深入浅出 Spark:内存计算的由来
Posted InfoQ
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深入浅出 Spark:内存计算的由来相关的知识,希望对你有一定的参考价值。

欲探究竟,还需从头说起。在 Hadoop 出现以前,数据分析市场的参与者主要由以 IOE(IBM、Oracle、EMC)为代表的传统 IT 巨头构成,Share-nothing 架构的分布式计算框架大行其道。传统的 Share-nothing 架构凭借其预部署、高可用、高性能的特点在金融业、电信业大放异彩。然而,随着互联网行业飞速发展,瞬息万变的业务场景对于分布式计算框架的灵活性与扩展性要求越来越高,笨重的 Share-nothing 架构无法跟上行业发展的步伐。2006 年,Hadoop 应运而生,MapReduce 提供的分布式计算抽象,结合分布式文件系统 HDFS 与分布式调度系统 YARN,完美地诠释了“数据不动代码动”的新一代分布式计算思想。
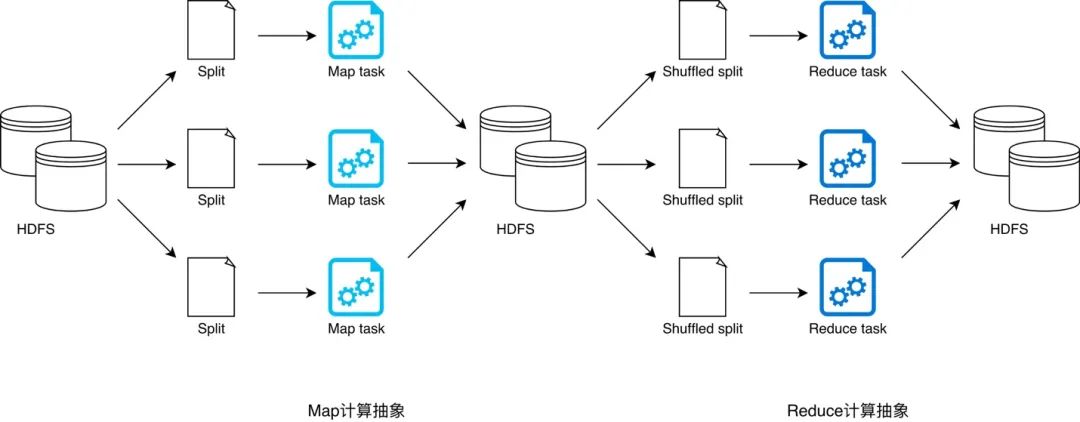
顾名思义,MapReduce 提供两类计算抽象,即 Map 和 Reduce。Map 抽象用于封装数据映射逻辑,开发者通过实现其提供的 map 接口来定义数据转换流程;Reduce 抽象用于封装数据聚合逻辑,开发者通过实现 reduce 接口来定义数据汇聚过程。Map 计算结束后,往往需要对数据进行分发才能启动 Reduce 计算逻辑来执行数据聚合任务,数据分发的过程称之为 Shuffle。MapReduce 提供的分布式任务调度让开发者专注于业务逻辑实现,而无需关心依赖管理、代码分发等分布式实现问题。在 MapReduce 框架下,为了完成端到端的计算作业,Hadoop 采用 YARN 来完成分布式资源调度从而充分利用廉价的硬件资源,采用 HDFS 作为计算抽象之间的数据接口来规避廉价磁盘引入的系统稳定性问题。
由此可见,Hadoop 的“三招一套”自成体系,MapReduce 搭配 YARN 与 HDFS,几乎可以实现任何分布式批处理任务。然而,近乎完美的组合也不是铁板一块,每一只木桶都有它的短板。HDFS 利用副本机制实现数据的高可用从而提升系统稳定性,但额外的分片副本带来更多的磁盘 I/O 和网络 I/O 开销,众所周知,I/O 开销会严重损耗端到端的执行性能。更糟的是,一个典型的批处理作业往往需要多次 Map、Reduce 迭代计算来实现业务逻辑,因此上图中的计算流程会被重复多次,直到最后一个 Reduce 任务输出预期的计算结果。我们来想象一下,完成这样的批处理作业,在整个计算过程中需要多少次落盘、读盘、发包、收包的操作?因此,随着 Hadoop 在互联网行业的应用越来越广泛,人们对其 MapReduce 框架的执行性能诟病也越来越多。
时势造英雄,Spark 这孩子不仅天资过人,学起东西来更是认真刻苦。当别人都在抱怨老师 Hadoop 的 MapReduce 心法有所欠缺时,他居然已经开始盘算如何站在老师的肩膀上推陈出新。在 Spark 拜师学艺三年后的 2009 年,这孩子提出了“基于内存的分布式计算引擎”—— Spark Core,此心法一出,整个武林为之哗然。Spark Core 最引入注目的地方莫过于“内存计算”,这一说法几乎镇住了当时所有的初学者,大家都认为 Spark Core 的全部计算都在内存中完成,人们兴奋地为之奔走相告。兴奋之余,大家开始潜心研读 Spark Core 内功心法,才打开心法的手抄本即发现一个全新的概念 —— RDD。
RDD(Resilient Distributed Datasets),全称是“弹性分布式数据集”。全称本身并没能很好地解释 RDD 到底是什么,本质上,RDD 是 Spark 用于对分布式数据进行抽象的数据模型。简言之,RDD 是一种抽象的数据模型,这种数据模型用于囊括、封装所有内存中和磁盘中的分布式数据实体。对于大部分 Spark 初学者来说,大家都有一个共同的疑惑:Spark 为什么要提出这么一个新概念?与其正面回答这个问题,不如我们来反思另一个问题:Hadoop 老师的 MapReduce 框架,到底欠缺了什么?有哪些可以改进的地方?前文书咱们提到:MapReduce 计算模型采用 HDFS 作为算子(Map 或 Reduce)之间的数据接口,所有算子的临时计算结果都以文件的形式存储到 HDFS 以供下游算子消费。下游算子从 HDFS 读取文件并将其转化为键值对(江湖人称 KV),用 Map 或 Reduce 封装的计算逻辑处理后,再次以文件的形式存储到 HDFS。不难发现,问题就出在数据接口上。HDFS 引发的计算效率问题我们不再赘述,那么,有没有比 HDFS 更好的数据接口呢?如果能够将所有中间环节的数据文件以某种统一的方式归纳、抽象出来,那么所有 map 与 reduce 算子是不是就可以更流畅地衔接在一起,从而不再需要 HDFS 了呢?—— Spark 提出的 RDD 数据模型,恰好能够实现如上设想。
