iOS 符号化:基础与进阶
Posted 老司机技术周报
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了iOS 符号化:基础与进阶相关的知识,希望对你有一定的参考价值。
作者:米广,有赞 ios 开发,喜欢折腾,微信订阅号:剁手指北, bilibili频道:yz06276
审核:
五子棋,老司机技术周报编辑,主要致力于研究一站式机器学习平台 — MNN 工作台,大家可以前往 www.mnn.zone 下载
Damonwong,iOS 开发,老司机技术周报编辑,就职于淘系技术部

App,bug 定位也变得难以进行;可以生成值区间在1-100间的随机数numberChoices() 可以生成一个包含 10 个上述随机数的数组selectMagicNumber(choices: numbers) 可以从入参 numbers 数组中,取出一个指定下标的元素generateMagicNumber() 按部执行上述操作,返回取出下标的元素
此处的 MAGIC_CHOICE 是一个随机值就崩溃了,查看生成的错误日志,里面没有很直观的信息,是一堆内存地址,我只能看到 App 在主线程上 crash 了;
我尝试直接 debug 我的 App,但在执行中没有复现该问题,看来调试器也不一定能帮得了忙;多次尝试之后终于复现了,但程序崩溃在汇编中,也没有直观的信息,汇编太硬核,搞不定。
上面的崩溃日志和汇编堆栈显然都不能直接解决问题,但在符号化的帮助下,我们可以不从这些原始内存地址中挖掘错误;相信大家都知道在 Xcode Organizer 中载入 App 的 dSYM 文件,他会重新处理崩溃日志,载入后我们就可以得到下面这种可读的、可以获得调用信息、文件名、具体行数的崩溃日志,崩溃日志直接告诉我,崩溃时发生了数组越界访问,非常直观;根据这些信息回溯到代码,我们也容易发现随机值 MAGIC_CHOICE 容易导致,在访问只有 10 个长度数组访问时,发生数组越界;
使用 atos 命令行工具,我们也可以得到上述信息
堆栈的符号化,别的地方还能载入 dSYM 吗?atos 的 -o -i -l 各自有什么用处?Instruments 为什么未能直接提供完全符号化的堆栈?Xcode 编译设置对符号化有何影响?带着这些问题,让我们深入探究一些符号化的原理。
为此我们首先分解介绍符号化的两个步骤:第一步:从内存地址回溯到文件第二步:还原运行时调试信息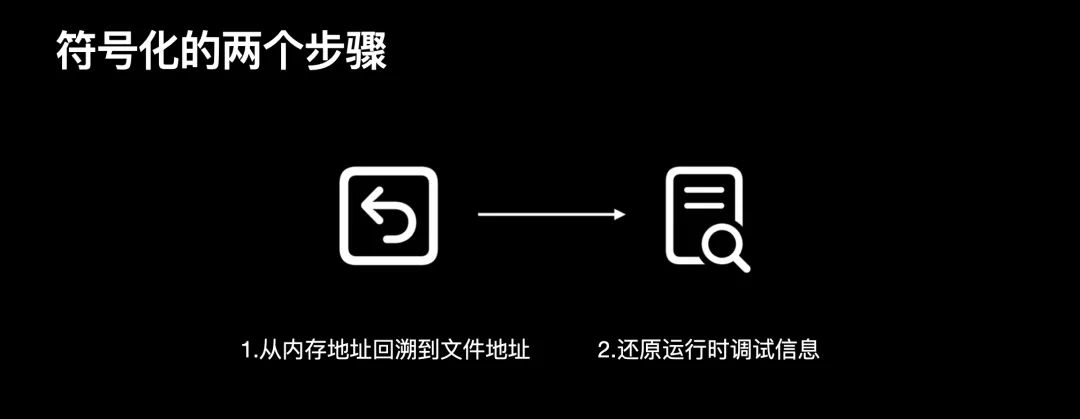
链接器赋予二进制文件的地址;具体而言,linker 会把二进制代码分组,分组后的部分称为段 Segment,每个二进制段都包含了一些数据和属性,例如段的名称,大小,地址等;举例来说,二进制文件中的 __TEXT 段会包含对应的方法和函数,__DATA 段会包含程序的全局状态,例如全局变量;每个段都被赋予了一个独一无二的起始地址,这种设计保证了段与段之间不会重叠;
-w871 具体而言 linker 会把段信息记录在可执行文件头部,作为 Mach-O 头的一部分;众所周知, Mach-O 是一种可执行文件和库的文件格式,Mach-O 头中包含许多与段的属性信息相关的 load 指令,操作系统内核通过读取这些 load 指令来把对应的二进制段加载入内存;如果 App 用到了 Universal2 打包技术,那每种架构都会有与之对应的 Mach-O 头和相关段信息;

-w860 上面讲了段信息和 load 指令,让我们来结合最初的小 demo,实践查看一下相关的 load 指令;我们可以通过 otool -l 来输出 load 指令信息,结合 grep(字符串筛选工具)可以过滤出 LC_SEGMENT_64 的 load 指令,如下图所示;输出结果提示 __TEXT 段的起始位置为 vmaddr 所示地址,段的长度为 vmsize 所示字节大小;
指令会包含载入的地址和大小,那为什么内核实际通过 load 指令载入后,二进制段的内存地址和这个 linker 生成的地址不一致?下图中内存地址和 linker 的 A、B、C 地址有啥关系?后文中会将 linker 生成的地址简称为 A、B、C
通过随机放置进程关键数据区域的地址空间来防止攻击者能可靠地跳转到内存的特定位置来攻击制定函数。现代操作系统一般都加设这一机制,以防范恶意程序对已知地址进行 Return-to-libc 攻击。简言之,内核在加载二进制段前,会初始化一个随机值,称为 ASLR Slide 「内存空间随机分布偏移量」,后文中会把该偏移量简称为 S;之后内核会将该偏移量 S 叠加到 linker 生成的 load 指令的地址 A、B、C上;因此,内核在执行 load 指令时,不会按照原始的 linker 地址直接载入到内存地址 A、B、C 中,而是载入到 A+S、B+S、C+S,我们可以把这些实际的 load 加载地址称为 Load Address「加载地址」,后文中,Load Address 将简称为 L
通过了解 ASLR 技术,我们弄明白了 linker address 和 load address 之间的差值是 ASLR Slide 随机内存地址分布偏移量;我们可以得到该公式 ALSR Slide = Load Address - Linker Address, 简化为 S = L - A
可以帮助我们查看二进制文件的 load 指令信息,进而得到 linker address (该地址也可以视为 file address 「文件地址」)
而获得运行时内存地址中的 Load Address,可以通过崩溃日志中的 Binary Image 列表,Instruments 提供的堆栈,或者通过 vmmap 命令行工具来获取;具体如何使用 vmmap 在后文中会有讲解
随机内存偏移量,才能够从崩溃日志和 Instruments 堆栈中的内存地址,减去 ASLR Slide 而获得文件地址;因此需要先计算出 ASLR Slide,计算 ASLR Slide 一般以特定段(如 __TEXT)的 load address 和 linker address 来相减得出,如何获取这俩地址上面已经说了,结合实践我们从崩溃日志中获取了 __TEXT 二进制段的 load address 为 0x10045c000 ;通过 otool 我可以获得 __TEXT 二进制段的 linker address 为 0x100000000 ;将这两者相减我们就可以的得到 ASLR Slide = 0x45c000;
有了 ASLR Slide ,我们可以从崩溃日志的运行时内存地址,换算出磁盘地址空间中的文件地址,如下图所示,我们可以得到我们 demo 中崩溃的堆栈的文件地址为 0x10003b70 ,有了文件地址,我们可以用来查看源码,这个后续再说。我们先继续探索一下其他计算 ASLR Slide 的姿势
如下图所示,otool 命令行工具可以用来查看崩溃时发生问题的指令信息, 传入 -tV 可以输出汇编堆栈;-arch arm64 是为了让 otool 正确处理 Universal 2 技术编译的产物;输出结构对应上述文件地址,显示此是 brk 指令,汇编中的 brk 一般代表着 App 出现了异常或问题;
atos 命令行工具也可以帮我们计算 ASLR Slide, atos 的 -o 指令会输出 file segment address, -l 指令会输出 load address;
除了 atos 和 otool ,还有 vmmap 命令行工具也可以帮助我们获取 load address ,我们可以用 vmmap 来验证上面的计算结果, vmmap 输出崩溃时 __TEXT segment 的 load address ,使用之前公式可以计算出本次运行的 ASLR Slide 为 0x104d14000 ,将本次崩溃日志中的 runtime address - ASLR Slide 得到了 file address 为 0x100003b70 ,和之前计算的 file address 一样;
上述两次不同运行时, 不同崩溃日志,不同的 ASLR Slide 能够得到同一个 file address ,这不是巧合;是因为内核每次运行的 ASLR Slide 都不同,因此不同时间,不同设备的崩溃日志中所对应的内存地址会变化,但实际的 linkder address 是一样的;基于此,虽然内存地址每次变化,我们仍然可以定位到相同的 file address;至此,我们发现了一种机制,能让我在随机的运行时内存中,定位到我们 App 源码级别所发生的的事;通过这种映射机制能够让我们从运行时的堆栈信息中,回溯到 App 源码中;
和 库的二进制文件格式是 Mach-O ,其中 Mach-O 的头中存放了二进制段的关联信息和 load 指令,这些二进制段是 linker 创建的,其中包括了二进制段的地址信息 linker address;
App 在主线程上 crash 了;我尝试直接 debug 我的 App,但在执行中没有复现该问题,看来调试器也不一定能帮得了忙;多次尝试之后终于复现了,但程序崩溃在汇编中,也没有直观的信息,汇编太硬核,搞不定。
上面的崩溃日志和汇编堆栈显然都不能直接解决问题,但在符号化的帮助下,我们可以不从这些原始内存地址中挖掘错误;相信大家都知道在 Xcode Organizer 中载入 App 的 dSYM 文件,他会重新处理崩溃日志,载入后我们就可以得到下面这种可读的、可以获得调用信息、文件名、具体行数的崩溃日志,崩溃日志直接告诉我,崩溃时发生了数组越界访问,非常直观;根据这些信息回溯到代码,我们也容易发现随机值 MAGIC_CHOICE 容易导致,在访问只有 10 个长度数组访问时,发生数组越界;
使用 atos 命令行工具,我们也可以得到上述信息
堆栈的符号化,别的地方还能载入 dSYM 吗?atos 的 -o -i -l 各自有什么用处?Instruments 为什么未能直接提供完全符号化的堆栈?Xcode 编译设置对符号化有何影响?带着这些问题,让我们深入探究一些符号化的原理。为此我们首先分解介绍符号化的两个步骤:第一步:从内存地址回溯到文件第二步:还原运行时调试信息
链接器赋予二进制文件的地址;具体而言,linker 会把二进制代码分组,分组后的部分称为段 Segment,每个二进制段都包含了一些数据和属性,例如段的名称,大小,地址等;举例来说,二进制文件中的 __TEXT 段会包含对应的方法和函数,__DATA 段会包含程序的全局状态,例如全局变量;每个段都被赋予了一个独一无二的起始地址,这种设计保证了段与段之间不会重叠;-w871 具体而言 linker 会把段信息记录在可执行文件头部,作为 Mach-O 头的一部分;众所周知, Mach-O 是一种可执行文件和库的文件格式,Mach-O 头中包含许多与段的属性信息相关的 load 指令,操作系统内核通过读取这些 load 指令来把对应的二进制段加载入内存;如果 App 用到了 Universal2 打包技术,那每种架构都会有与之对应的 Mach-O 头和相关段信息;
-w860 上面讲了段信息和 load 指令,让我们来结合最初的小 demo,实践查看一下相关的 load 指令;我们可以通过 otool -l 来输出 load 指令信息,结合 grep(字符串筛选工具)可以过滤出 LC_SEGMENT_64 的 load 指令,如下图所示;输出结果提示 __TEXT 段的起始位置为 vmaddr 所示地址,段的长度为 vmsize 所示字节大小;
指令会包含载入的地址和大小,那为什么内核实际通过 load 指令载入后,二进制段的内存地址和这个 linker 生成的地址不一致?下图中内存地址和 linker 的 A、B、C 地址有啥关系?后文中会将 linker 生成的地址简称为 A、B、C通过随机放置进程关键数据区域的地址空间来防止攻击者能可靠地跳转到内存的特定位置来攻击制定函数。现代操作系统一般都加设这一机制,以防范恶意程序对已知地址进行 Return-to-libc 攻击。简言之,内核在加载二进制段前,会初始化一个随机值,称为 ASLR Slide 「内存空间随机分布偏移量」,后文中会把该偏移量简称为 S;之后内核会将该偏移量 S 叠加到 linker 生成的 load 指令的地址 A、B、C上;因此,内核在执行 load 指令时,不会按照原始的 linker 地址直接载入到内存地址 A、B、C 中,而是载入到 A+S、B+S、C+S,我们可以把这些实际的 load 加载地址称为 Load Address「加载地址」,后文中,Load Address 将简称为 L通过了解 ASLR 技术,我们弄明白了 linker address 和 load address 之间的差值是 ASLR Slide 随机内存地址分布偏移量;我们可以得到该公式 ALSR Slide = Load Address - Linker Address, 简化为 S = L - A
可以帮助我们查看二进制文件的 load 指令信息,进而得到 linker address (该地址也可以视为 file address 「文件地址」)
