罗海伟:阿里云万亿级数据集成架构实践
Posted DataFunTalk
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了罗海伟:阿里云万亿级数据集成架构实践相关的知识,希望对你有一定的参考价值。


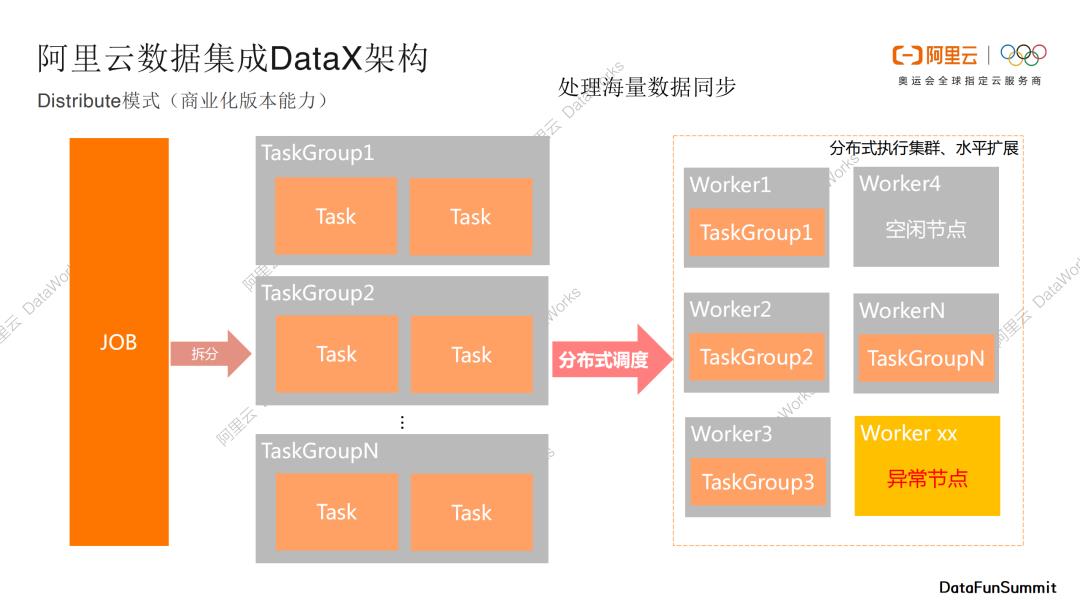
Distribute模式
On Hadoop模式
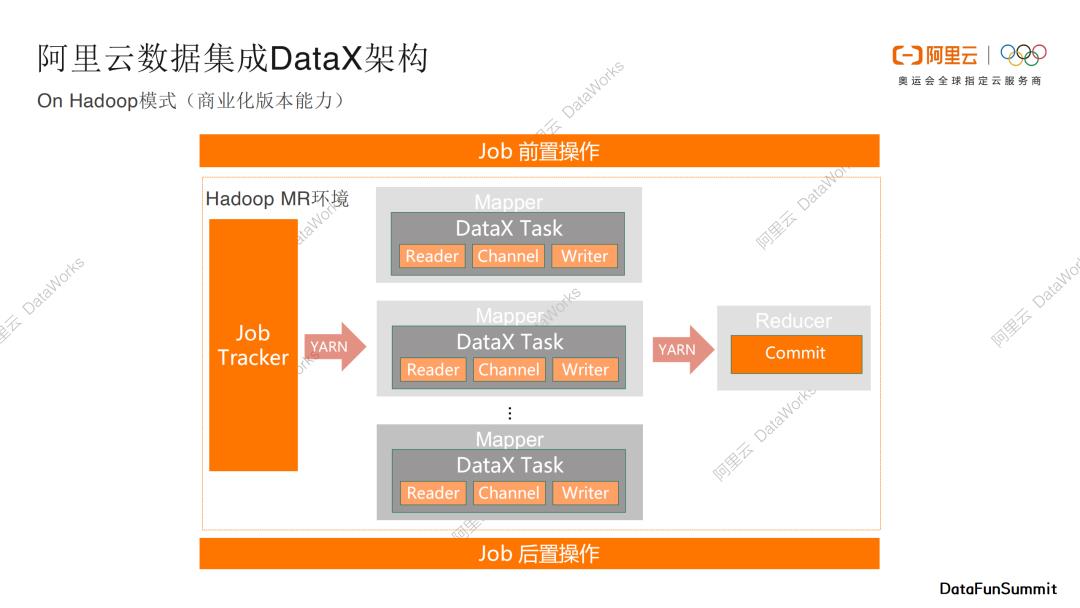
第三个模式是On Hadoop模式,也是商业化版本的一个能力。当用户已经拥有一个Hadoop执行集群,我们可以将DataX数据传输作业部署在已有的Hadoop集群里面,Hadoop中常见的编程模型是MapReduce,我们可以将DataX拆分的task寄宿在mapper节点和reducer节点中,通过Yarn进行统一调度和管理,通过这种方式我们可以复用已有的Hadoop计算和执行能力。这种模式和开源的Sqoop框架是有一点类似的。
2. 实时同步CheckPoint机制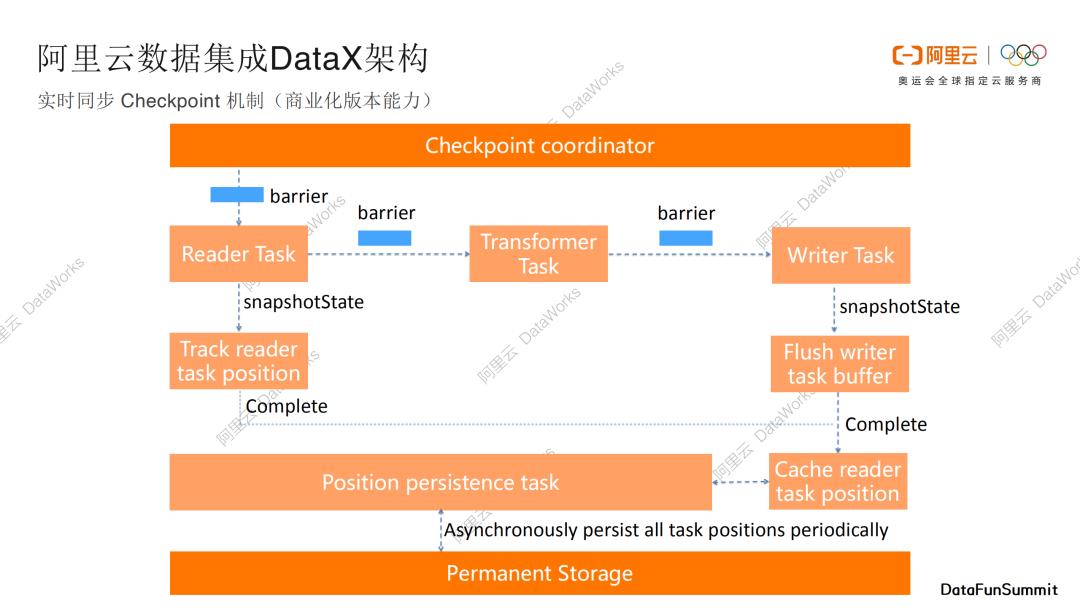
下面介绍阿里云数据集成DataX关于实时同步的checkpoint机制。checkpoint机制可以保证实时数据传输的稳定和断点续传的能力。
如果你对Flink特别了解的话,这张图会非常熟悉。Flink是阿里团队开源出去的另外一个非常重要的实时计算引擎,DataX框架也借助了Flink的checkpoint机制,比如Flink会定期发送一些barrier事件和消息。我们的Reader Task其实是source,收到barrier以后,会产生snapShotState,并且barrier会传递到Transformer Task,Transformer Task可以用来做数据的转换,Transformer Task收到barrier以后,barrier进一步传递到Writer Task,这个时候的Writer Task其实就是sink,收到barrier之后,会再做一次snapShotState,Writer Task会将我们的数据flush到目标储存。