为了弄清楚 RDD 的基本构成和特性,我们从它的 5 大核心属性说起。
| 属性名 | 成员类型 | 属性含义 |
|---|---|---|
| dependencies | 变量 | 生成该 RDD 所依赖的父 RDD |
| compute | 方法 | 生成该 RDD 的计算接口 |
| partitions | 变量 | 该 RDD 的所有数据分片实体 |
| partitioner | 方法 | 划分数据分片的规则 |
| preferredLocations | 变量 | 数据分片的物理位置偏好 |
对于 RDD 数据模型的抽象,我们只需关注前两个属性,即 dependencies 和 compute。任何一个 RDD 都不是凭空产生的,每个 RDD 都是基于一定的“计算规则”从某个“数据源”转换而来。dependencies 指定了生成该 RDD 所需的“数据源”,术语叫作依赖或父 RDD;compute 描述了从父 RDD 经过怎样的“计算规则”得到当前的 RDD。这两个属性看似简单,实则大有智慧。
与 MapReduce 以算子(Map 和 Reduce)为第一视角、以外部数据为衔接的设计方式不同,Spark Core 中 RDD 的设计以数据作为第一视角,不再强调算子的重要性,算子仅仅是 RDD 数据转换的一种计算规则,map 算子和 reduce 算子纷纷被弱化、稀释在 Spark 提供的茫茫算子集合之中。dependencies 与 compute 两个核心属性实际上抽象出了“从哪个数据源经过怎样的计算规则和转换,从而得到当前的数据集”。父与子的关系是相对的,将思维延伸,如果当前 RDD 还有子 RDD,那么从当前 RDD 的视角看过去,子 RDD 的 dependencies 与 compute 则描述了“从当前 RDD 出发,再经过怎样的计算规则与转换,可以获得新的数据集”。
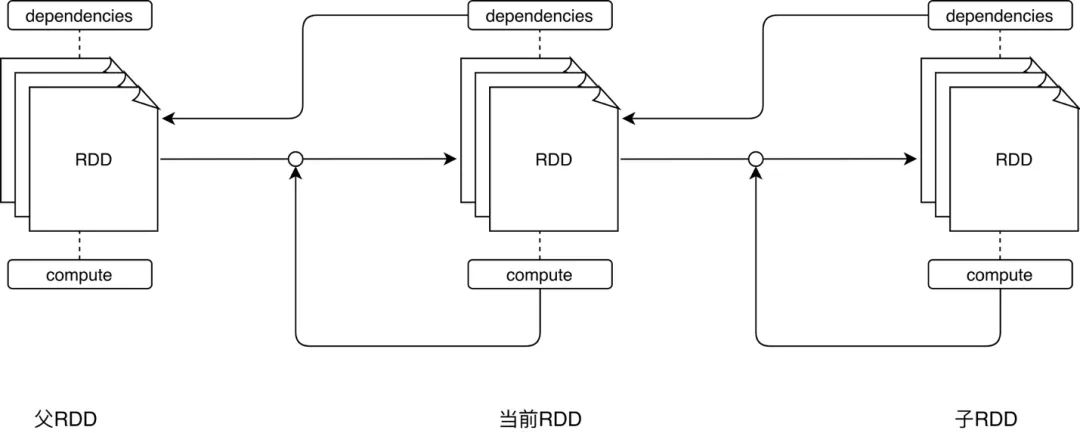
不难发现,所有 RDD 根据 dependencies 中指定的依赖关系和 compute 定义的计算逻辑构成了一条从起点到终点的数据转换路径。这条路径在 Spark 中有个专门的术语,叫作 Lineage —— 血统。Spark Core 依赖血统进行依赖管理、阶段划分、任务分发、失败重试,任意一个 Spark 计算作业都可以析构为一个 Spark Core 血统。关于血统,到后文书再展开讨论,我们继续介绍 RDD 抽象的另外 3 个属性,即 partitions、partitioner 和 preferredLocations。相比 dependencies 和 compute 属性,这 3 个属性更“务实”一些。
在分布式计算中,一个 RDD 抽象可以对应多个数据分片实体,所有数据分片构成了完整的 RDD 数据集。partitions 属性记录了 RDD 的每一个数据分片,方便开发者灵活地访问数据集。partitioner 则描述了 RDD 划分数据分片的规则和逻辑,采用不同的 partitioner 对 RDD 进行划分,能够以不同的方式得到不同数量的数据分片。因此,partitioner 的选取,直接决定了 partitions 属性的分布。preferredLocations —— 位置偏好,该属性与 partitions 属性一一对应,定义了每一个数据分片的物理位置偏好。具体来说,每个数据分片可以有以下几种不同的位置偏好:
根据“数据不动代码动”的原则,Spark Core 优先尊重数据分片的本地位置偏好,尽可能地将计算任务分发到本地计算节点去处理。显而易见,本地计算的优势来源于网络开销的大幅减少,进而从整体上提升执行性能。
RDD 的 5 大属性从“虚”与“实”两个角度刻画了对数据模型的抽象,任何数据集,无论格式、无论形态,都可以被 RDD 抽象、封装。前面提到,任意分布式计算作业都可以抽象为血统,而血统由不同 RDD 抽象的依次转换构成,因此,任意的分布式作业都可以由 RDD 抽象之间的转换来实现。理论上,如果计算节点内存足够大,那么所有关于 RDD 的转换操作都可以放到内存中来执行,这便是“内存计算”的由来。
