iOS端循环引用检测实战
Posted 贝壳产品技术
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了iOS端循环引用检测实战相关的知识,希望对你有一定的参考价值。

1. 前言
内存(Memory)是计算机中重要的组件之一,用于暂存CPU中的运算数据、与硬盘等外部存储交换数据。所有的程序都会在内存中运行,而内存的性能直接影响程序的运行效率。应用中最常见的内存问题有:内存泄漏(Memory Leak)、内存溢出(Out Of Memory)和野指针(Wild Pointer)等。本文重点介绍循环引用检测实战。
2. 基础
内存的生命周期大致可以概括为:分配内存 -> 使用内存 -> 释放内存。而内存泄露 (Memory Leak)是程序中动态分配的堆内存由于某种原因未释放或者无法释放。这会造成内存资源的浪费、程序运行变慢甚至系统崩溃等严重后果。
ios开发中,常见的内存泄漏有:C&C++分配的内存部分未释放、对象之间循环引用造成不能释放,典型例子如Block、NSTimer与self之间的相互引用。前者是没有引用的内存,内存活动图中是不可达的,后者是引用仍存在,但是不会再使用的内存。
目前,常见的泄露检测工具有:Analyze静态检测、 Instrusment的Leak动态检测、Instrusment的Allocation、Memory Graph以及第三方工具MLeaksFinder、FBRetainCycleDetector。
ARC引入之后,循环引用成为了内存泄漏产生的主要原因。本文将重点介绍循环引用的检测工具和典型实践。
3. 原理
3.1 概述
业内比较通用的检测工具是MLeaksFinder。它是WeRead团队设计的一款开源的iOS内存泄漏检测框架,框架使用十分简单,只需要将文件引入,运行项目,如果存在内存泄漏,利用FBRetainCycleDetector检测出循环引用环,并弹窗展示,如下:
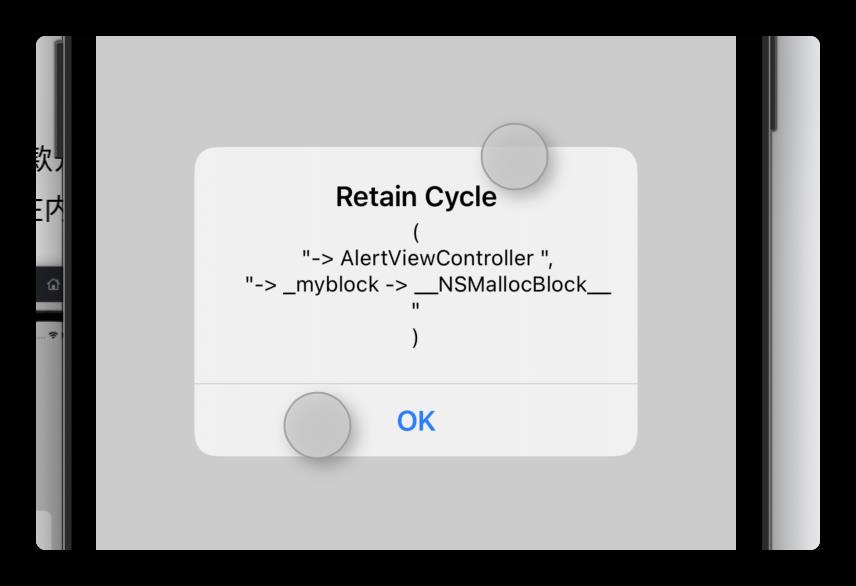
3.2 发现泄露
MLeaksFinder为NSObject类增加一个willDealloc方法,当我们认为某个对象应该释放的时候,建立一个弱指针,在2秒后,使用这个弱指针调用断言方法。如果这个对象被释放,nil向方法发消息不会有任何反应,否则会执行中断言方法,进而会执行其他操作获取内存泄漏相关信息并以弹窗的形式告知用户。

MLeaksFinder从UIViewController入手,通常一个UIViewController被pop或者dismiss之后,该UIViewController的view和view的subview都会很快被释放,所以只需要在ViewController被pop之后一小段时间后,查看其view、subview是否还存在就可以判断是否存在内存泄漏。MLeaksFinder首先会对白名单进行一个过滤,然后,执行target-action的时候,目标对象不检测内存泄漏,最后等待一小段时间后,使用弱指针调用中断言方法,如果弱指针不为空,中断言方法生效,中断生效,提示内存泄漏,否则此处不存在内存泄漏。
3.3 泄露误判
MLeaksFinder的泄露检测存在一些False Positive,主要有两类:
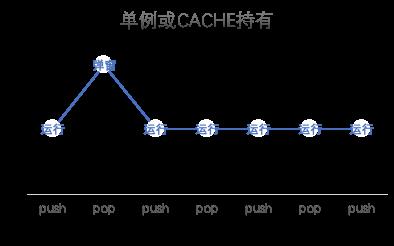
3.3.1 对象被设计为单例或者cache起来复用
单例模式和cache起来的对象,在pop和dismiss之后是不会被释放的,根据MLeaksFinder原理我们可以推断,此处会提示内存泄漏。但是此处是开发者由于性能等原因不得不这样设计的,我们不能把它当做一个内存泄漏的点去处理它。这种情况我们多次点击,只会产生一次弹窗提示。遇到这种情况,我们可以判断此处是单例模式或者cache。
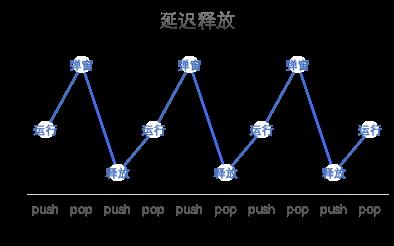
3.3.2 释放不及时
在异步执行代码中,可能会产生block内部代码没有及时释放的情况,在pop后也会提示内存泄漏,但紧接着也会提示Object Deallocated。
对应解决办法:在相应的类中重写willDealloc方法,直接返回NO即可消除这种误判。
3.4 发现引用环