我们会跟踪barrier进度情况,并且根据barrier进度情况,把数据流消费的点位cache缓存下来,并且可以进行持久化存储。当任务出现异常或者进程退出的时候,我们可以继续从上一个cache点继续消费数据,可以保证数据不会被丢弃,不过数据可能会有部分的重复,一般后序的计算引擎可以处理这种情况(幂等写出,最终一致)。
1. 阿里云数据集成离线同步-核心亮点
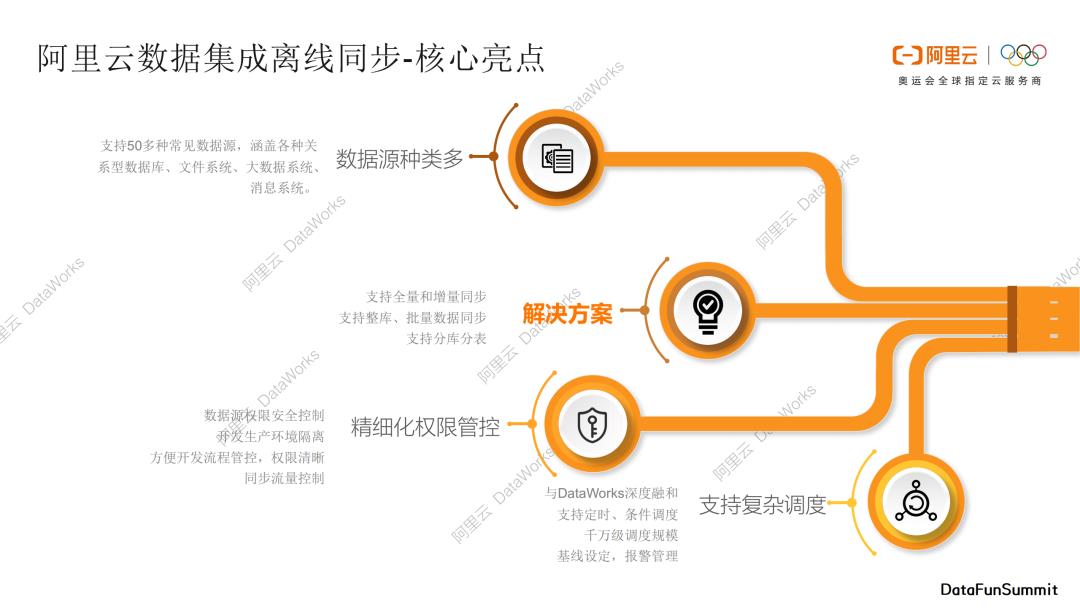
概况一下阿里云数据集成离线同步的核心亮点。主要分为以下四个部分:
第一部分是支持多种类的数据源,DataX支持50+常见数据源,涵盖各种关系型数据库、文件系统、大数据系统、消息系统;
第二部分是解决方案系统,我们为一些数据传输经典问题准备了对应的解决方案,比如支持全量和增量的数据同步,支持整库、批量数据同步、支持分库分表,我们将这些琐碎的功能整合成了产品化的解决方案,直接通过界面操作即可完整复杂的数据传输过程;
第三部分是精细化权限管控能力,可以对数据源权限进行安全控制,并且隔离开发和生产环境;
第四部分DataX支持复杂调度,数据集成与DataWorks深度融合,利用DataWorks强大的调度能力调度我们的数据传输任务。

再概况下阿里云数据集成实时同步的核心亮点。
DataX是借助插件化机制,对新的数据源支持扩展能力强。
DataX支持丰富多样的数据源,支持星型链路组合,任何一种输入源都可以和任何一种输出源搭配组成同步链路。
DataX支持断点续传,可以实时读取mysql、Oracle、SQLSever、OceanBase、Kafka、LogHub、DataHub、PolarDB等的数据,可以将数据实时写入到MaxCompute、Hologres、Datahub、Kafka、ElasticSearch等储存系统。
DataX天然具有云原生基因,和阿里云产品融合度非常高。
DataX可以轻松监控运维告警,提供运维大盘、监控报警、FailOver等运维能力,可以监控业务延迟、Failover、脏数据、心跳检查、失败信息,并且支持邮件、电话、钉钉告警通知。
