务端的新版本(如果是同一个大版本下)不会有错误的行为。这一点对于远程的API(HTTP/RPC)尤其重要。关于兼容性,已经有很好的总结,例如【4】提供的一些建议。
常见的不兼容变化包括(但不限于):
删除一个方法、字段或者enum的数值
方法、字段改名
方法名称字段不改,但是语义和行为的变化,也是不兼容的。这类比较容易被忽视。 更具体描述可以参加【4】。
另一个关于兼容性的重要问题是,如何做不兼容的API变更?通常来说,不兼容变更需要通过一个 Deprecation process,在大版本发布时来分步骤实现。关于Deprecation process,这里不展开描述,一般来说,需要保持过去版本的兼容性的前提下,支持新老字段/方法/语义,并给客户端足够的升级时间。这样的过程比较耗时,也正是因为如此,我们才需要如此重视API的设计。
有时,一个面向内部的 API 升级,往往开发的同学倾向于选择高效率,采用一种叫”同步发布“的模式来做不兼容变更,即通知已知的所有的客户端,自己的服务API要做一个不兼容变更,大家一起发布,同时更新,切换到新的接口。这样的方法是非常不可取的,原因有几个:
我们经常并不知道所有使用 API 的客户
发布过程需要时间,无法真正实现“同步更新”
不考虑向后兼容性的模式,一旦新的 API 有问题需要回滚,则会非常麻烦,这样的计划八成也不会有回滚方案,而且客户端未必都能跟着回滚。
因此,对于在生产集群已经得到应用的API,强烈不建议采用“同步升级”的模式来处理不兼容API变更。
Batch mutations 批量更新
批量更新如何设计是另一个常见的API设计决策。这里我们常见有两种模式:
客户端批量更新
服务端实现批量更新。 如下图所示。

API的设计者可能会希望实现一个服务端的批量更新能力,但是我们建议要尽量避免这样做。除非对于客户来说提供原子化+事务性的批量很有意义( all-or-nothing),否则实现服务端的批量更新有诸多的弊端,而客户端批量更新则有优势:
服务端批量更新带来了API语义和实现上的复杂度,例如当部分更新成功时的语义、状态表达等。
即使我们希望支持批量事物,也要考虑到是否不同的后端实现都能支持事务性。
批量更新往往给服务端性能带来很大挑战,也容易被客户端滥用接口。
在客户端实现批量,可以更好的将负载由不同的服务端来承担(见图)。
客户端批量可以更灵活的由客户端决定失败重试策略。
Be aware of the risks in full replace 警惕全体替换更新模式的风险
所谓 Full replacement 更新,是指在 Mutation API 中,用一个全新的Object/Resource 去替换老的 Object/Resource 的模式。
API写出来大概是这样的:
UpdateFoo(Foo newFoo);
这是非常常见的 Mutation 设计模式。但是这样的模式有一些潜在的风险作为 API 设计者必须了解。
使用 Full replacement 的时候,更新对象 Foo 在服务端可能已经有了新的成员,而客户端尚未更新并不知道该新成员。服务端增加一个新的成员一般来说是兼容的变更,但是,如果该成员之前被另一个知道这个成员的client设置了值,而这时一个不知道这个成员的 client 来做 full-replace,该成员可能就会被覆盖。
更安全的更新方式是采用 Update mask,也即在 API 设计中引入明确的参数指明哪些成员应该被更新。
UpdateFoo {Foo newFoo;boolen update_field1; // update maskboolen update_field2; // update mask}
或者 update mask 可以用 repeated "a.b.c.d“这样方式来表达。
不过由于这样的 API 方式维护和代码实现都复杂一些,采用这样模式的 API 并不多。所以,本节的标题是 “be aware of the risk“,而不是要求一定要用 update mask。
Don't create your own error codes or error mechanism 不要试图创建自己的错误码和返回错误机制
API 的设计者有时很想创建自己的 Error code,或者是表达返回错误的不同机制,因为每个 API 都有很多的细节的信息,设计者想表达出来并返回给用户,想着“用户可能会用到”。但是事实上,这么做经常只会使API变得更复杂更难用。
Error-handling 是用户使用 API 非常重要的部分。为了让用户更容易的使用 API,最佳的实践应该是用标准、统一的 Error Code,而不是每个 API 自己去创立一套。例如 HTTP 有规范的 error code 【7】,Google Could API 设计时都采用统一的Error code 等【5】。
为什么不建议自己创建 Error code 机制?
Error-handling 是客户端的事,而对于客户端来说,是很难关注到那么多错误的细节的,一般来说最多分两三种情况处理。往往客户端最关心的是"这个error 是否应该重试( retryable )"还是应该继续向上层返回错误,而不是试图区分不同的 error 细节。这时多样的错误代码机制只会让处理变得复杂。
有人觉得提供更多的自定义的 error code 有助于传递信息,但是这些信息除非有系统分别处理才有意义。如果只是传递信息的话,error message 里面的字段可以达到同样的效果。
More
更多的Design patterns,可以参考[5] Google Cloud API guide,[6] Microsoft API design best practices等。不少这里提到的问题也在这些参考的文档里面有涉及,另外他们还讨论到了像versioning,pagination,filter等常见的设计规范方面考虑。这里不再重复。
参考文献:
【1】File wiki
https://en.wikipedia.org/wiki/Computer_file
【2】阿白,域模型设计系列文章
https://yq.aliyun.com/articles/2255
【3】Idempotency, wiki
https://en.wikipedia.org/wiki/Idempotence
【4】Compatibility
https://cloud.google.com/apis/design/compatibility
【5】API Design patterns for Google Cloud
https://cloud.google.com/apis/design/design_patterns
【6】API design best practices, Microsoft
https://docs.microsoft.com/en-us/azure/architecture/best-practices/api-design
【7】Http status code
https://en.wikipedia.org/wiki/List_of_HTTP_status_codes
【8】A philosophy of software design, John Ousterhout
你可能还喜欢
以上是关于最佳实践 | 什么是好的日志记录实践?的主要内容,如果未能解决你的问题,请参考以下文章