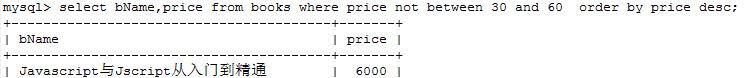iOS符号化浅析
Posted CoderStar
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了iOS符号化浅析相关的知识,希望对你有一定的参考价值。
Hi Coder,我是 CoderStar!
十一去云南(丽江、大理、昆明)玩了一趟,怎么说呢,可能我想象中的云南是西双版纳、香格里拉那样子的,所以这次云南之行跟想象中还是有一定差异的。
云南的小锅米线,豆花米线、米布还是挺好吃的,特别是米布,之前没有吃过,给人眼前一亮的感觉,不过乳扇个人接受不了,可能是喜欢喝牛奶的同学的福音。
还有就是这个时候去,用我女朋友的话说就是十一的玉龙雪山没有雪,滇池也没有海鸥。

好了,言归正传,下面我们聊聊ios符号化的知识吧,假期归来,需要肝篇文章找找状态。
之前对于符号化的相关知识总是零零碎碎的,不成体系,刚好最近看到很多位同学发了一些关于 iOS 符号化的文章,便整理这篇文章梳理一下 iOS 符号化的相关知识。我对符号化还处于初级阶段,文中很多知识来源于下面的参考资料,感谢各位同学的分享。
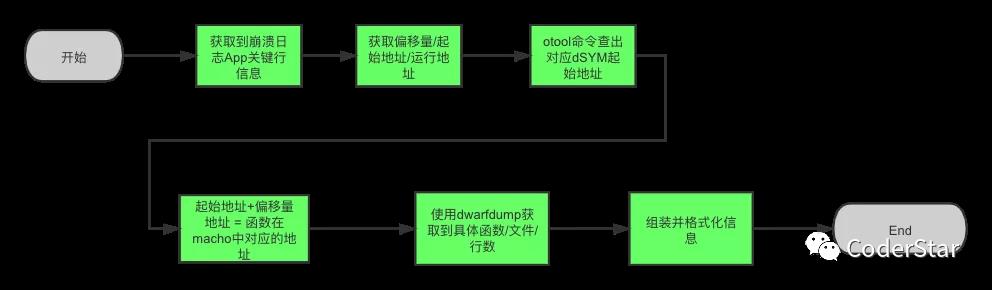
符号化从通俗意义上讲就是把一些机器语言可以转化成人类可读的符号,而在这里的环境下就是指 iOS 或者 Mac OS 下的一些异常信息(十六进制符号表示)通过某些手段转化成开发人员可读的高级代码片段,从而进一步定位异常的来源,迅速修复。
符号化程度一般会分为三种:

符号化一般情况会需要下面三个部分
崩溃日志的获取有多种来源,包括以下几种:
设置-隐私-分析与改进-分析数据导出,这个区域可以获取到整部手机的一些异常信息,是Jetsam机制产生的,格式为.ips,需要注意该位置不一定能拿到所有 APP 的异常日志(起码我测试时没拿到);Xcode -> Window-Devices and simulators -> View Device Logs(左侧工具栏选中你要导出的目的设备),导出文件格式为.crash,其实这种方式读取到的日志文件来源还是来自上面第一条的;Xcode-Organizer-Crashes获取崩溃日志,格式为.xccrashpoint,打开其包内容,其实内部还是文件格式为.crash的日志文件;其实上述几种方式大致可以分为两种
上面不管是哪种方式,对我们最重要的信息还是错误堆栈。对于我们需要在代码中去捕获异常这种情况,收集的实现思路会包括下列方式,常用的 Crash 收集框架会将下列方式进行组合使用。
mach_port_allocate -> mach_port_insert_right -> task_set_exception_ports -> 循环等待消息signalNSSetUncaughtExceptionHandler其实 Unix 信号本身也是 Mach 异常传递到上层进行转换得到的。
其中NSSetUncaughtExceptionHandler值可以捕获到 OC 的异常,Swift 的异常是捕获不到的,一般情况下在捕获 NSException 异常后同时也会捕获到一个对应的 signal 异常,当然,这也是一般情况,特殊情况下是有可能没有的。
下列给出简易的异常捕获代码示例,实际的异常捕获要比这个复杂很多,包含获取Slide Address,异常捕获的传递、Mach Exception等等。
详细的 Crash 收集代码可以看下列开源的异常捕获工具:
DWARF
DWARF(Debuging With Arbitrary Record Format) 是 ELF 和 Mach-O 等文件格式中用来存储和处理调试信息的标准格式。其内部数据是高度压缩的,可以通过 dwarfdump、otool 等命令提取其中的可读信息。通过 MachOView 打开 DWARF 后会发现其外层依旧是 Mach-O 格式。其中 debug_info、debug_line这两个 section 中存储了主要的调试信息。
ELF、Mach-O 分别是 Linux 和 Mac OS 平台用于存储二进制文件、可执行文件、目标代码和共享库的文件名称。
dSYM
iOS 平台中, dSYM 文件是指具有调试信息的目标文件,dSYM 中存储着文件名、方法名、行号等信息,是和可执行文件的 16 进制函数地址一一对应的,通过分析崩溃的崩溃文件可以准确知道具体的崩溃信息。
Build Settings -> Debug Information Format中可以设置调试信息的形式,其有两个选项,