DataX支持一站式解决方案,支持常见数据源整库全增量到MaxCompute、Hologres、ElasticSearch、DataHub等,同时能够满足分库分表,单表、整库多表、DDL消息等复杂场景。
1. 离线数仓-整库迁移方案
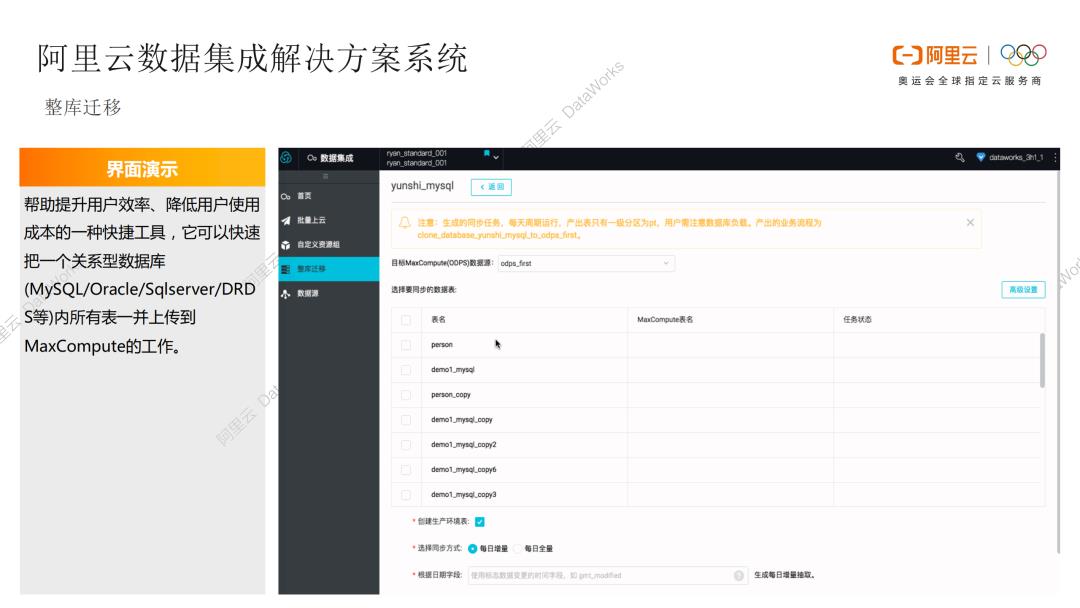
下面将详细介绍一下阿里云数据集成解决方案系统,首先是离线数仓的整库迁移解决方案,我们将数据集成中的一些典型场景,抽象为数据产品解决方案,可以帮助提升用户效率,降低用户使用成本。上图展示出源头数据库中所有的表列表,直接选中需要的表,选择对应的同步方式,比如每日增量或者每日全量,选择分批上传或者整批上传的同步并发配置,就可以上传到MaxCompute中,这种可视化操作可以满足大多离线数据迁移场景。
2. 实时数仓-全增量解决方案
实时数仓的全增量解决方案,可以非常方便的将现有数据库通过简单的配置后,完成存量的全量迁移,以及后续增量的实时同步。支持在目标库中建表、自动建立离线同步任务、自动建立实时任务、自动启动离线任务、自动启动实时任务、自动建立和启动增量和全量的融合任务、全流程的监控和展示,支持子步骤异常重试。通过这种方案,可以让用户不用关注每个全量任务和实时任务的琐碎配置细节。通过这一套解决方案,可以完成整个数据的全量、增量实时数据的同步。

前面介绍了阿里云数据集成开源和商业架构和能力,接下来介绍一下阿里云DataWorks和数据集成的关系。DataWorks是阿里云提供的一站式开发、数据治理的平台,融合了阿里云、阿里集团12年之久的数据中台、数据治理的实践经验。数据集成是阿里云DataWorks核心的一部分,DataWorks向下支持各种不同的计算和存储引擎,比如阿里大数据计算服务MaxCompute、开源大数据计算平台E-MapReduce、实时计算Realtime Compute、图计算引擎GraphCompute、交互式分析引擎MC-Hologres等,以及支持OSS、HDFS、DB等各种存储引擎。这些不同的计算存储引擎可以被阿里云DataWorks统一管理使用,后面可以基于这些引擎去做整个数据仓库。