FBRetainCycleDetector以待检测对象为根结点,遍历节点的强引用对象,同时根据配置进行过滤,返回强引用对象并将其保存到候选集里面。最后执行找环操作,对候选集中的对象依次执行深度优先搜索(DFS),如果找到环,将环数据合并到结果集中,最后得到所有的环。循环引用的检测问题被简化为有向图的环检测问题,而其中关键的是:获取普通OC对象、Block、NSTimer等场景下的强引用对象。

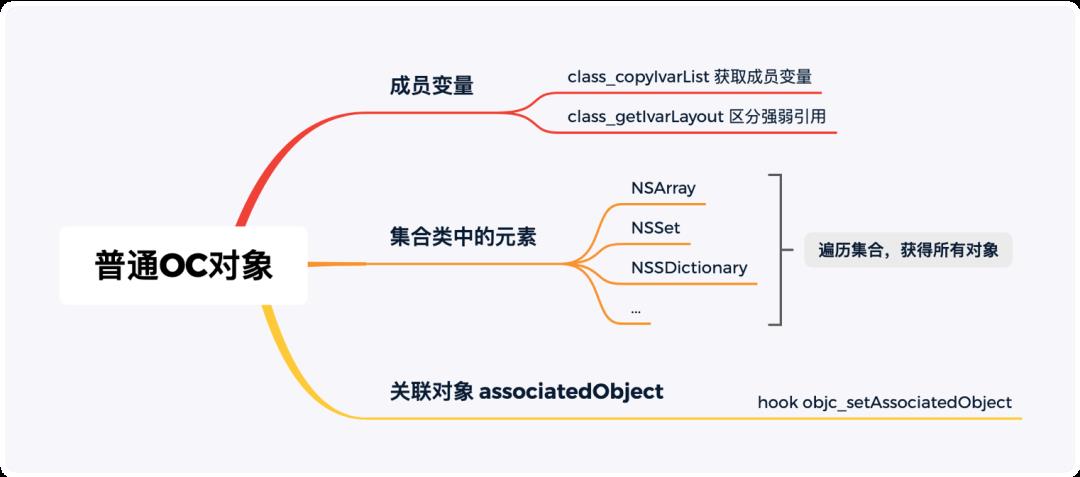
3.4.1 寻找普通OC对象的引用对象
普通OC对象通过ivar(成员变量)、集合类中的元素,比如 NSArray、NSDictionary 中的元素、associatedObject(关联对象)等方式引用(强引用、弱引用)其他对象。对于ivar(成员变量),可以利用class_copyIvarList拿到 ivar 列表,遍历所有的 ivar ,利用class_getIvarLayout识别出强引用的ivar集合。对于集合类中的元素,可以直接遍历其元素就能够获取所有其强引用的所有对象,需要注意对可以自定义对元素的引用类型的集合类处理。对于associatedObject(关联对象)等,可以hook objc_setAssociatedObject将运行时添加的强引用对象记录下来。
3.4.2 寻找Block引用对象
Block本质是封装函数调用以及函数调用上下文环境的OC对象,有三类:__NSGlobalBlock、__NSMallocBlock 和 __NSStackBlock,其底层实现是结构体。可以利用Block结构里的dispose_helper(析构)函数获得强引用对象。
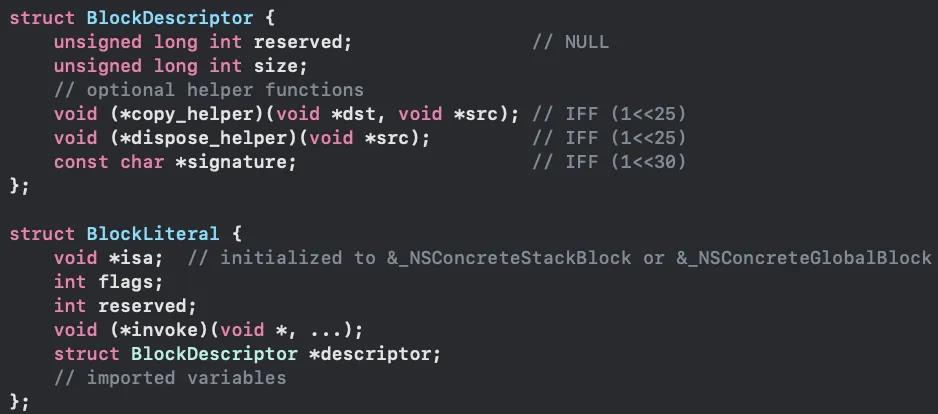
如果不存在析构函数,就意味着函数没有强引用对象,否则,可以取得析构函数dispose_helper,然后计算出Block所占的内存能存储多少个指针大小数据块,并建立两个相同大小的数组 obj 和 detectors 作为一个“假的block”,并在两个数组中存储BlockStrongRelationDetector对象,然后对数组执行目标block的析构函数dispose_helper,BlockStrongRelationDetector中重写release方法,执行release时会将对象中的_strong标记为 YES,真正的销毁是在 trueRelease 方法中完成的。
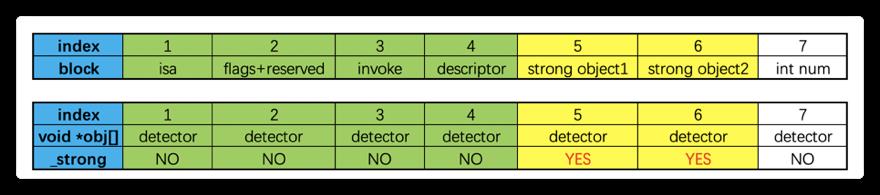
利用dispose_helper找到强引用对象原理如下图:人工创建的一个假的block(上半部分),内存结构与Block类似,下半部分是一个真实的Block。其中绿色部分是Block本身的内存结构,黄色部分是Block捕获的外部变量,析构函数释放的时候会对5,6执行release, 7是基础数据类型并不会执行。所以当对假的Block执行Block的析构函数时, 也会对5,6部分执行release方法,此处detector对象的release方法已经被重写,所以当析构函数执行之后,obj中5,6的_strong参数变为YES,只需要遍历obj数组,就能获得block对象的强引用对象的位置。
3.4.3 寻找Timer引用对象
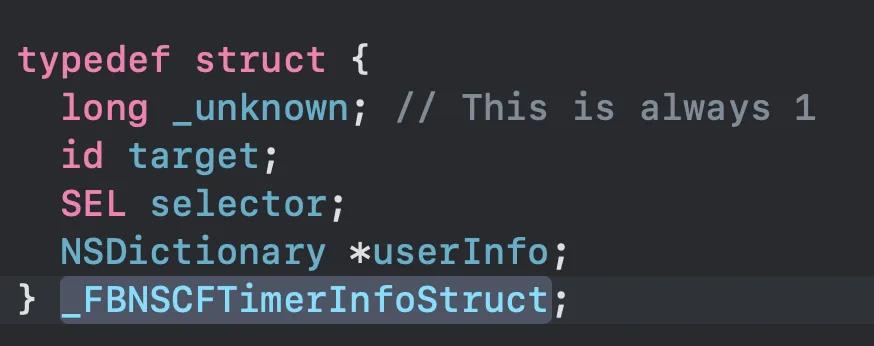
NSTimer对象的所有强引用对象,除了继承父类 NSObject的所有强引用对象之外,还包括 target 和 userInfo 对象。因此,利用CFRunLoopTimerGetContext获得NSTimer对应的CFRunLoopTimerContext结构体,其中,CFRunLoopTimerContext中的info字段可以强制转成_FBNSCFTimerInfoStruct, 通过他拿到target、userInfo信息,即强引用对象。

3.5 典型场景
实际项目中,循环引用中大部分是Block使用不当造成的,而常用解决Block循环引用的方式是weak-strong-dance,但是依旧存在weakify&strongify使用不当、Block嵌套处理不当造成的循环引用问题。
3.5.1 RAC的@weakify&@strongify