DWARFDWARF DWARF With dSYM File一般情况下我们Debug环境下使用DWARF方式,方便我们进行调试,那对于Release环境我们使用第二种方式,选择第二种方式便可以将符号表从二进制文件中进行剥离,改为使用 dSYM 文件进行存储。开启之后我们就可以在 Xcode 打包出来的文件 xcarchive 里面看到它。另外,如果开启了 bitcode 优化的话,苹果会做二次编译优化,所以最终的 dSYM 就需要在 Apple Connect 手动下载了。
dSYM 文件对于符号化过程非常重要,所以我们每次发版之后对 dSYM 文件的备份保存是非常必要的。
虽然没有 dSYM 文件时也有其他办法(可见
却都是 0,主要原因该崩溃处出现了函数内联,但是 符号化流程 dwarfdump没有很好兼容到多级内联这种场景,实际上dwarfdump这种方式相对还是受限,所以一般情况下使用下列方式atos居多。使用 atos
使用这种方式,我们不需在手动计算崩溃地址对应 dSYM 符号表中的地址,
通过上面的符号化流程,我们可以对符号化的原理及过程有个大致了解,并且从中我们也了解到了不同的符号化方式,比如
dwarfdump以及atos等。下面我们来看堆栈符号化有哪几种方式:
symbolicatecrash:可以符号化整个 Crash 文件,线上用的比较少,更多是线下使用,或者使用 Xcode 内置的 Crash -> Xcode-Organizer-Crashes;mac 下的 atos工具:单行堆栈符号化;linux 下的 atos 的替代品:如 根据上面的符号化流程,我们用到了下列工具。
或者Re-symbolicate Log就能符号化。symbolicatecrash_xcode 符号化自己 App 的方法名,需要编译生成的 dSYM 文件。而要将系统库的符号化为完整的方法名,也需要 iOS 各系统库的符号文件。
系统库符号的文件不是通用的,需要对应崩溃所在设备的系统版本和 CPU 型号。所以说为了符号化所有的符号,我们需要尽可能收集不同版本的系统符号文件。
下列为我从 Xcode 导出的 Crash Log 顶部信息,从中我们可以拿到产生 Crash 的设备相关信息。
目录下,就可以使用 Xcode 自带的符号化工具 symbolicatecrash 进行符号化了。这个工具会自动根据崩溃日志中系统库的 UUID 搜索本机系统库的符号文件。获取系统符号文件的几个方法
从真机上获取 当你用 Xcode 第一次连接某台设备进行真机调试时,会看到 Xcode 显示
Processing symbol files,这时候就是在拷贝真机上的符号文件到 Mac 系统的/Users/xxx/Library/Developer/Xcode/iOS DeviceSupport目录下。从已解密的固件中提取符号文件 已经有很多同学给出了方式,如参考资料中
聊聊从iOS固件提取系统库符号,不再赘述。给出过程中需要用到的地址。在线符号化其实就是上文中提到的符号化最后一种方式,其核心在于使用工具提取地址与符号的对应关系,这需要我们对 DWARF 文件结构有所了解,找到其对应关系所在位置,核心是
debug_line及debug_info两段的内容。相关细节可查看下面《iOS 符号解析重构之路》以及《iOS 符号化:基础与进阶》。
在解析 DWARF 过程中我们可以根据自己的情况选用一些工具。
gimli[15]:基于 rust 的读写 DWARF 调试格式的库 debug/dwarf:基于 golang 原生的系统库 debug/dwarf,可以实现对 DWARF 文件的解析,将地址解析为符号。当然我们也可以不使用一些现成的库,自己使用文件读取的方式进行解析,如 bugly 的
最后buglySymboliOS.jar。要更加努力呀!
Let\'s be CoderStar!
参考 & 建议资料
你真的了解符号化么? iOS 符号解析重构之路 iOS 符号化:基础与进阶 iOS 崩溃日志在线符号化实践 漫谈 iOS Crash 收集框架[16] iOS Crash 分析:符号化系统库方法[17] - 参考资料
聊聊从 iOS 固件提取系统库符号[18] [1] KSCrash: https://github.com/kstenerud/KSCrash
[2]plcrashreporter: https://github.com/microsoft/plcrashreporter