而获得运行时内存地址中的 Load Address,可以通过崩溃日志中的 Binary Image 列表,Instruments 提供的堆栈,或者通过 vmmap 命令行工具来获取;具体如何使用 vmmap 在后文中会有讲解随机内存偏移量,才能够从崩溃日志和 Instruments 堆栈中的内存地址,减去 ASLR Slide 而获得文件地址;因此需要先计算出 ASLR Slide,计算 ASLR Slide 一般以特定段(如 __TEXT)的 load address 和 linker address 来相减得出,如何获取这俩地址上面已经说了,结合实践我们从崩溃日志中获取了 __TEXT 二进制段的 load address 为 0x10045c000 ;通过 otool 我可以获得 __TEXT 二进制段的 linker address 为 0x100000000 ;将这两者相减我们就可以的得到 ASLR Slide = 0x45c000;有了 ASLR Slide ,我们可以从崩溃日志的运行时内存地址,换算出磁盘地址空间中的文件地址,如下图所示,我们可以得到我们 demo 中崩溃的堆栈的文件地址为 0x10003b70 ,有了文件地址,我们可以用来查看源码,这个后续再说。我们先继续探索一下其他计算 ASLR Slide 的姿势
如下图所示,otool 命令行工具可以用来查看崩溃时发生问题的指令信息, 传入 -tV 可以输出汇编堆栈;-arch arm64 是为了让 otool 正确处理 Universal 2 技术编译的产物;输出结构对应上述文件地址,显示此是 brk 指令,汇编中的 brk 一般代表着 App 出现了异常或问题;
atos 命令行工具也可以帮我们计算 ASLR Slide, atos 的 -o 指令会输出 file segment address, -l 指令会输出 load address;
除了 atos 和 otool ,还有 vmmap 命令行工具也可以帮助我们获取 load address ,我们可以用 vmmap 来验证上面的计算结果, vmmap 输出崩溃时 __TEXT segment 的 load address ,使用之前公式可以计算出本次运行的 ASLR Slide 为 0x104d14000 ,将本次崩溃日志中的 runtime address - ASLR Slide 得到了 file address 为 0x100003b70 ,和之前计算的 file address 一样;
上述两次不同运行时, 不同崩溃日志,不同的 ASLR Slide 能够得到同一个 file address ,这不是巧合;是因为内核每次运行的 ASLR Slide 都不同,因此不同时间,不同设备的崩溃日志中所对应的内存地址会变化,但实际的 linkder address 是一样的;基于此,虽然内存地址每次变化,我们仍然可以定位到相同的 file address;至此,我们发现了一种机制,能让我在随机的运行时内存中,定位到我们 App 源码级别所发生的的事;通过这种映射机制能够让我们从运行时的堆栈信息中,回溯到 App 源码中;
和 库的二进制文件格式是 Mach-O ,其中 Mach-O 的头中存放了二进制段的关联信息和 load 指令,这些二进制段是 linker 创建的,其中包括了二进制段的地址信息 linker address;
linker 会把段信息记录在可执行文件头部,作为 Mach-O 头的一部分;众所周知, Mach-O 是一种可执行文件和库的文件格式,Mach-O 头中包含许多与段的属性信息相关的 load 指令,操作系统内核通过读取这些 load 指令来把对应的二进制段加载入内存;如果 App 用到了 Universal2 打包技术,那每种架构都会有与之对应的 Mach-O 头和相关段信息;load 指令,让我们来结合最初的小 demo,实践查看一下相关的 load 指令;我们可以通过 otool -l 来输出 load 指令信息,结合 grep(字符串筛选工具)可以过滤出 LC_SEGMENT_64 的 load 指令,如下图所示;输出结果提示 __TEXT 段的起始位置为 vmaddr 所示地址,段的长度为 vmsize 所示字节大小;load 指令载入后,二进制段的内存地址和这个 linker 生成的地址不一致?下图中内存地址和 linker 的 A、B、C 地址有啥关系?后文中会将 linker 生成的地址简称为 A、B、C通过随机放置进程关键数据区域的地址空间来防止攻击者能可靠地跳转到内存的特定位置来攻击制定函数。现代操作系统一般都加设这一机制,以防范恶意程序对已知地址进行 Return-to-libc 攻击。简言之,内核在加载二进制段前,会初始化一个随机值,称为 ASLR Slide 「内存空间随机分布偏移量」,后文中会把该偏移量简称为 S;之后内核会将该偏移量 S 叠加到 linker 生成的 load 指令的地址 A、B、C上;因此,内核在执行 load 指令时,不会按照原始的 linker 地址直接载入到内存地址 A、B、C 中,而是载入到 A+S、B+S、C+S,我们可以把这些实际的 load 加载地址称为 Load Address「加载地址」,后文中,Load Address 将简称为 L通过了解 ASLR 技术,我们弄明白了 linker address 和 load address 之间的差值是 ASLR Slide 随机内存地址分布偏移量;我们可以得到该公式 ALSR Slide = Load Address - Linker Address, 简化为 S = L - A
可以帮助我们查看二进制文件的 load 指令信息,进而得到 linker address (该地址也可以视为 file address 「文件地址」)
而获得运行时内存地址中的 Load Address,可以通过崩溃日志中的 Binary Image 列表,Instruments 提供的堆栈,或者通过 vmmap 命令行工具来获取;具体如何使用 vmmap 在后文中会有讲解随机内存偏移量,才能够从崩溃日志和 Instruments 堆栈中的内存地址,减去 ASLR Slide 而获得文件地址;因此需要先计算出 ASLR Slide,计算 ASLR Slide 一般以特定段(如 __TEXT)的 load address 和 linker address 来相减得出,如何获取这俩地址上面已经说了,结合实践我们从崩溃日志中获取了 __TEXT 二进制段的 load address 为 0x10045c000 ;通过 otool 我可以获得 __TEXT 二进制段的 linker address 为 0x100000000 ;将这两者相减我们就可以的得到 ASLR Slide = 0x45c000;有了 ASLR Slide ,我们可以从崩溃日志的运行时内存地址,换算出磁盘地址空间中的文件地址,如下图所示,我们可以得到我们 demo 中崩溃的堆栈的文件地址为 0x10003b70 ,有了文件地址,我们可以用来查看源码,这个后续再说。我们先继续探索一下其他计算 ASLR Slide 的姿势
如下图所示,otool 命令行工具可以用来查看崩溃时发生问题的指令信息, 传入 -tV 可以输出汇编堆栈;-arch arm64 是为了让 otool 正确处理 Universal 2 技术编译的产物;输出结构对应上述文件地址,显示此是 brk 指令,汇编中的 brk 一般代表着 App 出现了异常或问题;
atos 命令行工具也可以帮我们计算 ASLR Slide, atos 的 -o 指令会输出 file segment address, -l 指令会输出 load address;
除了 atos 和 otool ,还有 vmmap 命令行工具也可以帮助我们获取 load address ,我们可以用 vmmap 来验证上面的计算结果, vmmap 输出崩溃时 __TEXT segment 的 load address ,使用之前公式可以计算出本次运行的 ASLR Slide 为 0x104d14000 ,将本次崩溃日志中的 runtime address - ASLR Slide 得到了 file address 为 0x100003b70 ,和之前计算的 file address 一样;
上述两次不同运行时, 不同崩溃日志,不同的 ASLR Slide 能够得到同一个 file address ,这不是巧合;是因为内核每次运行的 ASLR Slide 都不同,因此不同时间,不同设备的崩溃日志中所对应的内存地址会变化,但实际的 linkder address 是一样的;基于此,虽然内存地址每次变化,我们仍然可以定位到相同的 file address;至此,我们发现了一种机制,能让我在随机的运行时内存中,定位到我们 App 源码级别所发生的的事;通过这种映射机制能够让我们从运行时的堆栈信息中,回溯到 App 源码中;
和 库的二进制文件格式是 Mach-O ,其中 Mach-O 的头中存放了二进制段的关联信息和 load 指令,这些二进制段是 linker 创建的,其中包括了二进制段的地址信息 linker address;
ASLR 技术,我们弄明白了 linker address 和 load address 之间的差值是 ASLR Slide 随机内存地址分布偏移量;我们可以得到该公式 ALSR Slide = Load Address - Linker Address, 简化为 S = L - Aload 指令信息,进而得到 linker address (该地址也可以视为 file address 「文件地址」)
而获得运行时内存地址中的 Load Address,可以通过崩溃日志中的 Binary Image 列表,Instruments 提供的堆栈,或者通过 vmmap 命令行工具来获取;具体如何使用 vmmap 在后文中会有讲解随机内存偏移量,才能够从崩溃日志和 Instruments 堆栈中的内存地址,减去 ASLR Slide 而获得文件地址;因此需要先计算出 ASLR Slide,计算 ASLR Slide 一般以特定段(如 __TEXT)的 load address 和 linker address 来相减得出,如何获取这俩地址上面已经说了,结合实践我们从崩溃日志中获取了 __TEXT 二进制段的 load address 为 0x10045c000 ;通过 otool 我可以获得 __TEXT 二进制段的 linker address 为 0x100000000 ;将这两者相减我们就可以的得到 ASLR Slide = 0x45c000;有了 ASLR Slide ,我们可以从崩溃日志的运行时内存地址,换算出磁盘地址空间中的文件地址,如下图所示,我们可以得到我们 demo 中崩溃的堆栈的文件地址为 0x10003b70 ,有了文件地址,我们可以用来查看源码,这个后续再说。我们先继续探索一下其他计算 ASLR Slide 的姿势
如下图所示,otool 命令行工具可以用来查看崩溃时发生问题的指令信息, 传入 -tV 可以输出汇编堆栈;-arch arm64 是为了让 otool 正确处理 Universal 2 技术编译的产物;输出结构对应上述文件地址,显示此是 brk 指令,汇编中的 brk 一般代表着 App 出现了异常或问题;
atos 命令行工具也可以帮我们计算 ASLR Slide, atos 的 -o 指令会输出 file segment address, -l 指令会输出 load address;
除了 atos 和 otool ,还有 vmmap 命令行工具也可以帮助我们获取 load address ,我们可以用 vmmap 来验证上面的计算结果, vmmap 输出崩溃时 __TEXT segment 的 load address ,使用之前公式可以计算出本次运行的 ASLR Slide 为 0x104d14000 ,将本次崩溃日志中的 runtime address - ASLR Slide 得到了 file address 为 0x100003b70 ,和之前计算的 file address 一样;
上述两次不同运行时, 不同崩溃日志,不同的 ASLR Slide 能够得到同一个 file address ,这不是巧合;是因为内核每次运行的 ASLR Slide 都不同,因此不同时间,不同设备的崩溃日志中所对应的内存地址会变化,但实际的 linkder address 是一样的;基于此,虽然内存地址每次变化,我们仍然可以定位到相同的 file address;至此,我们发现了一种机制,能让我在随机的运行时内存中,定位到我们 App 源码级别所发生的的事;通过这种映射机制能够让我们从运行时的堆栈信息中,回溯到 App 源码中;
和 库的二进制文件格式是 Mach-O ,其中 Mach-O 的头中存放了二进制段的关联信息和 load 指令,这些二进制段是 linker 创建的,其中包括了二进制段的地址信息 linker address;