DataWorks内部划分为7个模块,最下面是数据集成,可以完成各种模式的数据同步。数据集成之上,是元数据中心,提供统一的元数据服务。任务调度中心可以执行任务调度服务,数据开发方面,不同的存储引擎,比如实时计算和离线计算,其有着不同的开发模式,DataWorks支持离线开发和实时开发。同时DataWorks拥有一套综合数据治理的解决方案,会有一个数据服务模块,统一向上提供数据服务,对接各种数据应用。最后将DataWorks各种能力统一通过OpenAPI对外提供服务。
数据集成模块是可以单独对用户提供服务,单独使用的,并不需要了解和掌握所有DataWorks模块就可以将数据同步作业配置和运行起来。

下面介绍一个智能实时数仓解决方案实例,可以应用在电商、游戏、社交等大数据实时场景中。数据源有结构化数据和非结构化数据,非结构化数据可以通过DataHub数据总线做实时数据采集,之后借助数据集成来实时写到Hologres中做交互式分析,也可以将数据实时写入到MaxCompute中,进行归档和离线数据计算,另外Flink也可以消费订阅数据,做实时数据计算。Flink计算结果同时又可以写入Hologres中,也可以将实时计算结果做实时大屏和实时预警。结构化数据也可以通过实时数据抽取或者批量数据采集方式,统一采集到DataWorks,实时数据可以写入到Hologres或者定期归档到MaxCompute,离线数据可以通过批量数据加工到MaxCompute中来,另外MaxCompute和Hologres可以结合使用,进行实时联邦查询。
上面这套解决方案可以将阿里云实时数仓全套链路与离线数据无缝衔接,满足一套存储、两种计算(实时计算和离线计算)的高性价比组合。
今天的分享就到这里,谢谢大家。
在文末分享、点赞、在看,给个3连击呗~
分享嘉宾:

电子书下载

《大数据典藏版合集》电子书目录如上,感兴趣的小伙伴,欢迎识别二维码,添加小助手微信,回复『大数据典藏版合集』,即可下载。

关于我们:
阿里云万亿级数据集成架构实践


Distribute模式