[3]CrashKit: https://github.com/kaler/CrashKit
[4]大白健康系统--iOS APP 运行时 Crash 自动修复系统: https://neyoufan.github.io/2017/01/13/ios/BayMax_HTSafetyGuard/
[5]JJException: https://github.com/jezzmemo/JJException
[6]KSCrashMonitor_NSException: https://github.com/kstenerud/KSCrash/blob/master/Source/KSCrash/Recording/Monitors/KSCrashMonitor_NSException.m
[7]KSCrashMonitor_Signal: https://github.com/kstenerud/KSCrash/blob/master/Source/KSCrash/Recording/Monitors/KSCrashMonitor_Signal.c
[8]详解没有 dSYM 文件 如何解析 iOS 崩溃日志: https://www.cnblogs.com/ciml/p/7422872.html
[9]DSYMTools: https://github.com/answer-huang/dSYMTools
[10]atosl: https://github.com/facebookarchive/atosl
[11]llvm-atosl: https://github.com/llvm/llvm-project/blob/main/llvm/include/llvm/DebugInfo/DWARF/DWARFContext.h
[12]theiphonewiki: https://www.theiphonewiki.com/wiki/Firmware
[13]Firmware_Keys: https://www.theiphonewiki.com/wiki/Firmware_Keys
[14]iOS-System-Symbols: https://github.com/Zuikyo/iOS-System-Symbols
[15]gimli: https://docs.rs/gimli/0.25.0/gimli/
[16]漫谈 iOS Crash 收集框架: http://www.cocoachina.com/articles/12301
[17]iOS Crash 分析:符号化系统库方法: https://zhuanlan.zhihu.com/p/142322138
[18]聊聊从 iOS 固件提取系统库符号: http://crash.163.com/#news/!newsId=31
有一个技术的圈子与一群志同道合的朋友非常重要,来我的技术公众号,这里只聊技术干货。
微信公众号:CoderStar
Msql浅析-基础命令
篇幅简介一、Msql数据类型
1、整型
tinyint, 占 1字节 ,有符号: -128~127,无符号位 :0~255
smallint, 占 2字节 ,有符号: -32768~32767无符号位 :0~65535
mediumint 占 3字节 ,有符号: -8388608~8388607,无符号位:0~16777215:
int, 占 4字节 ,有符号: -2147483648~2147483647,,无符号位 无符号位 :0~4 284967295
bigint, bigint,bigint, 占 8字节
bool 等价于 tinyint
2、浮点型
float([m[,d]]) 占 4字节 ,1.17E-38~3.4E+3838~3.4E
double([m[,d]]) 占 8字节
decimal([m[,d]]) 以字符串形式表示的浮点数
3、字符型
char([m]): :定长的字符 ,占用 m字节
varchar[(m)]::变长的字符 ,占用 m+1m+1 字节,大于 255 个字符:占用 m+2m+2
tinytext,255 个字符 (2 的 8次方 )
text,65535 个字符 (2 的 16 次方 )
mediumtext,16777215字符 (2 的 24 次方 )
longtext (2的 32 次方 )
enum(value,value,...)占 1/2个字节 最多可以有 65535 个成员 个成员
set(value,value,...) 占 1/2/3/4/8个字节,最多可以 有 64个成员
二、Mysql数据运算