ASLR Slide ,我们可以从崩溃日志的运行时内存地址,换算出磁盘地址空间中的文件地址,如下图所示,我们可以得到我们 demo 中崩溃的堆栈的文件地址为 0x10003b70 ,有了文件地址,我们可以用来查看源码,这个后续再说。我们先继续探索一下其他计算 ASLR Slide 的姿势otool 命令行工具可以用来查看崩溃时发生问题的指令信息, 传入 -tV 可以输出汇编堆栈;-arch arm64 是为了让 otool 正确处理 Universal 2 技术编译的产物;输出结构对应上述文件地址,显示此是 brk 指令,汇编中的 brk 一般代表着 App 出现了异常或问题;atos 命令行工具也可以帮我们计算 ASLR Slide, atos 的 -o 指令会输出 file segment address, -l 指令会输出 load address;atos 和 otool ,还有 vmmap 命令行工具也可以帮助我们获取 load address ,我们可以用 vmmap 来验证上面的计算结果, vmmap 输出崩溃时 __TEXT segment 的 load address ,使用之前公式可以计算出本次运行的 ASLR Slide 为 0x104d14000 ,将本次崩溃日志中的 runtime address - ASLR Slide 得到了 file address 为 0x100003b70 ,和之前计算的 file address 一样;ASLR Slide 能够得到同一个 file address ,这不是巧合;是因为内核每次运行的 ASLR Slide 都不同,因此不同时间,不同设备的崩溃日志中所对应的内存地址会变化,但实际的 linkder address 是一样的;基于此,虽然内存地址每次变化,我们仍然可以定位到相同的 file address;至此,我们发现了一种机制,能让我在随机的运行时内存中,定位到我们 App 源码级别所发生的的事;通过这种映射机制能够让我们从运行时的堆栈信息中,回溯到 App 源码中;Mach-O ,其中 Mach-O 的头中存放了二进制段的关联信息和 load 指令,这些二进制段是 linker 创建的,其中包括了二进制段的地址信息 linker address;otool -l 可以帮助我们输出 Mach-O 中指定二进制段的地址和属性信息,其中包括 linker address;binary image 列表中可以获取崩溃发生时的 load address;vmmap 也可以获得正在运行 App 的 load addressASLR Slide + Linker address = Load address
Xcode 会在编译时生成这些关系信息并存放为 dSYM 文件,也可以把这些关系信息内置在二进制编译产物中;
这些调试信息有三种类型,每一种都提供了不同级别与 file address 关联的调试信息;
Function startsNlist symbol tableDWARF
下图中展示了这三种工具分别提供了对应维度的调试信息
相较于其他工具提供最少的信息,该工具只能提供函数对应的起始地址,具体而言,function starts 会提供函数的起始地址和其调用的所在的地址;但这其中不会告诉你这调用地址里是否有其他函数,他只能告诉你这里有个函数出问题 ;
function starts 通过编码 __LINKEDIT 二进制段中的 linker 地址列表来提供该功能;function starts 基于直接内置在 App 编译产物中,通过 mach-O 文件的 load 指令的 LC_FUNCTION_STARTS 来描述 function starts;
实践中,可以通过 symbols -onlyFuncStartsData 命令行工具来输出 function starts 相关信息,如下图所示,其中的 null 是因为 function starts 不提供函数名称,所以用 null 来做函数名称的占位符;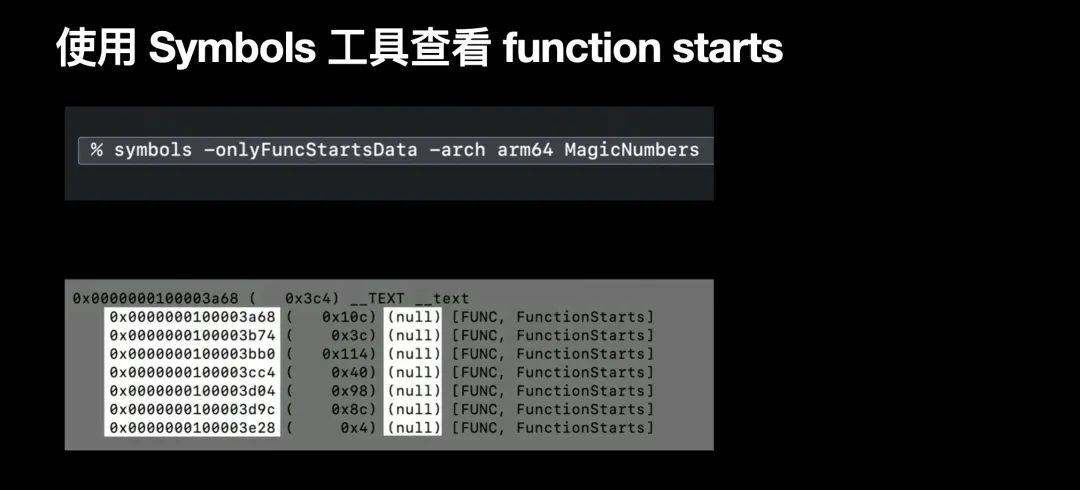
基于 function starts 我们可以对未符号化的崩溃日志进行处理,先从崩溃日志的内存地址 0x10045fb70 减去之前计算好的 ASLR Slide 0x45c000得到 file address 0x100003b70;
然后结合 function starts 输出结果,我们发现只有第一个地址 0x100003a68 小于我们算出的 file address 0x100003b70,所以只有这第一个地址包含了错误发生的地址;基于此我们计算这两个地址之间偏移了 0x108,换算成十进制 是 264,也就是我们 file address 与实际错误发生地址之间有 264 字节的偏移量;
至此 function starts 可以帮助我们理解崩溃日志中的函数如何被设置,修改了哪些寄存器;但因为 function starts 不提供函数名,我们只能在低级的机器码层面来分析这些错误日志,对于调试开发 App 来说挺有用,但对于分析错误日志,我们还需要其他工具;
是一个结构体,他具体结构如下图所示,nlist 符号表建立在 function starts 和一个编码后的 __LINKEDIT segment 的信息列表,当然 nlist 有自己的 load 指令;与 function starts 不同的是 nlist 不只是编码内存地址,他在其结构体中编码了更多信息;如下图所示,nlist 结构体中包含了名称和其他几个属性,具体而言 nlist 的类型由 n_type 所决定
n_type 有三种类型是我们符号化所感兴趣的,这里我们先着重聊一聊其中两种;第一种是 direct symbole - 直接符号;直接符号关联的是在 App 和二方库中,包含了已被完整定义的方法和函数;直接符号在 nlist_64 结构体中存储了函数名字和函数文件地址;
中的指定二进制位的值决定了该 nlist 的类型,具体而言,n_type 中的第二、三、四的二进制位为 1 时,表明该 nlist 类型为直接符号,这三个位的组合还被叫做 N_SECT;
我们可以通过 nm -defined-only —numberic-sort 命令行工具来查看 N_SECT;在这里 nm 遍历了 magicNumbers App 的制定符号,并以地址顺序罗列出来,具体参照下图中的输出;注意此处我们还是用了 xcrun -swift-demangle 来解析 Swift mangling 后的函数名称;
上图所示,我们已经可以从结果中获得了方法名 numberChoices()、类名 MagicNumbers、文件名 main;这是因为这些信息直接在 App 内定义;symbols 查看直接符号
和 nm 工具相似, symbols 命令行工具也提供查看 nlist 数据的方法,并且支持自动 demangle ,具体如下图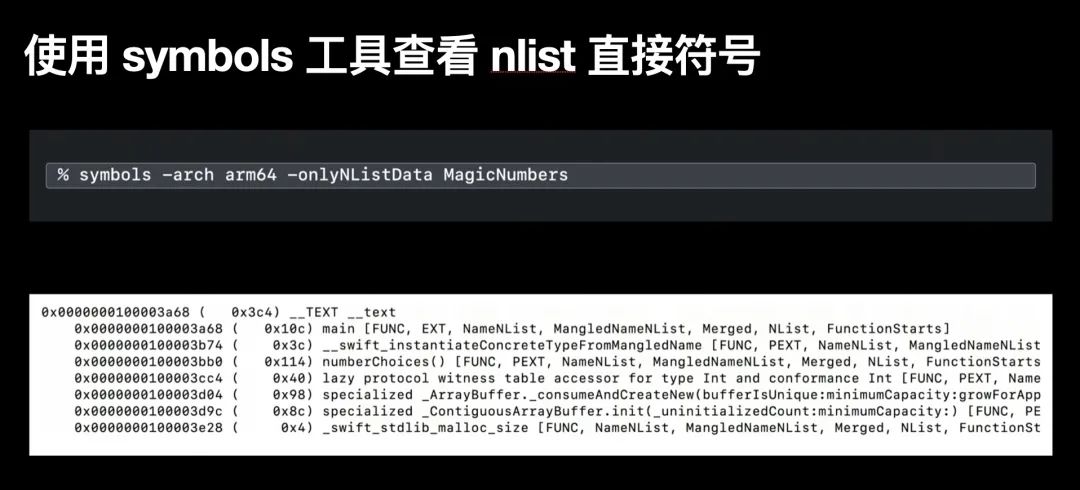 以上两个方法,让我们从崩溃日志中的内存地址,关联到了源码中的具体函数名称,至此,崩溃日志的符号化的信息丰富程度更进一步;至此,我们通过 fuction starts 提供的函数入口偏移地址从 direct symbols 中匹配到一个函数入口,并且这个入口有名字,把这些信息放在一起,我们可以发现 crash 发生在 main 方法地址的 264字节偏移处;但 main 并不是崩溃中唯一的函数,这表明我们还有更多的信息有待挖掘;例如我们还没有弄清楚代码中的行数信息
以上两个方法,让我们从崩溃日志中的内存地址,关联到了源码中的具体函数名称,至此,崩溃日志的符号化的信息丰富程度更进一步;至此,我们通过 fuction starts 提供的函数入口偏移地址从 direct symbols 中匹配到一个函数入口,并且这个入口有名字,把这些信息放在一起,我们可以发现 crash 发生在 main 方法地址的 264字节偏移处;但 main 并不是崩溃中唯一的函数,这表明我们还有更多的信息有待挖掘;例如我们还没有弄清楚代码中的行数信息
我们已经弄清 main 并不是唯一与崩溃关联的函数,我们还有更多的信息有待挖掘;例如我们还没获得文件的行数信息;并且在上述符号化中,部分函数被序列化,还有部分堆栈和崩溃日志信息没有被符号化
我们在 Instruments 的堆栈中遇到了类似的情况,一些函数名被符号化而可读,但部分仍是内存地址;发生这种现象的原因是,直接符号表中所包含的函数,只限于在链接时被直接链接的部分,动态库等运行时加载的二进制文件不被包含在内,这些未能符号化的方法就是跨模块从动态库中调用的方法;我们需要其他手段了符号化这些调试信息;
这种直接符号表的逻辑,有助于减少编译产物体积;毕竟换位思考,如果把打包时所有相关函数信息都存入符号表,这种操作才有违常识;对于 Frameworks 和 Libraries,我们需要处理记录那些被调用的方法,而剥离没用到的;当然了如果把直接符号表里的主程序内的函数剥离,那符号表里啥也不剩了;
的编译设置中,strip 配置项有 strip linked product、strip style 、strip swift symbols 三个选项。这些编译设置的选项控制了 App 在编译链接过程中的剥离多余符号表的逻辑;具体来讲,strip linked product 为 YES 时,二进制文件中将根据 strip style 的值进行符号表剥离;举例来说,strip style 值为 all symbols 时,符号表中将执行最激进的剥离策略,最终符号表中只包含最核心的方法;Non globals 类型会剥离应用中不同模块中共同使用的直接符号,但会留下用于其他 APP 中的符号;Debugging symbols 则删除了第三种 nlist 类型的符号,这个后续讨论 DWARF 时会讲到,但该类型的剥离会保留直接用到的符号。

-w875 举例来说,这里有一个定义了两个 public interface接口和一个 internal shared 实现的方法的 framework ,由于所有这些函数在链接环节中有用,他们都拥有直接的符号项。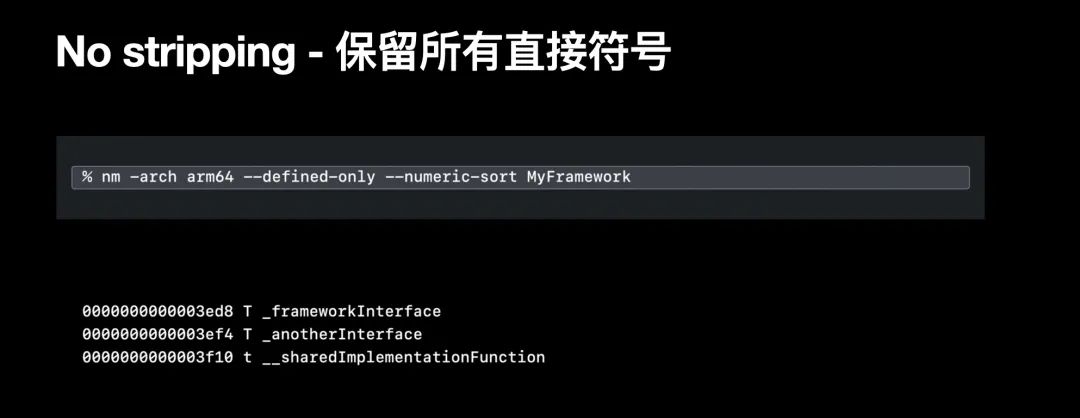
如果我按照 non globals 进行剥离,那只有两个 interface 会留下;由于共享实现的函数只在 framework 内使用,所以它不是全局的,进而也不会被放入符号表; 类似的如果是
类似的如果是 all symbols 剥离策略时时,如果这两个 interface 有被 framework 外部所调用时,他们仍然会被留下;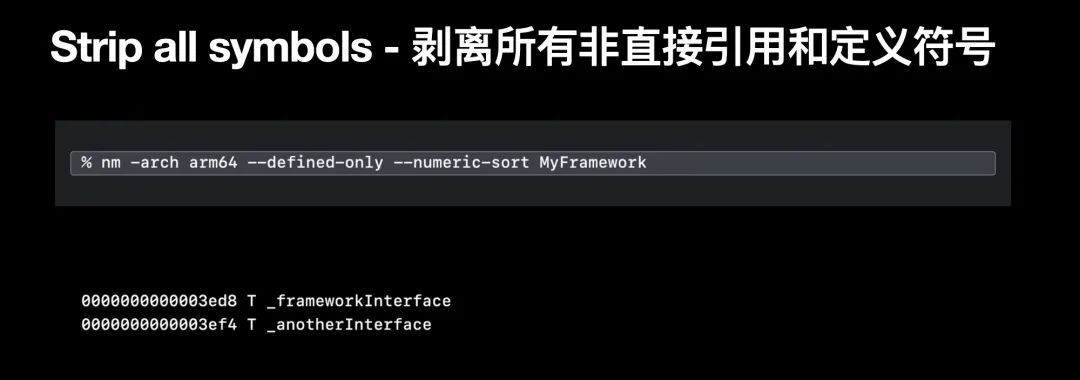
symbols —onlyNListData 会输出一些分布在直接符号之间 function starts 的条目;这些条目也表示了函数是存在于直接符号表中,亦或是已经被剥离了。你可以利用这些剥离设定,来实现你需要的符号表可见性;有了这些信息,我们就可以确定什么时候需要直接符号表。在实际应用中,有时候我们能符号化出函数名,但没有具体行数和文件名;或者符号化结果包含了方法名和方法起始地址,正如此处 framework 的 symbols 指令的例子;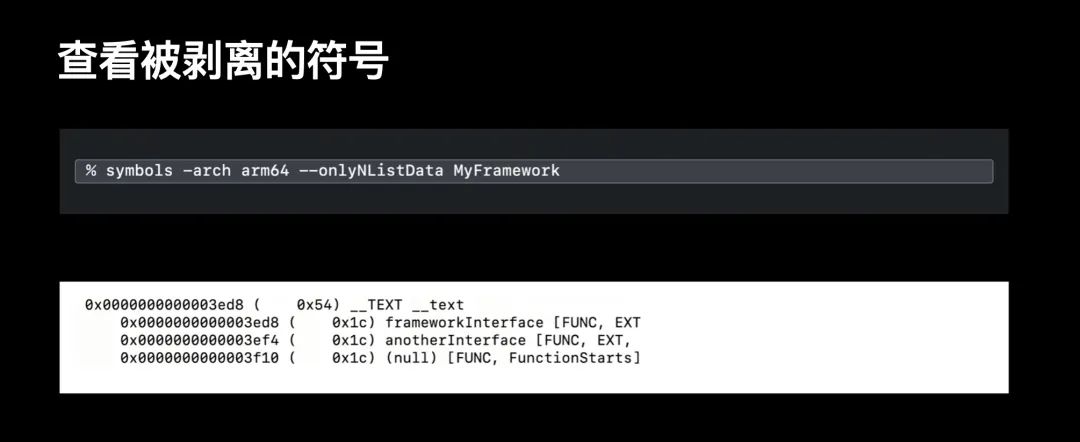
的第一位二进制位为 1 ,或称为 n_EXT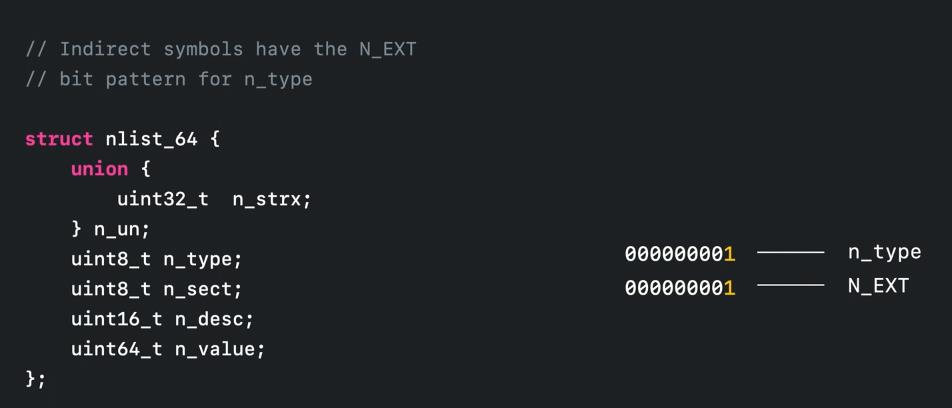
通过 nm -m -arch arm64 -undefined-only --numberic-sort MagicNumbers 输出间接符号的信息;这其中使用 —undefined-only 来替换 —defined-only ,该指令用于查看间接符号;-m ,这可以让你看到这些方法源自哪个 framework 或 libraries。下面图中的输出结果提示 MagicNumbers App 依赖了 libSwiftCore 中的一系列 Swift 基础方法如 print()。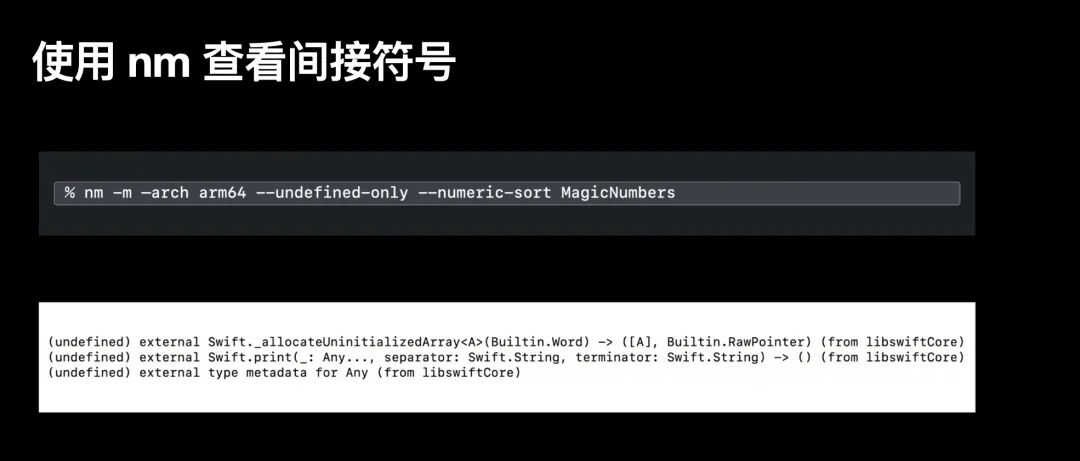
####小结 - Function starts 与 nlist 符号表
文章开头,我们约定了要讨论 function starts 、nlist 符号表和 DWARF 三种符号化工具;截止现在已经讨论了前两种,在此回顾一下;
Function starts 能提供地址列表,缺少方法名,可以帮助计算崩溃对应的文件地址偏移量;Nlist 符号表把关联到一个地址的详细信息构成结构体存储,nlist 符号能提供函数名称,还可以描述在 App 内定义的直接符号和在二方库中提供的间接符号;直接符号表通常保留与链接有关的函数,Xcode 项目设置中的 strip build style 会影响直接符号表中的内容;这两种符号表都直接嵌入在 App 二进制文件 Mach-O 头中的 __LINKEDIT 二进制段中
DWARF ;相较于 nlist 符号表只保留函数部分信息,DWARF 几乎记录了函数的所有上下文信息;回顾 function starts 只在一个维度上提供偏移量信息;nlist 基于编码 nlist_64 结构体将调试信息升级到两个维度,即地址信息和函数名称;作为比较 DWARF 增加了第三个维度:关系信息;实际项目中函数不是孤立存在的,函数会被调用和在其内部调用其他函数,函数会有出参入参;通过记录这些函数的上下文关系信息;DWARF 会带我们解锁符号化最牛逼的姿势;