从理论出发学习、理解新概念总是枯燥而乏味,通过生活化的类比来更好地理解 RDD 的构成和内存计算的由来也许会更轻松一些。假设有个生产桶装薯片的工坊,这个工坊规模小、工艺也比较原始。为了充分利用每一颗土豆、降低生产成本,工坊使用 3 条流水线来同时生产 3 种不同尺寸的桶装薯片,分别是小号、中号、大号桶装薯片。3 条流水线可以同时加工 3 颗土豆,每条流水线的作业流程都是一样的,即土豆的清洗、切片、烘焙、分发、装桶,其中分发环节用于区分小号、中号、大号 3 种薯片。所有小号薯片都会分发给第一条流水线,中号薯片分发给第二条流水线,不消说,大号薯片都分发给第三条流水线。看得出来,这家工坊工艺虽然简单,倒是也蛮有章法。桶装薯片的制作流程,与 Spark 分布式计算的执行过程颇为神似。
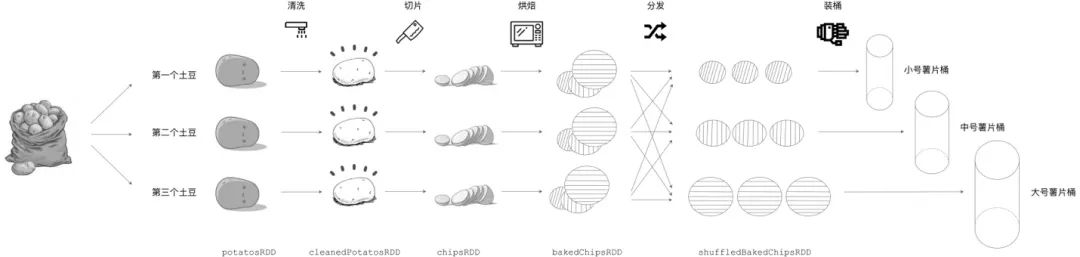
我们先从食材的视角审视薯片的加工流程,首先,3 颗土豆作为原始素材被送上流水线。流水线的第一道工序是清洗,原来带泥的土豆经过清洗变成了一颗颗“干净的土豆”。第二道工序是切片,土豆经过切片操作后,变成了一枚枚大小不一、薄薄的薯片,当然,这些薯片都还是生的,等到烘烤之后方能食用。第三道工序正是用来烘焙,生薯片在经过烘烤后,变成了可以食用的零食。到目前为止,所有流水线上都生产出了 “原味”的薯片,不过,薯片的尺寸参差不齐,如果现在就装桶的话,一来用户体验较差,二来桶的利用效率也低,不利于节约成本。因此,流水线上增加了分发的环节,分发操作先把不同尺寸的薯片区分开,然后根据预定规则把不同尺寸的薯片发送到对应的流水线上。每条流水线都执行同样的分发操作,即先区分大小号,然后再转发薯片。分发步骤完成后,每条流水线的薯片尺寸大小相当,最后通过机械手把薯片封装到对应尺寸的桶里,从而完成一次完整的薯片加工流程。
横看成岭侧成峰,我们再从流水线的视角,重新审视这个过程。从头至尾,除了分发环节,3 条流水线没有任何交集。在分发环节之前,每条流水线都是专心致志、各顾各地开展工作 —— 把土豆食材加载到流水线上、清洗、切片、烘焙;在分发环节完成后,3 条流水线也是各自装桶,互不影响。流水线式的作业方式提供了较强的容错能力,如果某个加工环节出错,流水线只需要重新加载一颗新的土豆食材就能够恢复生产。例如,假设第一条流水线在烘焙阶段不小心把薯片烤糊了,此时只需要在流水线的源头重新加载一颗新的土豆,所有加工流程会自动重新开始,不会影响最终的装桶操作。另外,3 条流水线提供了同时处理 3 颗土豆的能力,因此土豆工坊的并发能力为 3,每次可以同时装载并加工 3 颗土豆,大幅地提升了生产效率。
那么,用土豆工坊薯片加工的流程类比 Spark 分布式计算,会有哪些有趣的发现呢?仔细对比,每一种食材形态,如刚从地里挖出来的土豆食材、清洗后的“干净土豆”、生薯片、烤熟的薯片、分发后的薯片,不就是 Spark 中的 RDD 抽象吗?每个 RDD 都有 dependencies 和 compute 属性,对应地,每一种食材形态的 dependencies 就是流水线上前一个步骤的食材形态,而其 compute 属性就是从前一种食材形态转换到当前这种食材形态的加工方法。例如,对于烤熟的薯片(图中 bakedChipsRDD)来说,它的 dependencies 就是上一步的“已切好的生薯片”(chipsRDD),而它的 compute 属性,就是“烘焙”这一工艺方法。在土豆工坊的制作流程中,从头至尾会产生 6 个 RDD,即 potatosRDD、cleanedPotatosRDD、chipsRDD、bakedChipsRDD 和 shuffledBakedChipsRDD,分别对应不同的食材形态。注意,RDD 是对数据模型的抽象,它的 partitions 属性会对应多个数据分片实体。例如,对于原始食材 potatosRDD,它的 partitions 属性对应的是图中的 3 颗带泥土豆,每颗土豆代表一个“数据分片”。
同理,chipsRDD 的 partitions 属性包含的是从 3 颗土豆切出来的所有“生薯片”,每一枚生薯片都有一个 preferredLocation 用来标记自己所在的流水线,所有生薯片的 preferredLocation 集合构成了 chipsRDD 的 preferredLocations 属性。不难发现,如果我们把土豆工坊中的流水线看成是分布式计算节点,流水线上每一种食材形态的转换,都可以在计算节点中按序完成。特别地,如果节点内存足够大,那么所有上述转换,都可以在内存中完成。随着纳米工艺的飞速发展,在不远的将来,也许内存的价格会像现在的磁盘一样便宜。正是基于这样的判断,Spark 提出了“内存计算”的概念。