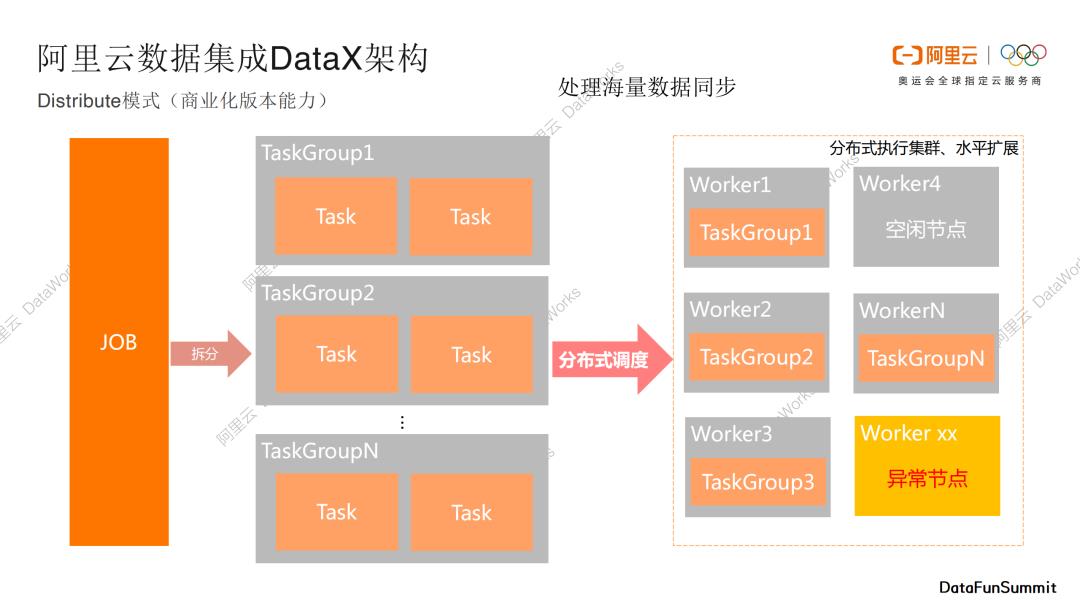
On Hadoop模式
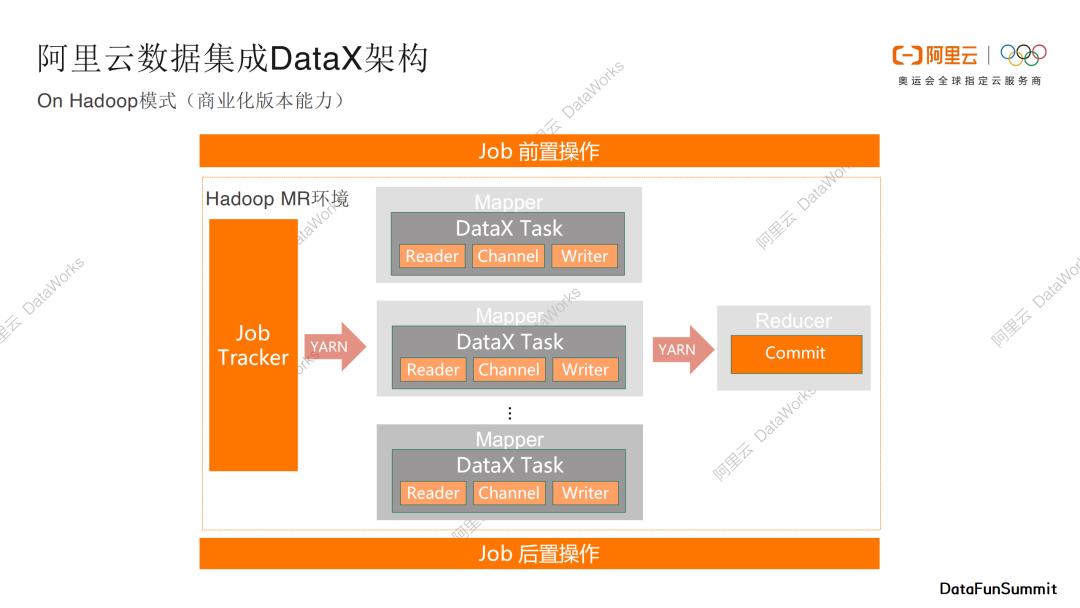
第三个模式是On Hadoop模式,也是商业化版本的一个能力。当用户已经拥有一个Hadoop执行集群,我们可以将DataX数据传输作业部署在已有的Hadoop集群里面,Hadoop中常见的编程模型是MapReduce,我们可以将DataX拆分的task寄宿在mapper节点和reducer节点中,通过Yarn进行统一调度和管理,通过这种方式我们可以复用已有的Hadoop计算和执行能力。这种模式和开源的Sqoop框架是有一点类似的。
2. 实时同步CheckPoint机制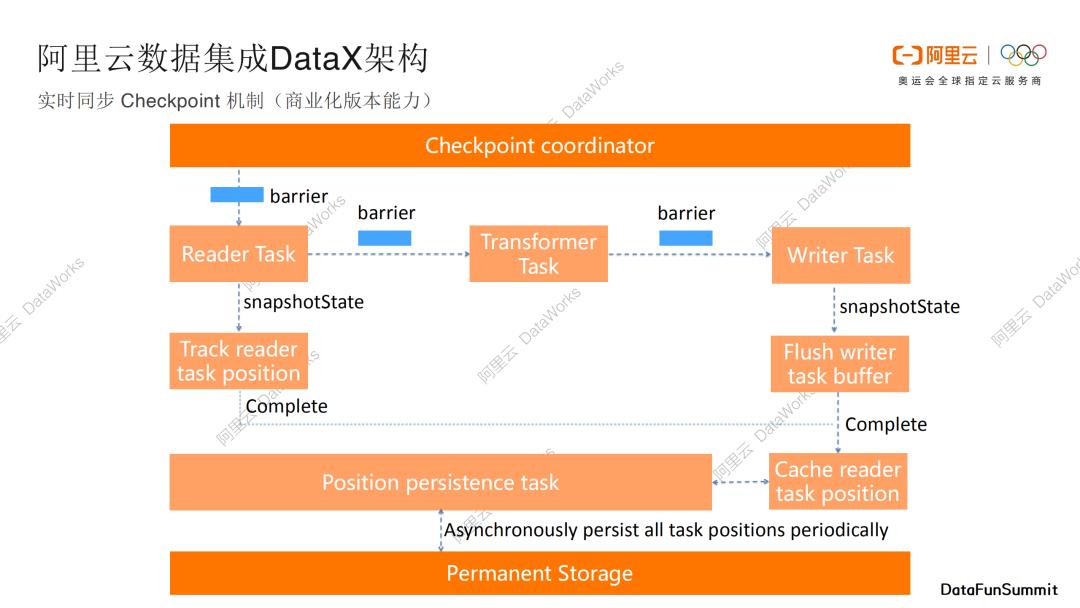
下面介绍阿里云数据集成DataX关于实时同步的checkpoint机制。checkpoint机制可以保证实时数据传输的稳定和断点续传的能力。
如果你对Flink特别了解的话,这张图会非常熟悉。Flink是阿里团队开源出去的另外一个非常重要的实时计算引擎,DataX框架也借助了Flink的checkpoint机制,比如Flink会定期发送一些barrier事件和消息。我们的Reader Task其实是source,收到barrier以后,会产生snapShotState,并且barrier会传递到Transformer Task,Transformer Task可以用来做数据的转换,Transformer Task收到barrier以后,barrier进一步传递到Writer Task,这个时候的Writer Task其实就是sink,收到barrier之后,会再做一次snapShotState,Writer Task会将我们的数据flush到目标储存。我们会跟踪barrier进度情况,并且根据barrier进度情况,把数据流消费的点位cache缓存下来,并且可以进行持久化存储。当任务出现异常或者进程退出的时候,我们可以继续从上一个cache点继续消费数据,可以保证数据不会被丢弃,不过数据可能会有部分的重复,一般后序的计算引擎可以处理这种情况(幂等写出,最终一致)。