当我们分析 DWARF 时,一般指的是引用分析一个 dSYM bundle,该 bundle 中存在由元数据组成的 plist,还包括一个 DWARF 二进制文件;二进制文件中将 DWARF 的信息记录在 __DWARF 二进制段中;DWARF 在该二进制段中记录了我们需要关注的三个数据流;具体而言三个数据流分别是 debug_info, debug_abbrev, debug_line ;debug_info 包含了原始数据,debug_abbrev 为原始数据进行了结构化处理,debug_line 包含了文件名和行号;除此之外 DWARF 还定义了需要讨论的两种 vocabulary list 词汇表:compile unit 编译单元和 subprogram 子程序;后文会提到第三种词汇表 - 内联子程序
文件都会有一个编译单元与之对应;DWARF 为每一个编译单元赋予了一些属性,诸如文件名、模块名称、__TEXT segment 的函数占位部分等;main.swift 文件对应的编译单元在 debug_info 数据流中储存了这些属性,如左侧所示;与之对应的,在 debug_addrev 数据流中包含了一个相关的条目,这些条目告诉我们这些值代表了什么,如右侧所示;我们看到图中右侧包含了文件名、语言和一个 low/high 对,用来表述 __TEXT segment 的范围 符号表中找到过已定义的方法,但子程序还可以用来描述静态方法和本地方法;子程序当然也有自己的名称和对应的
符号表中找到过已定义的方法,但子程序还可以用来描述静态方法和本地方法;子程序当然也有自己的名称和对应的 __TEXT segment 地址起始范围 使用树来表述这种关系;编译单元在根节点上,子程序是根节点的孩子节点;这些子节点可以通过他们的地址范围而被检索到;
使用树来表述这种关系;编译单元在根节点上,子程序是根节点的孩子节点;这些子节点可以通过他们的地址范围而被检索到;
我们可以通过 dwarfdump 命令行工具来验证上述 DWARF 的编译单元、子程序和关系树细节
首先我们将查看到一个编译单元,这句之前提到的编译单元所携带的属性相吻合(文件名、语言、行数等),dwarfdump 工具结合了 debug_info 和 debug_abbrev 内容来展示 dSYMs 文件中的数据结构与内容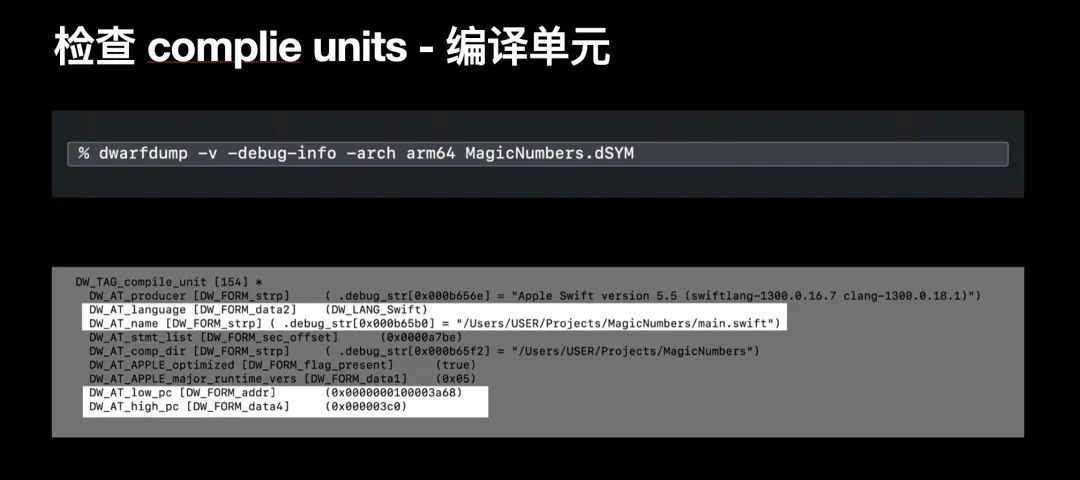
输出很长,我们往下看,会看到一个子程序 subprogram;它所占用的地址范围存在于该编译单元的地址范围内,并且可以看到方法名;之前提到过 DWARF 非常详细的描述符号表和关系信息,我们不会在深入探究 DWARF 的关系树 设计细节,但了解这些细节能够帮助我们理解符号化背后的逻辑;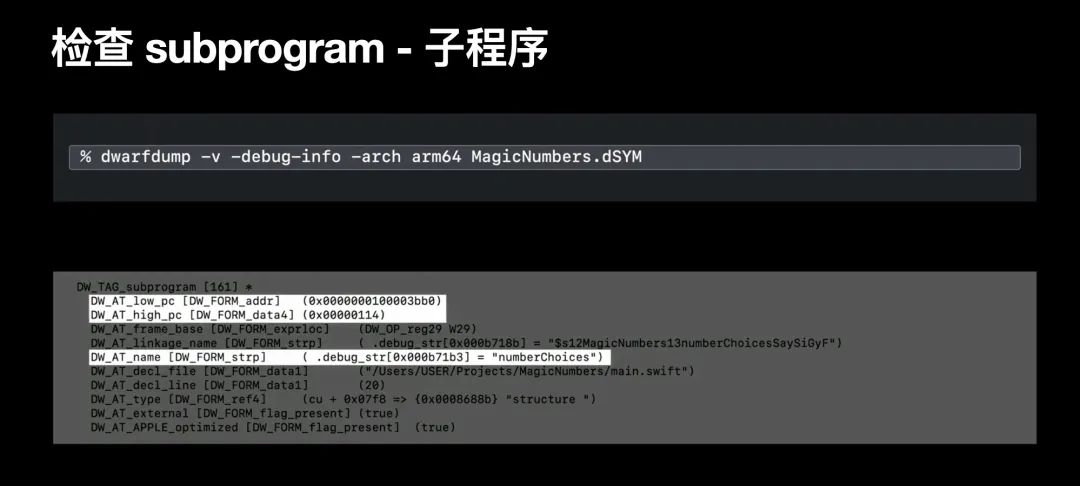
继续往下看输出结果,会发现其中还包括参数信息,DWARF 持有一个自己的词汇表,来描述参数的名称和类型;参数是子程序的一个子节点;下图中的输出,可以发现 numberofChoice 函数的参数 choices 的相关信息;文件名与行数信息
此外,debug_line 数据流中存储了函数关联的文件名和具体行数;但 debug_line 数据流不是树状结构,相反的,该数据流定义了一个 line table program 行表程序,这个航标程序可以让链接后的文件地址映射到源码文件中的具体行数;我们可以利用这个行表程序来查找文件地址关联的具体源码和行数;
综上,基于 debug_info 的树状结构和 debug_line 的行表程序,我们可以得到一个下面的结构;通过遍历这棵树,我们可以找到想要的文件地址;首先从编译单元开始,遍历其子节点,然后筛选出包含 debug_line 的子节点;
命令行工具来完成上述操作,这次我们省略 -i flag,可以看到输出结果少了很多,只剩下方法名、文件名和行数;这里的结果提供了行数,因此我们可以断定我们在使用 DWARF 来进行符号化;但除了文件名和行数,这个输出结果和 nlist 符号表的符号化结果没有太大区别;然后我们再试一试给 atos 加上 -i flag,输出结果是下面第二张图,大家可以对比这两个输出的差异,他们的命令只差了一个 -iatos -o MagicNumbers.dSYM/Contents/Resources/DWARF/MagicNumbers -arch arm64 -l 0x10045c000 0x10045fb70atos -o MagicNumbers.dSYM/Contents/Resources/DWARF/MagicNumbers -arch arm64 -l 0x10045c000 -i 0x10045fb70
-w974 大家也许会猜,这 -i 意味着什么;事实上 atos 的 -i 意味着 inlined function 内联函数,内联化是一种编译器执行的常规优化;详细而言,内联化就是在编译中把函数的实现代码直接替换函数被调用的代码;这样的替换操作可以让函数调用的代码和函数的定义代码都「消失了」;在我们的 Demo 中也就是使用 numberOfChoice() 的实现代码替换了调用代码;numberOfChoice() 调用代码不见了~
使用内联子程序来表述这种编译时内联优化;这就是我们要讨论的第三种 vocabulary list 词汇表类型 :inlined subroutines 内联子程序;内联子程序是子程序的一种,所以他也是一种方法,一种被内联到另一个子程序的方法;所以内联函数在 DWARF 关系树中是子程序的一个子节点;这样的定义意味着会出现递归关系;也就是说一个内联子程序可以有其他内联子程序作为子节点; 再次使用
再次使用 dwarfdump 命令行工具,我们可以来检查一下 DWARF 中的内联子程序;这些内联子程序被列为其他节点的子节点,并且有着与子程序类似的属性,诸如名称和地址;但是在DWARF 文件中,这些属性一般会通过一个公共节点来访问,这种设计叫抽象源;如果存在一个特定函数有很多内联拷贝,则该函数的公共共享属性将存储在抽象源中,如此这些内联函数就不会被重复多余的拷贝;内联子程序有一个独特的属性是 call site 调用位置;该属性表述了在源码中实际调用函数的位置,编译优化器会替换这些函数调用代码;例如,我们在 main.swift 文件中第36行调用了 generateANumber() ,这使得需要在树中新增子节点来记录这个函数调用;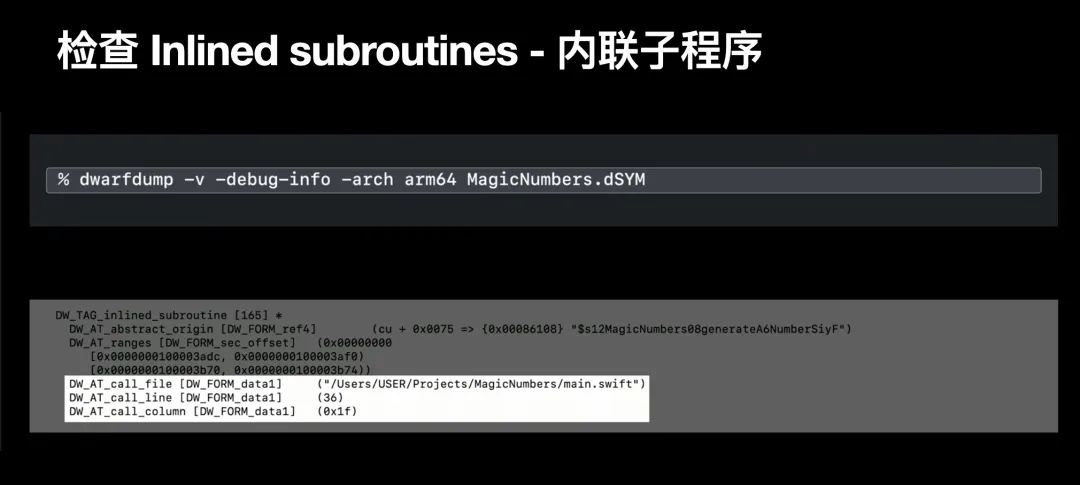
-w1010 到这里,我们对 DWARF 符号化有了更全面的了解,如下图所示,我们对 App 的调用逻辑也有了更广阔的视角。了解内联函数的优化方式和细节是完全符号化崩溃日志的关键所在;-i 指令实际会要求 atos 符号化过程中考虑到上述内联函数;这些内联函数的信息同样在 Instruments 堆栈中缺失;我们在崩溃日志和 Instruments 堆栈中都需要 dSYM 文件,正是由于 dSYM 中精确地包含了上述三种类型的信息:编译单元、子程序和 DWARF 关系树;
文件中,还可以在静态库和目标文件中找到 DWARF;也就是说即使没有 dSYM 文件,你仍然可以从静态库或目标文件中链接的函数,来生成 DWARF;这种情况下,你会找到调试符号表的 nlist 类型,这些本是可以被 strip 剥离的符号类型之一;但这些 nlist 类型并不直接包含 DWARF,相反,他们直接把函数关联到其源码文件;如果一个库在构建中包含调试信息,此时,这些 nlist 条目可以给我们提供 DWARF 的相关信息
上述类型的 nlist 条目可以通过 dsymutil -dump-debug-map 命令行工具来输出和详细查看;在此我们列出了不同函数方法和他们的出处;这些地址信息可以被扫描并处理成 DWARF 文件中所需的信息;
是深度符号化数据的重要来源DWARF 描述了函数与文件之间的重要关系信息;DWARF 妥当处理了编译时内敛优化的问题;dSYM 文件和静态库可以都可包含 DWARF;实践中推荐使用 dSYM 获取 DWARF,因为从 dSYM 中获取的 DWARF 可以方便的在其他工具中使用,并且 Xcode 许多内置工具也支持 DWARF;

dSYM 文件提交至 App Store Connect 的 App,你可以在那下载到 dSYM 即使使用了 bitcode 技术 ,你也可以从 App Store Connect 下载到 dSYM 文件
mdfind 命令行工具检查 dSYM 文件;这个字母数字组成的字符串是编译二进制产物的 UUID,也是运行时 load 指令的唯一标识符;你还可以通过 symbols -uuid 来查看 dSYM 文件的 UUID;
在少数情况下,编译过程会生成一个无效的 DWARF,你可以通过 draftdump -verify 命令来检验 DWARF 的有效性;如果这个检查命令输出任何错误,请直接通过 https://feedbackassistant.apple.com 来进行Developer Tool - 开发工具的 bug 反馈;
单个 DWARF 二进制文件大小上线是 4GB,如果上述校验中报告超过 4GB 的错误,你可以考虑将项目的进行组件化拆分,以便每个组件会有一个较小的 dSYM
实际操作中,通过比较 dSYM 的 UUID 和崩溃日志中 binary image 的 UUID 性来匹配两者;除了在崩溃日志中查看 App 二进制镜像的 UUID ,你还可以通过 symbols 命令行工具来获取 UUID,参照下图;实际符号化中,需要 dSYM 和崩溃日志的 UUID 匹配;
命令行工具还可以帮你检查你 App 编译产物中包含的可用调试信息;输出内容的方括号中的标签,告诉了这些调试信息的来源;当你不知道在调试时使用哪些调试信息时,使用该指令可以看看有哪些调试信息可用;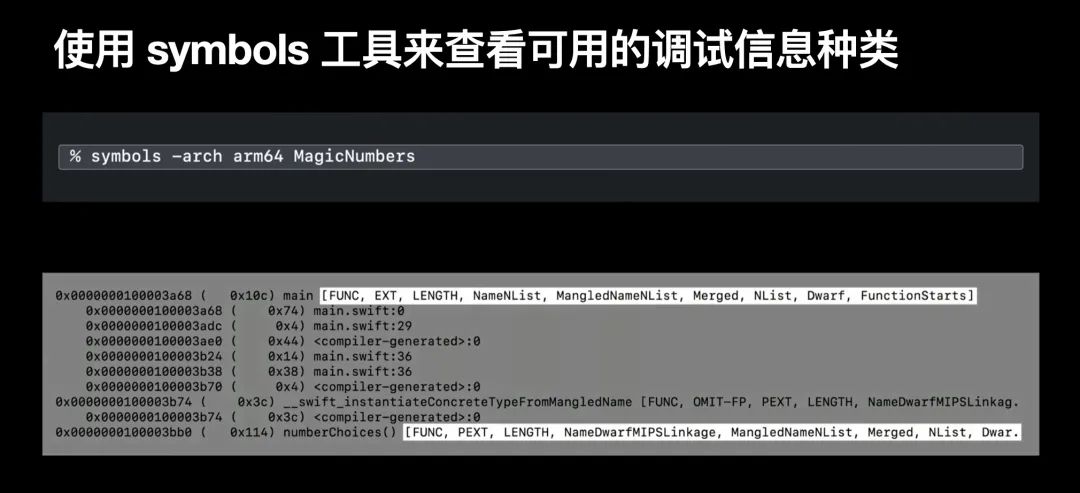
如果你确信已经有可用 dSYM 文件了,但是仍旧未能将 Instruments 中的堆栈信息符号化,请检查一下项目的 Entitlements 和代码签名配置;具体来说使用 codesign 命令行工具,你可以验证是否拥有正确的代码签名配置;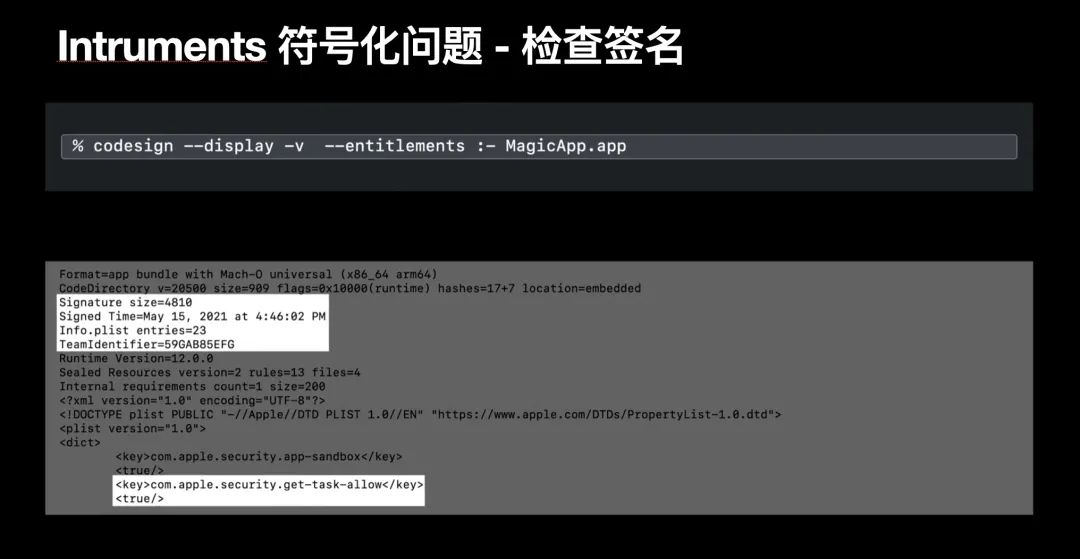
同时,你还需要检查本地开发的 entitlement 中是否包含了 get-task-allow 项,该配置授予 Instruments 这类工具在调试中执行对应 App 符号化的权利;一般来说,Xcode 默认自动会设置这个 get-task-allow 配置项;但 Instruments 不能符号化的时候,可以排查一下这个配置项;如果你发现 entitlement 中没有 get-task-allow ,可以检查确保 build-setting -> code signing -> code signing inject base entitlemens 的值为 true ,来解决该问题;
最后,对于使用 Universal 2 技术的 App, 在使用文章中提到的命令行工具时,都可以指定架构,诸如 symbols、otool、dwarfdump 都有 -arch 的参数可供配置,如此可以只执行特定架构的相关操作;
和文件地址是一致且可靠的方式来识别 App 在运行时的问题,因为这两者不受 ASLR Slide 偏移量的影响;UUID 和文件地址是运行时信息符号化关键的第一步实践中,尽可能利用 dSYM 完成符号化;dSYM 以 DWARF 的形式记录了最丰富细节的调试信息,并且被 Xcode 和 Instruments 所良好支持 文中介绍了几款命令行符号化工具,诸如 otool, vmmap, nm, symbols, dwarfdump, atos;这些工具包含在 Xcode Command line tool中,提供了强大的诊断和检视符号化过程与细节信息的能力;必要时,大家可以将这些工具集成进自己的工作流; 如果你有兴趣学习更多链接与符号化知识,我在此推荐两个WWDC18的Session :他们帮助你了解 App 在启动时如何运行起来,一个是Optimizing app startup time - 优化 App 启动速度,另一个是App startup time: past ,present, and future - App 启动的时间线:过去、现在和将来;
系列是由老司机牵头组织的精品原创内容系列。已经做了几年了,口碑一直不错。主要是针对每年的 WWDC 的内容,做一次精选,并号召一群一线互联网的 iOS 开发者,结合自己的实际开发经验、苹果文档和视频内容做二次创作。今年我们也引入了审核机制,内容和质量上也有了比较大的提升,欢迎订阅。
iOS进阶 - 链接器:符号是怎么绑定到地址上的?
iOS进阶 - 链接器:符号是怎么绑定到地址上的?
链接器的作用就是将符号绑定到地址上。
iOS 为什么使用编译器
iOS 编写的代码是先使用编译器将代码编译成机器码,然后在 CPU 上执行机器码,直接在 CPU 上执行机器码,之所以不用解释器运行代码是因为Apple希望 iPhone 的执行效率更高,运行速度能达到最快。
为什么运用解释器运行代码速度不够快呢?
因为解释器会在运行时解释执行代码,获取一段代码后将会将其翻译成目标代码(也就是字节码 (Bytecode)),然后一句一句地执行目标代码。
也就是说 解释器是在运行时才去解析代码,这样就比编译器直接生成完整的机器码再去执行的效率要低。