Linus Torvalds 他老人家常说:“Talk is cheap. Show me the code.”。在本篇的最后,我们通过代码示例来直观地感受一下 RDD 的转换过程。学习一门新的编程语言,我们通常从“Hello World”开始;学习分布式开发,我们得从“Word Count”说起。在开始之前,我们准备一个纯文本文件,内容非常简单,只有 3 行文本,如下图所示:

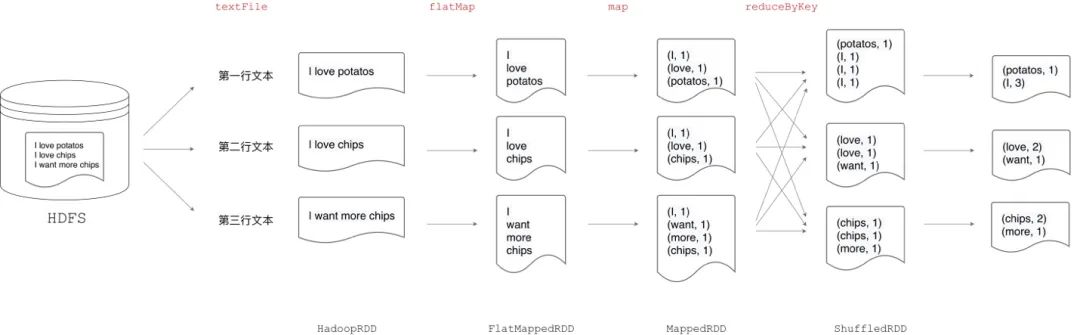
“Word Count”任务的目标是拆分文本中的单词并对所有单词计数,对于上图中的文本内容,我们期望的结果是 I 的计数是 3,chips 的计数为 2,等等。在用代码来实现这个任务之前,我们先来思考一下:解决这个问题,都需要哪些步骤。首先,我们需要将文件内容读取到计算节点内存,同时对数据进行分片;对于每个数据分片,我们要将句子分割为一个个的单词,同样的单词可能存在于多个不同的分片中(如单词 I),因此需要对单词进行分发,从而使得同样的单词只存在于一个分片之中;最后,在所有分片上计算每个单词的计数。对于这样一个分词计数任务,如果采用 Hadoop MapReduce 框架来实现,往往需要用 Java 来实现 Map、Reduce 抽象,编写上百行代码。得益于 Spark RDD 数据模型的设计及其提供的丰富算子,无论是用 Java、Scala 还是 Python,只消几行代码,即可实现“Word Count”任务。

结合刚刚分析的“解题步骤”,我们首先通过 textFile 算子将文件内容加载到内存,同时对数据进行分片。然后,用 flatMap 和 map 算子实现分词和计 1 的操作。这里计 1 的目的有二,一来是将数据转换为(键, 值)对的形式从而调用 pairRDD 相关算子;二来为 Map 端聚合计算打下基础。关于 pairRDD、性能优化,我们在后文书会详细展开,此处先行略过。最后,通过 reduceByKey 算子完成单词的分发和计数。在这份代码中,我们仅用 5 行 Scala code 就实现了“Word Count”分布式计算作业。在算子的驱动下,不同形态 RDD 之间的依赖关系与转换过程一目了然。那么,如果把这段代码放到土豆工坊的流水线上,会是怎样的流程呢?
本篇是《Spark 分布式计算科普专栏》的第一篇,笔者学浅才疏、疏漏难免。如果您有任何疑问,或是觉得文章中的描述有所遗漏或不妥,欢迎在评论区留言、讨论。掌握一门技术,书本中的知识往往只占两成,三成靠讨论,五成靠实践。更多的讨论能激发更多的观点、视角与洞察,也只有这样,对于一门技术的认知与理解才能更深入、牢固。在本篇博文中,我们从分布式计算发展历史的角度,审视了 Spark、RDD 以及内存计算的由来;以 RDD 的 5 大核心属性展开,讲解 RDD 的构成、依赖关系、转换过程,并结合“土豆工坊”的生活化示例来类比 RDD 转换和 Spark 分布式内存计算的工作流程。
最后,我们用一个简单的代码示例 —— Word Count 来直观地体会 Spark 算子与 RDD 的转换逻辑。细心的读者可能早已发现,文中多次提及“后文书再展开”,Spark 是一个精妙而复杂的分布式计算引擎,在本篇博文中我们不得不对 Spark 中的许多概念都进行了“前置引用”。换句话说,有些概念还没来得及解释(如 Lineage —— 血统),就已经被引入到了本篇博文中。这样的叙述方法也许会给一些读者带来困惑,毕竟,用一个还未说清的概念,去解释另一个新概念,总是感觉没那么牢靠。常言道:“出来混,迟早是要还的”。在后续的专栏文章中,我们会继续对 Spark 的核心概念与原理进行探讨,尽可能地还原 Spark 分布式内存计算引擎的全貌。
作者简介:
吴磊,Spark Summit China 2017 讲师、World AI Conference 2020 讲师,曾任职于 IBM、联想研究院、新浪微博,具备丰富的数据库、数据仓库、大数据开发与调优经验,主导基于海量数据的大规模机器学习框架的设计与实现。现担任 Comcast Freewheel 机器学习团队负责人,负责计算广告业务中机器学习应用的实践、落地与推广。热爱技术分享,热衷于从生活的视角解读技术,曾于《IBM developerWorks》和《程序员》杂志发表多篇技术文章。
今日荐文
点击下方图片即可阅读

120 天已至,华为全面断芯,没有 Plan B
InfoQ 读者交流群上线啦!各位小伙伴可以扫描下方二维码,添加 InfoQ 小助手,回复关键字“进群”申请入群。回复“资料”,获取资料包传送门,注册 InfoQ 网站后,可以任意领取一门极客时间课程,免费滴!大家可以和 InfoQ 读者一起畅所欲言,和编辑们零距离接触,超值的技术礼包等你领取,还有超值活动等你参加,快来加入我们吧!