我们常用RAC的@weakify&@strongify,源码如下:
#define weakify(...) \\
rac_keywordify \\
metamacro_foreach_cxt(rac_weakify_,, __weak, __VA_ARGS__)
#define strongify(...) \\
rac_keywordify \\
_Pragma("clang diagnostic push") \\
_Pragma("clang diagnostic ignored \\"-Wshadow\\"") \\
metamacro_foreach(rac_strongify_,, __VA_ARGS__) \\
_Pragma("clang diagnostic pop")
//@
#if DEBUG
#define rac_keywordify autoreleasepool
#else
#define rac_keywordify try @catch (...)
#endif
#define rac_weakify_(INDEX, CONTEXT, VAR) \\
CONTEXT __typeof__(VAR) metamacro_concat(VAR, _weak_) = (VAR);
//上述代码等价于
__weak __typeof__(self) self_weak_ = self;
#define rac_strongify_(INDEX, VAR) \\
__strong __typeof__(VAR) VAR = metamacro_concat(VAR, _weak_);
//上述代码等价于
__strong __typeof__(self) self = self_weak_;
debug和release环境下的rac_keywordify,分别对应自动释放池、try/catch。实现了"@"的效果。metamacro_foreach_cxt方法将weakify提供的参数进行了weak处理。在strongify定义中增加了三行_Pragma代码,意为忽略当一个局部变量或类型声明遮盖另一个变量的警告。其中metamacro_foreach方法主要对参数进行了strong处理。
解决Block循环引用,@weakify和@strongify必须成对使用,这是因为:使用@weakify(self)之后,会定义一个 __weak 类型的 weak_self 变量,而@strongify(self) 定义了一个 __strong 类型的self指向了weak_self。如图一所示,当只使用@weakify时,Xcode会提示存在一个没有使用过的变量 weak_self ,此时如果不使用@strongify(self),block内部的self 则还是self,相当于@weakify没起作用;如果只使用@strongify(self),就会产生图二所示情况,警告没有定义变量 weak_self ,可见,@strongify是对weak_self 的一个强引用,使用@strongify(self)之后, block内部的self 就不再和外部的self相同。

图一.单独使用@weakify
 图二. 单独使用@strongify
图二. 单独使用@strongify
在贝壳App循环引用检测实践中,遇到过类似问题,因@weakify和@strongify未成对使用造成内存泄漏。因此,在开发过程中必须保证@weakify和@strongify 成对出现。当然也有例外,如block块的嵌套使用场景。
3.5.2 Block嵌套问题
开发中,我们需要处理block嵌套的情况,否则依然会有循环引用。一般解决方法是:在外层block上使用@weakify和@strongify,内部的block使用@strongify。代码如下:
@weakify(self)
self.block1 = ^BOOL
@strongify(self)
self.block2 = ^BOOL
@strongify(self)
NSLog(@"hello %@ ",self);
;
;