两者的特点
- 采用编译器生成机器码执行的好处是效率高,缺点是调试周期长
- 解释器执行的好处是编写调试方便,缺点是执行效率低
iOS 使用的是什么编译器
现在苹果使用的编译器是 LLVM , 相比于Xcode 5 版本的 GCC 编译速度提高了三倍。 LLVM 是编译器工具链技术的一个集合,其中的 LLD 项目就是内置链接器。编译器会对每个文件进行编译,生成 Mach-O (可执行文件);链接器会将项目中的多个 Mach-O 文件合并成一个
编译的主要过程
- 首先,写好代码后, LLVM 会预处理代码,比如把宏嵌入到对应的位置
- 预处理完成后, LLVM 会对代码进行词法分析和语法分析,生成 AST , AST 是抽象语法树,结构上比代码更精简,遍历起来更快,所以使用 AST 能够快速的进行静态检查,同时还能更快地生成生成 IR (中间表示)
- 最后 AST 会生成 IR, IR 是一种更近机器码的语言区别在于和平台无关,通过 IR 可以生成多分适合不同平台的机器码。对于iOS系统,IR 生成的可执行文件就是 Mach-O.
编译时链接器做了什么
Mach-O 文件里的内容主要包含两部分,代码和数据。代码是函数的定义;数据是全局变量的定义,包括全局变量的初始值。不管是代码还是数据,它们的实例都需要由符号将其关联起来。
因为 Mach-O 文件里的那些代码,比如 if、for、while 生成的机器指令序列,要操作的数据会存储在某个地方,变量符号就需要绑定到数据的存储地址。代码还会引用其他的代码,引用的函数符号也需要绑定到该函数的地址上。
链接器的作用,就是完成变量、函数符号和其地址绑定这样的任务,这里所说的符号就可以理解为变量名和函数名。
编译时链接器对代码主要做的事总结而言:
- 去项目文件里查找目标代码文件里没有定义的变量
- 扫描项目中的不同文件,将所有符号定义和引用地址收集起来,并放在全局符号表中
- 计算合并后的长度和位置,生成同类型的段进行合并,建立绑定
- 对项目中不同文件里的变量进行地址重定位
动态库的链接
链接的共用库分为静态库和动态库:静态库是编译时链接的库,需要链接进你的 Mach-O 文件里,如果需要更新就需要重新编译一次,无法动态加载和更新;而动态库是运行时链接的库,使用 dyld 就可以实现动态加载
Mach-O 文件时编译后的产物,而动态库在运行时才会被链接,并没有参与 Mach-O 文件的编译和链接,
而动态库则是使用 dyld 进行加载和链接的:
- 先执行 Mach-O 文件,根据 Mach-O 文件里 undefined 的符号加载对应的动态库,系统会设置一个共享缓存来解决加载的递归依赖问题;
- 加载后,将 undefined 的符号绑定到动态库里对应的地址上
- 最后再处理 +load 方法,main 函数返回后运行 static terminator 。
+load 方法为什么先执行本类的再执行 Category 的呢?
通过 prepare_load_methods 方法可看出,在遍历 Class 的 +load 方法时会执行 schedule_class_load 方法,这个方法会递归到根节点来满足 Class 收集完整关系树的需求。最后,call_load_methods 会创建一个 autoreleasePool 使用函数指针来动态调用类和 Category 的 +load 方法。
小结
项目里文件越多,链接器链接 Mach-O 文件所需要绑定的遍历操作就会越多,编译速度就会越慢。
所以在开发调试阶段可以在代码改完后先不去链接项目里的所有文件,只编译当前修改的文件动态库,通过运行时加载动态库即时更新,看到修改结果。
极客时间-iOS开发高手课 学习笔记
以上是关于iOS 符号化:基础与进阶的主要内容,如果未能解决你的问题,请参考以下文章
function starts 通过编码 __LINKEDIT 二进制段中的 linker 地址列表来提供该功能;function starts 基于直接内置在 App 编译产物中,通过 mach-O 文件的 load 指令的 LC_FUNCTION_STARTS 来描述 function starts;symbols -onlyFuncStartsData 命令行工具来输出 function starts 相关信息,如下图所示,其中的 null 是因为 function starts 不提供函数名称,所以用 null 来做函数名称的占位符;function starts 我们可以对未符号化的崩溃日志进行处理,先从崩溃日志的内存地址 0x10045fb70 减去之前计算好的 ASLR Slide 0x45c000得到 file address 0x100003b70;
然后结合 function starts 输出结果,我们发现只有第一个地址 0x100003a68 小于我们算出的 file address 0x100003b70,所以只有这第一个地址包含了错误发生的地址;基于此我们计算这两个地址之间偏移了 0x108,换算成十进制 是 264,也就是我们 file address 与实际错误发生地址之间有 264 字节的偏移量;function starts 可以帮助我们理解崩溃日志中的函数如何被设置,修改了哪些寄存器;但因为 function starts 不提供函数名,我们只能在低级的机器码层面来分析这些错误日志,对于调试开发 App 来说挺有用,但对于分析错误日志,我们还需要其他工具;nlist 符号表建立在 function starts 和一个编码后的 __LINKEDIT segment 的信息列表,当然 nlist 有自己的 load 指令;与 function starts 不同的是 nlist 不只是编码内存地址,他在其结构体中编码了更多信息;如下图所示,nlist 结构体中包含了名称和其他几个属性,具体而言 nlist 的类型由 n_type 所决定n_type 有三种类型是我们符号化所感兴趣的,这里我们先着重聊一聊其中两种;第一种是 direct symbole - 直接符号;直接符号关联的是在 App 和二方库中,包含了已被完整定义的方法和函数;直接符号在 nlist_64 结构体中存储了函数名字和函数文件地址;
中的指定二进制位的值决定了该 nlist 的类型,具体而言,n_type 中的第二、三、四的二进制位为 1 时,表明该 nlist 类型为直接符号,这三个位的组合还被叫做 N_SECT;我们可以通过 nm -defined-only —numberic-sort 命令行工具来查看 N_SECT;在这里 nm 遍历了 magicNumbers App 的制定符号,并以地址顺序罗列出来,具体参照下图中的输出;注意此处我们还是用了 xcrun -swift-demangle 来解析 Swift mangling 后的函数名称;
上图所示,我们已经可以从结果中获得了方法名 numberChoices()、类名 MagicNumbers、文件名 main;这是因为这些信息直接在 App 内定义;symbols 查看直接符号
和 nm 工具相似, symbols 命令行工具也提供查看 nlist 数据的方法,并且支持自动 demangle ,具体如下图以上两个方法,让我们从崩溃日志中的内存地址,关联到了源码中的具体函数名称,至此,崩溃日志的符号化的信息丰富程度更进一步;至此,我们通过 fuction starts 提供的函数入口偏移地址从 direct symbols 中匹配到一个函数入口,并且这个入口有名字,把这些信息放在一起,我们可以发现 crash 发生在 main 方法地址的 264字节偏移处;但 main 并不是崩溃中唯一的函数,这表明我们还有更多的信息有待挖掘;例如我们还没有弄清楚代码中的行数信息
我们已经弄清 main 并不是唯一与崩溃关联的函数,我们还有更多的信息有待挖掘;例如我们还没获得文件的行数信息;并且在上述符号化中,部分函数被序列化,还有部分堆栈和崩溃日志信息没有被符号化
我们在 Instruments 的堆栈中遇到了类似的情况,一些函数名被符号化而可读,但部分仍是内存地址;发生这种现象的原因是,直接符号表中所包含的函数,只限于在链接时被直接链接的部分,动态库等运行时加载的二进制文件不被包含在内,这些未能符号化的方法就是跨模块从动态库中调用的方法;我们需要其他手段了符号化这些调试信息;
这种直接符号表的逻辑,有助于减少编译产物体积;毕竟换位思考,如果把打包时所有相关函数信息都存入符号表,这种操作才有违常识;对于 Frameworks 和 Libraries,我们需要处理记录那些被调用的方法,而剥离没用到的;当然了如果把直接符号表里的主程序内的函数剥离,那符号表里啥也不剩了;
的编译设置中,strip 配置项有 strip linked product、strip style 、strip swift symbols 三个选项。这些编译设置的选项控制了 App 在编译链接过程中的剥离多余符号表的逻辑;具体来讲,strip linked product 为 YES 时,二进制文件中将根据 strip style 的值进行符号表剥离;举例来说,strip style 值为 all symbols 时,符号表中将执行最激进的剥离策略,最终符号表中只包含最核心的方法;Non globals 类型会剥离应用中不同模块中共同使用的直接符号,但会留下用于其他 APP 中的符号;Debugging symbols 则删除了第三种 nlist 类型的符号,这个后续讨论 DWARF 时会讲到,但该类型的剥离会保留直接用到的符号。-w875 举例来说,这里有一个定义了两个 public interface接口和一个 internal shared 实现的方法的 framework ,由于所有这些函数在链接环节中有用,他们都拥有直接的符号项。
如果我按照 non globals 进行剥离,那只有两个 interface 会留下;由于共享实现的函数只在 framework 内使用,所以它不是全局的,进而也不会被放入符号表;类似的如果是 all symbols 剥离策略时时,如果这两个 interface 有被 framework 外部所调用时,他们仍然会被留下;
symbols —onlyNListData 会输出一些分布在直接符号之间 function starts 的条目;这些条目也表示了函数是存在于直接符号表中,亦或是已经被剥离了。你可以利用这些剥离设定,来实现你需要的符号表可见性;有了这些信息,我们就可以确定什么时候需要直接符号表。在实际应用中,有时候我们能符号化出函数名,但没有具体行数和文件名;或者符号化结果包含了方法名和方法起始地址,正如此处 framework 的 symbols 指令的例子;
的第一位二进制位为 1 ,或称为 n_EXT通过 nm -m -arch arm64 -undefined-only --numberic-sort MagicNumbers 输出间接符号的信息;这其中使用 —undefined-only 来替换 —defined-only ,该指令用于查看间接符号;-m ,这可以让你看到这些方法源自哪个 framework 或 libraries。下面图中的输出结果提示 MagicNumbers App 依赖了 libSwiftCore 中的一系列 Swift 基础方法如 print()。
####小结 - Function starts 与 nlist 符号表
文章开头,我们约定了要讨论 function starts 、nlist 符号表和 DWARF 三种符号化工具;截止现在已经讨论了前两种,在此回顾一下;
Function starts 能提供地址列表,缺少方法名,可以帮助计算崩溃对应的文件地址偏移量;Nlist 符号表把关联到一个地址的详细信息构成结构体存储,nlist 符号能提供函数名称,还可以描述在 App 内定义的直接符号和在二方库中提供的间接符号;直接符号表通常保留与链接有关的函数,Xcode 项目设置中的 strip build style 会影响直接符号表中的内容;这两种符号表都直接嵌入在 App 二进制文件 Mach-O 头中的 __LINKEDIT 二进制段中 DWARF ;相较于 nlist 符号表只保留函数部分信息,DWARF 几乎记录了函数的所有上下文信息;回顾 function starts 只在一个维度上提供偏移量信息;nlist 基于编码 nlist_64 结构体将调试信息升级到两个维度,即地址信息和函数名称;作为比较 DWARF 增加了第三个维度:关系信息;实际项目中函数不是孤立存在的,函数会被调用和在其内部调用其他函数,函数会有出参入参;通过记录这些函数的上下文关系信息;DWARF 会带我们解锁符号化最牛逼的姿势;当我们分析 DWARF 时,一般指的是引用分析一个 dSYM bundle,该 bundle 中存在由元数据组成的 plist,还包括一个 DWARF 二进制文件;二进制文件中将 DWARF 的信息记录在 __DWARF 二进制段中;DWARF 在该二进制段中记录了我们需要关注的三个数据流;具体而言三个数据流分别是 debug_info, debug_abbrev, debug_line ;debug_info 包含了原始数据,debug_abbrev 为原始数据进行了结构化处理,debug_line 包含了文件名和行号;除此之外 DWARF 还定义了需要讨论的两种 vocabulary list 词汇表:compile unit 编译单元和 subprogram 子程序;后文会提到第三种词汇表 - 内联子程序