点个在看少个 bug Apache Spark 内存管理详解
Apache Spark 内存管理详解
Spark 作为一个基于内存的分布式计算引擎,其内存管理模块在整个系统中扮演着非常重要的角色。理解 Spark 内存管理的基本原理,有助于更好地开发 Spark 应用程序和进行性能调优。本文旨在梳理出 Spark 内存管理的脉络,抛砖引玉,引出读者对这个话题的深入探讨。本文中阐述的原理基于 Spark 2.1 版本,阅读本文需要读者有一定的 Spark 和 Java 基础,了解 RDD、Shuffle、JVM 等相关概念。
在执行 Spark 的应用程序时,Spark 集群会启动 Driver 和 Executor 两种 JVM 进程,前者为主控进程,负责创建 Spark 上下文,提交 Spark 作业(Job),并将作业转化为计算任务(Task),在各个 Executor 进程间协调任务的调度,后者负责在工作节点上执行具体的计算任务,并将结果返回给 Driver,同时为需要持久化的 RDD 提供存储功能[1]。由于 Driver 的内存管理相对来说较为简单,本文主要对 Executor 的内存管理进行分析,下文中的 Spark 内存均特指 Executor 的内存。
1. 堆内和堆外内存规划
作为一个 JVM 进程,Executor 的内存管理建立在 JVM 的内存管理之上,Spark 对 JVM 的堆内(On-heap)空间进行了更为详细的分配,以充分利用内存。同时,Spark 引入了堆外(Off-heap)内存,使之可以直接在工作节点的系统内存中开辟空间,进一步优化了内存的使用。
图 1 . 堆内和堆外内存示意图

1.1 堆内内存
堆内内存的大小,由 Spark 应用程序启动时的 –executor-memory 或 spark.executor.memory 参数配置。Executor 内运行的并发任务共享 JVM 堆内内存,这些任务在缓存 RDD 数据和广播(Broadcast)数据时占用的内存被规划为存储(Storage)内存,而这些任务在执行 Shuffle 时占用的内存被规划为执行(Execution)内存,剩余的部分不做特殊规划,那些 Spark 内部的对象实例,或者用户定义的 Spark 应用程序中的对象实例,均占用剩余的空间。不同的管理模式下,这三部分占用的空间大小各不相同(下面第 2 小节会进行介绍)。
Spark 对堆内内存的管理是一种逻辑上的"规划式"的管理,因为对象实例占用内存的申请和释放都由 JVM 完成,Spark 只能在申请后和释放前记录这些内存,我们来看其具体流程:
- 申请内存:
- Spark 在代码中 new 一个对象实例
- JVM 从堆内内存分配空间,创建对象并返回对象引用
- Spark 保存该对象的引用,记录该对象占用的内存
- 释放内存:
- Spark 记录该对象释放的内存,删除该对象的引用
- 等待 JVM 的垃圾回收机制释放该对象占用的堆内内存
我们知道,JVM 的对象可以以序列化的方式存储,序列化的过程是将对象转换为二进制字节流,本质上可以理解为将非连续空间的链式存储转化为连续空间或块存储,在访问时则需要进行序列化的逆过程——反序列化,将字节流转化为对象,序列化的方式可以节省存储空间,但增加了存储和读取时候的计算开销。
对于 Spark 中序列化的对象,由于是字节流的形式,其占用的内存大小可直接计算,而对于非序列化的对象,其占用的内存是通过周期性地采样近似估算而得,即并不是每次新增的数据项都会计算一次占用的内存大小,这种方法降低了时间开销但是有可能误差较大,导致某一时刻的实际内存有可能远远超出预期[2]。此外,在被 Spark 标记为释放的对象实例,很有可能在实际上并没有被 JVM 回收,导致实际可用的内存小于 Spark 记录的可用内存。所以 Spark 并不能准确记录实际可用的堆内内存,从而也就无法完全避免内存溢出(OOM, Out of Memory)的异常。
虽然不能精准控制堆内内存的申请和释放,但 Spark 通过对存储内存和执行内存各自独立的规划管理,可以决定是否要在存储内存里缓存新的 RDD,以及是否为新的任务分配执行内存,在一定程度上可以提升内存的利用率,减少异常的出现。
1.2 堆外内存
为了进一步优化内存的使用以及提高 Shuffle 时排序的效率,Spark 引入了堆外(Off-heap)内存,使之可以直接在工作节点的系统内存中开辟空间,存储经过序列化的二进制数据。利用 JDK Unsafe API(从 Spark 2.0 开始,在管理堆外的存储内存时不再基于 Tachyon,而是与堆外的执行内存一样,基于 JDK Unsafe API 实现[3]),Spark 可以直接操作系统堆外内存,减少了不必要的内存开销,以及频繁的 GC 扫描和回收,提升了处理性能。堆外内存可以被精确地申请和释放,而且序列化的数据占用的空间可以被精确计算,所以相比堆内内存来说降低了管理的难度,也降低了误差。
在默认情况下堆外内存并不启用,可通过配置 spark.memory.offHeap.enabled 参数启用,并由 spark.memory.offHeap.size 参数设定堆外空间的大小。除了没有 other 空间,堆外内存与堆内内存的划分方式相同,所有运行中的并发任务共享存储内存和执行内存。
1.3 内存管理接口
Spark 为存储内存和执行内存的管理提供了统一的接口——MemoryManager,同一个 Executor 内的任务都调用这个接口的方法来申请或释放内存:
清单 1 . 内存管理接口的主要方法
|
1
2
3
4
5
6
7
8
9
10
11
12
|