在block2中,如果不存在第5行代码,此时self持有block2,block2持有self,形成了一个循环引用,在调用self.block1()时就会产生内存泄漏。而代码中,strongify宏定义会去捕捉一个weak_self变量,而这个变量在block1外部已经定义了,所以可以直接单独在block2内部使用strongify。
4. 实战
4.1 定位问题
实际开发中,遇到页面释放,但内存依然泄露的情况。一种是页面内的子元素因为循环引用问题而导致泄露;另一种是子元素因被单例持有而泄露。前者能很快定位到引用环,而后者却是"发现循环引用失败"。示意如下:
4.1.1 子元素循环引用
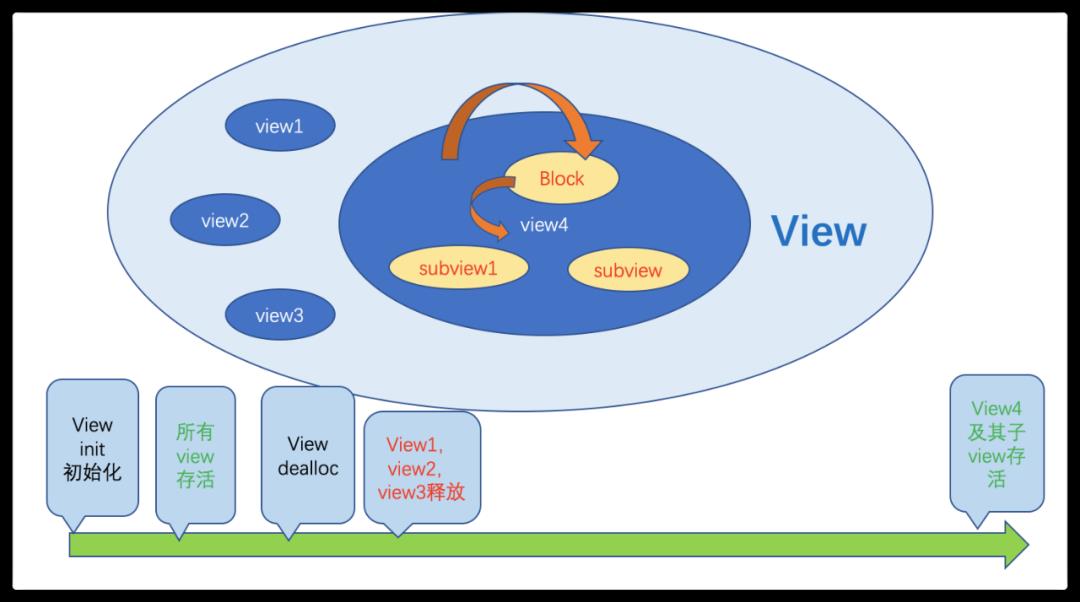
如图所示,父View强引用子View们,当父View被释放时,其持有的view1~view3都将被释放,但是view4由于其内部与block形成了循环引用(如图),产生了内存泄漏。
4.1.2 子元素被单例持有
如图所示,父View 中持有了三个子view,其中view3被单例对象Obj持有。而单例对象是在程序结束时才会释放。当父View释放后,view1,view2响应释放,而view3因为被单例持有,不能释放,进而造成了内存泄漏。
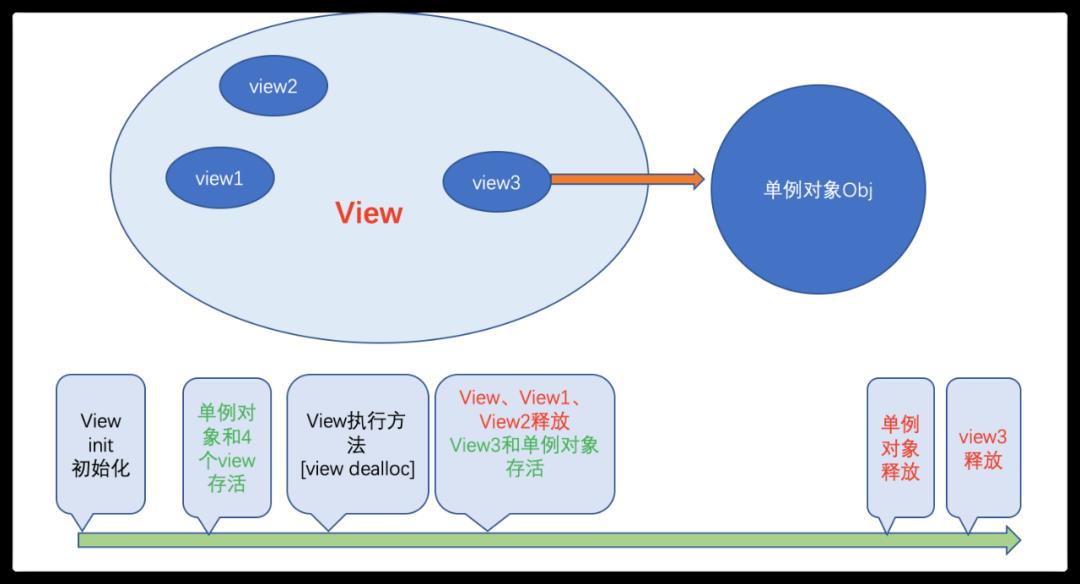
上述两类情况都比较容易被忽视,这会导致页面退出后,内存不怎么下降。这是因为:子元素持有图片或大内存对象。在页面多次访问后,内存消耗加剧,甚至最终导致OOM(低端机易复现)。
4.2 完善检测
我们知道MLeaksFinder会对页面的子元素,如View及其View的SubViews进行泄露检测,因此子元素的循环引用问题,是很方便被检测的。但是如果是全局对象持有的话,一般不存在泄漏对象对全局对象的引用,存在的是全局对象对泄漏对象引用,并没有引用环,因此需要做原有检测进一步优化。采用的方案是:发现泄露对象,正常引用检测失效后,检查是否被全局对象持有。
遍历主二进制的Mach-O文件中的__DATA segment __bss section的所有指针,利用对象符号化,找到所有全局OC对象。然后给泄漏对象 添加上对全局对象的引用 后,如果全局对象也引用了泄漏对象,那自然就出现循环引用了。检测结束后,将泄漏对象关联的全局对象移除之,恢复上下文。示意如下:
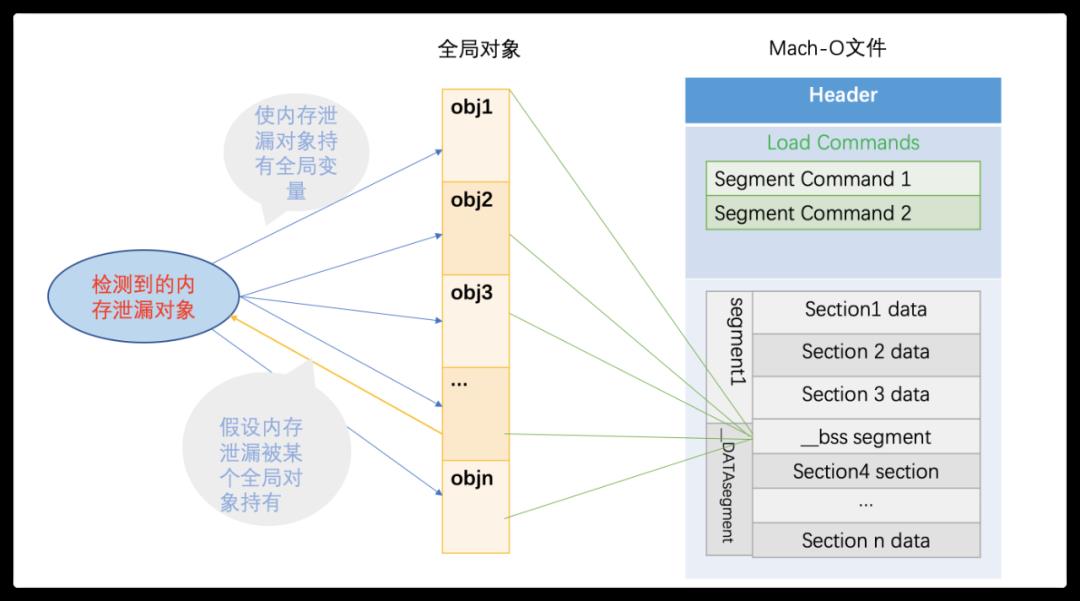
如上图所示,黄色线是假设存在的,某一个全局变量对内存泄漏对象的强引用关系,蓝色线是人为加上的内存泄漏对象对全局变量对象的强引用。这样一来,就产生了一个环,objx和内存泄漏对象之间互相引用,此时再使用MLeaksFinder工具进行检测,如果存在环,那么假设成立,存在一个全局变量对象强引用了内存泄漏对象。
4.3 线下防劣化
内存泄露问题容易被忽视,常见于大家默认不开启泄露检测。一方面在于弹窗提醒干扰比较大、发现泄露的非自己所属业务,推动解决繁琐。另一方面是在于自信,不会犯内存泄露这样的低级错误。但是从全局来看,开发和测试过程中,使用内存泄露检测是非常必要的。综合研发“不被打扰” 和 “内存泄露应该及早发现”的需求,提供内存泄露静默提醒,默认不出弹窗,将问题通过机器人发送对应的研发群中。同时在后台记录本版本遇到的所有内存泄露及其解决状态。

将内存泄露问题控制在线下,避免问题带入线上,保障App的稳定性。
5. 总结
本文介绍了iOS循环引用检测的原理和实战。经过阶段性治理,因循环引用导致的内存泄露问题基本解决,内存OOM率也降低了20%+,App的稳定性得到了提升。然而,治理循环引用并非一劳永逸,需要我们在解决和防劣化方面继续探索、实践。

iOS之深入解析如何检测“循环引用”
一、前言
- Objective-C 使用引用计数作为 iPhone 应用的内存管理方案,引用计数相比 GC 更适用于内存不太充裕的场景,只需要收集与对象关联的局部信息来决定是否回收对象,而 GC 为了明确可达性,需要全局的对象信息。引用计数固然有其优越性,但也正是因为缺乏对全局对象信息的把控,导致 Objective-C 无法自动销毁陷入循环引用的对象。虽然 Objective-C 通过引入弱引用技术,让开发者可以尽可能地规避这个问题,但在引用层级过深,引用路径不那么直观的情况下,即使是经验丰富的工程师,也无法百分百保证产出的代码不存在循环引用。