1、逻辑运算 and or not
for example:
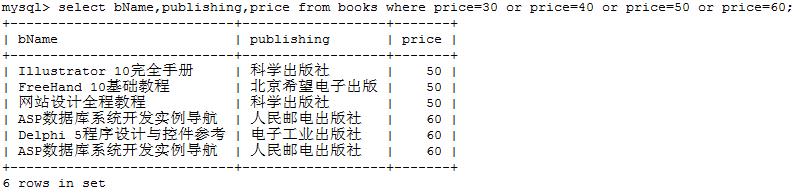
选择出 书籍价格 为(30,60,40,50)的记录
sql> select bName,publishing,price from books where price=30 or price=40 or price=50 or price=60;
12、in 运算符
in 运算符用于 WHERE 表达式,以列表的形式支持多个选择,语法如下
where colunmm in (value1,value2,.......)
where colunmm not in (value1,value2,..........)
当in前面加上not时,表示与in相反,既不在结果中
sql> select bName,publishing,price from books where price in (30,40,50,60)order by price asc;
23、算术运算符 >= | <=| <> |=
for example
找出价格小于70的记录
mysql> select bName,price from books where price <= 70;
34、模糊查询 like \'%...%\'
字段名 [not] like \'%......%\' 通配符 任意多个字符
查询书中包含程序字样的记录
mysql> select bName,price from books where bName like \'%程序%\'
45、范围运算 [not] between .......and
查找价格不在30和60之间的书名和价格
mysql> select bName,price from books where price not between 30 and 60 order by price desc;
56、Mysql 子查询
select where条件中又出现select
查询类型为网络技术的图书
mysql> select bName,bTypeId from books where bTypeId=(select bTypeId from category where bTypeName=\'网络技术\');
67、limit 限定显示的条目
LIMIT子句可以被用于强制 SELECT语句返回指定的记录数。 LIMIT 接受一个或两数字参。必 须是一个整数常量。如果给定两 个数,第一指定返 回记录行的偏移量,第二个参数返回记录行的最大数目。初始偏移量是 0( 而不是 1)。
语法 : select * from limit m,n
其中 m是指记录开始的 index indexindex,从 0开始,表示第一条记录,n是指从第 m+1 条开始,取 n。
查询books表中第2条到六行的记录
mysql>select * from books limit 1,6;
78、连接查询
以一个共同的字段,求两张表当中符合条件并集。 通过 共同字段把这两张表的共同字段把这两张表连 接起来。
常用的连接:
内连接:根据表中的共同字段进行匹配
外连接:现实某数据表的 全部记录和另外数据表中符合连接条件的记录。
外连接:左连接、右连接
内连接:for exmaple
create table student(sit int(4) primary key auto_increment,name varchar(40));
insert into student values(1,‘张三’),(2,‘李四’),(3,‘王五’),(4,‘mikel’);
create table teachers(sit int(4),id int(4) primary key auto_increment,score varchar(40));
insert into teachers values(1,1,‘1234’),(1,2,‘2345’),(3,3,‘2467’),(4,4,‘2134’);
select s.* ,t.* from student as s,teachers as t where s.sid=t.sid;
8左连接: select 语句 a表 left[outer] join b 表 on 连接条件 ,a表是主,都显示。
b表是从,主表内容全都有,主表多出来的字段,从表没有的就显示 null,从表多出主表的字段不显示。
select * from student as s left join teachers as t on s.sit=t.sit;