//申请存储内存def acquireStorageMemory(blockId: BlockId, numBytes: Long, memoryMode: MemoryMode): Boolean//申请展开内存def acquireUnrollMemory(blockId: BlockId, numBytes: Long, memoryMode: MemoryMode): Boolean//申请执行内存def acquireExecutionMemory(numBytes: Long, taskAttemptId: Long, memoryMode: MemoryMode): Long//释放存储内存def releaseStorageMemory(numBytes: Long, memoryMode: MemoryMode): Unit//释放执行内存def releaseExecutionMemory(numBytes: Long, taskAttemptId: Long, memoryMode: MemoryMode): Unit//释放展开内存def releaseUnrollMemory(numBytes: Long, memoryMode: MemoryMode): Unit |
我们看到,在调用这些方法时都需要指定其内存模式(MemoryMode),这个参数决定了是在堆内还是堆外完成这次操作。
MemoryManager 的具体实现上,Spark 1.6 之后默认为统一管理(Unified Memory Manager)方式,1.6 之前采用的静态管理(Static Memory Manager)方式仍被保留,可通过配置 spark.memory.useLegacyMode 参数启用。两种方式的区别在于对空间分配的方式,下面的第 2 小节会分别对这两种方式进行介绍。
2 . 内存空间分配
2.1 静态内存管理
在 Spark 最初采用的静态内存管理机制下,存储内存、执行内存和其他内存的大小在 Spark 应用程序运行期间均为固定的,但用户可以应用程序启动前进行配置,堆内内存的分配如图 2 所示:
图 2 . 静态内存管理图示——堆内

可以看到,可用的堆内内存的大小需要按照下面的方式计算:
清单 2 . 可用堆内内存空间
|
1
2
|
可用的存储内存 = systemMaxMemory * spark.storage.memoryFraction * spark.storage.safetyFraction可用的执行内存 = systemMaxMemory * spark.shuffle.memoryFraction * spark.shuffle.safetyFraction |
其中 systemMaxMemory 取决于当前 JVM 堆内内存的大小,最后可用的执行内存或者存储内存要在此基础上与各自的 memoryFraction 参数和 safetyFraction 参数相乘得出。上述计算公式中的两个 safetyFraction 参数,其意义在于在逻辑上预留出 1-safetyFraction 这么一块保险区域,降低因实际内存超出当前预设范围而导致 OOM 的风险(上文提到,对于非序列化对象的内存采样估算会产生误差)。值得注意的是,这个预留的保险区域仅仅是一种逻辑上的规划,在具体使用时 Spark 并没有区别对待,和"其它内存"一样交给了 JVM 去管理。
堆外的空间分配较为简单,只有存储内存和执行内存,如图 3 所示。可用的执行内存和存储内存占用的空间大小直接由参数 spark.memory.storageFraction 决定,由于堆外内存占用的空间可以被精确计算,所以无需再设定保险区域。
图 3 . 静态内存管理图示——堆外

静态内存管理机制实现起来较为简单,但如果用户不熟悉 Spark 的存储机制,或没有根据具体的数据规模和计算任务或做相应的配置,很容易造成"一半海水,一半火焰"的局面,即存储内存和执行内存中的一方剩余大量的空间,而另一方却早早被占满,不得不淘汰或移出旧的内容以存储新的内容。由于新的内存管理机制的出现,这种方式目前已经很少有开发者使用,出于兼容旧版本的应用程序的目的,Spark 仍然保留了它的实现。
2.2 统一内存管理
Spark 1.6 之后引入的统一内存管理机制,与静态内存管理的区别在于存储内存和执行内存共享同一块空间,可以动态占用对方的空闲区域,如图 4 和图 5 所示
图 4 . 统一内存管理图示——堆内

图 5 . 统一内存管理图示——堆外

其中最重要的优化在于动态占用机制,其规则如下:
- 设定基本的存储内存和执行内存区域(spark.storage.storageFraction 参数),该设定确定了双方各自拥有的空间的范围
- 双方的空间都不足时,则存储到硬盘;若己方空间不足而对方空余时,可借用对方的空间;(存储空间不足是指不足以放下一个完整的 Block)
- 执行内存的空间被对方占用后,可让对方将占用的部分转存到硬盘,然后"归还"借用的空间
- 存储内存的空间被对方占用后,无法让对方"归还",因为需要考虑 Shuffle 过程中的很多因素,实现起来较为复杂[4]
图 6 . 动态占用机制图示

凭借统一内存管理机制,Spark 在一定程度上提高了堆内和堆外内存资源的利用率,降低了开发者维护 Spark 内存的难度,但并不意味着开发者可以高枕无忧。譬如,所以如果存储内存的空间太大或者说缓存的数据过多,反而会导致频繁的全量垃圾回收,降低任务执行时的性能,因为缓存的 RDD 数据通常都是长期驻留内存的 [5] 。所以要想充分发挥 Spark 的性能,需要开发者进一步了解存储内存和执行内存各自的管理方式和实现原理。
3. 存储内存管理
3.1 RDD 的持久化机制
弹性分布式数据集(RDD)作为 Spark 最根本的数据抽象,是只读的分区记录(Partition)的集合,只能基于在稳定物理存储中的数据集上创建,或者在其他已有的 RDD 上执行转换(Transformation)操作产生一个新的 RDD。转换后的 RDD 与原始的 RDD 之间产生的依赖关系,构成了血统(Lineage)。凭借血统,Spark 保证了每一个 RDD 都可以被重新恢复。但 RDD 的所有转换都是惰性的,即只有当一个返回结果给 Driver 的行动(Action)发生时,Spark 才会创建任务读取 RDD,然后真正触发转换的执行。
Task 在启动之初读取一个分区时,会先判断这个分区是否已经被持久化,如果没有则需要检查 Checkpoint 或按照血统重新计算。所以如果一个 RDD 上要执行多次行动,可以在第一次行动中使用 persist 或 cache 方法,在内存或磁盘中持久化或缓存这个 RDD,从而在后面的行动时提升计算速度。事实上,cache 方法是使用默认的 MEMORY_ONLY 的存储级别将 RDD 持久化到内存,故缓存是一种特殊的持久化。 堆内和堆外存储内存的设计,便可以对缓存 RDD 时使用的内存做统一的规划和管 理 (存储内存的其他应用场景,如缓存 broadcast 数据,暂时不在本文的讨论范围之内)。