1. 阿里云数据集成离线同步-核心亮点
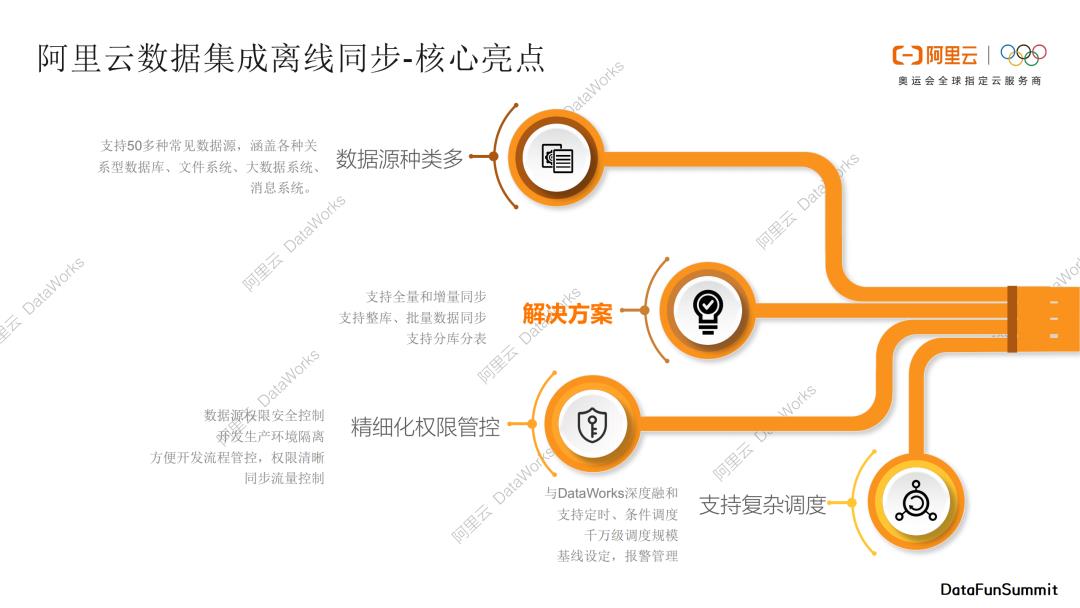
概况一下阿里云数据集成离线同步的核心亮点。主要分为以下四个部分:
第一部分是支持多种类的数据源,DataX支持50+常见数据源,涵盖各种关系型数据库、文件系统、大数据系统、消息系统;
第二部分是解决方案系统,我们为一些数据传输经典问题准备了对应的解决方案,比如支持全量和增量的数据同步,支持整库、批量数据同步、支持分库分表,我们将这些琐碎的功能整合成了产品化的解决方案,直接通过界面操作即可完整复杂的数据传输过程;
第三部分是精细化权限管控能力,可以对数据源权限进行安全控制,并且隔离开发和生产环境;
第四部分DataX支持复杂调度,数据集成与DataWorks深度融合,利用DataWorks强大的调度能力调度我们的数据传输任务。
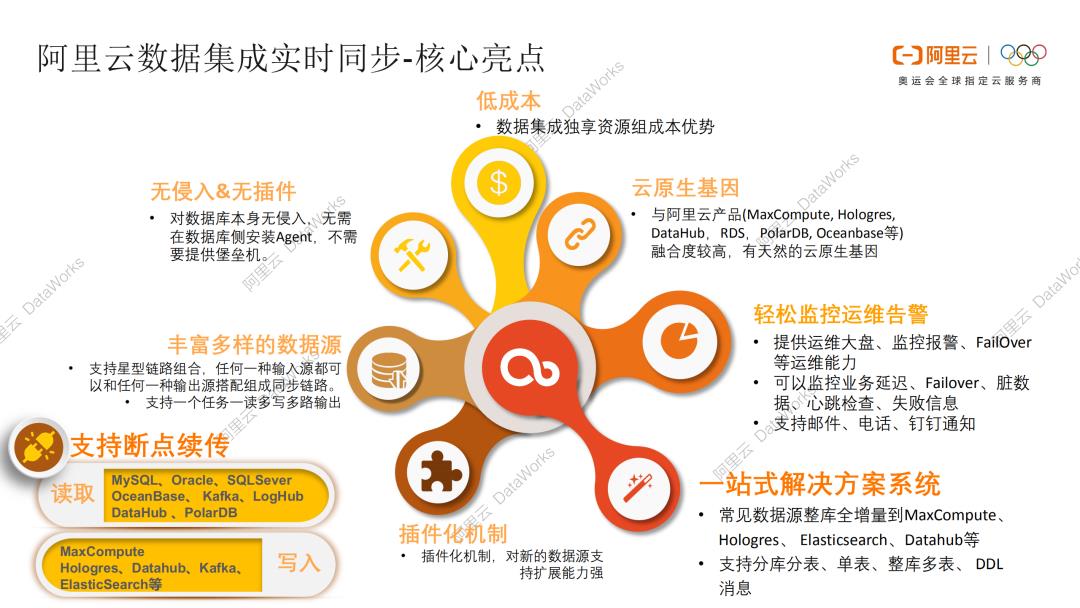
再概况下阿里云数据集成实时同步的核心亮点。
DataX是借助插件化机制,对新的数据源支持扩展能力强。
DataX支持丰富多样的数据源,支持星型链路组合,任何一种输入源都可以和任何一种输出源搭配组成同步链路。
DataX支持断点续传,可以实时读取MySQL、Oracle、SQLSever、OceanBase、Kafka、LogHub、DataHub、PolarDB等的数据,可以将数据实时写入到MaxCompute、Hologres、Datahub、Kafka、ElasticSearch等储存系统。
DataX天然具有云原生基因,和阿里云产品融合度非常高。
DataX可以轻松监控运维告警,提供运维大盘、监控报警、FailOver等运维能力,可以监控业务延迟、Failover、脏数据、心跳检查、失败信息,并且支持邮件、电话、钉钉告警通知。
DataX支持一站式解决方案,支持常见数据源整库全增量到MaxCompute、Hologres、ElasticSearch、DataHub等,同时能够满足分库分表,单表、整库多表、DDL消息等复杂场景。