- 这时候就需要有一种检测方案,可以实时检测对象之间是否发生了循环引用,来辅助开发者及时地修正代码中存在的内存泄漏问题。要想检测出循环引用,最直观的方式是递归地获取对象强引用的其他对象,并判断检测对象是否被其路径上的对象强引用了,也就是在有向图中去找环。明确检测方式之后,接下来需要解决的是如何获取强引用链,也就是获取对象的强引用,尤其是最容易造成循环引用的 block。
二、Block 捕获实体引用
① 捕获区域布局
- 根据 block 的定义结构,可以简单地将其视为:
struct sr_block_layout
void *isa;
int flags;
int reserved;
void (*invoke)(void *, ...);
struct sr_block_descriptor *descriptor;
/* Imported variables. */
;
// 标志位不一样,这个结构的实际布局也会有差别,这里简单地放在一起好阅读
struct sr_block_descriptor
unsigned long reserved; // Block_descriptor_1
unsigned long size; // Block_descriptor_1
void (*)(void *dst, void *src); // Block_descriptor_2 BLOCK_HAS_COPY_DISPOSE
void (*dispose)(void *); // Block_descriptor_2
const char *signature; // Block_descriptor_3 BLOCK_HAS_SIGNATURE
const char *layout; // Block_descriptor_3 contents depend on BLOCK_HAS_EXTENDED_LAYOUT
;
- 可以看到 block 捕获的变量都会存储在 sr_block_layout 结构体 descriptor 字段之后的内存空间中,通过 clang -rewrite-objc 重写如下代码语句:
int i = 2;
^
i;
;
- 可以得到 :
struct __block_impl
void *isa;
int Flags;
int Reserved;
void *FuncPtr;
;
struct __main_block_impl_0
struct __block_impl impl;
struct __main_block_desc_0* Desc;
int i;
...
;
- __main_block_impl_0 结构中新增了捕获的 i 字段,即 sr_block_layout 结构体的 imported variables 部分,这种操作可以看作在 sr_block_layout 尾部定义了一个 0 长数组,可以根据实际捕获变量的大小,给捕获区域申请对应的内存空间,只不过这一操作由编译器完成:
struct sr_block_layout
void *isa;
int flags;
int reserved;
void (*invoke)(void *, ...);
struct sr_block_descriptor *descriptor;
char captured[0];
;
- 既然已经知道捕获变量 i 的存放地址,那么就可以通过 *(int *)layout->captured 在运行时获取 i 的值,得到捕获区域的起始地址之后,再来看捕获区域的布局问题,考虑以下代码块:
int i = 2;
NSObject *o = [NSObject new];
void (^blk)(void) = ^
i;
o;
;
- 捕获区域的布局分两部分看:顺序和大小,先使用老方法重写代码块:
struct __main_block_impl_0
struct __block_impl impl; // 24
struct __main_block_desc_0* Desc; // 8 指针占用内存大小和寻址长度相关,在 64 位机环境下,编译器分配空间大小为 8 字节
int i; // 8
NSObject *o; // 8
...