RDD 的持久化由 Spark 的 Storage 模块 [7] 负责,实现了 RDD 与物理存储的解耦合。Storage 模块负责管理 Spark 在计算过程中产生的数据,将那些在内存或磁盘、在本地或远程存取数据的功能封装了起来。在具体实现时 Driver 端和 Executor 端的 Storage 模块构成了主从式的架构,即 Driver 端的 BlockManager 为 Master,Executor 端的 BlockManager 为 Slave。Storage 模块在逻辑上以 Block 为基本存储单位,RDD 的每个 Partition 经过处理后唯一对应一个 Block(BlockId 的格式为 rdd_RDD-ID_PARTITION-ID )。Master 负责整个 Spark 应用程序的 Block 的元数据信息的管理和维护,而 Slave 需要将 Block 的更新等状态上报到 Master,同时接收 Master 的命令,例如新增或删除一个 RDD。
图 7 . Storage 模块示意图

在对 RDD 持久化时,Spark 规定了 MEMORY_ONLY、MEMORY_AND_DISK 等 7 种不同的 存储级别 ,而存储级别是以下 5 个变量的组合:
清单 3 . 存储级别
|
1
2
3
4
5
6
7
|
class StorageLevel private(private var _useDisk: Boolean, //磁盘private var _useMemory: Boolean, //这里其实是指堆内内存private var _useOffHeap: Boolean, //堆外内存private var _deserialized: Boolean, //是否为非序列化private var _replication: Int = 1 //副本个数) |
通过对数据结构的分析,可以看出存储级别从三个维度定义了 RDD 的 Partition(同时也就是 Block)的存储方式:
- 存储位置:磁盘/堆内内存/堆外内存。如 MEMORY_AND_DISK 是同时在磁盘和堆内内存上存储,实现了冗余备份。OFF_HEAP 则是只在堆外内存存储,目前选择堆外内存时不能同时存储到其他位置。
- 存储形式:Block 缓存到存储内存后,是否为非序列化的形式。如 MEMORY_ONLY 是非序列化方式存储,OFF_HEAP 是序列化方式存储。
- 副本数量:大于 1 时需要远程冗余备份到其他节点。如 DISK_ONLY_2 需要远程备份 1 个副本。
3.2 RDD 缓存的过程
RDD 在缓存到存储内存之前,Partition 中的数据一般以迭代器(Iterator)的数据结构来访问,这是 Scala 语言中一种遍历数据集合的方法。通过 Iterator 可以获取分区中每一条序列化或者非序列化的数据项(Record),这些 Record 的对象实例在逻辑上占用了 JVM 堆内内存的 other 部分的空间,同一 Partition 的不同 Record 的空间并不连续。
RDD 在缓存到存储内存之后,Partition 被转换成 Block,Record 在堆内或堆外存储内存中占用一块连续的空间。将Partition由不连续的存储空间转换为连续存储空间的过程,Spark称之为"展开"(Unroll)。Block 有序列化和非序列化两种存储格式,具体以哪种方式取决于该 RDD 的存储级别。非序列化的 Block 以一种 DeserializedMemoryEntry 的数据结构定义,用一个数组存储所有的对象实例,序列化的 Block 则以 SerializedMemoryEntry的数据结构定义,用字节缓冲区(ByteBuffer)来存储二进制数据。每个 Executor 的 Storage 模块用一个链式 Map 结构(LinkedHashMap)来管理堆内和堆外存储内存中所有的 Block 对象的实例[6],对这个 LinkedHashMap 新增和删除间接记录了内存的申请和释放。
因为不能保证存储空间可以一次容纳 Iterator 中的所有数据,当前的计算任务在 Unroll 时要向 MemoryManager 申请足够的 Unroll 空间来临时占位,空间不足则 Unroll 失败,空间足够时可以继续进行。对于序列化的 Partition,其所需的 Unroll 空间可以直接累加计算,一次申请。而非序列化的 Partition 则要在遍历 Record 的过程中依次申请,即每读取一条 Record,采样估算其所需的 Unroll 空间并进行申请,空间不足时可以中断,释放已占用的 Unroll 空间。如果最终 Unroll 成功,当前 Partition 所占用的 Unroll 空间被转换为正常的缓存 RDD 的存储空间,如下图 8 所示。
图 8. Spark Unroll 示意图

在图 3 和图 5 中可以看到,在静态内存管理时,Spark 在存储内存中专门划分了一块 Unroll 空间,其大小是固定的,统一内存管理时则没有对 Unroll 空间进行特别区分,当存储空间不足时会根据动态占用机制进行处理。
3.3 淘汰和落盘
由于同一个 Executor 的所有的计算任务共享有限的存储内存空间,当有新的 Block 需要缓存但是剩余空间不足且无法动态占用时,就要对 LinkedHashMap 中的旧 Block 进行淘汰(Eviction),而被淘汰的 Block 如果其存储级别中同时包含存储到磁盘的要求,则要对其进行落盘(Drop),否则直接删除该 Block。
存储内存的淘汰规则为:
- 被淘汰的旧 Block 要与新 Block 的 MemoryMode 相同,即同属于堆外或堆内内存
- 新旧 Block 不能属于同一个 RDD,避免循环淘汰
- 旧 Block 所属 RDD 不能处于被读状态,避免引发一致性问题
- 遍历 LinkedHashMap 中 Block,按照最近最少使用(LRU)的顺序淘汰,直到满足新 Block 所需的空间。其中 LRU 是 LinkedHashMap 的特性。