1. 离线数仓-整库迁移方案
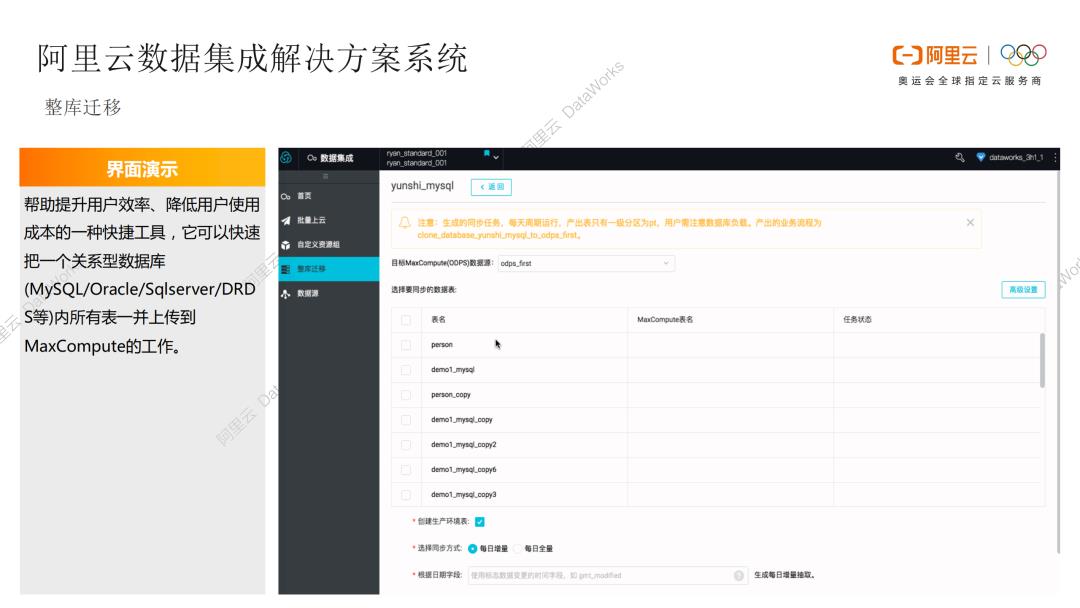
下面将详细介绍一下阿里云数据集成解决方案系统,首先是离线数仓的整库迁移解决方案,我们将数据集成中的一些典型场景,抽象为数据产品解决方案,可以帮助提升用户效率,降低用户使用成本。上图展示出源头数据库中所有的表列表,直接选中需要的表,选择对应的同步方式,比如每日增量或者每日全量,选择分批上传或者整批上传的同步并发配置,就可以上传到MaxCompute中,这种可视化操作可以满足大多离线数据迁移场景。
2. 实时数仓-全增量解决方案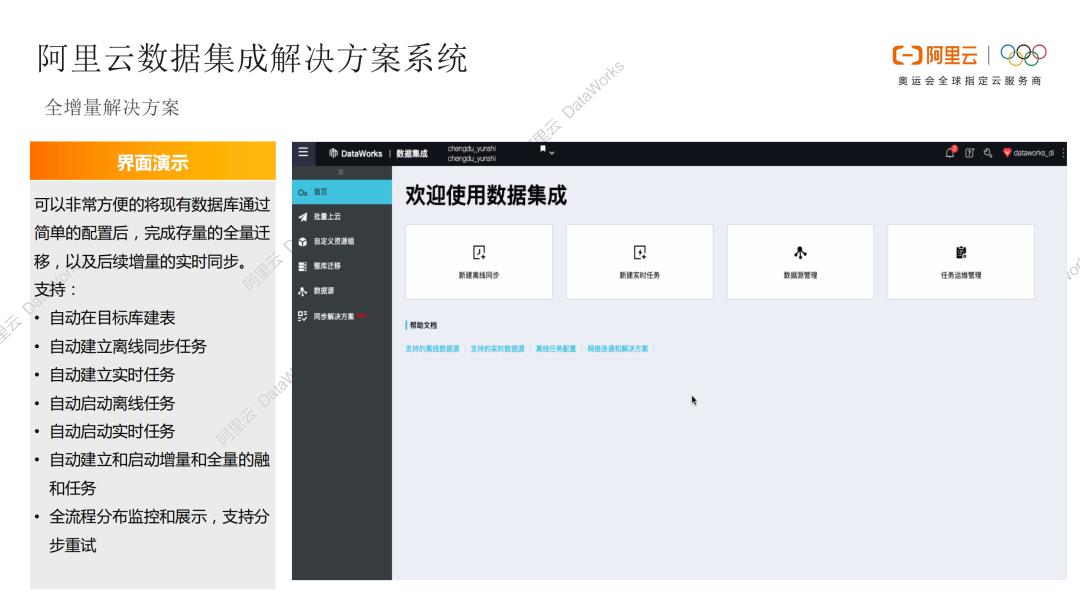
实时数仓的全增量解决方案,可以非常方便的将现有数据库通过简单的配置后,完成存量的全量迁移,以及后续增量的实时同步。支持在目标库中建表、自动建立离线同步任务、自动建立实时任务、自动启动离线任务、自动启动实时任务、自动建立和启动增量和全量的融合任务、全流程的监控和展示,支持子步骤异常重试。通过这种方案,可以让用户不用关注每个全量任务和实时任务的琐碎配置细节。通过这一套解决方案,可以完成整个数据的全量、增量实时数据的同步。

前面介绍了阿里云数据集成开源和商业架构和能力,接下来介绍一下阿里云DataWorks和数据集成的关系。DataWorks是阿里云提供的一站式开发、数据治理的平台,融合了阿里云、阿里集团12年之久的数据中台、数据治理的实践经验。数据集成是阿里云DataWorks核心的一部分,DataWorks向下支持各种不同的计算和存储引擎,比如阿里大数据计算服务MaxCompute、开源大数据计算平台E-MapReduce、实时计算Realtime Compute、图计算引擎GraphCompute、交互式分析引擎MC-Hologres等,以及支持OSS、HDFS、DB等各种存储引擎。这些不同的计算存储引擎可以被阿里云DataWorks统一管理使用,后面可以基于这些引擎去做整个数据仓库。