;
- 按照目前 clang 针对 64 位机的默认对齐方式(下文的字节对齐计算都基于此前提条件),可以计算出这个结构体占用的内存空间大小为 24 + 8 + 8 + 8 = 48字节,并且按照上方代码块先 i 后 o 的捕获排序方式,如果要访问捕获的 o 对象指针变量,只需要在捕获区域起始地址上偏移 8 字节即可,可以借助 lldb 的 memory read (x) 命令查看这部分内存空间:
(lldb) po *(NSObject **)(layout->captured + 8)
0x0000000000000002
(lldb) po *(NSObject **)layout->captured
<NSObject: 0x10073f290>
(lldb) p *(int *)(layout->captured + 8)
(int) $6 = 2
(lldb) p (int *)(layout->captured + 8)
(int *) $9 = 0x0000000100740d18
(lldb) p layout->descriptor->size
(unsigned long) $11 = 44
(lldb) x/44bx layout
0x100740cf0: 0x70 0x21 0x7b 0xa6 0xff 0x7f 0x00 0x00
0x100740cf8: 0x02 0x00 0x00 0xc3 0x00 0x00 0x00 0x00
0x100740d00: 0x40 0x1d 0x00 0x00 0x01 0x00 0x00 0x00
0x100740d08: 0xb0 0x20 0x00 0x00 0x01 0x00 0x00 0x00
0x100740d10: 0x90 0xf2 0x73 0x00 0x01 0x00 0x00 0x00
0x100740d18: 0x02 0x00 0x00 0x00
- 和使用 clang -rewrite-objc 重写时的猜想不一样,可以从以上终端日志中看出以下两点:
-
- 捕获变量 i、o 在捕获区域的排序方式为 o、i,o 变量地址与捕获起始地址一致,i 变量地址为捕获起始地址加上 8 字节;
-
- 捕获整形变量 i 在内存中实际占用空间大小为 4 字节;
- 那么 block 到底是怎么对捕获变量进行排序,并且为其分配内存空间的呢?这就需要看 clang 是如何处理 block 捕获的外部变量。
② 捕获区域布局分析
- 首先解决捕获变量排序的问题,根据 clang 针对这部分的排序代码,可以知道,在对齐字节数 (alignment) 不相等时,捕获的实体按照 alignment 降序排序 (C 结构体比较特殊,即使整体占用空间比指针变量大,也排在对象指针后面),否则按照以下类型进行排序:
-
- __strong 修饰对象指针变量;
-
- __block 修饰对象指针变量;
-
- __weak 修饰对象指针变量;
-
- 其他变量;
- 再结合 clang 对捕获变量对齐子节数计算方式 ,可以知道,block 捕获区域变量的对齐结果趋向于被 attribute ((packed)) 修饰的结构体,举个例子:
struct foo
void *p; // 8
int i; // 4
char c; // 4 实际用到的内存大小为 1
;
- 创建 foo 结构体需要分配的空间大小为 8 + 4 + 4 = 16,关于结构体的内存对齐方式,编译器会按照成员列表的顺序一个接一个地给每个成员分配内存,只有当存储成员需要满足正确的边界对齐要求时,成员之间才可能出现用于填充的额外内存空间,以提升计算机的访问速度(对齐标准一般和寻址长度一致),在声明结构体时,让那些对齐边界要求最严格的成员最先出现,对边界要求最弱的成员最后出现,可以最大限度地减少因边界对齐而带来的空间损失。再看以下代码块:
struct foo
void *p; // 8
int i; // 4
char c; // 1
__attribute__ ((__packed__));
- attribute ((packed)) 编译属性会告诉编译器,按照字段的实际占用子节数进行对齐,所以创建 foo 结构体需要分配的空间大小为 8 + 4 + 1 = 13。
- 结合以上两点,可以尝试分析以下 block 捕获区域的变量布局情况:
NSObject *o1 = [NSObject new];
__weak NSObject *o2 = o1;
__block NSObject *o3 = o1;
unsigned long long j = 4;
int i = 3;
char c = 'a';
void (^blk)(void) = ^
i;
c;
o1;
o2;
o3;
j;
;
- 按照 aligment 排序,可以得到排序顺序为 [o1 o2 o3] j i c,再根据 __strong、__block、__weak 修饰符对 o1 o2 o3 进行排序,可得到最终结果 o1[8] o3[8] o2[8] j[8] i[4] c[1]。同样的,我们使用 lldb 的 x 命令验证分析结果是否正确:
(lldb) x/69bx layout
0x10200d940: 0x70 0x21 0x7b 0xa6 0xff 0x7f 0x00 0x00
0x10200d948: 0x02 0x00 0x00 0xc3 0x00 0x00 0x00 0x00
0x10200d950: 0xf0 0x1b 0x00 0x00 0x01 0x00 0x00 0x00
0x10200d958: 0xf8 0x20 0x00 0x00 0x01 0x00 0x00 0x00
0x10200d960: 0xa0 0xf6 0x00 0x02 0x01 0x00 0x00 0x00 // o1
0x10200d968: 0x90 0xd9 0x00 0x02 0x01 0x00 0x00 0x00 // o3
0x10200d970: 0xa0 0xf6 0x00 0x02 0x01 0x00 0x00 0x00 // o2
0x10200d978: 0x04 0x00 0x00 0x00 0x00 0x00 0x00 0x00 // j
0x10200d980: 0x03 0x00 0x00 0x00 0x61 // i c
(lldb) p o1
(NSObject *) $1 = 0x000000010200f6a0
- 可以看到,小端模式下,捕获的 o1 和 o2 指针变量值为 0x10200f6a0,对应内存地址为 0x10200d960 和 0x10200d970,而 o3 因为被 __block 修饰,编译器为 o3 捕获变量包装了一层 byref 结构,所以其值为 byref 结构的地址 0x102000d990,而不是 0x10200f6a0,捕获的 j 变量地址为 0x10200d978,i 变量地址为 0x10200d980,c 字符变量紧随其后。
③ Descriptor 的 Layout 信息
- 经过上述的一系列分析,捕获区域变量的布局方式已经大致清楚,接下来回过头看下 sr_block_descriptor 结构的 layout 字段是用来干什么的?从字面上理解,这个字段很可能保存了 block 某一部分的内存布局信息,比如捕获区域的布局信息,依然使用上文的最后一个例子,看看 layout 的值:
(lldb) p layout->descriptor->layout
(const char *) $2 = 0x0000000000000111 ""
- 可以看到 layout 值为空字符串,并没有展示出任何直观的布局信息,看来要想知道 layout 是怎么运作的,可以阅读 block 代码 和 clang 代码,继续一步步地分析这两段代码里面隐藏的信息,这里贴出其中的部分代码和注释:
// block
// Extended layout encoding.