文件都会有一个编译单元与之对应;DWARF 为每一个编译单元赋予了一些属性,诸如文件名、模块名称、__TEXT segment 的函数占位部分等;main.swift 文件对应的编译单元在 debug_info 数据流中储存了这些属性,如左侧所示;与之对应的,在 debug_addrev 数据流中包含了一个相关的条目,这些条目告诉我们这些值代表了什么,如右侧所示;我们看到图中右侧包含了文件名、语言和一个 low/high 对,用来表述 __TEXT segment 的范围符号表中找到过已定义的方法,但子程序还可以用来描述静态方法和本地方法;子程序当然也有自己的名称和对应的 __TEXT segment 地址起始范围使用树来表述这种关系;编译单元在根节点上,子程序是根节点的孩子节点;这些子节点可以通过他们的地址范围而被检索到;我们可以通过 dwarfdump 命令行工具来验证上述 DWARF 的编译单元、子程序和关系树细节
首先我们将查看到一个编译单元,这句之前提到的编译单元所携带的属性相吻合(文件名、语言、行数等),dwarfdump 工具结合了 debug_info 和 debug_abbrev 内容来展示 dSYMs 文件中的数据结构与内容
输出很长,我们往下看,会看到一个子程序 subprogram;它所占用的地址范围存在于该编译单元的地址范围内,并且可以看到方法名;之前提到过 DWARF 非常详细的描述符号表和关系信息,我们不会在深入探究 DWARF 的关系树 设计细节,但了解这些细节能够帮助我们理解符号化背后的逻辑;
继续往下看输出结果,会发现其中还包括参数信息,DWARF 持有一个自己的词汇表,来描述参数的名称和类型;参数是子程序的一个子节点;下图中的输出,可以发现 numberofChoice 函数的参数 choices 的相关信息;文件名与行数信息
此外,debug_line 数据流中存储了函数关联的文件名和具体行数;但 debug_line 数据流不是树状结构,相反的,该数据流定义了一个 line table program 行表程序,这个航标程序可以让链接后的文件地址映射到源码文件中的具体行数;我们可以利用这个行表程序来查找文件地址关联的具体源码和行数;
综上,基于 debug_info 的树状结构和 debug_line 的行表程序,我们可以得到一个下面的结构;通过遍历这棵树,我们可以找到想要的文件地址;首先从编译单元开始,遍历其子节点,然后筛选出包含 debug_line 的子节点;
命令行工具来完成上述操作,这次我们省略 -i flag,可以看到输出结果少了很多,只剩下方法名、文件名和行数;这里的结果提供了行数,因此我们可以断定我们在使用 DWARF 来进行符号化;但除了文件名和行数,这个输出结果和 nlist 符号表的符号化结果没有太大区别;然后我们再试一试给 atos 加上 -i flag,输出结果是下面第二张图,大家可以对比这两个输出的差异,他们的命令只差了一个 -iatos -o MagicNumbers.dSYM/Contents/Resources/DWARF/MagicNumbers -arch arm64 -l 0x10045c000 0x10045fb70atos -o MagicNumbers.dSYM/Contents/Resources/DWARF/MagicNumbers -arch arm64 -l 0x10045c000 -i 0x10045fb70-w974 大家也许会猜,这 -i 意味着什么;事实上 atos 的 -i 意味着 inlined function 内联函数,内联化是一种编译器执行的常规优化;详细而言,内联化就是在编译中把函数的实现代码直接替换函数被调用的代码;这样的替换操作可以让函数调用的代码和函数的定义代码都「消失了」;在我们的 Demo 中也就是使用 numberOfChoice() 的实现代码替换了调用代码;numberOfChoice() 调用代码不见了~
使用内联子程序来表述这种编译时内联优化;这就是我们要讨论的第三种 vocabulary list 词汇表类型 :inlined subroutines 内联子程序;内联子程序是子程序的一种,所以他也是一种方法,一种被内联到另一个子程序的方法;所以内联函数在 DWARF 关系树中是子程序的一个子节点;这样的定义意味着会出现递归关系;也就是说一个内联子程序可以有其他内联子程序作为子节点;再次使用 dwarfdump 命令行工具,我们可以来检查一下 DWARF 中的内联子程序;这些内联子程序被列为其他节点的子节点,并且有着与子程序类似的属性,诸如名称和地址;但是在DWARF 文件中,这些属性一般会通过一个公共节点来访问,这种设计叫抽象源;如果存在一个特定函数有很多内联拷贝,则该函数的公共共享属性将存储在抽象源中,如此这些内联函数就不会被重复多余的拷贝;内联子程序有一个独特的属性是 call site 调用位置;该属性表述了在源码中实际调用函数的位置,编译优化器会替换这些函数调用代码;例如,我们在 main.swift 文件中第36行调用了 generateANumber() ,这使得需要在树中新增子节点来记录这个函数调用;-w1010 到这里,我们对 DWARF 符号化有了更全面的了解,如下图所示,我们对 App 的调用逻辑也有了更广阔的视角。了解内联函数的优化方式和细节是完全符号化崩溃日志的关键所在;-i 指令实际会要求 atos 符号化过程中考虑到上述内联函数;这些内联函数的信息同样在 Instruments 堆栈中缺失;我们在崩溃日志和 Instruments 堆栈中都需要 dSYM 文件,正是由于 dSYM 中精确地包含了上述三种类型的信息:编译单元、子程序和 DWARF 关系树;
文件中,还可以在静态库和目标文件中找到 DWARF;也就是说即使没有 dSYM 文件,你仍然可以从静态库或目标文件中链接的函数,来生成 DWARF;这种情况下,你会找到调试符号表的 nlist 类型,这些本是可以被 strip 剥离的符号类型之一;但这些 nlist 类型并不直接包含 DWARF,相反,他们直接把函数关联到其源码文件;如果一个库在构建中包含调试信息,此时,这些 nlist 条目可以给我们提供 DWARF 的相关信息上述类型的 nlist 条目可以通过 dsymutil -dump-debug-map 命令行工具来输出和详细查看;在此我们列出了不同函数方法和他们的出处;这些地址信息可以被扫描并处理成 DWARF 文件中所需的信息;
是深度符号化数据的重要来源DWARF 描述了函数与文件之间的重要关系信息;DWARF 妥当处理了编译时内敛优化的问题;dSYM 文件和静态库可以都可包含 DWARF;实践中推荐使用 dSYM 获取 DWARF,因为从 dSYM 中获取的 DWARF 可以方便的在其他工具中使用,并且 Xcode 许多内置工具也支持 DWARF;
dSYM 文件提交至 App Store Connect 的 App,你可以在那下载到 dSYM 即使使用了 bitcode 技术 ,你也可以从 App Store Connect 下载到 dSYM 文件 mdfind 命令行工具检查 dSYM 文件;这个字母数字组成的字符串是编译二进制产物的 UUID,也是运行时 load 指令的唯一标识符;你还可以通过 symbols -uuid 来查看 dSYM 文件的 UUID;在少数情况下,编译过程会生成一个无效的 DWARF,你可以通过 draftdump -verify 命令来检验 DWARF 的有效性;如果这个检查命令输出任何错误,请直接通过 https://feedbackassistant.apple.com 来进行Developer Tool - 开发工具的 bug 反馈;
单个 DWARF 二进制文件大小上线是 4GB,如果上述校验中报告超过 4GB 的错误,你可以考虑将项目的进行组件化拆分,以便每个组件会有一个较小的 dSYM
实际操作中,通过比较 dSYM 的 UUID 和崩溃日志中 binary image 的 UUID 性来匹配两者;除了在崩溃日志中查看 App 二进制镜像的 UUID ,你还可以通过 symbols 命令行工具来获取 UUID,参照下图;实际符号化中,需要 dSYM 和崩溃日志的 UUID 匹配;
命令行工具还可以帮你检查你 App 编译产物中包含的可用调试信息;输出内容的方括号中的标签,告诉了这些调试信息的来源;当你不知道在调试时使用哪些调试信息时,使用该指令可以看看有哪些调试信息可用;如果你确信已经有可用 dSYM 文件了,但是仍旧未能将 Instruments 中的堆栈信息符号化,请检查一下项目的 Entitlements 和代码签名配置;具体来说使用 codesign 命令行工具,你可以验证是否拥有正确的代码签名配置;
同时,你还需要检查本地开发的 entitlement 中是否包含了 get-task-allow 项,该配置授予 Instruments 这类工具在调试中执行对应 App 符号化的权利;一般来说,Xcode 默认自动会设置这个 get-task-allow 配置项;但 Instruments 不能符号化的时候,可以排查一下这个配置项;如果你发现 entitlement 中没有 get-task-allow ,可以检查确保 build-setting -> code signing -> code signing inject base entitlemens 的值为 true ,来解决该问题;
最后,对于使用 Universal 2 技术的 App, 在使用文章中提到的命令行工具时,都可以指定架构,诸如 symbols、otool、dwarfdump 都有 -arch 的参数可供配置,如此可以只执行特定架构的相关操作;
和文件地址是一致且可靠的方式来识别 App 在运行时的问题,因为这两者不受 ASLR Slide 偏移量的影响;UUID 和文件地址是运行时信息符号化关键的第一步实践中,尽可能利用 dSYM 完成符号化;dSYM 以 DWARF 的形式记录了最丰富细节的调试信息,并且被 Xcode 和 Instruments 所良好支持 文中介绍了几款命令行符号化工具,诸如 otool, vmmap, nm, symbols, dwarfdump, atos;这些工具包含在 Xcode Command line tool中,提供了强大的诊断和检视符号化过程与细节信息的能力;必要时,大家可以将这些工具集成进自己的工作流; 如果你有兴趣学习更多链接与符号化知识,我在此推荐两个WWDC18的Session :他们帮助你了解 App 在启动时如何运行起来,一个是Optimizing app startup time - 优化 App 启动速度,另一个是App startup time: past ,present, and future - App 启动的时间线:过去、现在和将来;
系列是由老司机牵头组织的精品原创内容系列。已经做了几年了,口碑一直不错。主要是针对每年的 WWDC 的内容,做一次精选,并号召一群一线互联网的 iOS 开发者,结合自己的实际开发经验、苹果文档和视频内容做二次创作。今年我们也引入了审核机制,内容和质量上也有了比较大的提升,欢迎订阅。
iOS进阶 - 链接器:符号是怎么绑定到地址上的?
iOS进阶 - 链接器:符号是怎么绑定到地址上的?
链接器的作用就是将符号绑定到地址上。
iOS 为什么使用编译器
iOS 编写的代码是先使用编译器将代码编译成机器码,然后在 CPU 上执行机器码,直接在 CPU 上执行机器码,之所以不用解释器运行代码是因为Apple希望 iPhone 的执行效率更高,运行速度能达到最快。
为什么运用解释器运行代码速度不够快呢?
因为解释器会在运行时解释执行代码,获取一段代码后将会将其翻译成目标代码(也就是字节码 (Bytecode)),然后一句一句地执行目标代码。
也就是说 解释器是在运行时才去解析代码,这样就比编译器直接生成完整的机器码再去执行的效率要低。
两者的特点
- 采用编译器生成机器码执行的好处是效率高,缺点是调试周期长
- 解释器执行的好处是编写调试方便,缺点是执行效率低
iOS 使用的是什么编译器
现在苹果使用的编译器是 LLVM , 相比于Xcode 5 版本的 GCC 编译速度提高了三倍。 LLVM 是编译器工具链技术的一个集合,其中的 LLD 项目就是内置链接器。编译器会对每个文件进行编译,生成 Mach-O (可执行文件);链接器会将项目中的多个 Mach-O 文件合并成一个
编译的主要过程
- 首先,写好代码后, LLVM 会预处理代码,比如把宏嵌入到对应的位置
- 预处理完成后, LLVM 会对代码进行词法分析和语法分析,生成 AST , AST 是抽象语法树,结构上比代码更精简,遍历起来更快,所以使用 AST 能够快速的进行静态检查,同时还能更快地生成生成 IR (中间表示)
- 最后 AST 会生成 IR, IR 是一种更近机器码的语言区别在于和平台无关,通过 IR 可以生成多分适合不同平台的机器码。对于iOS系统,IR 生成的可执行文件就是 Mach-O.