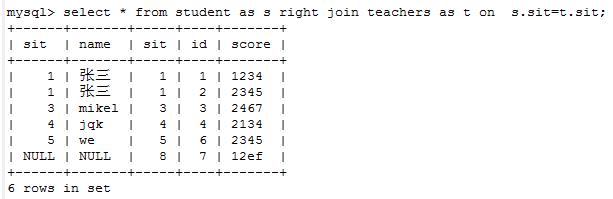
9右连接:select 语句 a表 right[outer] join b 表 on 连接条件 ,b表是主,都显示。
a表是从,主表内容全都有,主表多出来的字段,从表没有的就显示 null,从表多出主表的字段不显示。
select * from student as sright join teachers as t on s.sit=t.sit;
10三、聚合函数
1、sam() 求和
select sum (id+score) as g from teachers;
2、avg() 求平均值
select avg (id+score) as g from teachers;
3、max() 最大值
select max (id) as g from teachers;
4、min() 最小值
select min(id) as g from teachers;
5、substr(string,start,len) 截取
select substr(soucr,1,2) as g from teachers;
从start开始,截取len长度,start从1开始
concat(str1,str2,str3......................)字符串拼接,将多个字符串拼接在一起
select concat(id,score,sit) as g from teachers;
6、count() 统计计数 记录字段数据条数
select count(id) as g from teachers;
7、upper() 大写
select upper(name) as g from student; #将字段name中英文全部变为大写,但不改变原值
8、lower() 小写
select lower(name) as g from student; #将字段name中英文全部变为小写,但不改变原值
四、索引
mysql中索引是以文件形式存放的,对表进行增删改,会同步到索引,索引和表保持一致,常用在where 后字段查询就加索引。
优点:加快查询速度,减少查询时间
缺点:索引占据一定磁盘空间,会影响insert,delete,update执行时间
1、索引类型
普通索引:最基本索引,不具备唯一性
唯一索引:索引列的值必须唯一,但允许有空值。如果是组合索引,则列值的组合必须唯一
主键索引:记录值唯一,主键字段很少被改动,不能为空,不能修改,可用于一个字段或者多个字段
全文索引:检索文本信息的, 针对较大的数据,生成全文索引查询速度快,但也很浪费时间和空间
组合索引:一个索引包含多个列
2、创建索引
普通索引:
# 创建普通索引
create table demo(id int(4),uName varchar(20),uPwd varchar(20),index (uPwd));
# 查看建表过程
show create table demo;
demo | CREATE TABLE `demo` (
`id` int(4) DEFAULT NULL,
`uName` varchar(20) DEFAULT NULL,
`uPwd` varchar(20) DEFAULT NULL,
KEY `uPwd` (`uPwd`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 |
唯一索引:字段值只允许出现一次,可以有空值
# 创建唯一索引
create table demo1(id int(4),uName varchar(20),uPwd varchar(20),unique index (uName));
# 查看建表过程
show create table demo1;
demo1 | CREATE TABLE `demo1` (
`id` int(4) DEFAULT NULL,
`uName` varchar(20) DEFAULT NULL,
`uPwd` varchar(20) DEFAULT NULL,
UNIQUE KEY `uName` (`uName`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 |
主键索引:字段记录值唯一,字段很少被修改,一般主键约束为auto_increment或者not null unique,不能为空,不能重复。