// Values for Block_descriptor_3->layout with BLOCK_HAS_EXTENDED_LAYOUT
// and for Block_byref_3->layout with BLOCK_BYREF_LAYOUT_EXTENDED
// If the layout field is less than 0x1000, then it is a compact encoding
// of the form 0xXYZ: X strong pointers, then Y byref pointers,
// then Z weak pointers.
// If the layout field is 0x1000 or greater, it points to a
// string of layout bytes. Each byte is of the form 0xPN.
// Operator P is from the list below. Value N is a parameter for the operator.
enum
...
BLOCK_LAYOUT_NON_OBJECT_BYTES = 1, // N bytes non-objects
BLOCK_LAYOUT_NON_OBJECT_WORDS = 2, // N words non-objects
BLOCK_LAYOUT_STRONG = 3, // N words strong pointers
BLOCK_LAYOUT_BYREF = 4, // N words byref pointers
BLOCK_LAYOUT_WEAK = 5, // N words weak pointers
...
;
// clang
/// InlineLayoutInstruction - This routine produce an inline instruction for the
/// block variable layout if it can. If not, it returns 0. Rules are as follow:
/// If ((uintptr_t) layout) < (1 << 12), the layout is inline. In the 64bit world,
/// an inline layout of value 0x0000000000000xyz is interpreted as follows:
/// x captured object pointers of BLOCK_LAYOUT_STRONG. Followed by
/// y captured object of BLOCK_LAYOUT_BYREF. Followed by
/// z captured object of BLOCK_LAYOUT_WEAK. If any of the above is missing, zero
/// replaces it. For example, 0x00000x00 means x BLOCK_LAYOUT_STRONG and no
/// BLOCK_LAYOUT_BYREF and no BLOCK_LAYOUT_WEAK objects are captured.
- 首先要解释的是 inline 这个词,Objective-C 中有一种叫做 Tagged Pointer 的技术,它让指针保存实际值,而不是保存实际值的地址,这里的 inline 也是相同的效果,即让 layout 指针保存实际的编码信息。在 inline 状态下,使用十六进制中的一位表示捕获变量的数量,所以每种类型的变量最多只能有 15 个,此时的 layout 的值以 0xXYZ 形式呈现,其中 X、Y、Z 分别表示捕获 __strong、__block、__weak 修饰指针变量的个数,如果其中某个类型的数量超过 15 或者捕获变量的修饰类型不为这三种任何一个时,比如捕获的变量由 __unsafe_unretained 修饰,则采用另一种编码方式,这种方式下,layout 会指向一个字符串,这个字符串的每个字节以 0xPN 的形式呈现,并以 0x00 结束,P 表示变量类型,N 表示变量个数,需要注意的是,N 为 0 表示 P 类型有一个,而不是 0 个,也就是说实际的变量个数比 N 大 1。
- 需要注意的是,捕获 int 等基础类型,不影响 layout 的呈现方式,layout 编码中也不会有关于基础类型的信息,除非需要基础类型的编码来辅助定位对象指针类型的位置,比如捕获含有对象指针字段的结构体。
- 如下所示:代码块没有捕获任何对象指针,所以实际的 descriptor 不包含 copy 和 dispose 字段:
unsigned long long j = 4;
int i = 3;
char c = 'a';
void (^blk)(void) = ^
i;
c;
j;
;
- 去除这两个字段后,再输出实际的布局信息,结果为空(0x00 表示结束),说明捕获一般基础类型变量不会计入实际的 layout 编码:
(lldb) p/x (long)layout->descriptor->layout
(long) $0 = 0x0000000100001f67
(lldb) x/8bx layout->descriptor->layout
0x100001f67: 0x00 0x76 0x31 0x36 0x40 0x30 0x3a 0x38
- 接着尝试第一种 layout 方式:
NSObject *o1 = [NSObject new];
__block NSObject *o3 = o1;
__weak NSObject *o2 = o1;
void (^blk)(void) = ^
o1;
o2;
o3;
;
- 以上代码块对应的 layout 值为 0x111,表示三种类型变量每种一个:
(lldb) p/x (long)layout->descriptor->layout
(long) $0 = 0x0000000000000111
- 再尝试第二种 layout 编码方式:
NSObject *o1 = [NSObject new];
__block NSObject *o3 = o1;
__weak NSObject *o2 = o1;
NSObject *o4 = o1;
... // 5 - 18
NSObject *o19 = o1;
void (^blk)(void) = ^
o1;
o2;
o3;
o4;
... // 5 - 18
o19;
;
- 以上代码块对应的 layout 值是一个地址 0x0000000100002f44 ,这个地址为编码字符串的起始地址,转换成十六进制后为 0x3f 0x30 0x40 0x50 0x00,其中 P 为 3 表示 __strong 修饰的变量,数量为 15(f) + 1 + 0 + 1 = 17 个,P 为 4 表示 __block 修饰的变量,数量为 0 + 1 = 1 个, P 为 5 表示 __weak 修饰的变量,数量为 0 + 1 = 1 个:
(lldb) p/x (long)layout->descriptor->layout
(long) $0 = 0x0000000100002f44
(lldb) x/8bx layout->descriptor->layout
0x100002f44: 0x3f 0x30 0x40 0x50 0x00 0x76 0x31 0x36
④ 结构体对捕获布局的影响
- 由于结构体字段的布局顺序在声明时就已经确定,无法像 block 构造捕获区域一样,按照变量类型、修饰符进行调整,所以如果结构体中有类型为对象指针的字段,就需要一些额外信息来计算这些对象指针字段的偏移量,需要注意的是,被捕获结构体的内存对齐信息和未捕获时一致,以寻址长度作为对齐基准,捕获操作并不会变更对齐信息。
- 同样地,先尝试捕获只有基本类型字段的结构体:
struct S
char c;
int i;
long j;
foo;