DataWorks内部划分为7个模块,最下面是数据集成,可以完成各种模式的数据同步。数据集成之上,是元数据中心,提供统一的元数据服务。任务调度中心可以执行任务调度服务,数据开发方面,不同的存储引擎,比如实时计算和离线计算,其有着不同的开发模式,DataWorks支持离线开发和实时开发。同时DataWorks拥有一套综合数据治理的解决方案,会有一个数据服务模块,统一向上提供数据服务,对接各种数据应用。最后将DataWorks各种能力统一通过OpenAPI对外提供服务。
数据集成模块是可以单独对用户提供服务,单独使用的,并不需要了解和掌握所有DataWorks模块就可以将数据同步作业配置和运行起来。
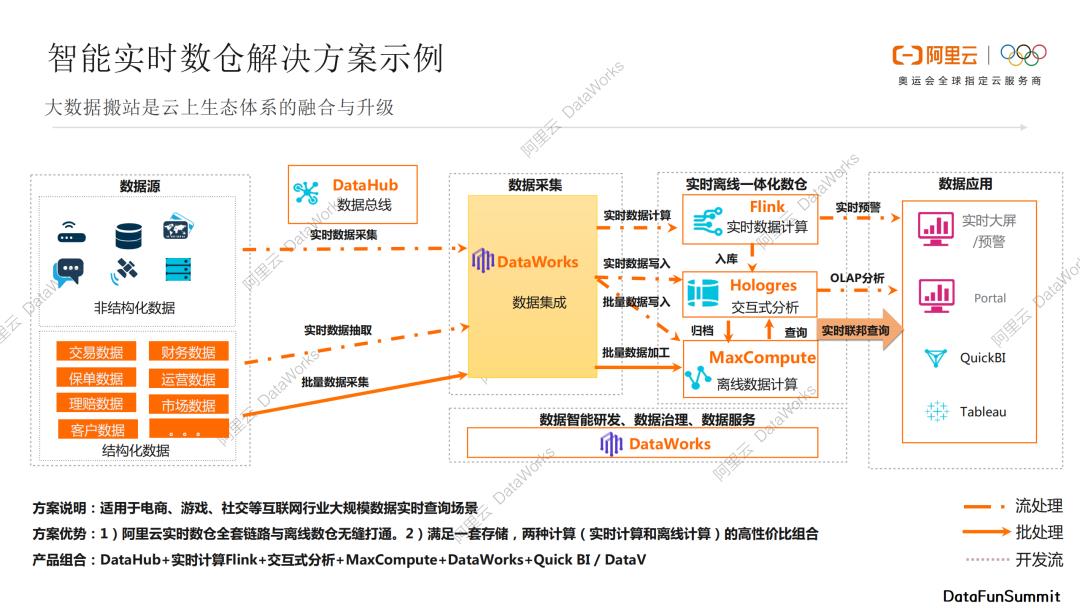
下面介绍一个智能实时数仓解决方案实例,可以应用在电商、游戏、社交等大数据实时场景中。数据源有结构化数据和非结构化数据,非结构化数据可以通过DataHub数据总线做实时数据采集,之后借助数据集成来实时写到Hologres中做交互式分析,也可以将数据实时写入到MaxCompute中,进行归档和离线数据计算,另外Flink也可以消费订阅数据,做实时数据计算。Flink计算结果同时又可以写入Hologres中,也可以将实时计算结果做实时大屏和实时预警。结构化数据也可以通过实时数据抽取或者批量数据采集方式,统一采集到DataWorks,实时数据可以写入到Hologres或者定期归档到MaxCompute,离线数据可以通过批量数据加工到MaxCompute中来,另外MaxCompute和Hologres可以结合使用,进行实时联邦查询。
上面这套解决方案可以将阿里云实时数仓全套链路与离线数据无缝衔接,满足一套存储、两种计算(实时计算和离线计算)的高性价比组合。
今天的分享就到这里,谢谢大家。
在文末分享、点赞、在看,给个3连击呗~
分享嘉宾:

电子书下载

《大数据典藏版合集》电子书目录如上,感兴趣的小伙伴,欢迎识别二维码,添加小助手微信,回复『大数据典藏版合集』,即可下载。

关于我们:
以上是关于罗海伟:阿里云万亿级数据集成架构实践的主要内容,如果未能解决你的问题,请参考以下文章