# 创建主键索引
create table demo2(id int(4) auto_increment primary key,uName varchar(20),uPwd varchar(20));
# 查看建表语句
demo2 | CREATE TABLE `demo2` (
`id` int(4) NOT NULL AUTO_INCREMENT,
`uName` varchar(20) DEFAULT NULL,
`uPwd` varchar(20) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 |
全文索引:提高全文检索效率,解决模糊查询
# 创建全文索引
create table demo3(id int(4),uName varchar(20),uPwd varchar(20),fulltext(uName,uPwd));
# 查看建表语句
| demo3 | CREATE TABLE `demo3` (
`id` int(4) DEFAULT NULL,
`uName` varchar(20) DEFAULT NULL,
`uPwd` varchar(20) DEFAULT NULL,
FULLTEXT KEY `uName` (`uName`,`uPwd`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 |
五、外键约束
外键约束:foreign key 表与表之间的一种约定关系,由于这种关系存在,让表与表之间的数据更加具有完整性,更加具有关联性。
创建外键约束
创建user主表
create table user1(id int(11)auto_increment primary key,name varchar(50),sex int(1));
插入数据
insert into user1(name,sex)values("mikel",4),("plyx",6);
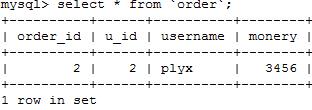
创建order外键表
create table `order`(order_id int(11)auto_increment primary key,u_id int(11),username varchar(50),monery int(11),foreign key(u_id) references user1(id) on delete cascade on update cascade )engine=innodb);
插入数据
INSERT INTO `order` (order_id,u_id,username,monery)values(1,1,\'mikel\',2345),(2,2,\'plyx\',3456)
测试级联删除
delete from user1 where id=1
查看order表记录
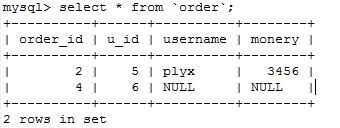
12测试级联更新
update user1 set id=5 where id=2
13测试数据完整性
在order表中插入一条u_id为6的记录
insert into `orser` (u_id)values(6);
Cannot add or update a child row: a foreign key constraint fails (`school`.`order`, CONSTRAINT `order_ibfk_1` FOREIGN KEY (`u_id`) REFERENCES `user1` (`id`) ON DELETE CASCADE ON UPDATE CASCADE)
user1中不存在id为6的记录,现在添加一条id为6的记录
insert into user1(id)values(6);
14可以看到数据已经插入进去了
视图
是一张虚拟表,由 select select select语句指定的数据结构和数据,不生成真实文件
create view mikel as select * from school.books;
select * from mikel;
15六、存储过程
存储过程用来封装mysql代码,相当于函数,一次编译,生成二进制文件,永久有效,提高效率。
1、定义存储过程
create procedure 过程名(参数1,参数2,.............)
begin
sql语句
end
2、调用存储过程
call 过程名(参数1,参数2,...................)