落盘的流程则比较简单,如果其存储级别符合_useDisk 为 true 的条件,再根据其_deserialized 判断是否是非序列化的形式,若是则对其进行序列化,最后将数据存储到磁盘,在 Storage 模块中更新其信息。
4. 执行内存管理
4.1 多任务间内存分配
Executor 内运行的任务同样共享执行内存,Spark 用一个 HashMap 结构保存了任务到内存耗费的映射。每个任务可占用的执行内存大小的范围为 1/2N ~ 1/N,其中 N 为当前 Executor 内正在运行的任务的个数。每个任务在启动之时,要向 MemoryManager 请求申请最少为 1/2N 的执行内存,如果不能被满足要求则该任务被阻塞,直到有其他任务释放了足够的执行内存,该任务才可以被唤醒。
4.2 Shuffle 的内存占用
执行内存主要用来存储任务在执行 Shuffle 时占用的内存,Shuffle 是按照一定规则对 RDD 数据重新分区的过程,我们来看 Shuffle 的 Write 和 Read 两阶段对执行内存的使用:
- Shuffle Write
- 若在 map 端选择普通的排序方式,会采用 ExternalSorter 进行外排,在内存中存储数据时主要占用堆内执行空间。
- 若在 map 端选择 Tungsten 的排序方式,则采用 ShuffleExternalSorter 直接对以序列化形式存储的数据排序,在内存中存储数据时可以占用堆外或堆内执行空间,取决于用户是否开启了堆外内存以及堆外执行内存是否足够。
- Shuffle Read
- 在对 reduce 端的数据进行聚合时,要将数据交给 Aggregator 处理,在内存中存储数据时占用堆内执行空间。
- 如果需要进行最终结果排序,则要将再次将数据交给 ExternalSorter 处理,占用堆内执行空间。
在 ExternalSorter 和 Aggregator 中,Spark 会使用一种叫 AppendOnlyMap 的哈希表在堆内执行内存中存储数据,但在 Shuffle 过程中所有数据并不能都保存到该哈希表中,当这个哈希表占用的内存会进行周期性地采样估算,当其大到一定程度,无法再从 MemoryManager 申请到新的执行内存时,Spark 就会将其全部内容存储到磁盘文件中,这个过程被称为溢存(Spill),溢存到磁盘的文件最后会被归并(Merge)。
Shuffle Write 阶段中用到的 Tungsten 是 Databricks 公司提出的对 Spark 优化内存和 CPU 使用的计划[9],解决了一些 JVM 在性能上的限制和弊端。Spark 会根据 Shuffle 的情况来自动选择是否采用 Tungsten 排序。Tungsten 采用的页式内存管理机制建立在 MemoryManager 之上,即 Tungsten 对执行内存的使用进行了一步的抽象,这样在 Shuffle 过程中无需关心数据具体存储在堆内还是堆外。每个内存页用一个 MemoryBlock 来定义,并用 Object obj 和 long offset 这两个变量统一标识一个内存页在系统内存中的地址。堆内的 MemoryBlock 是以 long 型数组的形式分配的内存,其 obj 的值为是这个数组的对象引用,offset 是 long 型数组的在 JVM 中的初始偏移地址,两者配合使用可以定位这个数组在堆内的绝对地址;堆外的 MemoryBlock 是直接申请到的内存块,其 obj 为 null,offset 是这个内存块在系统内存中的 64 位绝对地址。Spark 用 MemoryBlock 巧妙地将堆内和堆外内存页统一抽象封装,并用页表(pageTable)管理每个 Task 申请到的内存页。
Tungsten 页式管理下的所有内存用 64 位的逻辑地址表示,由页号和页内偏移量组成:
- 页号:占 13 位,唯一标识一个内存页,Spark 在申请内存页之前要先申请空闲页号。
- 页内偏移量:占 51 位,是在使用内存页存储数据时,数据在页内的偏移地址。
有了统一的寻址方式,Spark 可以用 64 位逻辑地址的指针定位到堆内或堆外的内存,整个 Shuffle Write 排序的过程只需要对指针进行排序,并且无需反序列化,整个过程非常高效,对于内存访问效率和 CPU 使用效率带来了明显的提升[10]。
Spark 的存储内存和执行内存有着截然不同的管理方式:对于存储内存来说,Spark 用一个 LinkedHashMap 来集中管理所有的 Block,Block 由需要缓存的 RDD 的 Partition 转化而成;而对于执行内存,Spark 用 AppendOnlyMap 来存储 Shuffle 过程中的数据,在 Tungsten 排序中甚至抽象成为页式内存管理,开辟了全新的 JVM 内存管理机制。
结束语
Spark 的内存管理是一套复杂的机制,且 Spark 的版本更新比较快,笔者水平有限,难免有叙述不清、错误的地方,若读者有好的建议和更深的理解,还望不吝赐教。
参考资源
- Spark Cluster Mode Overview
- Spark Sort Based Shuffle 内存分析
- Spark OFF_HEAP
- Unified Memory Management in Spark 1.6
- Tuning Spark: Garbage Collection Tuning
- Spark Architecture
- 《Spark 技术内幕:深入解析 Spark 内核架构于实现原理》第 8 章 Storage 模块详解
- Spark Sort Based Shuffle 内存分析
- Project Tungsten: Bringing Apache Spark Closer to Bare Metal
- Spark Tungsten-sort Based Shuffle 分析
- 探索 Spark Tungsten 的秘密
- Spark Task 内存管理(on-heap&off-heap)
以上是关于深入浅出 Spark:内存计算的由来的主要内容,如果未能解决你的问题,请参考以下文章