void (^blk)(void) = ^
foo;
;
- 然后调整 descriptor 结构,输出 layout :
(lldb) x/8bx layout->descriptor->layout
0x100001f67: 0x00 0x76 0x31 0x36 0x40 0x30 0x3a 0x38
- 可以看到,只有含有基本类型的结构体,同样不会影响 block 的 layout 编码信息。给结构体新增 __strong 和 __weak 修饰的对象指针字段:
struct S
char c;
int i;
__strong NSObject *o1;
long j;
__weak NSObject *o2;
foo;
void (^blk)(void) = ^
foo;
;
- 同样分析输出 layout :
(lldb) x/8bx layout->descriptor->layout
0x100002f47: 0x20 0x30 0x20 0x50 0x00 0x76 0x31 0x36
- layout 编码为0x20 0x30 0x20 0x50 0x00,其中 P 为 2 表示 word 字类型(非对象),由于字大小一般和指针一致,所以表示占用 8 * (N + 1) 个字节,第一个 0x20 表示非对象指针类型占用了 8 个字节,也就是 char 类型和 int 类型字段对齐之后所占用的空间,接着 0x30 表示有一个 __strong 修饰的对象指针字段,第二个 0x20 表示非对象指针 long 类型占用 8 个字节,最后的 0x50 表示有一个 __weak 修饰的对象指针字段。由于编码中包含每个字段的排序和大小,就可以通过解析 layout 编码后的偏移量,拿到想要的对象指针值。 P 还有个 byte 类型,值为 1,和 word 类型有相似的功能,只是表示的空间大小不同。
⑤ Byref 结构的布局
- 由 __block 修饰的捕获变量,会先转换成 byref 结构,再由这个结构去持有实际的捕获变量,block 只负责管理 byref 结构:
// 标志位不一样,这个结构的实际布局也会有差别,简单地放在一起好阅读
struct sr_block_byref
void *isa;
struct sr_block_byref *forwarding;
// contains ref count
volatile int32_t flags;
uint32_t size;
// requires BLOCK_BYREF_HAS_COPY_DISPOSE
void (*byref_keep)(struct sr_block_byref *dst, struct sr_block_byref *src);
void (*byref_destroy)(struct sr_block_byref *);
// requires BLOCK_BYREF_LAYOUT_EXTENDED
const char *layout;
;
- 以上代码块就是 byref 对应的结构体,第一眼看上去,比较困惑为什么还要有 layout 字段,虽然 block 源码注释说明 byref 和 block 结构一样,都具备两种不同的布局编码方式,但是 byref 不是只针对一个变量吗,难道和 block 捕获区域一样也可以携带多个捕获变量?带着这个困惑,先看下以下表达式 :
__block NSObject *o1 = [NSObject new];
- 使用 clang 重写之后:
struct __Block_byref_o1_0
void *__isa;
__Block_byref_o1_0 *__forwarding;
int __flags;
int __size;
void (*__Block_byref_id_object_copy)(void*, void*);
void (*__Block_byre/* @autoreleasepool */o __AtAutoreleasePool __autoreleasepool; e)(void*);
NSObject *o1;
;
- 和 block 捕获变量一样,byref 携带的变量也是保存在结构体尾部的内存空间里,当前上下文中,可以直接通过 sr_block_byref 的 layout 字段获取 o1 对象指针值。可以看到,在包装如对象指针这类常规变量时,layout 字段并没有起到实质性的作用,那什么条件下的 layout 才表示布局编码信息呢?如果使用 layout 字段表示编码信息,那么携带的变量又是何处安放的呢?
- 针对第一个问题,先看以下代码块 :
__block struct S
NSObject *o1;
foo;
foo.o1 = [NSObject new];
void (^blk)(void) = ^
foo;
;
- 使用 clang 重写之后:
struct __Block_byref_foo_0
void *__isa;
__Block_byref_foo_0 *__forwarding;
int __flags;
int __size;
void (*__Block_byref_id_object_copy)(void*, void*);
void (*__Block_byref_id_object_dispose)(void*);
struct S foo;
;
- 和常规类型一样,foo 结构体保存在结构体尾部,也就是原本 layout 所在的字段,重写的代码中依然看不到 layout 的踪影,接着输出 foo :
(lldb) po foo.o1
<NSObject: 0x10061f130>
(lldb) p (struct S)a_byref->layout
error: Multiple internal symbols found for 'S'
(lldb) p/x (long)a_byref->layout
(long) $3 = 0x0000000000000100
(lldb) x/56bx a_byref
0x100627c20: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00
0x100627c28: 0x20 0x7c 0x62 0x00 0x01 0x00 0x00 0x00
0x100627c30: 0x04 0x00 0x00 0x13 0x38 0x00 0x00 0x00
0x100627c38: 0x90 0x1b 0x00 0x00 0x01 0x00 0x00 0x00
0x100627c40: 0x00 0x1c 0x00 0x00 0x01 0x00 0x00 0x00
0x100627c48: 0x00 0x01 0x00 0x00 0x00 0x00 0x00 0x00
0x100627c50: 0x30 0xf1 0x61 0x00 0x01 0x00 0x00 0x00
- 看来事情并没有看上去的那么简单,首先重写代码中 foo 字段所在内存保存的并不是结构体,而是 0x0000000000000100,这个 100 是不是看着有点眼熟?没错,这就是 byref 的 layout 信息,根据 0xXYZ 编码规则,这个值表示有 1 个 __strong 修饰的对象指针。
- 接着针对第二个问题,携带的对象指针变量存在哪?往下移动 8 个字节,这不就是 foo.o1 对象指针的值么?总结下,在存在 layout 的情况下,byref 使用 8 个字节保存 layout 编码信息,并紧跟着在 layout 字段后存储捕获的变量。
- 以上是 byref 的第一种 layout 编码方式,再尝试第二种:
__block struct S
char c;
NSObject *o1;
__weak NSObject *o3;
foo;
foo.o1 = [NSObject new];
void (^blk)(void) = ^
foo;
;
- 使用 clang 重写代码之后 :
struct __Block_byref_foo_0 以上是关于iOS端循环引用检测实战的主要内容,如果未能解决你的问题,请参考以下文章