example:定义一个存储过程查看books表中所有数据
1. 修改sql默认执行符号
delimiter //
create procedure seebooks();
begin
select * from sctudent.books;
end //
call seebooks() //
163、存储过程参数传递
in 传入参数 int 赋值
IN输入参数:表示调用者向过程传入值(传入值可以是字面量或变量)
OUT输出参数:表示过程向调用者传出值(可以返回多个值)(传出值只能是变量)
INOUT输入输出参数:既表示调用者向过程传入值,又表示过程向调用者传出值(值只能是变量)
create procedure seebook(in b int)
begin
select * from school.books where bId=b;
end //
call seebook(4)
16out --------------传出参数
select into 在过程中赋值传给变量,并查看变量值
create procedure seebook2(out b varchar(100))
begin
select bName into b from school.books where bId=4;
end //
17过程内的变量使用方法
声明变量名称,类型,declare 过程内的变量没有@
赋值 set 变量名=(select 语句)
create procedure seebook3()
begin
declare str varchar(100);
set str=(select bName from school.books where bId=20);
select str;
end//
call seebook3() //
181、触发器
与数据表有关,当表出现(增,删,改,查)时,自动执行其特定的操作
语法:create trigger 触发器名称 触发器时机 触发器动作 on 表名 for each row
触发器名称:自定义
触发器时机:after/before 之后/之前
触发器动作:insert update delete
创建触发器:
create trigger delstudent after delete on grade for each now
delete from student where sid=\'4\';
delete from grade where sid=4;
mysql> select sid from student where sid=4;
Empty set
查看是否还有sid=4的值,可以发现已经被删除
2、事务
单个逻辑单元执行的一系列操作,通过将一组操作组成一个,执行的时要么全部成功,要么全部失败,使程序更可靠,简化错误恢复。
MySQL 事务主要用于处理操作量大,复杂度高的数据。比如说,在人员管理系统中,你删除一个人员,你即需要删除人员的基本资料,也要删除和该人员相关的信息,如信箱,文章等等,这样,这些数据库操作语句就构成一个事务!
在 MySQL 中只有使用了 Innodb 数据库引擎的数据库或表才支持事务。
事务处理可以用来维护数据库的完整性,保证成批的 SQL 语句要么全部执行,要么全部不执行。事务用来管理 insert,update,delete 语句。
MYSQL 事务处理主要有两种方法:
1、用 BEGIN, ROLLBACK, COMMIT来实现
BEGIN 开始一个事务
ROLLBACK 事务回滚
COMMIT 事务确认
2、直接用 SET 来改变 MySQL 的自动提交模式:
SET AUTOCOMMIT=0 禁止自动提交
SET AUTOCOMMIT=1 开启自动提交
创建事务
begin;
update books set bName="plyx" where bId=1;
update books set bName="plyx" where bId=2;
commit//
查看记录,已经修改了
select * from books;
19七、mysql数据结构
主配置文件 my.cnf
数据目录:/var/lib/mysql
进程通信sock文件 :/var/lib/mysql/mysql.sock
错误日志文件
[mysqld_safe]
log-error=/var/log/mysqld.log
进程PID文件:pid-file=/var/run/mysqld/mysqld.pid
二进制文件:log-bin=mysql-bin.log
八.常见的存储引擎介绍
myisam :
特性: 1、不支持事务,不支持外键,宕机时会破坏表
2、使用较小的内存和磁盘空间,访问速度快
3、基于表的锁,表级锁
4、mysql 只缓存index索引, 数据由OS缓存
适用场景:日志系统,门户网站,低并发。
Innodb:
特性:1、具有提交,回滚,崩溃恢复能力的事务安全存储引擎
2、支持自动增长列,支持外键约束
3、占用更多的磁盘空间以保留数据和索引
4、不支持全文索引
适用场景:需要事务应用,高并发,自动恢复,轻快基于主键操作
MEMORY:
特性:1、Memory存储引擎使用存在于内存中的内容来创建表。
2、每个memory表只实际对应一个磁盘文件,格式是.frm。memory类型的表访问非常的快,因为它的数据是放在内存中的,并且默认使用HASH索引,但是一旦服务关闭,表中的数据就会丢失掉。
3、MEMORY存储引擎的表可以选择使用BTREE索引或者HASH索引。
九、思考与总结
到此主要介绍,mysql一些使用技巧,包括数据类型,查询方法,存储过程,外键约束,索引。触发器,事务,还包含一些存储引擎介绍,到此基础部分结束,还有后面的分享将会陆续推出,敬请期待!
总结我是MIkel Pan,云计算爱好者,定期更新生活感悟,心灵进化者就在MIkel Pan,喜欢我就来找我吧!
博客园地址:http://www.cnblogs.com/plyx/
简书地址:https://www.jianshu.com/u/5986765934f4
以上是关于iOS符号化浅析的主要内容,如果未能解决你的问题,请参考以下文章