编译时链接器做了什么
Mach-O 文件里的内容主要包含两部分,代码和数据。代码是函数的定义;数据是全局变量的定义,包括全局变量的初始值。不管是代码还是数据,它们的实例都需要由符号将其关联起来。
因为 Mach-O 文件里的那些代码,比如 if、for、while 生成的机器指令序列,要操作的数据会存储在某个地方,变量符号就需要绑定到数据的存储地址。代码还会引用其他的代码,引用的函数符号也需要绑定到该函数的地址上。
链接器的作用,就是完成变量、函数符号和其地址绑定这样的任务,这里所说的符号就可以理解为变量名和函数名。
编译时链接器对代码主要做的事总结而言:
- 去项目文件里查找目标代码文件里没有定义的变量
- 扫描项目中的不同文件,将所有符号定义和引用地址收集起来,并放在全局符号表中
- 计算合并后的长度和位置,生成同类型的段进行合并,建立绑定
- 对项目中不同文件里的变量进行地址重定位
动态库的链接
链接的共用库分为静态库和动态库:静态库是编译时链接的库,需要链接进你的 Mach-O 文件里,如果需要更新就需要重新编译一次,无法动态加载和更新;而动态库是运行时链接的库,使用 dyld 就可以实现动态加载
Mach-O 文件时编译后的产物,而动态库在运行时才会被链接,并没有参与 Mach-O 文件的编译和链接,
而动态库则是使用 dyld 进行加载和链接的:
- 先执行 Mach-O 文件,根据 Mach-O 文件里 undefined 的符号加载对应的动态库,系统会设置一个共享缓存来解决加载的递归依赖问题;
- 加载后,将 undefined 的符号绑定到动态库里对应的地址上
- 最后再处理 +load 方法,main 函数返回后运行 static terminator 。
+load 方法为什么先执行本类的再执行 Category 的呢?
通过 prepare_load_methods 方法可看出,在遍历 Class 的 +load 方法时会执行 schedule_class_load 方法,这个方法会递归到根节点来满足 Class 收集完整关系树的需求。最后,call_load_methods 会创建一个 autoreleasePool 使用函数指针来动态调用类和 Category 的 +load 方法。
小结
项目里文件越多,链接器链接 Mach-O 文件所需要绑定的遍历操作就会越多,编译速度就会越慢。
所以在开发调试阶段可以在代码改完后先不去链接项目里的所有文件,只编译当前修改的文件动态库,通过运行时加载动态库即时更新,看到修改结果。
极客时间-iOS开发高手课 学习笔记
以上是关于iOS 符号化:基础与进阶的主要内容,如果未能解决你的问题,请参考以下文章
nm -defined-only —numberic-sort 命令行工具来查看 N_SECT;在这里 nm 遍历了 magicNumbers App 的制定符号,并以地址顺序罗列出来,具体参照下图中的输出;注意此处我们还是用了 xcrun -swift-demangle 来解析 Swift mangling 后的函数名称;numberChoices()、类名 MagicNumbers、文件名 main;这是因为这些信息直接在 App 内定义;symbols 查看直接符号
和 nm 工具相似, symbols 命令行工具也提供查看 nlist 数据的方法,并且支持自动 demangle ,具体如下图以上两个方法,让我们从崩溃日志中的内存地址,关联到了源码中的具体函数名称,至此,崩溃日志的符号化的信息丰富程度更进一步;至此,我们通过 fuction starts 提供的函数入口偏移地址从 direct symbols 中匹配到一个函数入口,并且这个入口有名字,把这些信息放在一起,我们可以发现 crash 发生在 main 方法地址的 264字节偏移处;但 main 并不是崩溃中唯一的函数,这表明我们还有更多的信息有待挖掘;例如我们还没有弄清楚代码中的行数信息main 并不是唯一与崩溃关联的函数,我们还有更多的信息有待挖掘;例如我们还没获得文件的行数信息;并且在上述符号化中,部分函数被序列化,还有部分堆栈和崩溃日志信息没有被符号化Instruments 的堆栈中遇到了类似的情况,一些函数名被符号化而可读,但部分仍是内存地址;发生这种现象的原因是,直接符号表中所包含的函数,只限于在链接时被直接链接的部分,动态库等运行时加载的二进制文件不被包含在内,这些未能符号化的方法就是跨模块从动态库中调用的方法;我们需要其他手段了符号化这些调试信息;Frameworks 和 Libraries,我们需要处理记录那些被调用的方法,而剥离没用到的;当然了如果把直接符号表里的主程序内的函数剥离,那符号表里啥也不剩了;strip 配置项有 strip linked product、strip style 、strip swift symbols 三个选项。这些编译设置的选项控制了 App 在编译链接过程中的剥离多余符号表的逻辑;具体来讲,strip linked product 为 YES 时,二进制文件中将根据 strip style 的值进行符号表剥离;举例来说,strip style 值为 all symbols 时,符号表中将执行最激进的剥离策略,最终符号表中只包含最核心的方法;Non globals 类型会剥离应用中不同模块中共同使用的直接符号,但会留下用于其他 APP 中的符号;Debugging symbols 则删除了第三种 nlist 类型的符号,这个后续讨论 DWARF 时会讲到,但该类型的剥离会保留直接用到的符号。举例来说,这里有一个定义了两个 public interface接口和一个 internal shared 实现的方法的 framework ,由于所有这些函数在链接环节中有用,他们都拥有直接的符号项。
如果我按照 non globals 进行剥离,那只有两个 interface 会留下;由于共享实现的函数只在 framework 内使用,所以它不是全局的,进而也不会被放入符号表;类似的如果是 all symbols 剥离策略时时,如果这两个 interface 有被 framework 外部所调用时,他们仍然会被留下;
symbols —onlyNListData 会输出一些分布在直接符号之间 function starts 的条目;这些条目也表示了函数是存在于直接符号表中,亦或是已经被剥离了。你可以利用这些剥离设定,来实现你需要的符号表可见性;有了这些信息,我们就可以确定什么时候需要直接符号表。在实际应用中,有时候我们能符号化出函数名,但没有具体行数和文件名;或者符号化结果包含了方法名和方法起始地址,正如此处 framework 的 symbols 指令的例子;
的第一位二进制位为 1 ,或称为 n_EXT通过 nm -m -arch arm64 -undefined-only --numberic-sort MagicNumbers 输出间接符号的信息;这其中使用 —undefined-only 来替换 —defined-only ,该指令用于查看间接符号;-m ,这可以让你看到这些方法源自哪个 framework 或 libraries。下面图中的输出结果提示 MagicNumbers App 依赖了 libSwiftCore 中的一系列 Swift 基础方法如 print()。
####小结 - Function starts 与 nlist 符号表
文章开头,我们约定了要讨论 function starts 、nlist 符号表和 DWARF 三种符号化工具;截止现在已经讨论了前两种,在此回顾一下;
Function starts 能提供地址列表,缺少方法名,可以帮助计算崩溃对应的文件地址偏移量;Nlist 符号表把关联到一个地址的详细信息构成结构体存储,nlist 符号能提供函数名称,还可以描述在 App 内定义的直接符号和在二方库中提供的间接符号;直接符号表通常保留与链接有关的函数,Xcode 项目设置中的 strip build style 会影响直接符号表中的内容;这两种符号表都直接嵌入在 App 二进制文件 Mach-O 头中的 __LINKEDIT 二进制段中 DWARF ;相较于 nlist 符号表只保留函数部分信息,DWARF 几乎记录了函数的所有上下文信息;回顾 function starts 只在一个维度上提供偏移量信息;nlist 基于编码 nlist_64 结构体将调试信息升级到两个维度,即地址信息和函数名称;作为比较 DWARF 增加了第三个维度:关系信息;实际项目中函数不是孤立存在的,函数会被调用和在其内部调用其他函数,函数会有出参入参;通过记录这些函数的上下文关系信息;DWARF 会带我们解锁符号化最牛逼的姿势;当我们分析 DWARF 时,一般指的是引用分析一个 dSYM bundle,该 bundle 中存在由元数据组成的 plist,还包括一个 DWARF 二进制文件;二进制文件中将 DWARF 的信息记录在 __DWARF 二进制段中;DWARF 在该二进制段中记录了我们需要关注的三个数据流;具体而言三个数据流分别是 debug_info, debug_abbrev, debug_line ;debug_info 包含了原始数据,debug_abbrev 为原始数据进行了结构化处理,debug_line 包含了文件名和行号;除此之外 DWARF 还定义了需要讨论的两种 vocabulary list 词汇表:compile unit 编译单元和 subprogram 子程序;后文会提到第三种词汇表 - 内联子程序
文件都会有一个编译单元与之对应;DWARF 为每一个编译单元赋予了一些属性,诸如文件名、模块名称、__TEXT segment 的函数占位部分等;main.swift 文件对应的编译单元在 debug_info 数据流中储存了这些属性,如左侧所示;与之对应的,在 debug_addrev 数据流中包含了一个相关的条目,这些条目告诉我们这些值代表了什么,如右侧所示;我们看到图中右侧包含了文件名、语言和一个 low/high 对,用来表述 __TEXT segment 的范围符号表中找到过已定义的方法,但子程序还可以用来描述静态方法和本地方法;子程序当然也有自己的名称和对应的 __TEXT segment 地址起始范围使用树来表述这种关系;编译单元在根节点上,子程序是根节点的孩子节点;这些子节点可以通过他们的地址范围而被检索到;我们可以通过 dwarfdump 命令行工具来验证上述 DWARF 的编译单元、子程序和关系树细节
首先我们将查看到一个编译单元,这句之前提到的编译单元所携带的属性相吻合(文件名、语言、行数等),dwarfdump 工具结合了 debug_info 和 debug_abbrev 内容来展示 dSYMs 文件中的数据结构与内容
输出很长,我们往下看,会看到一个子程序 subprogram;它所占用的地址范围存在于该编译单元的地址范围内,并且可以看到方法名;之前提到过 DWARF 非常详细的描述符号表和关系信息,我们不会在深入探究 DWARF 的关系树 设计细节,但了解这些细节能够帮助我们理解符号化背后的逻辑;
继续往下看输出结果,会发现其中还包括参数信息,DWARF 持有一个自己的词汇表,来描述参数的名称和类型;参数是子程序的一个子节点;下图中的输出,可以发现 numberofChoice 函数的参数 choices 的相关信息;文件名与行数信息
此外,debug_line 数据流中存储了函数关联的文件名和具体行数;但 debug_line 数据流不是树状结构,相反的,该数据流定义了一个 line table program 行表程序,这个航标程序可以让链接后的文件地址映射到源码文件中的具体行数;我们可以利用这个行表程序来查找文件地址关联的具体源码和行数;
综上,基于 debug_info 的树状结构和 debug_line 的行表程序,我们可以得到一个下面的结构;通过遍历这棵树,我们可以找到想要的文件地址;首先从编译单元开始,遍历其子节点,然后筛选出包含 debug_line 的子节点;
命令行工具来完成上述操作,这次我们省略 -i flag,可以看到输出结果少了很多,只剩下方法名、文件名和行数;这里的结果提供了行数,因此我们可以断定我们在使用 DWARF 来进行符号化;但除了文件名和行数,这个输出结果和 nlist 符号表的符号化结果没有太大区别;然后我们再试一试给 atos 加上 -i flag,输出结果是下面第二张图,大家可以对比这两个输出的差异,他们的命令只差了一个 -iatos -o MagicNumbers.dSYM/Contents/Resources/DWARF/MagicNumbers -arch arm64 -l 0x10045c000 0x10045fb70atos -o MagicNumbers.dSYM/Contents/Resources/DWARF/MagicNumbers -arch arm64 -l 0x10045c000 -i 0x10045fb70-w974 大家也许会猜,这 -i 意味着什么;事实上 atos 的 -i 意味着 inlined function 内联函数,内联化是一种编译器执行的常规优化;详细而言,内联化就是在编译中把函数的实现代码直接替换函数被调用的代码;这样的替换操作可以让函数调用的代码和函数的定义代码都「消失了」;在我们的 Demo 中也就是使用 numberOfChoice() 的实现代码替换了调用代码;numberOfChoice() 调用代码不见了~
使用内联子程序来表述这种编译时内联优化;这就是我们要讨论的第三种 vocabulary list 词汇表类型 :inlined subroutines 内联子程序;内联子程序是子程序的一种,所以他也是一种方法,一种被内联到另一个子程序的方法;所以内联函数在 DWARF 关系树中是子程序的一个子节点;这样的定义意味着会出现递归关系;也就是说一个内联子程序可以有其他内联子程序作为子节点;再次使用 dwarfdump 命令行工具,我们可以来检查一下 DWARF 中的内联子程序;这些内联子程序被列为其他节点的子节点,并且有着与子程序类似的属性,诸如名称和地址;但是在DWARF 文件中,这些属性一般会通过一个公共节点来访问,这种设计叫抽象源;如果存在一个特定函数有很多内联拷贝,则该函数的公共共享属性将存储在抽象源中,如此这些内联函数就不会被重复多余的拷贝;内联子程序有一个独特的属性是 call site 调用位置;该属性表述了在源码中实际调用函数的位置,编译优化器会替换这些函数调用代码;例如,我们在 main.swift 文件中第36行调用了 generateANumber() ,这使得需要在树中新增子节点来记录这个函数调用;-w1010 到这里,我们对 DWARF 符号化有了更全面的了解,如下图所示,我们对 App 的调用逻辑也有了更广阔的视角。了解内联函数的优化方式和细节是完全符号化崩溃日志的关键所在;-i 指令实际会要求 atos 符号化过程中考虑到上述内联函数;这些内联函数的信息同样在 Instruments 堆栈中缺失;我们在崩溃日志和 Instruments 堆栈中都需要 dSYM 文件,正是由于 dSYM 中精确地包含了上述三种类型的信息:编译单元、子程序和 DWARF 关系树;
文件中,还可以在静态库和目标文件中找到 DWARF;也就是说即使没有 dSYM 文件,你仍然可以从静态库或目标文件中链接的函数,来生成 DWARF;这种情况下,你会找到调试符号表的 nlist 类型,这些本是可以被 strip 剥离的符号类型之一;但这些 nlist 类型并不直接包含 DWARF,相反,他们直接把函数关联到其源码文件;如果一个库在构建中包含调试信息,此时,这些 nlist 条目可以给我们提供 DWARF 的相关信息上述类型的 nlist 条目可以通过 dsymutil -dump-debug-map 命令行工具来输出和详细查看;在此我们列出了不同函数方法和他们的出处;这些地址信息可以被扫描并处理成 DWARF 文件中所需的信息;
是深度符号化数据的重要来源DWARF 描述了函数与文件之间的重要关系信息;DWARF 妥当处理了编译时内敛优化的问题;dSYM 文件和静态库可以都可包含 DWARF;实践中推荐使用 dSYM 获取 DWARF,因为从 dSYM 中获取的 DWARF 可以方便的在其他工具中使用,并且 Xcode 许多内置工具也支持 DWARF;
dSYM 文件提交至 App Store Connect 的 App,你可以在那下载到 dSYM 即使使用了 bitcode 技术 ,你也可以从 App Store Connect 下载到 dSYM 文件 mdfind 命令行工具检查 dSYM 文件;这个字母数字组成的字符串是编译二进制产物的 UUID,也是运行时 load 指令的唯一标识符;你还可以通过 symbols -uuid 来查看 dSYM 文件的 UUID;在少数情况下,编译过程会生成一个无效的 DWARF,你可以通过 draftdump -verify 命令来检验 DWARF 的有效性;如果这个检查命令输出任何错误,请直接通过 https://feedbackassistant.apple.com 来进行Developer Tool - 开发工具的 bug 反馈;
单个 DWARF 二进制文件大小上线是 4GB,如果上述校验中报告超过 4GB 的错误,你可以考虑将项目的进行组件化拆分,以便每个组件会有一个较小的 dSYM
实际操作中,通过比较 dSYM 的 UUID 和崩溃日志中 binary image 的 UUID 性来匹配两者;除了在崩溃日志中查看 App 二进制镜像的 UUID ,你还可以通过 symbols 命令行工具来获取 UUID,参照下图;实际符号化中,需要 dSYM 和崩溃日志的 UUID 匹配;
命令行工具还可以帮你检查你 App 编译产物中包含的可用调试信息;输出内容的方括号中的标签,告诉了这些调试信息的来源;当你不知道在调试时使用哪些调试信息时,使用该指令可以看看有哪些调试信息可用;如果你确信已经有可用 dSYM 文件了,但是仍旧未能将 Instruments 中的堆栈信息符号化,请检查一下项目的 Entitlements 和代码签名配置;具体来说使用 codesign 命令行工具,你可以验证是否拥有正确的代码签名配置;
同时,你还需要检查本地开发的 entitlement 中是否包含了 get-task-allow 项,该配置授予 Instruments 这类工具在调试中执行对应 App 符号化的权利;一般来说,Xcode 默认自动会设置这个 get-task-allow 配置项;但 Instruments 不能符号化的时候,可以排查一下这个配置项;如果你发现 entitlement 中没有 get-task-allow ,可以检查确保 build-setting -> code signing -> code signing inject base entitlemens 的值为 true ,来解决该问题;
最后,对于使用 Universal 2 技术的 App, 在使用文章中提到的命令行工具时,都可以指定架构,诸如 symbols、otool、dwarfdump 都有 -arch 的参数可供配置,如此可以只执行特定架构的相关操作;
和文件地址是一致且可靠的方式来识别 App 在运行时的问题,因为这两者不受 ASLR Slide 偏移量的影响;UUID 和文件地址是运行时信息符号化关键的第一步实践中,尽可能利用 dSYM 完成符号化;dSYM 以 DWARF 的形式记录了最丰富细节的调试信息,并且被 Xcode 和 Instruments 所良好支持 文中介绍了几款命令行符号化工具,诸如 otool, vmmap, nm, symbols, dwarfdump, atos;这些工具包含在 Xcode Command line tool中,提供了强大的诊断和检视符号化过程与细节信息的能力;必要时,大家可以将这些工具集成进自己的工作流; 如果你有兴趣学习更多链接与符号化知识,我在此推荐两个WWDC18的Session :他们帮助你了解 App 在启动时如何运行起来,一个是Optimizing app startup time - 优化 App 启动速度,另一个是App startup time: past ,present, and future - App 启动的时间线:过去、现在和将来;
系列是由老司机牵头组织的精品原创内容系列。已经做了几年了,口碑一直不错。主要是针对每年的 WWDC 的内容,做一次精选,并号召一群一线互联网的 iOS 开发者,结合自己的实际开发经验、苹果文档和视频内容做二次创作。今年我们也引入了审核机制,内容和质量上也有了比较大的提升,欢迎订阅。
iOS进阶 - 链接器:符号是怎么绑定到地址上的?
