机器学习算法+中医电子病历抽取
Posted 古今医案云平台
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习算法+中医电子病历抽取相关的知识,希望对你有一定的参考价值。
在现今大数据时代背景下,中医电子病历对中医药信息的数据挖掘起到十分重要的作用,因为它们往往是最直接的数据来源。这些信息以纯文本、非结构化的形式记录在电子病历中,不利于进行专门的数据挖掘与分析。研究如何通过计算机算法,把一个完整的中医电子门诊病历文本的有价值信息自动分类输出,对中医诊疗经验的传承与中医电子病历的数据挖掘,以及更有效率地进行相关领域科研工作有着十分重要的作用。
目前,医学命名实体识别的方法主要有基于字典、基于规则和基于机器学习的方法,随着人工智能时代的逐渐到来,基于机器学习甚至是深度学习的方法体现出了较大的优势,并成为当前研究方法的主流。朴素贝叶斯算法与词向量(word2vec)都是比较成熟的文本分类机器学习算法。

朴素贝叶斯算法
朴素贝叶斯基于古典数学贝叶斯理论,假设样本各属性间相互条件独立。判断文本属于哪个类别,根据文本属于哪个类别的条件概率越大就判定为哪类,其中属于某类别的条件概率是依据贝叶斯公式计算样本的关键词属于各类别的条件概率乘积。从其原理可以看出,朴素贝叶斯算法忽视了词条间的相互依赖关系,不注重文本的上下文联系,且忽略了同义词的影响,适用于提取文本中内容较短、同义词少的字段,如‘舌’‘脉’信息。

图1:朴素贝叶斯模型训练
词向量(word2vec)
word2vec 算法是把每个分词转化为向量,从而可以刻画每个分词及其上下文的分词集合。利用其上下文联系强的特点,词向量(word2vec)适合于语段较长、有强上下文关联的中文语句分类。word2vec 是一种浅层的神经网络算法,主要包括2个模型,分别是连续词袋模型模型(continuous bag of words,CBOW)和连续跳跃元语法模型(continuousSkip-gram model,Skip-gram),CBOW 模型通过词的上下文对当前词预测学习词向量,而Skip-gram是根据当前词对其上下文进行预测来学习的。
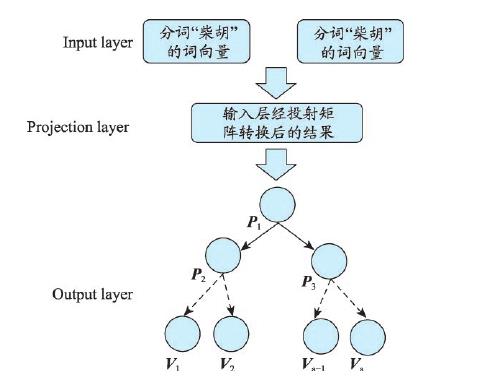
图2:CBOW模型网络结构
P(辅助向量)和V(词向量)在不断的迭代中进行更新)
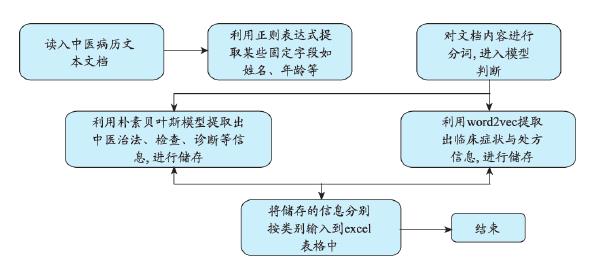
图3:测试集测试流程图

图4:中医电子病历文本

图5:中医电子病历模型分类抽取结果

图6:模型测试结果
小结
利用朴素贝叶斯和 word2vec 两种机器学习算法。先是通过对训练集的数据进行训练,得到最终的模型,然后通过测试集进行生成模型的测试。经过对测试结果的分析,得到了一个较好的中医电子门诊病历命名实体与信息抽取结果。不足之处在于总体数据有限,且可供训练的中医电子病历文本格式相对单一,造成了最终训练得到的模型对该种中医电子病历文本格式产生了一定的特异性。本研究为提取中医电子病历文本信息,从而进行更深一步的数据挖掘和科研任务做了基础性工作,提出了一种值得推广的方法。
参考文献:刘一斌,叶辉,易珺,曹东.基于朴素贝叶斯和word2vec的中医电子病历文本信息抽取[J].世界科学技术-中医药现代化,2020,22(10):3563-3568.
推荐阅读:
1.
2.
3.
4.
5.

古今医案云平台
提供40余万古今医案检索服务
支持手工、语音、OCR、批量医案结构化录入
设计九大分析模块,贴近临床实际需求
支持平台海量医案与个人医案协同分析
云医案APP
云医案V1.2.4新增健康医历、快速采集的功能。对写医案、说医案和扫医案的字段输入进行整体优化以及局部功能变更,医案管理、医案同步、个人中心做了相应调整。
仅支持安卓手机,扫描下方二维码进行下载或识别下载。
中国中医科学院中医药信息研究所
中医药大健康智能研发中心
大数据研发部
qq:2778196938
客户端下载:www.yiankb.com
以上是关于机器学习算法+中医电子病历抽取的主要内容,如果未能解决你的问题,请参考以下文章