iOS进阶 - 链接器:符号是怎么绑定到地址上的?
链接器的作用就是将符号绑定到地址上。
iOS 为什么使用编译器
iOS 编写的代码是先使用编译器将代码编译成机器码,然后在 CPU 上执行机器码,直接在 CPU 上执行机器码,之所以不用解释器运行代码是因为Apple希望 iPhone 的执行效率更高,运行速度能达到最快。
为什么运用解释器运行代码速度不够快呢?
因为解释器会在运行时解释执行代码,获取一段代码后将会将其翻译成目标代码(也就是字节码 (Bytecode)),然后一句一句地执行目标代码。
也就是说 解释器是在运行时才去解析代码,这样就比编译器直接生成完整的机器码再去执行的效率要低。
两者的特点
- 采用编译器生成机器码执行的好处是效率高,缺点是调试周期长
- 解释器执行的好处是编写调试方便,缺点是执行效率低
iOS 使用的是什么编译器
现在苹果使用的编译器是 LLVM , 相比于Xcode 5 版本的 GCC 编译速度提高了三倍。 LLVM 是编译器工具链技术的一个集合,其中的 LLD 项目就是内置链接器。编译器会对每个文件进行编译,生成 Mach-O (可执行文件);链接器会将项目中的多个 Mach-O 文件合并成一个
编译的主要过程
- 首先,写好代码后, LLVM 会预处理代码,比如把宏嵌入到对应的位置
- 预处理完成后, LLVM 会对代码进行词法分析和语法分析,生成 AST , AST 是抽象语法树,结构上比代码更精简,遍历起来更快,所以使用 AST 能够快速的进行静态检查,同时还能更快地生成生成 IR (中间表示)
- 最后 AST 会生成 IR, IR 是一种更近机器码的语言区别在于和平台无关,通过 IR 可以生成多分适合不同平台的机器码。对于iOS系统,IR 生成的可执行文件就是 Mach-O.
编译时链接器做了什么
Mach-O 文件里的内容主要包含两部分,代码和数据。代码是函数的定义;数据是全局变量的定义,包括全局变量的初始值。不管是代码还是数据,它们的实例都需要由符号将其关联起来。
因为 Mach-O 文件里的那些代码,比如 if、for、while 生成的机器指令序列,要操作的数据会存储在某个地方,变量符号就需要绑定到数据的存储地址。代码还会引用其他的代码,引用的函数符号也需要绑定到该函数的地址上。
链接器的作用,就是完成变量、函数符号和其地址绑定这样的任务,这里所说的符号就可以理解为变量名和函数名。
编译时链接器对代码主要做的事总结而言:
- 去项目文件里查找目标代码文件里没有定义的变量
- 扫描项目中的不同文件,将所有符号定义和引用地址收集起来,并放在全局符号表中
- 计算合并后的长度和位置,生成同类型的段进行合并,建立绑定
- 对项目中不同文件里的变量进行地址重定位
动态库的链接
链接的共用库分为静态库和动态库:静态库是编译时链接的库,需要链接进你的 Mach-O 文件里,如果需要更新就需要重新编译一次,无法动态加载和更新;而动态库是运行时链接的库,使用 dyld 就可以实现动态加载
Mach-O 文件时编译后的产物,而动态库在运行时才会被链接,并没有参与 Mach-O 文件的编译和链接,
而动态库则是使用 dyld 进行加载和链接的:
- 先执行 Mach-O 文件,根据 Mach-O 文件里 undefined 的符号加载对应的动态库,系统会设置一个共享缓存来解决加载的递归依赖问题;
- 加载后,将 undefined 的符号绑定到动态库里对应的地址上
- 最后再处理 +load 方法,main 函数返回后运行 static terminator 。
+load 方法为什么先执行本类的再执行 Category 的呢?
通过 prepare_load_methods 方法可看出,在遍历 Class 的 +load 方法时会执行 schedule_class_load 方法,这个方法会递归到根节点来满足 Class 收集完整关系树的需求。最后,call_load_methods 会创建一个 autoreleasePool 使用函数指针来动态调用类和 Category 的 +load 方法。
小结
项目里文件越多,链接器链接 Mach-O 文件所需要绑定的遍历操作就会越多,编译速度就会越慢。
所以在开发调试阶段可以在代码改完后先不去链接项目里的所有文件,只编译当前修改的文件动态库,通过运行时加载动态库即时更新,看到修改结果。
极客时间-iOS开发高手课 学习笔记
以上是关于iOS 符号化:基础与进阶的主要内容,如果未能解决你的问题,请参考以下文章
nm -m -arch arm64 -undefined-only --numberic-sort MagicNumbers 输出间接符号的信息;这其中使用 —undefined-only 来替换 —defined-only ,该指令用于查看间接符号;-m ,这可以让你看到这些方法源自哪个 framework 或 libraries。下面图中的输出结果提示 MagicNumbers App 依赖了 libSwiftCore 中的一系列 Swift 基础方法如 print()。function starts 、nlist 符号表和 DWARF 三种符号化工具;截止现在已经讨论了前两种,在此回顾一下;Function starts 能提供地址列表,缺少方法名,可以帮助计算崩溃对应的文件地址偏移量;Nlist 符号表把关联到一个地址的详细信息构成结构体存储,nlist 符号能提供函数名称,还可以描述在 App 内定义的直接符号和在二方库中提供的间接符号;直接符号表通常保留与链接有关的函数,Xcode 项目设置中的 strip build style 会影响直接符号表中的内容;App 二进制文件 Mach-O 头中的 __LINKEDIT 二进制段中DWARF 时,一般指的是引用分析一个 dSYM bundle,该 bundle 中存在由元数据组成的 plist,还包括一个 DWARF 二进制文件;二进制文件中将 DWARF 的信息记录在 __DWARF 二进制段中;DWARF 在该二进制段中记录了我们需要关注的三个数据流;具体而言三个数据流分别是 debug_info, debug_abbrev, debug_line ;debug_info 包含了原始数据,debug_abbrev 为原始数据进行了结构化处理,debug_line 包含了文件名和行号;除此之外 DWARF 还定义了需要讨论的两种 vocabulary list 词汇表:compile unit 编译单元和 subprogram 子程序;后文会提到第三种词汇表 - 内联子程序dwarfdump 命令行工具来验证上述 DWARF 的编译单元、子程序和关系树细节
首先我们将查看到一个编译单元,这句之前提到的编译单元所携带的属性相吻合(文件名、语言、行数等),dwarfdump 工具结合了 debug_info 和 debug_abbrev 内容来展示 dSYMs 文件中的数据结构与内容subprogram;它所占用的地址范围存在于该编译单元的地址范围内,并且可以看到方法名;之前提到过 DWARF 非常详细的描述符号表和关系信息,我们不会在深入探究 DWARF 的关系树 设计细节,但了解这些细节能够帮助我们理解符号化背后的逻辑;DWARF 持有一个自己的词汇表,来描述参数的名称和类型;参数是子程序的一个子节点;下图中的输出,可以发现 numberofChoice 函数的参数 choices 的相关信息;文件名与行数信息debug_line 数据流中存储了函数关联的文件名和具体行数;但 debug_line 数据流不是树状结构,相反的,该数据流定义了一个 line table program 行表程序,这个航标程序可以让链接后的文件地址映射到源码文件中的具体行数;我们可以利用这个行表程序来查找文件地址关联的具体源码和行数;debug_info 的树状结构和 debug_line 的行表程序,我们可以得到一个下面的结构;通过遍历这棵树,我们可以找到想要的文件地址;首先从编译单元开始,遍历其子节点,然后筛选出包含 debug_line 的子节点;-i 意味着什么;事实上 atos 的 -i 意味着 inlined function 内联函数,内联化是一种编译器执行的常规优化;详细而言,内联化就是在编译中把函数的实现代码直接替换函数被调用的代码;这样的替换操作可以让函数调用的代码和函数的定义代码都「消失了」;在我们的 Demo 中也就是使用 numberOfChoice() 的实现代码替换了调用代码;numberOfChoice() 调用代码不见了~DWARF 符号化有了更全面的了解,如下图所示,我们对 App 的调用逻辑也有了更广阔的视角。了解内联函数的优化方式和细节是完全符号化崩溃日志的关键所在;-i 指令实际会要求 atos 符号化过程中考虑到上述内联函数;这些内联函数的信息同样在 Instruments 堆栈中缺失;我们在崩溃日志和 Instruments 堆栈中都需要 dSYM 文件,正是由于 dSYM 中精确地包含了上述三种类型的信息:编译单元、子程序和 DWARF 关系树;nlist 条目可以通过 dsymutil -dump-debug-map 命令行工具来输出和详细查看;在此我们列出了不同函数方法和他们的出处;这些地址信息可以被扫描并处理成 DWARF 文件中所需的信息;DWARF 描述了函数与文件之间的重要关系信息;DWARF 妥当处理了编译时内敛优化的问题;dSYM 文件和静态库可以都可包含 DWARF;dSYM 获取 DWARF,因为从 dSYM 中获取的 DWARF 可以方便的在其他工具中使用,并且 Xcode 许多内置工具也支持 DWARF;App Store Connect 的 App,你可以在那下载到 dSYMbitcode 技术 ,你也可以从 App Store Connect 下载到 dSYM 文件DWARF,你可以通过 draftdump -verify 命令来检验 DWARF 的有效性;如果这个检查命令输出任何错误,请直接通过 https://feedbackassistant.apple.com 来进行Developer Tool - 开发工具的 bug 反馈;DWARF 二进制文件大小上线是 4GB,如果上述校验中报告超过 4GB 的错误,你可以考虑将项目的进行组件化拆分,以便每个组件会有一个较小的 dSYMdSYM 的 UUID 和崩溃日志中 binary image 的 UUID 性来匹配两者;除了在崩溃日志中查看 App 二进制镜像的 UUID ,你还可以通过 symbols 命令行工具来获取 UUID,参照下图;实际符号化中,需要 dSYM 和崩溃日志的 UUID 匹配;dSYM 文件了,但是仍旧未能将 Instruments 中的堆栈信息符号化,请检查一下项目的 Entitlements 和代码签名配置;具体来说使用 codesign 命令行工具,你可以验证是否拥有正确的代码签名配置;entitlement 中是否包含了 get-task-allow 项,该配置授予 Instruments 这类工具在调试中执行对应 App 符号化的权利;一般来说,Xcode 默认自动会设置这个 get-task-allow 配置项;但 Instruments 不能符号化的时候,可以排查一下这个配置项;如果你发现 entitlement 中没有 get-task-allow ,可以检查确保 build-setting -> code signing -> code signing inject base entitlemens 的值为 true ,来解决该问题;Universal 2 技术的 App, 在使用文章中提到的命令行工具时,都可以指定架构,诸如 symbols、otool、dwarfdump 都有 -arch 的参数可供配置,如此可以只执行特定架构的相关操作;dSYM 完成符号化;dSYM 以 DWARF 的形式记录了最丰富细节的调试信息,并且被 Xcode 和 Instruments 所良好支持otool, vmmap, nm, symbols, dwarfdump, atos;这些工具包含在 Xcode Command line tool中,提供了强大的诊断和检视符号化过程与细节信息的能力;必要时,大家可以将这些工具集成进自己的工作流;prepare_load_methods 方法可看出,在遍历 Class 的 +load 方法时会执行 schedule_class_load 方法,这个方法会递归到根节点来满足 Class 收集完整关系树的需求。最后,call_load_methods 会创建一个 autoreleasePool 使用函数指针来动态调用类和 Category 的 +load 方法。所以在开发调试阶段可以在代码改完后先不去链接项目里的所有文件,只编译当前修改的文件动态库,通过运行时加载动态库即时更新,看到修改结果。